
안녕하세요. 이번 리뷰할 논문은 RegionCLIP으로, 한 문장으로 요약하자면 “CLIP이 Detection, Segmentation 등에서 조금 더 유용히 활용되고자 제안된 방법”입니다. 비록 2년 전의 방법론이나, 최근의 VLM 기반의 논문들에서도 쓰이는 만큼 어렵지 않은 방식이지만 그만큼 유망한 성능을 보이며, 제안하는 문제 정의와 방법론이 굉장히 직관적이므로 어렵지 않게 읽을 수 있습니다.
Introduction
CLIP(Contrastive Language-Image Pretraining)은 이미지와 텍스트 한 쌍의 이미지를 학습하여 “Vision-only”만의 시대 다음의 시대, “VLM” 시대를 도래하였습니다. CLIP 이후 특히나 Zero-shot 성능에 관심이 많아졌으며, 이미지 분류 분야에서는 CLIP을 활용한 Zero-shot의 성능이 이전의 Supervision 방식에 견줄만함, 또는 그보다 위에 있음에서 해당 연구(VLP)에 대한 관심이 높아졌습니다. 하지만 저자의 문제 제기는 다음과 같습니다. “CLIP을 Detection, Segmentation 등의 객체 인식 분야에서 활용 시, Domain shift, 즉 CLIP은 이미지 전체와 하나의 문장 (A photo of a boy)에 대한 매칭을 학습하였으므로, 이미지 내 특정 영역인 예를 들면 Bounding box 내의 영역에 대한 Alignment에 대해서는 이해력이 부족하며 그로 인해 성능 하락이 초래된다”. 이는 위 Figure 1로 이해할 수 있습니다. Figure 1의 a는 CLIP을 활용하여 “boy”에 대한 Bounding box를 생성한 정성적 결과를 보여줍니다. 높은 확률(65%)로 채택되는 Bounding box는 우리 눈에도 보이듯 “boy”를 포함은 하지만, 그 경계가 포괄적입니다. 정량적 성능은 b에서 확인할 수 있습니다. 이미지(image)에 대한 분류의 성능은 59.6%로 비교적 높지만, 영역(region)에 대한 분류 성능은 19.1%로 저조합니다. 이에 저자는 c의 방식, CLIP을 영역과 텍스트의 매칭으로 학습하는 방식을 제안합니다. 사실 상 위 c가 해당 논문의 방법론을 모두 설명하는데, 해당 이미지를 “A photo of a boy”, “A photo of one crusie” 등으로 학습함이 아닌 “boy”에 해당하는 영역만을 따로 “A photo of a boy”와 매칭하여 학습합니다. 그럼, 빠르게 방법론을 살펴보겠습니다.
Method
problem definition
이전의 CLIP이 Visual-semantic matching을 학습함에 목표가 있었다면, 저자는 Regional visual-semantic matching을 학습함에 목표가 있습니다. 이후 이들을 OVD 태스크에 대한 Transfer-learning을 진행하여 해당 방식이 단순히 Global만이 아닌 Local에 대한 이해력을 높임을 증명하고자 합니다. Text description( t )가 이미지( I )내의 영역 ( r )을 나타낸다고 할 때, Visual-semantic space에서 Visual-region representation인 \mathcal{V}(I, r) 은 Text representation인 \mathcal{L}(t) 와 매칭되어 학습하여야 합니다. 이 때의 Visual/Language encoder는 이전 CLIP의 방식을 따라 활용됩니다.
Disentanglement of recognition and localization
이미지 영역에 대한 이해는, 특히 Object detection 분야는 Localization과 Classification으로 나뉩니다. 저자는 두 요소를 분리합니다. 논문 상에는 이에 대한 부분이 단 한 문장으로 쓰여있지만 실제 코드를 확인해보면 분리한다는 내용은 곧 학습되는 요소는 백본 네트워크일뿐, Region을 추출하기 위해서는 Faster R-CNN의 RPN을 활용하게 되는데 이 RPN은 이미 사전에 COCO dataset으로부터 학습된 Faster R-CNN의 RPN을 활용하여 추출합니다. 즉, RPN은 곧 Bounding box 후보군의 좌표만을 따오면 되는 역할이므로, 백본으로부터 Feature map을 뽑고 그 이후 RPN으로부터 Proposal의 후보 좌표를 가져오기만 합니다. 그런데 보통 우리가 생각하면 백본으로부터 추출한 Feature map을 입력으로 RPN을 통과시킬텐데, 그러한 방식이 아닌 RPN의 입력이 되는 Feature map은 또한 사전에 학습한 백본 네트워크(물론 이 백본도 Freeze)로부터 추출합니다. 즉, 저자는 사전에 학습한 RPN이 적어도 Region만큼은 잘 추출해내리라 생각하기에 (또한 RPN을 학습한다는 자체는 Pretraining의 본질을 해치기에) 해당 방식으로 설계하지 않았을까 싶습니다.
Method overview

Figure 2 보이는 바와 같이, RegionCLIP은 CLIP과 동일하게 \mathcal{V}, \mathcal{L} 을 매칭하여 학습합니다. 하지만 앞선 문단에서 말한 바처럼 \mathcal{V} 는 이미지 전체가 아닌 영역으로 부터 학습되는, Figure 2 상단의 2에서 확인됩니다. 이 2의 Region-text Pretraining (ours) 사진만 보아도 현재 방법론을 확실히 이해할 수 있습니다. 다만, 해당 방식으로 학습할 때는 Large-scale의 Region discription이 부족하다는 하나의 문제점이 존재합니다. CLIP은 Web-scale의 이미지-텍스트 쌍으로 학습하지만, 현재의 방식은 Region-Text 쌍으로 구성되어야 하는데, Region은 사전 학습된 RPN으로부터 추출할 지 언정 해당 Region을 설명하는 문구를 모두 가지는 데이터는 부재하기 때문입니다. 이에 저자는 Figure 2 하단 부에 보이는 바와 같이 CLIP의 Image-text corpus로부터 추출한 Concept pool (즉, Categories)을 Region desciptions로 생성한 후, Viusal teacher encoder \mathcal{V}_{t} 가 Region-text 쌍을 생성하도록 유도합니다. 즉, 사전 학습된 Visual encoder를 Teacher 모델로하여 이들로부터 생성된 Pseudo Region-text 쌍이 Pretraining에 관여합니다. 결국 중요한건 이 Pretraining 과정입니다. Pretraining의 핵심은 영역과 텍스트 간 매칭(Alignment)을 함에 있는데, 이 매칭은 결국 Contrastive learning이 핵심입니다. 하지만 Contrastive learning은 성능을 위하여 큰 Batch를 요구하기에 우리가 이를 직접 수행하긴 어렵습니다.
그렇다면 우리가 수행할 수 있는 이후 Figure 2 상단부의 3, Transfer learning for detection (ours) 부분에 집중하여 본다면, Visual encoder ( \mathcal{V} )는 Pretraining으로 학습된 백본으로 초기화한 이후 RPN은 동일하게 사전 학습된 RPN을 따르며 (저자가 깃허브 내 이슈에서 RPN을 직접 학습하더라도 문제되지는 않는다고 합니다), Transfer learning 시에는 RoI head를 학습합니다. RoI head에서 Visual-language 간의 매칭 결과를 토대로 Region에 대한 Classification을 진행하는데, 이때 Language vector는 Pretraining encoder로부터 사전에 추출하여 활용합니다. 그렇다면 RoI head는 Classification이 아닌 Localization만을 학습합니다. 그렇다면 Transfer learning에서는 백본과 RoI head의 Localization layer가 학습된다고 보면 됩니다. Pretraining 과정에 대해 설명하고 넘어갈까 했지만, CLIP과 동일한 방식의 Contrastive learning에 대한 설명이다 보니, 넘어가고 실험을 살펴보겠습니다.
Experiments
저자가 제안한 RegionCLIP은 Region-text 쌍의 학습으로부터 Pretraining하는 과정을 담기에, 핵심 벤치마킹은 Figure 2 상단부 3의 Transfer learning for detection을 Zero-shot의 OVD 세팅에서 보임에 있습니다. 저자는 Pretraining에 있어 Web-scale의 Image-text 쌍으로 구성된 CC3M, COCO에서 일부를 Caption한 COCO-Caption 데이터셋을 합하여 Pretraining합니다 (물론 COCO-Caption의 경우 COCO에서 OVD 평가시에는 제외합니다).
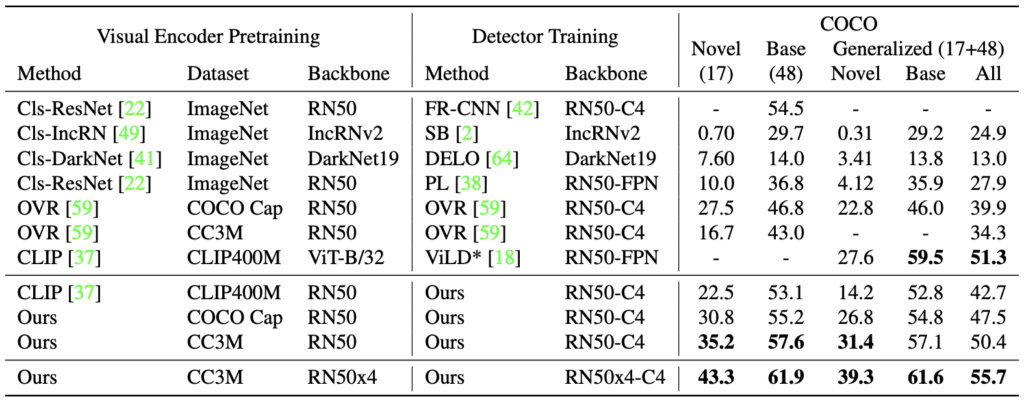
위 표는 COCO 데이터셋에서 OVD 실험 결과를 보여줍니다. 위 Cls-ResNet이 ResNet에서의 베이스라인이라 할 때, 그 아래의 CLIP과 Ours에 대한 비교가 주입니다. Generalized는 80개 클래스 중 65개의 클래스에 대한 Novel, Base, All으로 All의 경우 OVD가 아닌 일반적인 Object detection 평가로 보면 됩니다. 제 생각엔 RegionCLIP이 OVD를 위한 특별한 설계는 되어있지 않았으므로, CLIP과 Ours의 All에서 성능 차이에 집중해서 보면 좋습니다 (물론 Novel,Base 세팅에서도 모두 Ours가 뛰어납니다). CLIP-CLIP400M-RN50과 Ours-COCO cap(CC3M)-RN50의 성능 평가 비교 시, Generalized Base와 All에서 Ours는 CLIP에 비해 2~5% 이상의 성능 향상을 보입니다. 비록 Figure-1의 b만큼 CLIP에서 성능이 낮아지지는 (OVR CC3M-RN50과 비교 시) 않고 성능 향상을 보이지만, 저자의 방법론이 더 높은 성능을 보임을 확인할 수 있습니다.

다음으로는 Cls-ResNet(ResNet을 백본으로하는 Faster R-CNN)을 Supervision(Novel)로 학습한 방식에 비해, Ours는 동일한 RN50 세팅에서도 최대 5%의 성능 향상을 보입니다. CLIP의 백본은 ViT로 동일한 평가는 되지 않지만, 핵심은 Text 데이터를 통해 Zero-shot이 Supervision에 비해서 높은 성능을 보임을 확인할 수 있습니다.
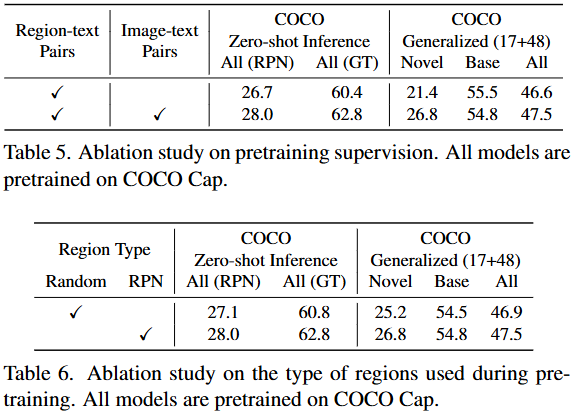
Pretraining 세팅에 대한 몇몇 Ablation study입니다. Table5는 Region-text pairs를 기반으로, Image-text pairs인 CLIP으로부터 초기화하여 시작함이 좋음을, Table 6은 Pretraining에서 Region 타입으로 Random한 Region을 입력으로 넣을지, 또는 RPN으로부터 Region을 입력으로 할지에 대해, 당연히도 RPN으로부터 추출한 Region이 좋겠죠?하고 성능을 보니, 오히려 Table 6에 비해 성능 차이가 미미합니다. 해당 성능은 Random으로 하더라도 CLIP보다 높다는 점에서 결국 Region-text pair가 가장 중요함을 알 수 있습니다.

마지막으로 정성적 결과입니다. 음, 제 생각에선 CLIP은 Ours에 비해 Bounding box의 Localization 성능이 낮을 것으로 예상하였지만, 오히려 생각보다 Classification에서 약함을 확인할 수 있습니다. 해당 정성적 결과는 본 논문을 읽으며 제가 예측한 부분과는 달라 당황스럽네요.
이번 리뷰에서는 CLIP을 Object recognition 태스크로 Down-stream할 때, Region-text pair로 학습하는 방식을 제안합니다. 어찌 보면 쉬운 문제 제기로 부터 성능 향상을 이루었다는 점에서 고무적이지만, 해당 논문도 64개의 GPU를 사용했다는 점에서 Pretraining은 역시 우리가 당장 범접하기엔 어렵다는 것을 다시 깨닫게 됩니다. 리뷰 읽어주셔서 감사합니다.
리뷰 잘 읽었습니다.
방법론 및 실험에 대한 부분은 평소에 관련된 디스커션을 많이 진행했던지라 막히는 부분이 없었는데요,
intro 부분에서 언급하신 ‘ (또한 RPN을 학습한다는 자체는 Pretraining의 본질을 해치기에)’ 라는 부분에 대한 추가 설명을 해 주시면 감사하겠습니다.
안녕하세요 좋은 리뷰 감사합니다.
표 6에서 사전학습 시 랜덤 영역을 보고 텍스트와 매칭시켜도 성능이 많이 하락하지 않는다는 점이 놀랍습니다. 여기서 COCO Zero Shot Inference의 RPN (All)은 어떤 성능인가요?
그리고 RegionCLIP 성능 리포팅 시 백본은 항상 ResNet만 사용하고 있는데, ViT는 왜 사용하지 않았는지에 대한 저자의 의견이 있는지도 궁금합니다.
감사합니다.
1
안녕하세요 상인님,
추천해주신 regionCLIP을 읽는 과정에서 상인님께서 X-review에 쓰신 글이 해당 논문을 이해하는데 많은 도움이 된 것 같습니다. 위 글에서 “저자는 사전에 학습한 RPN이 적어도 Region만큼은 잘 추출해내리라 생각하기에 (또한 RPN을 학습한다는 자체는 Pretraining의 본질을 해치기에) 해당 방식으로 설계하지 않았을까 싶습니다.” 이런 부분이 있었는데, 이 부분은 저자가 faster-RCNN 방식을 사용하여 localization, classification을 분리하였고, localization은 기존에 학습된 Faster R-CNN의 RPN을 그대로 사용하고, classification 만을 학습시킴으로써 pretraining의 본질을 해치지 않도록 하였다! 라고 이해해도 될까요?! 즉, Pretraining은 feature를 학습하는 것이지 detection box를 학습하는 것이 아니다! Detection 부분(RPN)은 기존 모델을 활용하고, Feature만 학습시켰다! 라고 이해하는 것이 맞는지 궁금합니다!
감사합니다!
대면 답변 완료
안녕하세요 상인 연구원님 리뷰 잘 읽었습니다.
아래는 읽으면서 궁금했던 것들입니다.
methods의 맨 앞 부분 즉 pseudo label을 만드는 과정에서
1) 이미지에서 RPN으로 region을 뽑을 때 어떤 객체에 대해서 region을 뽑게 되는 category가 주어져 있는 건가요?
2) concept pool을 만드는 이유가 어떤 이미지에 대한 캡션으로 주어지는 텍스트 데이터가 이미지의 세부적인 특징이나 캡션이 가리키지 않는 이미지내 또 다른 객체에 대해 나타내지 못하기 때문이라고 이해했습니다. 예를 들면 이미지에 어떤 남자아이가 풍선을 들고 있고 뒤에 비행기가 있다고 하고 해당 이미지에 대한 캡션이 a boy holding a balloon 이라고 했을 때 airplane에 대한 캡션 정보는 없기 때문에 이에 대한 region caption을 달아주기 위해 필요하다고 이해했는데요 이 또한 제가 잘 이해한 게 맞는지 궁금합니다.
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
1) 아닙니다. 이 부분은 Region Proposal Network (RPN)에 대한 이해가 필요한데, RPN은 객체의 범주와는 상관 없이 객체일법한 것에 대한 영역을 뽑아냅니다. 이것이 어떤 객체인지는 이 뒷단의 Detection Head에서 판단합니다.
2) 정확히는 “A boy holding a ballon”이라는 캡션에 대해 실제로는 boy, ballon과만 연산할 수 있습니다. 그렇다해도 Airplane이라는 텍스트와 Airplane에 해당하는 영역이 Negative로 되진 않습니다. 제가 이해한 Concept Pool이란 개념은 단순히 1000개, 10000개의 카테고리를 담고 연산하면 너무 느리니, 그 특정 데이터셋에 포함된 클래스 수만을 의미한다고 보심이 더 쉽습니다.