안녕하세요. 이번 리뷰에서는 센서과제에서 실제로 활용한 모델, 한달이 안되었지만 3.5K의 star를 받은 depth-pro에 대해 리뷰해보려 합니다. 본 논문의 ICLR나 NeurIPS 양식으로 쓰여졌지만, 애플에서 발표되었기에 테크 리포트와 유사합니다.
Introduction
본 논문은 zero-shot metric monocular depth estimation의 foundation model입니다. zero-shot, monocular depth estimation, foundation model은 워낙 익숙한 용어이므로, metric만 살펴본다면 metric(absolute) vs relative depth estimation은 기존 monocular depth estimation에서 나와 저 테이블 위의 노트북 간 거리가 정확히 몇 M인지를 알아내는 작업은 전자, 정확한 거리는 모르지만 저 테이블 위 노트북보다 테이블 옆의 의자가 더 가까운지를 알아내는 작업은 후자로, 고작 몇년 전까지만 하더라도 monocular depth estimation이라 하면 후자를 일컫었습니다. 전자는 후자의 작업에 카메라 내/외부 파라미터를 추가하여 해당 depth map의 스케일을 구한 후, depth map에 스케일을 곱하는 과정으로 이루어졌습니다. 이는 다른 말로, monocular, 즉 단일 카메라 영상만으로 metric depth를 추정하는 작업은 매우 어려운 작업으로 여겨져 왔습니다.
본 연구는 이름에서도 유추할 수 있듯, 두 가지 충족 요건을 만족해야 합니다. zero-shot, 즉 어떤 도메인의 이미지가 들어오든 잘 추정해내야하며 두 번째는 이상적으로는 위의 zero-shot 환경에서 metric depth를 추정해야합니다. 이 metric depth을 잘 추정한다는 의미는 object shape, scene layout, absolute scale를 복원하는데 핵심적인 역할을 하며, 이는 다시 monocular depth estimation의 활용 분야 중 저자(애플)가 관심을 가지는 novel view synthesis에서 핵심적인 역할을 합니다. 잘 생각해보면, 애플에서는 해당 분야의 연구를 어떻게 적용할까에 대해 생각해보았는데, monocular depth estimation 그 자체만으로도 당연히 휴대폰에 라이다를 부착할 수 없는 상황에서 도움되겠지만, 그 넘어서의 novel view synthesis에 큰 관심이 있지 않을까 생각합니다. 카메라 사진만으로 새로운 뷰를, 우리가 촬영한 관점이 아닌 다른 관점에서 동일한 뷰를 보여준다면 소비자들의 이목을 끌기 좋기 때문이죠. 이를 반증하듯, 논문에선 다음과 같이 서술합니다.
“This enables view synthesis scenarios such as “Synthesize a view of
this scene from 63 mm away” for essentially arbitrary single images.”
즉, Focal length와 같은 추가적인 정보 없이 사진으로 부터 metric depth를 잘 추론해낸다면, 사용자로부터 받은 “63mm 떨어진 위치에서 촬영한듯한 새로운 뷰 생성”에 잘 대응할 수 있으리라 생각합니다.
두 번째로 저자는 본 연구가 설득력 있는 결과를 도출해내기 위해서는 깊이 추정이 높은 해상도에서 잘 동작해야한다고 설명합니다. 제가 드는 하나의 예시로, monocular depth estimation의 대표격 dataset인 NYU v2의 경우, 640×480의 해상도를 가지고 있으며 이는 요즘 시대에선 잘 쓰이지 않는 수준의 해상도입니다. 저자는 고해상도에서도 잘 동작해야하는데, 이 때 동작한다는 의미가 단순히 깊이 추정만이 아닌 이미지의 fine-grained한 디테일, 예를 들면 머리, 털과 같은 굉장히 세밀한 부분에 대한 추정도 함께 이루어져야 함을 언급합니다. 일반적인 방법에서 그러한 세밀한 부분은 보통 배경으로 치부되기 마련이였습니다.
세 번째로 저자는 본 연구에서 중요한 점은 “low-latency”임을 강조합니다. 동영상에 대해 시시각각 처리할만큼, 우리가 아는 real-time의 30FPS 수준을 충족시킨다는 의미는 아닌, 적어도 고해상도 novel view 생성을 위한 query에 반응하여 1초 내에는 영상을 생성해내야함을 언급합니다. (실제로 depth-pro는 하나의 V100 gpu에서 2.25-mega pixel (1536×1536)에서 0.3의 추론 시간을 보입니다) 이렇게 논문의 글을 옮겨쓰다 보니, 역시나 애플에서는 단순히 metric-scale monocular depth estimation이 아닌 이를 기반으로 하는 novel-view synthesis에 더 관심이 있음을 알 수 있습니다. depth-pro로부터 생성된 depth-map이 얼마나 뛰어난지는, 아래의 정성적 결과를 우선 확인해보시죠.


저자가 말하는 네 가지 contribution은 다음과 같습니다.
- 고해상도에서 미세한 부분을 포착함과 동시에 정확한 (global) metric-scale 깊이 추정을 위한 multi-scale ViT 기반의 구조를 활용합니다.
- 해당 연구에서, 머리카락, 털과 같은 세부 boundary 정보에 대한 정량적 평가를 위한 metric을 제안합니다.
- synthetic dataset을 활용함을 pixelwise ground-truth에서 더 정확한 정보를 얻을 수 있지만, 현실성이 떨어집니다. 고로, 그 반대의 장단점을 가지는 real-world dataset과 함께 학습하기 위한 학습 방식과 손실 함수를 제안합니다.
- 마지막으로는, zero-shot depth estimation 뿐 아닌 zero-shot focal length (scale) estimation을 함께 연구하여 이전 방법론에 비해 월등히 뛰어난 성능을 보입니다.
여담으로, github 내 issue에서 training code에 대한 배포 일정을 물어보았습니다. 현재 코드는 inference-only로, library로 배포되어 있으며 training scheme에 대한 상세한 설명은 되어 있지 않은데, 그 issue에서 한 유저가 하나의 V100 gpu로 얼마나 학습 시간이 걸릴까 계산해보았을 때, 175일이 걸린다고 합니다. 물론, 애플급의 초거대 기업에서 진행되었기에 만약 정말 하나의 gpu로 175일이 걸린다할지언정, 단순히 175개의 gpu를 쓰면 하루, 350개의 gpu를 쓰면 반나절이면 모든 학습이 끝날 연구긴 합니다만, 이런 연구들을 어떻게 활용할 것인지에 초점을 잡아야지, 해당 연구를 어떻게 학습시킬 수 있을 것인지는 우리가 하긴 어렵습니다.
Method
저자가 고안한 구조가 새롭지는 않습니다. 적어도 제가 아는 foundation model이나 혹은 그 급의 모델들은 보통 ViT 인코더를 활용하며, 모델 구성에서 새로움이 있다기 보다는 여러 dataset을 활용하기에 학습 과정에서의 스킬이나 최적화 기법에 관여하기 마련입니다. 본 구조 또한 1536×1536의 이미지를 기반으로 하므로, 해당 사이즈로 resize한 이후, 백본을 거치며 multi-scale feature map을 추출하여 이들을 384×384의 사이즈로 만들어 ViT 인코더에 통과시킵니다. 저자는 해당 과정이 scale-invariant하게끔 scale별로 weight이 공유되므로, multi-scale에서의 다양한 표현력을 학습함에 장점이 있다고 설명하며, 큰 scale의 입력이 들어왔을 때 종종 마주치던 out-of-memory에 대해서도 자유로울 수 있음 (384×384로 down-sampling해서 ViT 인코더에 입력시키므로)을 설명합니다. 또한 이처럼 down-sampling하는 방식은 variable-resolution에 대한 접근 방식보다 더 빠르고 정확함을 보장하며, 서두에 언급한 일반적인 ViT 백본을 활용함은 결국엔 더 많이 연구되어 온 방식이므로, 풍부한 사전지식을 활용할 수 있기에 이를 선택했다고 합니다 (이는 뒤의 실험에서도 다양한 pretrained backbone에 대한 비교를 통해 증명됩니다).

ViT의 patch encoder를 제외하고도, 이미지를 split하지 않은 384×384의 feature map에서 image encoder를 태운다면, 24×24 resolution의 tensor를 얻을 수 있는데, 저자는 이렇게 patch encoder와 image encoder를 동시에 활용한 이유에 대해, image encoder의 feature map을 활용함으로써 세밀한 부분에 대한 모델의 이해력을 높일 수 있음을 언급합니다. 저자의 의도대로라면, 전체적인 구성에서 patch encoder는 global한 영역에 대한 이해력을, image encoder는 local한 영역에 대한 이해력을 높일 수 있음으로 이해됩니다. 이후 dpt (depth anything)의 decoder와 focal length를 예측하기 위한, 몇몇의 linear layer로 설계된 focal length head로, 모델 구성은 어찌보면 굉장히 단순합니다. 이제, 학습 과정을 살펴보겠습니다.
Training objectives
입력 이미지 I 에 대해, 네트워크 f 는 inverse depth image C = f(I) 를 생성합니다. 최종적으로 dense metric depth map D_{m} 을 얻기 위해선, 해당 depth map을 focal length f_{px} 와 width(baseline) w 으로 표현되는 horizontal FoV(scale)로 연산을 취해주어야 합니다 (자세히는, inverse depth map에 width를 곱한 값에 역수를 취한 후, focal length를 곱해주어야 합니다). 이 때 우선시되는 inverse depth map을 얻기 위해서 저자는 gt inverse depth map, \hat{C} 를 활용하여 학습할텐데, 이 때 학습 과정에서 mean absolute error 기반으로 예측한 depth map에서 모든 pixel i 에 대해 에러율을 구해, Top20%는 버리고서 학습시킵니다. 이렇게 한다면 예측하는 depth map을 어느 정도 신뢰한다는 말과 동시에, gt를 모두 활용하지 않으므로 예측 값과 분포가 많이 다른, gt pixel을 학습에서 제외시킬 수 있는 장점도 보유합니다. (metric dataset은 synthetic dataset으로 해석됩니다)
반면, real-world dataset에서는 non-metric dataset도 존재합니다. non-metric dataset이란 camera intrinsic이 존재하지 않거나, depth map의 scale이 일관되지 않고 큰 범위로 변하는 경우를 의미할 수 있는데, 저자는 해당 dataset을 활용 시에는 loss를 적용하기 이전, 중앙값으로부터 mean absolute의 편차를 통해 예측과 gt를 normalize합니다. 이는 곧 예측과 gt가 크게 벗어나는 값 또한 normalize됨으로써, 비록 잘못된 scale이 들어왔음에도 loss에 너무 큰 영향을 주지 않게 할 수 있습니다. 이 문단을 보며 드는 점으로는, 비록 non-metric dataset과 같이 신뢰할 수 없는 dataset임에도, 이들을 학습에 활용하지 않기 보다는 활용하는게 오히려 더 성능에 도움이 되지 않았을까, 즉 역시나 학습 데이터의 수가 굉장히 귀하고 중요하다는 생각이 다시 한 번 드네요.
Training curriculum
저자가 제안하는 학습 커리큘럼은 다음을 기반으로 합니다. 우선 저자가 실험을 통해/이전 연구들을 통해 통찰했을 시, real-world와 synthetic dataset을 혼합하여 학습함이 zero-shot의 정확도에 도움이 됨. 두 번째로는 synthetic dataset은 real-world dataset이 가지는 missing area, mismatched depth, false measurments on object boundaries의 단점에 비해 더 정확한 pixel-accurate gt를 가짐. 마지막으로는,훈련을 하면 할수록 모델이 boundary와 같은 지점의 표현이 명확해짐.
위 관찰을 토대로 저자는 앞선 training loss에서 소개한 바와 같이 real-world와 synthetic dataset을 혼합하여 학습하는 대신, real-world dataset 중 metric dataset에 대해서는 단순히 loss를 줄이도록 학습시키며, non-metric dataset에 대해서는 normalized loss를 줄이도록 학습시킵니다. 이 때 제가 관찰한 “그래도 부정확하더라도 많은 데이터가 짱이구나”와 유사한듯, 유사하지 않은듯한 저자의 관점은 “그러한 non-metric dataset을 학습함이 실제로 real-world gt에서 가능한 corruption도 대응할 수 있다”고 설명합니다. (저의 해석으로 이 때의 corruption이란, 모델이 예측하기 때문에 gt가 없는 상황이 아닌 아마도 영상 내 flying pixel 등 영상적 오류가 아닐까 생각합니다).
다음으로는 hair, fur과 같은 경계 지점에 보다 sharpe하고, 예측된 depth map이 그러한 세부 사항들을 잘 표현하기 위한 방법입니다. 이들은 곧, “얼마나 gt가 그런 세밀한 부분에 대해 정확한가”가 핵심이 될 수 있기에, 그러한 표현력을 학습하기 위해 synthetic data에 대해 fine-tuning을 하는, 일반적 기조를 뒤집습니다. 앞서 언급한 바와 같이 non-metric한 real-world dataset에서는 그런 세밀한 부분에 대한 gt depth가 부정확할때가 많기에, 저자는 real+synthetic으로 학습하여 전체적인 표현력을 끌어올리고 (두 문단 위에서 설명), synthetic dataset을 추가로 활용하여 세밀한 부분에 대한 학습을 추가로 지원한 것으로 보입니다.
Evaluation metrics for sharp boundaries
저자의 두 번째 contribution으로 소개드린 sharp boundary에서의 평가 매트릭입니다. 굉장히 복잡한 수식이 들어있기에 제 수학적 지식의 한계로 자세한 설명이 안될 수 있지만, 최대한 이해되는대로 설명해보겠습니다 ㅎㅎ;;
이전의 monocular depth estimation에서는 객체 경계 부분이 얼마나 sharpness한지 고려하는 metric이 없지만, misaligned되었거나 blurry한 객체 경계는 view synthesis 시 왜곡되게 보이거나 단일 객체가 여러 개로 보일 수도 있습니다. 이러한 부분에 대한 metric이 존재하지 않은 이유는 어쩌면 real-world에서 pixel-level로 정확한 dataset이 존재하지 않기 때문일 수도 있습니다. 저자는 boundary에 대한 metric을 세우고자 했으며, 이 때 고품질의 saliency map이나 segmentation map이 해결점이 될 수 있음을 주장합니다. 이 saliency/segmentation map을 binary map 형태로 가져간다면 (saliency는 원래 그렇지만), 해당 map에서의 boundary만을 활용하여 평가에 쓸 수 있습니다.
우선 foreground/background에 해당하는 pixel을 정의하고자, 저자는 이웃하는 픽셀의 깊이 비를 활용합니다. i,j 를 이웃하는 픽셀이라고 할 때, 두 픽셀이 contour인지를 정의짓기 위해 t라는 지표를 통해, t% 이상인지 c_d(i,j) ) 아닌지로 contour를 정합니다. 그 때, 아래의 수식을 통해 P(precision)과 R(recall)을 아래의 수식으로 정의한다고 합니다. 이 둘을 가지고 t를 5~25까지 조절하며 F1 score를 리포팅한다고 합니다. 흠,,, 이 부분에 대해선 제가 수식에 관한 이해력이 읽어봐도 잘 모르겠습니다 ㅎㅎ.. 어찌되었든 중요한 점은 결론은 두 이웃하는 픽셀로 contour를 정하고, 이들로부터 boundary인지 아닌지를 정의한 이후 boundary에 대한 precision과 recall을 구하며 이 둘로 다시 F1 Score를 정의할 수 있으니, 그 지표로 리포팅되어 있다고 이해하면 될 듯 합니다.
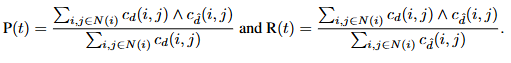
Focal Length Estimation
부정확한 EXIF 메타데이터 (EXIF 메타 데이터란, 셔터 속도, Focal length, ISO와 같은 카메라 값을 의미합니다)의 이미지에 대응하고자, 또한 monocular metric depth estimation의 기조 또한 Focal length도 함께 추정하기에, 앞선 architecture에서도 살펴볼 수 있었습니다. ViT image encoder로부터 horizontal FoV 값을 추정하는 형태로 학습되며, 한 가지 요점은 이 focal length estimation이 metric depth와 연관된 점이지만, 동시에 학습할 필요는 없다는 점입니다. 오히려 저자는 실험에서 joint training, 함께 학습하는 것 보다 따로 학습함이 더 좋았다고 하며, 실제로 몇몇 dataset에서는 focal length와 같은 정보가 주어져 있지 않아 어짜피 joint training은 힘들었을 것 같습니다.
Experiments
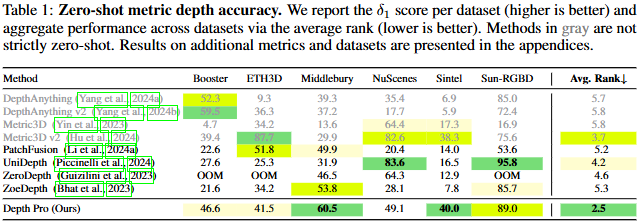
주요한 성능 몇 가지 표를 살펴보겠습니다. 우선 zero-shot metric depth accuracy에서, 표의 설명과 같이 저자는 depth anything은 엄격히 말해선 zero-shot이 아니라고 하네요. 왜 그런지 살펴보니, depth anything의 경우 relative depth estimation에 중점을 두어, metric depth estimation의 경우 해당 모델을 indoor&outdoor로 구분하여 fine-tuning하였다고 합니다. 즉, 해당 모델은 어떤 scene이든이 아닌, scene이 indoor면 depth anything 버전 A, outdoor면 depth anything 버전 B와 같이 활용되므로 엄격히는 zero-shot이 아니라고 설명합니다. Metric3D v1, v2의 경우, 읽어보진 않았지만 해당 모델에서 test time 시 crop size에 관해 지정하는 옵션이 있는 것 처럼 보이며, 저자는 이 crop size에 따라 성능이 천차만별이므로 이 또한 “어떤 scene이든 좋은”을 충족하지 않으므로 zero-shot이 아니라고 이해됩니다. 그렇기에 patchfusion 아래의 성능만 놓고보자면, 6개의 dataset에서 4개의 dataset에서 sota의 성능을 보입니다. unidepth는 대충 한 번 보긴 했는데, 신기한건 둘 다 foundation model인데 성능 차이가 dataset에 대비 꽤나 극심합니다. 이렇게 보다 보면 각 dataset에서 왜 그런 좋지/좋지 않은지에 대한 이해만 되어도 그들의 장점을 결합하여 더 좋은 모델이 될 수 있을텐데요.
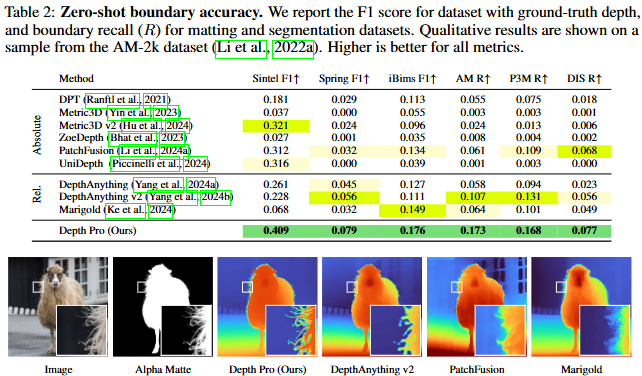
다음으로는 boundary accuracy입니다. 위에서 설명드린 바와 같이 F1 score로 리포팅하였으며, image matting과 segmentation에 대해서는 recall을 또한 리포팅하였습니다. 위 예시에서 이미지와 matte, 결과에서 gt boundary를 보았을 때, 이전의 세 방법론에 비해 depth pro는 거의 gt급의 굉장히 fine-grained한 결과를 보입니다.
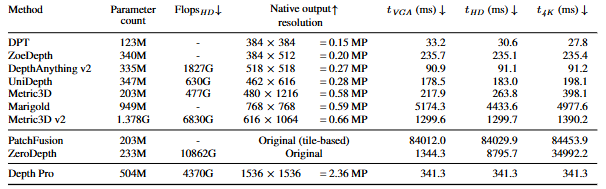
다음으로 foundation model들의 inference time을 측정하기 위해, 저자는 V100 GPU에서 위 모델들의 inference time을 모두 측정하였습니다. 괄목할만한 점으로, 1536×1536의 resolution에서도, 341(ms)의 빠른 속도를 보입니다. 하지만 이는 과연 DPT(depth anything v1)나 depth anything v2에 비해 정량적으로 비교될 수 있을지는 모르겠습니다.
이번에는 foundation model, zero-shot monocular depth estimation에 관한 논문(또는 테크리포트)을 리뷰 했습니다. 본 논문은 제 과제에서 실제로 활용하고 있기에 리뷰하였지만, 논문을 전체적으로 읽은 총평은, “애플에서 novel view synthesis에 관한 카메라(사진첩) AI 기능을 언젠가 탑재하겠구나”였습니다. 삼성에서도 카메라에 AI 기능을 많이 삽입하였는데, 애플에서도 당연히 카메라에 자부심이 있는 만큼 새로운 기술에 관심이 많은듯합니다.
안녕하세요 이상인 연구원님 좋은 리뷰 감사합니다.
모델 구조를 보면서 개인적인 의문점이 있어 질문 드립니다. image encoder의 feature map을 통해 local한 부분을 patch encoder를 통해 global한 정보를 이해할 수 있다고 설명해 주셨는데요, image encoder에 들어가는 384^2 이미지의 경우 원본 이미지를 downsampling한 feature에 해당하기 때문에 오히려 global 한 정보를 이미 가지고 있는 거라 이를 통해 세밀한 부분에 대한 이해가 가능한지 의문이 들었습니다. 오히려 원본 이미지의 각 patch 들이 고해상도의 raw 이미지이기 때문에 local 정보를 보완해주는 역할이 아닌지… 혹시 이 부분에 대해 간단히 알려주실 수 있나요…?
읽다보니 헷갈리네요…
안녕하세요. 질문 감사합니다.
아 그.. 제가 처음 작성하면서는 Patch Encoder와 Image Encoder가 각각 ViT기반, CNN기반인줄 알고 위와 같이 작성하였었는데, 작성하면서 다시 읽어보면서 Image Encoder 또한 ViT기반임을 알게 되었습니다.
그래서 아래에서부터 Image Encoder가 CNN기반이라는 내용을 거의 다 지운줄 알았으나, 아직 그 내용이 남아있었나봅니다.
질문에 답하자면, 말씀하신 바와 같이 Image Encoder 또한 ViT 기반으로 Global context를 가진다고 봐주시면 좋을 것 같습니다.
좋은 리뷰 감사합니다.
다른 일반적인 mono depth 방법론들에서는 불가능했던, 본 논문에서 metric depth를 예측할 수 있었던 key 가 어떤것일까요? 많은 dataset (with metric depth gt) 를 통해 풍부한 학습으로 얻은 일반화된 성능으로 얻을 수 있는 것인가요?
감사합니다.
안녕하세요.
다른 일반적인 음.. 제가 이 분야를 항상 보고 있는건 아니지만, relative depth estimation이 아닌 monocular 만으로 metric depth estimation을 예측하는 연구는 한 1-2년 전쯤부터 이어져오는 것 같습니다.
역시나 말씀하신 foundation 급의 데이터를 학습시킴이 역시 핵심이 아닐까 싶습니다.
혁신적인 방법이 나올지언정, 제 생각에 본 연구에서 너무나도 어려운 “카메라 파라미터가 실제로 존재하지 않는 상황”만으로 metric을 알려면, 그만큼 데이터가 뒷받침 되어야하기 때문입니다.
안녕하세요 상인님 좋은 리뷰 감사합니다. 정성적 결과를 보니 생각보다도 더 정교하게 예측하는 것이 신기하네요.
synthetic dataset에 대해 잘 알지 못하여 찾아보니 생성된 이미지를 통해 구성된 데이터셋인 것 같은데 데이터를 생성할 때 카메라의 intrinsic정보 등도 생성되어 활용하는 건가요? 관련해서 synthetic dataset이 어떻게 구성되는 것인지 궁금합니다.
추가로 신뢰할 수 없는 데이터를 활용하여 학습할 때에는 모델의 예측값에 의존하게 된다고 언급해주셨는데 학습 초기 예측값이 정확하지 않을 때에는 따로 처리를 해주나요? 제 생각으로는 정확한 데이터로 웜업을 하는 등의 과정이 있으면 좋을 것 같은데 관련된 디테일이 있는지 궁금합니다.
감사합니다.
안녕하세요 상인님 리뷰 감사합니다.
ViT기반 multi-scale구조가 scale-invariant를 위해서만 존재하는 건가요? 아니면 multi-scale자체가 정확도를 증가시키는데도 나름 중요한 요소로 기여를 하는걸까요?? 아직 지식이 부족해서 이해를 잘 하지 못해 여쭤봅니다!!
안녕하세요 상인님, 정말 좋은 리뷰 감사드립니다.
리뷰를 읽으면서 제가 이해한 내용과 헷갈리는 부분이 있어 확인 받고자 댓글을 드립니다!
첫번째 헷갈렸던 부분은 혜원님의 댓글로 해소가 되었습니다!
두번째도 비슷한 부분에서의 질문입니다!
patch encoder는 local patch를 대상으로 하기 때문에, 각 local patch들 각각에 한에서는 global 한 이해력은 가질 수 있지만 image 전체에 대해서는 global한 이해력을 가질 수 없지 않을까에 대한 의문점이 생겨서 답글을 드립니다!
혹시 제가 구조를 잘못 이해하고 있는 것일 수도 있어 조심스럽게 여쭤봅니다.
감사합니다!
음 사실 제가 본 논문을 읽은지는 꽤 오래되어 정확한 기억은 나지 않습니다만,
patch encoder가 multi-scale이기에 이들의 정보를 합친다면 곧 global한 이해력을 가진다고 해석할 수 있을 것으로 보입니다.