안녕하세요. 본 논문은 few-shot learning에 관한 논문입니다. 제목에서 알 수 있듯이 데이터 수집 비용 없이 기존의 정보를 활용해 추가 데이터를 생성하여 few-shot learning의 성능을 높인 논문입니다. 특히 few-shot learning의 어려움의 이유로 적은 학습 데이터로 인한 bias를 언급하며 분포를 calibration할 수 있는 데이터를 생성하는 방법론입니다. 자세한 리뷰는 아래를 참고해주세요
Few-shot Learning
Few-shot learning 관련 논문을 3번째로 다루기에, 해당 분야에서 사용되는 용어는 친숙하시겠지만 한번 더 다루겠습니다. Few-Shot Learning은 제한된 수의 학습 데이터(특히 클래스당 10개 이하의 샘플)만을 사용해 학습하는 방법에 대한 연구입니다. 따라서 해당 분야는 데이터 부족 상황에서도 모델이 일반화 능력을 갖추도록 만드는 데 중점을 둡니다. Few-Shot Learning은 일반적으로 N-way-K-shot 형태로 정의됩니다.
- N-way: 학습 및 테스트에 사용되는 클래스의 수.
- K-shot: 각 클래스당 제공되는 학습 샘플의 수.
- 예: “5-way-1-shot” 문제는 5개의 클래스를 대상으로, 각 클래스에서 샘플 하나로 학습하고 새로운 샘플을 분류해야 함.
또한 일반적으로 데이터는 다음 두 가지로 구분됩니다:
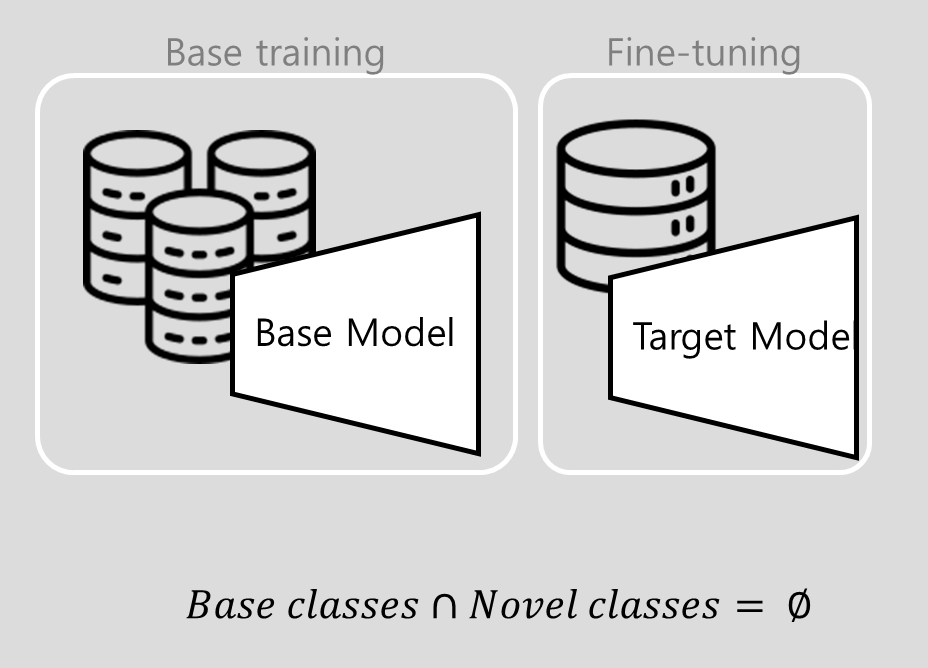
- Base classes: 초기 학습에 사용되는 클래스.
- Novel classes: Target task 수행을 위해 등장하는 새로운 클래스.
이때 base classes와 novel classes 사이에 공통되는 class는 없음이 가정됩니다.
논문 소개
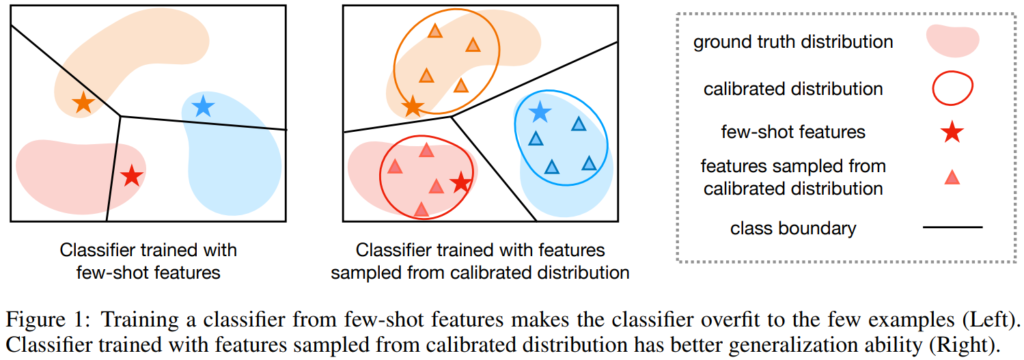
소량의 데이터를 활용해 학습하는 Few-shot Learning은 학습 데이터를 통해 모델을 업데이트 하는 기존의 Supervised Learning 과 동일한 메커니즘을 갖음에도 별개의 분야로 나뉘어졌습니다. 그 이유는 적은 수의 데이터로 학습하는 프로세스에서 발생할 수 있는 어려움 때문입니다. 데이터 편향으로 인한 모델의 일반화 성능 하락은 Few-shot Learning이 해결해야하는 대표적인 문제 중 하나입니다. Figure1은 소량의 데이터가 어떻게 모델의 일반화 성능을 하락시키는지 나타내는 그림인데요, 데이터 선별시에 분포를 고려할 수 없기 때문에 선별된 데이터가 대표성이 낮더라도, 해당 데이터가 클래스를 대표하는 값이 되어 모델의 일반화 성능을 해칠 수 있습니다.
본 연구는 augmentation을 통해 novel class 데이터를 보충하여 최종 target model의 일반화 성능을 개선하는 방법론에 속하며, 해당 연구 방법론 중에서 클래스의 분포를 고려해 bias를 해결하는데 집중한 최초의 방법론입니다. 장점으로는, 학습된 base class의 분포 정보를 활용하여 nover class date를 합성하는 연구로서, 기존에 제안된 상용(off-the-shelf) feature extrector에 쉽게 적용가능하고, feature level의 데이터 augmentation으로 학습 비용이 기존 방법론 대비 낮다는 장점이 있습니다.
방법론

위의 알고리즘에서 확인할 수 있듯이 본 연구의 방법론은 간단합니다. base class를 통해 분포의 평균과 분산을 구하고, 해당 정보를 활용하여 novel class의 분포를 정의한 다음, 정의된 분포에서 feature를 샘플링하여 학습 데이터를 증강하는 것 입니다. 수식을 통해 조금 더 자세하게 알아보겠습니다.
먼저 Algorithm1에 Require로 제시된 base class 의 분포를 구하는 수식은 아래와 같습니다. 본 논문에서 class의 statistic은 가우시안 분포라고 가정합니다. 가우시안 분포는 정규 분포(Normal Distribution)의 가장 대표적인 꼴로, 대칭을 이루는 종모양의 분포이며, 평균(µ)과 분산(Σ)을 정의하면 분포 전체를 특정할 수 있다는 장점으로 데이터의 분포를 모델링하는데 자주 사용됩니다. 따라서 우리는 특정 base class(C_i)에 속하는 base class data의 평균과 분산을 구함으로서 C_i의 분포를 특정할 수 있게되며 그 수식은 아래와 같습니다.
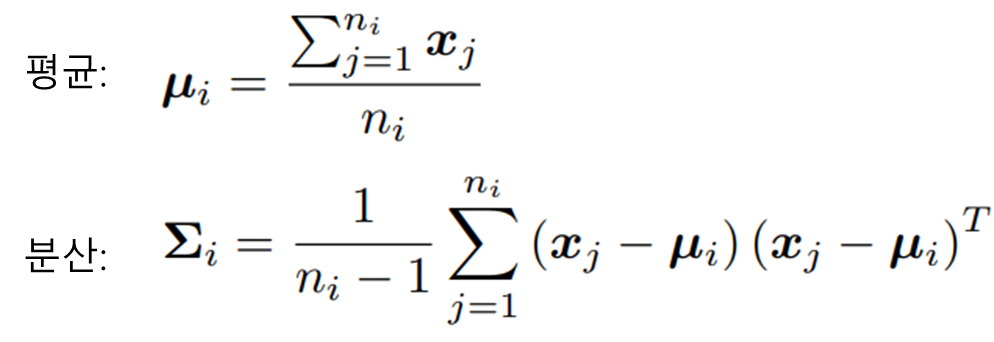
수식은 일반적인 평균/분산을 구하는 수식과 동일하며 feature extrector로 임베딩 된 feature(x)에 대해 평균과 분산을 구하게 됩니다. 여기서 n_i는 클래스 C_i에 속하는 base class의 갯수입니다. 이제 해당 분포를 활용해 novel data의 분포를 정의하게되는데, 이에 앞서 수학적 기법인 Tukey’s Ladder of Powers Transformation을 적용합니다. 이는 분포의 왜도(skewness)를 줄여 데이터를 가우시안 분포에 더욱 가깝게 만들기 위해 주로 사용되는 기법입니다. loss 함수의 적합도 개선을 위해 적용되는 log 스케일 변환을 적용하는 것과 유사한 기법으로 생각하시면 됩니다. Tukey’s Ladder of Powers Transformation의 수식은 아래와 같으며 λ=1일 경우 변환 결과가 원본 함수와 동일합니다. λ=0인 경우 log 변환을 적용하며 λ<1일 경우 분포를 더 평평하게(분산 감소), λ>1일 경우 데이터의 분산을 증가시키도록 동작합니다. 본 논문에서는 λ = 0.5로 설정되었으며, 해당 변환은 base data가 아닌, novel data에 속하는 support set과 query set에 적용됩니다.
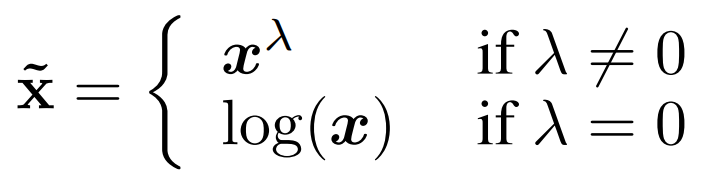
마지막으로 본 연구의 메인이 되는 novel data의 분포 생성 방법입니다. 분포는 feature extretor로 임베딩 된 few-shot novel data와 가장 가까이에 있는 base distribution의 평균을 활용하여 novel data의 분포를 정의되며 수식은 아래와 같으며, 본 논문에서는 k = 2로 설정되었습니다.
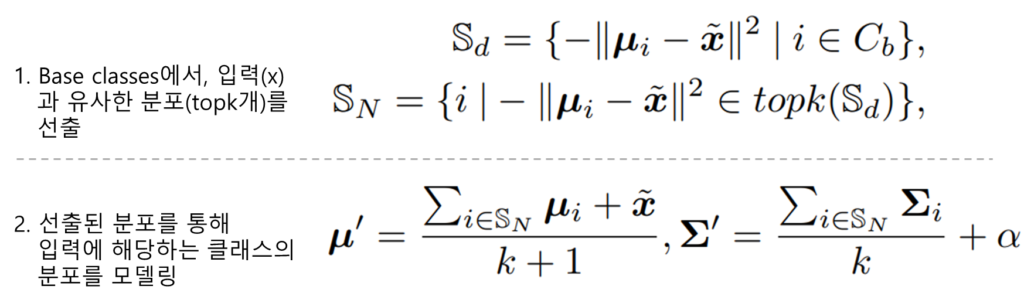
마지막으로 Sampling은 간단합니다. 정의된 분포에서 랜덤 샘플링하여 클래스 y에 속하는 데이터 x를 생성합니다. 데이터의 생성을 위해서는 다변량 정규 분포에서 랜덤 샘플링하는 np.random.multivariate_normal 모듈이 사용되었으며, 클래스 당 750개의 데이터를 샘플링 하였습니다. 이렇게 증강된 데이터를 활용하여 (classification task의 경우) Target task를 수행하는 분류기를 학습하게 됩니다.(라벨이 존재하므로 일반적인 cross-entropy 적용 가능)
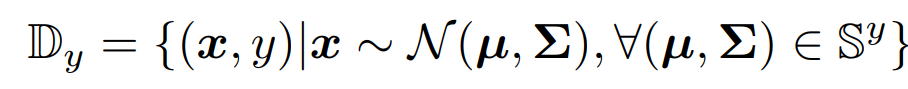
실험
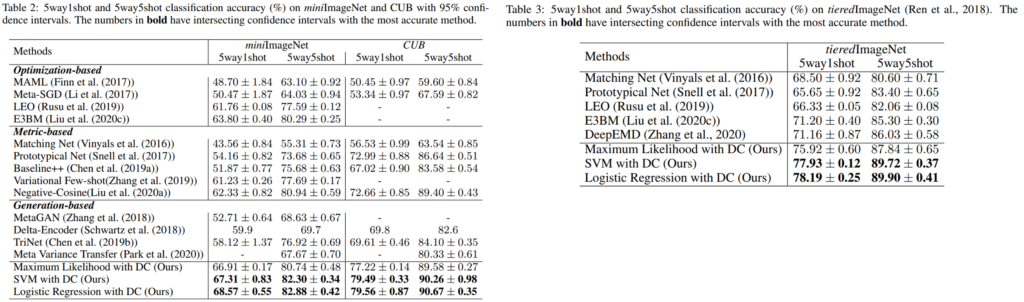
가장 먼저 제공된 정량적 평가는 SOTA와의 비교실험(Table2-3)입니다. 비교적 쉬운 데이터인 miniImageNet와 CUB과 이에 비해 real-world에 가까운 데이터셋인 tieredImageNet이 평가에 사용되었으며, 5way 1shot/5way 5shot 세팅에서 제안된 방법론(DC)를 간단한 분류기 (Maximum Likelihood./SVM/Logistic Regreesion)에 적용하였음에도 우수한 성능을 보였음을 확인할 수 있습니다. 또한 해당 방법론은 다른 off-the-shelf 방법론에 쉽게 적용할 수 있어, 분류기 성능 개선시에 더욱 SOTA 대비 높은 성능을 달성 할 수 있습니다.
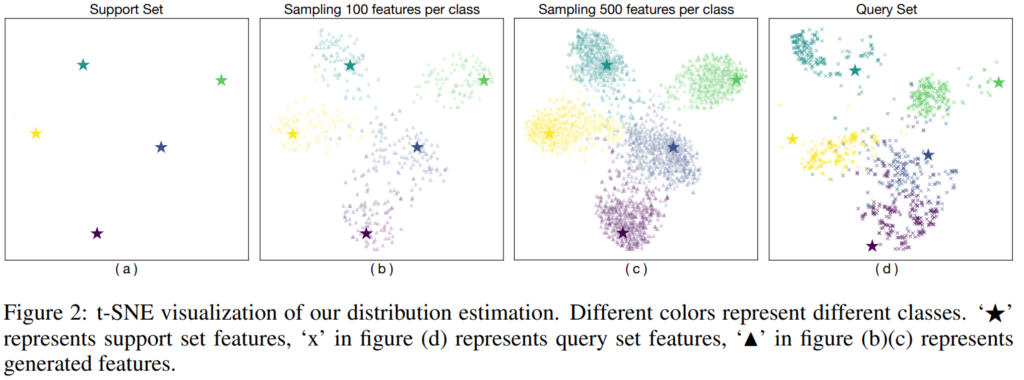
다음은 제안 방법론의 이점을 잘 보여주는 시각적 분석 결과(Figure2)입니다. 위의 (a)가 기본적으로 임베딩된 novel class의 feature(support set)이며, (b)와 (c)는 제안 방법론(DC)로 생성한 feature를 같이 표현공간에 나타냈습니다. 이때 (b)는 클래스당 100개의 샘플을 (c)는 클래스당 500개의 샘플을 생성했습니다. 가장 우측의 (d)는 실제 전체 query set의 임베딩 결과입니다. (query set과 support set은 모두 novel classes 데이터이며, query set이 support set을 포함함. support set은 Few-shot learning 학습에 사용되는 소량의 데이터이며 query set은 test에 사용됨) 결과에서 확인할 수 있듯이 (b)는 query 분포를 잘 나타내고 있으며, 일부 cover 되지 않은 영역이 있지만, 더 많은 sample을 샘플링 했을 때(c) 이러한 문제가 해결됨을 시각적으로 나타냈습니다.
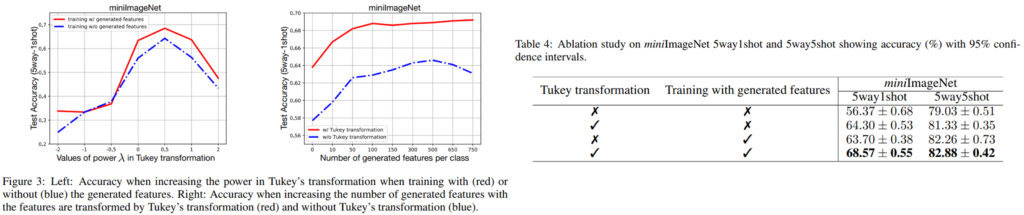
마지막으로 Ablation study입니다. 먼저 사용된 모듈로 novel data의 왜도를 감소하여 학습을 원활하게 하는 Tukey 변환을 적용하는 것과 novel data의 분포를 예측해 feature를 증강하는 기법에 대한 ablation study가 Table4에 제공 되었으며, 두 모듈이 성능개선에 효과적이였음을 보였습니다. 다음으로 각 기법에 사용된 하이퍼파라미터에 대한 효과를 분석했는데, 모든 파라미터에 대해 전반적으로 성능 개선이 있음을 확인할 수 있습니다.
이상으로 논문에 대한 리뷰를 마치겠습니다. 편향을 줄이는 것에 집중한 해결책이 궁금하여 읽게 되었는데, 데이터 단위의 분포 보정보다는 클래스 단위의 보정 기법이 많이 사용되는것 같습니다. 제가 실험중인 방법론은 데이터 단위의 모델링에 집중하고 있어 아쉽습니다. 해당 방법론을 실험중인 방법론에 적용 가능한지 테스트 해봐야겠습니다. 다음번엔 조금 최신 논문으로 리뷰하도록 해보겠습다. 감사합니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
본 논문에서는 base class에 대해 feature extrector로 임베딩 시켜 이들 분포의 평균과 분산을 구하고, 해당 정보를 활용하여 novel class의 분포를 정의한 다음, 정의된 분포에서 feature를 샘플링하여 학습 데이터를 증강한다고 설명해주셨습니다. 그렇다면 class들을 임베딩 시키는 feature extrector에 따라 성능에 영향을 미칠 것 같은데 논문에서는 이러한 부분에 대해 언급이 있을까요?
감사합니다.
안녕하세요 정의철 연구원님. 질문 감사합니다.
임베딩 이후의 feature를 활용하여 데이터 증강을 하기에 질문 주신것처럼 feature extrector의 성능의 영향을 받게 되는데요, 다만 해당 방법론의 장점이 off-the-shelf extrector에 적용 가능함임(Plug-and-play)에 따라, extrector 성능에 따른 성능 하락은 다루지 않습니다. 다만, WideResNet을 포함한 다양한 backbone에 대해서 해당 방법이 효과를 보였음을 보이는 ablation study 등은 존재합니다. 감사합니다.
안녕하세요 유진님, 좋은 리뷰 감사합니다.
제가 few-shot learning 연구에 대한 전반적인 흐름을 깊게 따라가 본 적이 없어 생긴 단순한 궁금증이 몇개 있습니다.
1. few-shot learning 관련 태스크들은 다운스트림 태스크로써 보통 object-centric한 classification 으로만 상정하여 실험을 진행하는 건가요?!
2. data 분포가 imbalanced해서 발생할 수 있는 모델의 bias 현상이 본 방법론을 통해 완화될 수 있는 것으로도 이해해도 될까요?
3. novel class에 해당하는 분포 정의는 무조건 base class에 대한 domain distribution 을 따르게 되나요? 만약.. 그렇다면 novel class 분포가 완전히 domain이 다른 class에 대해서는 대응을 못하는 것일지 궁금합니다. (정리하면.. 해당 domain 관련 문제가 domain adaptation 분야에서 말고도, 이 few-shot learning 연구에서도 같이 고려될 수 있는 문제일지 궁금합니다)
감사합니다.
안녕하세요 이재찬 연구원님. 질문 감사합니다.
각 질문에 대해 답변드리겠습니다.
1. 제가 소개한 논문이 classification이 다수여서 혼란스러우셨을텐데, 다양한 테스크에 대해 해당 연구가 진행되고 있습니다. Object-detection, Image Segmentation 등 다양한 비전 테스크에서 연구가 되고 있으며, 다만, 해당 연구들이 최근에는 VLM 모델에서 zero-shot Learning 등을 이용해 과제를 수행는 데에 집중하고 있는 듯 합니다.
2. 네 맞습니다. base class의 분포를 활용하여 기존 방법론 대비 편향 등을 완화하는데 사용될 수 있습니다.
3. 해당 질문에 대한 답변은 맞다, 아니다로 단순히 답변드리기 어려운데요, 세상에 존재하는 모든 데이터가 표준 정규분포를 갖는다는 가정하에, 인코더가 모델링한 공간(즉, 메니폴드 공간)에서 동일한 분포를 갖을것이라는 가정하에 위와같은 설계가 진행된 것 같습니다. 그러나 일반적으로는 메니폴드 공간이 모든 클래스 카테고리에 선형적으로 모델링하기 어렵습니다…..
== 즉, 정리하면 few-shot learning 을 통해 기존 모델을 novel class에 대해 확장할 때 해당 방법론이 동작하는지의 여부는 각 세팅에서 실험을 해봐야 알 수 있을 것 같습니다. ==
다만 다른 연구들과 마찬가지로 단 하나의 데이터가 아닌 miniImageNet, tieredImagent, CUB 등 3가지의 다양한 데이터셋에 대해 제안 방법론이 효과적이였음을 보임으로서 해당 접근법의 일반화 가능성을 확인할 수는 있습니다. 감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
첫 번째 그림에서 말씀해주신 few shot setting에서의 편향 발생의 원인과 실험 테이블을 보고 생긴 의문인데, 평가 시 사용할 클래스와 클래스별 query set 모두 매번 랜덤으로 추출하는 것인가요? 평가할 클래스는 정해져있는데 샘플은 매번 뽑는다든지, 클래스와 샘플 모두 바뀌는 것인지 또는 다른 방식인건지 궁금합니다.
태스크마다 데이터셋마다 다를 수 있겠지만, zero shot에선 특정 데이터셋의 base/novel 클래스를 어떻게 나눌 것인지에 대한 학계 내 합의가 있는 경우를 많이 봐왔어서 전통적인 few shot은 어떤 방식으로 실험하는지 궁금합니다.
감사합니다
안녕하세요 김현우 연구원님. 질문 감사합니다.
우선 데이터셋 설명이 미흡한점 죄송합니다. 우선 few-shot learning에 사용되는 데이터셋 벤치마크들은 비교를 위해 기존 방법론의 세팅을 따르는것이 일반적이며, 사전에 novel class와 query를 정의하는 데이터셋도 존재합니다. 해당 방법론은 전자로서 기존의 방법론들의 정의해둔 방식을 따랐습니다. 감사합니다.
안녕하세요, 황유진 연구원님. 좋은 리뷰 감사합니다.
결국 base class 의 데이터를 사전 정보 삼아 novel class의 분포를 보정하는 것 이네요. oversampling에 base class 의 사전 정보를 넣는 느낌인데, 아이디어가 간단하면서도 신기합니다.
해당 방법은 base class가 novel class의 분포를 어느 정도 반영할 수 있다는 전제가 깔려있는 것 같습니다. 밸런스가 잘 맞게 수집된 데이터셋에선 잘 동작하겠지만 실제로 bias가 존재하거나 밸런스가 맞지 않는 데이터셋에서 섣불리 적용하기에는 위험해 보이는데요, 혹시 이런 케이스에 대한 설명이 논문에 있나요?
감사합니다.
안녕하세요 허재연 연구원님. 질문 감사합니다.
말씀해주신 것처럼 bias가 존재하거나 밸런스가 맞지 않는 데이터셋에서는 적용이 어려울 수 있습니다. 다만, 일반적으로 few-shot learning은 base class에 대한 학습이 충분하다는 가정하에 설계되기에 해당 문제를 다루지 않은 것 같습니다. 말씀해주신 위험이 발생할 수 있기에 항상 적용 가능한지 실험을 통해 확인해보는것을 추천드립니다. 감사합니다.