안녕하세요. 오늘 리뷰할 논문은 NIPS2014에 게재된 Temporal Sentence Grounding(TSG) 논문으로 이름만 다를 뿐 Video Moment Retrieval과 같은 연구입니다.
Introduction
TSG는 Temporal Sentence Grounding 연구로 영상 내 자연어 쿼리에 매칭되는 특정 video segment(비디오의 단위로 짧은 단위의 영상을 의미함)을 반환하는 task를 얘기합니다. 여기서 말하는 자연어 쿼리는 특정 클래스 혹은 상황뿐만 아니라 자유 형태의 자연어 쿼리를 포함합니다. 따라서, TSG 연구들은 보통 Video Moment Retrieval(VMR)연구와 같은 연구를 의미합니다.
저자가 이번 연구에서 지적하는 부분은 바로 기존의 연구들은 비디오 내 쿼리와 연관 있는 구간이 있다는 것을 전제로 진행되기 때문에 실제 현실에 적용하기 어렵다는 점입니다. 따라서, 저자는 비디오와 관련이 없는 쿼리가 주어진다면, 비디오 내 쿼리에 해당하는 구간이 없다고 입력자에게 알려야한다고 말하고 있습니다. 따라서 저자는 이와 같은 motivation으로 Temporal Sentence Grounding with Relevance Feedback(TSG-RF)라는 task를 제안합니다. 최근에 비슷한 문제정의의 연구들이 많이 생기고 있네요. Relevance Feedback이라는 이름은 모델이 쿼리가 비디오와 연관(relevance)있는지를 피드백한다는 취지에서 이렇게 네이밍을 한 것 같습니다. 저자는 Relation-aware Temporal Sentence Grounding(RaTSG) 모델을 제안하여 TSG-RF를 해결하고자합니다. 추가로 저자는 기존에 사용되던 데이터셋을 직접 수정하여 TSG-RF를 수행할 수 있는 데이터셋으로 변형하여 벤치마킹합니다. 일반적인 TSG과정에서 쿼리가 비디오와 관련이 있는지 없는지를 판단하는 부분이 추가되어 있다고 생각하시면 될것 같습니다.

위 Figure 1은 저자가 제안하는 TSG-RF를 시각화하여 보여주는 figure로 기존 연구들은 무조건 하나 이상의 쿼리와 연관 있는 구간을 반환하는 반면 저자가 제안하는 RaTSG는 만약 자연어 쿼리가 비디오와 연관이 없다면 구간을 반환하지 않고 연관성이 없다고 출력합니다. 이는 저자는 real world에 실제로 TSG를 수행하기 위해서는 필수적인 연구로 앞으로의 TSG 연구들은 모두 쿼리와 비디오의 연관성을 우선적으로 고려해야한다고 강조합니다.
나이브한 방법으로 위의 문제를 해결하기 위해서는 먼저 비디오와 쿼리의 연관성을 파악하는 1stage와 연관성이 있다면 구간을 반환하는 2stage로 나누어 수행할 수 있지만, 저자는 2stage approach는 불필요한 반복적인(redundant) 연산을 필요로하기에 불필요한 작업이라는 것을 얘기하며 저자가 제안하는 RaTSG는 end-to-end로 학습되고 수행된다는 점을 강조합니다. 저자는 추가로 fine-grained와 coarse-grained level 모두 즉, multi-granularities에서의 쿼리 비디오 연관성을 구하기 위하여 multiple instance learning의 아이디어를 가져와 전체 영상을 bag, 각각의 프레임을 instance로 여겨 학습하고 global video-level semantics와 full query text의 연관성을 구합니다. 자세한 방법론은 Method 부분에서 설명하겠습니다. 마지막으로 저자는 TSG-RF의 올바른 평가를 위해 기존의 데이터셋을 살짝 변형하여 효과적으로 TSG-RF를 평가합니다.
이에 따른 저자의 Contribution은 다음과 같습니다.
- 저자는 실제 상황에 더 적합한 TSG를 위해 새로운 task인 Temporal Sentence Grounding with Relevance Feedback(TSG-RF)를 제안합니다.
- 저자는 TSG-RF에 적합한 프레임워크인 Relation-aware Temporal Sentence Grounding(RaTSG)를 제안합니다. Multi-granularity relevance discriminator모듈을 통해 fine-grained level의 query와 video를 매칭하고 relation-aware segment grounding 모듈을 통해 coarse-grained level의 query와 video를 매칭합니다.
- TSG-RF 작업의 평가를 위해 일반적으로 사용되는 TSG의 데이터셋을 재구성하여 TSG-RF에 적합한 데이터셋으로 변형한 후에 평가를 진행하는 것으로 제안하는 모델의 성능을 입증합니다.
Method
먼저, TSG-RF task에 대해 간략하게 설명하겠습니다. video V = [v_1, v_2, ..., v_n]와 query Q = [q_1, q_2, ..., q_m]를 입력으로 받아, query와 관련된 내용이 실제로 video 내에 존재하는 지를 피드백 받습니다(Relevance Feedback). 추가적으로 만약에 query가 video와 관련된 내용이 존재한다면 query과 semantically 연관이 있는 정확한 구간(start, end timestamps)을 반환합니다. 만약에 query와 관련된 내용이 존재하지 않는 다면 매칭 결과를 무시하게 됩니다. 저자는 TSG-RF를 관련없는 구간에 대한 non-existence signal를 생성해야하는 도전적인 task라는 것을 강조합니다.
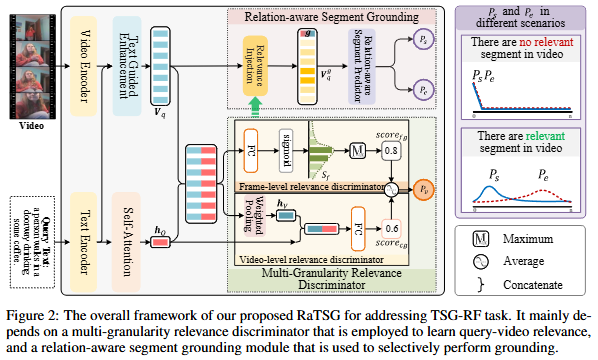
저자가 제안하는 전체적인 프레임워크는 Figure 2에서 설명하고 있습니다. 입력 video V와 query Q는 attention기반의 메커니즘을 통해 인코딩되고 이후 multi-granularity relevance discriminator는 frame 및 segment(여러 frame 묶음으로 짧은 video의 한 단위) 수준과 전체 video 수준에서 query가 video와 얼마나 유사한 지에 대한 relevance 점수 P_r를 생성합니다. relation-aware segment grounding에서는 멀티모달로 강화된 video feature를 사용하여 query에 관련된 구간의 start timestamp P_s와 end timestamp P_e를 생성합니다. 마지막으로 위 점수들을 기반으로 최종 예측을 수행하게 됩니다.
Preprocessing
저자는 I3D를 video feature extractor로 사용합니다. 그리고 GloVe를 text feature extractor로 사용합니다. video feature과 text feature 모두 FC layer를 통해 같은 임베딩 공간에 매핑합니다. 그 후에 text의 feature는 self-attention을 통해 강화되고 sentence level의 query feautre h_Q를 얻습니다. video feature의 경우 query의 정보를 담기 위해 cross-attention을 진행하는 것으로 video feature를 강화하여 결과적으로 query feature로 강화된 video feature V_q를 생성합니다. 최종적으로 V_q와 h_Q를 concat하는 것으로 contextual mulit-modal representatino V'_q를 생성합니다.
Multi-Granularity Relevance Discriminator
query-video 쌍에 대한 매핑 결과를 얻기 전에 저자는 먼저 query와 video의 의미적 관련성을 구합니다. 따라서 fine-grained level의 frame-level relevance discriminator와 coarse-grained level의 video-level relevance discriminator를 사용해 의미적 관련성을 구하게 됩니다.
먼저 Frame-level relevance discriminator는 Preprocessing에서 최종 생성된 contextual multi-modal representation V'_q를 FC layer를 통해 점수를 예측합니다. 그 후 sigmoid 함수를 활용해 0~1 사이로 매핑해 foreground frame prediction S_f를 얻습니다. 수식으로 표현하면 다음과 같습니다. S_f = \mathrm{sigmoid}(\mathrm{FC}(V'_q)) \in \mathbb{R}. loss는 BCE를 사용합니다. 추가로 frame-level에서 text와 video의 관련성을 세분화하기 위해 multiple instance learning의 개념을 도입합니다. 심플하게 전체 video는 bag로, 각각의 frame은 instance로 여겨 학습을 하는 것이며, max-pooling을 통해 query-video discrimination score인 \mathrm{score}_{f_g}를 얻습니다. 수식으로 표현하면 다음과 같습니다. \mathrm{score}_{fg} = \mathrm{max}(S_f). 저자가 말을 좀 있어보이게 서술했지만, 심플하게 “하나의 frame이라도 query에 연관된 구간이 있으면 연관성이 있다고 판단한다”의 관점에서 maxpooling을 사용했습니다.
다음으로 Video-level relevance discriminator는 contextual multi-modal representation V'_q를 frame-wise weighted sum operation을 통해 h_v \in \mathbb{R}^d를 얻습니다. 이 과정에서 각 frame에 frame-level similarity score(위에서 구한 sigmoid함수 이후의 점수)를 가중치로 할당합니다. 그 후 softmax 연산을 통해 각 프레임의 점수를 가중치에 따라 합이 1이 되도록 정규화 한 후에 preprocessing에서 구한 sentence-level의 h_Q를 합한 후 유사도 점수를 구합니다. frame-level과 마찬가지로 FC layer를 통해 연산됩니다. 수식으로 표현하면 다음과 같습니다. \mathrm{score}_{eg} = \sigma(\mathrm{FC}(g)). 이렇게 해서 얻은 점수는 전체 video와의 관련성을 의미하게됩니다. 마찬가지로 BCE loss를 통해 학습됩니다.
마지막으로 저자는 최종 multi-level relevance prediction score P_v = (\mathrm{score}_{fg} + \mathrm{score}_{eg}) / 2를 통해 얻습니다. 위 P_v 점수는 query와 video과 연관성이 있는 지를 판단하는 데에 사용됩니다.
Relation-Aware Segment Grounding
P_v를 고려하여 저자는 video 내 관련있는 구간이 존재하는 지를 판단합니다.또한 query가 video와 연관이 있는 지를 명시적으로 학습시키기 위하여 저자는 임의로 0번 인덱스를 추가하여 query가 video와 연관이 없다면 0번 인덱스에 매핑되도록 유도합니다. 즉, query가 video와 연관이 없다면 start timestamp와 end timestamp가 [0,0]으로 매핑되고, 만약 실제 연관 있는 구간이 존재한다면, [a^s,a^e], (1 \le e^s \le e^e \le 1)로 매핑됩니다.
구간 예측은 두개의 unidirectional LSTM과 두개의 feed-forward layer를 사용하여 start와 end timestamps boundary를 예측합니다. 손실함수는 다음과 같습니다.
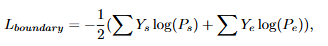
추가 디테일로는 학습 할 때에 multi-level relevance discriminator를 통해 얻은 P_v를 thresholding하는 것으로 학습 시에 관련이 있는 query인지 아닌지를 판단합니다.
Experiments
저자는 기존 TSG에서 많이 활용되는 데이터셋인 Charades-STA 데이터셋과 ActivityNet Captions 데이터셋을 TSG-RF에 활용할 수 있도록 가공을 한 후에 성능을 검증합니다.
평가지표로는 R{n}@{m}과 mIoU를 사용합니다. R{n}@{m}는 상위 n개의 segment에서 IoU가 m 이상인 instance를 포함하는 비율을 의미하고 mIoU는 IoU값의 평균을 의미합니다.
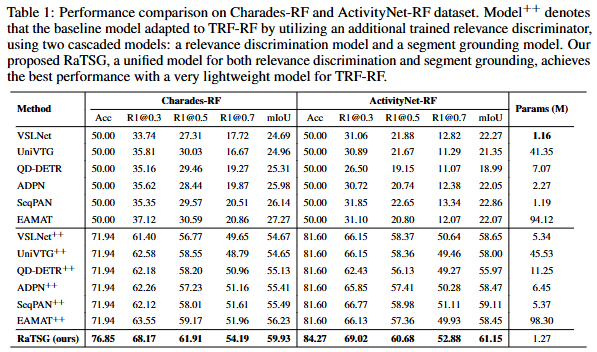
++는 저자의 기존 TSG 모델에 relevance discriminator를 추가하여 저자가 직접 실험한 성능을 의미합니다. Acc는 foreground와 background 이진분류의 정확도 입니다. 기존의 모델의 정확도는 정확하게 50%로 저자가 데이터셋을 새로 구성할 때 foreground와 background를 반반 섞어서 구성한 것을 확인할 수 있습니다. 눈 여겨볼만한 점은 굉장히 적은 파라미터 수로도 기존의 방법론을 뛰어넘는 성능을 보여준다는 점입니다. 첨언하자면, 사실 기존 연구들 중에 성능표에는 존재하지 않지만, EaTR과 같은 연구의 성능이 Charades-STA와 ActivityNet에서의 성능이 굉장히 높은 것으로 알고 있는데, 성능표에 추가하지 않은 점이 약간 아쉽네요. 아무래도 성능이 약간 미치지 못했거나 프레임워크상 relevance discriminator를 부착할 수 없는 구조이기에 실험하지 못한것으로 추정됩니다(사실 EaTR연구의 경우에는 discriminator를 부착할 수 있는 구조이긴 합니다(?)). 아무튼 적은 파라미터로도 충분히 좋은 성능을 보여준다는 점에서 눈여겨볼만한 연구이기는 합니다.
Ablation Study
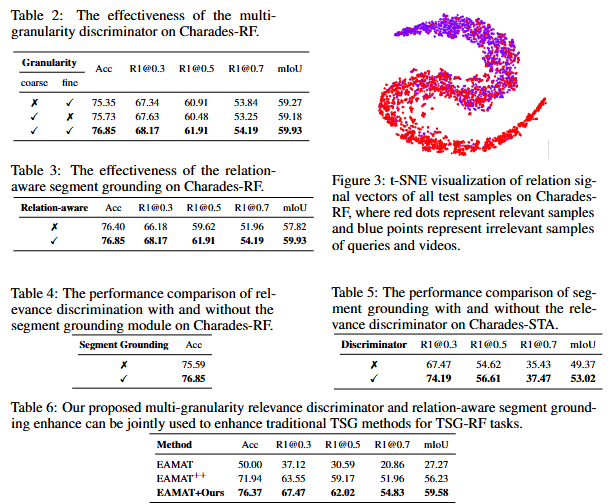
ablation study는 저자가 fine-grained와 coarse-grained level을 모두 잘 다루는 것을 보여주는 Table 2, relation-aware segment grounding 모듈의 성능을 보여주는 Table 3로 구성되어 있습니다. 추가로 저자는 데이터셋 내 query의 분포를 시각화해서 보여주고 있습니다(Figure 3). Table 4,5는 segment grounding와 relevance discriminator의 유무에 따른 Charades-RF 데이터셋(저자가 변형한 Charades-STA데이터셋)에서의 성능을 보여줍니다. 결국 저자가 제안하는 모듈들이 유의미하게 효과를 보고 있다는 보여주고 있습니다. Table 6이 약간 애매한데 다른 baseline 모델에 자신들의 relevance discriminator를 통한 성능 개선이 얼마나 많이 되는 지를 보여주는 지표인데, 자신들이 제안하는 데이터셋에 자신들이 제안하는 모듈을 통해 성능을 개선한거니 당연히 성능이 오른 것이 아닐까 싶네요. 추가로 +Ours를 통해 성능을 추가로 올릴 수 있었으니 Experiments의 Table1 에서도 +Ours를 통한 다른 베이스라인과의 성능 비교도 가능했을 것으로 보이는데 ablation에서만 맛보기?로 성능을 보여주는게 살짝 아쉽습니다. baseline모델 중에 제일 성능이 좋았던 모델의 성능을 보여준 것이니 자신의 모델과도 비교해도 괜찮았을 것 같은데 분량을 넘어가게되서 그런건지는 모르겠지만 살짝 아쉽습니다(?). ablation study는 결국 특별한 점은 없고 자신의 모듈을 하나 붙일 때마다 성능이 늘어난다 정도를 보여주는 것 같습니다.

정성적 결과입니다. 본인 방법론의 한계를 보여주는 figure도 추가했네요(Figure 5). 첫번째 예시는 모델이 재채기 동작을 식별하는 데에 있어 중요한 정보인 오디오 정보가 부족하여 relevance feedback을 제대로할 수 없었음을 지적하고 있고 두번째 예시에서는 모델이 동작의 시간적 순서를 잘못 해석하여 닫는 동작을 여는 동작으로 잘못 판단하는 것을 보여주고 있습니다. 저자는 이러한 한계점이 현재에는 존재하지만, 오디오의 특징을 활용하는 것과 temporal 모델링을 통해 이러한 한계점을 완화할 수 있을 것이라고 설득하고 있습니다.
리뷰를 마치며, NIPS에 개제된 논문임에도 불구하고 굉장히 심플한 방법론으로 문제를 해결하고 있습니다. 사실 문제 정의 또한 기존에 아예 없었던 문제 정의는 아니지만 왜 문제인지에 대한 자세한 서술과 이를 해결하기 위한 방법을 제안하며 이전 연구와의 차별점을 두고 있습니다. 다시 한번 문제 정의와 리뷰어들을 설득하는 라이팅 능력(?)(+주장을 뒷받침하는 실험)이 중요하다는 것을 느끼게 되네요.
감사합니다.