이번 리뷰 논문은 전에 소개해드린 3DLF의 느릴 수 밖에 없는 파이프라인과 추론 속도를 보강하기 위한 기법입니다. 해당 기법은 입력 영상으로부터 0.1 second 정도의 온보딩 과정만 갖추면 view synthesis, depth prediction, open-vocabulary 3D segmentation을 100+FPS로 추론 가능합니다. 해당 방식이 진짜 성능만 높다면 정말 수 많은 어플리케이션들이 가지고 있는 문제점들을 해소 가능할 것 같습니다.
Intro

컴퓨터 비젼 분야에서는 오랫동안 상대적으로 값싼 2차원 영상으로부터 3차원 정보를 이해하기 위한 수많은 연구들이 진행되어 왔습니다. 해당 방식들의 목적은 2차원 영상만으로 기하적/의미론적 정보를 3차원 표현으로 변경하여 3차원 물리적 공간과 상호작용하고 추론하고 작업을 위한 계획을 수립하기 위한 것이죠. 가장 전통적인 기법은 SfM을 활용한 다음 서브-모듈로부터 재구성된 3D에 대한 의미론적 추론을 진행하는 방식을 이용합니다.
최근 SfM의 sparse reconstruction을 이용하여 3D 표현을 강화시키는 MVS, NeRF, 3D-GS와 같은 연구들이 진행되어져 왔으며, 자율주행, 로보틱스, VR/AR들 수 많은 어플리케이션에 영향을 주고 있죠. 이러한 방식들은 2D 영상으로부터 3D 정보로 표현하는 복잡성 문제를 해결하기 위해 명확하게 구분 가능하게 단계를 나눴습니다. 그러나 해당 전략은 단계별 오차에 대한 전파가 어려워 성능을 하락 시키는 문제가 있습니다. 예를 들면 SfM은 입력되는 뷰 뿐만이 아니라 파라미터에 따라 성능이 크게 좌지우지됩니다. SfM으로부터 추론된 정보를 입력으로 받는 기존 방법들의 성능은 SfM의 품질에 따라 크게 변경되는 문제가 발생하겠죠.
또한, Open-vocabulary methods를 통해 3차원 환경과 유연한 상호작용이 가능한 3DLF 기법도 NeRF와 3D-GS의 파이프라인을 그대로 가지고 있기 때문에 SfM에 의존적인 문제를 가집니다.
저자는 이러한 문제들을 해결하기 위해 처음으로 unposed and uncalibrated images로부터 SfM->3DLF 구성의 기존 프레임워크(dense 3D reconstruction, open-vocabulary semantic segmentation, and novel view synthesis)를 하나로 통합한 프레임워크 Large Spatial Model (LSM)을 제안합니다.
해당 기법은 3D scene을 semantic anisotropic Gaussians으로부터 학습하는 단일 Transformer-based model를 활용합니다. 기존 기법들이 알려진 카메라 파라미터를 활용하거나, SfM으로부터 추론된 값을 활용하는 것과는 달리 직접적으로 pixel-aligned point maps을 예측하고 이를 anisotropic Gaussians으로 활용하는 coarse-to-fine strategy를 제안합니다.
+ 설명이 복잡할 수 있는데… 기존 3D-GS는 SfM으로부터 추론된 sparse reconstruction을 구성하는 point cloud(+RGB)를 anisotropic Gaussians의 초기 값으로 활용합니다. 완전 새로운 개념은 아니니 어렵다면 NeRF와 3D-GS 논문을 보시면 도움이 될 것 같습니다.
Method
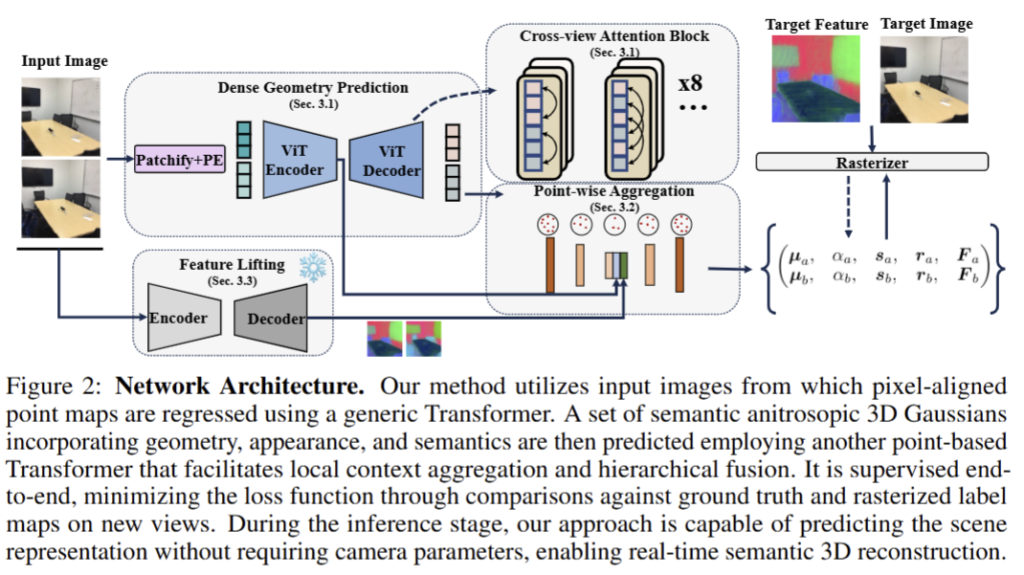
Dense Geometry Prediction
해당 모듈이 SfM의 sparse reconstruction을 대체하는 파트에 해당합니다. 저자는 기존 epipolar attention을 활용하는 Transformer가 아닌 새로운 방식을 이용했다고 합니다. 이는 수 백개의 쿼리로부터 pixel-wise prediction을 수행하는 것이 비효율적이기 때문에 정규화된 공간에서 직접 회귀를 수행하는 방식을 적용했다고 합니다.
Direct Regression of Normalized Depth Map. 우선 공유된 가중치를 가진 Siamese ViT-based encdoer로부터 stereo images를 추론합니다. 그 다음, pixel-aligned point maps을 unposed image for view v \in {1, 2} 로부터 직접 회귀하기 위해서 cross-view attention을 활용합니다. (이에 증명은 기존 연구로부터 증명되었다고 하네요.) decoder block은 self-attention과 앞서 언급한 cross-view attention을 통해 두 시점의 영상을 통합합니다. 구체적으로는 기존 MVS [Croco, Dust3r]과 유사하게 12 attention blocks으로 구성했다고 합니다. 그 다음, DPT head를 통해 정규화된 좌표계의 pixel-wise point map과 이에 대한 confidence value를 예측합니다.
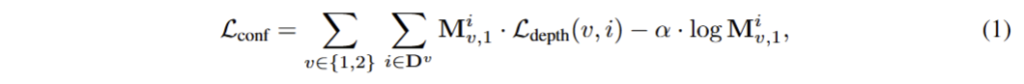
여기서 M은 기존 MVS[Dust3r]와 동일한 pixel-aligned confidence map이며, D는 유효한 포인트, \alpha 는 regularization을 위한 하이퍼파라미터에 해당합니다. 여기서 depth에 대한 loss는 다음과 같이 구성됩니다.
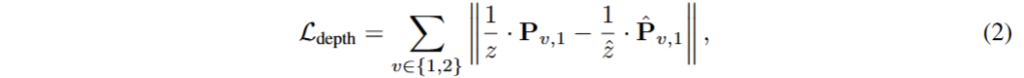
여기서 (z and \hat{z} ) 는 다음과 정규화 되었음을 의미합니다.
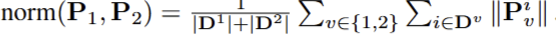
+ 해당 섹션 내용은 저도 이해가 잘 안가서 참고 걸어준 논문들을 살펴봐야 할 것 같습니다. 기본적인 원리는 relative depth를 두 뷰 간의 disparity로 활용하는 방법을 제시하는 것 같은데… 어떻게 가능한지 논문 내용으로는 충분히 이해가 안가네요… 찾아보고 공유하도록 하겠습니다.
Point-wise Feature Aggregation
Point-wise Attribute Prediction. 여기서는 two Transformer-based networks를 구분된 태스크에 최적화를 수행합니다. 하나는 “coarse” global gemetry를 위해, 다른 하나는 “fine” local information aggregation을 목적으로 합니다. 처음 입력으로는 p = {x, y, z, r, g, b} 형태로 컬러와 각 포인트 정보들을 통합한 스테레오 point maps을 입력으로 받습니다. 해당 정보는 기존 point cloud processing 연구[PCT; point-cloud Transformer]를 활용하여 기하학적 정보를 고려한 localized window 내에서 연산이 가능한 Transformer를 활용하여 point-wise aggregation을 수행합니다.
point-wise features에 대한 aggregating이 완료된 후, set of anisotropic Gaussians을 회귀하기 위한 MLP를 적용합니다. anisotropic Gaussians은 기존 3D-GS와 동일한 값을 추론하며, 다음과 같이 렌더링이 진행됩니다.
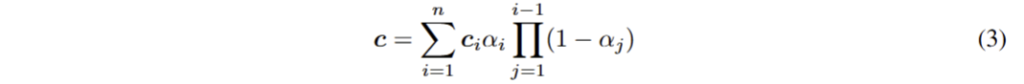
+ 자세한 내용은 3D-GS 참고
Cross-model Feature Aggregation. 저자는 또한 두 뷰의 image feature F와 point-wise geometric information P을 효율적으로 결합하기 위해서 cross-model attenton을 제안합니다.
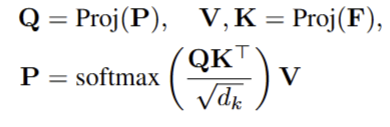
+ 논문을 읽어보니 특별하게 다른 건 없고… 걍 cross-attention 적용한 것이 끝이네요…
P와 F는 입력되기 전에 linear layer로 정규화된다고 합니다.. (무슨 소리지…)
Learning Hierarchical Semantics
해당 파트는 3DLF 중 LangSplat의 내용을 기반으로 합니다…
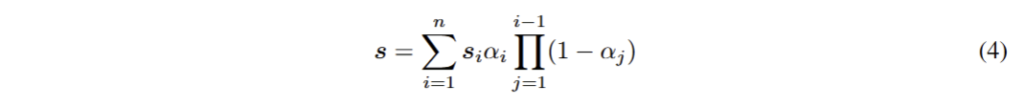
저기서 s는 foundation model (e.g. CLIP)으로부터 추론된 image feature에 해당합니다.
3D Semantic Field from 2D Images. 해당 모듈에서는 획득한 s를 rasterized featue map과 2D foundation model로부터 추론된 feature와의 차이를 최소화하는 것을 목적으로 합니다. test time 최적화가 필요한 기존 기법 [feature 3DGS]와 다르게 직접 예측이 가능하도록 학습 가능한 프로세스로 변경합니다.
기존 2D model은 view-inconsitnet에 대한 추론 능력이 떨어지기 때문에 새로운 뷰에 대한 추론 중에 OVS 예측[LSeg]을 하도록 학습을 구성합니다. (+해당 방식이 LangSplat 방식입니다.) 이에 대한 내용은 다음과 같습니다.
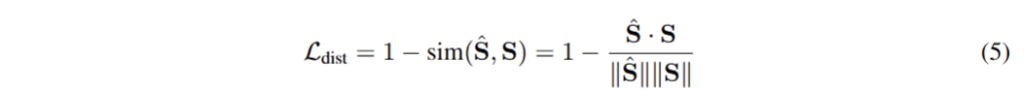
Multi-scale Feature Fusion. 해당 모듈에서는 ViT encoder F와 frozen semantic feature S, 3D latent space (point feature P)를 anisotropic Gaussians를 추론하기 위한 값으로 전달하는 기법을 소개합니다.
+ fig 2에서 중간 입력에 point-wise aggregating에 전달하는 것을 의미합니다. 해당 값들이 결합되어 anisotropic Gaussians을 예측합니다.
Training Objective
이를 모두 결합하면 end-to-end로 최적화가 가능합니다.

여기서 C는 rasterization 중 사용된 GT pixel, G는 3D scene을 구성하는 3D semantic anisotropic Gaussians을 의미하며 S는 LSeg feature exrator로부터 나온 semantic feature, d는 new view에 대한 direction and position에 해당합니다. 저자는 생성된 raserized new views에 대해서 photometic loss와 semantic loss를 지도학습을 수행하도록 합니다. geometry prediction과 semantic feature lifting을 위해 저자는 confidnece-weighted depth loss를 적용합니다.
Experiment
Implementation Details. 해당 모델은 encoder는 ViT-L, decoder는 ViT-B를 활용했으며, pixel-wise geometry regression은 DPT head를 활용. geometry prediction layers에는 DUSt3R의 가중치를 활용해 초기화를 함. 총 100 epochs 학습. 데이터 셋은 ScanNet++과 ScanNet을 활용하여 1,565 Scenes을 학습. 학습에는 8 Nvidia A100 GPU lasts for 3 days. 평가에는 40 unseen scenes from ScanNet를 활용
Semantic 3D Reconstruction
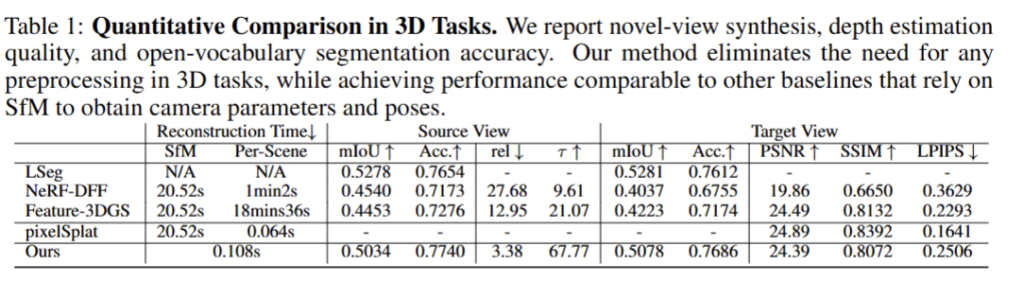
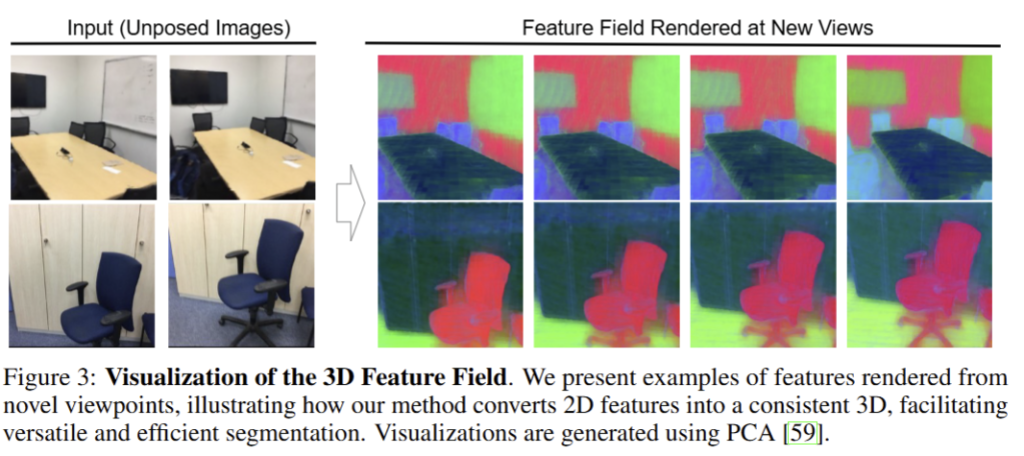

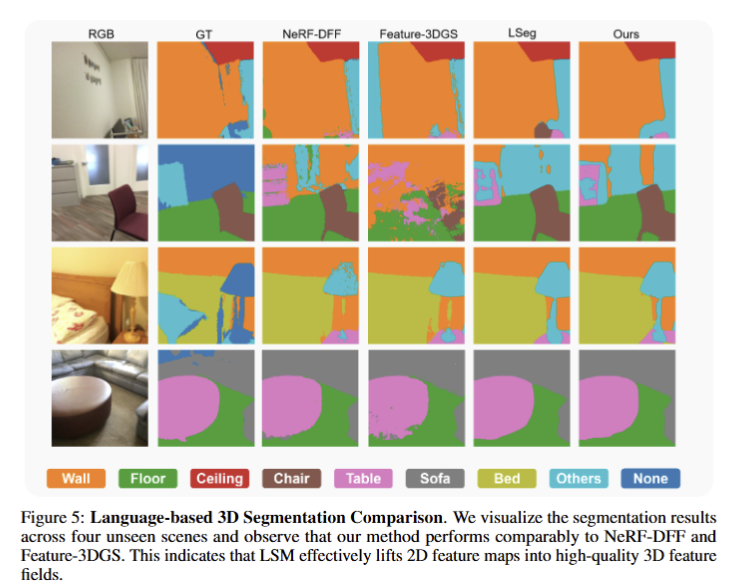
전반적으로 Tab 1과 같이 기존 기법들을 압도하는 성능을 보여줌. 특히, Reconstruction time은 SfM을 활용하지 않기 때문에 압도적인 결과를 보여줌. 또한, segmentation 결과에서도 2D model과 준하는 성능을 보여주고 있음. Novel view synthesis의 결과인 PSNR, SSIM, LPIPS의 결과도 end-to-end 임에도 불구하고 기존 기법과 준하는 결과를 보여주고 있음. 정성적인 결과(fig 3)도 일관성을 보여주고 있음. fig 4에서는 다른 기법보다 좋은 결과를 보여주고 있음 (+체리픽이겠지만…) Fig 5에서는 기존 기법에 준하는 Language-based 3D Segmentation 결과를 보여줌.
Ablation Studies
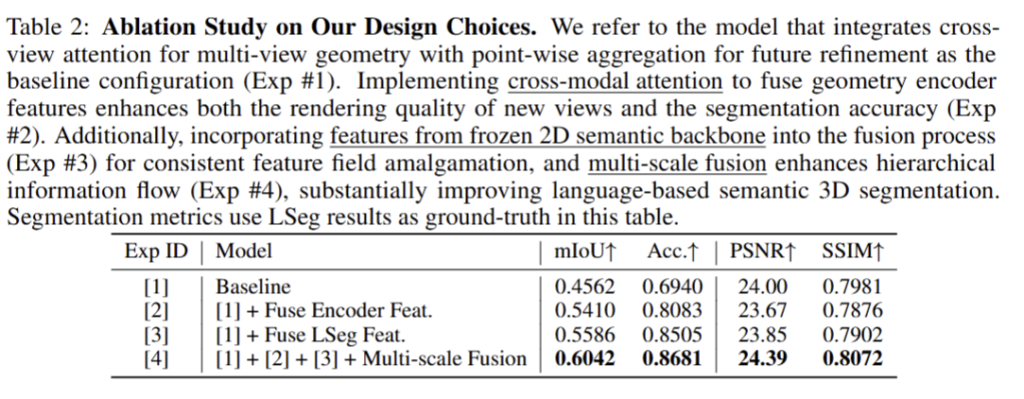
제안하는 모듈을 추가하는 경우에 성능이 향상되는 결과를 보여줌
+ 유의미한 분석 내용은 없는 것 같아 생략
Module Timing.

ScanNet test dataset에 대한 1,000 번 추론한 결과에 대한 속도라고 합니다. 모델 크기 대비 엄청 빠르긴 한데… test 할 때 사용한 자원이 뭔지 알려줬으면 좋았을 텐데 아쉽네요…
Evaluation of Generalizable Methods on New Datasets.

일반화를 보기 위해서 시뮬레이터 데이터인 Replica Dataset을 활용하여 실험을 진행함. Offline SfM이 필요한 기법과 다르게 직접 추론이 가능하며, segmentation, depth, novel view synthesis가 가능함을 보여주며, 성능 또한, 우세하거나 준수한 결과를 보여줌.
논문이 생각보다 기존 연구로 넘기는 설명들이 너무 많아서 사전 지식이 없으면 이해하기 어려운 부분이 있었습니다. 또한, 어떻게 통합했는가를 주 관점으로 보아도… 특별한 스킬이 없었던 것 같아서 아쉬움이 큰 것 같습니다. 더 나아가… novel-view synthesis에 있어 가능한 view range가 어느 정도 인지 설명하는 실험이 있었으면 좋았을텐데 딱히 없는 부분도 아쉬운 포인트인 것 같습니다. 실험에서는 큰 변화 없는 뷰 포인트만 한정지어 정성적 결과를 보여주었기 때문에 더 아쉬움이 큰 것 같습니다.