
1. Introduction
오늘 리뷰할 논문은 EfficientSAM 이라는 논문입니다.
이제는 널리 알려지고 활용되어지고 있는 Segment Anything Model (SAM) 의 후속작으로, 마찬가지로 Meta 에서 발표한 논문입니다. 그리고 이름에서부터 알 수 있다시피 기존 SAM과의 성능은 최대한 유지하면서 효율성(속도)을 극대화하려고 노력 한 그런 논문이라고 보시면 됩니다.
Meta 에서 2023년에 Segment Anything Model (SAM) 을 발표한 이후, vision 필드에서 이 SAM 모델은 매우 활발하게 사용되어져 왔습니다. 11M장의 이미지, 그리고 1B 이상의 마스크로 구성된 매우 큰 규모의 SA-1B 라고 하는 데이터셋을 통해 사전학습된 segmentation 계의 foundation model이죠. 그렇기에 zero-shot 등의 일반화 성능도 매우 뛰어납니다.
이렇듯 성능적으로는 SAM 이 매우 성공적인 행보를 이어가고 있지만, 반면 효율성의 측면에서 봤을때는 개선해야 할 부분이 많습니다. 기본적으로 SAM 이 사용하는 encoder는 ViT-H(huge) 구조로 실제 real-time application에서 사용하기에는 매우 높은 계산 및 메모리 비용이 소모됩니다. decoder의 parameter가 3.87M 인데에 반해, encoder는 632M 이라고 하네요..
이렇듯 SAM은 효율성 측면에서 매우 큰 bottleneck을 가지고 있고, 몇몇 연구들에서 이 문제를 해결하고자 많은 시도들을 했습니다. Faster Segment Anything 에서는 SAM의 원본 ViT-H image encoder 로 부터의 knowledge를 ViT-Tiny/Small로 distillation 하고자 하였습니다. 또한 Fast segment anything 에서는 real-time CNN 기반의 백본을 사용하여 계산 cost를 대폭 줄였다고 합니다.
본 논문에서 제안하는 방법론에 대해서는 아래에서도 자세히 설명 드리겠지만, 간단히 한 문장으로 정리하자면 ‘masked image modeling (MIM) 컨셉을 사용하여 기존 SAM ViT-H 인코더의 풍부한 정보를 가벼운 ViT 인코더 (ViT-Tiny/Small) 로 잘 전이해보자~‘ 가 되겠습니다.
사전학습 단계에서 MIM을 통한 pretraining을 수행하고, 예측 단계에서는 가벼운 ViT 인코드를 사용하게 되면 real-time application에서도 사용할 수 있겠죠.
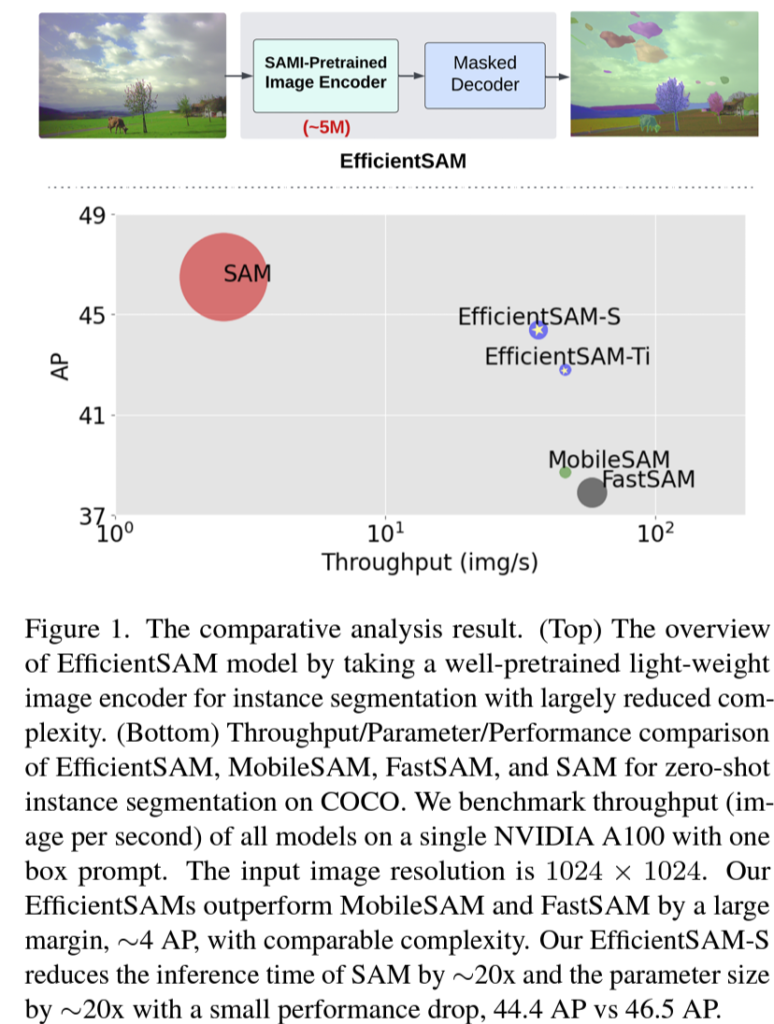
뒤 실험 table 에서도 성능/속도를 함께 고려하여 비교를 할텐데, intro 단계에서 간단하게 figure로 살펴본 결과는 위와 같습니다. COCO 에서의 zero-shot instance segmentation 수행 결과입니다. 본 논문에서 제안하는 EfficientSAM의 경우 SAM에 비해 당연히 성능은 살짝 떨어지지만 x축으로의 throughput, 즉 fps는 훨씬 빠른것을 볼 수 있습니다. 또한 비슷한 컨셉으로 제안된 MobileSAM과 FastSAM 대비 속도적인 측면에서는 조금 부족하지만 성능 차이가 꽤나 크게 나네요.
2. Approach
2.1. Preliminary
Masked Autoencoders.
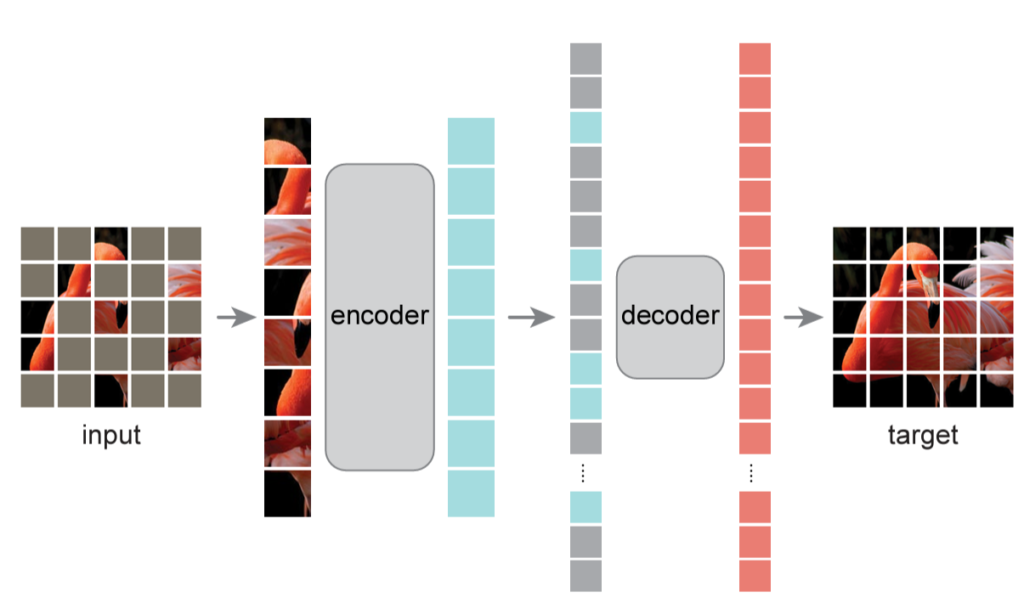
Masked Autoencoder, 흔히 MAE 라고 불리는 기법은 MIM 기반의 self-supervised pre training 기법으로 FAIR(facebook ai research) 에서 제안한 기법입니다. 구조는 간단하게 encoder와 decoder로 구성되어 있으며, 입력 영상에 대해 높은 비율(75%) 로 마스킹을 적용한 후 겹치지 않게 patch 단위로 잘라서 입력 token을 생성합니다. 이후 마스킹 되지 않은 token을 통해 feature를 추출하고(encoder), 이를 기반으로 decoder에서 reconstuction을 수행함으로써 마스킹 된 이미지를 원본 이미지로 복원하는 과정을 거치게 되는 것이죠.
2.2. SAM-Levaraged Masked Image Pretraining
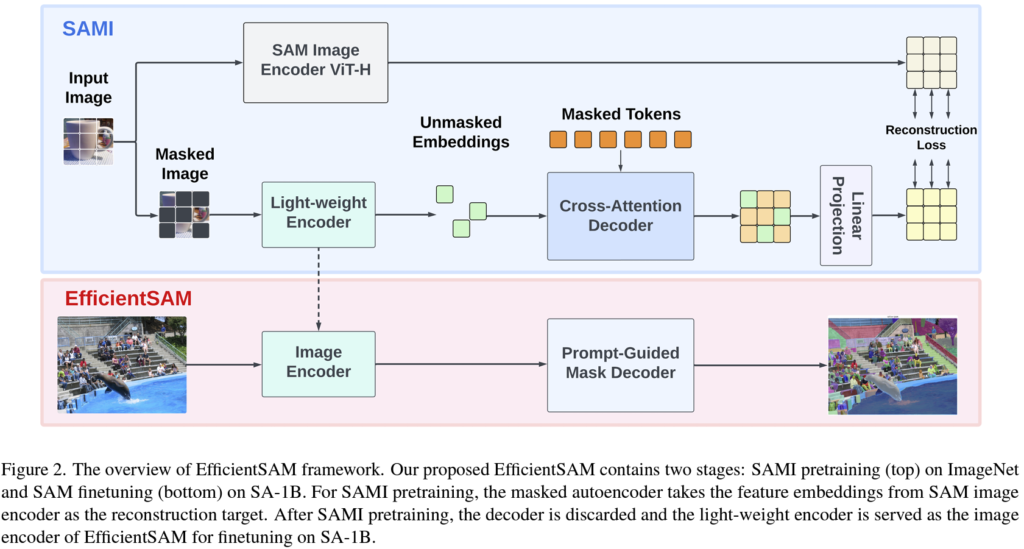
사실 뭐 방법론/컨셉은 매우 간단합니다. 위 그림으로 봤을 때 크게
i) SAMI pretraining 단계 (그림 속 파랑)
ii) EfficientSAM finetuning 단계 (그림 속 빨강) 으로 진행됩니다.
본 단락에서는 SAMI pretraining 에 대한 설명이 진행됩니다.
위 intro 에서 설명드렸다시피 기존 SAM ViT-H 인코더의 지식을 가벼운 light-weight encoder로 전이받고자 하는 컨셉입니다. 이름은 SAM-leveraged masked image pretraining 라고 하여 SEMI로 명명합니다.
MAE와 마찬가지로 마스킹 되지 않은 unmasked tokens를 encoder 에 통과시켜 unmasked embeddings를 얻습니다. 이후 cross-attention decoder 에서는 마스킹되지 않은 token으로 부터 추출된 unmasked feature embeddings의 도움을 받아 masked token의 reconstruction이 수행되게 됩니다. 그런 후 뒷단의 projection layer를 거치고 SAM 출력의 가이드를 받아 reconstruction loss 를 계산하게 됨으로써 pretraining 과정이 진행되게 됩니다.
Cross-Attention Decoder.
앞선 MAE 의 Decoder 입력부분을 보시게 되면 embedding된 unmasked token에 더불어 masked token이 함께 통과되어 reconstruction이 수행되게 됩니다. 하지만 본 논문에서 말하길 decoder의 입력으로는 masked token만 들어가면 된다고 합니다. 이때 query로는 masked token를 사용하고, key와 value로는 embedding된 unmasked token 과 masked token을 함께 사용하여 cross-attention 을 수행합니다. 이후 cross-attention의 query로 지정되어 연산을 수행한 masked token과, encoder를 통해 embedding된 unmasked token이 합쳐진 후 (merge), input image token의 space로 재정렬되게 됩니다. 마지막으로 linear projection head를 통과시켜서 기존 SAM image encoder와의 정렬을 수행하게 됩니다.
구조는 위와 같고, 학습(pretraining)을 위해서 SAM 의 output과 위 MAE 의 output 사이에서의 reconstruction loss가 계산되게 됩니다. 간단하게 L2 loss를 사용합니다.
SAMI for EfficientSAM
앞선 pretraining 과정이 끝났다면, 이제 본 논문에서 사용하는 light-weight한 ViT 인코더는 SAM으로 부터 풍부한 정보와 context 모델링 능력을 잘 학습한 상태일겁니다. 이후 fine-tuning단계 (위 모델 그림 속 빨강) 에서는 위에서 학습된 decoder는 버려지고 encoder만 학습됩니다. 그리고 segmentation을 위한 decoder의 경우 SAM의 기본 mask decoder를 사용한다고 합니다. fine-tuning 때 사용되는 dataset은 SA-1B 데이터셋이라고 합니다.
3. Experiment
3.1. Main Results
Image Classification
우선 ImageNet-1K 데이터셋에서의 분류 비교 결과입니다. DeiT, MAE, DINO 등 여러 ViT 기반 foundation 백본들과의 비교가 진행되고 있습니다. 각각 ViT-T, S, B 에 대해 따로 진행했네요.
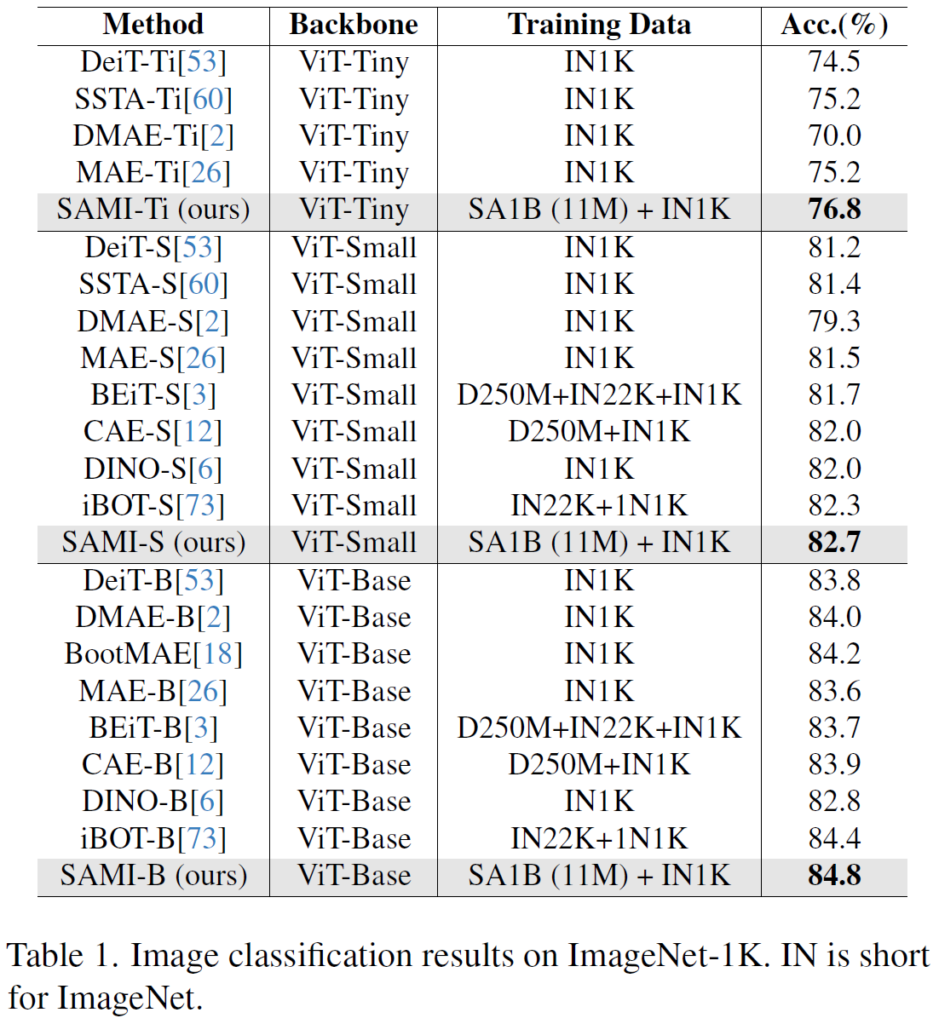
위 method 에서 말씀드렸다시피 본 논문의 SAMI 는 크게 i) pretraining 과정 with ImageNet-1K (1N1K) 데이터셋, ii) finetuning 과정 with SA-1B 데이터셋으로 학습이 진행됩니다. 그렇기에 위 table 에서 타 foundation 백본들과 학습 data가 조금은 상이한 것을 볼 수 있습니다.
하지만 이런 foundation 모델 논문들에서 하고자 하는 말이 결국 ‘성능 좋은 우리 백본을 사용해봐~’ 인것이고, 그런 관점에서 학습 데이터셋이 다르다 한들 높은 성능만 강조하면 되기에 이런 비교가 가능하지 않을까 싶습니다.
Object Detection, Instance Segmentation / Semantic Segmentation
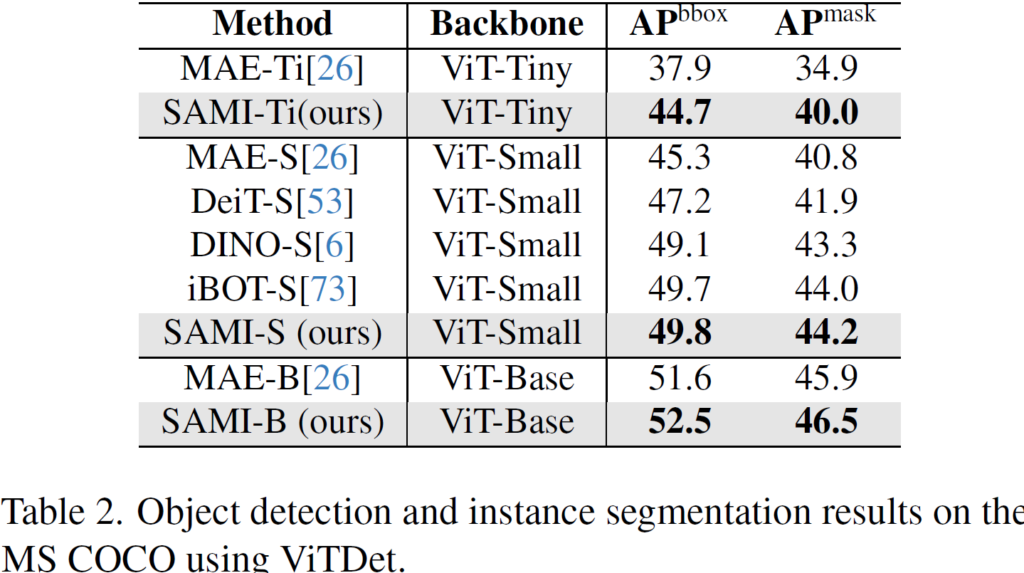
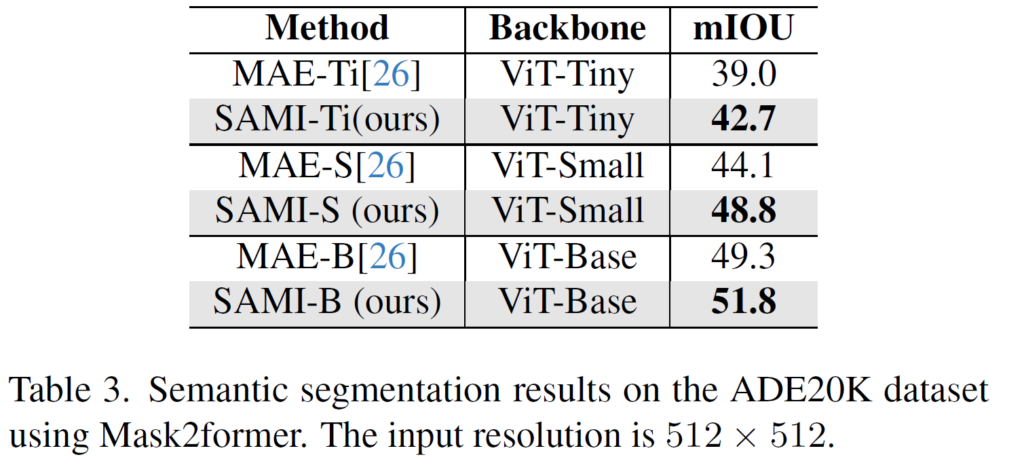
다음은 COCO 데이터셋에서 Object Detection (OD), Instance Segmentation (IS), 그리고 ADE20K 에서의 Semantic Segmentation (SS) 실험 결과입니다.
우선 OD와 IS 실험 시 Mask-RCNN 의 기본 구조에 백본만 교체하여 사용했다고 합니다. 타 방법론들에 비해 능가한 성능을 보이고 있으며, 특히 Tiny 백본을 사용했을 때 MAE 와 성능 차이가 매우 인상적입니다. 본 논문의 SAMI 가 결국 기존 SAM의 대규모 정보를 잘 distillation하고자 하였기 때문에, 동일한 tiny 백본을 사용하였다고 해도 MAE보다 압도적인 성능 향상을 이뤄낼 수 있었습니다.
SS 에서는 Mask2former 모델에 백본만 본인들 것을 사용해서 실험을 진행했다고 하네요. tiny의 경향성이 OD, IS 와는 조금 다르긴한데 어쨌든 MAE 대비 꽤나 괜찮은 향상을 보여줍니다.
3.2. EfficientSAMs for Segment Anything Task
본 논문의 메인, EfficientSAM 에 대한 zero shot segmentation 성능을 측정하는 단락입니다. 기존 SAM 과 동일하게 실험에서는 point와 box를 prompt 삼아 Segment Anything을 수행한다고 합니다. 한층 효율적인 SAM인 EfficientSAM을 구축하기 위해 image encoder로는 SAMI 방식을 사용하여 ImageNet-1K 로 pretraining을 수행한 경량(ViT-T, S) 백본을 사용하게 됩니다. 또한 SA-1B 데이터셋에 대해 EfficientSAM의 finetuning 을 진행합니다.
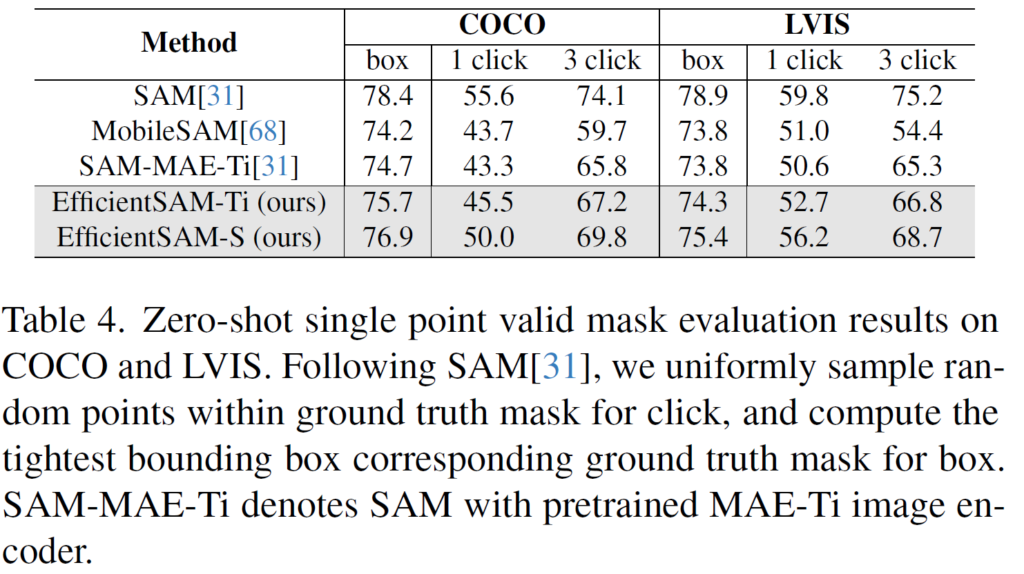
위는 COCO, 그리고 LVIS 에 대한 zero-shot 실험 결과입니다. prompt 로는 gt mask 내부 영역 속 랜덤하게 1/3 click, 그리고 box prompt를 사용했습니다. box prompt의 경우 gt mask를 기준으로 가장 타이트하게 box를 생성하여 사용하였다고 합니다. (기존 SAM 과 동일)
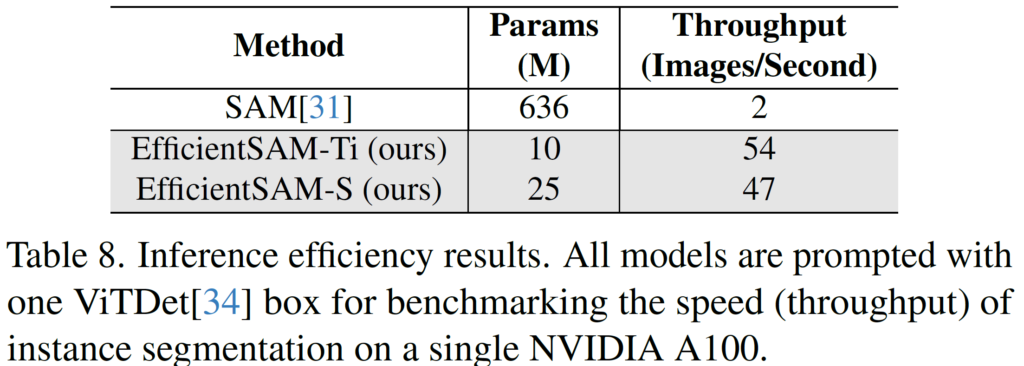
SAM과 EfficientSAM-S 를 보면 COCO box 기준으로 성능 차이가 1.5 mIoU 밖에 나지 않지만 이때 parameter는 20배나 적다고 하네요.
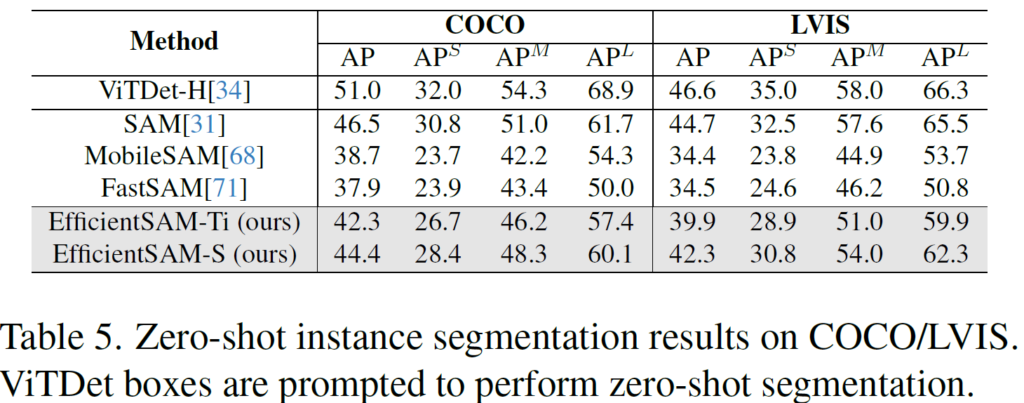
이번엔 ViTDet-H 이라는 detection 모델이 예측한 bbox를 prompt 삼아 수행한 zero-shot Instance Segmentation 실험 결과입니다. 이때 앞선 방법론인 FastSAM은 68M parameters를 사용하여 COCO AP 37.9의 성능을 보이고 있는데, EfficientSAM-Ti 는 9.8M parameters (약 1/7)를 가지고 42.3의 높은 성능을 보이고 있습니다.
Qualitative Results
마지막으로 정성적 결과입니다.

위는 이미지 내에서 랜덤하게 1개 point를 prompt 삼아 seg mask를 예측한 결과입니다. 그림 속을 자세히 보시면 별표 모양이 보이실텐데 해당 별 모양이 point-prompt 입니다.

위는 box prompt 를 사용한 결과입니다.

마지막으로는 segment anything 결과입니다. 마지막 3번째 젖소 영역만 제외하면 SAM과 EfficientSAM 사이의 결과가 크게 차이가 없는 것을 확인할 수 있습니다. 두 모델 사이의 params, 그리고 throughput(1초에 처리하는 이미지 장수) 비교는 아래와 같습니다. 차이가 어마어마하네요.
잘 알려진 Segmentation용 foundation 모델인 SAM, 정말 많은 연구 분야에서 활용되고 있습니다. 일각에서는 SAM의 느린 처리속도를 해결하고자 여러 연구들이 진행되어져 왔었고 이번에 리뷰한 논문인 EfficientSAM 또한 그 중 하나입니다. 최대한 SAM의 지식을 살리면서 효율성을 가져가기 위해 MIM 기반의 self-sup 전략을 사용해서 reconstruction loss 기반 distillation 을 진행하였고 결과적으로 수십배의 param 감소, 수십배의 속도 증가, 최소한의 성능 하락만 일어난 빠른 foundation seg 백본이 탄생(?) 되었습니다.
리뷰 마치겠습니다. 감사합니다.
리뷰 잘 읽었습니다.
의문점으로, 본 논문은 Masked Auto Encoder + SAM으로 분명 SAM에 비해 성능은 크게 뒤쳐지지 않은 채(?) 파라미터 수나 실행 시간이 매우 빠른 이점이 있음을 알겠습니다만,
근본적으로는 MAE와 SAM을 합친 부분에서 새로운 점을 발견하기가 어려웠습니다. 그런 점에서, 본 논문이 CVPR2024에 붙었을 수 있는 핵심은 어떤 점이라고 생각하시나요? 단순히 SAM에 대한 새로운 접근으로 이해하기엔 어려운데, 뭔가 놓치고 있는 차별점이 있나 하여 질문드립니다.
댓글 감사합니다.
method 적으로는 MAE+SAM 가 이 논문의 전부이긴 하고, 놓치고 있는 차별점은 없다고 저는 생각합니다. 다만 음.. 본 논문이 붙을 수 있었던 이유(?)에 대해 생각해 보면
i) 동일 규모의 dataset으로 학습된다는 가정 하 우리는 모델의 규모(param 수) 가 성능에 핵심적인 영향을 끼친다는 사실을 알고 있습니다. 하지만 본 논문의 EfficientSAM 의 경우 SAM 대비 약 30~60 배나 적은 param수를 가지고도 COCO seg 성능 기준 1.5~2.5 의 하락만을 달성하였습니다.
ii) 제 생각에 보통의 foundation model을 포함한 백본 모델들은 사실 method 적으로 복잡한 설계를 잘 하지 않습니다. (적어도 제가 읽었던 논문 기준). 다만 이들이 강조하는 것은 여러 task, dataset으로의 downstream 성능, 그리고 풍부한 정보를 기반으로 한 zero-shot 성능이죠. 추가적으로 전 세계 다양한 연구/개발자들이 사용할 수 있게 코드 및 pretrained weight 을 공개했다는 점도 연구 활성화적 측면에서 한 몫 했다고 봅니다..
감사합니다.
안녕하세요 석준님, 좋은 리뷰 감사합니다.
저 또한 상인님과 같은 생각으로 댓글을 정리하고 있었는데, 상인님께서 먼저 말씀해주셨네요 ㅎㅎ..
비슷한 듯 조금 다른 질문인데, 그럼 결국 이전의 MobileSAM과 비교하자면, MobileSAM에서 사용되는 KD Loss 방식보다, 왜 EfficientSAM에서 활용되는 MAE의 Reconstruction Loss 방식이 파라미터 수와 실행 시간도 잘 방어가 되고, 성능 면에서는 더 효과적이었던 것인가요?
댓글 감사합니다.
KLLoss vs Recon Loss 중 어떤것을 사용했느냐가 param/fps 차이에 영향을 주는 것은 아닙니다. loss 는 그저 학습 시에만 반영되고, 모델을 어떻게 “학습” 할것이냐기 때문에 inference 때 체크되는 param/fps 와는 관련이 없기 때문이죠.
성능적인 측면에서는.. 완벽한 1대1 비교는 불가능 하다고 생각이 되는것이, 보통의 task들과는 달리 foundation 모델 논문들의 table을 보면 사용된 학습 데이터셋이 다름에도 불구하고 그냥 같은 table에서 비교를 해버립니다. (예를 들면 본 리뷰 속 table 1). 이것도 이해가 되는것이, 결국 요즘같은 data-centric 상황 속에서 양질의 data가 결국 자신들의 자산이기 때문이죠.
다시 말하자면 MobileSAM과 EfficientSAM의 성능 차이가 나는 이유가 loss 에서 기인한 것일 수도 있죠. 하지만 이것 보다도 학습때 사용한 dataset 차이를 봐야하는데,, 지금 확인해보니 둘 다 SA-1B를 사용했네요?? (SA-1B는 meta 가 SAM을 학습할 때 사용했던 대규모 데이터셋으로 공개를 안 한줄 알았건만, MobileSAM 논문을 보니 마찬가지로 학습때 SA-1B 를 사용했다고 하네요. META가 공개했나 봅니다 허허..)
그럼 뭐 다른 디테일한 차이도 있겠지만, 성능 차이가 났던 이유는 아마 loss의 차이, 그리고 이것 보다도 단순 distillation 보다 masked image modeling (MIM) 기반 마스킹 방식에서 효과를 톡톡히 본 듯 합니다.
답글이 좀 난잡하네요. 감사합니다..ㅎㅎ
안녕하세요 석준님 리뷰 감사합니다.
아직 지식이 부족해 완전히 이해는 못 했지만 SAM과 비슷한 성능으로 엄청 가벼워진게 EfficientSAM인것 같은데, 이것을 가능하게 해준 핵심이 Masked Token만 쿼리로 사용하는 Cross-Attention Decoder라고 이해해도 괜찮을까요?