안녕하세요. 이번에 리뷰할 논문은 기존의 텍스트-비디오 검색 방식에서 한 단계 발전하여, 비디오에 포함된 관련 텍스트 정보(예: 제목, 태그, 자막)를 활용하여 텍스트 쿼리를 더 효과적으로 매칭하는 새로운 접근 방식을 제안한 논문입니다. 이 모델은 웹 규모로 사전 학습된 모델(CLP와 GPT-2)을 사용한 제로샷 비디오 캡셔닝을 통해 비디오에서 연관된 캡션을 생성하고, 이를 텍스트-비디오 검색에 활용하는 Cap4Video 프레임워크를 도입합니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
텍스트-비디오 검색은 비디오-언어 학습의 기본 과제입니다. 이미지-언어 사전 학습이 빠르게 발전하면서 연구자들은 특히 CLIP 모델을 활용하여 텍스트-비디오 검색 문제에 도전하기 위한 이미지-언어 모델의 확장을 연구하고 있습니다. 연구는 global matching(비디오-문장 정렬)에서 프레임-단어 정렬, 비디오-단어 정렬, multi-hierarchical 정렬과 같은 Fine-grained Matching으로 발전해왔습니다. 이러한 연구들은 놀라운 성과를 보여줬으며, 기존 모델을 크게 능가하였습니다. 두 가지 주요 요인이 이 개선에 기여했습니다. 첫째, CLIP은 강력한 visual 및 텍스트 표현을 제공하여, 비디오-텍스트 일치에서 cross-modal 학습의 어려움을 줄였습니다. 둘째, 이러한 방법들은 희소하게 샘플링된 프레임을 사용하여 비전 및 텍스트 인코더를 end-to-end 방식으로 미세 조정할 수 있습니다. 모든 이러한 방법들은 비디오의 visual 표현과 해당 query의 텍스트 표현 간의 cross-modal 정렬을 학습하는 것을 목표로 합니다. 이는 그림 1에 설명되어 있습니다.
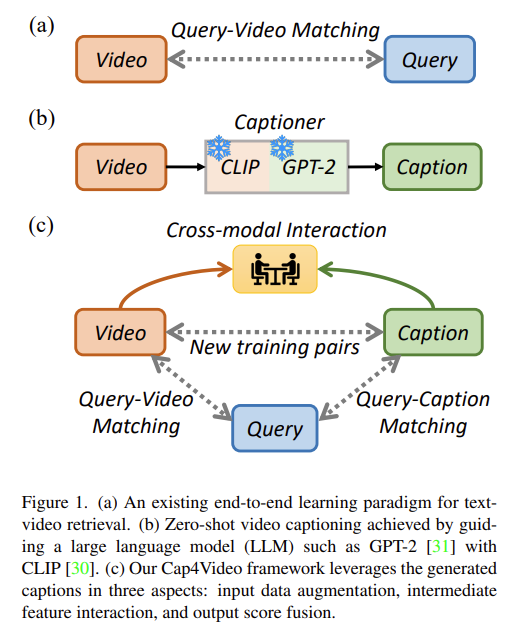
그러나 현실에서는 온라인 비디오에 웹사이트에 표시된 비디오의 제목이나 태그와 같은 관련 콘텐츠가 자주 제공됩니다. 이 visual 신호 외에도 관련 텍스트 정보는 어느 정도 비디오 콘텐츠를 설명하고 query와 매칭시킬 수 있습니다. 여기서 중요한 점은 비디오에 대한 연관된 텍스트 설명을 어떻게 생성할 수 있는가?입니다. 하나의 해결책은 웹사이트에서 비디오 제목을 크롤링하는 것입니다. 그러나 이 방법은 주석에 의존하며 비디오 URL이 무효화될 위험이 있습니다. 또 다른 자동화된 해결책은 제로샷 비디오 캡션 모델을 사용하여 캡션을 생성하는 것입니다. 따라서 저자는 이러한 개방형 문제를 처리하기 위해 지식이 풍부한 사전 학습 모델에 주목합니다.
최근 연구 ZeroCap은 제로샷 이미지 캡션을 위해 CLIP 및 GPT-2를 사용하는 모델입니다. 이에 저자는 추가 학습 없이 비디오 도메인에서 캡션을 생성하기 위해 ZeroCap의 비디오 확장을 활용합니다. 보조 캡션을 제공받은 상태에서, 이러한 캡션을 텍스트-비디오 검색 작업을 향상시키기 위해 본 논문에서는 Cap4Video 학습 프레임워크를 제안하며, 이는 캡션을 세 가지 핵심 방식으로 활용합니다:
- Input Data: 생성된 캡션을 사용하여 학습 데이터를 증강하는 간단한 접근 방식입니다. 주어진 비디오와 그에 대한 생성된 캡션을 매칭된 쌍으로 취급하여 query-비디오 쌍 외에도 학습을 위한 추가 양성 샘플 쌍으로 사용할 수 있습니다.
- Intermediate Feature Interaction: 비디오와 캡션 간의 cross-modal 상호작용을 통해 비디오 표현을 개선할 수 있습니다. 비디오와 캡션 간의 보완 정보를 활용하여 비디오의 중복 피처를 줄이고, 더 구별력 있는 비디오 표현을 학습할 수 있습니다.
- Output score: 생성된 캡션은 비디오의 내용을 나타낼 수 있으며, 이를 사용하여 query-캡션 매칭을 활용하여 기존 query-비디오 매칭을 보완할 수 있습니다. 또한, 이중 스트림 아키텍처를 사용하여 모델 편향을 줄이고 보다 견고한 결과를 도출할 수 있습니다
저자의 contributions을 정리하면 다음과 같습니다.
- 저자는 기존 텍스트-비디오 검색을 향상시키기 위해 보조 캡션을 활용하는 새로운 문제를 탐구했습니다. 비디오 웹사이트 제목을 수작업으로 크롤링하는 방법 외에도, 저자는 대형 언어 모델(LLM)이 자동으로 생성한 풍부한 캡션이 텍스트-비디오 검색에 도움이 될 가능성을 조사했습니다.
- 저자는 Cap4Video 학습 프레임워크를 제안하여 입력 데이터, 피처 상호작용, Output score를 통해 보조 캡션의 유용성을 향상시킵니다. 저자의 프레임워크는 기존의 query-비디오 매칭 메커니즘(Global Matching 및 Fine-grained Matching 포함)의 성능을 향상시킵니다.
- 네 가지 비디오 벤치마크에서 수행된 광범위한 실험은 제안된 방법의 효과를 입증합니다. 저자의 Cap4Video는 MSR-VTT (51.4%), VATEX (66.6%), MSVD (51.8%), 및 DiDeMo (52.0%)에서 sota 달성합니다
2. Methodology
2.1 Background: Text-Video Matching
텍스트-비디오 매칭은 주어진 문장 (Q_i)와 주어진 비디오 (V_j) 간의 유사성을 평가하는 것으로, 일반적으로 유사도 함수 (s(Q_i, V_j))를 사용합니다. 텍스트-비디오 검색에서는 특정 query 문장과의 유사도 점수를 기준으로 모든 비디오를 순위 매기는 것이 목표입니다. 텍스트-비디오 검색 성능을 향상시키기 위해 최근 연구에서는 CLIP 모델을 초기화 모델로 사용합니다. 텍스트-비디오 매칭의 기본 모델로는 Global Matching과 Fine-grained Matching 두 가지 기법이 있고 이는 그림 2(b)에 나와있습니.
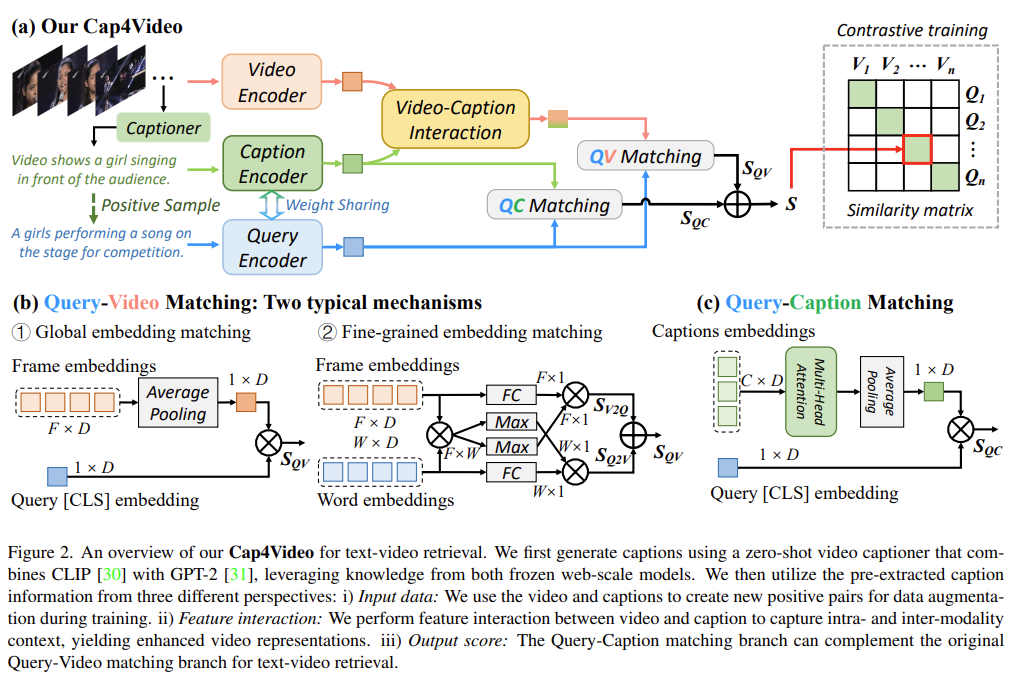
Global Matching은 cross-modal contrastive learning에서 흔히 사용되는 기술로, 각 모달을 독립적으로 인코딩하여 global 피처를 얻은 후 유사도를 계산합니다. 여기서 비주얼 인코더는 주어진 비디오에서 (F)개의 프레임을 샘플링하여 프레임 임베딩을 생성하고, query 인코더는 주어진 문장에서 (W)개의 단어 임베딩과 global 표현으로 [CLS] 임베딩을 반환합니다. 프레임 임베딩은 평균 풀링을 통해 global 비디오 임베딩으로 통합되고, 이후 global query 임베딩과 비교하여 유사도를 계산합니다.
Fine-grained Matching은 프레임-단어 정렬과 같은 모달 간 토큰 정렬을 모델링하는 데 중점을 둡니다. 이미지-텍스트 학습을 위한 토큰 정렬을 위해, FILIP 및 ColBERT는 Max-Mean 파이프라인을 사용합니다. 이 파이프라인은 패치와 단어 토큰 간의 토큰별 최대 유사도를 찾고, 이미지 또는 텍스트 내의 토큰 최대 유사도를 평균화하여 유사도를 얻습니다. DRL은 이러한 토큰별 정렬을 텍스트-비디오 검색으로 확장하며, 가중 풀링을 학습하기 위한 attention메커니즘을 도입합니다. 이 메커니즘을 기본 모델로 채택하였습니다.
2.2 Preprocessing: Caption Generation
주어진 비디오에 대한 보조 캡션을 얻기 위해 다음 두 가지 접근 방식을 사용합니다.
- Manual Crawling of Video Titles : 비디오 원본 링크(예: YouTube ID)를 크롤링하여 웹사이트 제목을 캡션으로 사용합니다. 단, 만료된 링크의 비디오는 생략합니다.
- Automatic Video Captioning : 주석에 의존하는 수동 방식과 달리, 저자는 대형 언어 모델(LLM)의 지식을 활용하여 다양한 캡션을 생성합니다. 프레임워크의 확장성을 고려하여, 추가 학습 없이 제로샷 비디오 캡션 생성을 통해 다운스트림 비디오에서 직접 캡션을 생성하고자 합니다. 이를 위해 GPT-2를 사용하여 “Video shows”와 같은 초기 프롬프트로부터 다음 단어를 예측합니다. 이후, 비디오 관련 지식을 포함하는 문장을 생성하도록 calibrated CLIP 손실을 적용합니다.
2.3 Data Augmentation with Auxiliary Captions
보조 캡션은 학습 데이터를 증강하는 데 사용될 수 있습니다. 예를 들어, (N)개의 비디오와 해당 query 문장으로 구성된 데이터셋에서, 각 비디오와 생성된 캡션을 매칭된 샘플 쌍으로 간주하여 원래의 query-비디오 쌍 외에도 추가적인 양성 샘플 쌍으로 학습에 사용합니다. 비디오마다 하나의 캡션을 선택함으로써 학습 중 추가적으로 최소 (N)개의 쌍을 데이터 증강에 추가할 수 있습니다.
자동 비디오 캡션 생성기는 각 비디오에 대해 여러 개의 캡션(예: 20개)을 생성할 수 있습니다. 그러나 일부 캡션은 잡음이 포함되거나 비디오 내용과 완전히 일치하지 않을 수 있으므로, 학습에 부정적인 영향을 미치지 않도록 사전 학습된 텍스트 인코더를 사용해 각 캡션과 비디오의 정답 query 간의 의미적 유사성을 평가하는 필터링 메커니즘을 적용합니다. 이는 유사도가 가장 높은 캡션을 선택하여 데이터 증강에 사용합니다. 이 필터링 작업은 학습 단계에서만 수행됩니다.
2.4 Video-Caption Cross-Modal Interaction
비디오와 캡션 간의 상호 보완성을 활용하여 중복 피처를 줄이고, 더 구별력 있는 비디오 표현을 학습하기 위해 cross-modal 상호작용을 고려합니다. 효율적인 전이 학습을 위해 사전 학습된 CLIP 인코더 아키텍처를 유지하고, 최종 캡션 및 프레임 임베딩으로 상호작용을 제한합니다. 구체적으로, 프레임 임베딩 (ev = {v1, v2, …. , vF})와 캡션 임베딩 (ec = {c1, c2, … , cC})을 interaction module에 전달하며, 여기서 (F)와 (C)는 각각 프레임과 캡션의 수를 나타냅니다. 몇 가지 상호작용 방식은 다음과 같습니다.
- Sum

- 글로벌 캡션 임베딩 cg과 각 프레임 임베딩 vi의 합을 계산하여 프레임 임베딩을 강화합니다.
- 이때, vi는 i-번째 프레임 임베딩을 의미하고, cg는 여러 캡션의 [CLS] 임베딩을 평균하여 계산한 글로벌 캡션 임베딩입니다.
- MLP

- 각 프레임 임베딩 vi와 글로벌 캡션 임베딩 cg을 concatenation한 후, 이 연결된 임베딩을 MLP에 입력하여 가중합을 학습합니다.
- MLP는 학습 가능한 가중치 θ를 사용하여, 프레임과 캡션 임베딩의 중요한 특징을 가중합으로 나타낼 수 있게 합니다. 이를 통해 임베딩 간의 복잡한 상호작용을 모델링할 수 있습니다.
- Cross Transformer

- 프레임 임베딩과 캡션 임베딩의 상호작용을 위해 self-attention 메커니즘을 사용하는 크로스 트랜스포머를 도입합니다.
- 이 방식에서는 프레임 임베딩 ev와 캡션 임베딩 ec이 하나의 시퀀스로 결합되어 트랜스포머 인코더를 통해 처리됩니다. 트랜스포머 블록 L 개를 사용하여 최종 임베딩 표현을 얻어내며, 프레임과 캡션 간의 복잡한 상호작용을 모델링합니다.
- Co-attention Transformer

- Co-attention 을 사용하여 비디오와 캡션 간의 정보를 교환하는 방법입니다.
- Co-attention Transformer 레이어 fϕ1를 통해 상호간의 중요한 정보에 집중하고, 이 후 시간적 정보를 모델링하기 위해 L 개의 추가 트랜스포머 레이어 fϕ2를 사용합니다. 이를 통해 프레임과 캡션 임베딩 간의 상호작용을 모델링하고 시간적 정보를 더욱 잘 포착할 수 있습니다
2.5 Complementary Query-Caption Matching
캡션은 데이터 증강과 비디오 피처 향상뿐 아니라 비디오 내용을 직접 나타내어 텍스트-텍스트 검색에 사용할 수 있습니다. 구체적으로, 비디오에서 생성된 각 (C)개의 캡션은 캡션 인코더를 통해 [CLS] 텍스트 임베딩을 얻으며, 이 캡션 임베딩을 집계하여 global 표현을 형성합니다. 이 global 캡션 임베딩과 global query 임베딩 간의 코사인 유사도를 계산하여 query-비디오 매칭을 보완할 수 있습니다.
Learning Objectives
query-캡션 매칭 학습 단계에서 관련된 경우 캡션 임베딩 ec와 query 임베딩 et가 가깝게, 그렇지 않은 경우 멀게 만들고자 합니다. 저자는 symmetric cross-entropy 손실을 사용하여 일치하는 query-캡션 쌍의 유사성을 최대화하고, 다른 쌍의 유사성은 최소화합니다. 이와 유사하게, query-video contrastive 손실을 정의하여 총 손실 (L)을 계산합니다. [ L = L_{QV} + L_{QC} ]
쿼리-캡션 학습: 학습 중, 관련이 있는 캡션 임베딩 ec와 쿼리 임베딩 et는 가깝게, 관련이 없는 경우는 멀어지도록 목표로 설정합니다.
- 쿼리-캡션 쌍의 유사도를 최대화하고 다른 쌍의 유사도를 최소화하기 위해 symmetric cross-entropy 손실을 사용합니다

여기서 sqc(⋅,⋅)는 쿼리-캡션 매칭 유사도 함수이며, τ는 스케일링을 위한 하이퍼 파라미터입니다.
쿼리-비디오 학습: 유사한 방식으로 쿼리-비디오 쌍을 위한 대조 손실이 다음과 같이 정의됩니다:

따라서 전체 로스는 쿼리-비디오 loss와 쿼리-캡션 loss로 구성되며 다음과 같이 표현됩니다.

3. Experiments: Text-Video Retrieval
3.1 Setups
데이터셋
- MSR-VTT: 10,000개의 비디오 클립과 각 클립당 20개의 캡션이 포함된 데이터셋입니다. Training-9K 세트로 모델을 학습하고, 테스트 1K-A 세트에서 평가합니다.
- DiDeMo: 10,000개의 비디오와 40,000개의 설명이 있습니다.
- VATEX: 약 35,000개의 비디오로 구성되며, 학습용 26,000개, 검증용 1,500개, 테스트용 1,500개로 나뉩니다.
- MSVD: 1,970개의 비디오와 80,000개의 캡션이 포함되며, 학습용 1,200개, 검증용 100개, 테스트용 670개로 구성됩니다.
평가 지표
- R@K (K = 1, 5, 10): 주어진 텍스트 쿼리에 대해 상위 K개로 검색된 비디오 중 정답 비디오가 포함된 비율을 평가합니다.
- MdR (중위 순위): 검색된 정답 비디오의 중간 순위입니다.
- MnR (평균 순위): 검색된 정답 비디오의 평균 순위입니다. MdR과 MnR 값이 낮을수록 성능이 좋습니다.
3.2 Comparison with State-of-the-Arts
이 절에서는 네 가지 벤치마크(MSR-VTT, MSVD, VATEX, DiDeMo)에서 Cap4Video 와 최근 sota 모델과 비교합니다. DiDeMo 에 대한 성능을 Table 1 에서 보면, Cap4Video 는 CLIP4Clip 대비 R@1 에서 9.2%의 큰 향상을 보이며, DRL 대비 3.0%를 초과하여 저자 방법의 효과를 입증합니다.

Table 2 는 MSR-VTT 에서 성능을 보여주며, ViT-B/32 와 ViT-B/16 백본 모두에서 텍스트-비디오 검색에 있어 sota 성능을 달성하였습니다.

Table 3 과 Table 4 는 각각 MSVD 와 VATEX 데이터셋에 대한 결과를 보여줍니다.


네 가지 벤치마크에서 일관된 sota 성능은 Cap4Video 의 효율성을 입증합니다.
3.3 Ablation Study

이 절에서는 디자인의 각 부분이 미치는 영향을 분석하는 Ablation Study를 진행합니다.
Auxiliary Caption as Data Augmentation : 실험에서는 GPT-2 모델이 생성한 캡션과 웹사이트에서 추출한 비디오 제목을 비교하여 캡션이 학습에 미치는 영향을 조사했습니다. Table 5 의 결과에서, 웹 규모 모델이 생성한 캡션을 데이터 증강에 사용한 경우, R@1 에서 각각 1.4%, 0.6%의 개선이 있었으며, 비디오 제목을 사용해도 Global Matching 에서 1%의 개선이 확인되었습니다. 생성된 캡션 수의 영향을 살펴본 결과, 하나의 캡션만 사용해도 충분한 성능 향상이 있었습니다.
Benefit on Both Online and Offline Videos Scenarios : Cap4Video 는 온라인 및 오프라인 비디오에 모두 적용 가능합니다. 온라인 비디오에서는 캡션 생성 단계를 생략하고 웹사이트 제목을 캡션으로 사용합니다. Table 6 의 결과는 Cap4Video 가 두 시나리오 모두에서 Global Matching 기본 모델 대비 크게 개선되었음을 보여줍니다.

3.4 Visualization
Figure 4 에서는 Cap4Video 와 보조 캡션이 없는 모델이 검색한 예시 비디오 두 개를 제공합니다. Cap4Video 는 캡션의 도움으로 정답 비디오를 성공적으로 검색한 반면, 비디오 전용 모델은 query 와 다소 관련이 있지만 정확하지 않은 여러 비디오를 반환합니다.

4. Conclution
저자는 웹 규모의 언어 모델이 생성한 캡션을 활용하여 텍스트-비디오 매칭을 향상시키는 Cap4Video라는 새로운 프레임워크를 소개합니다. Cap4Video는 세 가지 주요 방식으로 텍스트-비디오 매칭을 개선합니다: 1) 학습을 위한 입력 데이터 증강, 2) 압축된 비디오 표현을 위한 중간 비디오- 캡션 피처 상호작용, 3) 텍스트-비디오 검색을 개선하기 위한 Output score 융합입니다. 본 접근 방식은 네 가지 표준 텍스트-비디오 검색 벤치마크에서 일관된 성능 향상을 보여주었으며, 기존의 sota 모델을 초과하는 성능을 달성했습니다.
안녕하세요. 좋은 리뷰 감사합니다.
프레임 임베딩과 캡션 임베딩 간의 similarity matrix관련하여 궁금한 부분이 있습니다. 프레임 임베딩은 비디오를 구성하는 frame을 임베딩한 것으로 이해하였는데, 이를 캡션간 similarity를 구하면 전체 frame과의 유사도는 고려하지 않는 것인지 궁금합니다. Figure를 보면 본 논문에서 말하는 caption은 video의 전반적인 내용을 담고 있는 text인 것 같은데 (딱히 한 frame을 나타내는 text는 아닌듯 한데) 이렇게 frame과 caption간의 similarity를 구하게 되면 전체 frame(즉, video)에 대해서는 어떻게 고려하게 되나요?
감사합니다.
안녕하세요 주연님. similarity matrix 부분에서 질문을 주셨습니다. 논문의 아키텍쳐에서 frame과 caption간의 similarity를 구하는 부분은 없습니다. Figure에 나와있는 부분은 비디오와 쿼리의 similarity를 계산하는 과정입니다. 여기서 caption의 역할은 비디오-쿼리 사이의 관계를 더 잘 학습하기위해 각 모달리티의 정보를 보완해 주는 역할이라고 이해하시면 될 것 같습니다.
감사합니다.
안녕하세요 리뷰 잘 읽었습니다.
1.
제가 GPT-2를 잘 모르는데, 이 모델을 통해 비디오의 캡션을 어떻게 생성하는 것인가요? 언어를 입력받고 출력하는 모델이 아니었나요?
2.
논문을 읽다보니 GPT-2, global matching, fine-grained matching, cross-modal interaction, 실제 학습하는 loss 중 저자가 제안한 부분은 없는 것 같은데 맞나요? 리뷰만 읽어보면 기존 방법론들에서 다 조금씩 떼와 만든 방법론인 것 같은데, 찾아보니까 CVPR Highlight로 accept된 논문이더라고요. 23년 논문이라곤 하지만 그 당시에도 이러한 논문들은 굉장히 많았는데, 어떤 부분이 이 논문을 highlight로 만들어주었다고 생각하시는지 궁금합니다.
추가로.. 리뷰 작성하실 때 번역기 글을 그대로 옮기시나요? 이해를 위해 번역기를 사용하는 것은 좋지만 리뷰에까지 그 문장들을 그대로 옮기시는 것은 전혀 의미가 없다고 생각합니다. 쓰는 사람이나 읽는 사람 모두에게 큰 도움이 되지 않아서, 다음부터는 시간을 들여 글을 직접 작성하시면 좋을 것 같습니다. 리뷰를 작성하면서 의철님이 생각했을 때 각 부분에 대한 강약조절도 들어가고 개인적인 의견도 붙여주셨으면 좋을 것 같은데 아쉽습니다.