안녕하세요, 마흔 여덟번째 x-review 입니다. 이번 논문은 2024년도 NeurIPS에 게재된 OV3D 논문으로,처음으로 monocular 3D detection에서 ov 개념을 도입한 논문 입니다.
그럼 바로 리뷰 시작하겠습니다.

1. Introduction
많은 3D detection 연구는 여러 벤치마크 데이터셋에서 sota를 갱신하며 성능 개선을 이루었지만 여전히 데이터셋에서 주어지는 학습 데이터 이외에 물체에 대해서는 일반화를 이루기 어렵다는 한계가 존재합니다. 이런 한계를 해결하기 위해 ov-3D 시나리오가 등장하여 학습 동안에 보지 못했던 새로운 물체에 대해서도 검출할 수 있도록 연구를 진행하고 있습니다. 그러나 현재 ov-3D 검출기들은 LiDAR나 다른 3D 센서로 취득한, 일반적으로 이용하기에는 비용 문제가 발생하는 포인트 클라우드 데이터를 메인 데이터로 의존하고 있습니다. 그래서 ov에서 말고 일반적인 3d detection 연구에서는 한편으로는 monocular 3D detection, 즉 하나의 이미지로에서 바로 물체의 3D bounding box를 검출하는 연구가 진행되고 있었죠. monocular 3D detection은 2D에서의 물체 검출 방식을 활용하기도 용이하고, 비용적으로도 효율적이라는 장점이 존재하죠. 이전까지의 monocular 3D는 비록 inference 시에는 포인트 클라우드의 사용한다는 제약에서 벗어났지만, 여전히 학습에는 많은 cost가 드는 어노테이션 과정을 거쳐야 하는 포인트 클라우드 데이터를 필요로 하여 특정 수준 이상의 데이터 확장이 어려운 상황이라고 합니다. 그래서 본 논문에서는 이런 3D에서의 ov의 필요성과 monocular detection의 장점을 살려 ov 인지 성능을 향상시키기 위해 학습 중에도 RGB 이미지만을 이용한 monocular 3D 검출기인 OVM3D-Det를 설계하였습니다.

Fig.1과 같이 학습에 RGB 이미지만 사용하여 확장된 데이이터를 구축할 수 있고, ov-3D를 통해 새로운 novel 클래스를 검출할 수 있게 됩니다. 이 과정에서 3D 바운딩 박스 정보를 자동으로 라벨링하기 위해 detph estimator를 사용해서 pseudo-LiDAR를 먼저 생성하여 활용한다고 합니다. 그런데 pseudo-LiDAR는 아무래도 직접 센서로 취득한 데이터에 비해 노이즈가 발생할 수 밖에 없겠죠. 노이즈가 발생한 데이터에 바운딩 박스를 친다고 해도 정확하다고 단정지을 수도 없습니다. 물론 최근의 depth estimator들은 좋은 zero shot 일반화 성능을 갖추고 있다곤 하지만, 그래도 pseudo-LiDAR는 노이즈가 포함될 가능성이 있고 그 LiDAR에 학습 과정에서 자동으로 라벨링하는 과정에서 에러가 축적될 수 있습니다. 이런 pseudo-LiDAR를 생성하고 자동 라벨링 과정에서 발생할 수 있는 문제를 크게 두 가지로 나눌 수 있는데, (1) 만들어진 포인트가 noise가 존재해서 배경 포인트 artifact로부터 타겟으로 하는 물체를 구별하기 어렵고, (2) 하나의 view를 가진 이미지만으로 만들어진 포인트이기 때문에 물체가 occlusion되면 실제 사이즈를 추정하기 어려워진다는 것 입니다.
이런 challenge한 점을 해결하기 위해 OVM3D-Det에서는 두 개의 구성을 설계합니다. (1) 첫번째 문제를 보완하기 위해 pseudo-LiDAR에서 배경 artifact를 필터링하는 adaptive erosion 방식을 제안합니다. 이 방식은 주어지는 포인트 데이터에 따라 adaptive하게 타겟 물체와 가까이 존재하면서 노이즈로 적용되는 포인트들을 제거하여 바운딩 박스가 좀 더 정확한 물체 포인트에 맞추어 생성되도록 합니다. (2) 두번째 문제는 occlusion 때문에 물체의 포인트가 대다수 표현이 되지 않아 정확한 물체의 크기를 추정하는 것이 어렵기 때문에 발생하게 됩니다. 그래서 GPT-4와 같은 LLM을 사용해서 물체마다의 범용적인 크기를 알아내어 각 클래스의 물체에 대한 사전 지식으로 사용합니다. 알아낸 사전 지식과 만들어진 박스가 일정 수준 범위에 들어맞지 않는다면 박스를 최적화할 수 있는 bounding box search 방식을 설계하였습니다. 마지막으로는 ov monocular 3D를 위해 pseudo 바운딩 박스로 찾아낸 물체와 텍스트 임베딩과 align을 맞추어 학습합니다.
이러한 본 논문이 mian contribution을 정리하면 다음과 같습니다.
- 처음으로 indoor와 outdoor 시나리오 모두에서 이미지 기반의 monocular ov 3D detection 수행
- LiDAR 포인트 클라우드에 의존하지 않고 자동으로 3D 어노테이션이 가능하면서 웹 스케일의 이미지 데이터를 이용할 수 있는 OVM3D-Det 제안
- 자동 라벨링된 pseudo 3D 라벨로 학습을 하여 기존 베이스라인 방법론들보다 우수한 성능을 보이는 것을 실험적으로 증명
2. Method
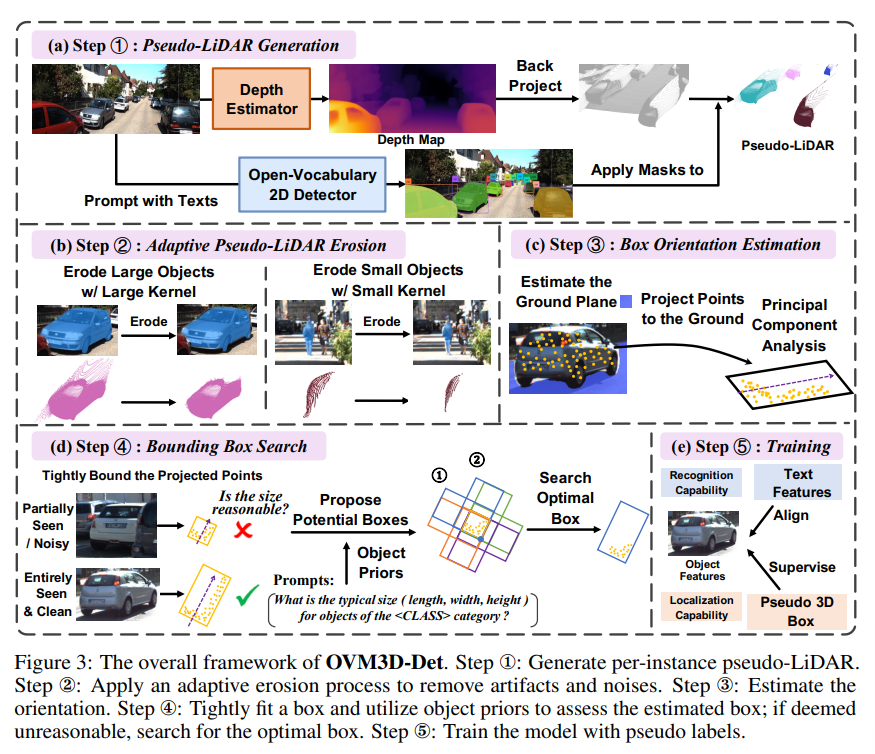
OVM3D-Det은 Fig.3과 같이 학습 이전에 크게 4가지 단계로 구성됩니다. 먼저 RGB 이미지로부터 depth map과 scene 안에서 instance 별로 pseudo-LiDAR 포인트 클라우드를 생성합니다. 두번째로 만든 instance level의 pseudo-LiDAR 데이터에서 artifact와 노이즈를 제거하기 위한 처리를 위한 adaptive erosion 과정을 거칩니다. 세번째로 데이터 중에는 물체의 방향까지 고려하여 박스를 생성해야 하는 경우도 있기 때문에 생성할 바운딩 박스의 방향을 추정하게 됩니다. 그 다음 마지막으로는 물체마다의 사전 지식을 이용하여 물체 포인트에 박스가 fit하게 맞도록 초기 박스를 refinement하는 과정을 거치면 최종적으로 3D detection 학습을 할 수 있게 되어, 자동 라벨링된 데이터를 가지고 Cube R-CNN이라는 3D detector를 학습하게 됩니다.
2.1. Generate Pseudo-LiDAR
Pseudo-LiDAR Generation
먼저 입력으로 이미지가 주어지면 Grounded-SAM을 사용해서 이미지 안에 주어진 모든 물체에 대한 바운딩 박스 \{B_k\}^K_{k=1}와 segmentation 마스크 \{M_k\}^K_{k=1}를 얻습니다. 그리고 나서 사전 학습된 monocular depth estimation 모델인 Unidepth를 사용해서 depth map D(u,v)를 예측합니다. 여기서 사전학습된 zero shot depth estimation 모델을 사용하긴 하지만, 본 논문의 실험 데이터셋과 사전학습된 모델의 학습 데이터셋 사이에 겹치는 데이터가 없음을 알려주고 있습니다. 여기까지 수행을 하면 RGB-Depth map pair 데이터를 가질 수 있기 때문에 카메라 좌표계 내에서 각 픽셀 (u,v)을 식 (1)과 같이 3차원 좌표 (x,y,z)로 변환할 수 있습니다.
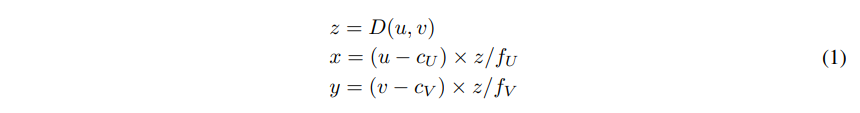
- (c_U, c_V) : 카메라 중심 좌표
- f_U, f_V : 수평, 수직 방향의 focal length
이런 3차원 좌표 변환 식을 이용해서 물체를 나타내는 모든 N_i개의 마스크 M_i에 대한 Pseudo-LiDAR 포인트 \{(x^{(n)}, y^{(n)}, z^{(n)}\}^{N_i}_{n=1}를 생성할 수 있습니다.
Adaptive Pseudo-LiDAR Erosion
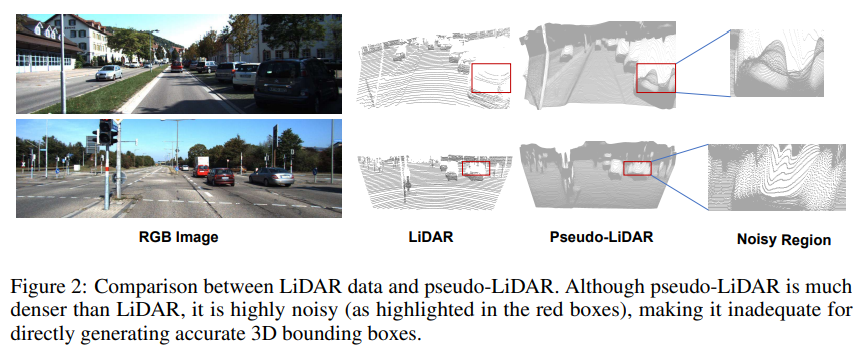
Fig.2와 같이 같은 scene에 대해 실제로 LiDAR 센서로 취득한 데이터와 pseudo-LiDAR를 비교해보면 pseudo-LiDAR는 훨씬 dense한 반면에 상당한 노이즈가 발생한 것을 확인할 수 있습니다. 저자는 이러한 노이즈가 발생하는 가장 큰 이유는 이미지에서 예측했던 마스크의 엣지 부분이 projection 되는 과정에서 발생하는 에러라고 설명하는데요, 이 엣지 부분은 물체의 전경과 배경이 인접한 영역이기 때문에 큰 depth 값 차이를 가져 물체 경계에서 depth estimation을 하는데 어려움이 있기 때문 입니다. 이런 노이즈를 제거하기 위해 간단한 이미지 erosion 연산을 수행하는데, 간단하지만 erosion을 거치면 노이즈를 효과적으로 줄여 더 깨끗한 pseudo-LiDAR 표현이 가능하게 된다고 합니다. Fig.3(b)를 자세히 보면, 자동차의 마스크를 erosion 처리 하고 나서 상단이나 차의 바운더리 부분에 노이즈 영역이 포함되지 않게 됩니다. (사실 자동차에 대한 예시는 제 눈에 보기에 큰 차이는 모르겠습니다만 .. 이 정도의 마스크를 erosion 처리하는 것만으로 3D 포인트에서 노이즈 감소에 큰 영향을 미칠 수 있다고 하네요)
그런데 모든 물체에 대해 동일한 erosion을 적용하게 될까요 ? 강한 erosion을 만약 Fig.3(b)에서 보행자와 같이 작은 물체에 적용한다면 노이즈만 제거하는 것이 아니라 보행자 마스크 자체를 완전히 제거할 수도 있게 됩니다. 또 반면에 약한 erosion을 자동차와 같이 큰 물체에 적용한다면 노이즈를 완전히 제거하지 못할 수도 있겠죠. 따라서 어떤 물체이냐에 따라서 adaptive한 erosion 모듈을 설계하여 RGB 이미지에서 Grounding-SAM으로 생성한 마스크 크기에 따라서 다른 강도의 erosion을 적용하게 됩니다. 즉, 작은 물체는 더 약한 erosion을 거쳐 물체 자체의 마스크는 보존하고, 큰 물체일 수록 강한 erosion을 거쳐 많은 엣지 부분의 노이즈는 제거하면서 정확한 pseudo-LiDAR을 생성할 수 있도록 한 것 입니다.
2.2. Generate Pseudo 3D Bounding Boxes
Box Orientation Estimation
앞선 과정으로 개선된 pseudo-LiDAR를 만들었다는 가정하에, 이제 3차원 바운딩 박스를 pseudo 라벨로 생성해서 monocular 3D detection 모델이 localization을 할 수 있도록 해야 합니다. 보통의 3D 데이터셋에 따라, scene 안에 있는 물체들은 모두 지면에 붙어 평행하다는 가정을 합니다. 박스를 생성하기 위해서는 먼저 카메라 좌표계 C에서 ground plane 방정식을 추정해야 합니다. 앞서 이미지에서 포인트를 생성하는 방식과 동일하게 이번에는 물체가 아니라 지면에 대한 pseudo-LiDAR를 생성하면 됩니다. 예를 들어 outdoor scene에서는 “ground”, indoor에서는 “floor”를 Grounded-SAM의 입력으로 넣어 각 scene마다의 지면에 해당하는 영역의 마스크를 예측합니다. 이 마스크에 대한 depth map을 얻어서 3차원으로 변환하고, 최소제곱법을 적용해서 지면을 나타낼 수 있는 방정식을 도출한다고 하네요. 그 다음에 pseudo-LiDAR를 카메라 좌표계 C의 원점과 align이 맞으면서 수평면이 지면과 평행한 새로운 좌표계 C’로 변환하게 됩니다. 사실 이 부분에 방정식 수식적인 설명이 없어서 이해가 완전히 되진 않지만 .. 생성한 포인트의 수평면이 지면이 될 수 있도록 맞추기 위해 방정식을 정의하고 있는 것 같습니다 . .
Fig.3(c)에서 볼 수 있듯이 이제 평면이 어딘지를 찾아냈으니 포인트를 평면으로 투영해서 상자가 어느 방향을 향해 있는지를 추정해야 합니다. 이전 연구에 따라, pseudo-LiDAR의 각 포인트끼리의 방향을 계산하고 계산된 방향에 대한 히스토그램을 구성한다고 합니다. 구성한 히스토그램에서 가장 빈도가 높게 나타나는 방향을 바로 그 물체가 향해 있는 방향으로 선택하여 사용하게 됩니다. 병렬적으로 PCA를 통해 pseudo-LiDAR의 main feature을 추출하여 가장 큰 편차를 가진 방향을 바운딩 박스의 방향으로 지정할 수도 있는데, 이런 히스토그램과 PCA 중에서 실험을 통해 PCA가 더 간단하면서도 효율적으로 물체의 방향을 정확하게 추출할 수 있어 PCA를 최종적으로 사용하게 됩니다.
Bounding Box Search
물체의 방향을 찾고나면, 각 물체의 psduo-LiDAR를 물체의 방향에 따라 타이트하게 3D 바운딩 박스를 치고, 이 박스들이 coarse pseudo 박스가 됩니다. 그런데 앞서 이야기한 것 처럼, 이미지에서 물체가 occlusion되어 있을 수 있기 대문에 생성된 pseudo-LiDAR는 물체의 일부만 보이고 있을 수도 있고 아니면 refine했던 포인트가 아직까지도 여전히 노이즈가 포함되어 있을 수 있죠. 그러면 바운딩 박스의 사이즈가 실제 물체의 크기를 커버하지 못하고 사이즈가 너무 작거나 커져버릴 수 있습니다. 따라서 학습을 위해 물체의 크기에 맞는 pseudo 라벨을 생성하기 위해서는 coarse 박스를 기반으로 가장 적절한 바운딩 박스를 만들어야 합니다.
그러기 위해서 먼저 coarse pseudo 박스의 사이즈가 합리적인 물체 크기 범위 내에 있는지 파악합니다. 여기서 GPT-4와 같은 LLM을 사용하게 되는데, GPT-4를 사용해서 물체의 일반적인 사이즈에 대한 데이터를 먼저 수집합니다. 가령 “<클래스> 카테고리의 사물에 대한 (length, width, height)를 실생활에서의 보편적인 크기에 따라 알려줘”라는 메시지를 GPT-4에게 넣으면 GPT-4는 특정 클래스에 속하는 물체의 보편적인 사이즈에 대한 신뢰할 수 있는 정보를 제공할 수 있다고 합니다. 나중에 실험적으로 보이겠지만 미리 얘기를 해보면 GPT-4가 예측한 물체의 일반적인 크기와 존재하는 데이터셋에서의 GT와 비교해봤을 때 성능이 유사하게 나오는 것을 확인할 수 있습니다.
이렇게 GPT-4에서 예측된 물체의 크기는 바운딩 박스의 dimension으로 여겨져 물체의 바운딩 박스를 칠 카테고리 prior로 간주하게 됩니다. coarse pseudo 박스의 dimension이 만약 이 카테고리 prior를 기준으로 합리적인 범위에 포함된다면, coarse pseudo 박스 자체가 합리적인 pseudo 라벨이라고 판단할 수 있는 것 입니다. 여기서 합리적인 범위란 \tau_1에서 \tau_2로 범위를 정하는데, prior의 배수로 설정되어 \tau_1은 lower 임계값이고 \tau_2는 upper 임계값 입니다. 만약 정의한 범위 안에 들지 않고 coarse 박스가 너무 작거나 크면 이 때 부터는 최적의 상자를 찾는 과정을 거쳐야 합니다.
최적의 박스를 찾기 위한 후보 박스들은 coarse 박스를 기반으로 만들어집니다. pseudo-LiDAR라는게 monocular RGB 카메라로 물체 표면에 대해 촬영한 영상에서 만들어진 것이기 때문에 coarse 박스의 4개 모서리 중 하나 이상은 최종적으로 만들어질 최적의 pseudo 박스에 속해야 한다는 가정을 하게 됩니다. 따라서 하나의 모서리는 무조건 최적의 박스가 될 수 있다고 보고, BEV로 봤을 때 coarse pseudo 박스의 4개에 대해서 각각 앞서 gpt로 얻은 prior 사이즈를 가지는 두 방향의 상자를 만들게 됩니다. Fig.3(d)에서 볼 수 있는 것처럼 하나의 파란색 모서리에 대해 1,2와 같이 두 방향의 최적의 박스 후보를 생성할 수 있는 것 입니다. 결국 한 coarse 박스 당 8개의 박스 후보가 만들어지는 것이죠.
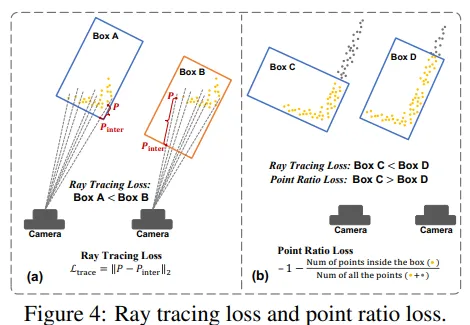
박스 후보들을 만들고 나면 그 박스들 중에서 가장 물체 포인트에 적합한 박스를 선택해야 합니다. 물체 표면에 대한 포인트들로 pseudo-LiDAR가 만들어지기 때문에 적절한 박스라고 함은 카메라에서 멀리 떨어진 모서리에 비해 가까운 모서리 주변에 포인트 클라우드가 모여있을 것 입니다. 따라서 이전 연구를 따라 ray tracing loss라는 걸 사용해서 어떤 박스가 가장 적절한지를 판단한다고 합니다. Fig.4(a)를 보면, loss는 각 포인트 클라우드, 후보 박스, 그리고 카메라 ray 사이에 가장 가까운 교차점을 찾아서 포인트와 교차점 사이의 거리를 계산합니다. Box A보다는 Box B가 포인트와 교차점 사이의 거리가 크기 때문에 loss가 크게 계산이 되겠죠.
하지만 이 ray tracing loss만으로는 적절한 박스를 찾기 충분하지 않다는데요, 그 이유는 카메라 자체가 포인트와 멀리 떨어져 있음에도 불구하고 교차점과 포인트 사이의 거리만 계산하기 때문에 자칫 잘못된 박스를 적절하다고 판단하게 될 수도 있기 때문입니다. 예를 들어 Fig.4(b)에서 Box C는 ray tracing loss 자체는 작을 수 있지만 Box D보다 적절한 박스라고 할 수 없습니다. 그래서 전체 물체를 나타내는 포인트 중에서 후보 박스로 둘러싸인 포인트의 비율을 계산하는 point ratio loss를 추가로 제안하였습니다. 이 point ratio loss를 추가하면 ray tracing loss만으로는 Box C가 D보다 더 적절하다고 판단되지만, 실제 물체 포인트를 더 많이 포함하고 있는 박스는 D이기 때문에 적절한 박스를 더 정확하게 찾을 수 있는 것 입니다. 사용하는 두 loss를 식으로 정의하면 아래의 식(2)와 같습니다.
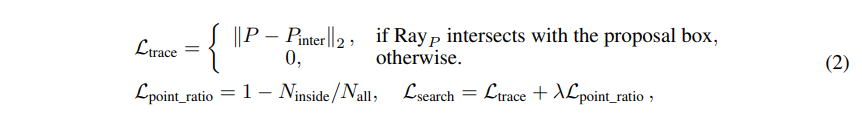
- N_{inside}, N_{all} : 후보 박스 내에 포함된 물체 포인트의 수, 전체 물체 포인트 개수
결국 각 물체마다 가장 낮은 \mathcal{L}_{search}를 가지는 후보 박스가 학습에 사용하는 pseudo label로 정의할 수 있습니다.
2.3. Training Detector on Auto-Generated Pseudo Labels
베이스 3D monocular detector로는 sota 모델인 Cube R-CNN을 사용하였고, classification 브랜치는 텍스트 align head로 대체하여 출력으로 나오는 물체 feature를 텍스트 임베딩과 align을 맞춥니다. alignment loss \mathcal{L}_{aligning} = \mathcal{L}_{CE}(c_i, y_i)로 정의할 수 있는데, 여기서 c_i는 f_i \cdot t이며 y_i는 Grounded-SAM이 예측한 클래스 라벨을 의미합니다. 최종 학습 loss는 \mathcal{L}_{train} = \mathcal{L}_{localization} + \mathcal{L}_{aligning}로 정의할 수 있습니다.
3. Experiments
실험은 outdoor 데이터인 KITTI과 nuScenes, 그리고 indoor 데이터셋인 SUN RGB-D와 ARKitScenes에서 진행하였습니다.
데이터셋에서 base 클래스와 novel 클래스를 나누었는데요, 먼저 KITTI는 (car, pedestrian)을 base 클래스, (cyclist, van truck)을 novel 클래스로 정의하였습니다. nuScenes는 8개의 base 클래스와 6개의 novel 클래스로 나누었습니다. SUN RGB-D는 20/18, ARKitScenes는 8/6으로 base와 novel 클래스를 나누어 평가하였다고 합니다.
3.1. Main Results
Baselines
해당 논문을 작성할 때 까지 OV monocular 3D detection 모델은 없어서 평가를 위한 베이스라인 모델을 먼저 설계하였다고 합니다. 지금 기준으로는 arXiv에 몇 개의 같은 task 논문이 나와있네요 !
- oracle 베이스라인을 설정하기 위해 base와 novel 클래스를 포함한 모든 데이터셋 어노테이션 정보로 Cube R-CNN을 학습
- Grounding DINO를 활용해서 OV 능력을 가지고 있는 Cube R-CNN을 설계
- 학습 데이터의 base 클래스를 사용해서 class agnostic한 Cube R-CNN을 학습하고, 테스트 때 학습 때 봤던 제한된 클래스가 아니라 새로운 물체 instance를 검출 가능
- 테스트 중에 Cube R-CNN에서 3D 박스를 예측하고, Grounding DINO를 활용하여 이미지에서 2D detection 결과를 생성
- 그 다음 3D 박스를 이미지에 reprojection하고 Grounding DINO 예측과 매칭
- Grounding DINO에서 일치하는 2D 검출 박스를 사용해 3D 박스에 클래스 할당
- OVM3D-Det에서는 학습을 위한 어노테이션이 필요하지 않지만, base 클래스에 대한 GT 어노테이션과 새로운 클래스에 대한 pseudo 라벨을 사용해서 학습된 비교를 위한 베이스라인인 OVM3D-Det* 설계
Results
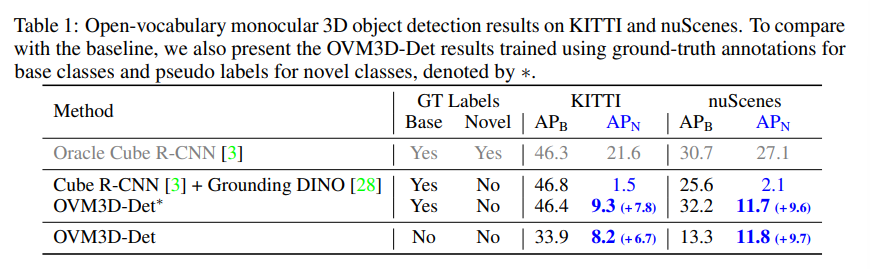
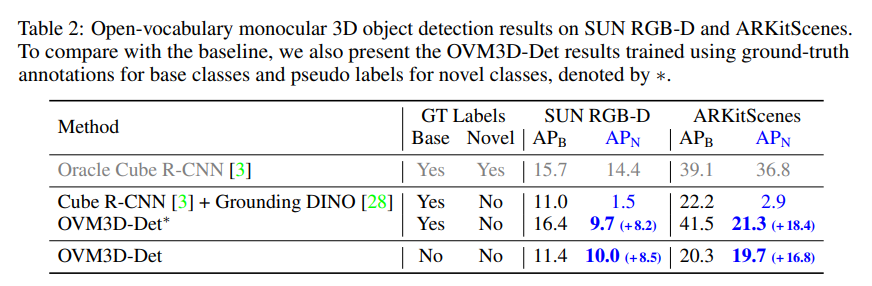
Tab.1과 Tab.2에서 각각 outdoor/indoor 데이터셋에 대한 ov monocular 3D 검출 결과를 보여주고 있습니다. unsupervised OVM3D-Det 모델이 novel 클래스에 대해 설정한 베이스라인들보다 더 높은 성능을 보이고 있습니다.
이러한 결과는 OVM3D-Det가 실제 다양한 새로운 클래스에 대해 포인트 클라우드와 사람의 어노테이션 없이도 pseudo 라벨을 정확히 생성하여 novel 물체를 검출하는 성능을 향상시킨다는 것을 의미합니다.
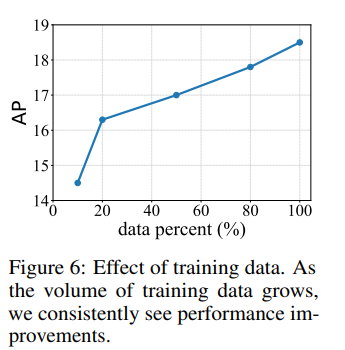
위의 Fig.6을 보면 KITTI에서 학습 데이터의 스케일에 따라 모델의 성능이 달라지며 학습 데이터 양이 많아질 수록 성능 또한 비례하게 향상되는 것을 확인할 수 있습니다. 이를 통해 구축하기 어려운 포인트 클라우드와 같은 3차원 데이터보다 비교적 대규모 수집이 쉬운 이미지 데이터를 사용할 때 더 일반화된 ov 성능을 달성할 수 있도록 학습이 가능하다는 것을 보여주고 있습니다.
Comparison with Point Cloud-Based Methods
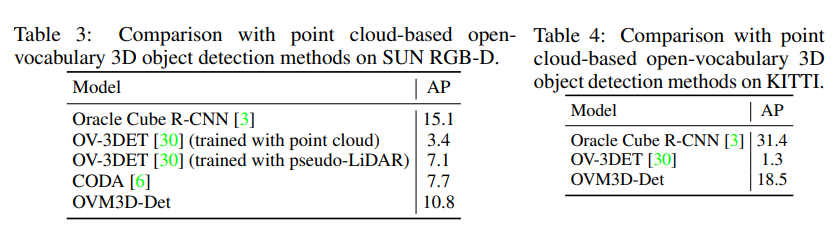
다음은 대부분의 ov 3D는 포인트 클라우드 기반으로 연구되고 있었기 때문에 sota 모델들과의 비교 실험 입니다. pseudo-LiDAR를 입력으로 사용해서 포인트 클라우드에 대해 학습 및 테스트된 OV-3DET와 평가할 수 있도록 하였습니다. OV-3DET의 포인트 입력을 기존 포인트 클라우드가 아니라 pseudo-LiDAR로 대체하여 동일한 데이터 조건으로 평가한 것 입니다.
Tab.3을 먼저 보면, 원래 포인트로 학습한 OV-3DET보다 pseudo-LiDAR로 학습했을 때 더 향상된 성능을 보이고 있습니다. pseudo-LiDAR로 학습하면 기존 모델에 비해 약 2배 정도 개선된 결과를 보여주며 CoDA는 이보다 조금 더 향상된 성능을 보입니다. 이러한 결과에 대해 저자는 기존 ov 3D 검출기는 주로 실제 포인트에 대해 pseudo 라벨을 생성하지만, 본 논문의 방법론은 pseudo-LiDAR를 생성하고 이 포인트의 노이즈를 제거하는데 초점을 맞추어 고퀄리티의 포인트를 생성할 수 있기 때문이라고 합니다. 또한 이전 연구와 차별화되는 점은 LLM을 통해 prior를 얻어 adaptive한 pseudo-LiDAR erosion 모듈을 설계하였고, pseudo 박스를 refine하는 과정이라고 이야기합니다.
Tab.4는 outdoor에 대한 결과로, OV-3DET는 indoor 데이터에 대한 결과만 존재하여 다른 베이스라인을 설정하였습니다. pseudo-LiDAR를 사용해서 KITTI 데이터셋에 대한 OV-3DET를 학습하였다고 하네요. 단순하게 pseudo-LiDAR로 학습을 하게 되면 1.3%라는 매우 낮은 성능을 보이게 되지만 .. 이 결과에 대해서는 outdoor 데이터 특성상 포인트가 커버하고 있는 공간적 스케일이 indoor보다 더 커서 작은 노이즈가 발생하면 더 치명적인 pseudo 라벨 에러로 이어질 수 있기 때문이라고 분석하고 있습니다. 따라서 본 논문이 제안하는 pseudo-LiDAR refinement를 거치지 않고서는 raw한 pseudo-LiDAR만으로는 신뢰할만한 pseudo 박스를 생성하는 것이 어렵다는 걸 보여주는 결과라고 합니다.
3.3. Ablation Studies
ablation sutdy는 KITTI 데이터셋에서 수행하였습니다.
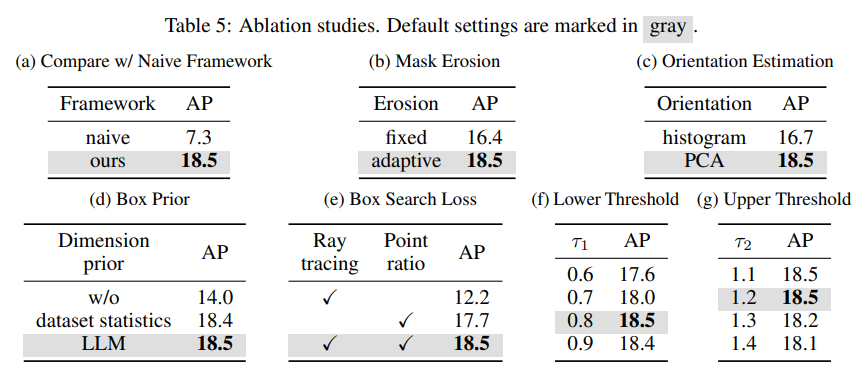
Comparison with Naive Framework
pseudo-LiDAR와 바운딩 박스에 적용된 segmentation을 제거하였는데, raw pseudo-LiDAR를 그대로 사용하고 여기서 바운딩 박스를 바로 얻는 방식 입니다. 이런 방식으로 성능을 리포팅했을 때 성능이 11.2% 감소하면서 노이즈가 있는 pseudo-LiDAR를 처리하는 본 논문의 방식이 효과가 있다는 것을 보여주며 pseudo-LiDAR와 바운딩 박스 추정에 segmentation이 중요하다는 것을 증명하고 있습니다.
Mask Erosion
adaptive하게 erosion 과정에 대한 ablation sutdy인데요, adaptive하게가 아니라 모든 물체에 대해 고정된 erosion로 대체했을 때 2.1%의 성능 감소가 나타나게 됩니다. 이는 물체의 크기에 따라 adaptive한 erosion을 적용하는 것이 필요하며, 고정적인 erosion은 작은 물체를 아예 없애버리거나 노이즈가 큰 물체를 제대로 처리하지 못한다는 것을 의미합니다.
Orientation Estimation
이 실험은 orientation을 추정하는데 있어서 제가 방법론에서 잠깐 언급했던 것으로, PCA를 사용하거나 pseudo-LiDAR에서 각 포인트 쌍의 방향 분포에 대한 히스토그램을 계산하는 두 가지 방법을 비교합니다. PCA가 더 간단하고 효율적이면서 성능을 약 1.8% 향상시키면서 최종적으로 PCA를 사용했다고 하네요.
Dimension Priors
GPT-4를 통해 얻는 prior에 대한 ablation study로 pseudo 박스의 잘못된 예측을 수정하는데 사용하고 있죠. Tab.5(d)를 보면 만약 이러한 prior를 사용하지 않았을 때 성능이 크게 감소하게 됩니다. GPT-4와 같은 LLM을 사용할 때와 기존 데이터셋의 바운딩 박스 크기를 통계낸 결과를 사용한 것은 유사한 결과를 보여주고 있는걸 확인할 수 있습니다. 이는 LLM을 사용했을 때 LLM이 가지고 있는 상식을 활용할 수 있으며, 개별적인 데이터셋의 통계를 내지 않아도 된다는 장점이 존재합니다.
또한 Tab.5(f)와 (g)를 통해 prior를 기준으로 lower 임계값과 upper 임계값의 민감성을 평가했는데, 특정 범위에서만 두드러지는 성능을 보이는 것이 아니라 넓은 범위에서 안정적인 성능을 낼 수 있다는 것을 보여주고 있네요.
Box Search Loss
마지막으로 pseudo 바운딩 박스를 예측하는 두 개의 loss 함수에 대한 영향을 평가하는 ablation study 입니다. 방법론에서 얘기한 것과 동일하게, ray tracing loss만 사용하는 것은 충분하지 않으며 point ratio loss를 추가하여 두 가지 방면으로 박스를 고려하였을 때 비로소 18.5%의 성능을 달성할 수 있는 것을 확인할 수 있습니다.
리뷰 잘 읽었습니다.
초반부 2D->3D 로 올리는 과정에서 객체 표면부 쪽에서 발생하는 노이즈에 관련된 질문이 있습니다. 객체 표면부를 기준으로 전경/배경쪽의 depth 차이가 많이 나는건 자명하게 이해가 가는데, 이로 인해 노이즈가 생기는 부분이 연결이 잘 안돼서요.
추가 설명가능할까요?
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
depth 차이가 많이 발생하는 엣지 부분이 depth estimation 모델을 타고 나왔을 때 다른 일반적인 전경/배경 영역보다 명확하게 depth 값을 추론할 수 없게 되고, 부정확한 depth 값을 가진 영역이 3차원으로 projection되면서 노이즈로 간주될 수 있게 됩니다.
감사합니다.
안녕하세요 건화님, 좋은 리뷰 감사합니다.
adaptive erosion 부분에서 질문이 있습니다.
1. adaptive erosion의 기준으로 제시되는 마스크 크기는 넓이로만 고려하는 것인가요?
2. 우선 adaptive erosion이 전경과 배경간의 depth차이 심화로 노이즈가 생기는 것을 완화하기 위함으로 이해했습니다. 하지만 Grounded-SAM이 마스크를 물체랑 항상 딱 맞게 혹은 조금 넉넉하게 만드는 경우 말고도 오히려 물체보다 조금 작게 만들어버리는 경우도 간혹 있을 것 같은데, 그런 부분에선 erosion 말고 아주 약간의 dilation은 오히려 효과적일 수도 있지 않을까 생각하는데, 저자들은 이런 부분에서 dilation에 대한 언급은 없었나요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 넓이만 고려한다기보단 전체적인 면적을 고려한다고 이해해주시면 될 것 같습니다.
2. 재찬님 말대로 작게 만들어버리는 경우에는 dilation이 도움이 될 수도 있겠다고 생각은 들지만, 저자가 dilation에 대해 특별이 언급하진 않았습니다.
감사합니다.
안녕하세요 건화님 좋은 리뷰 감사합니다.
adptive erosion을 통해 노이즈를 제거한다고 하셨는데 erosion과정 어떤 kernel을 통해 노이즈를 제거하는 방식인가요? Figure3에서 kernel을 사용한다고 했는데 제가 erosion 과정을 잘 몰라서 조금만 더 자세하게 설명 부탁드립니다.
감사합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
성준님이 말씀하신 대로 erosion 과정은 영상 처리 기법 중 하나로 일정 크기의 커널을 통해서 어떤 물체를 관련 배경과 연관지어 일정하게 줄여주는 방식을 의미합니다.
해당 논문에서 물체이지 않은데 배경을 물체라고 인지하는 부분들을 제거하고 실제 물체인 마스크 영역만 남겨놓는 것이 목적이다 보니 불필요한 배경 부분을 날릴 수 있는 erosion 과정을 거치는 것 입니다.
감사합니다.
좋은 리뷰 감사합니다.
단일 RGB로부터 Open-Vocabulary 3D Detection을 수행하는 연구로,
pseudo-LiDAR로 3D 정보를 추정하며, 이때 노이즈를 제거하기 위핸 artifact 필터링과 LLM 모델의 사전지식을 통해 물체의 일반적인 크기를 고려할 수 있도록 설계한 방법론으로 이해하였습니다.
이때, LLM이 물체의 크기 정보를 활용하기 위해 “<클래스> 카테고리의 사물에 대한 (length, width, height)를 실생활에서의 보편적인 크기에 따라 알려줘”라는 프롬프트를 사용하여 답을 얻는 다는 것이 인상적입니다.(LLM이 어떻게 보면 3차원인 크기 정보를 알고있다는 것이 신기하네요 ㅎㅎ)
실험 결과, Table 3에서 실제 Point cloud보다 Pseudo-LiDAR를 사용하는 게 성능이 2배 더 좋은 결과를 보이고 있는데, OVM3D-Det에 대해서는 Pseod-LiDAR가 아닌 실제 point cloud를 사용하는 실험 결과는 따로 없을까요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
LLM을 사용해서 물체의 일반적인 크기를 알아내는 방식은 본 논문이 말고도 다른 ov 논문에서도 활용을 하더라구요 ! 물체의 prior를 알아낼 때 꽤나 유용하게 사용할 수 있는 방식인 듯 합니다.
질문 주신 OVM3D-Det에 대해서 pseudo-LiDAR가 아닌 실제 포인트를 사용하는 실험 결과는 아쉽게도 없습니다. 아무래도 이전 방법론들에 psuedo-LiDAR를 입력으로 해본거는 원래 기존 포인트를 쓰는거보다 성능 향상이 발생하는 걸 보여주기 위해 해봤던 것 같고 본 논문의 방법론에는 따로 입력 데이터를 바꿔서 실험을 해보지는 않은 듯 합니다.
감사합니다.
안녕하세요. 리뷰 잘 읽었습니다.
Method 부분에 보면 Back proj라는 표현이 있는데, 이에 대한 설명은 빠져있는 것으로 확인되어서요~ 간단한 설명 부탁드립니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
Back proj라는 것은 2차원 공간의 정보를 3차원으로 올리는 것을 의미하며 역으로 projection을 하는 과정을 나타냅니다.