안녕하세요, 마흔 일곱번째 x-review 입니다. 이번 논문은 arXiv에 올라온 논문이긴 하나, 3D FM을 구성하기 위한 연구를 수행했다고 하여 읽고 리뷰를 작성해 보았습니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
2D foundation model (FM)은 많은 분들이 아시다시피 SAM의 등장으로 많은 발전을 이루었습니다. SAM은 3D 도메인에서도 활용한 연구가 많이 등장하고 있는데요, 다만 3D task에 최적화된 FM이 아니다보니 3차원으로 올리는데에서 많은 시행착오가 발생하게 됩니다. 그래서 SAM을 3D 영역으로 확장해서 단순 활용이 아닌 3D에서의 FM으로 발전시키려는 시도가 있지만, 기존 방법론들은 아직까지 2D 이미지에 SAM을 적용한 다음에 그 결과를 3D로 올리는 것에 그칩니다. 이런 프로세스는 이미지에서 나오는 결과에 의존도가 높기 때문에 만약에 CAD 모델과 같이 텍스터나 색상이 없는 데이터에 대해서는 성능이 나오지 않을 가능성이 높습니다. 또한 사용하는 데이터의 view에도 영향을 많이 받게 되죠. view 수가 너무 적으면 전체 scene의 형태를 완전히 커버할 수 없는 반면, view 수가 많아진다 해도 늘어나는 계산 비용을 무시할 수 없습니다. 또한 많은 view를 하나의 scene으로 합칠 때 멀티뷰 사이의 연관성을 잘 찾지 못하면 inconsistency 문제가 발생할 수 있습니다. 이 inconsistency로 인해 view 사이의 겹치는 부분을 연결하지 못하고 occlusion 되는 영역에는 취약하다는 문제가 나타납니다. 이렇게 SAM의 결과를 단순히 3차원으로 올릴 때 발생할 수 있는 한계들을 해결하기 위해 본질적으로 3D를 위해 설계된 FM이 개발되어야 합니다.
그러나 3D FM을 개발하거나 SAM을 3D 영역으로 확장하는 데는 몇 가지 challenge한 점들이 존재합니다. 먼저 3D shape에 대한 통합된 표현이 없다는 점인데요, 이미지라는 정형화된 데이터가 있는 2D 도메인과 달리 3D는 mesh, voxel, point cloud 그리고 멀티뷰 이미지 이렇게 다양한 형태의 데이터가 존재하고 있습니다. 또한 3D 데이터는 스케일과 sparse의 정도 또한 크게 다르게 구성되어 있는데, 예를 들어 indoor와 outdoor 데이터는 흔히 센서가 커버할 수 있는 범위가 다르며 일반적으로 서로 다른 방식의 모델을 필요로 합니다.
두번째는 앞서 얘기한 서로 다른 데이터 형태를 처리할 수 있는 통합적인 구조가 없다는 것 입니다. raw 포인트 클라우드 같은 경우에는 PointNet이라는 모델을, 복셀 형태는 Sparse Convolution을 사용해야 하는 등, 다양한 표현이 존재하는 만큼 서로 다른 네트워크를 사용해야만 입력으로 들어오는 데이터를 처리할 수 있습니다.
세번째는 3D 네트워크를 scale up 하기 어렵다고 표현되어 있는데, 3차원 네트워크는 기본적인 계산 비용이 2D보다 훨씬 많이 들게 됩니다. 예를 들어, SAM은 디코더에서 deconvolution과 bilinear 업샘플링을 사용할 수 있지만, 포인트에 대해서는 2D만큼 그런 효율적인 3D 연산 방식이 없습니다.
마지막으로는 높은 퀄리티의 3차원 라벨링, 그 중에서도 각 포인트에 대한 마스크를 제공하는 데이터가 드물다는 점 입니다. SAM은 처음에는 적은 종류의 GT 라벨이 있는 기존 데이터로 학습을 한 다음에 클래스의 다양성을 높이기 위해 part, object, semantic의 범위에 해당하는 마스크 어노테이션을 할 수 있도록 하죠. 그러나 3차원에서는 일단 기존 데이터셋에 포함된 segmentation 라벨 수부터가 매우 적어서 높은 퀄리티의 다양한 범위에 속하는 마스크 정보를 제공하기가 매우 어렵다고 합니다.
이러한 challenge한 부분들을 해결하면서 3D FM을 만들기 위한 기초적인 단계로서 본 논문에서는 포인트 클라우드에 대한 3D 프롬프트가 가능한 segmentation 모델을 구축하는 것을 목표로 하였다고 합니다. 많은 데이터 형태 중에 포인트를 기본 데이터 표현으로 선택한 이유에 대해서는 나머지 표현들은 포인트로 쉽게 변환이 가능하고, 실제 데이터들 중에 대다수는 raw 포인트로 제공되는 경우가 많기 때문이라고 합니다. SAM을 따라 task, model, 그리고 data 를 중요한 관점으로 다루었습니다. 즉 segmentation 프롬프트가 주어지면 segmentation 마스크를 예측할 수 있는 3D promptable segmentation task에 초점을 맞추었다고 하네요.
본 논문에서는 Point-SAM이라는 이름으로 SAM의 3D로의 확장을 제안하고 있습니다. 구체적으로, 트랜스포머 기반의 인코더를 사용해서 우선 입력으로 들어오는 포인트를 임베딩하고, 포인트 프롬프트를 위한 포인트 프롬프트 인코더, 그리고 마스크 프롬ㅍ트를 위한 마스크 프롬프트 인코더로 구성되어 있습니다. 포인트, 프롬프트 임베딩은 마스크 디코더의 입력으로 들어가서 최종 segmentation 마스크를 예측하게 되죠. 데이터는 part와 object 레벨의 어노테이션을 모두 포함할 수 있도록 PartNet와 ScanNet이라는 데이터를 합쳐서 Point-SAM을 학습한다고 합니다. 라벨링의 다양성과 ShapeNet과 같이 물체에 대한 포인트는 제공하지만 segmentation 라벨링이 없는 large scale의 데이터를 활용하기 위해 SAM을 활용해서 pseudo 라벨을 생성하는 데이터 엔진을 추가적으로 개발하였습니다.
이러한 Point-SAM의 main contribution을 정리하면 다음과 같습니다.
- 다양한 라벨링 정보가 포함된 포인트 클라우드 데이터를 통합하여 segmentation task를 위한 3D FM Point-SAM을 개발
- SAM에서 knowledge를 전달받아 많은 마스킹 정보를 가진 pseudo 라벨을 생성하는 데이터 엔진 제안
- 3D segmentation task를 위해 모델과 데이터셋을 확장하여, 실험을 통해 occlusion되어 파악하기 어려운 영역과 새로운 task에 대한 모델의 zero shot 성능을 증명
2. Point-SAM
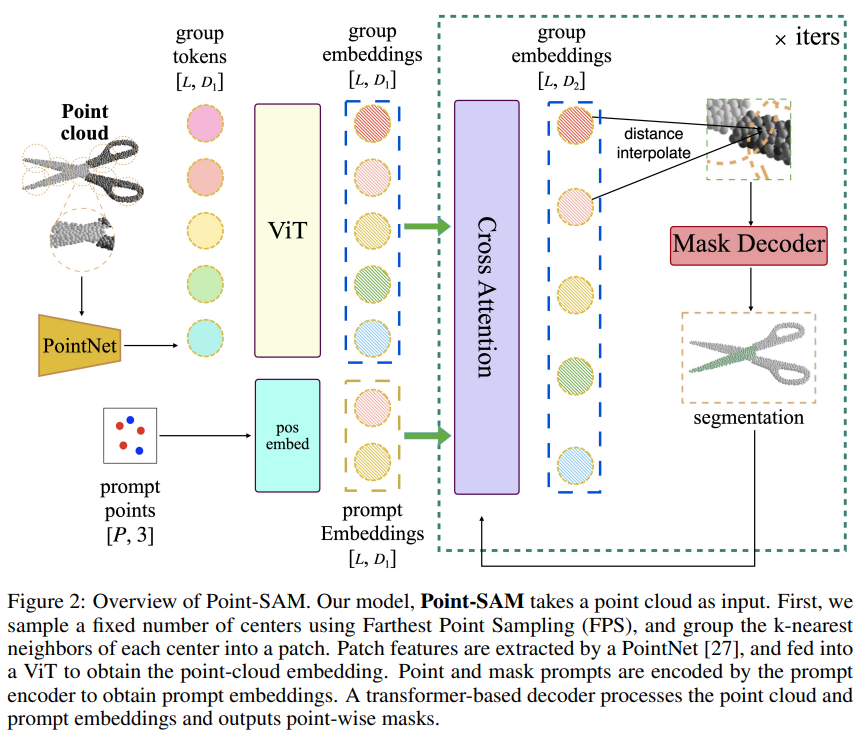
Fig.2는 Point-SAM의 overview를 나타낸 것으로, SAM을 따라 포인트 클라우드 인코더, 프롬프트 인코더, 그리고 마스크 인코더 이렇게 3가지 구성으로 이루어져 있습니다. 2D와 다르게 Point-SAM은 포인트 클라우드를 다루기 때문에 포인트와 관련된 계산 효율, scalability, 그리고 irregularity를 해결하고 있습니다.
- Point-cloud encoder
포인트 인코더는 입력으로 들어오는 포인트를 임베딩으로 변환합니다. 먼저 FPS 방식을 사용해서 고정된 수의 중심 포인트 C \in \mathbb{R}^{L \times 3}을 샘플링 합니다. 그 다음에 샘플링한 중심 포인트들을 기준으로 KNN 방식으로 그룹화를 합니다. 그럼 입력으로 들어오는 포인트들이 마치 이미지를 패치 단위로 나누는 것처럼 각각의 나눠진 포인트 영역을 만들 수 있는데, 편의상 이러한 그룹화 영역들을 포인트 패치라고 부르겠습니다. 만들어진 각 포인트 패치에 대한 feature는 PointNet을 사용해서 추출하는데, 여기까지가 패치 임베딩 모듈의 과정으로 결과적으로 패치들마다의 feature을 생성하는 것 입니다. 이 feature는 각 중심 포인트의 position 임베딩과 합쳐져서 F_{patch} \in \mathbb{R}^{L \times D_1}가 됩니다. F_{patch}는 사전학습된 3D 트랜스포머로 처리되어 최종적인 포인트 클라우드 임베딩 F_{pc} \in \mathbb{R}^{L \times D_2}를 생성합니다. 사용되는 사전학습 트랜스포머를 스케일링해서 Point-SAM을 직접적으로 스케일을 높일 수 있는데, 스케일에 따라 Point-SAM-Large(307M)와 Point-SAM-Giant(1B)으로 제공됩니다.
- Prompt encoder
프롬프트 인코더는 여러 유형의 프롬프트를 임베딩 하게 됩니다. 여기서는 여러 프롬프트 중에서 포인트와 마스크 두 개의 프롬프트에 초점을 맞추어 수행했다고 합니다. 프롬프트로 들어오는 각 포인트는 전경 프롬프트인지 여부를 나타내는 이진 라벨과 연관되어 있습니다. 포인트 프롬프트가 들어오면 position 임베딩 F_{point} \in \mathbb{R}^{Q \times D_2}로 인코딩되어 라벨을 나타내는 learnable 임베딩과 합쳐집니다. 마스크 프롬프트는 일반적으로 모델의 이전 예측에서 나온 dense한 포인트별 logit X_{mask} \in \mathbb{R}^{N \times 1}을 사용합니다. logit은 입력 포인트의 좌표와 연결되고, 포인트 클라우드 인코더의 패치 임베딩 모듈을 반영하는 마스크 인코더를 통해 처리할 수 있습니다. 결과적으로 마스크 프롬프트 임베딩 F_{mask} \in \mathbb{R}^{L \times D_2}는 포인트 임베딩과 요소 합을 통해 합쳐집니다.
- Mask Decoder
마스크 디코더는 포인트 임베딩, 프롬프트 임베딩, 그리고 출력으로 나오는 토큰 F_{out} \in \mathbb{R}^{1 \times D_2}를 segmentation 마스크 Y_{mask} \in \mathbb{R}^{N \times 1}에 매핑합니다. 포인트의 irregular한 특성 때문에 마스크 디코더는 2D에서의 디코더와 좀 달라지는데요, 먼저 SAM을 따라서 프롬프트 self attention과 양방향(프롬프트↔포인트) cross attention을 사용하는 두 개의 트랜스포머 디코더 블록을 사용해서 모든 임베딩을 업데이트 합니다. 앞서 샘플링한 중심 포인트를 기준으로 가장 가까운 이웃 포인트 3개를 사용해서 inverse distance weighted average interpolation을 통해 입력 해상도와 일치하도록 업데이트된 포인트 클라우드 임베딩 F_{pc} \in \mathbb{R}^{L \times D_2}를 업샘플링 합니다. 그 다음에 MLP 사용해서 나오는 최종 포인트 클라우드 임베딩을 X_{pc} \in \mathbb{R}^{N \times D_4}로 표시합니다. 또 다른 MLP에서는 출력 토큰을 linear classifier X_{out} \in \mathbb{R}^{1 \times D_4}의 가중치로 사용해서 각 포인트 위치에서의 마스크가 전경, 물체일 확률을 Y_{mask} = X_{pc} \cdot X^T_{out}으로 계산합니다. SAM과 마찬가지로, 여러 출력 토큰을 사용해서 단일 포인트 프롬프트에 대해서 여러 개의 출력 마스크를 생성할 수 있또록 하는 것 입니다. (다만 여러 개의 마스크를 출력하는건 마스크 프롬프트가 없는 단일 오인트 프롬프트만 있는 경우에 가능하다고 하네요.) 마지막으로 마스크 출력에 대한 IoU score를 구하기 위해 또 다른 토큰인 F_{iou} \in \mathbb{R}^{M \times D_2}를 사용했다고 합니다.
3. Training Datasets
Integrating existing dataset
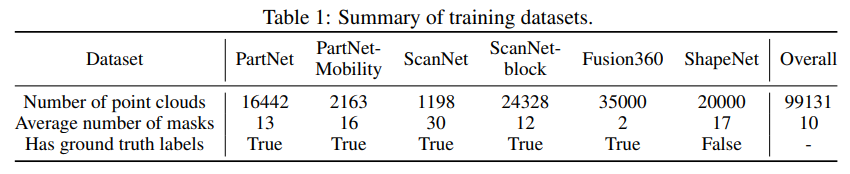
FM은 일반적으로 많은 데이터를 사용하며 여기서는 다양한 segmentation 마스크의 존재가 중요합니다. 그래서 본 논문에서도 Tab.1과 같이 기존 데이터셋과 segmentation 라벨을 합쳐서 사용했다고 하네요. PartNet-Mobility의 경우 ShapeNet에 포함되지 않는 3개의 카테고리 (가위, 냉장고, 문)을 포함하고 있어서 unseen 카테고리에 대해 평가할 때 사용하였다고 합니다. object level로 제공되는 데이터셋들은 각 물체에 대해 12개의 뷰를 ㄹ네더링하고, 렌더링된 RGB-D 이미지에서 포인트를 합친 다음에 FPS를 사용해서 합쳐진 포인트에서 32768개의 포인트를 샘플링하였습니다. scene level의 데이터셋인 ScanNet200 같은 경우에는 scene을 block으로 나누어서 사용했다고 하네요 .. block 레벨이란게 정확히 뭔지는 모르겠지만 아마 더 작은 영역으로 나누어 object level과 유사해질 수 있도록 분할한 것이지 않을까 싶습니다.
Generating pseudo labels
존재하는 데이터셋들을 합쳤다고 해도 FM에 활용하기에는 마스크의 다양성이 부족했다고 판단한 것 같습니다. 그래서 ShapeNet과 같은 데이터셋은 large scale이긴 하지만 part level의 segmentation 라벨이 포함되어 있지 않고, 각 포인트들이 single instance에 속한다는 한계가 있기 때문에 본 논문에서는 추가적으로 pseudo 라벨을 생성하기 위한 데이터 엔진을 개발하였다고 합니다.
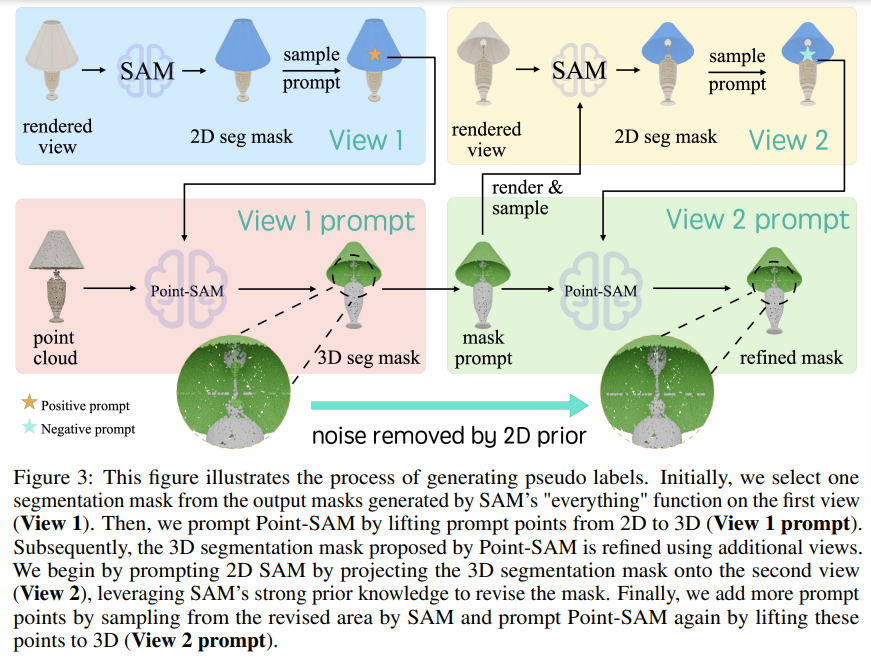
먼저 Point-SAM을 존재하는 데이터셋들을 합친 데이터로 사전학습 합니다. 그 다음에 그 사전학습된 Point-SAM과 SAM을 pseudo 라벨을 만들기 위해 함께 사용하게 됩니다. 각 메쉬마다 6개의 고정된 카메라 pose에서 RGB-D 이미지를 렌더링하고, 색깔이 있는 포인트 클라우드를 합칩니다. 그 다음에 Fig.3과 같이 SAM을 렌더링된 각 뷰에 대해서 다양한 2D mask proposal을 생성하고, 각 2D proposal에 대해서 해당하는 3D proposal을 찾아야 합니다.
View1이라고 표시된 부분을 보면, 2D proposal mask에서 2D 프롬프트를 랜덤 샘플링해서 3D 프롬프트로 올리고나면, View1 prompt 파트와 같이 그 프롬프트를 사용해서 포인트에서 3D 마스크를 예측하게 됩니다. 여기까지 예측을 하면, 2D 프롬프트와 해당 뷰의 3D 프롬프트로 투영하는 과정에서 노이즈가 발생하거나 잘못 예측하는 영역이 발생하는데, 여기서 다음 2D 프롬프트를 다른 뷰에 대해서 샘플링합니다. 새로운 3D 프롬프트로 올려서 이전의 3D 프롬프트 마스크가 같이 Point-SAM에 들어가서 3D 프롬프트를 업데이트 하게 되는 것이죠. 이 과정에서 2D proposal과 3D proposal 사이의 IoU가 임계값보다 커질 때 까지 반복하게 됩니다. 이를 통해 SAM의 예측을 활용하여 다양한 mask를 예측하면서도 Point-SAM을 통해 3D segmentation이 가능해집니다.
이런 과정을 반복적으로 수행하여 proposal 사이에 계산하는 IoU가 가장 높은 값을 가지는 출력 2D 마스크를 최종 2D proposal로 선택하게 되며, IoU가 임계값보다 낮은 경우에는 그에 해당하는 3D proposal은 사용하지 않는다고 합니다. 이러한 데이터 엔진을 통해 선택되는 3D proposal을 통해 ShapeNet에서 약 2만개의 pseudo 라벨을 추가적으로 생성할 수 있게 되어 마스크의 다양성을 확보하고자 했던 목적을 이룰 수 있게 됩니다.
4. Experiments
4.1. Zero-Shot Point-Prompted Segmentation
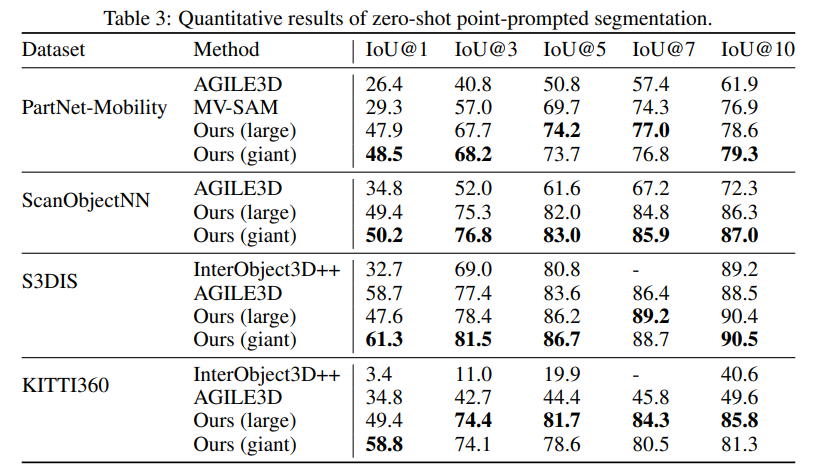
우선 zero-shot point prompted segmentation에 대한 실험을 Tab.3과 같이 진행하였습니다. 여기서 베이스라인은 3D interactive segmentation 방법론인 AGILE3D와 SAM의 멀티뷰 확장 방식인 MV-SAM을 사용합니다. MV-SAM과 본 논문의 방법론 모두 여러 개의 출력이 있는 경우에 가장 확실한 예측을 선택하게 됩니다.
Point-SAM은 모든 데이터셋에서, 그 중에서 특히 PartNet-Mobility와 KITTI360과 같은 OOD 시나리오에서 베이스라인 방법론 보다 훨씬 좋은 성능을 보이면서 zero shot transperability 능력과 데이터셋 확장의 중요성을 강조하고 있습니다. 또한 MV-SAM은 충분한 수의 프롬프트가 제공되면 꽤나 높은 성능을 보이고 있는데, 이는 기존 SAM을 단순히 확장한 방식은 프롬프트가 제한되는 상황에서는 추가적인 fine tuning 없이 멀티뷰 consistency를 달성하는 것이 어렵다는 것을 보여줍니다. 따라서 Point-SAM과 같이 3D를 위해 설계된 프롬프트 방식이 더 효율적이라는 것을 강조하고 있습니다.
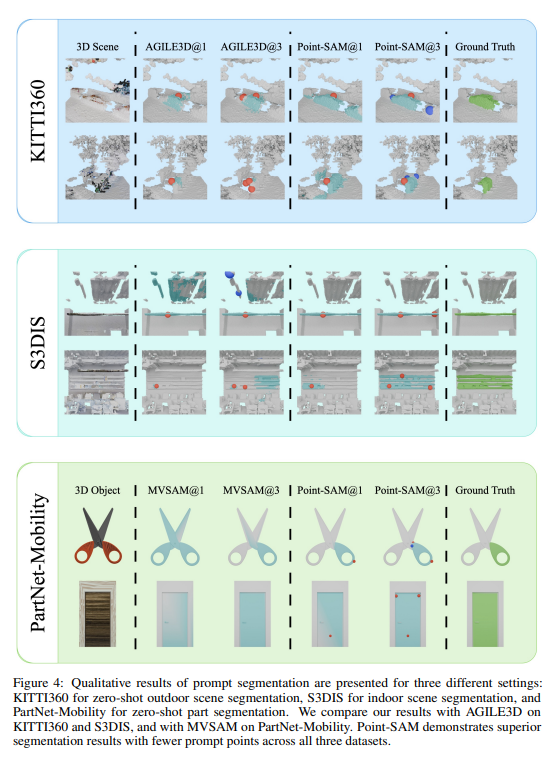
Fig.4는 정성적인 결과로, Point-SAM과 AGILE3D는 둘 다 outdoor 데이터셋으로 학습되지 않았음에도 불구하고 KITTI360 데이터셋에서 Point-SAM이 3개의 포인트 프롬프트 만으로 outdoor 물체를 정확히 segmentation 하는 것을 확인할 수 있습니다. 또한 PartNet-Mobility 데이터에서 MV-SAM이 가위의 손잡이와 날 부분을 모호하게 예측하는 반면, Point-SAM은 손잡이를 정확하게 분리하여 예측하는 것을 통해 기하학적 정보를 사용해서 작은 부분들까지 효과적으로 처리하는 것을 정성적으로 보여주고 있습니다.
4.2. Few-shot Part Segmentation
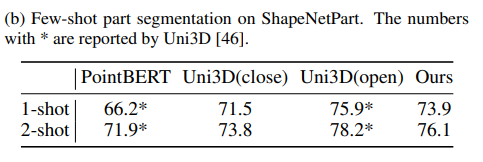
FM은 다양한 task에 맞게 fine tuning하여 사용할 수 있는데, (b)는 Point-SAM의 part segmentation에 대한 성능을 리포팅하고 있습니다. ShapeNetPart라는 데이터를 사용해서 클래스 전체에 대한 mIoU_C를 평가하였습니다. few shot 학습 중에는 인코더를 freeze하고 CE loss를 사용해서 feature propagation과 MLP만 최적화하였다고 합니다. Uni3D는 원래 ov part segmentation이기 때문에 이를 Uni3D(close)로 표시하고, 본 논문과 같이 세팅하여 Uni3D(close)를 따로 비교 모델로 선정하였다고 합니다. Point-SAM은 기존 Uni3D(open)보다는 낮은 성능을 보이지만 두 PointBERT와 Uni3D(close) 대비 높은 성능을 보이며 여러 downstream task에서의 활용 가능성을 보여주고 있습니다.
4.3. Ablations
Scaling up datasets
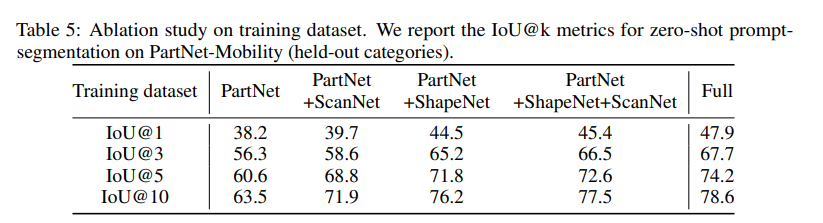
데이터셋을 확장하는 것에 대한 ablation study 인데요, 이전 연구들은 학습 데이터셋의 규모와 범위가 한정적이었던 반면에 본 논문은 존재하는 많은 포인트 데이터 뿐만 아니라 추가적인 pseudo label을 통한 어노테이션 정보까지 확장할 수 있었습니다. 따라서 학습 데이터 확장의 효과를 보여주기 위해 데이터셋 크기와 구성에 대한 실험을 진행하였다고 합니다.
총 4가지 데이터셋 구성을 통해 실험을 했는데, 1) PartNet만 사용 / 2) PartNet+ScanNet / 3) PartNet + ShapeNet(pseudo label 포함) / 4) PartNet + ShapeNet + ScanNet 이렇게 4가지 경우를 구성하였습니다.
모든 경우에서 데이터셋을 확장할 수록 좋은 성능을 보이는 것을 우선 확인할 수 있습니다. 또한 PartNet+ShapeNet으로 학습된 모델은 특히 단일 프롬프트에서 훨씬 더 나은 성능을 보이고 있는데, 단일 프롬프트가 들어오게 되면 아무래도 정보가 모호해지기 때문에 IoU@1 성능을 통해 모델이 충분히 마스크의 다양성을 찾을 수 있는지 여부를 판단할 수 있었습니다. 점점 더 규모가 커지고 다양한 영역에 대한 어노테이션이 활용될 수록 OOD 데이터에 대한 zero shot 성능도 비례하여 향상되는 것을 확인할 수 있습니다.
Sensitivity to Point Count
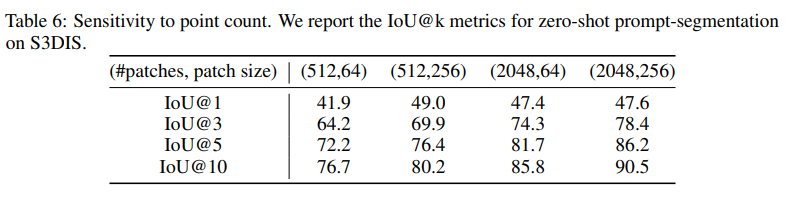
앞서 이야기한 것처럼 포인트는 매우 irregular한 특성을 가지고 있는데, 학습에 사용된 포인트보다 더 많은 포인트를 처리할 때는 패치 수와 크기를 적절히 조정해야 합니다. 따라서 이 패치 수와 크기라는 하이퍼파라미터의 효과를 ablation study를 통해 확인하였다고 합니다. Tab.6은 S3DIS라는 indoor datset에 대한 zero shot prompt segmentation 결과를 보여주고 있습니다. S3DIS 데이터셋은 포인트의 평균 수가 학습 데이터셋의 거의 50배에 해당하는 약 500만 개의 포인트를 가지고 있는데, 결과를 보시면 더 큰 규모의 포인트를 활용하기 위해서는 많은 패치 수를 사용하는 것이 중요하다는 것을 보여주고 있습니다 . . 사실 어쩌면 당연한 얘기일 수도 있다고 생각이 들긴 하네요. 한 데이터 안에 들어있는 포인트가 많을 수록 큰 패치 수를 사용하는 것이 어쩌면 당연하게 받아들여질 수도 있을 것 같은데 여하튼 실험을 통해서 이를 증명했다고 합니다. 또한 패치 수 뿐만 아니라 학습 데이터의 분포와 비교했을 때 샘플링하는 중심 포인트 주변에 있는 이웃 포인트들의 분포 밀도도 더 dense할 것이기 대문에 패치 크기를 확대하는 것 역시도 필요하다는 걸 해당 ablation study를 통해 보여주고 있습니다.
좋은 리뷰 감사합니다.
PartNet와 ScanNet 데이터를 합쳐 Point-SAM을 학습하다고 하셨는데, 두 데이터는 동일 데이터를 기반으로 파생된 데이터인가요??
또한, 여기서 3D 렌더링이란 결국 RGB-D를 이용하는 것으로 보이는데, 인트로에서 언급하였던 문제점인 view 사이의 inconsistency는 어떻게 해결하였는 지 설명해주실 수 있을까요??
마지막으로, 3D에서의 Foundation Model을제안한 것이라 이해하였는데, segmentation 외의 다른 task에 대한 실험 결과는 따로 없을까요??
감사합니다.
안녕하세요. 리뷰 잘 읽었습니다.
아주 간단한 질문이 될 수 있겠는데요, 연구원님께서 시작 부에 “3D FM을 구성하기 위한 연구를 수행했다고 하여”라고 해주셨습니다.
그리고서 읽다 보니 드는 의문점으로, FM이란 결국 하나의 모달리티만이 아닌 다양한 모달리티의 대용량 데이터를 학습하여야 하는데, 본 논문에서의 입력은 PCD로만 보이는데, 그럼 지금 실험에서 Zero-shot이라 함은 결국 클래스까지 따지지는 않고 단순히 해당 데이터셋의 학습데이터를 썻냐 안썻냐의 수준인게 맞을까요?
안녕하세요 ! 좋은 리뷰 감사합니다.
문제 정의로 3D 네트워크를 scale up 하기 어렵다고 표현했는데, 그렇다면 기존의 3차원 네트워크는 연산이 어떻게 이루어지는 것인가요 ?,,? 기존에도 어쨌든 deconvolution이나 업샘플링 같은 연산이 이루어지고 있어야 할 것 같은데 유사한 동작을 하는 방식은 없었던 건지 궁금합니다.
또, 여러 많은 데이터셋들을 합쳐서 3차원에서의 large scale 데이터셋을 구축하였는데, 그럼 여러 데이터셋에서 겹쳐지는 물체가 존재하지만 스케일이 다르거나 구성되어 있는 segmentation 마스크의 형태가 다르다면, 이런 부분은 어떻게 처리한 것인지 혹시 논문에 설명이 되어있을까요?>?
감사합니다.