Introduction
본 논문의 intro에서는 기존 SER의 한계점을 바탕으로 저자들이 Speech emotion captioning이라는 task를 제안한 이유에 대해 설명하고 있는데요, 일반적으로 음성 감정인식은 분류 task로, 인간의 감정을 ‘행복’, ‘슬픔’, ‘공포’와 같이 discrete한 class에 할당하는 방식으로 동작하였습니다. 그러나 이러한 방식으로 단일 라벨링을 진행하게 되면 음성 데이터에 내재된 감정에 대한 정보를 충분히 활용할 수 없게 됩니다. 본문에서는 음성의 뉘앙스를 파악하기 어려웠다고 합니다.
어떤 음성을 하나의 discrete한 감정으로 mapping하는 것을 논문에서는 ‘single-word label’이라 표현하였으며, 저자들은 이러한 방식에는 몇 가지 문제점이 있음을 언급하였습니다. 먼저, 앞서 언급하였듯이 보다 복잡한 수준의 정보 파악이 어려워진다는 단점이 있습니다. 감정에는 category 뿐 아니라 해당 감정이 어느 정도의 강도를 가지는지 나타내는 intensity와 시간에 따른 감정의 변화를 나타내는 fluctuation이 있으나, 어떠한 음성의 감정을 단순히 하나의 단어(emotion class)로만 표현해 버리면 이러한 정보를 충분히 고려할 수 없겠죠. 또 다른 문제는 감정의 주관성으로, 동일한 음성이라도 듣는 사람에 따라 그 감정을 다르게 해석할 여지가 있으며, 일반적인 데이터셋은 annotator 개인의 주관에 의해 감정 label이 결정되기 때문에 label의 일관성이 떨어지는 문제가 발생하고, 감정 인식 결과에 가변성이 존재하게 된다는 것입니다.
저자들은 SER에서 class label을 사용하는 것은 음성 데이터가 가진 정보를 충분히 드러내지 못한다는 점에 주목하여 label 대신 자연어 문장 형태로 감정을 표현하고자 하였고, Automated Audio Captioning task에서 영감을 받아 Speech Emotion Captinoing(SEC)라는 framework를 제안하였습니다.
SEC에는 두 가지 challenge가 있으며, 첫 번째는 음성으로부터 emotion-related feature를 잘 추출하는 것이고, 두 번째는 high-quality human-like speech emotion description을 생성하는 것이라고 합니다.
첫 번째 challenge, emotion-related feature 추출의 경우, 감정 captoin이 있는 음성 데이터로 학습된 음성 사전학습 모델은 드물기 때문에 기존 SER논문에서 좋은 성능을 보인 HuBERT를 feature extractor로 사용하고자 하였습니다. 그러나 HuBERT의 feature를 직접 사용하는 것은 연산이 무거워지기 때문에 저자들은 QFformer를 Bridge-Net으로 사용하여 HuBERT에서 뽑아낸 feature를 압축하여 연산량을 줄였다고 합니다.
두 번째 challenge는 음성으로부터 추출된 feature로부터 보다 높은 품질의, 사람이 이해할 수 있는 자연어 형태의 caption을 생성하는 것으로, 논문에서는 감정의 미묘한 뉘앙스 변화를 담아내는 것이 중요하다고 언급하였습니다. 저자들은 대규모 LLM인 LLaMA를 text decoder로 사용하여 Bridge-Net인 QFormer가 뽑아낸 feature를 기반으로 일관적이면서도 고품질의 caption을 생성하고자 하였습니다. 동시에, LLaMA를 통해 QFormer의 학습을 유도함으로써 emotion related feature가 LLaMA에 더 효과적으로 반영될 수 있게 하였다고 합니다.
저자들이 밝힌 본 논문의 contribution은 아래와 같이 정리할 수 있습니다.
- We propose the task of Speech Emotion Captioning (SEC), which, to our knowledge, stands among the pioneering efforts to characterize speech emotions using natural language.
- We introduce SECap to tackle the SEC task, which comprises a HuBERT-based audio encoder, a Q-Formerbased Bridge-Net, and a LLaMA-based text decoder.
- Experimental results show that SECap is capable of generating suitable and fluent speech emotion captions that are on par with human-labeled speech emotion captions.
Method
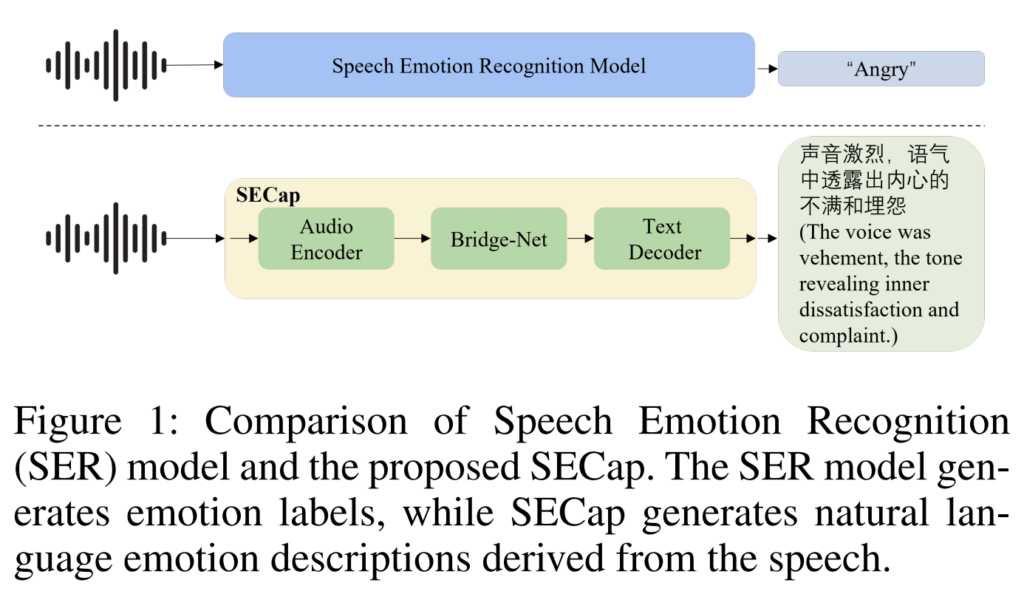
위의 [그림 1]을 통해 기존 SER과 본 논문에서 제안하는 SEC의 차이점을 확인할 수 있습니다. 입력된 음성 데이터에 대해 “Angry”라는 emotion label을 출력하는 SER과 달리, SEC는 caption을 통해 감정을 드러내는 요소(vehement voice) 및 보다 세분화된 표현(dissatisfaction, complaint)을 통해 음성에 포함된 감정적인 뉘앙스를 표현하려는 것을 확인할 수 있습니다.
그렇다면 이제 저자들이 제안하는 captioning 모델 SECap의 구조에 대해 설명드리겠습니다.
위의 [그림 1]에서 간단히 묘사되어 있듯 SECap은 음성 신호로부터 feature를 추출하기 위한 Audio Encoder, 음성 feature를 기반으로 caption을 생성하기 위한 Text Decoder, 그리고 그 중간에 위치한 Bridge-Net으로 구성되어 있습니다. 각 부분에 대한 자세한 구조는 아래의 [그림 2]와 같습니다.
Model Architecture
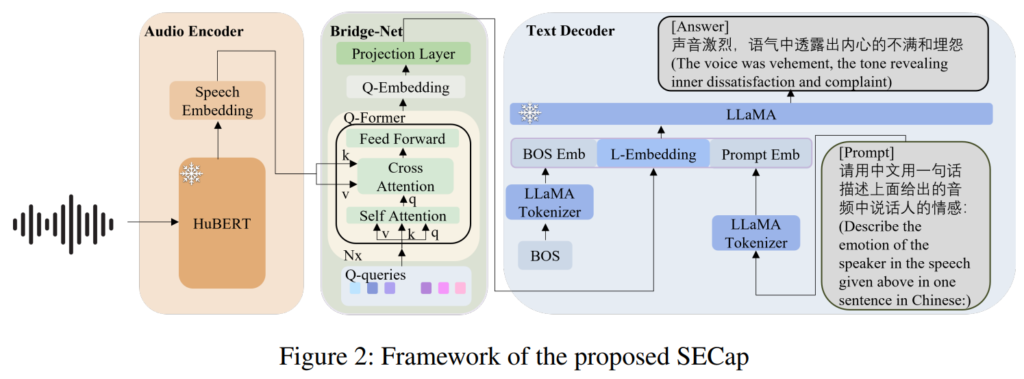
SECap의 보다 구체적인 구조는 위의 [그림 2]와 같습니다.
Encoder는 사전 학습된 HuBERT를 freeze하여 사용하였는데, 저자들은 based audio encoder인 HuBERT는 잘 학습되었기에 고품질의 speech embedding을 만들 수 있었다고 합니다. 그러나, audio의 frame-level에서 추출된 feature는 많은 연산량을 필요로 하게 되어 그대로 사용하기에는 비효율적인 측면이 있다는 점을 언급하였습니다. 이에, encoder와 decoder 사이에서 Bridge-Net을 통해 feature 압축을 진행하였습니다. 저자들이 제안한 Bridge-Net은 Q-Former 기반의 구조를 가지고 있으며, encoder에서 추출된 음성 feature의 차원 수를 줄일 뿐 아니라 emotion -related feature를 추출하도록 설계하였습니다. 또한 audio representation을 text 공간에 embedding하는 역할을 한다고 하네요. 마지막으로 Decoder는 LLaMA를 사용하였다고 합니다. 이때 encoder와 마찬가지로 freeze하여 사용하였으며, LLaMA에는 input fearue이외에도 문장의 시작을 의미하는 BOS token, prompt embedding이 추가로 필요한데, 프롬프트의 경우, [그림 2]의 [Prompt]와 같은 형식의 문장을 사용하였다고 합니다.
Q-Former
앞서 언급하였듯 결국 학습이 진행되는 것은 Bridge-Net이며, 그 구조는 아래의 그림과 같이 Q-Former와 projection layer로 구성되어 있습니다.
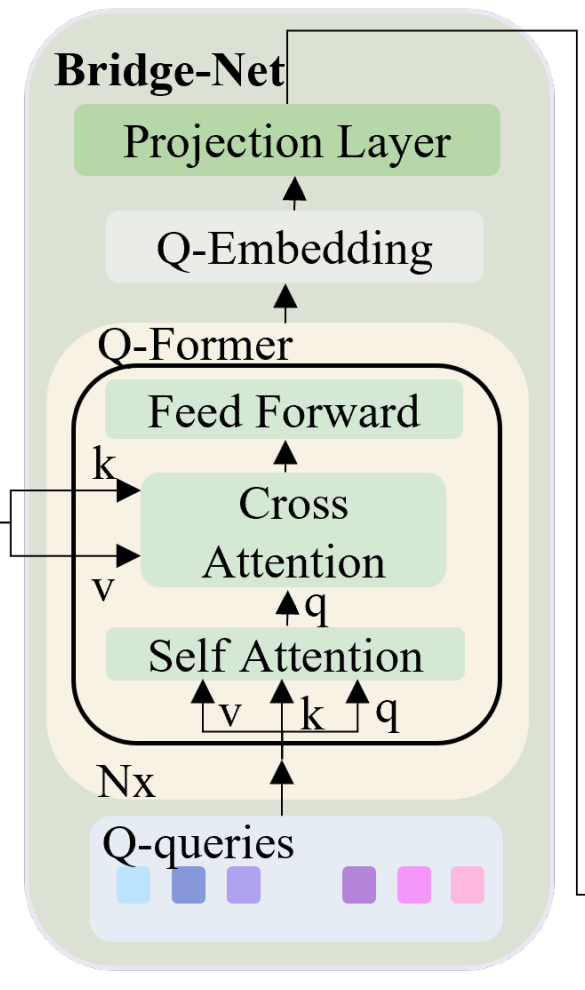
위 그림에서 self-attention이 진행되는 부분이 특이하게 input audio feature가 아니라 Q-query로 되어있는데요, Q-query는 learnable parameter로써 학습을 통해 감정 정보를 보다 잘 표현할 수 있는 방향으로 업데이트가 진행된다고 합니다.
Q-query의 self-attention을 통해 query가 생성되면 audio feature가 key, value로 cross attention을 진행하는데 이 attention mechanism을 통해 speech embedding안에서 Q-queries와 관련된 feature를 추출할 수 있게 됩니다.
이때 cross attention을 수행하기 위해 learnable weight matrix를 통해 key, value의 shape을 조정하며, 결과적으로 Q-former의 output인 Q-Embedding은 Q-Query와 동일한 차원 수를 가지며, 그 길이는 입력된 audio의 길이와 동일하다고 합니다. 즉, Q-Former의 출력인 Q-Embedding Q_e \in \mathbb{R}^{n_s \times n_q \times d_q}는 input audio에 대해 각각 독립적인 길이를 유지하여, 다양한 길이의 음성 입력에 대한 일반화 성능을 향상시켰습니다.
Obtain Emotion-Related Representations
저자들은 q-former가 emotion-related representation을 잘 학습할 수 있도록 human-labeled speech emotion caption과 audio의 transcription을 함께 사용하는 방식을 제안하였고, pipeline은 아래의 [그림 3]과 같습니다.
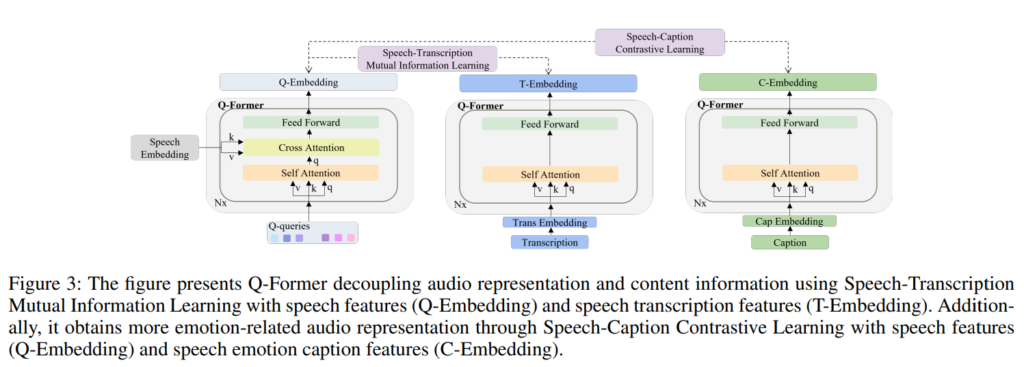
Speech-Transcription Mutual Information Learning (STMIL)
Speech-Transcription Mutual Information Learning 단계에서는 speech의 transcription을 사용하여 speech로부터 content 정보를 분리하였고, 이를 통해 발화의 내용이 아닌 speech의 음성적 특징에 집중하도록 하였습니다. 본문에서 사용된 표현을 빌리자면 speech feature를 speech content로부터 disentangle하는 것이라고 할 수 있습니다. Speech에서 언어가 가진 content 정보는 모델의 감정 예측에 영향을 줄 수 있습니다. 그러나 문장에 쓰인 단어와 음성에 담긴 감정 정보가 상반되는 경우에는 오히려 단어의 content 정보가 감정 예측에 악영향을 주게 됩니다.
논문에서는 speech feature에서 content 정보를 제거하기 위해 mutual information을 활용하였는데요, 쉽게 말하자면 speech feature와 speech transcription feature간의 상관 관계를 최소화하는 것입니다. Speech Embedding과 Speech Transcription Embedding을 각각 Q-Former에 통과시켜 얻은 embedding vector를 각각 Q_e와 Q_t라고 할 때, Q_e와 Q_t 사이의 상관 관계, 즉 mutual information은 아래의 [수식 3]과 같이 나타낼 수 있습니다.
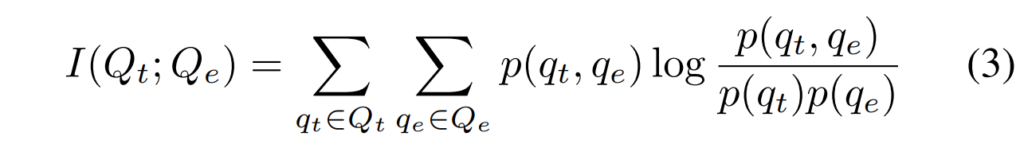
위의 [수식 3]에서 p(q_t, q_e)는 Q_t와 Q_e의 결합 확률 분포를, p(q_t) 와 p(q_e)는 각각 Q_t와 Q_e의 주변 확률 분포를 나타낸다고 합니다. 그러나 이러한 mutual information을 직접 계산하는 것이 불가능하다고 하며, 이에 따라 저자들은 아래의 [수식 4]와 같이mutual information의 상한을 계산하는 방법인 vCLUB[ ]을 두 벡터간의 상관 관계로써 사용하였다고 합니다.
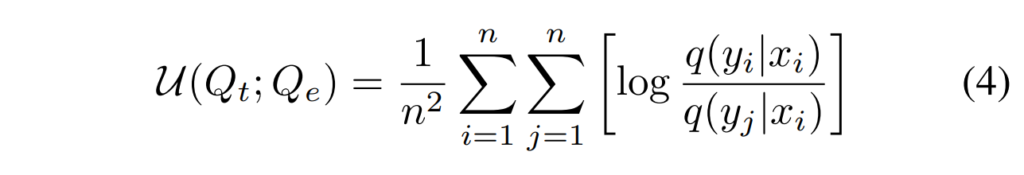
Speech-Caption Contrastive Learning (SCCL)
앞선 STMIL이 content의 정보를 배제하는 것이라면 Speech-Caption Contrastive Learning은 gt인 caption 정보를 활용하여 q-former에 emotion-related speech feature를 학습시키는 것이라고 할 수 있습니다. speech feature에는 content 정보 이외에도 background noise, emotion-related 등 여러 정보가 포함되어 있습니다. 저자들이 제안하는 SCCL은 LLaMA가 처리하는 speech feature의 복잡성을 완화하기 위해 Q-Former가 speech emotion caption과 관련성이 높은 feature만을 추출하도록 하였습니다.
SCCL은 [그림 3]의 오른쪽과 같이 speech feature와 caption에서 생성되는 text feature 간의 gap을 줄이 text modality사이의 gap을 줄이는 방식으로 학습되며, 아래의 [수식 5]와 같이 나타낼 수 있습니다.
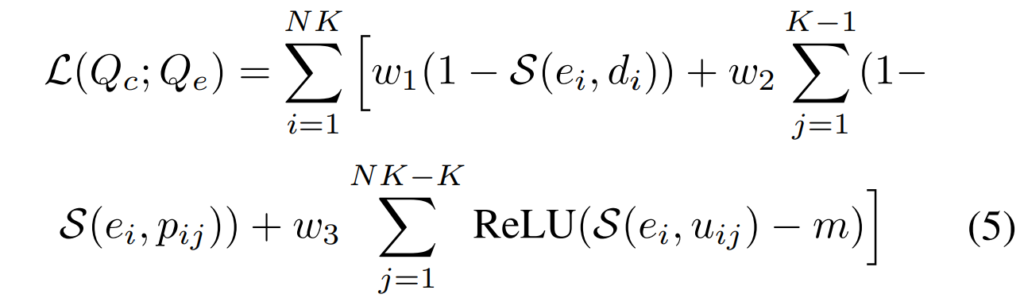
위의 수식은 speech representation Q_e와 caption representation Q_c간의 contrastive learning을 나타내는 것입니다. 감정 카테고리가 N개 일 때 각 감정별로 K개의 speech-caption pair를 선정한다면, 하나의 Q_e에는 해당 음성과 완전히 일치하는 caption에서 추출된 Q_c 1개와, 동일한 감정 카테고리에 있는 K-1개의 sample이 존재하게 되며, 이들을 positive sample로 취급하였습니다. 그리고 나머지 NK-1개의 caption들을 negative sample로 취급하였습니다.
Training Process
SECap은 두 단계의 training process로 구성되어 있으며, 첫 번째는 추출한 audio feature을 압축하고 emotion-related 정보를 학습하는 것이고, 두 번째는 해당 feature를 LLaMA의 feature space에 projection하는 것입니다.
먼저 첫 단계는 [그림 3]과 같이 STMIL과 SCCL을 결합하여 Q-former를 학습하는 것이고 그 때의 Loss는 아래의 [수식 6]과 같습니다. 이 단계에서는 decoder 없이 encoder와 Q-former만 사용하게 됩니다.
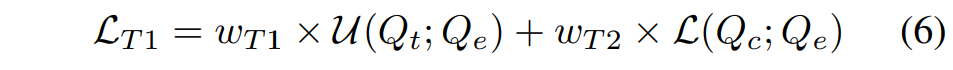
다음으로는 앞 단계에서 학습된 Q-Former에 projection layer를 추가하고, 그 뒤에 decoder를 연결하여 Bridge-Net 전체를 fine-tuning하였습니다.
Experiments
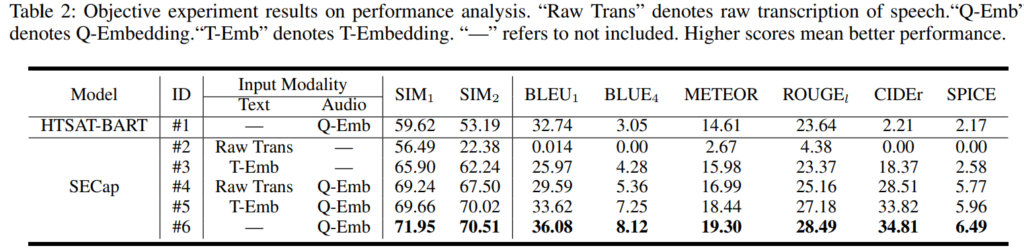
위의 [표 2]는 SECap의 성능을 평가한 것이며, 사용된 metric은 captioning 분야의 것으로, 생성한 caption과 labelling된 caption간의 유사도입니다. BLEU ~ SPICE는 word-level 기반의 metric이고, SIM_1, SIM_2의 경우 sentence level 의 metric이라고 합니다.
[표 2]를 통해 SECap이 Q-Embedding만 사용했을 때 모든 metric에서 HTSAT-BART 보다 높은 성능을 보이는 것을 확인할 수 있습니다.
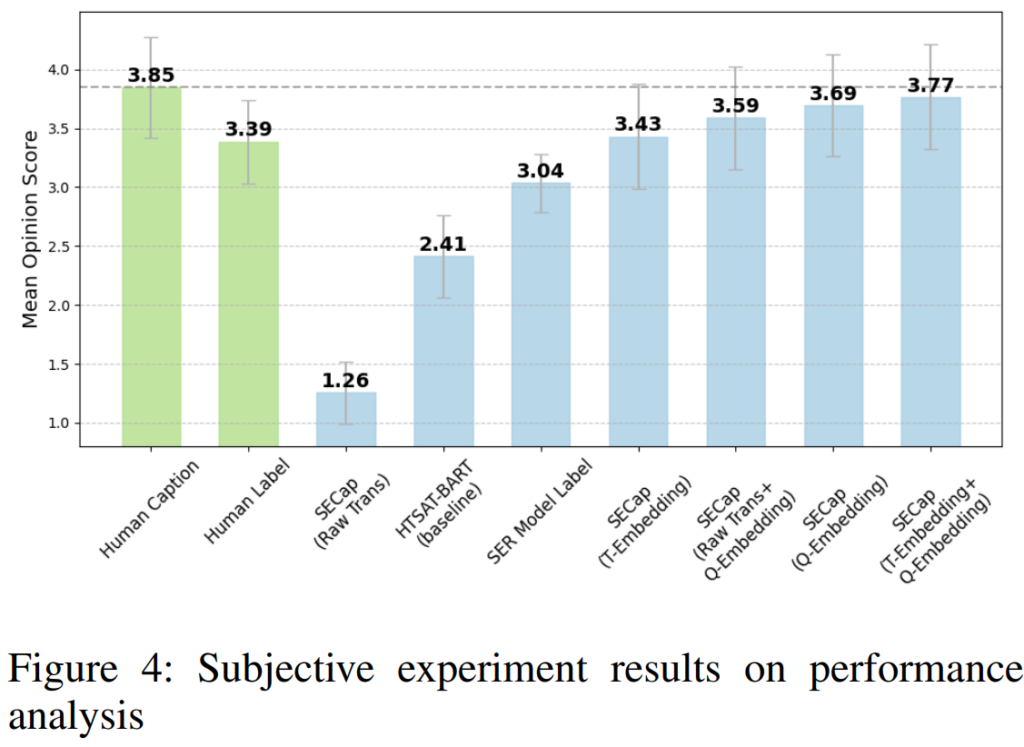
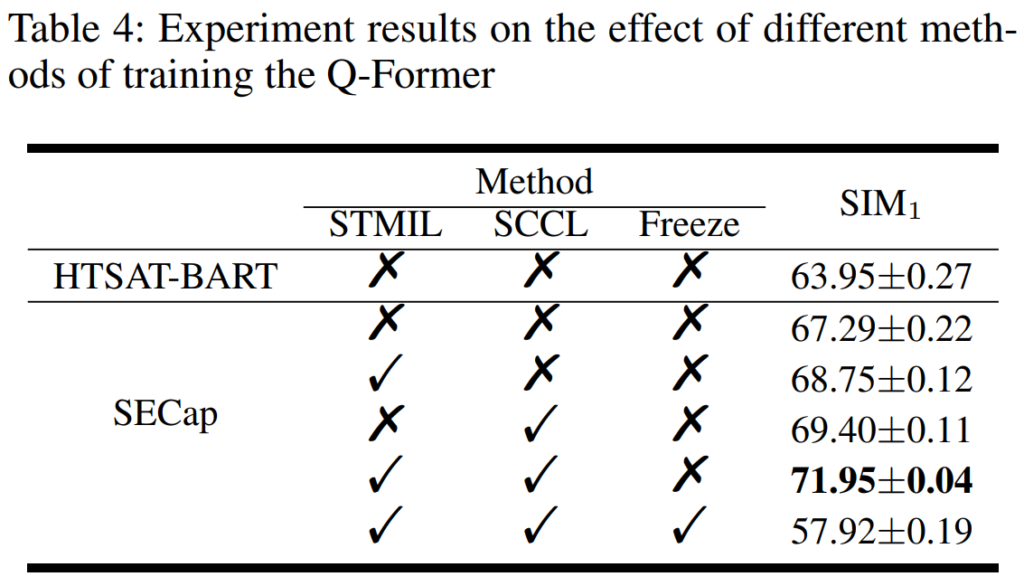
안녕하세요 혜원님 좋은 리뷰 감사합니다.
본문의 ‘Speech-Transcription Mutual Information Learning (STMIL)’ 부분에서 질문이 있습니다. 해당 내용에서 speech feature에서 content 정보를 제거하기 위해 mutual information을 활용하였다고 하였습니다. 여기서 ‘content 정보’가 구체적으로 어떤 유형의 정보가 포함되는지 예를 들어 설명해주실 수 있을까요? 또한, 어떤 특정한 단어들이 음성적 감정 표현과 상충할 수 있는지 궁금합니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
논문의 컨셉은 굉장히 최근의 트렌드를 따르는 것 같아 재밌게 읽었습니다. 그런데 읽고보니 음성의 늬앙스라는 것이 감정을 discrete하게 정의하는 것보다 더욱 주관적이게 되는 것이 아닌가 싶었습니다. LLAMA를 사용하였다고 적혀있었지만 다른 LLM을 사용하였을 때는 동일한 프로세스로 학습하더라도 다른 대답으로인해 성능이 매우 달라질 것 같은데 따로 이와 관련된 실험은 없었을까요?
감사합니다.