안녕하세요, 마흔여덟 번째 X-Review입니다. 이번 논문은 2022년도 CVPR에 게재된 DN-DETR: Accelerate DETR Training by Introducing Query DeNoising 논문입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
DETR은 transformer를 사용하여 Object Detection task를 set prediction 문제로 푼 방법론입니다. set prediction problem으로 접근하면서 기존 방법론들이 사용하던 anchor나 NMS 등의 hand-designed 요인들을 사용하지 않을 수 있었다는 장점이 있지만, 이전 detector들과 비교해보았을 때 수렴 속도가 넘 느리다는 문제가 있었죠. 이 DETR을 사용해 좋은 성능을 뽑기 위해서 COCO 데이터셋에 대해 500 epoch를 학습시켜야 했는데, 동일 조건의 faster-RCNN는 오직 12 epoch이 사용될 정도로 차이가 컸습니다.
그래서 DETR이 수렴이 느린 근본적인 원인을 찾아 이를 완화시키려는 연구들이 있어왔구요, 동시에 모델 구조를 개선함으로써 DETR을 개선시킨 연구들도 진행되어 왔습니다. 예를 들어, 한 논문에서는 수렴이 느린 원인으로 decoder의 cross-attention이 효율적이지 못하다는 점을 들어 encoder만을 사용한 DETR을 제안했었습니다. 또 다른 접근법으로 detr의 query에 대한 개선 연구가 이뤄져 왔는데요, 아무래도 기존 detr의 각 query가 특정 위치에 고정되지 않고 모든 pixel과의 attention 연산을 수행하기에, 이런 비효율성을 해결하고자 query를 특정 위치에 고정하거나, query가 global한 영역을 다보기보다는 몇 선택된 위치에서만 attention하도록 함으로써 효율성을 극대화한 것입니다. 대표적으로는 Deformable DETR을 들어볼 수 있겠는데, reference point라는 개념을 도입해 query가 reference point를 기준으로 제한된 위치에서만 attention을 하도록 한 것입니다.
이외에 Anchor DETR이나 DAB-DETR 등이 있었는데, 저자가 말하기를 DETR의 이분 매칭 부분을 개선함으로써 보다 효율적으로 학습하고자 한 연구들은 거의 없었다고 합니다. 본 논문에서는 수렴이 느린 원인으로 학습 초기에 이분 매칭이 좀 불안정하게 동작하기 때문이라고 주장합니다. 이분 매칭은 query와 실제 object의 짝을 찾는 과정이라고 보면 되는데 모델이 학습하는 동안 매번 새로운 쌍을 형성하게 되고,, 학습 초기에는 최적화가 잘 되어있지 않다보니 이 매칭 과정이 좀 불안정하다는 의미인데요. 결과적으로, 한 이미지에서 특정 query가 어떤 object에 matching될 지 매 에포크마다 다를 수 있다는 점이 수렴을 느리게 한다는 것입니다.
본 논문에서는 이런 문제를 해결하기 위해 query denoising이라는 새로운 학습 방식을 제안합니다. 이건 decoder에 noise가 섞인 query를 noise가 안섞인 기존 query들과 함께 넣어 학습을 안정화하겠다는 것인데요. 구체적으로는 gt bbox에 약간의 noise를 더해 noise query를 생성한 후에 learnable한 anchor query와 함께 transformer decoder의 입력으로 넣어주는 식입니다. 그 다음 먼저 noise가 추가된 query에 대해서는 denoising 작업을 통해 원래 bbox를 복원하도록 하구, learnable한 query는 기존 DETR과 동일한 loss를 통해 기존과 같이 학습되도록 하였습니다.
정리해보자면, DETR은 최종적으로 class와 bbox를 예측한 후, 각 query와 gt간의 이분 매칭을 진행하는데, 이 과정이 매 epoch마다 일관되지 않기 때문에 수렴이 느리다는 점을 지적했으며 이를 해결하고자 query denoising을 제안했는데 이 과정은 matching하는 과정과 병렬적으로 진행되며 gt에 noise를 추가한 query를 decoder에 통과시켜 실제 gt로 reconstruction하는 것입니다.
이 query denoising은 hungarian loss로 학습되는 것이 아니라 추가된 reconstruction loss로 학습하기 때문에 기존 detr에 플러그 인 형식으로 쉽게 추가해 사용할 수 있다고 합니다. 아래 method에서 DN-DETR의 세부 구조를 살펴보도록 하겠습니다.
2. Why Denoising accelerates DETR training?
그 전에 이 denoising 과정이 왜 DETR의 학습을 가속화시키는지 살펴보고 넘어가겠습니다.ㅎ . 앞서 말했듯이 DETR은 학습할 때 매 epoch마다 일관되게 query와 gt가 매칭되는 것이 아니라 같은 query임에도 다른 gt와 매칭될 수 있습니다. 이건 hungarian matching의 특성이라고 보면 되겠는데, 이 헝가리안 매칭이 매칭 cost를 기반으로 최적의 쌍을 찾아내는 것이기 때문에 prediction이 조금이라도 달라지면 이 cost가 달라지게 되겠고 글머 또 최종 matching 결과도 바뀔 수 있겠죠. 아무튼 이런 특성 때문에 학습 초기에 matching이 불안정하게 동작할 수 있습니다. 결국 다시 말해 최적화가 어렵겠고 수렴 속도도 느리게 되는 원인이 되는 것입니다.
일단 저자는 DETR 계열 모델의 학습 과정을 두 단계로 나눠서 보는데요, 첫 번째는 ‘좋은 anchor 학습’이고 두 번째는 ‘상대적인 offset 학습’입니다. 구체적으로 ‘좋은 anchor 학습’이란 ,, 좋은 anchor란.. 이미지 안에서 object가 있을 법한 대략적인 위치를 나타내는 시작점이라고 보면 됩니다. 이 anchor는 정확한 위치가 아니기 때문에 예측된 위치와 실제 object의 위치 간의 약간의 차이가 있을 수 있습니다. 그래서 anchor와 실제 gt의 정확한 위치까지의 offset를 학습하는 것이죠.
Decoder의 query들은 anchor 학습을 담당하는데, anchor가 일관성 없이 업데이트 되면, 상대적인 offset을 학습하기 어렵습니다. 예를 들어 한 epoch에서는 특정 query가 A object에 맞춰진 anchor를 학습했다가 다음 epoch에서는 B라는 object로 matching이 바뀌게 된다면 그 query의 상대적인 offset을 학습하는 것이 혼란,, 스러울겁니다. 이 문제를 해결하고자 저자가 denoising을 추가한건데,, 그럼 왜 denoising이 이 문제를 해결할 수 있갸 하면, 이 denoising 과정은 모델이 noise가 추가된 bbox(좋은 anchor로 간주할 수 있는..) 를 원래 실제 object 위치로 복원하는 것을 목표로 하는데 이 과정에서 모델이 anchor 위치에서 실제 object까지의 offset을 자연스럽게 학습하게 됩니다. 이렇게 denoising을 통해 학습된 offset 정보가 상대적인 위치를 조정하는 데 도움되기 때문에 아까 모델의 학습 과정을 두 개로 나눈 것 중 두번째 상대적인 offset 학습을 더 쉽게 할 수 있는 것이죠.
즉, 이 denoising 과정이 이분 매칭을 거치지 않고도 noise를 제거하면서 object의 위치를 예측하기 때문에 query가 특정 object에 대해 더 일관되게 학습할 수 있고 이로 인해 matching 과정의 불안정성을 피하면서 안정적인 학습이 가능한 것입니다.
저자가 Instability를 측정하는 새로운 metric을 설계했고 그에 대한 식도 논문에 나와있긴 하지만 구체적으로 다루지는 않고 그냥 이 IS(Instability)를 가지고 기존 DETR와 base로 삼은 이전 논문인 DAB-DETR과 본 논문에서 제안하는 DN-DETR의 학습 시 불안정성을 비교한 figure를 살펴보고 넘어가도록 하겠습니다.
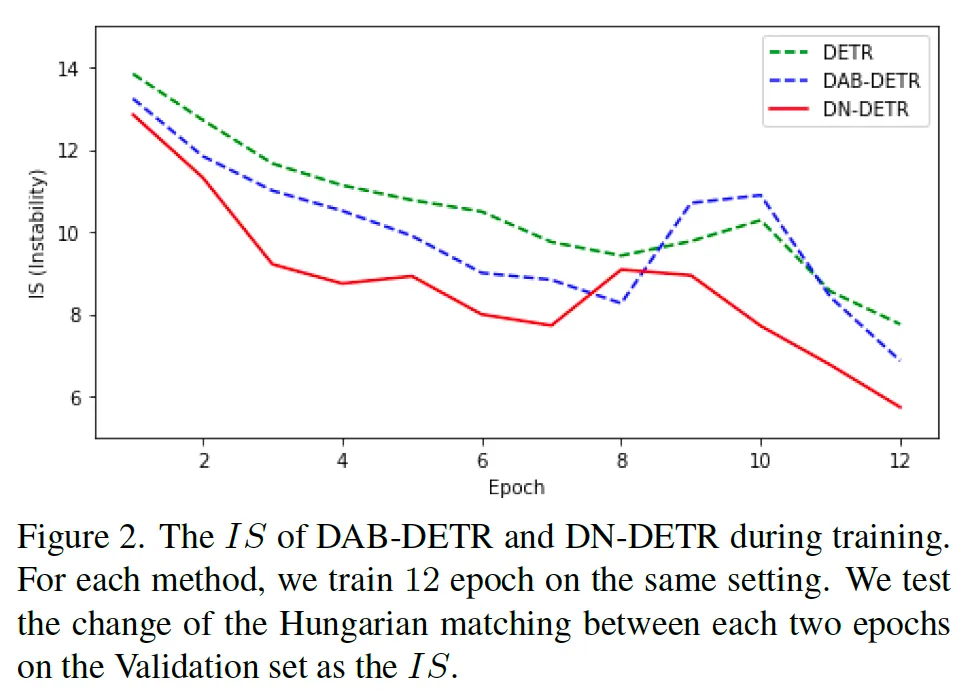
보시면 지표가 불안정성(IS)이기 때문에 낮을 수록 모델이 안정적으로 학습함을 의미하는데 학습 초기에 특히 본 논문에서 제안된 DN-DETR(빨간 라인)이 matching의 불안정성을 효과적으로 줄였음을 확인할 수 있습니다.
3. DN-DETR
3.1. Overview
이제, 제안된 DN-DETR의 모델을 자세히 살펴보도록 하겠습니다. DN-DETR은 DAB-DETR을 base로 삼았는데, DAB-DETR은 기존 DETR의 decoder query를 4차원의 bbox 좌표로 정의해 사용함으로써 query에 object의 위치를 더 잘 반영함으로써 개선시킨 모델이라고 보면 됩니다. 이 DAB-DETR과 DN-DETR의 차이점은 decoder embdding 부분인데요, 이걸 class label embedidng으로 지정해 label denoising을 할 수 있도록 하였습니다.
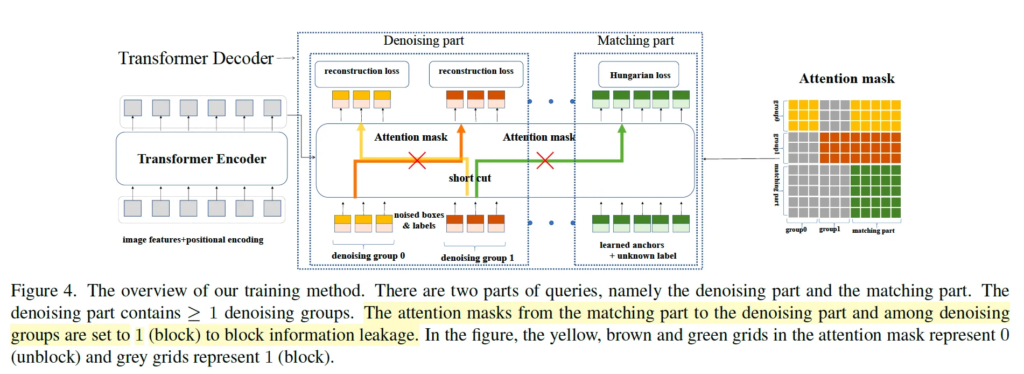
학습 방식의 전반적인 그림은 위 figure4에서 확인해볼 수 있는데요, detr 계열 모델이기 때문에 동일하게 transformer encoder, decoder로 구성되어 있습니다. encoder 부분에서는 backbone을 통해 feature를 추출하고 다시 positional encoding과 함께 transformer encoder에 태워 feature를 추출하게 되구요 decoder에서 query가 입력으로 들어가 cross attention을 수행하게 됩니다. decoder query를 q = {q_0, q_1, q_2, … , q_{N-1}}로, decoder output을 o = {o_0, o_1, …, o_{N-1}}로 나타낼 수 있고, F를 encoder를 타고 나온 feature, attention mask를 A라고 나타내 본다면.
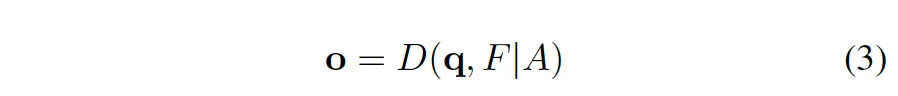
본 방법론을 위 식 3과 같이 나타내 볼 수 있겠죠. D는 decoder입니다. 이 때 Decoder query q는 두 부분으로 나뉘는데 그 중 하나가 matching 부분입니다. matching 부분의 입력은 learnable한 anchor이고 이건 기존 DETR과 동일한 방식 즉 이분 매칭을 통해 실제 gt와 매칭되어 학습되게 됩니다. 나머지 decoder query의 한 부분이 denoising 부분인데요, 이 입력은 noise가 추가된 실제 gt bbox-label 쌍이며 이 부분에서 output은 복원된 실제 gt입니다. 앞으로 이 denoising 부분의 query를 q = {q_0, q_1, … q_{K-1}}로 matching 부분의 query를 Q = {Q_0, Q_1, …, Q_{L-1}}로 표기하도록 하겠습니다.
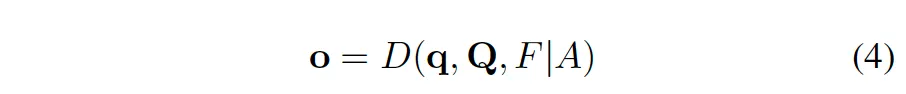
그렇다면 식3을 위처럼 다시 나타내 볼 수 있겠죠. 즉, decoder output o는 q(denoising query), Q(matching query), F(encoder output feature), A(attention mask)를 입력으로 받아 계산됩니다.
여기 Attention mask A는 denoising 부분에서 matching 부분으로의 information leakage가 발생하지 않도록, 또 같은 gt의 여러 다른 노이즈 버전간의 information leakage를 막는 부분에서 사용됩니다. 즉, 한마디로 denoising 부분과 matching 부분을 명확히 분리하고, noise가 추가된 여러 gt들이 독립적으로 복원되도록 하는 용도인것이죠.
3.2. Intro to DAB-DETR
잠깐, 본 DN-DETR의 베이스인 DAB-DETR에 대해 간략히 살펴보고 넘어가겠습니다.
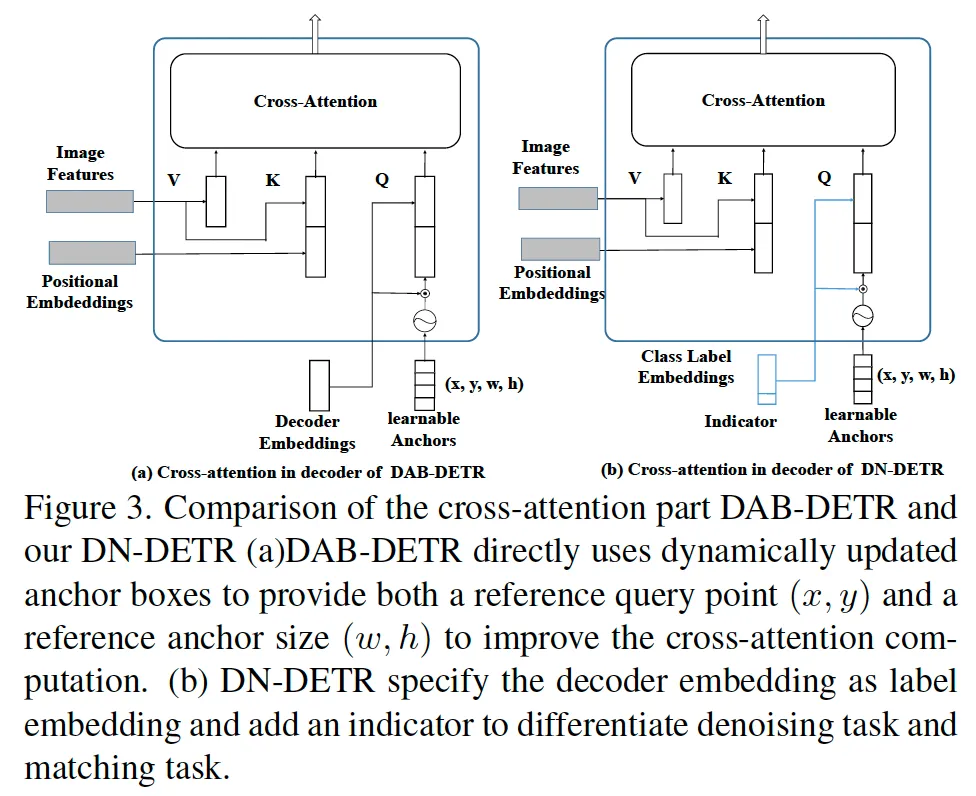
DN-DETR이 나오던 당시 다양한 positional information을 담은 query를 사용해보자는 DETR 계열 논문들이 나오고 있었습니다. (DETR의 기본 query는 초기에 위치 정보가 부족하기 때문에) DAP-DETR도 그런 격의 모델인데요, 그림 3(a)에 DAP-DETR의 decoder가 그려져 있습니다. 보시면 각 query를 4차원 (x, y, w, h) anchor 좌표로 정의해 사용하고 있으며 decoder layer를 한 번 한 번 거칠떄마다 (Δx, Δy, Δw, Δh)가 output으로 나오게 되어 (x + Δx, y + Δy, w + Δw, h + Δh)로 매 layer마다 update되는 식으로 위치가 조정되며 학습됩니다.
DN-DETR은 이 DAP-DETR에서 약간의 변형을 했는데, 3-(b)에 보이는 것처럼 decoder embedding을 label embedding으로 바꿨고 추가로 indicator를 더해 사용한 차이가 있습니다.
3.3. Denoising
제안된 denoising 부분에 대해 살펴봅시다. 먼저 gt에 noise를 추가해야 하는데, bbox와 label 모두에 대해 random noise를 추가했다고 합니다. 이 때 여러 버전의 noise를 추가했는데 bbox에 noise를 더하는 방식에는 bbox의 중심을 이동시키는 center shifting과 크기를 조정하는 box scaling을 사용했습니다. 또 label noising의 경우에는 label filpping이라고 실제 gt label을 무작위로 다른 label로 변경시켰습니다.
이렇게 noise를 추가한 gt를 denoising할 때 사용한 reconstruction loss는 loc loss로 L1 loss GIOU loss, cls loss로 focal loss를 사용하였습니다. 뒤에서 noise가 추가된 gt를 나타낼 때 δ(·)로 표현할건데, dnoising 부분에서의 각 query q_k는 δ(t_m)로 표현할 수 있겠죠. t_m는 m번째 GT object입니다.
이 denoising은 당연하게도 학습 때만 사용되고 inference때는 denoising 부분을 뺀 matching 부분만 사용합니다.
3.4. Attention Mask
이제 attention mask에 대해 살펴볼건데, 이 attention mask가 본 모델에서 매우 중요한 부분입니다. 이 attention mask가 없으면 denoising 학습이 오히려 성능을 저하시킬 수 있는데, 이 부분은 후에 실험 부분에서 확인해보도록 하겠습니다.
이 attention mask를 도입하기 위해서는 noise가 추가된 gt object를 먼저 그룹으로 나눠야 하는데요 이 그룹은 각기 다른 노이즈가 추가된 object들로 구성됩니다. 그니까 서로 다른 노이즈가 더해지면 그룹으로 나눠진다는 것이죠.
그럼 denoising 부분은 아래 식 5와 같이 표현해볼 수 있겠는데,
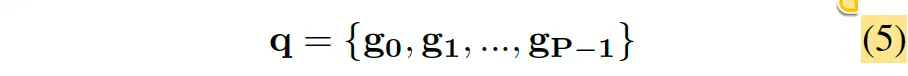
g_p가 p번째 denoising group임을 명시합니다. 각 denoising group은 image내의 gt object 수(M) 만큼의 query를 포함하고 있겠죠.
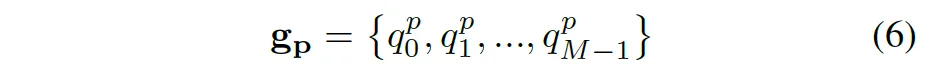
따라서 각 그룹도 위 식 6과 같이 나타내볼 수 있습니다. p는 그룹 번호, M은 한 image의 object 개수. q_m^p = δ(t_m)겠죠.. m번째 object의 noise버전..
앞서 언급한 바 있지만 이 attention mask의 설계 목적은 information leakage를 방지하는 것입니다. 크게 두 유형의 누출이 있을 수 있겠죠. 하나는 matching 부분이 noise가 있는 gt object를 보고 gt object를 보다 쉽게 prediction할 가능성이 있다는 것이고, 다른 하나는 동일한 gt object의 한 noise 버전이 다른 noise 버전을 볼 수 있다는 것입니다. 따라서 attention mask는 matching 부분이 denoising 부분을 못 보도록 하구, denoising 그룹 간에도 서로 볼 수 없도록 하는 마스크인거죠.
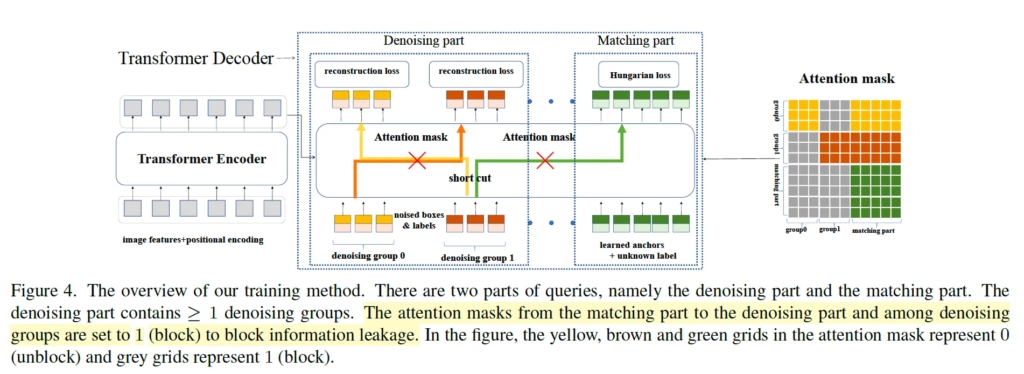
위 figure 4에 mask의 그림이 나와있습니다. 오른쪽에 있는 attention mask에서 노란색, 주황색, 초록색 grid는 0의 값으로 information을 차단하지 않는 부분이며 회색 부분이 1의 값이 들어가 정보를 차단하는 부분입니다. 이를 통해 matching 부분과 denoising 부분이 서로의 정보를 볼 수 없도록 독립적으로 학습하게 됩니다. denoising 그룹 간에도 마찬가지구요.
식으로는 아래 식7에서 살펴볼 수 있습니다. 그림으로 봐도 직관적이기에 구체적인 설명은 생략.. 하겠습니다.

3.5. Label Embedding
아까 DAP-DETR과의 차이점으로 decoder embedding을 label embedding으로 변경하여 사용했다고 했는데, 이로써 box denoising과 label denoising을 모두 하고자 한 것입니다. 이 label embedding에는 indicator가 추가되었다고 했는데, 이 indicator는 query가 denoising 부분에 속하면 1, 아니면 0으로 설정됩니다.
4. Experiments
4.1. Denoising Training Improves Performance
이제 실험 결과에 대해 살펴보도록 하겠습니다. 먼저, 저자가 제안한 denoising 학습 방식에 대한 효과를 보여주는 실험입니다.
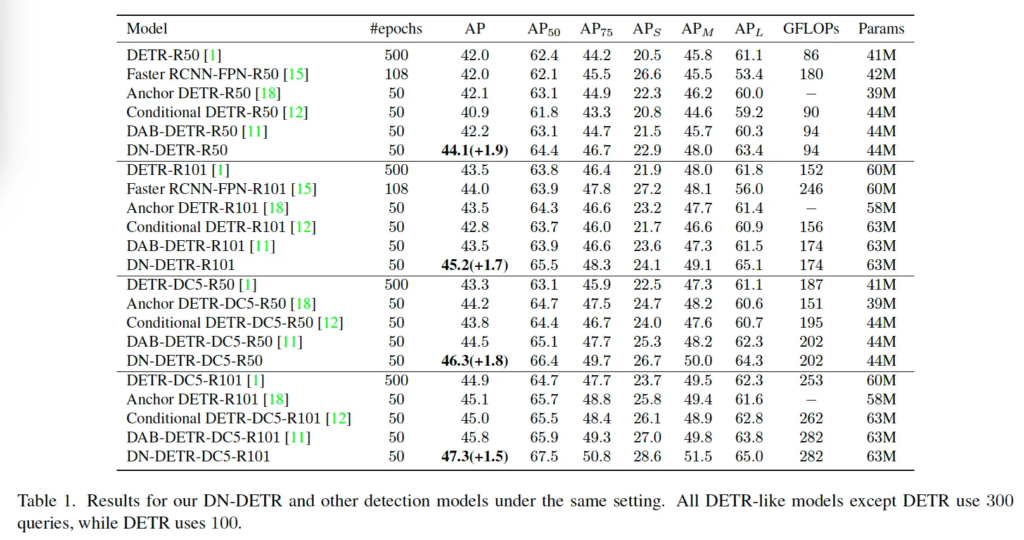
베이스로 삼은 DAB-DETR 및 다른 DETR 모델에 대해 여러 backbone 모델에 대해 실험을 수행하였습니다. 실험 결과는 표 1에서 확인해볼 수 있는데, 각 구분선은 각각 다른 백본을 사용한 결과입니다. 보시면 DN-DETR이 모든 백본에 대해 다른 DETR 계열 모델들보다 더 좋은 성능을 보였습니다. 완전히 동일한 세팅으로 실험된 베이스 모델인 DAB-DETR과 비교해봤을 때 ResNet50 backbone을 사용했을 때 대비 1.9AP의 상승을 보인 것이 그 예라고 보면 되겠습니다. 또, 이 표에서 볼만한 점이 DAP-DETR에 denoising학습을 추가한 DN-DETR 둘 다 파라미터 수가 같은 것으로 본 논문에서 제안된 denoising 학습이 성능을 향상시키는 동시에, 모델 복잡도나 연산략에 큰 부담을 주지 않는다는 것을 시사합니다.
4.2. 1x Setting
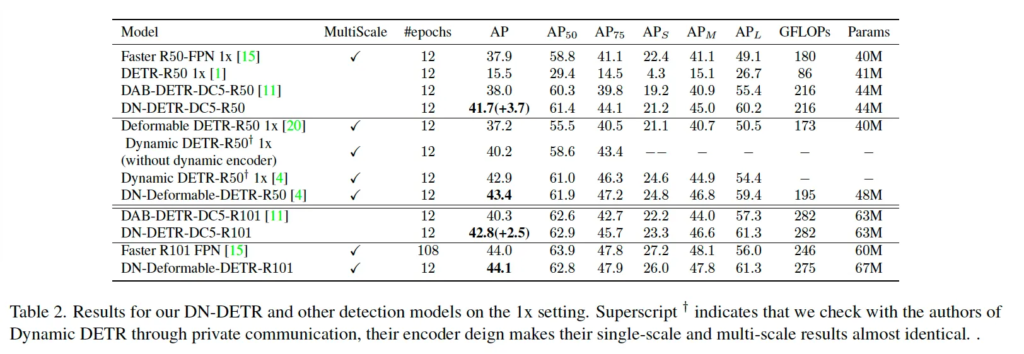
논문에서 1x setting이라고 학습을 짧게 몇 에포크만 했을 떄의 성능에 대해 리포팅한 부분입니다. 본 Denoising 학습이 수렴 속도를 빠르게 하기 위해 제안된 점을 보아 이 실험을 수행한 것 같은데, 위 table 2를 보면 denoising 학습을 통해 수렴 속도가 향상된 것을 확인할 수 있습니다. Faster RCNN과 DETR, DAP-DETR 등의 모델과 비교를 하고 있는데, DC5-R50 백본을 사용한 버전에서 DN-DETR이 DAB-DETR보다 12epoch 내에서 3.7의 성능 향상을 보이고 있는 것을 보아 학습 초기 단계에서 수렴이 더 빠르게 된다고 볼 수 있겠습니다. 또, Deformable DETR에 denoising training을 추가한 DN-Deformable DETR이 12 epoch 에서 가장 좋은 성능을 보였는데 여기서 볼 만한 점은 이 DN-Deformable DETR이 ResNet 101 backbone을 사용할 때 108 epoch만큼 학습한 Faster R-CNN보다 더 성능이 좋다는 점입니다. 즉, 9배 빠르게 유사한 성능을 뽑아냈다는 점을 주목해볼 수 있을 것 같습니다.
4.3 Compared with State-of-Art Detectors
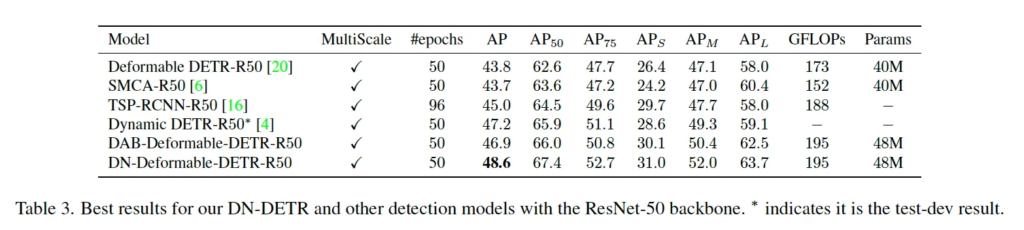
마지막으로 multi-scale 모델들과 본 방법론을 비교하는 실험입니다. 실험 결과는 위 표 3에 나와있는데, 본 논문에서 제안된 DN-Deformable DETR이 48.6 AP로 sota를 달성하였습니다. Deformable DETR에 denoising을 붙이기 위해서 deformable detr query 형식을 그대로 따르지 않고 DAP과 같이 anchor box로 구성했었는데, 이로 인한 성능 향상을 배제하기 위해서 denoising training을 하지 않은 DAB-Deformable DETR의 성능도 뽑아본 것 같습니다. 결과를 보시면 맨 아랫줄과 그 바로 윗줄을 비교하면 되는데 query를 통일했음에도 여전히 1.7 AP의 성능 향상을 보이고 있습니다.
4.4. Ablation Study

마지막으로 ablation study입니다. table4는 저자가 제안한 box denoising, label denoising, attention mask에 대한 효과를 확인하기 위한 실험에 대한 결과를 담고 있습니다. 보시면 denoising 학습의 각 구성 요소 (box, label)가 있는 경우 성능이 향상됨을 확인할 수 있습니다. 그냥 기존 detr에 box denoising을 추가했을 경우 1.2 향상을, 여기에 label까지 추가했을 경우 0.4의 향상을 보이고 있죠. 특히 볼만한 점은 attention mask의 유무에 따른 성능인 것 같은데, 이 information leakage를 막기 위한 attention mask가 없으면 성능이 43.4 → 24.0으로 크게 하락합니다.
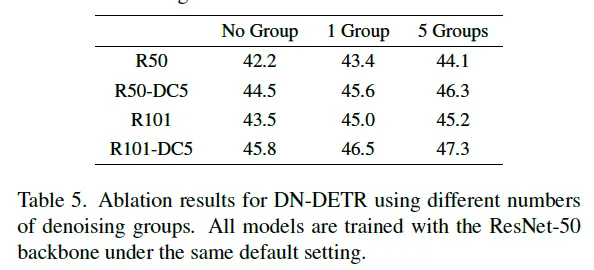
또, 논문에서는 denoising group 수에 대한 ablation study 결과도 실려있었는데요, 결과에 따르면 더 많은 denoising group을 추가하면 성능이 향상되기는 한데, 그 향상 정도가 미미해집니다. 그래서 기본 세팅으로는 5개의 group을 사용하도록 했다고 하네요.
안녕하세요 윤서님 좋은 리뷰 감사합니다.
denoising이 DETR 구조 초기의 매칭 과정에서의 불안정을 해결하는 것으로 학습의 수렴속도를 개선한 것이라고 이해했습니다. 실험 결과를 보니 확실히 이전 DETR기반의 방법론들에 비해 빠른 수렴속도를 보이는 것을 확인할 수 있었는데, 다른 방법론들에 비해 성능도 꽤나 많이 올라 신기하네요. denoising 방법을 처음 접해 성능이 오르는 것이 신기하네요. 단순히 생각했을 때에 수렴이 빠르다고 성능이 좋아지지는 않을 것 같은데 denoising의 어떤 부분이 성능에 영향을 끼친 건지 궁금합니다.
감사합니다.
안녕하세요 윤서님 리뷰 감사합니다.
gt에 noise를 추가하여 denoising query를 생성하고 이를 복원하는 과정에서 anchor의 위치와 offset을 학습한다고 하셨는데 denoising query를 복원하는 과정에서 어떻게 학습을 하는지가 와닿지 않아서 질문드립니다. 혹시 조금만 풀어서 설명해주실 수 있으실까요? 감사합니다!
안녕하세요 ! 좋은 리뷰 감사합니다.
ablation study에서 제안된 box denoising이나 label denoising, attention mask에 대한 유효성을 확인하는 실험을 수행한 것으로 보이는데, table4에서 3행을 보면 denoising은 없는데 attention mask만을 적용한 실험이 리포팅되어 있습니다. 생각해봤을 때 denoising과정이 없으면 attention mask도 필요 없을 것 같은데 이런 결과를 같이 리포팅한 이유가 있는지 궁금합니다.
감사합니다.