안녕하세요, 3번 째 X-Review 입니다. 이번주도 Amodal Completion에 대한 논문을 읽어봤습니다. 이 논문의 저자들은 3D 데이터를 활용하여 가려진 물체의 Amodal Masks를 자동 생성하는 Pipeline을 제안하고 새로운 Evaluation Benchmark도 구축했다고 합니다. 또 제시한 Amodal Completion 모델은 여러 데이터셋에서 sota 성능을 달성했다고 하네요. 하지만 이전 논문들 처럼 가려진 객체 자체를 전부 복원하는것 보다는 Amodal Mask를 예측하는것에 초점을 두고 있는 것 같습니다.
Introduction
다른 Amodal Completion 논문들의 저자와 같이 해당 논문의 저자는 Mask-RCNN, SAM 같은 모델들이 나오면서 Instance Segmentation 분야가 매우 발전했지만, 모두 Amodal Segmentation을 수행할 때는 한계를 가지고 있다는 문제를 정의합니다. Amodal Segmentation을 성공적으로 수행한다면, Object Detection, 3D Reconstruction, Manipulation 및 Navigation Task Planning 등 여러 분야에서 응용해서 유용하게 사용될 수 있을 것이라는 점을 어필했습니다. 그러고 이 Amodal Segmentation의 큰 도전과제를 3D세계에 존재하는 다양한 객체들이 2D로 투영될 때 생기는 복잡한 occlusion과 아래 표에서 알 수 있듯 기존 Amodal Segmentation Dataset이 synthetic 데이터라는 점을 한계로 정했습니다. 이 문제를 해결하기 위해 MP3D-Amodal Dataset을 새로 만들었고, 이 데이터 셋은 Real Image 기반 Authentic Ground Truth Amodal Mask를 제공한다고 합니다. 데이터셋을 만들 때는 MatterPort3D 데이터셋의 3D 구조를 2D로 투영해서 생성했습니다. 또한 Amodal Segmentation을 위한 새로운 모델인 OccAmodal, SDAmodal을 제시했는데, SDAmodal 같은 경우는 이름에서 알 수 있듯 다른 Amodal Completion 모델들과 같이 Diffusion을 사용했습니다. 아무래도 Diffusion이 제일 성능이 좋은 것 같습니다. 또 SDAmodal의 경우 다른 Diffusion을 사용한 모델들도 비슷할 것 같긴 한데 Class-Agnostic하게 작동하고, Occluder Mask가 제공되지 않는 경우에도 성능을 발휘한다고 합니다.
MP3D-Amodal Dataset
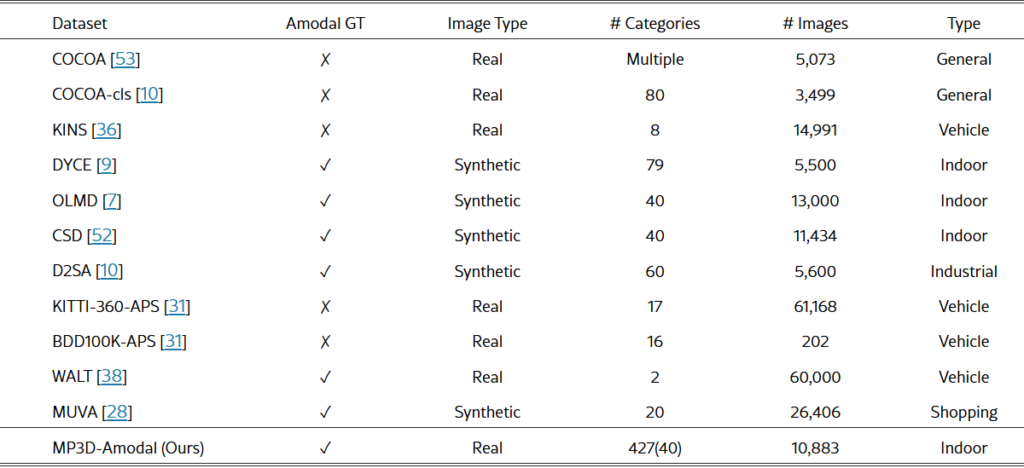
표와 함께 MP3D데이터셋의 얘기를 하자면 기존의 Amodal GT를 가지고 있는 데이터셋들은 대부분 전부 Synthetic 데이터로 구성 돼있는 점을 볼 수 있습니다. MP3D는 Real 이미지 기반의 Amodal GT를 제공하고, 427개의 Semantic Label 10883개의 이미지로 구성됐다는 점에서 기존의 synthetic 이미지를 활용한 데이터셋보다 카테고리도 많고 이미지 수도 비슷함을 볼 수 있습니다. 이는 자동화된 파이프라인을 통해 가능하게 만들 수 있는 부분이고, MatterPort3D 기반으로 제작됐기 때문에 실내환경의 이미지로 구성돼있습니다. 데이터셋 은 Training 과 Evaluation으로 구분되어 있고, 평가의 포괄성을 위해 Evaluation 부분에 더 많은 Scene을 포함하고있습니다. Training과 Evaluation에는 88개의 공통 Semantic Label을 공유하고, Evaluation에는 297개의 고유 Semantic Label을 가지고 있다고 합니다. 또 MP3D 데이터셋은 각기 다른 Occlusion Ratio를 가지고 있는데, 객체의 Amodal Mask와 Modal Mask의 차이를 Amodal Mask의 면적으로 나눈 값을 Occlusion Ratio로 정의해서 0.1부터 0.9 까지 여러 범위에 걸쳐 분포돼있습니다.
이 데이터셋은 MatterPort3D 데이터셋의 3D Mesh와 Real Image를 활용하여 Amodal Mask와 Modal Mask를 생성하는 과정을 자동화했습니다. Modal Mask는 객체가 현재 보이는 영역만을 표현하는 마스크이고, 따라서 Modal Mask를 만들 때 특정 scene의 모든 객체를 3D Mesh로 표현한 후, 이를 전부 카메라 공간으로 투영해 2D 이미지를 얻어서 각 객체들의 Modal Mask를 구한다고 합니다. 아래 그림과 같은 마스크를 얻을 수 있습니다.

Amodal Mask의 경우 객체의 가려진 영역까지 전체를 나타내는 영역의 마스크인데, 각 객체를 따로 카메라 공간에 투영해서 만들어줍니다. 이후 Amodal Mask와 Modal Mask를 비교해 Amodal Mask의 면적이 Modal Mask보다 1.2배 이상 크다면, 해당 객체는 가려진 객체로 간주합니다. 위의 예시와 같은 Chair의 Amodal Mask 같은 경우는 가려진 객체에 대한 조건을 충족해서 데이터셋에 포함시키게 되는데, 여기서 3D 메시가 불완전하거나 노이즈가 섞여있는 경우들이 있어서 Modal Mask가 객체를 제대로 포함하지 않는 경우나 Amodal Mask에 너무 노이즈가 많은 경우에는 사람이 직접 필터링 한다고 합니다. 그래도 일정부분 자동화 단계를 거치면서 사람의 의존도가 많이 감소되고, 높은 데이터 품질도 획득할 수 있었다고 합니다.
Architectures for Amodal Prediction
OccAmodal(Two-Stage)
데이터셋 이외에 Amodal Prediction을 위한 모델에 대한 얘기를 해보겠습니다. 일단 여타 Amodal Completion 모델들과 같이 고안된 모델의 목표는 이미지와 이미지 내 객체의 Modal Mask가 주어졌을 때, 해당 객체의 Amodal Mask를 예측하는 것이 목표입니다. 저자는 두 가지 아키텍처를 소개하는데요, 먼저 Two-Stage 인 OccAmodal과 One-Stage인 SDAmodal 입니다. OccAmodal은 먼저 Occluder Mask를 예측하고 이를 이용해서 Amodal Mask를 생성합니다. Occluder Mask는 객체를 가리는 부분을 나타내는 바이너리 마스크로 주어지고, Occluder Mask는 복원해야하는 목표 객체를 가리고 있는 물체의 마스크를 제공하는 것이기 때문에, 어느 부분이 정확히 가려져 있는지를 효과적으로 알 수 있다는 점에서 중요하게 작용합니다. OccAmodal은 사전에 Occluder Mask가 주어지지 않는 상황에서도 동작하도록 설계되었는데, 모델을 Occluder Predictor와 Amodal Predictor로 나누어서 설계했습니다. Occluder Predictor는 입력으로 원본 이미지와 가려진 물체의 Modal Mask를 입력받아 ResNet과 U-Net Encoder를 사용하여 Occluder Mask를 예측합니다. 이후에 Occluder Mask를 활용해 실제로 Amdoal Mask를 생성하는 Amodal Predictor를 통해 Amodal Completion을 수행합니다. Amodal Mask를 생성하는 과정에서는 앞서 생성된 Occluder Mask와 Modal Mask를 통해 Occlusion Boundary를 계산하고, 이를 이미지와 Modal Mask까지 전부 Amodal Predictor의 입력으로 넣어줍니다. 이 정보들을 활용해 ResNet 인코더에서 시각적 특징을 추출하고 U-Net 베이스의 아키텍쳐를 활용해 최종적으로 Amodal Mask를 예측합니다.
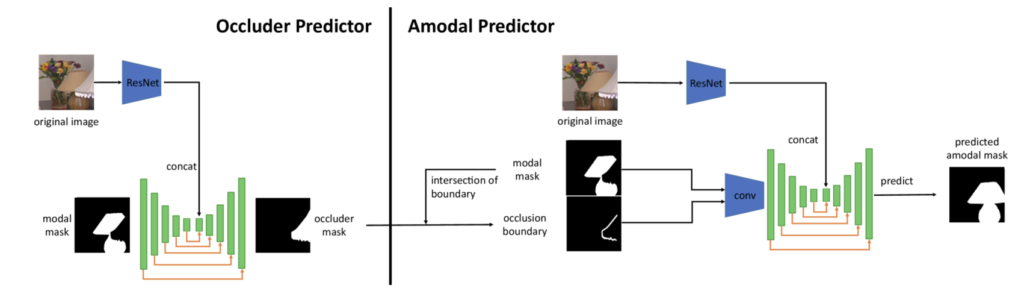
그림과 같이 모듈화 되어있는 모델 덕분에 occlusion에 대한 복잡한 관계를 단계적으로 학습할 수 있다고 하네요. 뭔가 유리해 보이긴 하고 덜 꼬일 것 같은 느낌이긴 한데, 모듈화된 모델이 그렇지 않은 모델에 비해 정확히 어떻게 복잡한 관계를 단계적으로 학습하는지는 조금 더 생각을 해봐야 알 것 같습니다. Occluder Predictor는 충분히 학습된 상태라면 Amodal Predictor 부분만 이어서 더 학습할 수 있고, 이는 곧 성능 향상으로 이어진다는 의미로 이해하고 넘어갔습니다.
SDAmodal(One-stage)
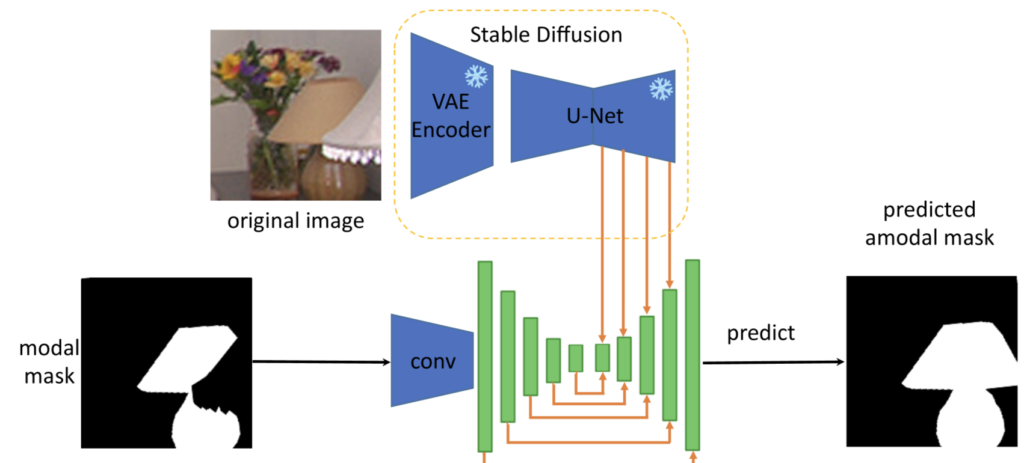
SDAmodal은 Stable Diffusion 모델을 활용하여 Amodal Mask를 예측하는 One-Stage Architecture입니다. 지금까지 읽었던 다른 논문들과 같이 저자는 Amodal Completion을 하는데 있어 객체 전체의 형태와 구조를 시각적 이해를 바탕으로 추론하는 것이 핵심이라고 언급합니다. 이를 위해 사전 학습된 Stable Diffusion을 활용했습니다. Stable Diffusion이 학습한 객체의 형태, 시각적 표현, 그리고 Occlusion 정보를 그대로 활용하기 위해 Stable Diffusion 모델은 학습중에는 freeze하고 사용합니다. Stable Diffusion의 VAE를 통해 입력 이미지를 Latent Space로 변환하고, Latent Feature에 노이즈를 추가한 뒤 U-Net의 디코더 부분에서 Multi-Scale Feature를 추출합니다. 추출된 Feature에 Modal mask의 feature를 결합해 디코딩 레이어에 전달한 뒤 Amodal Mask를 생성합니다.
Training
OccAmodal의 경우 두 모듈로 나누어져 있기 때문에 Occluder Predictor와 Amodal Predictor를 따로 학습시키는데, Occluder Predictor 같은 경우는 COCOA데이터셋의 Occlusion 관계를 기반으로 GT를 생성해서 Cross-Entropy Loss를 통해 학습한다고 합니다. Amodal Predictor의 경우에는 COCOA와 MP3D 데이터셋의 GT를 사용해서 Uncertainty Weighted Segmentation Loss를 통해 학습한다고 하네요. Uncertainty Weighted Segmentation Loss의 경우 각 픽셀에 가중치를 할당하고 예측 결과와 GT의 Loss를 구한다고 합니다. 이 때 이 가중치를 픽셀의 uncertainty에 기반한다고 합니다. 이러한 Loss를 사용하는 이유는 Cross-Entropy Loss같은 경우는 모든 픽셀에 동일한 중요도를 부여하는데, 가려진 부분을 복원하는 task인 만큼 실제로 가려져 있는 영역의 예측이 잘못되면 부정적인 영향이 더 크기 때문에 불확실성이 높은 (가려진) 부분에 대한 가중치를 높게 주고 학습을 한다고 합니다. SDAmodal은 GT Amodal 마스크와 예측한 마스크 사이의 Cross-Entropy Loss를 활용합니다.
Experiments
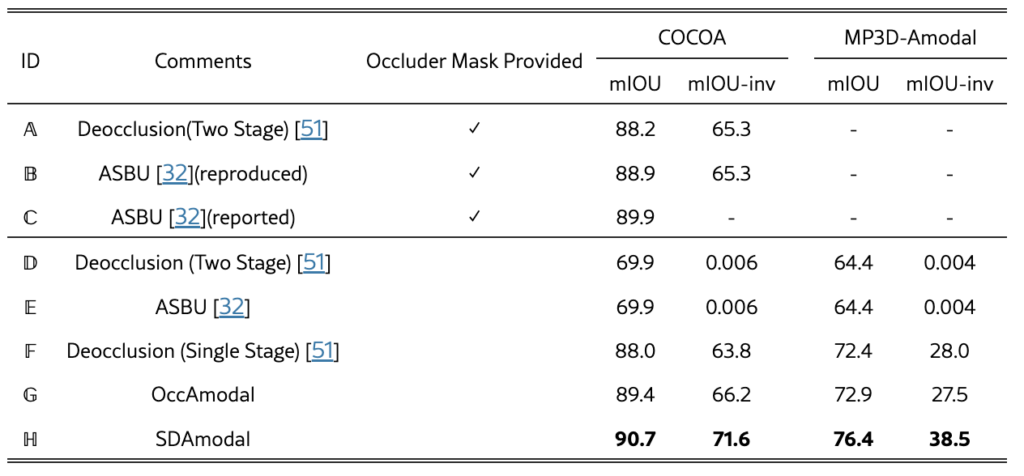
저자는 모델 성능 평가를 위해 COCOA와 MP3D-Amodal 데이터셋을 사용하였으며, 공정한 비교를 위해 비교에 사용한 Deocclusion, ASBU (Amodal Segmentation by Bottom-Up Completion)와 동일한 설정을 적용하였습니다. 평가 척도로는 Amodal Mask의 정확도를 나타내는 mIOU와 Occluded Region의 예측 정확도를 평가하는 mIOU-inv를 사용했다고 합니다. 일반적인 mIOU는 객체 전체에 대해 Ground Truth Mask와 예측된 Mask 간의 IOU를 계산하지만, mIOU-inv는 가려진 영역만을 대상으로 평가해서 모델이 가려진 부분을 얼마나 정확히 예측하는지 측정한다고 하네요.
Ablation Study
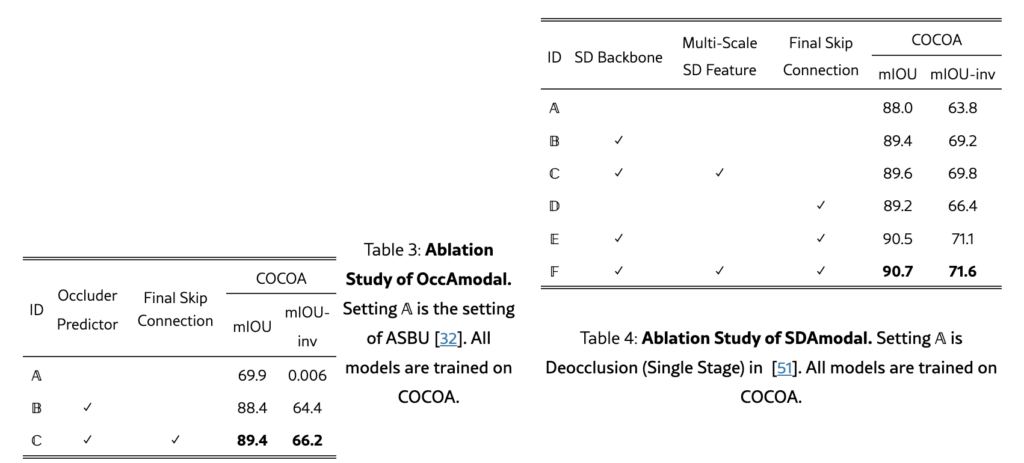
OccAmodal에 대한 Ablation Study에서는 Occluder Mask의 중요성과 Skip Connection의 효과를 분석하였습니다. Occluder Mask를 사용하지 않고 Amodal Mask를 예측한 경우보다 Occluder Mask를 포함했을 때 아래 표와 같이 성능이 크게 향상되었습니다. 또한, U-Net의 마지막 레이어에 Skip Connection을 추가한 경우에서는 결과가 더 개선되었습니다. SDAmodal의 Ablation Study에서는 Stable Diffusion Backbone이 기존 ResNet 인코더의 성능보다 좋은 점을 알 수 있었고, Multi-Scale Feature를 활용한 강점도 알 수 있었습니다. 마지막 레이어에 Skip Connection을 추가하는 것의 의미도 알 수 있었습니다.
Comparison with State-of-the-Art
SOTA 모델(ASBU, Deocclusion)과의 비교에서는 SDAmodal과 OccAmodal이 Occluder Mask 없이도 기존 모델보다 좋은 성능을 나타냈습니다. 모든 모델은 COCOA 데이터로 학습 한 뒤 COCOA와 MP3D-Amodal 데이터셋으로 평가했는데, ASBU와 Deocclusion은 Occluder Mask가 없을 때 성능저하가 큰 반면, OccAmodal은 Occluder Predictor 덕분에 높은 점수를 보인 것 같습니다. 특히, SDAmodal은 COCOA 데이터셋으로만 학습했을 때 MP3D-Amodal에서 높은 일반화 성능을 보였습니다. Stable Diffusion Backbone이 클래스 agnostic 하다는 점을 어필하려고 넣은 것 같습니다.
안녕하세요 영규님 좋은 리뷰 감사합니다.
MP3D 데이터셋이 표를 보니 기존 데이터셋들에 비해 카테고리의 수가 굉장히 많이 늘었는데 카테고리 수가 굉장히 많아지게 된다면 long-tail문제가 생길 것으로 예상되는데 long-tail 문제에 대한 저자의 고찰이 있었는지 궁금합니다. 제가 Amodal Completion task를 잘 몰라서 특정 카테고리의 데이터가 적다면 해당 rare한 카테고리에 대해서 모델이 과적합되지 않을까하는 생각에 질문합니다.
감사합니다.
김영규 연구원님 좋은 리뷰 감사합니다.
Occluder Mask를 통해 가려진 대상역역이 아니라 대상을 가리는 객체의 윤곽에 대한 정보를 예측한다는 점이 독특한데 해당 논믄이 처음으로 고안한 방식인디 궁금합니다.
또한 Authentic Ground Truth Amodal Mask는 GT Amodal Mask와는 다른것인지 궁금합니다.
마지막으로, MatterPort3D는 기존의 real 데이터로 보이는데 기존 어떤 task에서 사용되던 데이터인지 궁금합니다.
감사합니다!
안녕하세요 ! 좋은 리뷰 감사합니다. Amodal segmentation을 수행할 때 한계점으로 3D에 존재하는 다양한 객체들이 2D로 투영될 때 생기는 복잡한 occlusion과 amodal segmentation dataset이 synthetic 데이터셋이라는 점을 언급해주셨는데요, 올려주신 데이터셋 표를 보면 기존에 WALT이라고 하는 데이터셋은 amodal gt를 가지고 있으면서 REAL 데이터로 구성되어 있는 것 같습니다. 이 WALT이 categories가 2개인 데이터셋 같은데 본 제안된 MP3D같은 경우 427개로 보아 카테고리가 더 많을 수록 이점이 잇는 것인지 궁금합니다.
또, 학습 과정에서 사용하는 uncertainty weighted segmentation loss에서 pixel의 uncertainty를 가중치로 할당하여 어떻게 loss가 계산되는지 추가 설명 부탁드립니다.
감사합니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
1. OccAmodal에서 Occlusion Boundary 계산은 어떻게 하나요? edge 같은 느낌인 거라고 이해해도 될까요? 그리고 이를 modal mask와 함께 인풋으로 들어갈 때, 함께 들어간다는 것이 실제로 코드레벨에서 어떻게 작동하는 것일까요?
2. Uncertainty weighted segmentation loss는 이전 연구들에서 사용되던 loss인가요?
식이 있으면 글과 함께 보면서 이해하는 데 더욱 도움이 될 것 같습니다!