첫 번째 X-Review… 중간에 모르는 내용들이 많았어서 내용이 잘못 전달되거나 생략된 것 처럼 느껴지는 부분이 있으실 수 있을 것 같은데 감안하고 읽어주시면 감사하겠습니다..!!
Introduction

우리는 위와 같은 그림/사진을 보고 자연스럽게 가려져 있는 물체를 재구성 할 수 있습니다. 사람은 부분만 보이는 물체일지라도 전체의 형상을 떠올리고 그 형상이 어떤 물체인지 유추할 수 있을 뿐 만 아니라, 해당 이미지의 3D구조까지 직관적으로 유추할 수 있습니다.
뜬금없지만 이 논문의 제목은 왜 pix2gestalt일까요? gestalt(게슈탈트)는 독일어로 “전체”를 의미하는 심리학 용어입니다. 사람이 앞서 말한 것 처럼 자연스럽게 가려진 물체의 본질에 도달할 수 있는 이유는 사물의 형태를 인식할 때 단순히 부분만을 보는 것이 아니라, 각 부분들이 어떻게 연결됐는지 전체적으로 파악하기 때문입니다. 이 논문의 저자는 이 점에 집중해서 기존 모델이 특정 데이터셋에 국한되는 문제를 해결하기 위해 diffusion을 활용한 zero-shot learning의 접근 방식을 제안했습니다. 이를 통해 기존의 모델들이 어려워하던 환경, 너아가 자연에서 관찰할 수 없는 그림이나 캐릭터를 예측해야 하는 상황에서도 대응할 수 있는 모델을 설계했습니다.
이 모델을 설계하기 위해, 저자는 diffusion model의 사용을 강조합니다. Denoising diffusion model은 대규모 데이터로 학습되었기 때문에, 보이지 않는 부분의 형상을 직관적으로 유추할 수 있는 능력을 내재하고 있을 것으로 판단하고 활용합니다. 저자는 이 모델을 가려진 물체와 그에 대응하는 완전한 물체 쌍이 포함된 합성 데이터셋으로 추가 학습시켜, 단순히 가려진 부분만 메우는 것에서 나아가, 가려진 부분들이 전체적으로 어떻게 연결되어 있는지를 고려하여 전체 형상을 유추하고 재구성하는 능력을 부여했습니다. 예를 들어 자동차의 바퀴가 가려져 있는 경우, 단순히 바퀴만 그려넣는 것이 아니라, 바퀴를 포함한 자동차 전체의 형태를 하나로 일관성 있게 재구성할 수 있도록 설계되었습니다.
최종적으로 이 모델은 zero-shot setting에서도 amodal segmentation에서 기존의 supervised된 모델보다 더 좋은 결과를 냈고, 이 모델을 다른 객체 인식 및 3D재구성 모델의 모듈로 탑재해 성능을 크게 향상시킬 수 있다고 주장합니다. 추가적으로 diffusion model을 활용했기 때문에 재구성 된 결과에 여러 변형을 샘플링 해서 불확실성을 효과적으로 다룰 수 있다고 합니다.
Amodal Completion via Generation
이 모델의 목표는 부분적으로 가려진 물체가 포함된 RGB 이미지와 프롬프트를 입력받아, 가려진 물체의 전체 형상과 외형을 예측하여 새로운 이미지를 생성하는 것입니다. 입력으로 주어진 프롬프트는 관심 물체의 위치나 형태를 나타내는 마스크 혹은 점로 주어지고, 생성된 이미지는 물체 전체만 표현된 형태이며, 배경이나 다른 요소는 배제됩니다.
\hat{x}_p = f_{\theta}(x, p)
이미지를 x, 프롬프트를 p로 입력받아 diffusion model f를 통해 hat{x}_p인 복원된 물체를 얻고, 이렇게 얻은 결과는 전체 픽셀을 직접 합성한 데이터를 형성하기 때문에 기존의 segmentation, detection, 3D reconstruction 태스크를 보완하는 용도로도 사용될 수 있다고 합니다. 가려진 물체의 부분을 채워넣는것과 가려진 물체를 완전하게 재구성해서 복원하는 것이 얼마나 다른것인지 약간 감이 오지 않지만 여러번 언급하는 만큼 중요한 부분인 것 같습니다..
여기서 저자는 모델 f는 물체의 전체 형상을 표현할 수 있어야 하기 때문에 대규모 데이터로 사전 학습된 diffusion 모델을 활용하는 접근을 제안합니다. 특히 Stable Diffusion과 같은 확산 모델은 자연 이미지의 다양한 분포를 잘 포괄할 수 있어, 가려지지 않은 물체 전체의 형상을 생성하는 데 유용하다는 점을 강조하고 있습니다.
하지만 여기에는 한계점이 있습니다. 모델이 고품질의 이미지를 생성할 수 있지만, 물체를 배경과 분리하여 그룹화하거나 경계를 명시적으로 인코딩하지는 못한다는 단점이 있습니다. 즉, 모델이 생성한 이미지에는 물체와 배경의 경계에 대한 명확한 정보가 부족할 수 있다는 것입니다.
따라서, 이 연구에서는 확산 모델의 뛰어난 이미지 생성 능력을 활용하면서도, 물체의 그룹화 및 경계 인식을 개선하여 동작할 수 있도록 모델을 설계하고자 합니다.
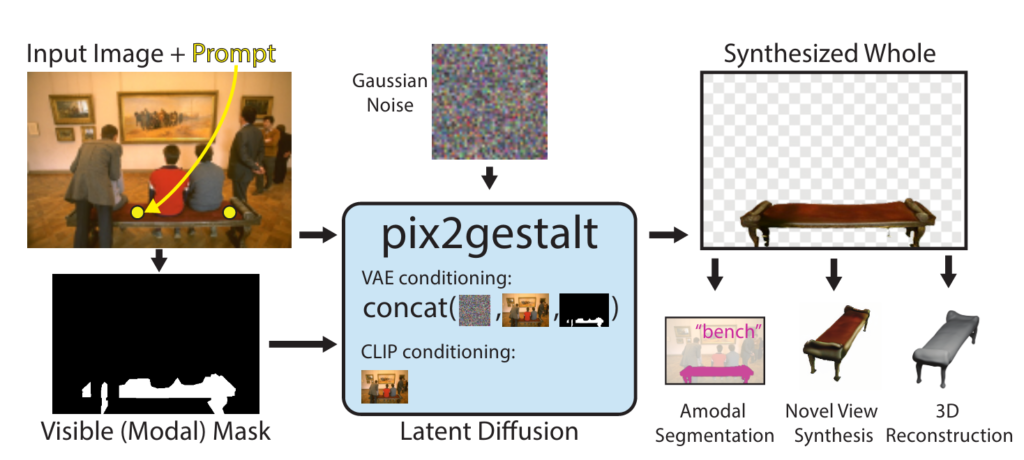
위 그림과 같이 복원해야 할 물체의 위치를 점으로 제공하면, 해당 위치의 물체를 나타내는 마스크가 생성되고, 이를 통해 복원 작업이 진행됩니다. Conditional diffusion model을 사용하여 두 가지 스트림으로 나누어 high-level semantic features와 low-level visual details를 결합합니다.
High-level features는 CLIP 임베딩을 통해 diffusion model의 high-level semantifc stream에 전달됩니다. CLIP모델을 통해 임베딩 되었기 때문에 물체의 형태와 분류등 의미적인 정보를 얻게 됩니다. Low-level features는 VAE에서 추출한 low level feature를 가우시안 노이즈와 결합하여 diffusion 과정에서 프롬프트 정보를 포함하여 가려진 부분을 재구성하는 데 활용됩니다. 이후 Denoising 과정에서 high-level과 low-level 정보가 점차 결합되어, 가려진 물체의 전체 형상이 자연스럽게 생성됩니다. 이를 통해, 최종적으로 가려진 물체의 완전한 형상을 얻을 수 있습니다.
Whole-Part Pairs
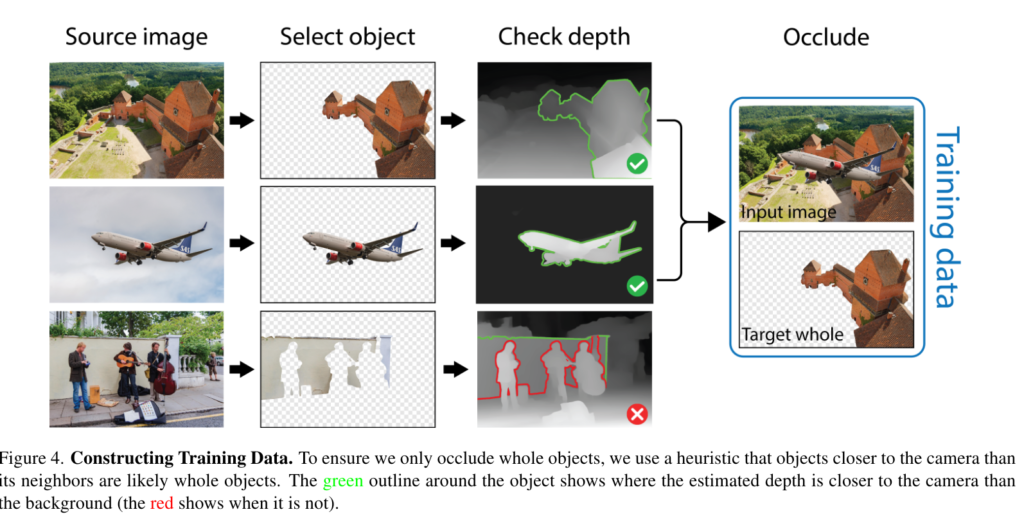
모델이 물체를 잘 그룹화 하고 경계를 잘 인식하게 하기 위해 전체-부분 쌍으로 이루어진 데이터셋을 통해 학습합니다. 기존의 amodal segmentation annotation이 제공된 데이터셋은 가려진 부분의 픽셀 정보를 포함하지 않기 때문에 제한적이고, 그래픽 시뮬레이션을 통해 생성된 데이터셋은 현실세계의 복잡성과 다양성을 충분히 반영하지 못하는 단점이 존재하기 때문에, 저자들은 이미 존재하는 이미지 위에 물체를 얹어서(중첩시켜서) 데이터셋을 구성했습니다. 이렇게 생성된 데이터는 가려지지 않은 물체의 Ground Truth(이미 존재하던 이미지)를 제공하기 때문에 가려진 물체와 온전한 물체의 짝을 이루는 데이터셋으로 구성됩니다. 이를 통해 부분적인 정보를 통해 하나의 일관된 전체를 인식할 수 있게 될 뿐 만 아니라, 명확하게 구분된 배경과 물체를 통해 학습하기 때문에 더 확실하게 경계를 인식할 수 있게 됩니다.
저자들은 휴리스틱 규칙을 통해 카메라에서 가까운 물체가 온전한 물체일 가능성이 높다는 가정을 적용합니다. 배경보다 가까이 있는 물체를 초록색 테두리로 표현해서 초록색 테두리를 가지고 있는 물체가 ‘가려질 수 있는 물체‘(온전한 물체)로 정해집니다. 온전한 물체를 식별하는 것은 불완전한 물체를 학습하지 않아야 하기 때문에 필요한 과정입니다.
Segment Anything과 MiDaS를 활용하여, SA-1B 데이터셋에서 물체 후보를 찾고, 온전한 물체를 선택합니다. 이 과정을 통해, 각 이미지에서 온전한 물체가 포함된 경우 해당 물체를 가리는 방법으로 837,000장의 이미지 쌍을 가진 데이터셋을 구축했습니다.
Amodal Base Representations
Conditional Diffusion을 통해 얻은 Amodal Base를 통해 여러가지 작업을 수행할 수 있습니다. Segmentation의 경우 결과에 threshold를 적용해 amodal segmentation map을 얻을 수 있습니다. 하지만 제약조건이 충분하지 않기 때문에 여러개의 복원 결과를 생성해서 다수결로 마스크를 정하는 방식이 제일 성능이 좋았다고 합니다. 만약 가려진 물체를 복원한 후 CLIP을 사용해서 classify한다면 zero-shot recognition을 수행할 수 있습니다. 마지막으로 복원된 물체에 SyncDreamer와 Score Distillation Sampling을 통해 mesh를 예측해서 3D로 만들 수 도 있다고 합니다.
Experiments
저자는 amodal completion을 각 task 별로(amodal segmentation, occluded object recognition, amodal 3D reconstruction) 나누어 평가했습니다. 평가에는 Amodal COCO (COCO-A), Amodal Berkeley Segmentation (BSDS-A), Occluded COCO Benchmark가 사용됐습니다.
Amodal Segmentation
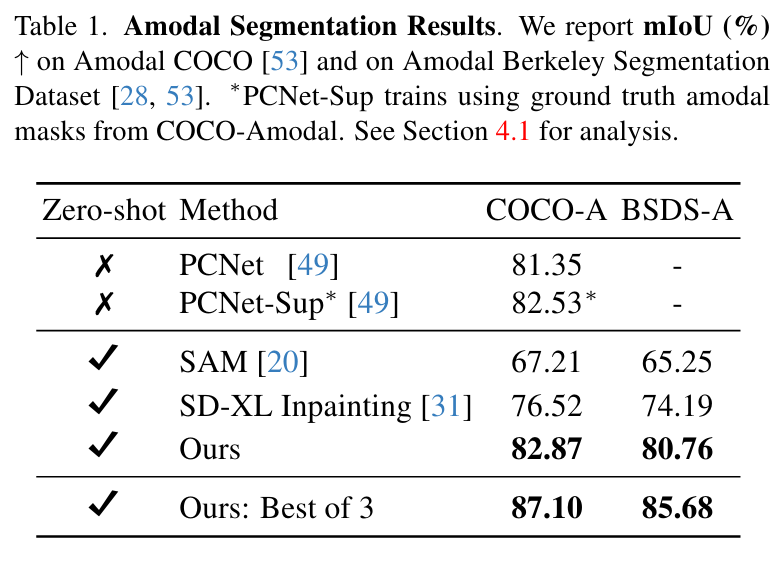
먼저 Amodal segment의 경우 COCO-A, BSDS-A로 PCNet, SAM, Stable Diffusion XL 모델과 비교했는데, 위의 Table1에서 볼 수 있듯 제로샷 환경에서 기존의 모델들의 mIOU를 모두 능가하는 성능을 보였으며, 아래 Figure6과 같이 결과물 자체에 비현실 적인 부분이 훨씬 적을 뿐 만 아니라, 전체 적인 모양을 훨씬 더 잘 예측하는 모습을 보였고, 이를 통해 기존의 Stable Diffusion 모델보다 더 적은 데이터로 학습했을지언정 Fine Tuning하는것이 중요하다는 점을 알 수 있다고 합니다. 이렇게 놓고 보니 엄청 차이가 많이 나긴 하는 것 같습니다. Best of 3는 무슨 의미가 있는지 잘 모르겠습니다..

Occluded Object Recognition
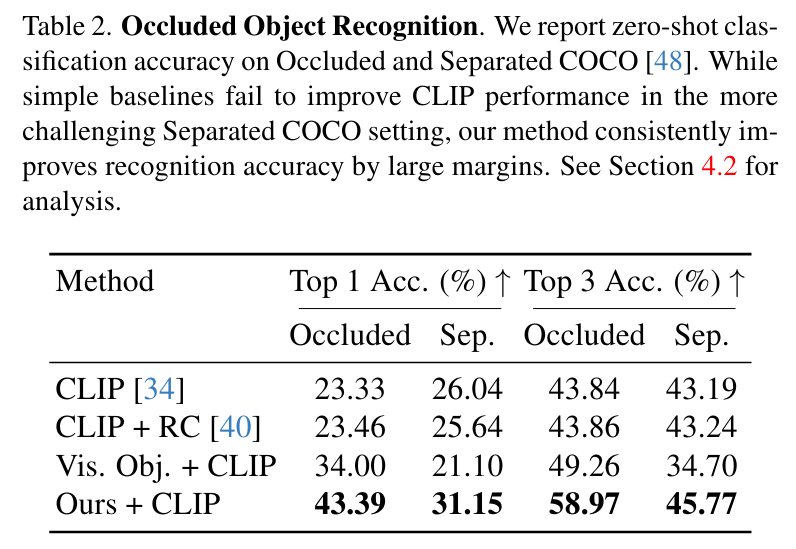
Occluded Object Recognition의 경우에는 복원된 결과를 CLIP을 open vocabulary classifier로 사용해 클래스를 구해 평가했고, Occluded COCO와 Seperated COCO 데이터셋을 사용했다고 합니다. 가려진 물체 주변을 빨간 원으로 시각적 프롬프팅 하는 방법(RC)과 가려진 물체 외의 모든 부분을 마스킹 한 경우 (Vis. Obj.), 이미지 자체를 CLIP에 전달하는 경우와 비교했을 때 훨씬 우수한 성능을 Table2와 같이 보인다고 합니다. 하지만 별다른 비교 모델이 없는 것 같은 점이 아쉬웠고, Top-3안에 정답이 있는 경우는 Top-1에 있을 때 보다 격차가 많이 줄어드는 모습을 볼 수 있었습니다.
Amodal 3D Reconstruction
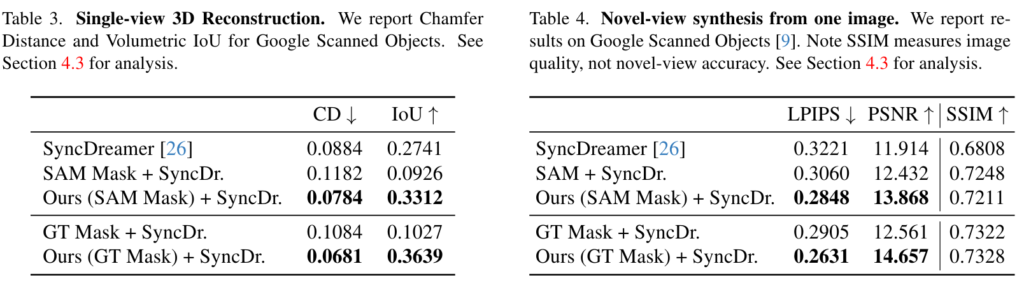
Amodal 3D Reconstruction 같은 경우는 Novel-view synthesis와 single-view 3D reconstruction으로 나누었습니다. single view인 경우 3D생성 모델인 SyncDreamer에 모든 전경 물체의 segmentation을 입력으로 제공했을 때, SAM 마스크를 활용했을 때, 저자의 모델을 입력으로 사용했을 때를 비교했을 때 Table3와 같이 Chamfer Distance(실제 pointcloud와의 거리 차)는 더 낮고 IoU는 더 높았다고 합니다. Novel-view인 경우에도 같은 비교군을 통해 PSNR, SSIM, LPIPS를 비교했습니다. PSNR (Peak Signal-to-Noise Ratio)는 생성된 이미지와 실제 이미지 간의 유사성을 측정하는 지표로, 값이 높을수록 정확한 복원을 의미합니다. SSIM (Structural Similarity Index)는 이미지의 구조적 유사성을 평가하며, 값이 높을수록 시각적 일관성이 뛰어남을 나타냅니다. LPIPS (Learned Perceptual Image Patch Similarity)는 인간의 시각적 유사성을 더 잘 반영하는 지표로, 낮을수록 두 이미지 간의 유사성이 높음을 의미합니다. Table4와 같이 생성된 이미지와 실제 이미지가 구조적으로 더 유사하고 인간의 시각적 유사성을 더 잘 반영했습니다. 아래의 Figure 10인 정성적인 결과물은 정말 훌륭한 것 같습니다..

Conclusion
해당 모델은 일단 Zero-Shot 환경에서 성능이 잘 나오는 것 만으로 의미가 있어보입니다. 하지만 뭔가 진짜 엄청나게 좋은 모델인지 아직 제 안에서 평가할 기준도 없고 비교군인 다른 모델이 많이 없어서인지 Conditional Diffusion을 하는 만큼 많은 연산량에 비해 엄청 좋은 모델인지 의문이 들긴 합니다. 실시간 처리에는 무리가 있어보입니다..
영규님 좋은 리뷰 감사합니다.
‘가려진 물체의 부분을 채워넣는것과 가려진 물체를 완전하게 재구성해서 복원하는 것’이 다르다고 해당 논문에서 강조한다고 하셨는데, 해당 논문에서는 어떠한 설계가 가져맂 부분을 채워넣는 게 아니라 재구성한다고 할 수 있는지 설명해주실 수 있을까요?
Best of 3는 무슨 의미가 있는지 잘 모르겠다고 하셨는데, 논문에서 의미하는 Best 3는 amodal completion의 불확실성으로 인해 다양한 결과나 나올 수 있으므로(논문의 figure 8을 통해 예시 듦) diffusion 과정에서 3반복하여 가장 좋은 결과를 이용하였다고 합니다. 리뷰를 작성하실 때 대부분 관련 설명이 적혀있을테니 조금 더 잘 찾아보시면 좋을 것 같습니다.
Amodal 3D reconstruction 파트에서 Novel-view synthesis와 single-view 3D reconstruction에 대한 평가를 수행하였는데, 두 테스크에 대한 간략한 설명도 부탁드립니다.
안녕하세요 승현님 읽어주셔서 감사합니다
이 논문에서 물체 전체를 재구성하는 컨셉은 그저 가려진 부분만 채워넣는게 아닌 가려진 부분을 얼마나 자연스럽게 만들어내는가?에 있고, 이를 ‘전체를 재구성한다’로 표현했다고 이해했습니다. 단순히 diffusion이 가려진 물체를 재구성할 수 있게 만들어준 건 아닙니다.
저자는 학습시 whole-part pair로 이루어진 데이터셋과 conditional diffusion model에 CLIP, VAE를 조건으로 주어서 가려진 물체의 전체적인 물체의 구조를 이해시키고 디테일한 부분을 자연스럽게 이어지게 만들었습니다. 이로 인해 diffusion 할 때 일관되게 가려진 물체의 전체형상을 추론하게 유도했습니다.
또 best of 3같은 경우는 결과를 비교할 때 ours만 표기해 두어서 비교의 의미가 없는것 아닌가? 라는 의견을 적고 싶었는데 제대로 전달을 하지 못 한것 같습니다. 다시 읽어보니 그 부분에 대한 내용이 빠져있네요.. 3반복을 해서 가장 좋은 결과를 사용해도 모델 자체에 물리적인 현상을 이해하는 것이 부족해 논문의 figure 9 과 같이 박스를 들고있는 팔이 가려져 있을 때 박스를 들고있는 자세가 아닌 차렷자세를 복원한다고 합니다.
마지막으로 Novel-view synthesis는 한 이미지로 주어진 물체가 다른 각도에서는 어떻게 보일지 예측하는 것이고, single-view 3D reconstruction같은 경우는 한 이미지로 주어진 물체의 완전한 3D 형상을 복원하는 것입니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
1. 제가 Diffusion model의 자세한 원리를 잘 몰라서 그러는데,, Denoising 과정에서 high-level과 low-level 정보의 점차 결합은 어떻게 이루어지는 지 간략하게만 설명해주실 수 있으신가요?
2. SyncDreamer와 Score Distillation Sampling 은 무엇인가요?
안녕하세요 재찬님 읽어주셔서 감사합니다
1. Denoising 과정을 거치기 전 high-level정보와 low-level정보, gaussian noise를 concat합니다. 이후에 반복적인 샘플링을 통해 가우시안 노이즈를 점차 제거해나가면서 초반에는 high-level정보들을 복원하고 노이즈가 줄어들면 줄어들수록 low-level정보들을 복원합니다. 이 과정에서 gaussian noise를 통해 확률적 성질을 추가해서 불확실성이 있는 부분에 대해 더 나은 결과를 생성합니다.
2. SyncDreamer는 3D reconstruction 모델로, NeRF와 결합하여 3D Reconstruction을 해줍니다. 3D reconstruction을 진행할 때 NeRF의 새로운 시점에서의 렌더링 능력을 사용해 일관성 있는 생성을 한다고 합니다.
Score Distillation Sampling같은 경우는 Diffusion 모델에서 생성된 샘플을 특정 목표점수를 설정해둔 뒤 해당 목표에 도달할 때 까지 계속 샘플을 업데이트 해서 최종적으로 목표에 가장 가까운 이미지를 결과로 출력하는 것 입니다. 목표가 있는 diffusion이라고 생각하면 될 것 같습니다.