안녕하세요. 제가 이번에 리뷰할 논문은 올해 10월에 공개된 논문입니다. 최근 affordance 관련 연구들을 리뷰하였는데, 이번에 리뷰할 논문은 3D point cloud에서의 Affordance 영역을 찾는 논문이라 읽어보게 되었습니다. 리뷰 시작하겠습니다.
0. Abstract
affordance understanding이란 3D 객체에서 actionable한(어떠한 작업을 수행할 수 있는) 영역을 인식하는 것 입니다. VLM의 발전으로 고차원 추론과 long-horizon planning(짧고 단순한 작업이 아닌 복잡한 로봇 작업 계획을 의미하는 것으로 보입니다)이 가능해졌으나 사람과 로봇의 상호작용을 위한 미묘한 물리적 특성을 파악하는 것에는 여전히 어려움이 있습니다. 저자들은 PAVLM(Point Affordance VLM)을 제안하여 Point Cloud에 대한 3D Affordance 이해를 높이기 위해 사전학습된 language 모델이 내포한 다양한 멀티모달 지식을 활용하였다고 합니다. PAVLM은 시각적 정보 강화를 위해 LLM의 hidden embdding과 geometric-guided propatation 모듈을 통합하였다고 합니다. 또한, 언어적 측면에서는 더 의미론적으로 증강한 지시문을 입력으로 사용하여 Llama-3.1 모델이 정교한 context-aware text를 생성하도록 하였다고 합니다. 3D affordanceNet 밴치마크에 대한 실험 결과를 통해 PAVLM이 기존 방법론의 성능을 뛰어넘는다는 것을 보였으며, 특히 3D object에 대한 novel open-world affordance task에서 뛰어난 일반화 성능을 보였다고 합니다.
1. Introduction
Affordance understangin은 컴퓨터비전에서 어려운 문제이며, 로봇이 환경과 상호작용을 위해 필수적입니다. 전통적인 방법론은 사람이 annotation한 대량의 데이터로 지도학습을 하는 것에 의지를 해왔으며, 이러한 annoation에는 많은 시간과 비용이 소요되며, 데이터에 해당하는 특정 시나리오로 한정된다는 한계가 있습니다. 또한, 이러한 방식들은 새로운 object나 본 적 없는 환경에서 일반화에 어려움을 겪었으며, 이는 로봇의 실제 활용에 큰 걸림돌이 되었습니다. 로봇 조작시 affordance understanding을 위해서는 객체의 3D 기하학적 정보를 이해하는 것뿐만 아니라 어떻게 잡거나 조작하는 지 등 객체의 기능적 특성도 파악해야 합니다. 또한, real-world에서의 affordance understanding은 로봇 자체에 대한 이해와 주변 물체의 구성, 수행하고자 하는 작업까지 고려해야하며, 해당 논문에서는 object의 3D point 일부와 전체를 모두 고려한 affordance understanding에 초점을 맞췄다고 합니다.(여러 어려움을 언급하지만 그 중 하나에 초점을 맞춘것으로 보입니다,,)
최근 오픈소스 모델인 LLaVA, Blip-2, Qwen-VL 등 다양한 VLMs이 발전하였으며, VLM 모델들은 강력한 시각적 이해와 추론 능력을 보여주었습니다. 그러나 이러한 VLM 모델들은 2D 이미지에 국한되어있으며, 3D affordance 작업을 위한 기하학적 3차원 정보가 부족합니다. AffordanceLLM(자세한 내용은 제가 이전에 작성한 X-review를 참고해주세요)은 최초로 Affordance 인식 task에 LLM을 도입한 방법론으로, 2D 이미지와 함께 실제 depth 정보가 아닌 pseudo depth를 생성하여 함께 입력으로 사용합니다. 그러나 이러한 방식은 이미지로부터 depth를 생성하는 것이다보니 실제 depth 정보로 얻을 수 있는 3D 공간에서의 기하학적 구조를 파악하기 어려워 real-world에서 로봇 조작에 활용되는 데 제한적입니다.
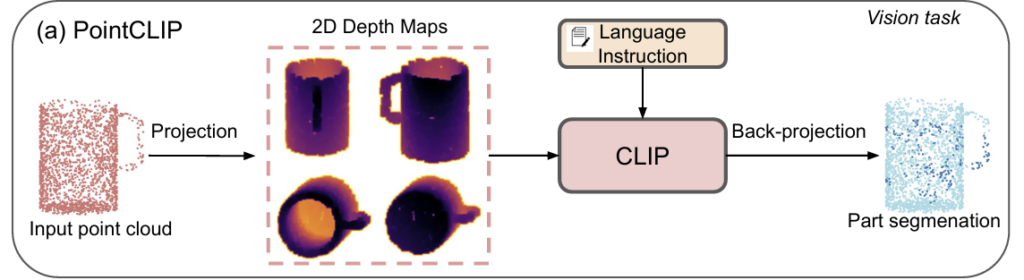
이러한 한계를 극복하기 위해 PointCLIP과 PointCLIP v2 같은 일부 연구는 point cloud를 depth map으로 투영한 뒤 VLM을 적용하는 연구를 제안하였으나, 이러한 방식은 다양한 view로의 투영 과정에 기하학적 정보와 공간적 정보가 소실되게 됩니다. 따라서 저자들은 raw point cloud로 부터 직접 semantic feature를 추출하는 새로운 프레임워크를 제안하였다고 합니다. 3D representation으로부터 직접 feature를 추출하므로써 기하학적 디테일을 풍부하게 하였으며, 보다 포괄적이고 정밀한 affordance understanding이 가능하도록 하였다고 합니다. 저자들이 제안한 PAVLM(point cloud Vision Language Model)은 Llama와 같은 LLM의 지식과 추론 능력을 활용하고 geometric-guided propagation 모듈을 통합하였으며, 3D-AffordanceNet 벤치마크에 대한 실험 결과를 통해 저자들이 제안한 PAVLM이 open-vocabulary affordance learning task에서 강력한 일반화가 가능함을 보였다고 합니다. 폭 넓은 지식과 3D 기하학적 정보를 결합하므로써 저자들의 방식은 새로운 객체에도 더 효과적으로 일반화 되며 이를 통해 실제 3차원 환경에서 직관적이고 효과적으로 로봇과 상호작용이 가능하도록 하였다고 이야기합니다.
해당 논문의 contribution을 정리하면
- 3D point cloud 데이터를 open-source language model과 융합하여 affordance understanding 능력을 강화한 통합된 구조 제안
- 3D point cloud 객체와 학습 샘플에 대한 question-answer 쌍에 폭넓은 augmentation을 주는 파이프라인 제안
- 3D-AffordanceNet 밴치마크에서 SOTA 달성 및 새로운 카테고리의 객체에 대한 강력한 일반화 능력 입증
2. PAVLM FRAMEWORK
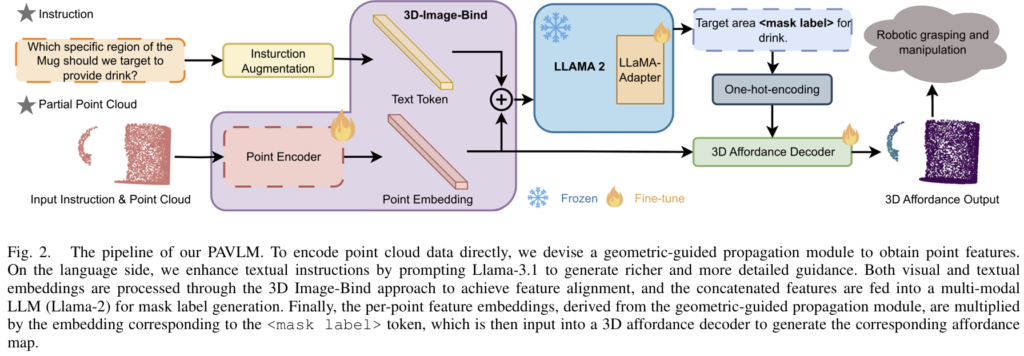
해당 논문에서 제안한 PAVLM은 Point Cloud P와 텍스트 intruction T가 주어졌을 때, <mask label>과 함께 3D affordance map을 생성하는 파이프라인으로 mask label은 point cloud와 합쳐저 정확한 affordance map을 생성하도록 합니다. 전체적인 파이프라인은 [Fig. 2]에서 확인할 수 있으며, 먼저 geometric-guiede point encoder를 통해 기하학적 feature를 추출한 뒤, feature의 정보를 풍부하게 만들기 위해 piont cloud embeding 의 추가합니다.(Section2.1) 그 다음, 데이터 증강을 통해 시스템의 추론 능력을 향상시키고자 프롬프트를 통해 Llama-3.1 LLM 모델을 활용하여 다양한 context-aware question-answer 쌍을 생성합니다.(Section2.2) 이후 사전학습된 3D Image-Bind 모델을 채택하여 point cloud embedding을 text token과 정렬하여 3D 데이터와 지시문 사이의 일관성을 확보합니다.(Section2.3) 그 다음 fine-tuniung된 Llama-2 모델을 사용하여 affordance mask labels를 생성하여 point cloud embeding과 통합한 뒤, 마지막으로 두 embeddings를 3D affordance decoder에 입력하여 최종적으로 정교한 affordance map을 만들어냅니다.(Section2.4) 이제 각 파트에 대해 살펴보겠습니다.
2.1. Geometric-guided Point Encoder
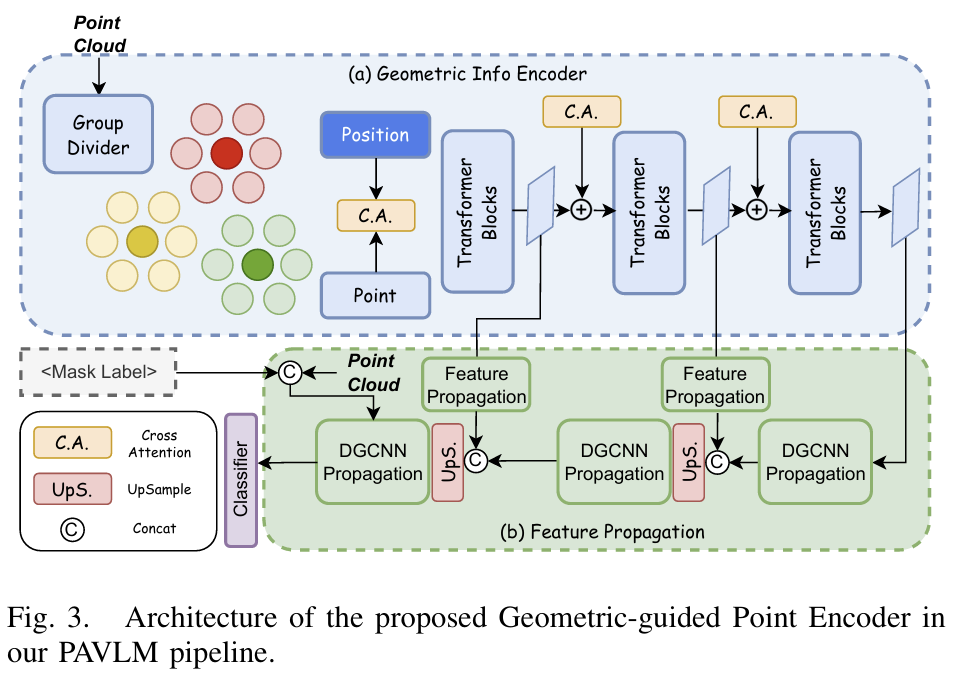
위의 [Fig. 3]은 geometric-guieded point encoder에 대한 네트워크 구조로, point cloud embedding을 생성하는 것을 목표로 합니다. 해당 encoder는 2개의 서브모듈인 (a) geometric information extraction 모듈과 (b) feature propagation 모듈로 이루어져 있습니다.
<geometric information extraction 모듈>
먼저 geometric information extraction 모듈은 point cloud P \in \mathbb{R}^{2080⨉3}를 k개의 point 패치로 만든 뒤, 각 패치들에 convolution 레이어를 적용하여 point-wise features \{f_i\}^k_{i=1}를 생성합니다. 이 feature들은 positional embeddings \{p_i\}^k_{i=1}와 합쳐진 뒤, cross-attention 매커니즘으로 이루어진 일련의 transformer 블록을 통과하여 refine된 geometric features \{g_i\}^k_{i=1} 생성합니다. 이때 transformer blocks은 3개의 레이어로 구성되며, 해당 과정은 아래의 식으로 표현할 수 있습니다.
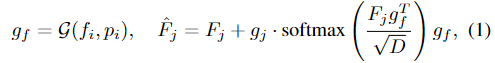
- F_j: j번째 transformer layer의 output
<feature propagation 모듈>
그 다음, point embeddings의 representation을 향상시키기 위해 propagation 모듈을 추가하였다고 합니다. 첫번째와 두번째 transformer block의 outputs에 up-sampling을 적용하여 propagation을 수행하며, DGCNN propatation 방식**을 활용하여 feature가 point cloud전체에 효과적으로 분포하도록 하였다고 합니다.
** DGCNN propatation 방식?
Neural Networks에 2018년에 공개된 ‘DGCNN: A convolutional neural network over large-scale labeled graphs’ 논문으로 대규모 동적 그래프의 지역적 구조를 유연하게 학습할 수 있는 네트워크를 제안한 논문이라고 합니다. 노드 간의 관계를 학습하면서 그래프의 전체 구조적 정보를 통합하는 방식을 적용했다는 것으로 보이지만, 코드가 아직 공개되어있지 않아서 자세한 확인이 어렵네요…
2.2. Textual Instruction Augmentation
그 다음 affordance understanding과정에서 point cloud와 text 사이의 alignment를 강화하기 위해 3D-specific descriontion을 통합하였다고 합니다. 기존 affordance 연구는 “cut”, “handover”, “tool use”와 같은 일반적인 행동 용어를 사용하였으나, AffordanceLLM에서 “What part of the <object name> should we interact with to <action name> it?”이라는 seed question을 생성한 뒤, 이에 대한 “You can <action name>the area <mask token>이 포함된 answer를 생성하는 방식을 제안하였으며, 저자들은 이에 영감을 받아 더 디테일한 question-answer 방식을 채택하였다고 합니다.

저자들은 더 풍부하고 3D 구조에 특화된 augmentation question-answering 쌍을 만들기 위해 Llama-3.1 7B모델을 활용하였다고 합니다. Llama-3.1은 명령어를 처리하고, 사전학습된 지식을 기반으로 응답을 출력하여 보다 상세하고 맥락 정보를 고려할 수 있도록 하였다고 합니다. 프롬프트의 예시는 아래의 [Fig. 4]에서 확인하실 수 있으며, 구체적으로는 K개의 카테고리가 포함된 3D dataset에 대해 <mask label>을 해당 카테고리로 바꾸고, Llama-3.1에 그림과 같은 명령어를 주어 의미는 유지하지만 표현을 다양하게 augmentation하였다고 합니다.

2.3. Feature Alignment of Point Cloud and Text

Image-Bind^{[1]}( X-review)는 비디오, Depth, IMU, 오디오, 텍스트,Thermal 모달리티의 데이터에 대한 공동의 embedding 공간을 학습하기 위해 이미지를 중심으로 활용하는 방식이며, Image-Bind에 영감을 받은 Point-Bind^{[2]}는 3D 데이터와 여러 모달리티의 데이터 사이의 공동 embedding 공간으로 확장한 방식입니다. 저자들은 이러한 아이디어를 기반으로 두 feature 사이의 align을 강화하기 위해 point cloud와 text에서 추출한 feature에 유클리드 거리를 구하고 minimum margin을 1로 설정하여 contrastive batch average loss L_c를 학습합니다.
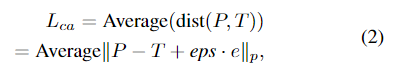
- eps · e에 해당하는 항은 학습의 안정성을 위해 활용
[1] Girdhar, Rohit, et al. “Imagebind: One embedding space to bind them all.” CVPR 2023.
[2] Guo, Ziyu, et al. “Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following.” arXiv preprint 2023.
2.4. Masked-based Affordance Decoding
앞의 과정을 통해 align을 강화한 feature embeddings는 사전학습된 multi-modal Llama-2 모델로 입력되고, Llama-2의 대부분은 freeze하고 LLaMA-adapter를 finetuning하여 <mask label>을 예측합니다. output label은 인코딩하기 위해 one-hot-encodding을 적용하여 query embedding q로 변환한 뒤, 이를 원래의 Point cloud P와 concat하고 point cloud의 embedding P_{em}과 함께 3D affordance Decoder에 통합됩니다. Decoder는 2개의 convolution 레이어와 batch normalization layer로 구성되며, 멀티모달 feauture embedding의 차원을 줄이고, point cloud의 각 점에 대한 affordance map M \in \mathbb{R}^{2048⨉1}를 생성하도록 학습됩니다. 각 점에 대한 M_i \in [0,1] 은 각 점의 affordance 점수를 의미하며 해당 과정은 아래의 식으로 정리할 수 있습니다.
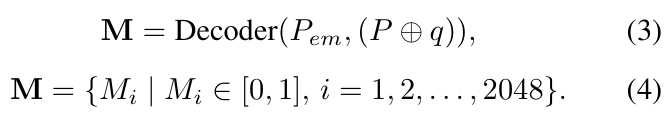
2.5. Training Objectives
geometric-guided encoder와 3D affordance decoder를 학습하기 위해 affordance loss L_{aff}를 이용합니다. affordance loss L_{aff}는 cross-entropy lossL_{ce}와 Dice loss L_{Dice}의 가중합으로 이루어지며, 아래의 식으로 정리됩니다.
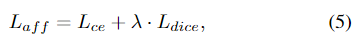
이 외의 text와 3D feature의 align을 맞추기 위해 식(2)에서 정의한 L_c와 LLaMA-Adapter를 <mask label>로 학습하기 위한 cross-entropy loss L_q는 독립적으로 각 모듈의 학습에 사용하였다고 합니다.
Experiments
해당 task는 3D Point cloud 형태의 object가 주어졌을 때, 전체적인 형태와 일부분의 형태에 대해 모두 affordance를 추정하는 것을 목표로 하며, 실험을 통해 특정 디자인을 선택하였을 때 성능에 미치는 영향과 최신 방법론과 비교했을 때 일반화 성능에 대한 평가를 수행합니다.
<Metrics & Baseline>
총 4개의 평가지표(mAP, AUC, aIoU(average IoU), MSE)를 사용합니다.
베이스라인 방법론은 PointCLIP과 PointCLIP v2로, 언어정보를 활용한 3D task의 SOTA 방법론입니다.
- PointCLIP: 2D이미지와 text에 대한 사전학습 모델 CLIP과 불규칙적인 구조의 3D Point cloud의 gap을 줄이기 위한 모델로, point cloud를 multi-view depth map으로 변환 한뒤 이를 CLIP의 visual encoder로 처리
- PointCLIP v2: PointCLIP의 확장된 버전으로, 3D open-world learning을 위해 CLIP과 GPT 모델을 활용.
<Dataset>
3D AffordanceNet 벤치마크 데이터 셋을 사용하였으며, 해당 데이터 셋은 23개의 semantic 카테고리에 대해 총 22,949개의 3D object로 이루어져있습니다. 또한 18개의 affordance 카테고리를 포함하며, seen과 unseen 2개의 split으로 나눠 학습 및 평가를 진행합니다. seen의 경우 원본 데이터셋을 8:1:1의 비율로 train/val/test set으로 분할하여 모든 set에 모든 카테고리가 분포하도록 하며, unseen의 경우 8:1:1 비율은 동일하지만, ‘mug’ ‘knife’ ‘scissors’와 같은 특정 카테고리를 test set에만 추가합니다. 이를 통해 새로운 물체에 대한 모델의 일반화 성능을 평가할 수 있습니다.
Ablation study
먼저 저자들은 자신들이 선택한 디자인에 대한 ablation study를 수행합니다.
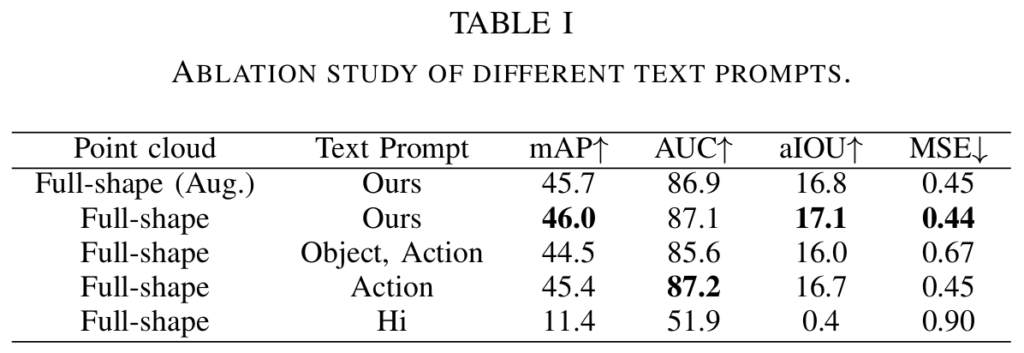
- Text Prompt 타입은 “Hi”를 입력하는 Hi, 객체와 관련된 행동 라벨을 입력하는 “Action”, 객체 이름과 행동 라벨을 입력하는 “Object, Action”, “Which specific region of the mug should we target to provide drinking?”와 같은 전체적인 question을 이용하는 Ours 4가지로 구성됨.
- Ours 방식이 다른 프롬프트와 비교했을 때 대체로 좋은 성능을 보임.
- Object, Action과 Action의 성능 비교를 통해 Object보다 Action이 Point cloud embedding과 결합했을 때 더 좋은 성능을 보임
- text augmentation을 적용할 경우 성능이 다소 낮아지는 경향이 있으나, 저자들은 이를 통해 LLM의 일반화 성능을 향상시킬 것이라고 기대함(즉, unseen에서의 성능을 고려하는 것이라고 이해하시면 됩니다. 이에 대한 실험을 함께 리포팅하지 않은 것이 아쉽습니다.)
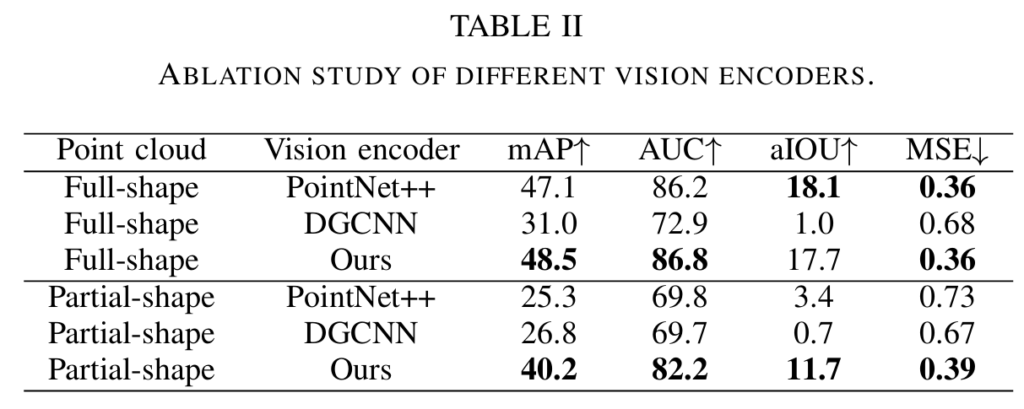
- geometric-guided point encoder를 PointNet++과 DGCNN과 비교한 결과
- 기존 방법론 대비 저자들이 제안한 방식이 대체로 좋은 성능을 보였으며, 이를 통해 저자들이 제안한 encoder가 affordance를 위한 의미론적 feature를 효과적으로 추출할 수 있음을 어필함
Evaluation Result
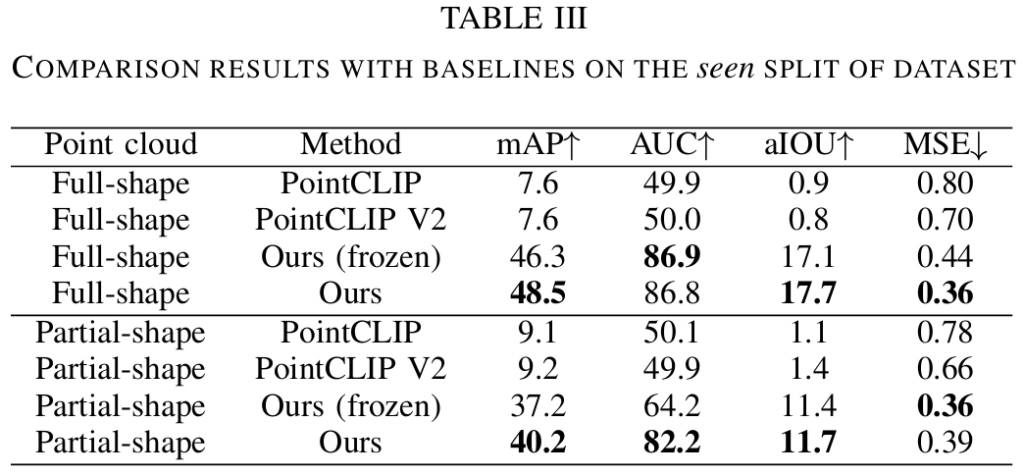
- 최신 방법론인 PointCLIP과 PointCLIP v2와 비교한 결과로, 두 모델이 사전학습된 CLIP을 사용하였으므로, 저자들도 Image-Bind와 LLaMA-Adapter를 학습하지 않은 frozen 버전도 함께 비교하였다고 합니다.
- PointCLIP과 PointCLIP v2와 비교했을 때 상당한 성능 개선이 이루어짐을 확인하였으며, 전체 형태 뿐만 아니라 일부 point에 대해서도 동일하게 효과적임을 보였습니다.
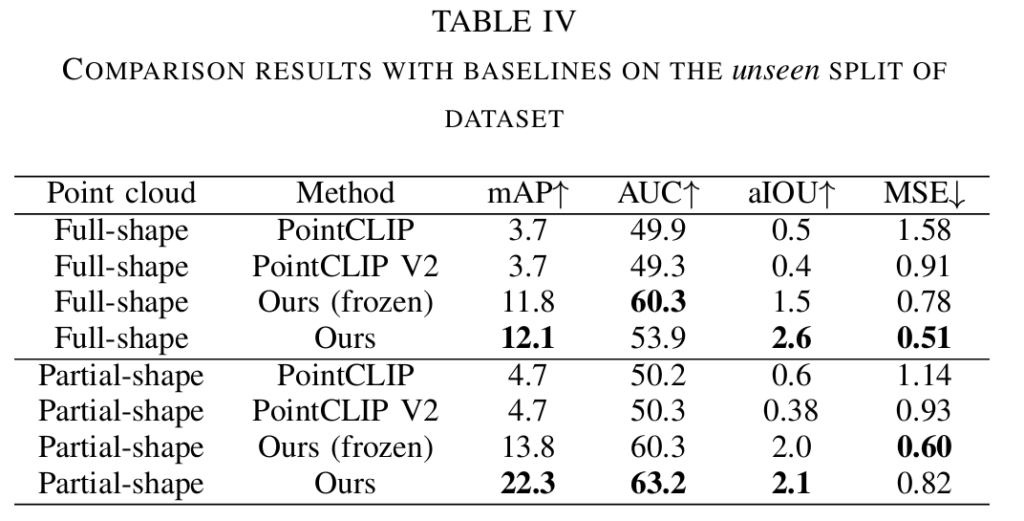
- open-world 카테고리에 대한 평가를 위해 unseen split에서 동일한 실험을 진행합니다.
- 실험 결과 전체 형태와 일부 형태에 대해 seen에 대한 실험 결과보다는 성능이 크게 저하되었으나 모두 기존 방법론 대비 큰 성능 개선을 이루었습니다.
- 이를 통해 저자들이 제안한 방식의 affordance 이해에 대한 일반화 능력을 어필합니다.
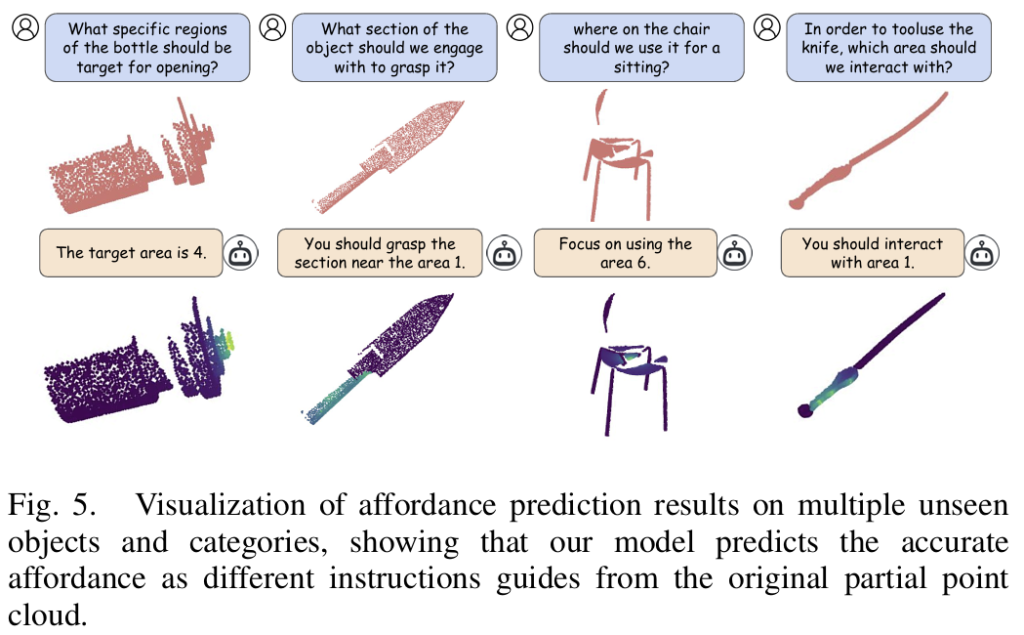
- 위의 [Fig. 5]는 unseen 카테고리에 대한 정성적 결과로, question이 주어졌을 때 affordance map을 시각화 한 것입니다. 위의 text와 point cloud를 입력으로 하였을 때, 아래의 text 답변과 point cloud에 대한 affordance mask를 예측하게 됩니다.
- 일부 point cloud만 제공되는 어려운 케이스에도 (3열 의제 예시 등) 고품질의 affordance mask를 생성할 수 있음을 어필합니다.(저자들은 고품질의 affordance mask라 하지만, 가려짐이 심하고 GT 영역을 함께 비교하기 어려워 고품질인지는 잘 모르겠습니다….)
안녕하세요 ! 좋은 리뷰 감사합니다.
Geometric-guided Point Encoder 부분에 대해 Fig.2에서 partial Point Cloud가 입력으로 들어가고, 그림 상 먼가 마치 머그잔의 손잡이와 몸통 부분이 나뉘어서 들어가는 것처럼 표시가 되어 있는데 실제로는 단순히 object level의 포인트가 샘플링 되어 들어가는 것일까요 ?? k개의 point 패치로 나누는 기준이 FPS같은 샘플링을 하여 중심 포인트들을 찾고 KNN을 처리하여 마치 vit에서 이미지 패치를 나누는 것과 같은 과정을 포인트에 적용하는게 맞는지가 궁금합니다.
실험적으로 궁금한 점은 augmentation된 question이 굉장히 중요해 보이는데, 혹시 하나의 질문으로 기준으로 몇 개의 augmentation 지시어를 사용하는지에 따른 실험 결과는 없었을까요 ??
또한 아직 이런 afordance를 예측하는 task가 각 물체에 대해서도 중요하겠지만 로봇이 동작하는 전체 공간에서 여러 상호작용적으로 물체에 대해 예측할 수 있는게 중요해보이는데, object level이 아닌 scene level에서의 연구는 아직 진행되지 않는지가 궁금합니다.
감사합니다.
질문 감사합니다.
제가 해당 내용에 대한 설명이 부족했던 것 같습니다. 저자들은 해당 논문이 전체 point cloud 뿐만 아니라 일부 정보가 사라진 partial point cloud에 대해서도 잘 작동한다는 것을 어필합니다. 그러나 제가 이해했을때는 partial을 위해 별도로 고안된 부분은 없었고 방법론에서도 이를 다루고 있지 않습니다. 저자들은 입력으로 partial point cloud도 잘 작동한다고 어필하고 싶었던 게 아닐까 합니다..
저자들이 하나의 QA쌍에 대해 6가지의 augmentation을 만들어낸다는 설명은 있으나 주어진 QA에 따라 문장의 내용을 변경하지 않기 위해 augmentation 된 6가지가 다를 것으로 보입니다. 따라서 augmentation된 형식의 Question이 좋다던가, 몇개가 좋다던 가 하는 설명은 따로 없었습니다.
3D에서의 afforance 연구는 아직 object level에서 이루어지고 있는 것 같습니다. 어찌보면 최근 scene level이라고 하기보다는 주변의 객체들도 고려할 수 있는 연구가 진행되었으나, 데이터 셋 자체가 scene-level의 affordance 데이터를 구축하는 것에는 어려움이 있고 연구도 초기단계인 것으로 보입니다.