안녕하세요 박성준 연구원입니다. 제가 오늘 리뷰할 논문은 조금은 생소할 수 있는 task인 Sign Language(수화) Video Retrieval를 다룬 논문입니다.
Introduction
Sign Language Video Retrieval은 두가지의 목표를 갖는 task입니다. 하나는 text-to-video retrieval(T2V)로 text가 주어지면 text가 설명하는 올바른 video를 검색하는 task이고 하나는 video-to-text retrieval(V2T)로 video가 주어지면 video를 설명하는 올바른 text를 검색하는 task입니다. Sign Language Video Retireval은 T2V와 V2T 둘 모두 수행 가능해야하고 특히나 일반적인 video retrieval과 다르게 주어지는 video가 수화영상이라는 점, 그리고 text가 video의 전반적인 행동을 설명하는 것이 아닌 video 내 사람의 수화를 번역한다는 점에서 fine-grained level의 Video Retrieval이라는 차이점이 있습니다.
제가 평소에 서베이하고 연구하고 있는 분야는 Video Moment Retrieval로 text가 설명하는 video 내 구간(moment)를 검색하는 task로 video를 검색하는 것이 아닌 video 내 구간을 검색하는 task라는 차이점이 있습니다. 하지만, 두 task 모두 video와 text의 representation의 이해가 필요하다는 점, 그리고 일반적인 Video Retrieval보다 fine-grained level이라는 공통점이 있습니다. 결국 video와 text의 representation을 파악하고 다른 두 모달리티의 특징을 활용하는 연구를 찾아보면서 Video Moment Retrieval에 접목시킬만한 아이디어를 찾아보고자 해당 논문을 읽게 되었습니다.
논문의 내용으로 돌아와 Sign Language Video Retrieval은 특수성을 갖는 task로 Sign Language에 대한 이해를 필요로하는 task입니다. 이전의 Sign Language Video Retrieval 연구들은 sign language의 특수성을 고려하지 않고 일반적인 video retrieval과 같은 방식인 sign language video와 text의 fine-grained model alignment를 통해 수행하고 있었습니다. 저자는 sign language 데이터셋은 fine-grained annotation이 부족하고 sign language의 내재적 불확실성(uncertainty)로 인해 적절하지 않은 방법이라고 말합니다.
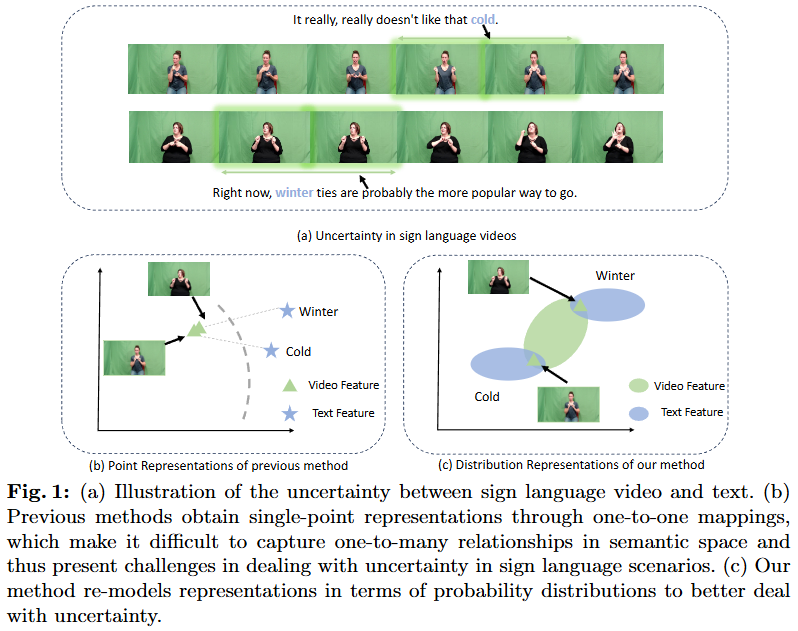
Fig. 1은 sign language의 불확실성을 보여주는 figure입니다. 수화는 일반적인 언어와 다르게 같은 동작이어도 앞선 문맥에 따라 다른 의미를 가지는 단어가 많습니다. Figure에서의 예시로보면 Winter와 Cold라는 의미를 갖는 손동작이 사실은 같은 동작이기에 저자가 말하길 하나의 행동이 하나의 언어로 매핑되는 것은 불가능하다고 말합니다. 이러한 점을 저자는 논문에서 uncertainty라고 표현하고 있습니다. 즉 이러한 uncertainty로 인해서 one-to-one 매핑을 통한 sign language를 이해하려는 시도는 올바르지 못한 시도가 되버립니다.
저자는 이러한 문제를 해결하기 위해서 probability distributions(확률 분포)를 이용합니다. Fig. 1의 (c)에서 시각화한 것과 같이 video feature, text feature를 한 점에 매핑하는 것이 아니라 확률 분포로 매핑해 video 혹은 text의 특정 상황, 문맥에 대응되는 지점을 찾을 수 있도록 매핑하는 것으로 저자는 똑같은 visual representation이라고 하더라도 다른 의미를 모델링할 수 있도록 했습니다. 이렇게 확률분포를 통해 매핑함으로 저자는 sign language가 갖는 특수성을 모델이 이해할 수 있도록했습니다.
추가로 저자는 이 확률분포를 학습시키는 데에 있어서 일반적인 contrastive learning이 아닌 Optimal Transport(OT)를 사용했습니다. Optimal Transport는 두 확률 분포 간의 거리를 계산하고 이를 최소화하는 문제를 다루는 수학적 이론입니다. OT의 기본 아이디어는 두 개의 확률 분포 P와Q 사이의 최적의(Optimal) 이동(Transport) 전략을 찾는 것입니다. visual feature와 text feature를 벡터로 하나의 점으로 임베딩 공간에 매핑하는 것이 아니라 확률 분포의 형태로 매핑하게 되고 이를 학습시키기 위해서는 일반적인 두 벡터에 대한 코사인 유사도를 통한 매핑 방법보다는 OT가 더 효율적이라고 생각했기에 OT를 사용했다고 논문에서 밝히고 있습니다. OT에 대한 자세한 설명은 제가 이전 리뷰[ICLR2024] Multi-granularity Correspondence Learning from Long-term Noisy Videos – Part 1 에서 다룬적이 있으니 이전 리뷰를 참고해주시고 오늘은 OT에 대한 개념적인 설명은 생략하도록 하겠습니다.
즉, 정리하면 저자는 이전 Sign Language Video Retrieval 연구들이 한 동작에 하나의 단어를 one-to-one 매핑하는 방식이 갖고 있는 문제점(한 동작이 다양한 문맥에서 여러 의미를 가짐)을 지양하고 one-to-many 매핑이 가능하도록 visual, text feature를 벡터로 표현하지 않고 probability distribution으로 매핑합니다. 이 과정에서 probability distribution에 적합한 학습 방법인 OT를 도입하여 문제를 해결합니다. 이에 따른 저자의 contribution입니다.
- video와 text를 probability distribution으로 간주하여 uncertainty를 포착하는 새로운 관점을 제안합니다.
- probability distribution 사이의 fine-grained level의 측정을 위해 Optimal Transport를 도입합니다.
- 실험 결과 3가지 벤치마크에서 SOTA를 달성하여 제안하는 방법의 성능을 증명합니다.
Preliminary
먼저 저자는 이전 연구의 흐름에 대해 간략히 소개하고 있습니다. T2V의 목표는 text query t^q에 가장 매칭되는 v \in V를 검색하는 것입니다. 반대로 V2T의 경우에는 video query v^q에 가장 매칭되는 t \in T를 검색하는 것입니다. 먼저 Visual Encoder F_v와 Text Encoder F_q를 거쳐 feature 임베딩 V'_i = [v^0_i, v^1_i,...v^{N_v}_i와 T'_i = [t^0_i,t^1_i,...v^{N_t}_i]를 얻습니다. 당연히 N_v와 N_t는 video의 프레임 수, text의 단어 수를 의미합니다. video의 전체적인 특징은 average pooling을 통해 표현되고 문장의 특징은 첫 [CSL] 토큰에 표현됩니다.
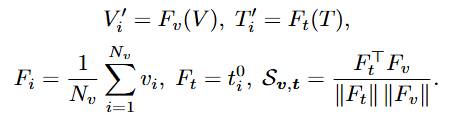
S(t,v)는 text와 video의 유사도를 의미합니다.
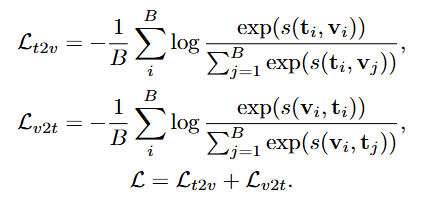
cross-modal contrastive loss는 위와 같이 정의되어 왔습니다.
Method
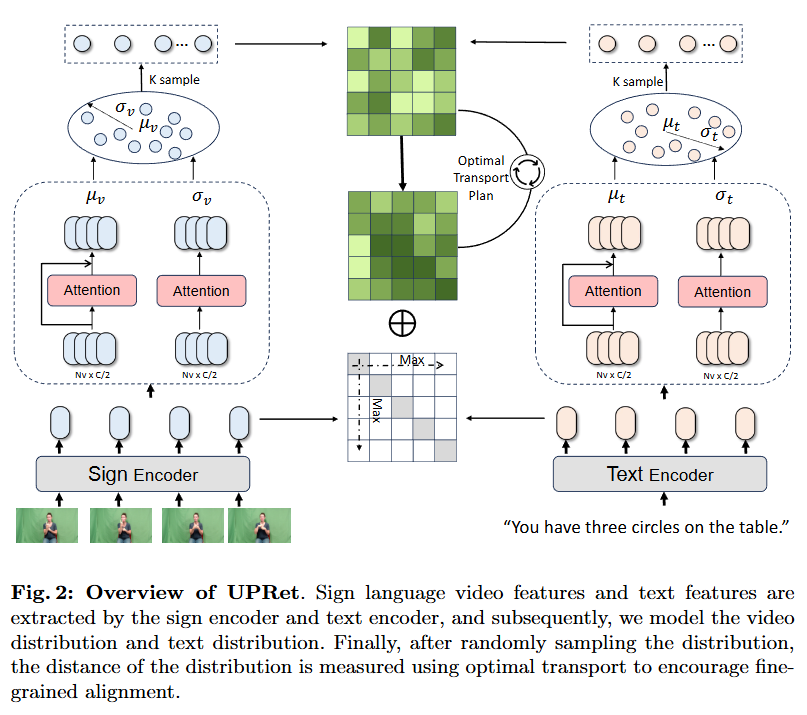
저자가 제안하는 Uncertainty-aware Probability Distribution Retrieval (UPRet)의 구조입니다. 먼저 각 Encoder를 통해 sign(video)와 text의 특징을 추출합니다. 그 후 video distribution과 text distribution을 모델링하고 distribution 사이의 거리는 OT를 통해 계산하는 것으로 sign feature와 text feature를 매핑합니다.
인코더로 저자는 이전 연구인 CiCo에서의 방법을 따라 BSL-1k 데이터셋(sign language 데이터셋)에서 학습된 I3D를 sign 인코더로 사용합니다. 사전학습 데이터셋(BSL-1k)와 target 데이터셋과의 domain 차이를 줄이기 위해 저자는 인코더를 target dataset에 pseudo-labeling을 한 후에 fine-tuning하여 사용합니다. sign language는 domain에 굉장히 민감하기 때문에 이 과정을 추가하는 것만으로도 성능이 많이 개선된다고 합니다. 최종 encoder는 사전학습 인코더와 fine-tuning한 인코더의 가중치 조합으로 사용합니다.
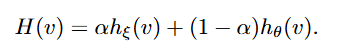
H는 최종으로 사용하는 인코더, h_{\xi}는 fine-tuned 인코더, h_{\theta}는 사전학습된 인코더입니다.
저자는 여기서 그치는 것이 아니라 결국 video와 text의 공통된 임베딩 공간에 매핑을 위해 CLIP을 사용하는데요. video와 text 모두 CLIP의 인코더를 거치는 것으로 같은 임베딩 공간 내 feature를 추출합니다. video feature는 위에서 I3D인코더를 거쳐 나온 feature를 CLIP의 video encoder를 거치는 것으로 표현됩니다.
즉, 최최종 video feature는 V = F(H(v)), text feature는 T = G(T) \in \mathbb{R}^{N_t \times D}로 얻게 됩니다. sign language가 굉장히 fine-grained level에서 진행된다는 것을 확인할 수 있는 대목입니다. 인코더로 그냥 추출하는 것이 아니라 인코더에서 특징을 추출할 때에도 잡기술이 많이 들어가네요. 본 리뷰에서 기술하지는 않았지만 Related Work에서 기존 연구는 과적합을 해결하는 데에만 집중하고 one-to-one mapping의 문제를 해결하지 않았다고 비판했었는데 확실히 과적합을 방지하는 것도 sign language 도메인에서는 굉장히 중요한 작업으로 보입니다.
Distribution Modeling
무튼, 다음으로 넘어와 feature를 probability distribution으로 매핑하는 방법입니다. 한마디로 요약하면 가우시안 분포로 변환하는 과정입니다. 가우시안 분포가 uncertainty를 모델링 하는 데에 있어 가장 많이 사용되는 방법인 동시에 가장 효율적인 방법인 것 같네요. 기존 벡터의 끝점, 즉 임베딩 공간에 매핑되는 지점을 분포의 중심으로 설정하고 분산 벡터를 통해 분포의 범위를 나타낸다고 합니다. input feature F \in \mathbb{R}^D가 주어졌을 때 F를 F_{\mu} \in \mathbb{R}^{D/2}와 F_{sigma} \in \mathbb{R}^{D/2}로 나눈 후에 multi-head attention을 사용해 평균 벡터 \mu와 분산 벡터 \sigma^2를 예측합니다.
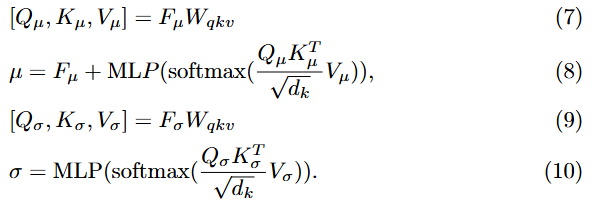
매핑되는 distribution에서 mean 즉 중간 지점은 최대 의미 확률(maximum probability of meaning)을 의미하며 분산은 불확실성(uncertainty)를 의미합니다. 즉, Introduction의 Fig. 1 (c)와 같이 매핑되며 임베딩 공간 내에 확률로 매핑되기에 같은 단어 혹은 동작이어도 여러가지로 매핑되는 one-to-many 매핑이 가능하게됩니다. 이후 feature refinement를 위해 K개의 distribution이 선택되어 reparameterization과 풀링을 통해 input feature와 최대한 유사하도록 설계됩니다.
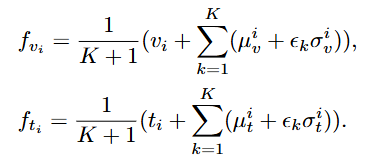
Optimal Transport
OT는 video 분포 \mu_v와 text 분포 \mu_t 사이의 수송 비용을 최소화하는 수송 계획 T를 찾는 것을 목표로 합니다.
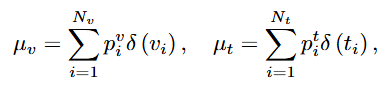
여기서 \delta(\cdot)는 Dirac delta function이라고 합니다. 정확히 무슨 함수인지는 잘 모르지만 확률분포를 표현할때 쓰는 함수라고 합니다(Distribution Modeling에서의 과정과 같은 함수 같은데 논문에서 추가설명이 없어서 잘 모르겠네요…. ㅎ). 아무튼
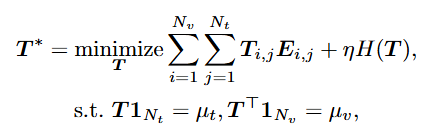
위의 OT 과정을 통해 최적화되는게 Sinkhorn-Knopp 알고리즘이 사용되어 H(T) = \sum_{i,j}T_{i,j}(\mathrm{log}T_{i,j} - 1)는 음의 엔트로피 정규화이고 여러번의 반복을 통해 최적화됩니다.
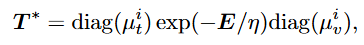
여기서 i는 반복을 나타내는 notation입니다. OT거리 D_{v,t}는 다음과 같이 표현됩니다.
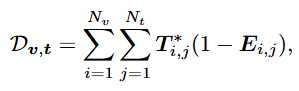
OT를 활용한 최적화 loss는 다음과 같습니다.
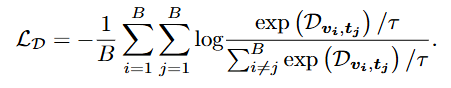
OT에 대해서 공부했다고 생각하는 데도 논문에서의 수식이 많이 나오니 무슨 말인지 헷갈리네요. OT에 대한 부분은 일단 두 확률분포의 거리를 계산해서 거리를 최소화시키는 최적화 기법으로 Sinkhorn-Knopp 알고리즘은 반복하는 것으로 계산 cost도 적으면서 동시에 두 확률분포를 같은 공간에 매핑하는 방법으로 학습시킬 수 있다 정도로 이해하고 넘어가면 될 것 같습니다. 조금 더 간단하게는 두 벡터사이의 코사인 유사도와 같은 역할을 수행해 두 확률분포 사이의 유사도를 계산한다 정도로 이해하면 될 것 같습니다. 수식의 정확한 설명은 추후에 OT에 대해 조금 더 공부한 뒤에 추가해두겠습니다…
끝으로 방법론을 정리하면
- video와 text로부터 인코더를 통해 feature를 추출한다.
- feature를 probability distribution으로 바꿔 표현한다.
- distribution을 OT를 활용해 학습한다.
입니다.
Experiments
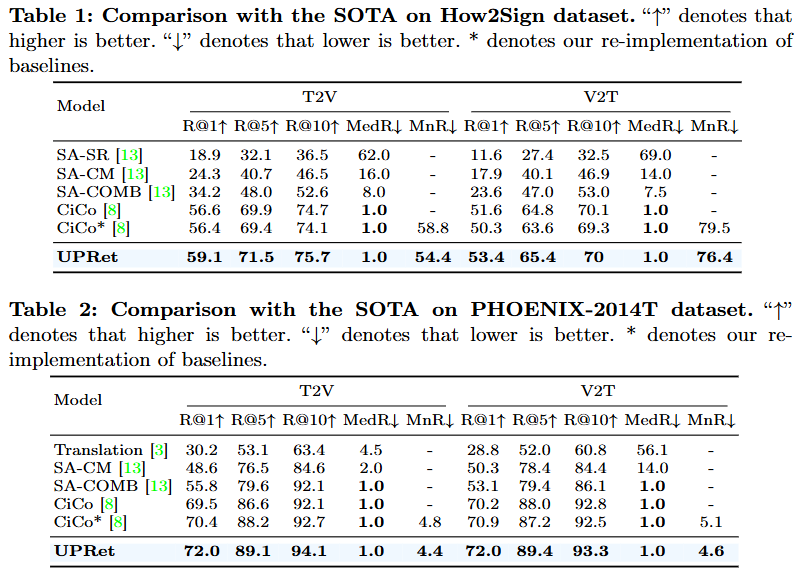
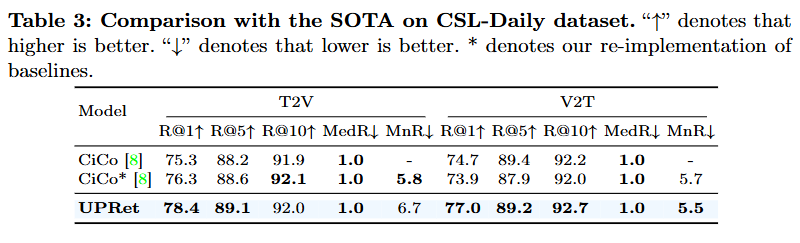
Table 1~3 모두 sign language video retrieval 데이터셋입니다. 사실 실험 파트는 성능이 기존 SOTA 모델에 비해 좋다말고는 크게 얘기할 부분은 없는 것 같습니다. 저자도 데이터셋의 특징을 설명하기 보다는 자신들이 제안하는 방법이 one-to-many mapping도 가능하고 확률 분포를 통한 매핑 방식의 장점을 실험적으로 증명했다고 설명하고 있네요.
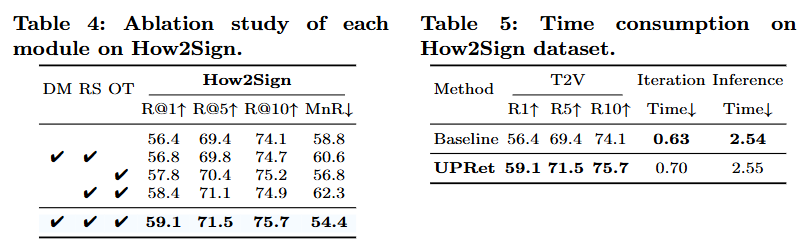
다음은 Ablation Study입니다. How2Sign 데이터셋(Sign Language Video Retrieval에서 가장 널리 사용되는 데이터셋)에서 평가가 진행되었으며 Table 4.는 저자가 사용하는 각 Distribution Modeling, Random Sampling, Optimal Trasport를 사용했을 때의 성능 차이를 보여줍니다. Random Sampling은 OT를 통해 학습을 진행할 때 랜덤하게 video text를 산출하는 것을 말하는데 일반적으로 학습할 때 train=True로 설정해서 shuffle하는 것과의 차이점이 무엇인지는 잘 모르겠네요. Method에서도 사실 중요하게 설명하지 않아 넘어갔는데 Ablation에서 다루는 것을 보니 일반적인 학습과는 다른 것 같으나 코드가 공개되어 있지 않아서 확인을 해보지 못한 점 양해바랍니다. 아무튼 저자가 주장하는 것과 마찬가지로 일반적인 contrastive learning에 비해서는 각 모듈을 포함시킬때의 성능이 점진적으로 좋아지는 것으로 각 모듈이 저자의 의도대로 성능을 올리는 데에 일조하고 있다고 봐도 좋을 것 같습니다. Tab 5.는 inference time에 대한 비교인데 베이스라인에 비해 확률 분포를 사용하기에 약간 속도가 느려지기는 했지만, 사람이 느끼기에는 큰 차이가 없다는 것을 저자가 강조하며 자신의 방법론이 속도에 비해 성능을 많이 올린 효율적인 모델이라는 점 또한 강조하고 있습니다.
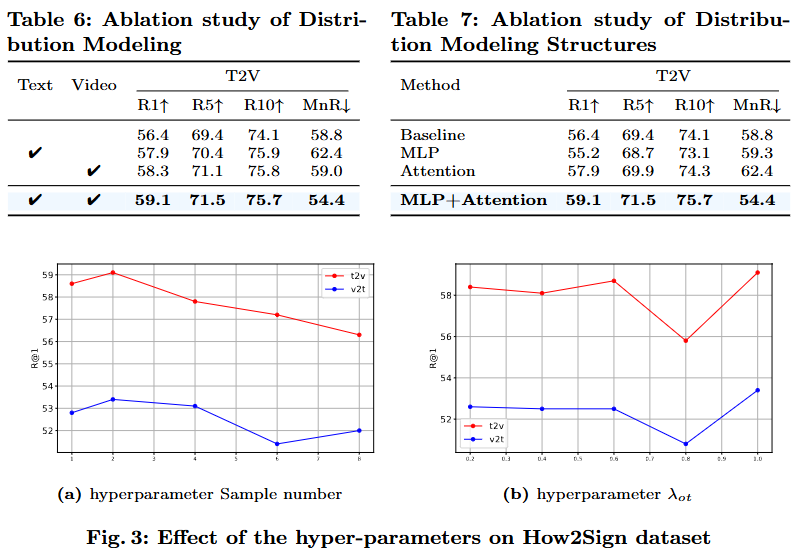
Tab. 6은 Distribution Modeling을 각 모달리티별 적용을 했을 때와 안했을 때의 비교로 video를 distribution modeling했을 때 성능이 text만을 모델링했을 때보다 좋은 성능을 보여주고 있고 두 모달리티 모두 확률 분포로 매핑했을 때의 성능이 더 좋은 것을 확인할 수 있습니다. Tab.7은 Distribution Modeling 과정에서 MLP와 Attention을 모두 사용했을 때 더 효율적인 것을 설명하고 있네요. Fig.3은 저자가 파라미터를 어떻게 설정하냐에 따른 성능 비교로 sign language video retrieval은 굉장히 fine-grained level에서의 alignment를 연구하다보니 파라미터를 어떻게 설정하는 지에 대한 정보도 논문에서 리포팅을 자주 하는 것 같습니다. 저자가 여러가지 실험을 통해서 최적의 파라미터를 찾았다는 것을 강조하고 있습니다.
사실 최근까지의 Moment Retrieval 연구를 대부분 follow up해서 video와 text를 fine-grained level에서 align하는 다른 task에서의 연구가 궁금해서 찾아보게 된 논문으로 Video Moment Retrieval에서 저자의 아이디어를 어떻게 활용해야할 지에 대해서는 조금 더 고민해봐야할 것 같습니다. 나이브하게 생각했을 때에는 Video Moment Retrieval 또한 쿼리에 대응하는 비디오 내 구간이 여러군데 존재할 수 있기 때문에 one-to-many 매핑을 하기 위한 방법으로 해당 논문의 distribution modeling, OT를 차용할 수는 있으나 이미 one-to-many 매핑을 시도한 연구는 존재하고 메인 아이디어로 가져가기에는 약한 느낌이 있네요. 물론 같은 motivation에서 기존에 없던 방식으로 해결하는 논문을 라이팅할 수도 있고(아직 Video Moment Retrieval에서 distribution modeling과 OT를 활용한 논문은 없음) main contribution은 아니어도 sub contribution으로 가져갈 수 있는 아이디어라고 생각하기에 feasibility 실험을 하고 싶은 생각은 있으나 코드 공개가 되어있지 않은게 또 아쉽네요… ㅎㅎ 그래도 video feature와 text feature를 활용하는 효과적인 방법론인 것 같아 재미있게 읽은 논문인 것 같습니다. 좋은 문제정의와 그에 대한 효율적인 해결책을 잘 적용시킨 논문인 것 같네요.
앞으로 Video Moment Retrieval 뿐만 아니라 video와 text 모달리티를 모두 활용하는 여러가지 task의 논문을 서베이하면서 Video Moment Retrieval에서 활용할만한 아이디어를 조금 모색해볼 예정입니다. 혹 video text 멀티모달에 관심이 있으시다면 다음 리뷰도 기대해주시기 바랍니다(?) 리뷰는 여기서 마치도록 하겠습니다. 감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
확률적 임베딩을 만들어낼 때, D차원의 feature를 D/2 차원으로 나눌 때 그냥 반반으로 split해주는 것인가요?
보통 D차원의 feature를 통해 평균, sigma를 만들어주는 방법론들을 많이 봐왔었는데, D/2로 만들고 구하는 것이 다른 논문을 참고한 것인지, 아니면 저자가 그렇게 설정한 이유가 나타나 있는지 궁금합니다.
안녕하세요. 현우님 좋은 댓글 감사합니다.
저자는 몬테-카를로 샘플링을 통해 확률적 임베딩을 생성한다고 언급하고 있습니다. 다만 몬테-카를로 샘플링을 하기 전에 multivariate Gaussian distributiton을 모델링하는 과정에서 multi-head attention을 통해 평균 벡터와 분산 벡터를 구하는데 이과정에서 왜 D/2를 선택했는 지에 대한 선정 이유를 저자가 논문에서 설명하고 있지는 않습니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰감사합니다.
Fig2에 대해 질문이 있습니다. 그림에서 Text Encoder로 “You have three circles on the table”의 문장이 들어가고 이를 설명하는 수화 비디오가 Sign Encoder로 들어가는 것 같습니다. 이후 분포에서 K개를 sampling해서 Optimal Transport를 수행하는 것으로 이해했습니다. 그렇다면 Text와 Video에서 랜덤하게 K개의 샘플이 선택되면 text를 설명하는 비디오 영상의 의미가 불일치 할 수 있는거 아닌가요? 수식을 확인해보았을때는 K개의 샘플을 평균을 내어 Optimal Transport를 수행하는 것 같은데 이 부분이 헷갈려서 질문드립니다.
감사합니다.
안녕하세요 의철님 좋은 댓글 감사합니다.
저자는 random sampling을 통해 sign language의 uncertainty를 학습할 수 있다고 말하고 있습니다. 분포의 평균을 사용하여 샘플의 중심을 결정하는 반면, 분산은 특징의 다양성을 강조한다고 언급하고 있는데 랜덤하게 샘플링하기는 하지만 라벨링이 되어있어 평균을 통해 샘플의 중심(샘플의 평균)을 분산은 OT로 인해 학습되는 것을 그대로 학습하는 것으로 random sampling은 각 샘플을 positive, nagative로 정하는 비율을 랜덤하게 선정했다라고 이해해주시면 될 것 같습니다.
감사합니다.