안녕하세요, 오늘의 X-Review는 Video-Text 간 상호작용을 극대화하는 사전학습 방식에 관련된 22년도 CVPR 논문 <Bridging Video-text Retrieval with Multiple Choice Questions>입니다. 효율성과 정확도 모두 가져가고자하는 사전학습 방식을 제안하였으며, V-T 간 사전학습의 표현력을 검증하고자 Video-Text Retrieval 성능을 측정한 논문입니다. 홍콩대학교와 텐센트의 협업으로 나온 연구 결과네요.


1. Introduction
비디오-텍스트 간 상호작용을 잘 파악해야하는 여러가지 task들이 있습니다. 가장 대표적인 Video-text retrieval은 비디오(or텍스트)를 쿼리로 던져 데이터베이스 내 가장 유사한 텍스트(or비디오)를 찾아내야 합니다. 또한 원래는 비디오 단일 모달만을 다루는 Video action recognition이 Zero-shot 세팅으로 내려온다면 텍스트를 활용해 action 클래스 단어 자체를 이해함으로써 바로 분류 및 평가가 가능해지기도 합니다. 또한 좀 더 깊게 들어가면 제가 살펴보고있는 Video moment retrieval도 두 모달리티 간 깊은 상호작용을 바탕으로 이루어집니다.
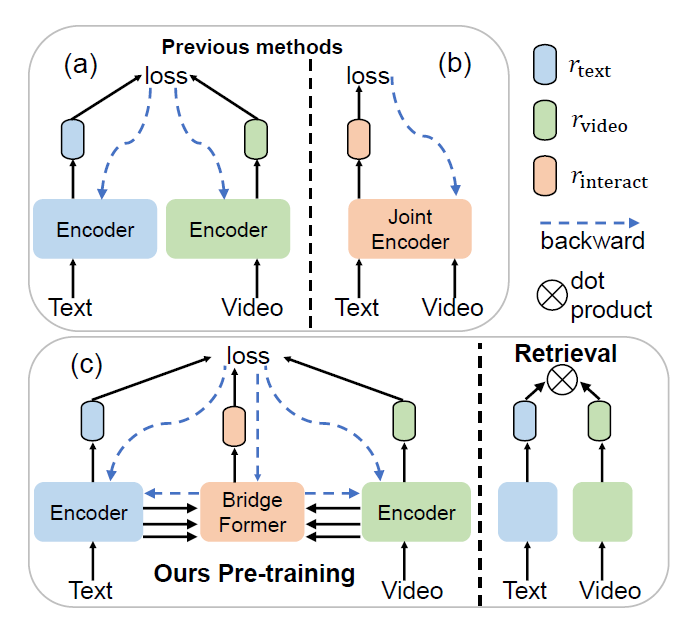
비디오-텍스트 사전학습 연구는 이러한 흐름 속에서 활발히 이루어지고 있는데, 대략 두 갈래로 나눠볼 수 있다고 합니다. 이는 위 그림 2에서 볼 수 있는데, 논문의 넘버링을 따라가다보니 리뷰의 첫 그림이지만 그림 2로 표기한 점 양해 부탁드립니다. 첫 번째는 그림 2-(a)의 Dual-encoder 방식으로, 각 모달리티의 인코더를 따로 두고 각각이 단일 level의 모달별 feature를 내뱉게 됩니다. 이후 두 모달의 feature를 aggregate하여 유사도를 구하고 실제 정답과 비교하여 학습하는 방식입니다. 이는 두 모달 사이 local한 정보를 주고받지 않기에 연산량이 적어 효율적이지만, 말 그대로 local한 정보를 주고받지 않으니 디테일한 정보를 놓쳐 정확도는 조금 떨어집니다. 두 번째로 그림 2-(b)의 Joint-encoder 방식은 두 모달 처리에 단일 인코더가 사용되며 앞선 방식과 반대로 local 정보를 모델링하기에 연산량은 떨어지지만 성능은 높은 편입니다. 물론 여기서 효율성이란 inference할 때를 따지는 것입니다.
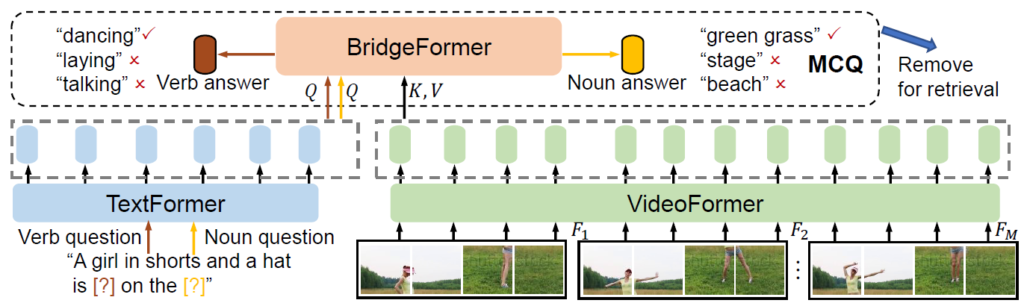
저자는 높은 검색 효율성을 유지하는 동시에 fine-grained한 모델링을 수행하기 위해 Multiple Choice Questions (MCQ)라는 parametric pretext task를 제안합니다. 이는 그림 1에서 볼 수 있듯 기본적으로 Dual-encoder 구조를 갖추고 있으며, BridgeFormer 모듈을 통해 비디오와 텍스트를 모든 level의 feature에서 상호작용시키게 됩니다. 제안하는 pretext task 방법론 이름이 MCQ인데, 우선 비디오-텍스트 쌍에서 텍스트를 활용해 question을 만들어내고, 비디오 정보를 참고해 answer를 답변하여 이를 정답과 학습하는 방식으로 진행됩니다. 그러나 진짜 Visual Question Answering task에서의 질문은 아니고, 문장의 주어와 동사를 지운 뒤 맞추도록 하는, 즉 당시 많이 사용되던 Masked Language Modeling (MLM) 기법이지만 예측 시 visual 정보를 참고하는 느낌이라고 이해해볼 수 있습니다.
간단한 프레임워크는 가장 처음 보여드린 그림 2-(c)에 나타나있습니다. 이를 그림 1과 같이 보면, 우선 문장 내 중요한 정보인 “주어”, “동사”를 답변으로서 맞추도록 문제를 설계하고 있습니다. 또한 질문의 답변을 학습하는 과정에서 각 모달의 low-, mid-, high-level feature가 모두 관여하고, backward되는 gradient는 두 모달리티를 엮는 BridgeFormer의 정보를 포함해 각 인코더로 흘러가기에 인코더들만 있을 때보다 깊은 표현을 학습할 수 있습니다. 마지막으로 downstream에서 inference는 BridgeFormer를 떼고 수행하기에 효율성을 챙길 수 있다고 주장합니다.
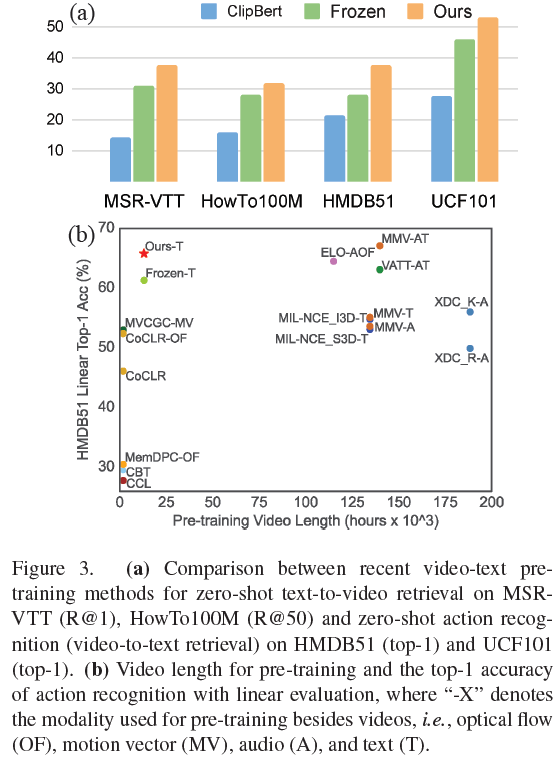
위 그림 3에서 볼 수 있듯, 저자가 제안하는 MCQ는 여러 실험에서 기존 모델에 비해 좋은 성능을 보여주고 있으며 무려 11배나 많은 개수의 비디오를 사전학습에 활용한 MMV라는 방법론(우상단 갈색 점)과 견줄만한 성능을 가진다고 합니다.
그럼 이제 MCQ가 질문을 어떻게 만들고 답변하는지, 그 내면에는 어떠한 디테일이 숨있는지 방법론 파트에서 알아보도록 하겠습니다.
2. Method
2.1 Dual-encoder for Video-text Pre-training: a revisit
우선 본 방법론은 앞서 말씀드린대로 효율성을 잡기 위해 Dual-encoder 구조를 채택합니다. 이 구조에 MCQ 사전학습을 위한 BridgeFormer를 붙여 두 모달리티 간 fine-grained semantic association을 모델링하게 됩니다. Dual-encoder 구조는 비디오 프레임을 입력받는 VideoFormer와 자연어 문장을 입력받는 TextFormer로 구성됩니다. 각 모달리티의 인코더로부터 얻은 embedding은 다시 각 모달의 linear layer를 타고 공통의 임베딩 공간으로 투영되며 이는 f_{v}, f_{t}와 같이 표기합니다. 이후 두 feature간 코사인 유사도를 구해 pos 쌍은 최대화, neg 쌍은 최소화하는 것이 기본적은 Dual-encoder 방식의 사전학습 프레임워크입니다. 방식이 간단한만큼 높은 효율성을 자랑합니다.
2.2 Multiple Choice Questions
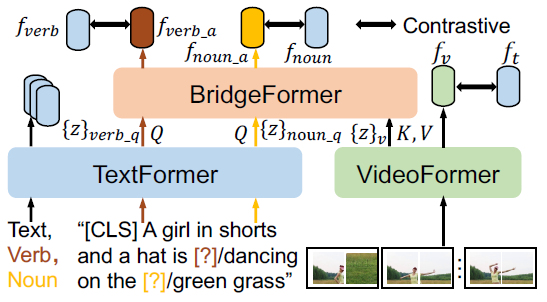
위 그림 4에서도 볼 수 있듯 MCQ는 parametric module BridgeFormer를 바탕으로 이루어집니다. VideoFormer, TextFormer에서 생성하는 모든 level의 intermediate token을 사용하기에 fine-grained하고 다양한 관점에서의 멀티모달 모델링이 가능해집니다. 문장 내에서 주어와 동사가 핵심적인 의미론적 역할을 수행한다는 사실은 자명한데, 주어는 보통 local object, 즉 spatial한 정보를 담고 있다고 많이 알려져 있죠. 동사는 비디오에서 object motion 정보를 담고 있으며 temporal dynamic으로 표현된다고 볼 수 있습니다. 결국 이렇게 문장에서 주요 역할을 하는 주어와 동사를 지운 뒤 BridgeFormer가 지워진 단어를 맞추는 방식으로 사전학습이 이루어집니다. 본문에서 문장 내 주어, 동사를 찾아내기 위해 off-the-shelf NLP 모델을 사용한다고 했는데, 아마 SRLBert와 같은 모델이 사용된 것 같습니다.
Answer Noun Question.
비디오에 상응하는 텍스트 “A girl in shorts and a hat is dancing on the green grass”가 입력되면, 랜덤한 noun phrase(예시에선 “green grass”)를 하나 선택하고 지워 “noun question” (“A girl in shorts and a hat is dancing on the [?]”)을 만들어냅니다. 이후 명사구가 지워진 noun question은 TextFormer로 입력되어 intermediate text tokens \{z\}_{noun_q}를 만들어냅니다. 비디오의 intermediate token \{z\}_{v}도 VideoFormer로부터 추출됩니다. 이후 BridgeFormer는 \{z\}_{noun_q}를 Q, \{z\}_{v}를 K, V로 두고 cross-attention을 수행합니다. 비디오 feature를 참고하여 비워둔 토큰에 들어갈 명사 feature를 예측해내는 것이죠.
방금 진행한 과정인 BridgeFormer에서의 cross-attention을 통해 “[?]”에 들어갈 answer로서 예측한 feature f_{noun_a}를 얻을 수 있게 됩니다. 사실 이 “[?]” 부분, 즉 “green grass”는 저희가 알고 있는 답이니 “green grass”도 TextFormer에 태워 feature f_{noun}을 얻을 수 있겠죠. 이후 둘을 각각의 linear layer에 태워 임베딩 공간을 맞춰준 후 유사도를 최대화합니다. 배치 내 다른 문장의 “[?]” feature였다면 유사도를 최소화하는 방식입니다. 기존의 MLM이 사전에 5,000 등과 같이 큰 vocab_size를 정해두고 분류하는 방식으로 흔히 학습했다면, 여기선 개수를 정해두고 분류하는 것이 아닌 contrastive learning 기반으로 문제를 해결하는 것이 제가 봐오던 MLM과의 차이점이라고 볼 수 있겠습니다. 이러한 학습은 VideoFormer에서도 각 명사에 관련된 spaital content에 잘 집중하도록 만드는 효과를 주게 됩니다.
Answer Verb Question.
명사 학습과 유사하게 여기서도 랜덤으로 동사구를 지웁니다. 예시에서는 “dancing”을 지워 “A girl in shorts and a hat is [?] on the green grass”와 같은 문장을 만들고 TextFormer에 태워 verb question text tokens \{z\}_{verb_q}를 만들어냅니다. 또 다시 \{z\}_{v}를 K, V로 두고 cross-attention을 수행해 “[?]” 부분의 feature f_{verb_a}를 예측해냅니다. 마찬가지로 정답 동사 “dancing”을 알고있으니 이를 TextFormer에 태워 f_{verb} 토큰을 얻을 수 있고, pos-neg 쌍에 따라 유사도 조정을 수행합니다. 이러한 학습 과정을 통해 VideoFormer가 비디오 내에서 발생하는 세부적인 temporal dynamic을 놓치지 않도록 만들어줄 수 있겠죠. 여기서 일부 아쉬운 점은 명사와 동사가 각각 spatial, temporal한 특성을 가짐을 살리지 못했다는 것입니다. 각 특성에 적합하게 모델링을 조금 다르게 해주었다면 좋았을 것 같은데, 그 부분은 가능하면 제가 한 번 연구해보도록 하겠습니다…
2.3 Pre-training Objectives
여기까지 하여 방법론적인 설명은 끝났고, 학습 과정에 대해 간단히 알아보겠습니다. 기본적으로 3개의 NCE loss를 통해 학습하며 이는 아래 수식과 같습니다.
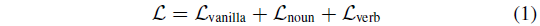
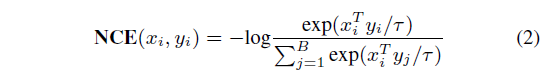
\mathcal{L}_{\text{vanilla}}는 각 인코더를 타고 나온 모달별 feature 간 contrastive learning을 담당하며, \mathcal{L}_{\text{noun}}, \mathcal{L}_{\text{verb}}는 앞서 설명드린 MCQ에서 제안된 loss입니다.
2.4 Model Architecture
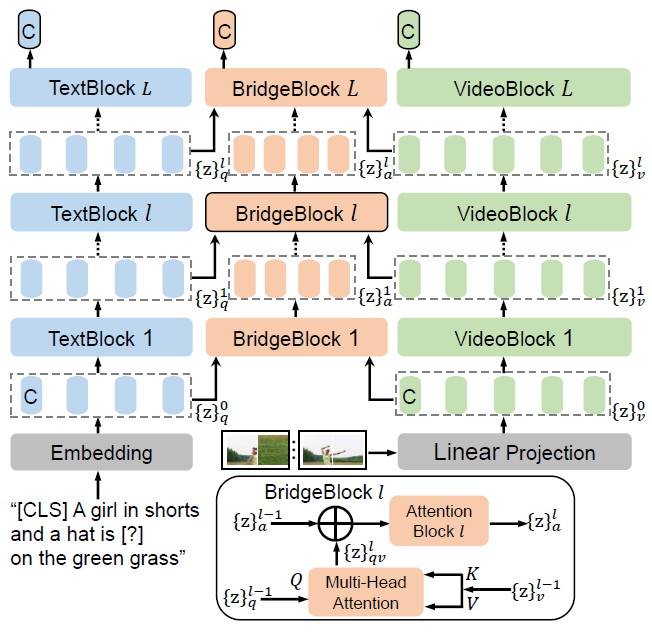
앞서 각 인코더 구조나 intermediate token에 대한 설명이 나오지 않았는데, 본 절에서 VideoFormer, TextFormer, BridgeFormer의 입력값과 Block에 대해 설명해줍니다.
2.4.1 VideoFormer
Input.
VideoFormer는 M개 프레임으로 이루어진 비디오 V \in{} \mathbb{R}^{M \times{} 3 \times{} H \times{} W}를 입력받습니다. V는 우선 M \times{} N개 패치로 나뉘고 linear projection을 거쳐 토큰 시퀀스 \{z\}_{v} \in{} \mathbb{R}^{M \times{} N \times{} D}로 변형됩니다. 많은 연구들과 같이 BERT를 따라 앞에 [CLS] 토큰을 달아주어 최종적인 토큰 시퀀스 \{z\}_{v}^{0} \in{} \mathbb{R}^{(1+M \times{} N) \times{} D}가 VideoBlock의 입력이 됩니다.
VideoBlock.
\{z\}_{v}^{0}는 위 그림 5에서 초록색을 표시된 VideoFormer에 입력되어 L개의 layer를 거치게 됩니다. ViT의 동일한 VideoFormer를 거치게 되는 것입니다.
2.4.2 TextFormer
Input.
VideoFormer가 여러 프레임으로 구성된 비디오를 입력받았다면, TextFormer는 3가지 종류의 자연어를 입력받습니다. 비디오와 쌍으로 주어지는 완전한 문장, 그리고 앞서 방법론 부분에서 “[?]”로 표현되었던 명사와 동사가 이에 해당합니다. 마찬가지로 L개 layer로 구성되어있으며, [CLS] 토큰을 최종 embedding으로 사용하게 됩니다.
TextBlock.
텍스트 모델링을 위해서 BERT의 효율성 강조 버전인 DistillBERT(Multi-layer bidirectional transformer encoder) 모델을 채택하였습니다.
2.4.3 BridgeFormer
Input.
BridgeFormer는 명사 또는 동사가 마스킹된 문장의 TextFormer 임베딩을 입력받고, 비디오의 VideoFormer 임베딩을 함께 활용해 비어있는 명사와 동사 feature를 예측하게 됩니다.
BridgeBlock.
BridgeBlock은 그림 5 아래와 같이 구성되어 있습니다. 우선 명사나 동사의 question token \{z\}_{q}^{l-1} \in{} \mathbb{R}^{L \times{} D}, Q를 입력받습니다. 이는 TextFormer로부터의 출력이며, 동시에 VideoFormer의 출력인 비디오 토큰 \{z\}_{v}^{l-1} \in{} \mathbb{R}^{M \times{} (N \times{} D)} ([CLS] 토큰 제외)을 받아 K, V로 둡니다. l번째 BridgeBlock은 cross-attention을 통해 모달간 상호작용을 마친 \{z\}_{qv}^{l}을 얻습니다. 각 텍스트 토큰과 프레임 내 비디오 패치들끼리의 attention 연산을 수행하는 것입니다.
최종적인 출력 \{z\}_{a}^{l}은 이전 BridgeBlock의 출력 \{z\}_{a}^{l-1}과의 Attention 연산을 거쳐 얻어집니다. Contrastive loss 학습에 사용되는 feature는 마지막 블록의 [CLS] 토큰입니다. 사실 제가 Transformer 모델 관련 방법론들을 많이 못봤는데, 위와 같이 세부적인 구조 설계는 타 유명 방법론을 따라하는 것인지, 저자들이 여러 실험으로 만들어내는 것인지도 궁금하네요.
3. Experiments
3.1 Pre-training Datasets
우선 사전학습 방법론이기에 어떠한 데이터셋을 활용했는지 알아보겠습니다. 기존 방법론들과 동일하게 330만 개 image-text 쌍으로 구성된 구글의 데이터셋 Google Conceptual Captions (CC3M), 250만 개 video-text 쌍의 WebVid-2M을 사용했다고 합니다. Temporal 정보를 위한 모델링도 들어가있지만 비디오-텍스트만을 사용하는 것은 아닌듯 하네요. 대용량 셋 중 HowTo100M이라는 데이터셋은 1억 3천 6백만 개의 video-text 쌍으로 구성되어있는데, 스케일이 너무 크기에 사전학습에는 활용하지 않았다고 합니다. 대신 이 데이터셋을 zero-shot t2v retrieval에 벤치마크로 사용했다고 합니다.
3.2 Downstream Tasks
위와 같은 대용량 셋들로 사전학습한 후 MCQ의 표현력을 알아보기 위해 Text-to-Video Retrieval, Action Recognition task의 성능을 측정했다고 합니다. T2V Retrieval은 MSR-VTT, MSVD, LSMDC, DiDeMo, HowTo100M과 같은 데이터셋에 대해 zero-shot과 fine-tune 세팅으로, Action Recognition은 HMDB51, UCF101 데이터셋에 대해 linear, fine-tune, zero-shot 세팅으로 평가했다고 합니다. 이들 중 유의미한 결과들만 살펴보도록 하겠습니다.
3.3 Main Results
본격적인 실험 결과를 살펴보기 전 Implementation detail이 궁금하신 분들은 논문을 참고하시거나 질문 주시면 답변 드리도록 하겠습니다.
3.3.1 Text-to-Video Retrieval
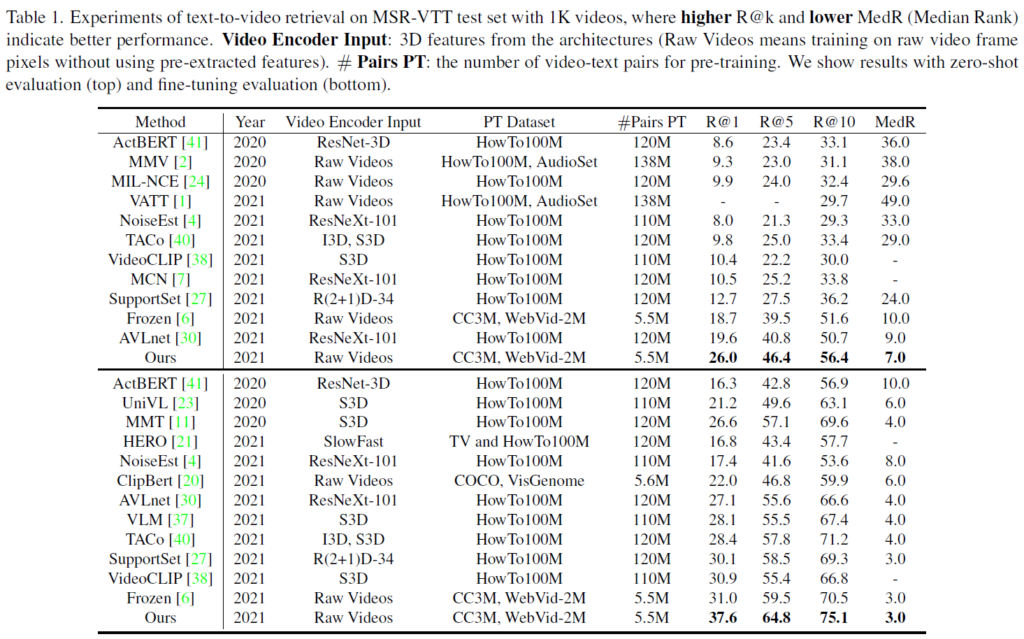
표 1은 MSR-VTT에서의 벤치마크 성능입니다. 위쪽 절반은 zero-shot, 아래쪽 절반은 fine-tune 성능입니다. 우선 어떠한 세팅이든 기존 방법론에 비해 압도적인 성능을 보이고 있습니다. 동일 년도임에도 MCQ의 zero-shot 성능이 타 방법론의 fine-tune 성능을 뛰어넘는 신기한 현상도 발생하고 있습니다. 동일 개수의 사전학습 데이터 양은 물론 거의 20배 많은 데이터셋으로 사전학습한 방법론들보다 높은 성능을 보여주는 점이 놀랍습니다. 물론 사전학습 데이터가 동일한 Frozen이라는 방법론도 전반적으로 성능이 높기에 개수는 적지만 표현력 좋은 사전학습 데이터셋을 선택한 것이 아니냐고 이야기할 수도 있지만 Frozen과의 성능 격차도 굉장히 크네요.
이러한 상황에서, 그럼 모델이 엄청 크고 연산량이 많은 것 아니냐라는 의문이 나올 수 있는데, 저자는 이에 대해 VATT라는 기존 방법론의 경우 256개 TPU로 3일 간 학습한 반면 자신들은 40개의 A100에서 25시간이면 사전학습을 마칠 수 있다고 하네요. 간단한 방법론으로 높은 성능을 냈다는 그런 이야기인 것 같습니다. 나머지 데이터셋에 대해서도 기존 방법론들보다 더욱 높은 성능을 보이고 있으며 이는 생략하도록 하겠습니다.
3.3.2 Action Recognition
HMDB51과 UCF101이라는 데이터셋에 대해 zero-shot 세팅으로 성능을 측정합니다. 여기서 zero-shot은 비디오만 보고 비디오의 행동을 분류하는 기존 action recognition과 달리 클래스 단어들 중 비디오와 가장 유사한 단어를 찾기에 사실상 video-to-text retrieval이라고 볼 수 있습니다.
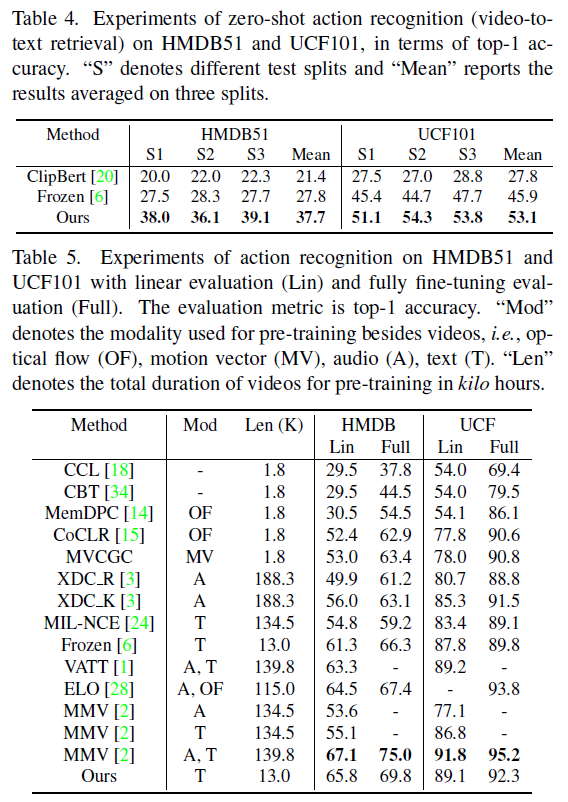
표 4는 두 데이터셋에서의 zero-shot action recognition 성능입니다. 사실 이 데이터셋의 비디오 도메인을 처음본다는건 둘째 치고 그러한 비디오의 분류를 텍스트만으로 해낼 때, 정확도가 40%, 50% 가까이 나온다는 점이 놀랍습니다. 최신 방법론들은 성능이 더 높겠지만, 이 실험에서도 기존 방법론들과 큰 격차를 벌리며 성능을 향상시켰습니다.
다음으로 표 5는, 본 방법론이 두 모달리티 간 상호작용을 열심히 학습했지만 이게 결국 비디오 단일 모달리티의 표현력도 올렸음을 보여줍니다. 표 4에서 본대로 zero-shot이 아니라 linear, fine-tune 세팅에서는 비디오를 학습시킨 뒤 비디오 모달리티만 사용해서 분류를 수행하는데요, 이 상황에서도 높은 성능을 보여줍니다. Optical flow나 Audio, Text 등 다른 모달을 사전학습 시 함께 활용한 방법론들이 다양하게 나타나있으며, 사실 어떤 모달을 사전학습 때 같이 봤냐에 따라 유.불리가 생기는지까진 잘 모르겠네요.
아무튼 성능을 보면 가장 높진 않습니다. 아무래도 비디오 모달리티의 표현력만을 평가하다보니 사전학습 때 얼마나 많은 비디오를 봤는지가 중요할텐데요, 표 5의 “Len” 열이 kilo hour 단위로 학습에 사용된 비디오 총 길이를 알려주고 있습니다. MMV(A, T) 모델은 비디오를 본 방법론보다 11배 가량 더 많이 학습했기에 더욱 높은 성능이 나올 수 밖에 없었다고 주장하는데, 사실 이 정도 데이터셋 규모 차이에 따른 성능 차이는 납득이 되는 수준이라고 생각합니다.
3.4 Ablation Studies
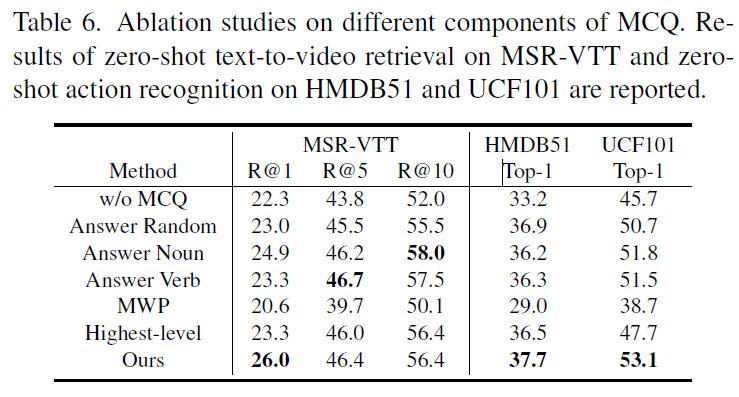
표 6, 7은 저자가 제안하는 MCQ 방법론의 ablation 실험 성능들이며, 신기하게 제가 읽으면서 궁금했던 부분부분들을 잘 실험해준 것 같아 한 행씩 살펴보도록 하겠습니다. 우선 첫 번째 행은 제안한 MCQ 방법론 없이 Dual-encoder만을 학습시킨 경우로, 베이스라인에 해당합니다.
이후 3개 행은 MCQ의 BridgeFormer가 대답할 대상에 따른 실험 성능입니다. 이전에 Reconstruction을 수행하는, 즉 MLM을 수행하는 방법론들을 보면 문장의 주어, 동사가 있음에도 불구하고 문장의 1/3을 랜덤하게 마스킹하고 복원하는 task를 많이들 채택하였었습니다. 그 때마다 논문을 읽어보면 대부분 이유가 설명되어있지 않았는데, 여기선 랜덤/주어/동사 경우를 나누어 실험을 진행했네요. 우선 랜덤보다 주어나 동사만을 마스킹했을 때 성능이 더 좋았으며, 심지어 R@5, R@10은 명사 동사에서 가장 높은 성능을 보이는 것을 알 수 있습니다.
다음으로 MWP는 Masked Word Prediction으로 제가 Method 작성할 때 보통은 vocab_size를 크게 설정해두고 분류하는 방식으로 reconstruction을 한다고 말씀드렸었는데, 그 방식을 의미합니다. 정확히 어떠한 방식으로 MWP 실험을 수행한 것인지는 설명되어있지 않지만 이와 같은 분류보단 feature-level에서의 예측과 유사도 조정이 훨씬 더 높은 성능을 보여주고 있습니다. 마지막으로 Highest-level은 intermediate feature를 사용하지 않고 가장 높은 level의 feature만 가져다 썼을 때의 성능인데 특히 R@1에서의 성능이 크게 떨어지는 것을 볼 수 있습니다.
4. Conclusion
이렇게 논문의 모든 부분에 대해 살펴보았습니다. 우선 제가 도전해보고자 하는 실험과 굉장히 결이 유사해 읽게 되었으며 비슷하게 제 task에도 적용해볼 수 있을 것 같습니다. 방법론이 직관적이고 코드도 공개되어있어 활용하기 좋을 것으로 생각됩니다.
이상으로 리뷰 마치겠습니다. 감사합니다.