오늘 리뷰할 논문은 Prompt Learning 을 DA 에 접목한 연구입니다.
2022년에 arxiv, 그리고 2023년에 TNNLS에 게재된 논문이고 인용수가 160회에 육박하는 논문입니다. DA 수행을 위해 Prompt Learning 기법을 적용한 최초의 시도라 하여 읽어보게 되었습니다. 바로 리뷰 시작하도록 하겠습니다.
1. Introduction
다들 많이들 들어보셨을 UDA라고 하는 기술은 풀고자 하는 목표 상황에 대해 데이터셋이 부족한 경우, 이를 위해 타 대규모 source 데이터셋으로부터 풍부한 지식을 활용하여 목표 상황에 대해 해결하는 task 입니다. 우리가 모델을 학습시키는 이유는 결국 목표로 하는 target 상황에 대해 높은 성능의 task 를 수행하기 위함이고, 최근들어 빠르게 발전하고 있는 LLM 등의 foundation 모델의 경우도 물론 여러 domain에 대해 일반화된 지식들을 학습하였지만 특정 specific한 domain 의 경우에는 강인한 예측이 불가능할 수 있고 이를 해결하기 위한 것이 UDA 기술이라고 볼 수 있습니다.
전통적인, 이전 UDA 기법의 핵심은 결국 여러 domain으로 부터 domain-invariant한 표현력을 학습하는 것입니다. 여러 domain feature에 대해 직접 통계값 차이를 최소화 하거나, discriminator 기반의 adversarial 학습을 통해 이를 수행했죠. 이렇게 학습된 domain invariant feature를 사용해서 공통된 하나의 classifier 등의 것으로 예측을 수행하게 됩니다. 아래 그림의 위쪽-exisiting methods 에 해당하죠.
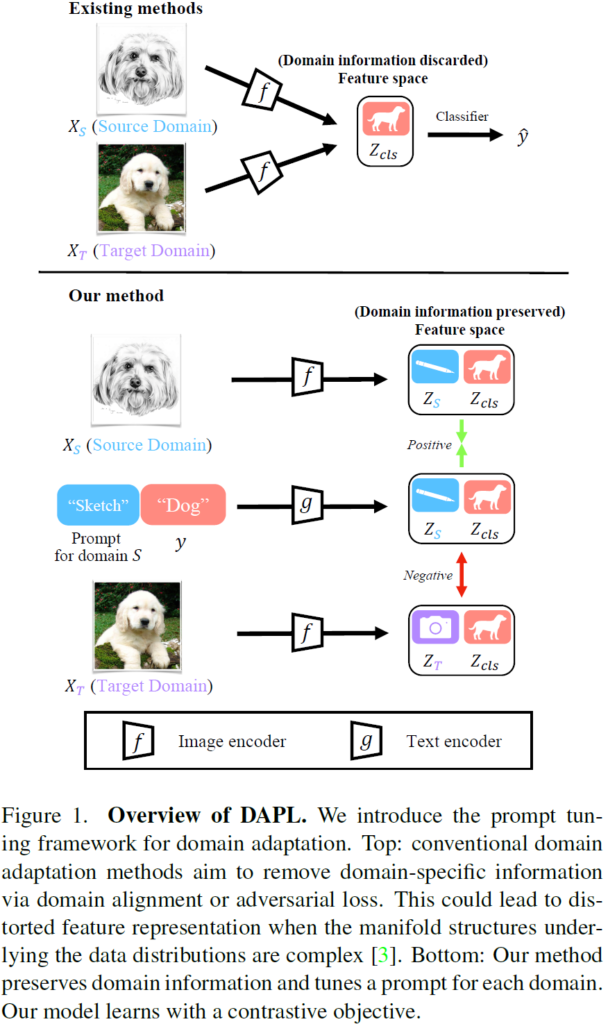
반면 최근 연구들에서는 이렇게 여러 domain feature 를 정렬하는 과정 속에서 각 domain들이 가지고 있는 중요한 의미론적인 정보들이 소실될 수 있다고 표현합니다 (loss of semantic information). 이러한 소실은 데이터 분포의 매니폴드 구조가 복잡할 때, 의미론적 정보와 도메인 정보가 복합적으로 얽혀있는 특성으로부터 비롯된다고 합니다.
이를 해결하고자 최근의 연구들은 분포 관점에서 domain-invariant 한 특징을 무작정 추출하는 것이 아니라, class의 분별력(discriminability)를 최대한 유지하면서 UDA를 수행하고자 하였습니다. 해결책으로 이상적일 순 있는데, class 분별력을 유지하려고 하다 보니 정작 domain alignment 능력을 얻을 수 없다고 합니다. 즉 UDA 기법을 설계하는 데에 domain alignment 능력과 semantic features preserving 능력 사이의 trade-off 를 적절히 고려해야 한다고 합니다. 이에 따라 저자는 semantic representation과 domain representation을 구분 (disentangled) 하여 학습하는 것이 대안이 될 수 있다고 주장합니다. 그리고 이를 위해 prompt learning 기법을 도입합니다.
자세한 것은 아래 method 에서 설명드릴 예정이며 컨셉적으로는 위 figure 1의 하단부와 같습니다. source domain에 해당하는 sketch 강아지 영상, 그리고 target domain 에 해당하는 photo 강아지 영상이 있습니다. 그리고 text prompt 의 경우 “Sketch Dog” 라고 하는, source domain에 매핑되는 prompt 가 있네요. 학습은 CLIP의 contrastive learning 과 마찬가지로 동작하는데 이때 positive pair가 되기위한 조건은 domain과 class가 모두 일치해야 합니다. 즉 target domain인 photo 강아지 영상과, prompt “Sketch Dog” 는 같은 강아지를 의미하지만 negative pair로 간주됩니다.
학습은 사전학습 CLIP 모델을 고정하여 그대로 사용하고, 위에서 간단히 설명드린 바와 같이 domain과 class를 모두 고려하여 positive – negative pair를 구성한 뒤 contrastive learning 을 수행하여 점차적으로 learnable prompt가 학습되게 됩니다. 이때 prompt 는 domain agnostic한 부분과 domain specific 한 부분으로 나눠서 학습이 진행되는데, 이에 대해서는 아래서 설명 드리겠습니다.
2. Method
2.1. Preliminary
CLIP의 경우 “a photo of a [CLASS]” 라는 수동으로 디자인된 prompt 를 사용하여 고정된 embedding vector를 추출하게 됩니다. 물론 CLIP은 여러 dataset에서 강한 zero-shot 등의 성능을 달성하였지만, 항상 상황에 맞는 가장 최적의 prompt를 manually하게 설정하는 것은 매우 어려웠습니다. 하나의 데이터셋에 대해 여러 prompt를 다 넣어보고 성능이 좋은것을 골라야 하는 상황이였죠. 또한 “a photo of a [CLASS]” 와 “a photo of [CLASS]”, prompt 속 a의 유무에 따라서도 classication accuracy 가 5% 이상 차이가 나는 그런 불안정한 예측 결과들도 존재했습니다.
CLIP의 이런 문제점을 해결하고자 CoOp 라는 방법론이 제안되었습니다.
([IJCV 2022] Learning to Prompt for Vision-Language Models)
해당 방법론에서는 text prompt로 “a photo of a [CLASS]”처럼 고정된 형태가 아닌, 유동적으로 학습해 나가게 됩니다. text prompt의 [CLASS] 앞쪽 정보, 즉 context 정보를 최적화해 나간다고 하여 CoOp (Context Optimization) 이라고 명명합니다. 구조는 아래와 같습니다. M개의 learnable context token이 구성되어 있습니다.
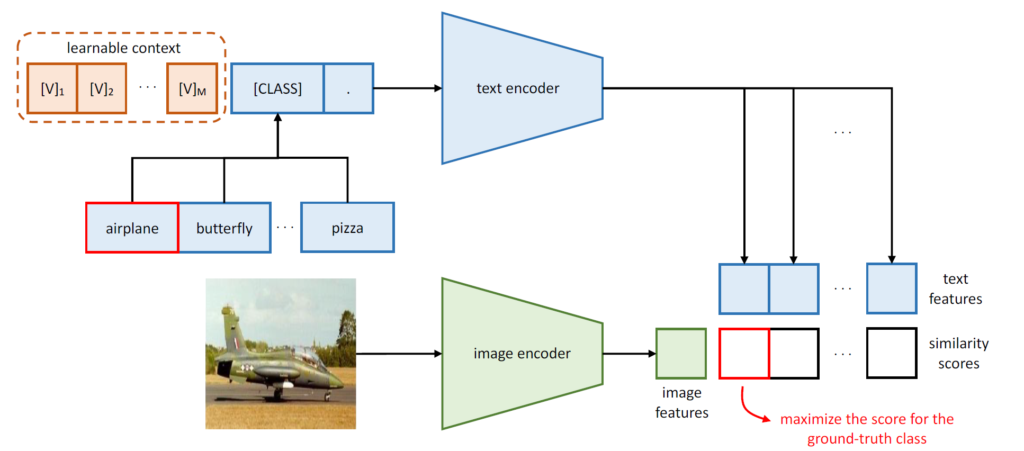
학습되는 learnable token을 수식으로 표현하면 아래와 같습니다.
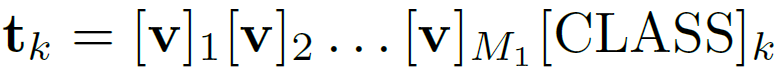
2.2. Domain Adaptation via Prompt Learning
intro에서 설명드렸다시피 본 논문에서는 전체 learnable prompt (context token)을 M_1개의 domain-agnostic token과 M_2개의 domain-specific token 으로 나눕니다. 각 prompt 에 대한 개념도는 아래와 같습니다.

위 그림을 통해, 본 논문의 방법론으로 최종적으로 잘 학습이 이루어졌다면,
domain-agnostic prompt에는 domain과 무관한 “An image of” 와 같은 정보가, domain-specific prompt에는 각 domain의 특징을 나타내주는 style과 같은 정보들이 반영되기를 기대합니다. learnable prompt에 말이죠.
위를 수식으로 나타내면 아래와 같습니다.
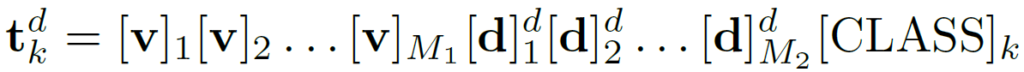
고정된 [CLASS] token 앞쪽으로 학습가능한 M_1개의 domain-agnostic token과 M_2개의 domain-specific token 가 구성되어 있네요. 부가적으로 domain-agnostic token을 총 K개의 class별로 다르게 두는, class-specific style 방식을 취하게 되었을때의 수식은 아래와 같습니다.
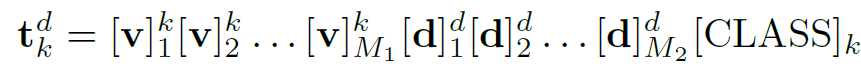
domain-agnostic token [v] 의 지수부분에 class를 뜻하는 k가 붙었네요. 뭐 최종 성능적으로 봤을때 class-specific style 방식을 취했을때도 성능은 거의 동일하긴 합니다.
위 prompt 를 사용하여, 학습 source labeled image가 class k에 속하는 확률을 cosine similarity 기반으로 계산하여 표현하면 아래 수식과 같습니다. g는 text encoder, f는 image encoder 입니다.
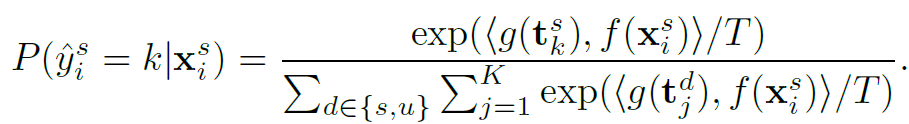
이를 기반으로 source gt label과 ce loss를 계산하게 됩니다. CLIP의 학습 방식과 동일합니다.
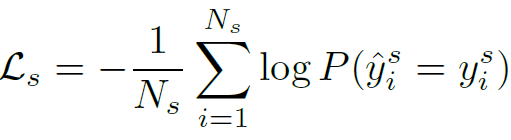
target image에 대해서도 위와 동일한 과정이 수행되긴 합니다. 하지만 UDA의 특성 상 gt label이 없기 때문에, CLIP의 zero-shot 예측을 pseudo label 삼아서 해당 예측이 특정 threshold 를 넘는 sample만 reliable pseudo-label 로 고려한 후 동일하게 ce loss가 계산되게 됩니다. 그리고 위에서 구한 source loss와 더해진 최종 loss는 아래와 같습니다.
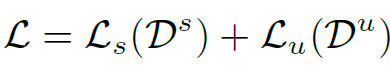
본 논문에서는 위의 이러한 학습 기법을 통해 domain 정보와 class 정보를 분리하고, 각각을 모두 고려하여 학습하도록 설계하였다고 합니다. 아래 개념도를 살펴보시겠습니다.
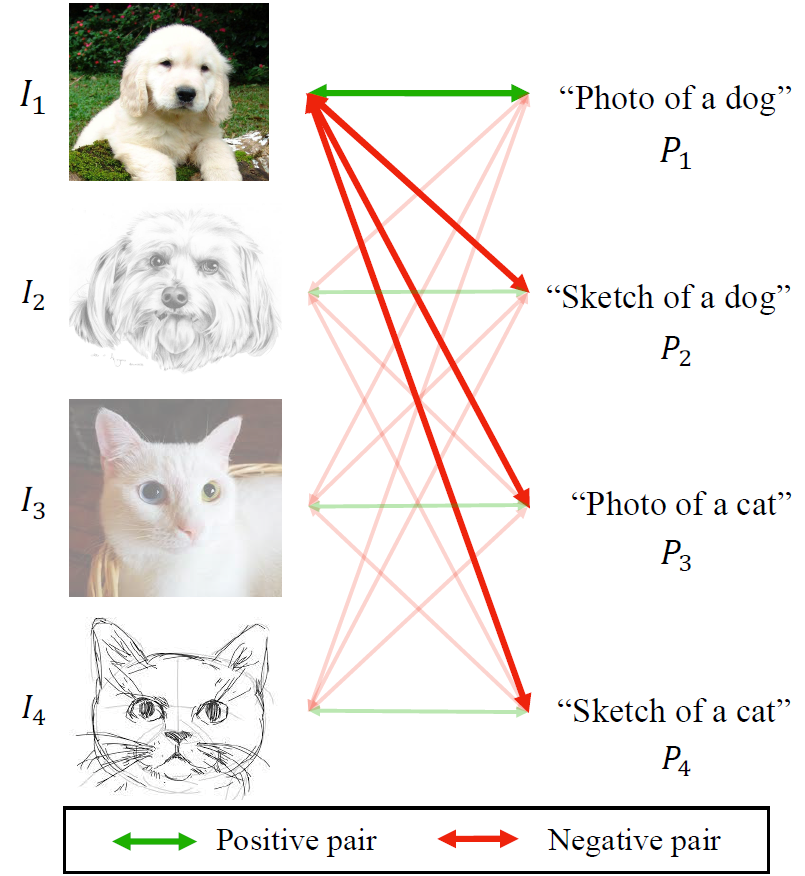
좌상단에 있는 강아지 real 사진에 대해, 이와 대응되는 positive pair는 우측의 “Photo of a dog” 입니다. 즉, class정보와 domain 정보가 모두 동일한 sample만을 positive pair로 구성하고 하나라도 틀리면 negative로 고려하게 되는 것이죠. 이를 통해 class 분별력과 함께 domain 분별력까지 함께 학습하고자 하였습니다.
하지만 위 수식, 그리고 github 코드와 issue까지 살펴본 결과 class 관점으로는 분별력을 가지도록 학습이 진행되는데, domain과 관련해서는 딱히 아무런 loss가 부여되지 않은 것을 확인할 수 있었습니다.
실험에서 리포팅한 결과가 어떤 코드로부터 나온건진… 모르지만 일단 뭐 DA task에 prompt learning 을 도입한 최초의 논문이다~ 라는 점만 인지하시면 될 듯 합니다.
3. Experiment
실험에는 2080 gpu 1장만을 사용했다고 합니다. CLIP image/text encoder는 freeze하고 prompt 만 학습하는거라,, 2080 1 장으로 가능했나봅니다.

위는 Office-Home 이라고 하는 데이터셋입니다. 65개의 class에 대해 object-centric 한 영상으로 구성되어 있는 classification dataset이고, Art ( Ar ), Clip Art (Cl), Product (Pr), and Real World (Rw) 도메인으로 구성되어 있습니다. 해당 데이터셋에서의 UDA 결과는 아래와 같습니다.
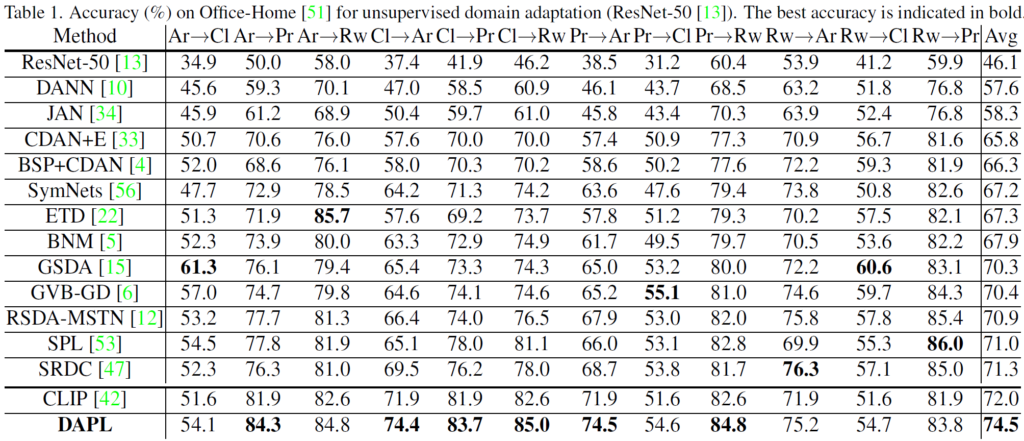
이전 learnable prompt 방식인 CoOp와의 직접적인 비교가 없는것은 조금 아쉽습니다. 그리고 타 UDA 기법들보다는 3 이상의 높은 성능 향상폭을 보이고 있습니다. 사실 뭐 image만 입력으로 받는 타 UDA 기법과 달리 본 논문은 image+text이니.. 성능 향상이 생길법도 합니다.
CLIP zero-shot 과의 성능 비교에서도 평균 2.5의 accuracy 향상으로 꽤나 높은 폭이네요.
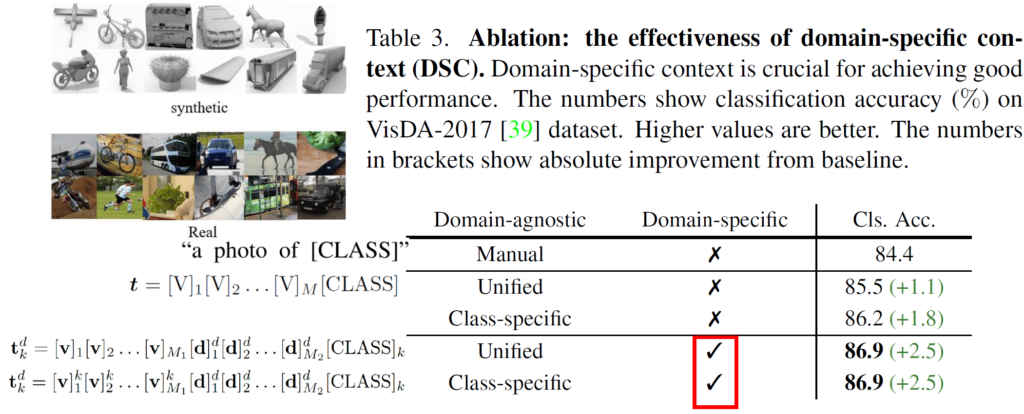
다음은 VisDA-2017 데이터셋에서의 실험 결과입니다. 해당 데이터셋은 좌상단에서 보시는 것과 같이 3d 모델 느낌이 나는 합성 영상을 source로, real 영상을 target으로 삼습니다. 그리고 prompt를 어떻게 구성하느냐에 대한 성능 변화는 table을 보시면 됩니다.
CLIP의 고정된 prompt에서 CoOp에서 제안한 M개의 context token optimization 방식으로 바꿨을때에 84.4->85.5로의 성능 향상을 달성합니다. 여기에 본 논문이 제안한 prompt learning 방식을 부여했을때에 대한 성능이 아래 2줄에 해당하는 86.9 입니다. domain-agnostic token을 unified/class-specific하게 가져가는 지에 대한 성능 차이는 없는 것으로 보여지고 최종적으로 CLIP zero-shot 에 비해 2.5 향상을 달성합니다.
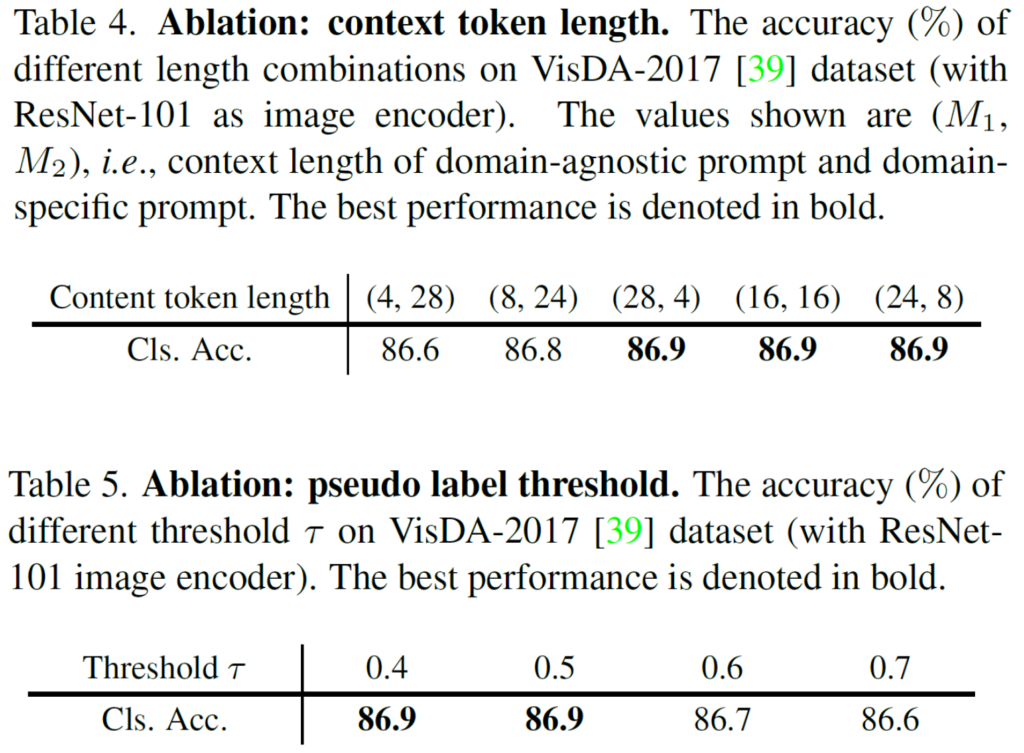
전체 token 32개 중에 domain agnostic/specific token을 각각 몇개로 가져갈 지에 대한 실험 결과가 위 표 4 입니다. 이 중 16,16 개를 선정했다고 하네요.
또한 표 5는 CLIP zero-shot 예측을 통한 pseudo label 설정 시 어떤 threshold 를 사용하는 지에 대한 실험입니다. 이에 따른 성능 차이는 크게 없었다고 하네요.

마지막으로 시각화 결과입니다. 물론 체리픽 결과이긴 하겠지만,,, 좌상단 화분 예시를 보면 CLIP의 Manual prompt 방식 (연두) 과 Our Prompt 방식 사이의 예측 정확도 차이가 엄청나게 많이 나는것을 확인할 수 있습니다.
prompt learning 이라는 분야의 논문을 읽은지 아직 1주정도밖에 되지 않아서 아직은 “prompt 를 학습한다” 라는 것에 대해 의미론적으로 잘 와닿지는 않는 것 같습니다. 조금 더 관련된 논문을 더 읽어봐야겠네요. 리뷰 읽어주셔서 감사합니다.
안녕하세요 석준님, 좋은 리뷰 감사합니다.
제목에 prompt learning이란 워딩에 끌려 읽게 되었네요..ㅎㅎ..
처음에 리뷰 읽기 시작할 때, prompt learning이 저는 prompt를 gradient descent처럼 구현해서 prompt optimization을 하는 태스크(예; Automatic Prompt Optimization with “Gradient Descent” and Beam Search (EMNLP 2023))를 활용했나 라고 생각했는데, 아니었군요! 실제로 prompt와 관련된 어떤 learnable한 context token을 contrastive learning을 통해 학습하며 domain agnostic과 domain specific, class image간에 align을 맞춰나가겠다로 이해했습니다! 학습 때 필요한 computing cost도 2080밖에 안되다보니, 직관적이면서도 효율적으로 보입니다!
질문이 하나 있는데, M1, M2 토큰의 갯수는 어떤 기준으로 구성되는 건가요?!
하하, 이해하신 부분이 맞습니다.
M1, M2의 갯수는 그냥 실험적으로 선정했다고 합니다. 리뷰 속 table 4 를 보시면 되는데요, (28,4) (16,16) (4,28) 모두 동일한 성능을 보이고 있고 M1과 M2 모두 16개로 선정하였다고 합니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
사실 CoOp을 도메인/클래스로 나누고 contrastive learning만 붙인 논문인 것 같은데, 해결하려는 task 특성과 잘 엮어서 설명했다는 것이 설득력있었던 것 같습니다.
실험 부분에서 데이터셋의 도메인이 Art ( Ar ), Clip Art (Cl), Product (Pr), and Real World (Rw)로 나눠져있는 것 같은데, 이전에 리뷰해주신 UDA 논문에선 자율주행을 상정하며 Sunny<->Foggy, Rainy<->Night 등등 조금 다른 범주에서의 domain 변화를 다뤘던 것으로 기억합니다. 혹시 두 갈래의 연구가 별도로 진행 되고 있는 것인지 궁금합니다.
만약 두 갈래의 연구가 별도로 진행되고 있다면, 리뷰해주신 논문도 자율주행 상황에서의 도메인 변화에 대응할 수 있을만한 방법론이라 생각하시는지 궁금합니다.
감사합니다.
댓글 감사합니다.
아무래도 vision쪽 연구들의 특성 상 classification에서 연구가 먼저 되고난 후 1~2년 후 부터 segmentation, detection 등의 task로 퍼져나가는 것이 일반적입니다.
UDA 수행 시 prompt learning 을 적용하여 자율주행의 다양한 날씨상황 속 seg, det을 수행하는 연구의 경우도 활발하게는 아니지만 조금씩 진행되고있는 추세로 보여집니다. 그중 하나가 [NIPS 2024] Learning Domain-Aware Detection Head with Prompt Tuning 연구인데, 사실 뭐 대단한 건 없고 prompt learning 을 통해 detection 에서의 uda를 수행하자~ 라는 연구입니다.
질문에 답변드리자, 두 갈래의 연구가 별도로 진행되는것은 아니구요 슬슬 seg/det 분야에도 적용이 되어져 가는 추세인 듯 합니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
UDA의 특성상 타겟 이미지에 대해서는 gt 라벨이 없기 때문에 CLIP의 zero shot 예측을 pseudo 라벨 삼는다고 하셨는데요, 그렇다면 pseudo 라벨이 CLIP의 결과에 너무 의존적이라는 한계가 있다고 생각이 듭니다. 제가 최근에 읽는 ov3d 논문들에서도 이미지에 대한 CLIP의 결과를 그대로 쓰는 것이 오히려 노이즈를 발생시킬 수도 있어 여러 pseudo 라벨을 생성할 수 있는 방식들을 제안하고 있는데 UDA 쪽에서는 아직 그런 한계를 해결하고자 하는 방법은 나오지 않고 있는지, 혹은 본 논문에서 따로 언급하는 부분은 없는지 궁금합니다.
감사합니다.