제가 이번에 리뷰할 논문은 SAM을 3D Part segmentation에 적용한 논문입니다. 11월에 공개된 따끈따끈한 논문으로, 최근 로봇의 grasping 관점에서 인식을 위한 방법론에도 관심을 가지고있다보니, part segmentation에 SAM을 적용한 논문을 리뷰하게 되었습니다. 리뷰 시작하겠습니다.
Abstract
3D part segmentation은 3차원 인식에서 중요하고 어려운 과제로, 최근 text 프롬프트를 활용하는 방법론들이 활용되고 있으나, 이러한 기존 연구들은 확정성과 유연성에 있어 3D 정보와 text가 함께 요구된다는 점에서 한계가 있습니다. 해당 논문에서는 SAMPart3D라는 프레임워크를 제안하므로써 사전정의된 text 프롬프트 없이 3D 객체를 여러 수준에서 세분화할 수 있는 zero-shot 기반의 방법론을 제안합니다. text-agnostic한 vision foundation 모델을 사용하므로써 대규모의 unlabeled 3D dataset으로 확장이 가능하도록 하였으며, scale조건에 따른 다양한 수준의 prat segmentation을 통해 유연성을 확보하였다고 합니다. 이렇게 segmentation된 정보에 대하여 multi-veiw 렌더링 기반의 VLM을 적용하여 의미론적 label을 할당하였다고 합니다. 저자들이 제안한 방법론은 3D part segmentation 라벨이 할당되지 않은 대규모 3D object 데이터 셋인 Objaverse로 확장이 가능하며, 복잡하고 비정형의 형태를 가진 객체를 처리할 수 있다는 장점이 있습니다. 또한 기존의 벤치마크에서 객체의 부품의 다양성과 복잡성 문제를 해결하기 위해 새로운 3D part segmentation 벤치마크를 제공하였으며, 실험을 통해 SAMPart3D가 기존 zero-shot 기반의 방법론보다 성능이 크게 향상되었음을 보였다고 합니다.
Introduction
3D part segmentation은 3차원 인식 task에서 필수적으로, 로봇 조작, 3차원 분석 및 생성, part-level의 편집 등 다양한 분야로 활용이 가능합니다. 이전의 데이터 기반의 fully-supservised 방식들의 경우 closed-set에서는 좋은 성능을 보였으나, part annotation이 된 3D 데이터의 부족으로 다양한 객체를 포괄하지 못하였습니다. 최근 대규모 3D object 데이터 셋이 등장했음에도 불구하고, 대량의 3D 데이터에 대한 part수준의 anntation을 수집하는 것은 시간과 노동력이 너무 많이 소요되므로 2D에서 만큼 segmenatation에서 part segmentation으로 확장이 되지 못하였다고 합니다.
이러한 데이터 부족 상황에서 zero-shot 3D part segmentation을 위해서는 몇가지 어려움을 해결해야 합니다. 먼저, 첫번째 어려움은 3D part annotation 없이 어떻게 open-world 3D object로 일반화 할 수 있는지 입니다. 이를 위해 최근 SAM, GLIP과 같은 사전학습된 2D vision모델을 활용하여, multi-view 렌더링에 적용하여 3D로 투영하는 연구가 진행되었으며, 이러한 방식은 3D 기하학적 단서를 고려하지 못하고 2D의 외관정보만을 이용하며, 이는 두번째 어려움인 unlabeled 3D 형태로부터 3D 사전 정보를 활용하는 방법으로 이어집니다. PartDistill이라는 방법론은 2D-3D 지식 증류를 통해 3D point cloud 특징을 학습하는 방식을 연구하였으나, Objaverse와 같은 대규모 3D 데이터 셋으로 확장할 수 없으며, 사전 정의된 부품 label과 GLIP의 성능에 제약을 받았습니다. 이러한 기존 연구를 기반으로 저자들은 세번째 어려움인 3D part의 모호성을 연구하였다고 합니다. 저자들은 3D part 모호성을 semantics와 granularity(세분성) 두가지 측면에서 바라보았습니다. 먼저 semantics 관점에서 3D part 모호성은 part에 대한 모호한 설명에서 나타나는 문제로, 기존의 GLIP과 같은 vision-language 모델은 part에 대한 프롬프트가 요구되며, 이는 3D part가 언어적으로 명확히 설명되기 어렵기 때문으로 분석하였습니다. 또한 granularity 측면의 모호성은 3D 객체가 다양한 세분화 수준으로 나눠질 수 있다는 점에서 발생합니다. 예를 들자면 사람을 세분화 할 때, 상체-하체로 나눌 수 있으며 더 세분화하여 팔-다리-몸통-머리와 같은 수준으로 더 나눌 수 있다는 것을 의미합니다. 이러한 모호함에 의해 정확한 part segmentation에 어려움이 있다고 저자들은 주장하였습니다.
이러한 어려움을 다루기 위해, SAMPart3D는 확장 가능한 zero-shot 3D part segmentation 프레임워크를 제안합니다. 이는 사전 정의된 프롬프트를 사용하지 않고, 다양한 수준의 세분화가 가능한 방식으로, 기존의 방법론이 사전 정의된 label set과 GLIP에 너무 의존하여 복잡한 대규모 unlabeled 데이터 셋으로의 확장과 3D part의 의미론적 모호성을 해결하기 어려웠음을 주장합니다. 이러한 한계를 보완하고자 GLIP대신 2D에서 3D로 low-level의 text와 독립적인 DINOv2를 적용하여 part label에 대한 의존성을 제거하고 확장 가능성과 유연성을 높였습니다. 또한, segmentation 세분성의 모호함을 다루기 위해 scale-conditioned MLP를 활용하여 세분화 수준을 조절하였습니다. DINOv2와 SAM으로부터 추출한 데이터를 두 학습 stage를 통해 나누고 segmentation된 3D part에 multi-veiw 렌더링을 적용한 뒤 MLLM(Multi-modal Large Language Models)을 통해 semantic dewscription을 할당하여 최종적으로 segmentation을 수행합니다.
해당 논문의 contribution을 정리하면,
- SAMPart3D라는 확장 가능한 zero-shot 기반의 3D part segmentation 프레임워크를 제안하여 사전 정의된 part labels 없이 다양한 수준의 segmentation을 수행
- text와 독립적인 2D-3D distillation을 제안하여 대규모 unlabeled 3D objects로부터 3D 사전지식을 학습하고, semantics와 granularity(세분성) 측면의 모호성을 다룰 수 있다고 합니다. distillation은 2-stasge 방식으로 이루어지며, segmentation의 성능과 학습의 효율 사이의 균형을 고려
- PartObjaverse-Tiny라는 3D part segmentation 데이터셋을 제안. 이는 200개의 복잡한 3D객체에 대하여 세부적인 segmantic&instance level의 part를 제공
- 다양한 실험을 통해 SAMPart3D가 기존 zero-shot 방법론 대비 복잡하고 다양한 3D 객체에 두드러지는 성능을 보임을 입증.
Method
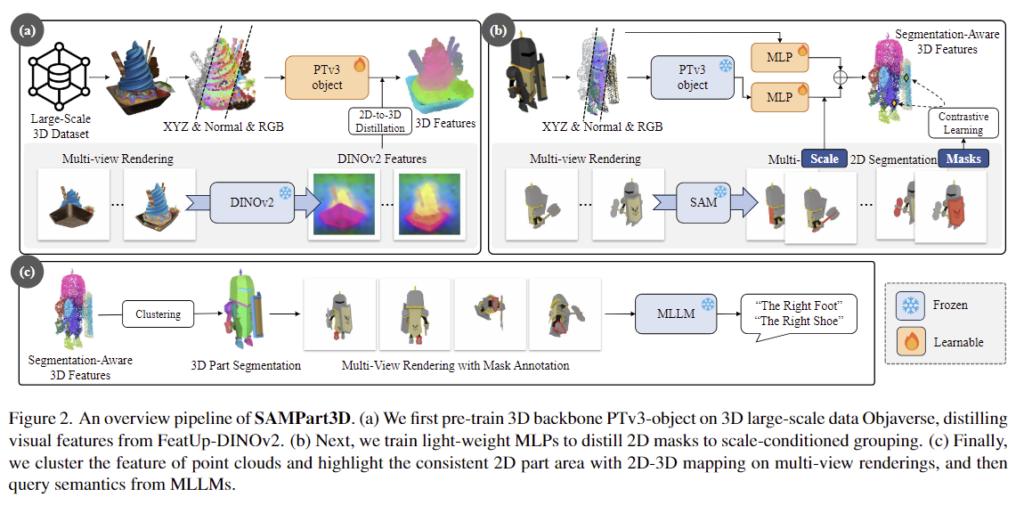
저자들이 제안한 SAMPart3D는 3-stage로 구성됩니다. (a)large-scale pre-training을 통해 대규모 unlabeled 3D object로부터 3D feature를 추출하는 백본을 학습하고, (b)sample-specific fine-tuning을 통해 가벼운 MLP로 scale-conditioned 그룹핑을 학습합니다. 이후 (c)semantic querying을 통해 학습을 하지 않고 semantic label을 할당하게 됩니다. 이러한 전체적인 프레임워크는 위의 Figure 1에서 확인할 수 있으며, 각 파트에 대해 살펴보도록 하겠습니다.
1. Large-scale Pre-training: Distilling 2D Visual Features to 3D Backbone
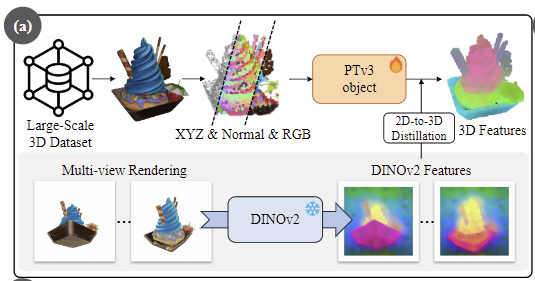
해당 stage는 3D object의 기하학적 단서를 활용하여 대규모 unlabeled 3D object 데이터 셋으로부터 3D feature를 추출하는 백본을 학습하는 것을 목표로 합니다.
<Training Data>
제한된 카테고리의 3D object로 학습하는 기존 방법론과 다르게 저자들은 대규모 3D object 데이터 셋인 Objaverse 데이터 셋을 활용하여 학습을 진행합니다. Objaverse는 다양한 카테고리의 800K 이상의 3D object로 구성되어있어 zero-shot part segmentation을 위한 풍부한 정보를 제공합니다. 또한, 3D point cloud를 위한 3D 백본에 맞추기 위해 3D object의 mesh 표면엣어 무작위로 point를 샘플링하여 입력으로 사용하였다고 합니다.
<Backbone for 3D Feature Extraction>
저자들은 Point Transformer V3를 기반으로 PTv3 object를 설계하였다고 합니다. PTv3는 scene 레벨의 point cloud를 위해 설계된 네트워크로, receptive filed를 넓게 하고 계산량을 줄이기 위해 여러 down-sampling 레이어로 구성된 네트워크입니다. 그러나 scene level이 아니라 object를 잘 표현하기 위해 더 좁은 영역을 고려해야하므로 PTv3의 down-sampling 레이어를 제거하고 transformer 블록을 더 추가하여 디테일한 정보를 유지하였다고 합니다. 추가로, 저자들은 해당 논문을 통해 3D part segmentation을 위한 학습 프레임워크를 제안하는 것이므로, modal-agnostic하여 다른 3D backbone으로 적용이 가능하다고 이야기합니다.
<Distilling 2D Visual Features to 3D Backbone>
unlabeled 3D object로부터 3D feature를 추출하는 백본을 학습하기 위해 사전학습된 2D vision foundation model을 이용합니다. 기존 방법론들은 VLM을 이용하였으며, 이때 part label sets을 텍스트 프롬프트로 활용하였으며, 이러한 방식으로 인해 Objaverse 데이터로 확장이 어려웠습니다.(Objaverse 데이터는 part label set이 없음) 따라서 저자들은 VLM이 아닌, low-level의 text를 사용하지 않는 DINOv2를 supervision으로 사용하였습니다. 그러나 DINOv2의 visual feature는 저해상도이며, detail 정보가 부족하므로 이를 보완하고자 최근의 feature upsampling 방법론인 FeatUp(FeatUp은 feature의해상도를 높이기 위한 연구로, 자세한 내용은 태주님의 이전 X-review를 참고해주세요!)을 적용하여 DINOv2 feature를 보강하였다고 합니다.
구체적인 학습 과정은 다음과 같습니다. point cloud X \in \mathbb{R}^{N⨉3}로 표현되는 3D object를 PTv3-object 백본에 입력하여 3D feature F_{3D} \in \mathbb{R}^{N⨉C}(C는 384차원으로 DINOv2의 feature 차원과 동일하게 설정)를 구합니다. 그 다음 학습에 사용할 2D visual feature를 구하기 위해 객체를 K개의 view로 렌더링하여 DINOv2 features를 추출합니다. 3D point cloud와 2D 픽셀의 대응 관계를 고려하여 2D feature F_{2D} \in \mathbb{R}^{N⨉C}를 얻게 됩니다. 이때, occlusion에 의해 대응되는 2D feature가 없을 경우에는 3D feature를 그대로 이용하며, 그 외의 3D feature에 대해서는 렌더링된 모든 K view의 2D feature의 평균을 이용하였다고 합니다.
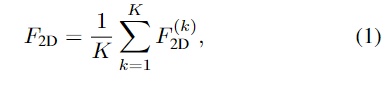
- F_{2D}^{(k)}: k번째 view에서의 2D feature
2D visual feature를 3D 백본으로 전달하기 위해 MSE loss를 적용하여 3D 백본을 학습합니다.
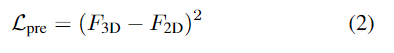
2. Sample-specific Fine-tuning: Distilling 2D Masks for Multi-granularity Segmentation
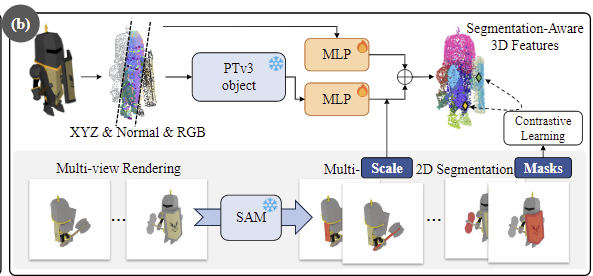
3D 백본을 통해 추출한 3D feature는 Part Segmentation을 위해 SAM에 2D segmentation mask와 함께 사용됩니다. 또한, 세분화 수준을 제어하기 위해 scale-conditioned MLP를 도입하여 scale 값을 조절할 수 있도록 합니다.
<Long Skip Connection>
사전학습된 백본으로부터 풍부한 3D feature를 추출할 수 있으나 네트워크의 깊이가 깊어 point cloud의 low-level정보(point 수준의 정보)을 잃게 됩니다. 따라서 MLP에 long skip connection을 적용하여 point cloud의 각 point에 면(face)의 normal value를 구한 뒤, 이 normal value를 RGB와 좌표 정보와 함께 long skip connection 모듈의 입력으로 하여 3D 백본으로 구한 feature에 추가하여 low-level의 특징을 보완합니다. (간단하게 3차원 좌표 정보와 normal 값, RGB값을 단순한 MLP를 통과시킨 뒤 3D feature에 추가한 것으로 이해하시면 될 것 같습니다.)
<Scale-conditioned Grouping>
다음은 grouping을 위한 파트로, 두 포인트를 sampling한 뒤, contrastive learning을 통해 동일 마스크에 속하는 point들은 가까워지고 다른 mask에 속하는 point들을 멀어지도록 하는 것 입니다. 구체적으로는 다음 순서로 진행됩니다.
먼저 3D object에 대한 multi-view 이미지에 SAM을 적용하여 2D masks를 생성합니다. 각 mask에 대하여 대응되는 point와 3D scale \sigma를 구합니다.
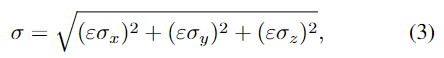
- \sigma_x, \sigma_y, \sigma_z: x,y,z 좌표의 표준편차
- \varepsilon: scaling factor로 저자들은 10으로 설정하였다고 합니다. (그 이유나 별도의 실험은 해당 논문에서 확인할 수 없네요..)
그 다음, contrastive learning을 위해 렌더링된 이미지에서 확인 가능한 두 3D point p_i, p_j를 샘플링하여 아래의 식으로 feature를 구합니다.
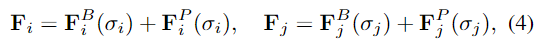
- F^B(\sigma): PTv3-object 백본에서 구한 feature
- F^P(\sigma): positional embedding
그 다음 contrastive learning을 위해 아래의 loss 식을 적용합니다.
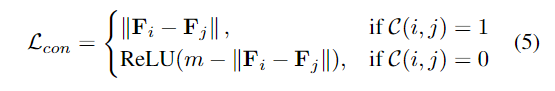
- \mathcal{C}(i,j): (i,j)가 동일 마스크인지를 나타내는 이진 함수로, 동일 마스크에 포함될 경우 1, 아닐 경우 0
- m: margin 값
위의 방식으로 scale-conditioned MLP를 학습하면 scale에 따라 세분화된 3D point cloud의 feature 얻을 수 있게 됩니다. 이 feature에 HDBSCAN과 같은 clustering 알고리즘을 적용하여 3D point cloud에 대한 part segmentation결과를 얻게 됩니다.
3. Semantic Querying with MLLMs

다음은 segmentation이 된 3D point cloud에 대하여 semantic label을 할당하는 과정입니다. 여기서는 Multimodal Large Language Models(MLLMs, 해당 논문은 GPT-4o를 사용합니다)를 사용하며, 3D-to-2D mapping을 통해 3D part에 해당하는 2D 영역을 알 수 있으며, multi-view rendering을 통해 해당 영역에 대하여 highlighting을 합니다.(코드를 확인해보았을 때, 정말 해당 영역에 대한 빨간색 테두리를 표시하여 이미지로 저장하는 과정입니다,) 그 다음, multi-view 이미지들 중 해당 영역이 가장 큰 이미지를 선택하여 MLLM에 입력하여 semantic label을 얻게 됩니다.(해당 과정에 대해 김태주 연구원님이 어떤 프롬프트가 들어가는 지 의문을 제기하셨는데, 실제 GPT-4o에 하이라이팅한 이미지를 넣어보니 원하는 형태의 라벨을 얻을 수 없었고, 어떤 형태의 프롬프트를 입력으로 사용하는지는 코드나 논문에서 확인할 수 없게 되어있었습니다.)
Experiments
PartObjaverse-Tiny
기존 part segmentation 데이터 셋은 제한적인 카테고리로 이루어져 있으며, 불완전한 part annotation이 되어있어 임의의 객체와 part에 대한 평가에 부적절하다고 저자들은 주장하였습니다. 따라서 3D object 데이터 셋인 Objaverse의 하위 집합에 annotation을 하여 PartObjaverse-Tiny라는 데이터 셋을 제안하였습니다. 이 데이터 셋은 200개의 객체에 대하여 세분화된 annotation이 된 데이터로, 먼저 200개의 object를 크개 8개의 major 카테고리로 나눕니다.: Human-Shape (29), Animals (23), Daily-Used (25), Buildings&&Outdoor (25), Transportations (38), Plants (18), Food (8) and Elec- tronics (34). 각 major 카테고리는 하위 객체 카테고리가 포함됩니다.(e.g. Transportations -> cars/motorcycles/airplanes 등) 각 object에 대해 part 수준의 annotation을 수행하였으며, 데이터 예시는 아래의 Figure 3에서 확인하실 수 있습니다. 또한 학습에 사용한 GPU는 A800 8장으로 7일동안 학습을 진행하였다고 합니다.

Results
1. Comparison with Existing Methods

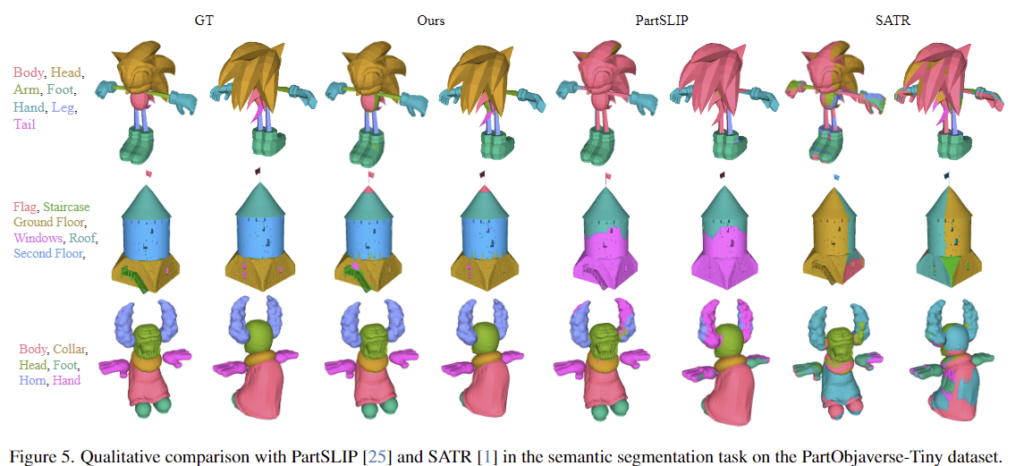
Table 1은 zero-shot semantic segmentation 성능을 리포팅한것으로 이때, GLIP을 사용하는 PartSLIP과 SATR의 경우 예측 값에서 blank 값이 많이 나오는 문제가 있어 kNN을 적용하여 가장 가까운 라벨에 할당하였다고 합니다. 전체적으로 저자들의 방식이 가장 좋은 성능을 보이고 있습니다.
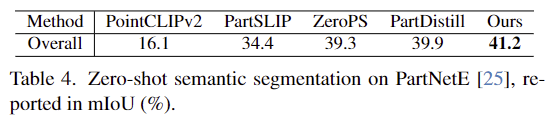
Table 4는 기존의 데이터 셋인 PartNetE에 대한 성능을 나타낸 것으로, 저자들의 방식은 open-set을 대상으로 하므로, PartNetE에 포함되지 않는 클래스들은 “others”로 할당하여 평가를 수행하였다고 합니다. 해당 데이터 셋에서도 저자들의 방식이 가장 좋은 성능을 보이고 있습니다.



Table 2는 class-agnostic part segmentation 성능, Table 3은 instance segmentation 성능을 나타낸 것으로 두 테스크에서도 저자들의 방식이 가장 좋은 성능을 보이고 있습니다. 또한, Figure 4는 여러 scale 조건에 따른 part segmentation 결과로, scale factor가 달라짐에 따라 여러 세분화가 가능하다는 것이 인상적입니다.
2. Ablation Analysis

Table 5는 SAMPart3D에 대한 ablation study 결과 입니다.
- 1행의 결과는 PTv3-object 백본을 사전학습하지 않을 경우에 대한 결과로, 전반적으로 성능이 저하되는 결과를 확인할 수 있습니다.
- 2행의 결과는 PTv3를 그대로 이용하는 경우로, 저자들이 scene이 아닌 object에 맞도록 수정하는 과정을 통해 모델의 encoding 능력을 개선하였음을 어필합니다.
- 3행은 point cloud의 특징을 활용하기 위해 long skip connection을 적용한 것의 효과를 확인하기 위한 실험으로, low한 정보를 고려하기 힘들어 성능이 저하된다고 주장합니다.
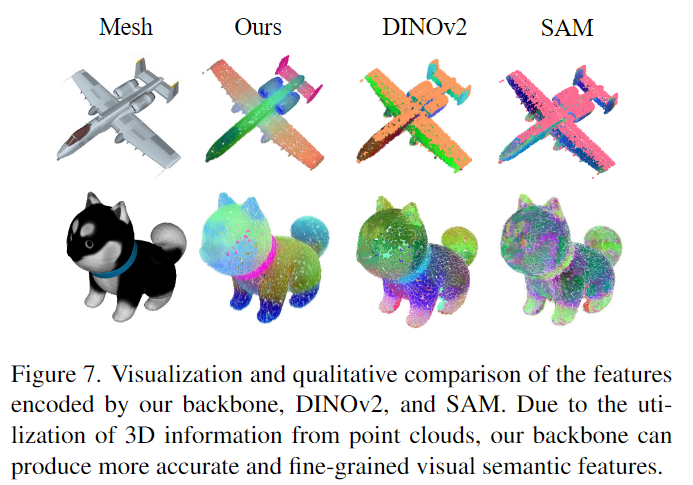
- 위의 Figure 7은 PTv3-object, DINOv2, SAM의 인코딩 능력을 시각화한 것으로, SAM만으로는 part 정보를 학습하기 어렵다는 것을 보여준 것이 흥미로웠습니다. 이러한 이유로 저자들은 DINOv2 feature를 학습하도록 백본을 사전학습하였다고 합니다.
Application
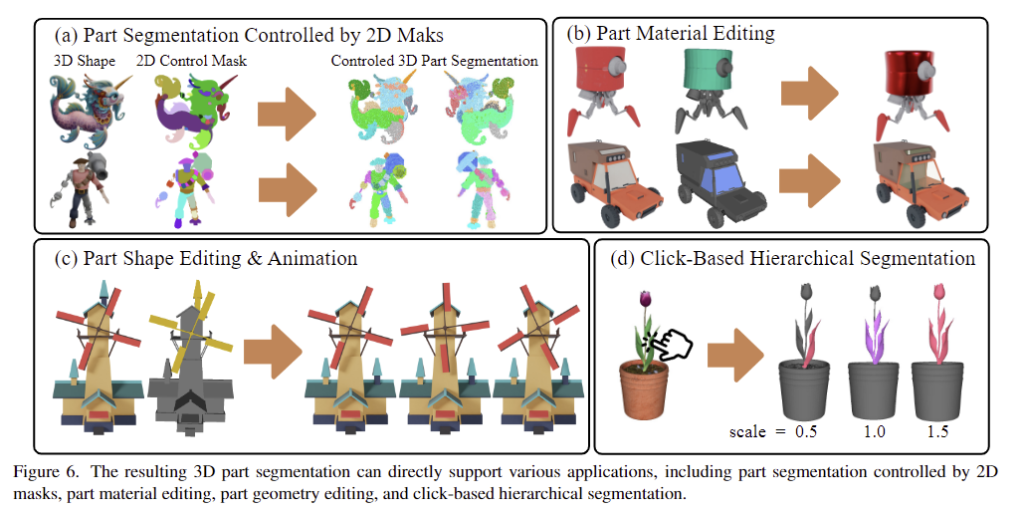
마지막으로 Figure 6은 여러 application에 적용한 결과입니다.
좋은 논문 리뷰 감사합니다.
Q1. 해당 논문에서 제안한 기법은 프롬프트된 SAM의 지식을 전이 받는 수준이라고 생각이 드는데… 맞나요?
Q2. Point Transformer v3는 기개발된 모델 같습니다. 그럼 저자가 제안한 건 파이프라인이라는 생각이 드는데 맞을까요? 그리고 PTv3의 초기화는 어떻게 진행되었는지 궁금합니다.
Q3. GPU와 추론 시간에 대해서 공유 부탁합니다.
질문 감사합니다.
A1. 넵 part segmentation을 수행하는 부분은 결국 SAM에 의존적인 것으로 이해됩니다. 다만 scale-condition을 통해 세분화의 수준을 결정할 수 있다는 점을 통해 어느정도 확장 SAM을 뛰어넘을 수 있는 이해력을 확보할 수 있다고 이해할 수 있지 않을까요??
A2. 넵 대부분이 기존의 방법론들을 가져와 적용한 것으로 보입니다. PTv3의 구조를 조금 변형한 정도의 설계가 포함되어있으며, 컨트리뷰션 측면에서는 전체적인 학습 과정과 그를 통해 다양한 수준의 세분화가 가능한 성능 크게 개선된 Part Segmentation이 가능하다는 것에 집중한 것 같습니다. PTv3는 scratch level로 SCANet등 scene level의 3D 데이터로 학습이 된 것으로 보입니다.
A3. 7일동안 8장의 A800를 이용하여 학습을 진행하였다고 합니다. 해당 내용은 리뷰에 업데이트 해두도록 하겠습니다.
안녕하세요 승현님, 좋은 리뷰 감사합니다.
1. 3D part segmentation을 위한 학습 프레임워크를 제안하는 것이 modal-agnostic하여 다른 3D backbone으로 적용될 수 있는 이유가 궁금합니다!
2. occlusion에 의해 대응되는 2D feature가 없을 경우에 3d feature를 그대로 이용했다는 것이 무슨 뜻인가요?!
3. k개 multi-view 렌더링에는 어떤 기법을 사용하나요?
4. Long Skip Connection에서 “point cloud의 각 point에 면(face)의 normal value”를 구하는 것은 어떻게 하나요..?
+) Long Skip Connection을 수행하는 이유가 pc의 low-level 특징을 3D백본에서 많이 잃어버려서 이를 보완하고자 하는 것으로 이해했는데, 원래 pc가 가진 low-level 특징이라는 것은 주로 normal 정보를 가지고 있는 것인가요?!
5. 3.Semantic Querying with MLLMs에서 저도 MLLM의 입력 부분에서 딱 작성해주신 대로의 의문이 들었습니다… 사실 프롬프트 지시를 명확하게 사전 세팅해놓지 않았다면 매 쿼리시마다 굉장히 일관적이지 않은 label이 나올테고, 할루시네이션 현상도 무시할 수 없을 텐데 말이죠.. MLLM으로 쓰인 GPT4o의 temperature 값 세팅도 몇인 지 궁금하고,, 혹여나,,, 코드와 프롬프트가 공개된다면,, 공유 부탁드립니다.
질문 감사합니다.
1. 먼저, 해당 방법론은 여러 기존 방법론을 적용하여 하나의 프레임워크를 구성한 논문으로, 백본을 다른 모델로 변경하여도 적용이 가능하다는 점에서 model-agnostic하다고 표현하였습니다.
2. occlusion이 발생하여 3D point에 대응되는 2D 픽셀을 구하기 어려운 경우에는, 2D feature를 활용하는 게 아닌, 3D feature를 그대로 사용하였다는 것 입니다.
3. k개의 multi-view 렌더링 과정은 별도의 기법을 활용하기보다는 K개의 균일하게 샘플링된 view에 대한 2D 이미지를 구하는 과정입니다.
4. point들의 low-level 정보를 활용하고자 하는것이 맞으며, point들의 표면 정보를 활용하는 것으로 이해하시면 좋을 것 같습니다.
5. 저도 코드를 확인해봤는데.. 아직 정보가 없었습니다… 이 논문이 리비전도 거치고 수정이 되면 다시 공개가 될 수 있지 않을까요..? 혹은 나중에 문의 메일을 보내보는 것 도 좋을 것 같습니다..하하 아무튼 넵 확인하게 되면 공유하도록 하겠습니다.
안녕하세요 승현님 좋은 리뷰 감사합니다.
3D part segmentation 연구를 처음이라 헷갈리는 부분이 많네요. 해당 연구는 SAM의 2D mask 정보를 통해 3D point를 샘플링하는 연구라고 이해했습니다. 결국 2D mask를 그루핑하는 과정이 제일 중요한 부분이라 생각이 되는데 contrastive learning을 위해 각 point들이 같은 마스크에 해당하는지, 해당하지 않는 지를 어떻게 구하는 것인지 궁금합니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
(a) 과정에서 사용하는 렌더링 이미지는 objaverse라는 데이터셋에서 제공하는 멀티뷰 이미지인건가요 ??
만약에 제공하는게 아니라면 3D 물체에 대한 렌더링 이미지를 어떻게 구축한 것인지 궁금합니다 . .
그리고 occlusion에 의해 대응되는 2D feature가 없다면 3D feature를 그대로 이용한다고 하셨는데, 이 feature는 결국에는 노이즈로 작용할거라 생각했는데 실험 결과 성능이 정성적으로만 봐도 굉장히 좋아서 .. 이런 occlusion에 대한 고려는 따로 없었을까요 ??
감사합니다.
안녕하세요 승현님 리뷰 감사합니다.
scale-conditioned MLP를 학습하면 scale에 따라 세분화된 3D point cloud의 feature 얻을 수 있다는 것이 포인트 클라우드가 있으면 세밀한 부분을 보고싶을 때 세밀한 부분을 보고, 반대의 경우에는 더 큰 범위에서 볼 수 있다는 것인가요?
또 occlusion에 의해 대응되는 2D feature가 없을 경우에는 3D feature를 그대로 이용한다고 했는데 k view의 평균을 이용한다는게 어떤 의미가 있는지 궁금합니다!!
질문 감사합니다.
먼저, 첫 번째 질문은 이야기하신 것처럼 어느정도 세밀한 수준에서 세분화를 진행할지를 조절하는 것 입니다.
가려진 영역에 대한 정보를 알 수 없기 때문에, 다른 view에서 해당 영역의 정보를 참고하는 것으로, 하나의 view가 아닌 여러 view에 나타나는 객체의 정보를 평균내어 사용하므로써, outlier를 줄이는고 신뢰도를 높일 수 있을 것이라 생각합니다.