안녕하세요, 마흔 여섯번째 x-review 입니다. 이번 논문은 2024년도 NeurIPS에 게재된 ImOV3D라고, large scale의 이미지 detection용 데이터셋을 가지고 OV 3차원 검출을 수행하는 논문 입니다.
그럼 바로 리뷰 시작하겠습니다.

1. Introduction
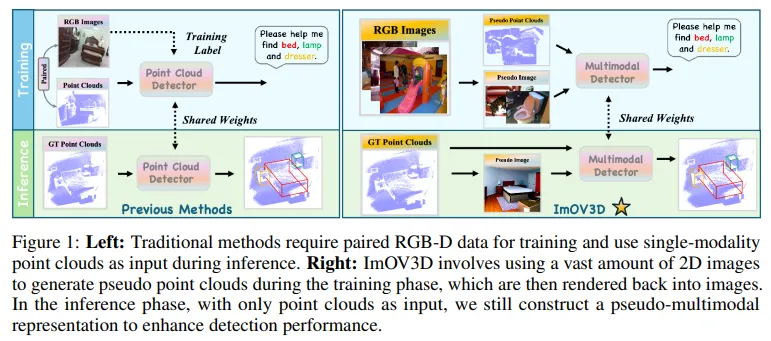
현재 OV-3Det는 기존의 OV 2D 검출기의 도움을 크게 받고 있습니다. Fig.1의 왼쪽 그림처럼 포인트 클라우드와 pair한 RGB 데이터를 사전학습된 2D 검출기로 3차원 수도 라벨을 생성하여 포인트 클라우드에서 부족한 라벨 문제를 해결하고자 합니다. 하지만 이마저도 기존 pair한 RGB-포인트 데이터의 규모가 이미지 데이터셋과 비교하면 굉장히 작다는 한계가 존재하죠. 또한 스크래치 레벨로 학습되는 3차원 검출기는 모달리티 차이로 인해 OV 2D 검출기 모델의 성능을 직접적으로 활용할 수 없다고 합니다. 이러한 상황에서 OV-3Det을 위해 이미지 도메인 지식을 3차원으로 잘 전달할 수 있는 가장 좋은 방법을 고민해봐야 하는 상황 입니다. 본 논문에서는 모달리티의 차이가 직접적인 도메인 사이의 지식을 전달하는데 어려움을 준다는 점을 고려하여 pseudo 다중 모달리티 표현력을 활용하는 방법인 ImOV3D를 제안하였습니다. 먼저 depth와 카메라 파라미터를 추정해서 이미지를 pseudo 3차원 표현으로 리프팅합니다. 또한 렌더링을 통해 포인트 클라우드를 pseudo 2차원 표현으로 변환합니다. 즉 pseudo 이미지, 포인트 클라우드를 각각 만들어서 두 모달리티에서의 표현력을 갖추어 2D→3D로의 지식 전달을 하고자 하는 것 입니다.
Fig.1 오른쪽 그림을 보면 학습과 추론에서 모두 이미지로만 학습을 하고 멀티 모달리티의 정보를 잘 통합해서 OV-3Det의 성능을 향상시키는 것이 본 논문의 목표 입니다. 이미지만을 입력으로 받아서 모달리티의 변환을 이루는게 본 논문의 핵심인데, 크게 2가지로 나누어 볼 수 있습니다.
(1) 이미지 → pseudo 포인트 클라우드
large scale의 이미지 학습 데이터를 monocular depth estimation과 이미지에서는 원래는 알 수 없는 카메라 파라미터를 얻어서 이미지를 pseudo 포인트로 변환합니다. 그리고 이미지 어노테이션을 기반으로 pseudo 3D 라벨을 자동으로 생성하여 3D 검출에 필요한 학습 데이터를 완성합니다. 또한 revision module이라는 걸 설계했는데, 이 모듈은 GPT-4 모델과 normal map 추정을 통해 생성한 pseudo 3차원 데이터의 퀄리티를 향상시킵니다.
(2) pseudo 포인트 클라우드 → pseudo 이미지
pseudo 포인트를 만들었으니 이제는 이 포인트 클라우드에서 자연스러운 텍스처 정보를 가지는 pair한 이미지를 생성할 수 있는 renderer을 학습합니다. 이 과정을 통해 ImOV3D는 추론 중에 포인트만 입력을 받았을 때도 pseudo 멀티 모달리티 3차원 검출기를 활용해서 이미지의 의미론적인 정보를 3차원으로 전달하여 검출기의 성능을 향상시킬 수 있습니다.
2차원의 이미지 학습 데이터로만 학습했음에도 불구하고, ImOV3D는 실제 3차원 데이터가 추론에 입력으로 들어와도 잘 검출하는 결과를 보여줍니다. 추가적으로 3차원 어노테이션 없이도 만약에 작은 스케일의 실제 3차원 데이터를 사용할 수 있다면, ImOV3D는 그 3차원 데이터를 fine tuning해서 pseudo 데이터와 실제 데이터 사이의 갭을 최소화하여 검출 성능을 개선할 수 있다고 합니다.
여기서 본 논문의 main contribution을 정리하면 다음과 같습니다.
- 포인트 클라우와 3차원 주석 없이도 2D 검출용 이미지로만 학습할 수 있는 최초의 OV-3Det 방법인 ImOV3D 제안
- 이미지를 입력으로 pseudo 포인트, 3차원 어노테이션, 그리고 렌더링으로 변환하여 포인트 기반의 멀티모달리티 OV-3Det을 할 수 있는 새로운 pseudo 멀티 모달리티 표현 방식 설계
- 다양한 실험 세팅에서 SUN RGBD와 ScanNet 데이터셋에서 SOTA를 달성
2. Method
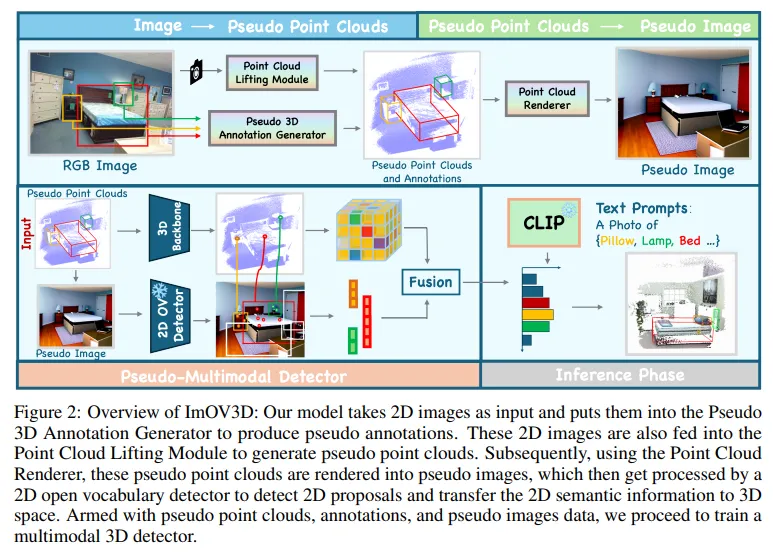
2.1. Overview
간단하게 ImOV3D의 구조를 살펴보면 Fig.2와 같습니다. ImOV3D는 기존 포인트 전용 모델로, OV 3차원 검출기에서 어노테이션된 3차원 데이터셋이 부족하다는 문제를 해결하고자 하였기 때문에, large scale의 이미지용 2D 데이터셋을 사용하여 pseudo 포인트 클라우드와 어노테이션을 생성합니다. 구체적으로 monocular depth estimation 모델을 사용해서 depth 이미지를 생성한 다음에, indoor/outdoor scene에 대해 모두 pseudo 포인트로 변환합니다. pseudo 포인트를 만들고 나면 멀티모달 데이터를 활용하기 위해 renderer를 사용해서 pseudo 이미지로 변환하게 됩니다. 학습 방식은 크게 2단계로, 먼저 pseudo 포인트와 그 어노테이션 정보를 사용해서 사전학습을 합니다. 그 다음에 2D↔3D 데이터셋 간에 도메인 차이를 최소화하는 것을 목표로 adaptation 단계를 수행합니다.
2.2. Point Cloud Lifting Module
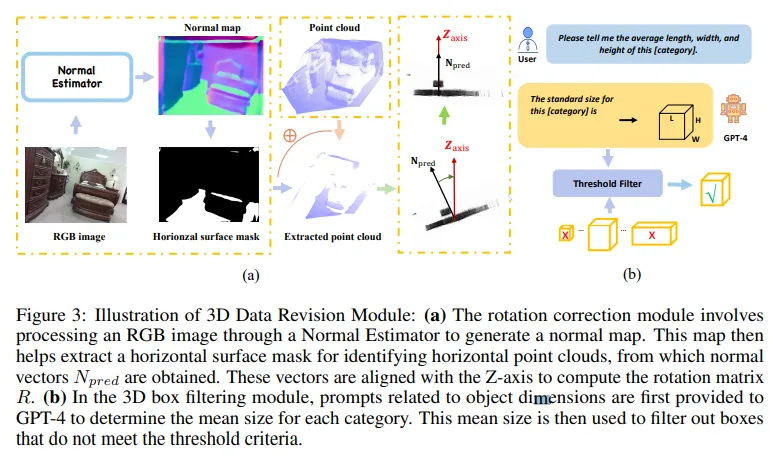
그럼 먼저 pseudo 포인트를 만들기 위한 lifting 모듈을 살펴보도록 하겠습니다. 대규모 3차원 데이터셋의 부족을 해결하기 위해 2D 이미지 \mathcal{I}_{2D} \in \mathbb{R}^{M \times H \times W \times 3}를 psuedo 포인트 클라우드 \mathcal{P}_{pseudo} \in \mathbb{R}^{M \times N \times 3}를 생성하고자 합니다. 하지만 이미지 검출용 데이터셋에는 depth 이미지와 카메라 파라미터가 없다는 문제가 있죠. 이를 해결하기 위해 monocular depth estimation 모델을 사용해서 단일 뷰에 대한 depth 이미지 \mathcal{D}_{metric} \in \mathbb{R}^{M \times H \times W}를 얻습니다. 또한 55도의 FOV와 이미지 dimension을 기준으로 계산된 초점거리를 정의해서 고정적인 카메라 내부 파라미터 K \in \mathbb{R}^{3 \times 3}을 사용하게 됩니다. 그런데 카메라 외부 파라미터는 지정돼있지 않고 고정된 파라미터를 쓰게 되면 포인트의 방향이 임의로 지정되어 정확한 데이터를 생성할 수 없습니다. 이를 위해 Fig.3(a)와 같이 회전에 대한 보정 모듈을 사용해서 바닥 평면이 수평이 되도록 합니다. 먼저 normal estimation 모델을 사용해서 각 픽셀의 surface normal 벡터를 추정하여 normal map을 생성합니다. 생성한 normal map에서 선택적으로 각 픽셀의 수평적인 normal 벡터 N_i를 추출해서 (N_x, N_y, N_z)로 정의합니다. 그 다음에 수평 평면에 대한 normal 벡터를 N_{pred} = Cluster(N_i)로 계산합니다. N_{pred}는 이제 바닥면에 대해 정의된 것이기 때문에 이를 z축에 정렬하기 위해 식(1)과 같이 회전 행렬 R을 계산합니다.
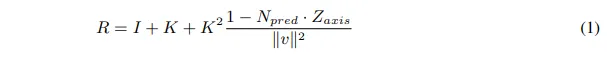
- I : identity matrix
- v : N_{pred}와 Z_{axis}의 외적
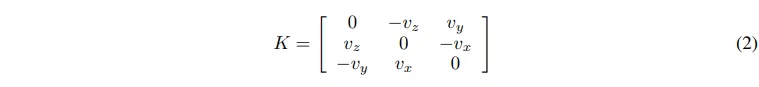
내부 파라미터 K는 식(2)와 같이 정의되며, 이렇게 내부,외부 파라미터를 얻을 수 있으니 이 파라미터들을 사용해서 depth 이미지 D_{metric}을 pseudo 포인트 \mathcal{P}_{pseudo}로 변환합니다.
2.3. Pseudo 3D Annotation Generator
이제 pseudo 포인트를 만들었으니 이를 기반으로 pseudo 3차원 바운딩 박스 \mathcal{B}_{3Dpseudo} \in \mathbb{R}^{M \times K \times 7}을 생성합니다. 여기서 K는 바운딩 박스의 개수이고, 7은 바운딩 박스의 파라미터를 의미합니다.
구체적으로 이미지 데이터셋에는 3차원 바운딩 박스를 생성할 수 있는 GT 정보가 포함되어 있죠. 리프팅 모듈을 통해 얻은 카메라 내부, 외부 파라미터를 사용해서 2차원 GT 정보를 3차원으로 올려 frustum 형태의 3차원 박스 \mathcal{B}_{3Dpseudo}를 생성합니다. 보통 이렇게 만든 frustum 형태의 박스는 배경 포인트나 outlier 값이 포함되어 있어서 노이즈를 제거하기 위해 클러스터링 알고리즘을 사용해 대상 물체에 속하지 않는 노이즈 값들을 찾습니다.
그러나 이런 과정을 거쳐도 3차원 박스에는 monocular depth estimation으로 얻은 depth 이미지 자체에 존재하는 노이즈가 존재할 수도 있습니다. 이러한 노이즈는 Fig.3(b)와 같이 3차원 박스 필터링을 통해 부정확한 3차원 박스를 한 번 더 필터링 해야 합니다. 부정확한 박스라는 기준을 세워 필터링을 해야하다보니 여기서 GPT-4 모델을 사용해서 물체의 크기 중앙값에 대한 데이터베이스를 먼저 구축하였다고 합니다. 가령 GPT에 “미터를 단위로 해서 [클래스]의 평균 length, width, height를 알려줘”라고 해서 중앙값인 L_{GPT}, W_{GPT}, H_{GPT}를 받습니다. 중앙값을 각 물체 클래스에 대해 알았으니 특정 임계값 T를 지정해서 중앙값 dimension과 각 3차원 바운딩 박스의 dimension을 식(3)과 같이 비교하여 필터링합니다.
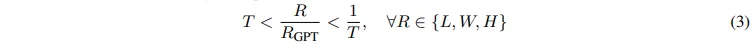
2.4. Point Cloud Renderer
포인트 클라우드는 sparse한 포인트가 dense한 텍스터 정보를 제공할 수 없다는 데이터의 본질적인 한계가 존재합니다. 그래서 보통 이미지를 포인트의 부족한 텍스처 정보를 추가하여 제공하는 목적으로 활용하죠. 본 논문에서 2D 이미지를 활용하기 위해 포인트 \mathcal{P}를 렌더링 이미지 \mathcal{I}_{rendered} \in \mathbb{R}^{M \times H \times W}로 변환합니다. 저도 이런 렌더링 이미지를 사용하는 것은 처음 보는데, 안 그래도 논문에서도 렌더링 이미지를 3차원 검출 작업에 통합하는 게 매우 어렵다고 합니다. 그래서 본 논문에서는 생성한 3차원 포인트 외에 추가적인 입력이 없도록 하면서 멀티 모달 정보를 활용하기 위해 pseudo 이미지로 변환할 수 있는 renderer을 설계하였습니다.
renderer는 크게 2가지 주요 모듈로 구성되어 있는데요, 먼저 포인트 클라우드 렌더링 모듈은 \mathcal{P}를 렌더링된 이미지 \mathcal{I}_{rendered}로 변환 합니다. 두번째 컬러 렌더링 모듈은 이 이미지를 ControlNet이라는 모델을 사용해서 컬러화된 최종 pseudo 이미지 \mathcal{I}_{pseudo} \in \mathbb{R}^{M \times H \times W \times 3}를 출력합니다. 마지막으로 2D 데이터셋의 pseudo 이미지와 어노테이션을 사용해서 OV 2D 검출기를 fine tuning 합니다. 결국 \mathcal{I}_{pseudo}를 사용해서 해당 pseudo 2D 바운딩 박스 \mathcal{B}_{2DT_{pseudo}} \in \mathbb{R}^{M \times K \times 4}를 얻을 수 있습니다.
2.5. Pseudo Multimodal 3D Object Detector
3차원 데이터 \mathcal{P}, \mathcal{B}_{3D_{pseudo}}와 pseudo 이미지 \mathcal{I}_{pseudo}로 구성된 데이터셋을 사용해서 2 단계로 pseudo 멀티모달 3차원 검출기를 학습합니다.
Training Strategy
intro에서 말씀드린대로 사전학습과 adaption 단계로 이루어져 있습니다. 사전학습에는 pseudo 포인트와 어노테이션을 pseudo 이미지와 합쳐서 학습합니다. 사전학습 모델은 zero shot 검출에 대해서는 좋은 성능을 보이지만 두 모달리티 데이터셋 사이에는 큰 도메인 갭이 존재하죠. adaptation 단계에서는 이런 사전학습 단계에서의 도메인 갭을 최소화하기 위해 기존의 OV-3DET과 동일한 접근 방식을 사용한다고 합니다. 먼저 OV 2D 검출기를 사용해서 이미지에서 물체를 찾습니다. 그 다음 검출 결과를 RGB-D 데이터와 함께 3차원 공간으로 올리고 위 섹션에서 말씀드린거처럼 클러스터링을 통해 노이즈 제거해서 3차원 박스를 생성합니다. 마지막으로 이렇게 처리한 데이터는 adaptation에 사용하게 됩니다.
Loss Function
pseudo 포인트와 바운딩 박스를 활용해서 3차원 백본 네트워크를 학습하여 시드 포인트 \mathcal{K} \in \mathb{R}^{K \times 3}를 얻습니다. 그 다음에 시드 포인트는 카메라 파라미터를 통해서 다시 2D 공간으로 투영합니다. 이렇게 투영한 2D에서의 feature를 F_{img}로 표시하며, 마지막으로 포인트 feature F_{pc}와 이미지 feature F_{img}를 합쳐서 joint 표현인 F_{joint}를 생성합니다.
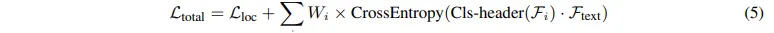
- i : 포인트, 이미지, join 각각의 feature를 의미
- W_i : i에 대응하는 weight
- \mathcal{L}_{loc} : 기존 3D detection에서 쓰는 localization loss
3. Experiments
3.1. Main Results
Pretraining
OV에서 3D detection의 비교군이 많지가 않아서 CLIP을 활용해 3DETR이나 VoteNet과 같은 기존의 3D detector가 OV 기능을 할 수 있도록 CLIP을 사용해서 변형하였다고 합니다. 이렇게 변형해서 세운 베이스라인을 OV-VoteNet, OV-3DETR이라고 표현하였습니다.
Adaptation
SOTA OV3Det 방법론과 pair comparison을 위해 adaptation 단계에서 모든 베이스라인은 adaptation을 위한 학습 데이터로 사용되는 GT 포인트 데이터에 대한 pseudo 라벨을 생성하는 OV-3DET 방법론을 동일하게 적용했다고 합니다. 여기서는 이전 방법론인 CoDA와 OV-3DET와 비교를 중점적으로 다룬다고 하네요.
3.1.1. Pretraining → 3D Training Data Free OV-3Det
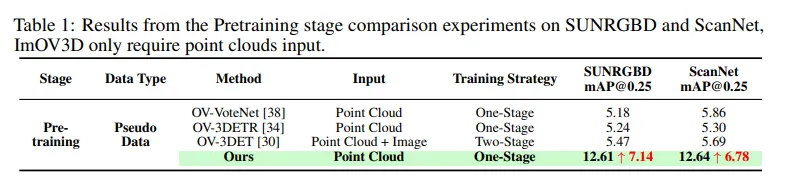
먼저 사전학습 단계에 대한 비교를 Tab.1을 통해 보면, ImOV3D는 생성된 pseudo 3차원 데이터로만 학습한 결과 이전 방법론인 OV-3DET보다 최대 7.14%의 성능 향상을 이루었습니다. 실제 3D 포인트 클라우드 데이터가 아니라 대규모의 이미지 데이터셋을 가지고 달성한 결과이기에 좀 더 OV 인지를 개선하는데 효과적이었다고 볼 수 있을 것 같습니다. 또한 이미지 데이터를 사용하지 않는 OV-VoteNet보다 SUN RGBD에서 7.43%의 성능 향상을 이루면서 멀티 모달리티의 효과까지 입증할 수 있었습니다.
3.1.2. Adaptation → 3D Training Data Guided OV-3Det
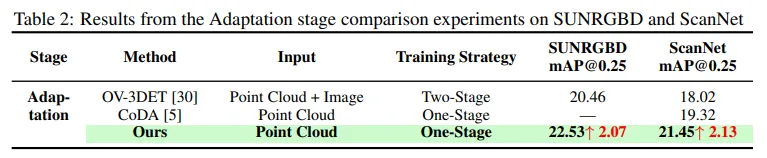
두번째로 Tab.2는 adaptation 단계의 결과를 보여주는데, 본 논문의 방법론은 pseudo 3D 데이터로 사전학습 하였는데 그 결과 SUN RGBD와 ScanNet에서 각각 2.07%, 2.13%의 성능 향상을 보여줍니다. 이를 통해 학습에서 pseudo 3차원 데이터를 사용하는 중요성과 학습하는 데이터셋의 규모가 얼마나 중요한지를 보여주고 있습니다.
4. Ablation Study
4.1. Ablation Study of 3d Data Revision
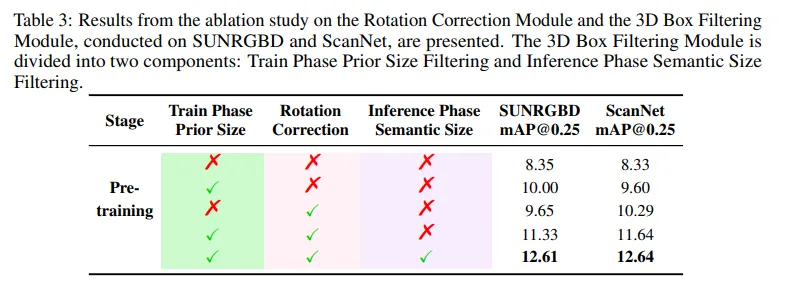
먼저 pseudo 3D 데이터의 퀄리티를 검증하기 위해 회전 보정 모듈과 3차원 박스 필터링 모듈에 대한 ablation study를 진행하였습니다. Tab.3을 보면, 3차원 박스 필터링 모듈은 학습 단계에서의 prior size와 inference 시의 semantic size 필터링으로 나누어져 있습니다. 모듈을 아예 아무것도 추가하지 않은 베이스라인에서 학습 시에 prior size 필터링, 회전 보정 모듈을 추가하면 모두 성능이 향상되면서 두 모듈 모두 성능 향상에 도움이 된다는 것을 보여주고 있습니다. 마지막으로 inference 시에도 필터링을 추가하게 되면 또 한번 성능이 개선되면서 각 모듈이 데이터의 퀄리티를 높이면서 OV 3D 검출 정확의 개선에 효과적이라는 것을 입증하고 있습니다.
4.2. Ablation Study of Depth and Pseudo Images


마지막으로 ControlNet에서 생성한 pseudo RGB 이미지의 효과를 검증하기 위해 Fig.4와 같이 pseudo 포인트의 2D depth map을 pseudo 이미지와 비교해보았다고 합니다. Tab.4를 보면, 두 데이터셋에서 모두 성능이 개선되면서 2D 이미지의 풍부한 텍스처 정보, 의미론적인 정보를 가지고 3차원 물체 검출을 진행하면 단일 모달리티에서 보다 크게 검출 성능이 향상된다는 것을 보여줍니다.
안녕하세요. 리뷰 잘 읽었습니다.
1. 본문 내용 중 “large scale의 이미지 학습 데이터를 monocular depth estimation과 이미지에서는 원래는 알 수 없는 카메라 파라미터를 얻어서 이미지를 pseudo 포인트로 변환합니다.”에 대해, 원래는 알 수 없는 카메라 파라미터를 얻는다는 의미가 어떤 의미인가요? monocular depth estimation에서 일반적으로 relative depth 외 같이 추론하는 파라미터로는 focal length가 있는데, 이 focal length만으로는 pseudo point 생성을 위한 카메라 파라미터는 부족할 것 같고, 이에 대한 설명으로 “55도의 FOV와 이미지 dimension을 기준으로 계산된 초점거리를 정의해서 고정적인 카메라 내부 파라미터”에 대해 적혀져 있는데 음… 55도의 FoV와 이미지 dimension을 기준으로 계산된 초점 거리를 정의하는데 주점 없이 갑자기 카메라 내부 파라미터가 정의되는 그 부분에 대한 (제가 모르는 부분이 있을 수 있으니) 자세한 설명을 해주시면 감사합니다.
2. 그 다음 문장 “그런데 카메라 외부 파라미터는 지정돼있지 않고 고정된 파라미터를 쓰게 되면 포인트의 방향이 임의로 지정되어 정확한 데이터를 생성할 수 없습니다. 이를 위해 Fig.3(a)와 같이 회전에 대한 보정 모듈을 사용해서 바닥 평면이 수평이 되도록 합니다. “에 대한 질문입니다.
해당 문장에서 포인트 방향에 대해 알고자 , 바닥 평면이 수평이 되도록 하기 위해 normal map을 쓴다고 이해하였는데, 이 normal map이 해당 상황에서 어느 정도 도움이 된다는 점에서 이해가 되나, normal map을 그럼 모든 point에 대해 적용하는 건가요? 뭔가 설명에선 normal vector를 활용한다고 이해하였으나, normal vector라는게 2D 이미지 상에서도 각 픽셀/패치마다 바뀔 수 있는데, 이걸 각 point마다는 어떻게 적용하는지 / 그리고 본 논문에서 활용한 normal estimation 모델은 무엇인지 궁금합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. 카메라 내부 파라미터 예측하는 부분을 제가 다른 부분에서 유사한 방식을 봤었어서 많이 생략된 부분이 있었는데도 자세하게 설명을 안 적었었네요.
제 생각에는 아마도 55도의 FOV를 가진다고 가정을 하고, 이미지 width와 height를 사용해서 focal length는 height를 그리고 초점 거리는 1/2w, 1/2h 이런 식으로 고정된 파라미터를 임의로 지정했다고 이해했습니다. 이 방식은 본 논문 뿐만 아니라 다른 2D detection용 이미지를 사용하고자 하는 논문에서 이미 사용됐던 방식이기도 합니다. depth estimtation을 한 depth 이미지에서 연결돼서 파라미터를 찾고자 하는건 아니고 병렬적으로 monocular depth estimation도 수행하고, 이미지에 대해서 내부,외부 파라미터를 찾는 과정을 수행하는 것 입니다. 2D detection용 이미지만으로는 depth map을 생성한다 해도 파라미터를 모두 알지 못하면 3차원으로 올릴 수가 없으니까요.
2. 제가 이해하기로는 normal map을 모든 포인트에 대해 구해서 horizon 방향을 향하는 포인트에 대한 normal map 정보를 모아서 사용하는 것 같습니다. 아무래도 바닥 평면을 가리키는 포인트들만을 사용해야 하다보니 … 그리고 normal estimation 모델은 21년도 ICCV에 oral로 기재된 “Estimating and Exploiting the Aleatoric Uncertainty in Surface Normal Estimation”이라는 논문의 방식을 사용했다고 합니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
박스 필터링 모듈에 대해서 설명해주셨는데, 잘 이해가 가지 않는 것이 단순히 2D에서 검출한 박스의 결과를 3차원으로 올려주는 모듈이라고 이해했습니다. 근데 실험에서 봤을 때는 학습과 inference에서 다르게 어떤 prior와 size라는 기준을 가지고 필터링 모듈을 나누는 거 같은데 이 부분에 대해서 좀 더 설명해주시면 감사하겠습니다.
또한 GPT-4를 활용하는 부분에서 예시로 말씀해주신 중앙값을 말해달라는 요청 이외에 다른 요청을 하게 된다면 어떻게 이후의 처리가 바뀌는건지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
박스 필터링 모듈은 학습 때의 prior size filtering과 inference 단계의 semantic size filtering으로 나뉘는게 맞습니다. 학습에는 prior size 기준과 맞지 않는 상자를 필터링 하게 되고, inference 시에는 의미론적으로는 유사하지만 크기가 다른 클래스를 제거해서, 가령 책을 책장으로 잘못 인시하는 케이스를 막기 위해 적용됩니다.
논문에서 얘기하기로는 중앙값을 말해달라는 요청이 하나의 예시가 아닌 고정적인 입력인 것 같습니다. 따라서 중앙값을 요청해서 이어지는 후처리들은 모두 동일하게 변하지 않고 수행됩니다.
감사합니다.
안녕하세요 건화님, 좋은 리뷰 감사합니다.
사과 논문 저자이신 건화님 승현님을 도와 저 또한 사과 3D annotation을 찍먹해 본 입장에서 보니,, 정말 수고스러운 3D annotation이 없이도 학습이 된다는 점과, OV3DET 성능향상, 모달리티 갭을 줄일 수 있는 등의 여러 contribution이 꽤나 인상깊은 논문이네요.
그런데 읽으면서 몇 가지 의문점들이 있었습니다.
1. ControlNet을 통해 나온 렌더링된 Pseudo 이미지가 Figure 2와 4에서의 형태로 보아하니 기존 input 이미지와 texture, color 측면에서 꽤나 다른 것을 확인했습니다. ControlNet에 대해 좀 찾아보니 Diffusion 기반의 이미지 생성모델인 것으로 확인했는데요. 저 개인적으로 생각하기엔 아직까지의 생성모델은 (기존 이미지 혹은 Pseudo pc에) 없던 object를 만들어내거나, 혹은 없애버리거나, 생성모델 특유의 요상한(?) 형태의 artifacts 들도 만들어버리면서 노이즈를 많이 만들어버릴 수도 있다고 생각을 합니다. 그럼 여기서 의문이 드는 게, OVD 태스크의 특성 상 Pseudo 이미지 내의 object들을 웬만하면 찾아낼 수 있어야 할텐데, 기존 이미지, Pseudo pc, Pseudo image 모두에 object 간의 매칭이 안되는 요소가 있다면 본 방법론에서 꽤나 큰 허점이 되지 않을까 생각합니다. 이 부분에 대한 저자들의 고찰은 없었나요?
2. 제가 파이프라인을 좀 이해하기 위해 정리해보며 리뷰를 읽었습니다. 아래와 같이 정리했는데요.
input RGB image —> monocular depth estimation, surface normal vector estimation, clustering —> Pseudo 3D pc —> pseudo 3d bbox 생성, clustering, GPT-4 filtering —> ControlNet(Diffusion) pseudo image renderer –> ~ ~ ~
2-1. 지금 앞에서부터 순서대로 정리해봐도, 이렇게 중간중간 estimation과 clustering, 2d<->3d 변환, LLM prompting, diffusion 이미지 생성 등의 엄청난 다양한 단계로 파이프라인이 진행되고 있는데, 읽으면서도 estimation이 너무 많이 들어가서 noise가 연쇄적으로 심해지지 않을까 생각하던 와중 outlier나, coarse한 box에 대해 clustering도 하고, GPT로 filtering을 해준다고 설명이 되어있었습니다. pseudo 방식으로 인한 coarse-to-fine 을 추구하기 위해서면 그럴 수도 있다고 생각하지만, GPT-4의 hallucination 현상으로 인한 부정확한 예측은 또 무시 못할 문제가 될 것 같은데, 이에 대한 저자들의 고찰은 없었나요?
2-2. 또, 너무 많은 estimation 모델을 태우고, clustering을 하고, GPT API도 활용하고, diffusion rendering도 활용하고 하다보면 computational & time cost가 매우 많이 들 것으로 우려되는데,,, 해당 사항에 대한 reporting은 없었나요?
2-2. 마지막으로 위와 같이 정말 다단계로 파이프라인이 이루어져있는데 저자들은 모델의 전체 파이프라인을 실험파트에서 1-stage로 주장하는 것으로 보입니다. 해당 OV3D 태스크에서 stage를 나누는 기준이 혹시 무엇인가요?
안녕하세요, 리뷰 읽어주셔서 감사합니다.
1. 우선 RGB image, pseudo point, 그리고 pseudo image에서 검출하는 물체의 매칭이 안되는 경우에 대한 부분은 RGB 이미지에서 검출한 결과가 있고, 포인트 클라우드로 올릴 수 있는 파라미터가 있어서 3차원으로 검출 결과를 그대로 올릴 수가 있습니다. 그리고 나서 그 결과를 다시 pseudo image로 보내는 것이기 때문에 아예 3가지 데이터에서 물체가 매칭되지 않는 것을 우려하지는 않아도 된다는 것이 제 개인적인 생각 입니다. 말씀하신대로 노이즈가 생기는 부분은 계속 개선되어야 할 부분이 아닐까 하네요.
2-1. 사실 GPT로 필터링을 한다고는 하지만 GPT의 역할은 정말 어쩌면 단순하게도 각 클래스 박스들의 중앙값을 출력해주는 것이기 때문에 엄청나게 부정확한 예측을 하는 케이스까지 고려하지는 않는 것 같습니다.
2-2. 파이프라인이 복잡하긴 해서 저도 꽤나 cost가 들거라고 생각이 들긴 하는데요, 아쉽게도 그런 부분에 대한 리포팅은 포함되지 않습니다. 아무래도 3D detection task 자체가 원래 time cost 측면에 대한 리포팅을 잘 안 하기도 하고, 특히나 OV 관점에서는 현재 성능을 일반화되는 수준으로 끌어올리는게 먼저인지라 FPS나 속도 관점에 대한 얘기는 모든 논문에서 거의 없는 편 입니다.
2-3(?). 실험에서 말하는 학습 전략의 1, 2-stage은 학습 단계에서 데이터를 병렬적으로 몇가지를 사용하는지에 따라 나눈 것 같습니다. 본 논문은 2D 검출용 이미지만을 입력으로 파이프라인이 수행되기 때문에 1-stage, OV-3Det 같은 경우에는 이미지와 포인트 클라우드 두개가 입력으로 들어가서 따로 처리가 되기 때문에 2-stage로 표시했다고 이해하였습니다.
감사합니다.