
안녕하세요, 허재연입니다. 오늘 리뷰 할 논문은 Facebook AI Research에서 2021년 ICCV에 게재한 논문으로 DINO라는 Self-Supervised Learning 방법을 제안한 논문입니다. DINOv2라는 방법론을 공부해 볼 예정이기에 먼저 본 논문을 읽어보았으며, 지금까지 주로 리뷰했던 논문들이 ResNet 등 CNN 기반 SSL 방법론들이었다면 이번 논문은 ViT를 위한 SSL를 제안했다는 점에서 차이점이 있다고 할 수 있습니다. 한번 살펴보겠습니다.
Introduction
Transformer는 자연어처리 분야에 성공적으로 정착되어 혁신을 일으켰으며, 논문 발표 당시 컴퓨터비전 학계에서도 visual recognition에 있어 기존에 사용되던 convolutional neural networks(convnets)의 대안으로 떠오르고 있었습니다. 결과적으로 ViT가 convnets에 견주는 결과를 보여주었지만, 당시까지 CNN 기반 모델보다 명확한 개선 결과를 보여주지는 않았습니다. ViT는 CNN보다 더 많은 데이터와 계산 리소스를 필요로 했으며 추출한 특징에서도 딱히 별다른 차별 점이 없었습니다.
하지만 NLP에서 트랜스포머의 성공은 단순한 supervision에 있지 않았습니다. BERT나 GPT의 성공에는 대량의 데이터를 가지고 Self-Supervised Learning을 통해 풍부한 representation을 확보한 점에 있었죠. 문장마다 하나의 라벨을 부여해 이를 objective 삼아 지도학습 방법으로 예측하는 것보다 문장 속 단어를 objective로 삼아서 사전학습 하는 것이 훨씬 더 풍부한 학습 신호로 작용할 수 있었습니다. 마찬가지로, 이미지 데이터에 대해서도 이미지 단위 지도학습을 수행하는 것은 이미지 데이터에 포함된 풍부한 시각적 정보를 기존에 정의된 category set 중 하나로 줄여버리는 문제점이 있습니다.
NLP에서 사용된 pretext task들이 text-specific하긴 하지만 컴퓨터비전에서도 많은 기존의 Self-Supervised 방법들이 convnet에서 충분한 포텐셜을 보여주었습니다. 여기서 저자들이 말하는 기존 SSL 방법론들은 SimCLR나 MoCo, BYOL과 같은 instance discrimination 기반 방법론 들인데, 이 방법론들은 trivial solution(collapse문제)를 방지하거나 추가적인 성능 향상을 위해 서로 약간의 차이점은 있지만 전반적으로 비슷한 구조를 공유합니다.
Self-Supervised Learning은 학습의 정답값이 되는 GT 없이 특정한 pretext task를 설계하여 사전학습함으로 데이터 자체에 대한 표현력을 확보하는 방법입니다. 이미지 데이터의 경우 이미지를 회전시켜 얼마나 회전된 건지 각도를 맞추거나 이미지를 패치 단위로 잘라 퍼즐을 풀게 하는 등의 pretext task를 구성할 수도 있고, 텍스트 데이터의 경우 문장 안에서 특정 단어를 마스킹해 빈칸 채우기를 반복하여 SSL을 수행할 수도 있습니다.
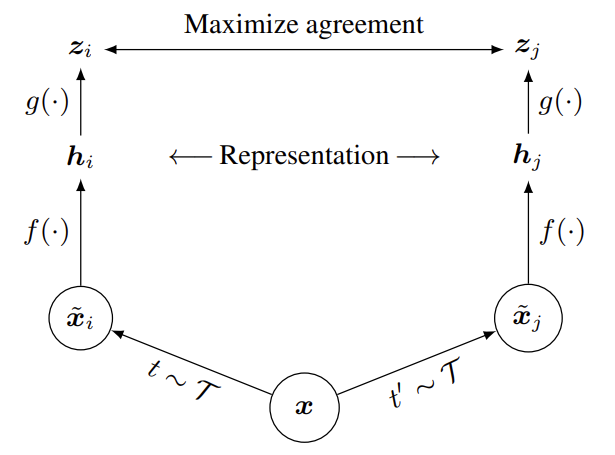
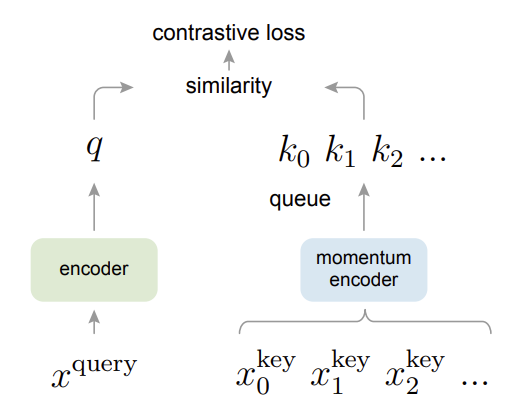
위 그림은 각각 SimCLR(왼쪽)와 MoCo(오른쪽)의 프레임워크인데, 동일한 이미지에 서로 다른 random augmentation을 취하고 encoder를 거쳐 feature를 추출한 다음 embedding space(벡터를 normalize하므로 hypersphere 상에 있습니다)상에서 contrastive learning을 통해 동일한 이미지에서 추출한 positive pair 간 코사인 유사도는 높아지도록(벡터 간 거리가 가까워지도록), negative pair 간 코사인 유사도는 낮아지도록(벡터 간 거리가 멀어지도록) 학습하며 사전학습을 진행합니다. 둘 다 강력한 augmentation을 가해도 모델이 동일한 이미지인지 알아볼 수 있도록 학습하게 하며, trivial solution을 방지하기 위해 대량의 negative pair를 활용해야 한다는 점이 동일합니다. 차이점은 negative pair를 활용하기 위해 매우 큰 배치 사이즈를 유지하는 SimCLR와 달리 MoCo의 경우 feature extractor 한쪽에 dictionary를 구성해서 학습 사이클마다 새로운 데이터를 enqueue하고 기존의 데이터를 dequeue하며 dictionary를 업데이트 한다는 점과, MoCo의 양쪽 feature extractor의 파라미터를 동시에 업데이트 하지 않고 key encoder는 query encoder의 파라미터를 momentum update하는 방식으로 파라미터를 갱신하게 구성된다는 점이 다릅니다.
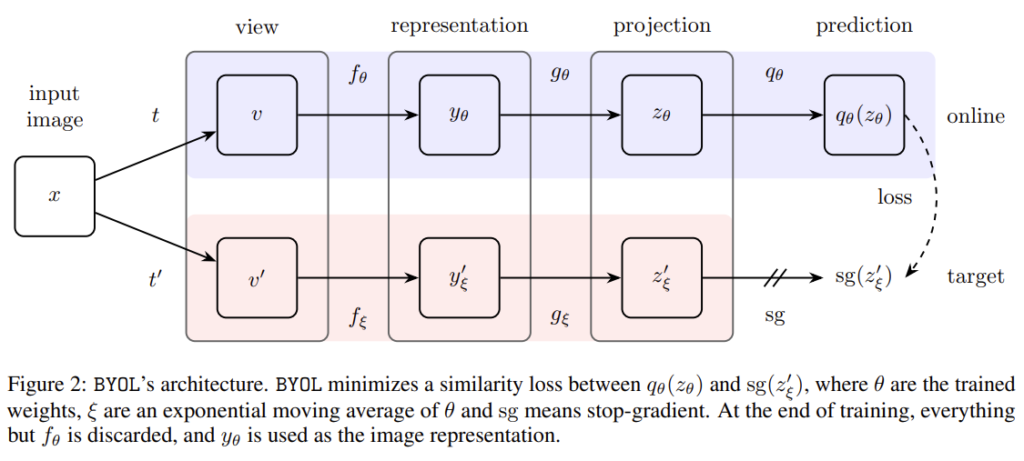
SimCLR와 MoCo는 collapse(trivial solution)을 방지하기 위해 많은 양의 negative pair를 사용했다는 단점이 있습니다. 이후에 제안된 BYOL은 negative pair를 사용하지 않고 대신 collapse를 방지하기 위해 비대칭 구조를 활용합니다. online network에는 추가적으로 predictor를 추가한 뒤 online network와 target network의 출력값의 유사도를 이용하여 학습을 하게 됩니다.
이러한 Self-Supervised Method들은 데이터의 라벨값을 얻기 위해 annotation 할 필요가 없기에 대량의 데이터를 활용해 SSL로 사전학습을 할 수 있습니다. NLP에서 BERT나 GPT 같은 트랜스포머 기반 방법론들의 성공 뒤에는 바로 이 SSL이 있었고, 저자들은 여기서 영감을 얻어 이미지 인식을 위한 트랜스포머 모델에도 SSL을 통해 강력한 visual representation을 학습시키고자 합니다. 이 연구 과정에서, 저자들은 convnect이나 supervised learning으로 학습된 ViT와는 다른, Self-Supervised Learning으로 학습된 ViT의 다음과 같은 특징을 발견했다고 합니다:
- Self-Supervised ViT feature는 Figure1에서 확인할 수 있듯 객체의 경계와 같은 scene layout를 포함한다(즉, 명확한 semantic segmentation 정보를 포함한다). 이 정보는 마지막 block의 self-attention module에서 바로 접근 가능하다.
- Self-Supervised ViT는 추가적인 파인튜닝이나 데이터증강, linear classifier 없이 기본적인 KNN에서도 잘 동작하며, ImageNet에서 78.3%의 정확도를 기록했다

segmentation mask 특성은 self-supervised method 전반적으로 나타나는것 같으나, KNN에서의 좋은 성능은 momentum encoder나 multi-crop augmenation같은 특정한 요소들을 결합했을때만 나타난다고 합니다. 왜 갑자기 KNN을 언급할까 생각해봤는데, DINO로 사전학습하여 특징을 추출하면 별다른 CNN/NLP classifier를 사용할 필요도 없이 그 특성이 잘 구분된다는것을 강조하기 위한 게 아닌가 싶네요.
저자들은 이러한 특징을 바탕으로 label이 필요 없는 knowledge distillation 형태로 해석할 수 있는 self-supervised learning 접근법을 설계하였습니다. 이렇게 설계된 DINO라는 방법론을 간단히 요약하면 momentum encoder를 활용하여 만들어진 teacher network의 ouput을 cross-entropy를 사용하여 예측하는 것으로 생각할 수 있습니다. 기존의 SSL 방법들이 collapse를 막기 위해 predictor, 추가적인 정규화, contrastive loss 등등의 추가적인 구조를 활용한 것과 다르게 해당 방법론은 teacher network에 centering과 sharpening을 추가한 것 만으로 collapse를 막을 수 있었다고 합니다. 저자들이 제안하는 프레임워크는 추가적인 구조의 수정 없이 ViT와 convnet 모두에 적용이 가능하며, 내부 정규화를 추가적으로 수행할 필요도 없다고 합니다.
실험적으로는 ImageNet linear classification benchmark에서 80.1%의 top-1 acc를 달성해 DINO와 ViT의 시너지 효과를 달성하는데 성공하였으며, ResNet50에 적용해도 잘 작동함을 확인하였습니다. 특히 학습 자원 측면에는 ViT를 DINO로 학습하는 것이 훨씬 적은 컴퓨팅 리소스를 활용하며 convnet 기반 SSL방법보다 좋은 성능을 달성하였다고 합니다.
Approach
SSL with Knowledge Distillation

DINO는 기존의 SSL 방법론들(SimCLR, MoCo, BYOL 등)와 전반적으로 유사한 프레임워크 구조를 사용했지만, knowledge distillation의 특징도 가져왔습니다(DINO라는 이름도 Knowledge DIstillation with NO labels에서 따온 것입니다). knowledge distillation 기법은 student network의 output을 teacher network의 output에 매칭하여 (보통 큰 network인)teacher의 지식을 (보통 작은 네트워크로 구성되는)student에 전달합니다. teacher network의 output을 softmax로 정규화해 이 출력 logit vector를 일종의 soft label로 사용하여 student를 학습하는 target으로 사용하는 것이죠. 논문에서는 student network를 g_{θs}, teacher network를 g_{θt}, 각 네트워크의 K차원 출력 확률 분포(output logit vector)를 P_{s}, P_{t} 로 표기합니다. 그럼 각 network의 출력은 classification을 수행할때와 유사하게 다음과 같이 표기할 수 있습니다.
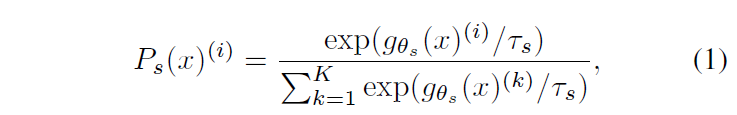
여기서 τ (τ>0) 는 output vector 분포의 sharpness(얼마나 고르게 분포하게 하는지)를 조정하는 파라미터로, contrastive loss에서 등장하는 것과 같은 temperature parameter입니다. student network는 주어진 fixed teacher network g_{θt}의 출력 분포를 cross-entropy로 학습하게 됩니다.
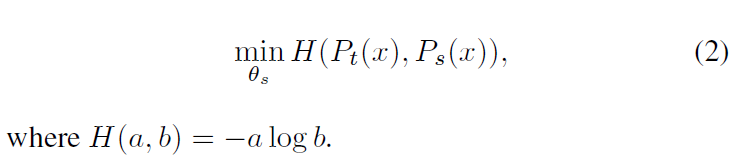
P_{t}(x)와 P_{s}(x)를 구하는 것은 기존의 SSL방법론들과 유사한데, input image에 대해 random augmentation을 가해 2개의 global views x_{1}^{g},x_{2}^{g} 와 추가적인 local views를 만든 후 global views는 teacher network에, local views는 student network에 통과시킨 다음 local-to-global 대응을 수행합니다. 이는 이미지의 다양한 feature level을 얻기 위함입니다. Transformer 구조가 가지는 가장 큰 문제점 중 하나가 local-to-global correspondence가 적다는 것인데, 트랜스포머는 attention 기반으로 한번에 global 정보를 인지하기 때문에 CNN이 가지는 계층적 구조로 얻을 수 있는 low-high level feature의 특징을 살리기 어려운 특성이 있습니다. 이에 따라 teacher network에는 이미지 전체에 대한 큰 augmentation을 수행한 global view를 사용하고, student network에는 multi-crop같은 이미지의 작은 범위의 augmentation이 적용된 local/global 정보를 활용하는 것입니다. 최종적으로 최적화하는 loss는 다음과 같습니다.
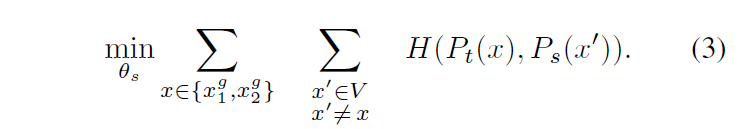
이 loss로는 범용적으로 다양한 수의 views에 사용될 수 있는데, 저자들은 기본 세팅으로 이미지의 넓은 영역을 포함하게 되는 224×224 해상도의 global view(2개)와 작은 영역을 포함하게 되는 96×96 해당도의 local view(여러 개)를 사용합니다.
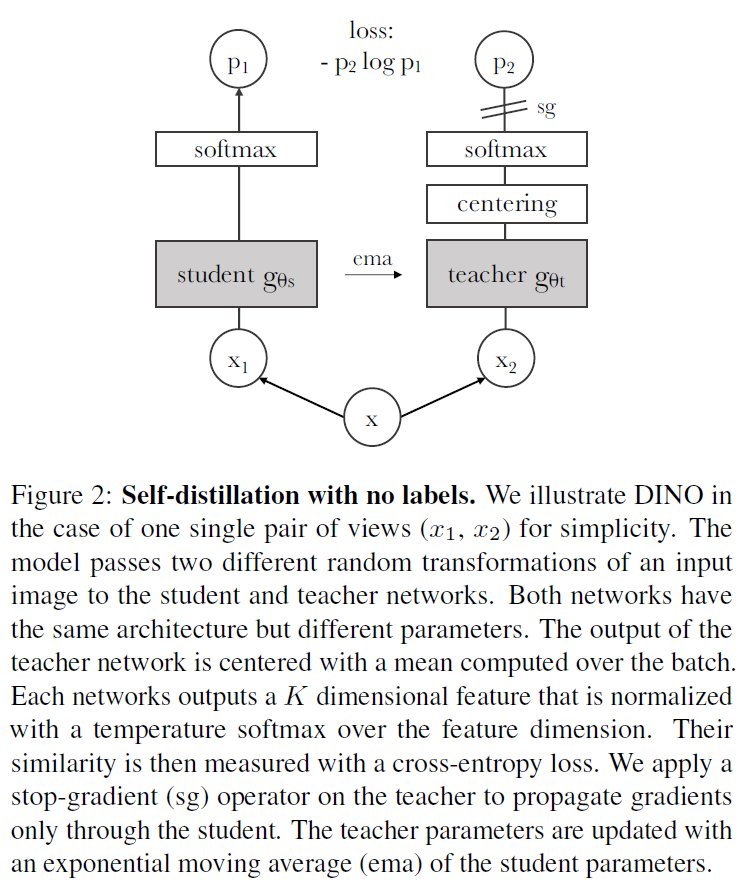
DINO의 전반적인 동작 프레임워크는 Figure2와 같습니다. 동일한 이미지에 다른 random augmentation을 가해 student 및 teacher network로 보내고, teacher network의 출력을 pseudo label 삼아 student network를 학습 시킨 다음 teacher network는 ema를 통해 업데이트 하게 됩니다. 이 때 student와 teacher의 모델 구조는 동일하지만 서로 다른 내부 파라미터를 가지고 동작합니다. Pytorch pseudocode로는 다음과 같이 나타낼 수 있습니다.

Teacher network
여기서는 knowledge distillation과 다르게 사전 지식으로 teacher network g_{θt}를 사용하지 않고, student network의 이전 iteration을 teacher network로 사용했습니다. 여기서 저자들은 다양한 update 방법을 teacher에 실험해보았는데 해당 프레임워크에서는 epoch가 진행되는 동안 teacher network를 freeze하는 것이 좋은 결과를 보였으며 student의 가중치를 teacher에 복사하는 방법은 수렴에 실패했다고 합니다. 특히, exponential moving average (EMA. θt←λθt+(1−λ)θs) 방법을 사용하는 것이 좋았다고 합니다. 원래 (MoCo계열 프레임워크에서는)momentum encoder가 contrastive learning의 queue에 사용되었는데, DINO에는 queue나 contrastive loss가 없으므로 contrastive learning의 ema와는 그 역할이 약간 다르고 self-training에 사용하는 mean teacher의 역할에 더 가깝다고 합니다. 습 중에는 teacher가 student보다 더 성능이 좋으며, teacher가 target feature들을 고품질로 제공하여 student의 학습을 guide합니다.
Network Architecture
신경망 g는 backbone f(ViT or ResNet)와 profection head h 로 구성된다고 합니다. projection head는 3계층 MLP와 l2 norm, 그리고 weight normalized fc layer로 구성됩니다. 다양한 projection head를 실험해 보았지만 이러한 구조가 가장 적합하였다고 합니다. 이 때, 표준 convnet과 달리 ViT에는 batch norm이 없으므로 projection head에도 batch norm을 제거하여 전체 시스템에 batch norm이 없도록 하였습니다.
Avoiding collapse
여러 self-supervised learning 방법들이 contrastive loss, clustering constraints, predictor, batch norm과 같은 방법을 통해 collapse를 피하려고 했습니다. DINO에도 이런 방법을 사용할 수 있긴 하지만 momentum teacher output의 centering 및 sharpening만으로 collapse를 피할 수 있다고 합니다. Centering은 teacher network가 생성한 feature vector의 평균을 각 벡터에서 빼는 방법인데, 이렇게 하면 한 차원이 dominate하게 되는 것을 방지하며 uniform distribution을 따르게 하는 효과가 있습니다. sharpening은 temperature parameter를 조정하여 softmax vector output의 정규화 정도를 조정하는 것인데, centering과는 반대의 효과를 갖기 때문에 두 연산을 균형 있게 적용하면 momentum teacher에서의 collapse를 방지하기에 충분하다고 합니다.
Experiment
모델은 ImaegNet으로 label 없이 사전학습되었습니다. 학습에는 adamw optimizer, 1024 batch, 16개 GPU에 distributed train이 사용되었다고 합니다. 데이터 증강 기법은 BYOL과 동일하게 사용되었습니다.
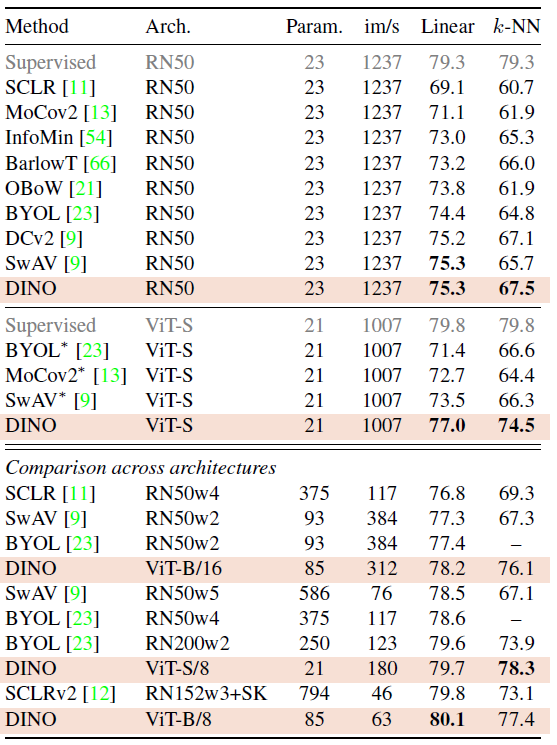
위 표는 ImageNet 데이터셋에 대한 Linear 및 k-NN classification 결과를 나타낸 것입니다. ResNet-50과 ViT-small architecture을 feature extractor로 사용하여 비교 정리한 표입니다. DINO는 두 backbone 모두에서 경쟁력 있는 결과를 보였습니다.
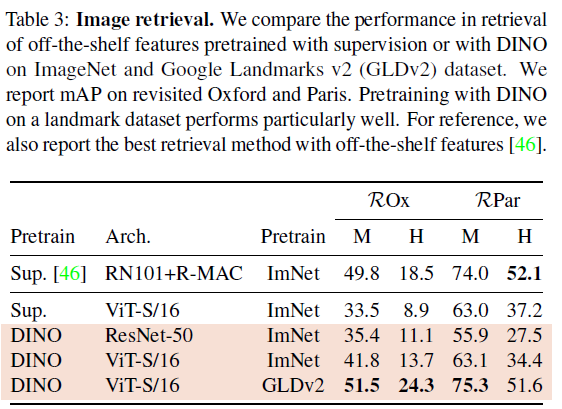
Table3는 Image Retrieval 결과입니다. 사전학습은 ImageNet과 Google Landmarks v2로 수행되었습니다. retrieval task는 잘 알지 못하는데, revisited Oxford and Paris image retrieval dataset이 사용되었다고 합니다. query/database pair가 3단계 난이도로 구성되어 있다고 하네요. 저자들은 Medium(M)과 Hard(H) split에 대해서 mAP를 report하였습니다. 저자들은 feature를 freeze하고 retrievel을 위해 바로 k-NN을 적용하였다고 합니다. 결과적으로는 DINO feature가 supervised ImageNet보다 좋은 성능을 보였습니다.
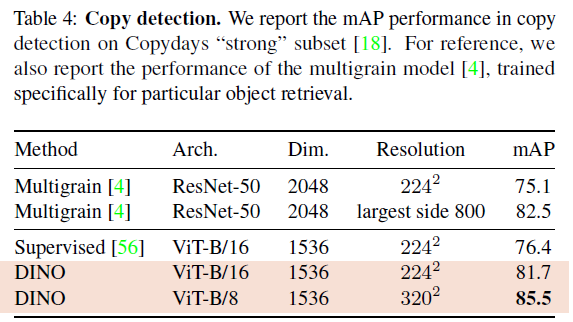
다음은 ViT DINO의 Copy detection 결과입니다. 저자들은 INRIA Copydays dataset의 strong sub에서 mean average precision을 report하였습니다. 낯선 task였는데, blur, insertions, print, scan 등으로 왜곡된 이미지를 인식하는 task라는 설명이 있습니다. 이를 위해 사전학습된 network에서 얻은 feature vector의 cosine similarity를 사용해 copy detection을 수행했다고 합니다. feature는 output [CLS] token과 GeM pooled output patch token을 concat해 얻었으며 ViT-B에서 1536차원의 descriptor를 얻었다고 합니다. Table4에서 확인할 수 있듯, DINO는 매우 경쟁력있는 결과를 보였습니다.
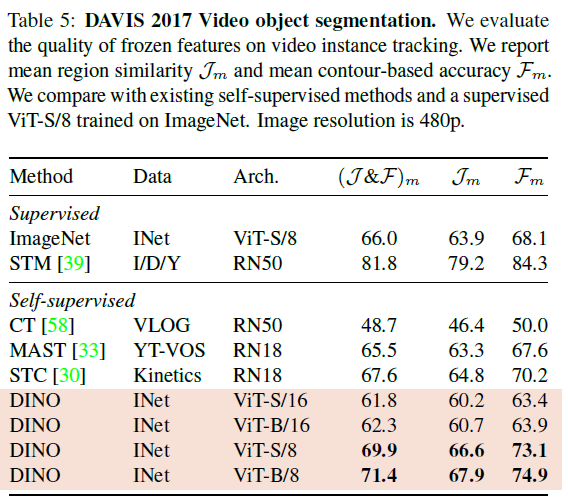
Table 5에서는 DAVIS-2017 video instance segmentation benchmark에서 output patch token을 평가했다고 합니다. 해당 table을 확인하면 DINO의 학습 loss와 구조가 dense task를 고려하여 설계된 것이 아님에도 해당 벤치마크에서 경쟁력 있는 결과를 보임을 강조하고 있습니다.


Fig3은 ViT-S/8 마지막 layer의 head에서의 attention map을 시각화 한 것입니다. 결과를 보면 다른 head는 다른 semantic region에 집중하는것을 볼 수 있습니다. Fig4에서는 정량적/정석적으로 supervised ViT보다 DINO가 좋은 segmentation(mask)를 만드는것을 확인할 수 있습니다.
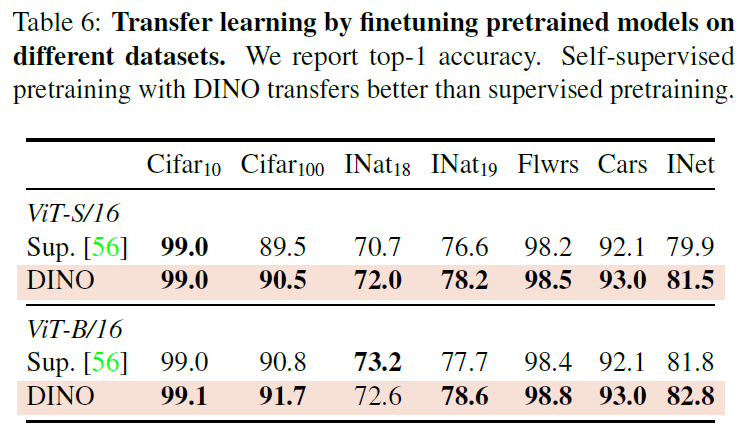
Table 6에서는 사전학습한 모델을 fine-tuning했을때의 성능입니다(위에서는 linear evaluation 및 k-nn 성능을 보였죠). 해당 성능에서도 ViT DINO가 경쟁력 있는 성능을 보이고 있습니다.
ViT를 기본으로 하는 SSL 논문은 처음 읽어보았는데, KD 관점을 가져와 학습을 한 것과 attention map으로 재밌는 성질까지 확인할 수 있어서 흥미로운 논문이었습니다.
감사합니다.
안녕하세요 허재연 연구원님 DINO 리뷰 잘 읽었습니다.
한 가지 궁금한 점이 생겨서 질문드립니다.
SSL로 학습된 ViT는 독특한 특징 (객체의 경계 같은 scene layout, semantic segmentation)을 포함한다고 하였는데,
왜 이러한 특징이 ConvNet이 아닌 ViT에서 나타나는지와 관련한 분석이 있나요?
그리고 DINOv2를 공부할 예정이라고 하셨는데,
그동안 리뷰하신 ConvNet기반의 Contrastive SSL이 아닌 ViT구조를 사용하려는 이유가 있으신가요?
다시말해, DINO를 선택하고 알아보게된 계기가 궁금합니다.
self-attention map이 scene의 semantic layout 정보를 갖고 있다는 분석은 Table5, Figure3과 함께 나와 있지만, Supervised ViT나 Convnets에서는 나타나지 않는 이런 속성이 SSL ViT에서만 나타나는 이유에 대한 별다른 언급은 없습니다.
DINOv2에 대한 follow-up 필요성을 느낀 것은 당장 Transformer계열 모델 활용을 염두고있기보다는 비교적 최신 SSL 방법을 공부하기 위한 것에 더 가깝습니다. 2020년contrastive learning 방법론들 및 2022년 MAE 이후에 대표적인 SSL 중 하나가 DINOv2이기에 해당 Foundation모델이 어떻게 만들어졌는지를 이해하고 이후 필요한 상황이 오면 활용할 생각을 갖고 있습니다. 또한 이전부터 몇몇 선배 연구원들께서 SSL에 관심 있으면 DINOv2를 한번 살펴보라는 권유가 있기도 했습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 잘 읽었습니다.
최근에 DINO를 사용할 일이 있었는데, 내부 구조를 이해하지 못한 채로 사용하여
이번 기회에 잘 이해하게 된 것 같습니다.
일반적으로 사용하는 teacher model의 softmax 값을 student model이 사용하는 것이 아닌
DINO에서 사용하는 knowledge distillation이 굉장히 달라, 신기하기도 하면서 바로 이해하기 어려웠습니다.
저는 teacher model을 통해 model이 더 안정되고 굳건한 방향으로 학습하기에 label 없이 SSL을 할 수 있었다라고 이해했습니다.
읽으면서든 의문점이 있습니다.
teacher model은 EMA를 통해, student model에 가까워지는 방향으로 이동하고
student model은 바로 이전 iteration인 teacher model과 같은 예측을 내놓는 방향으로 학습한다고 읽었습니다.
그렇다면 직관적으로 생각하면, teacher model과 student model이 서로 가까워지는 방향으로 학습하기에
학습이 진행되는게 아니라 수렴하는게 아닌가 라는 의문이 들었습니다.
물론 두 model이 다른 view의 augmention된 image를 받기 때문에 괜찮지 않을까 싶긴한데, 잘 이해가 되지 않아 질문합니다.
리뷰에 작성되어있듯이, 실제로 두 예측값을 뱉는 모델 구조를 동일하게 두고 단순히 positive pair끼리만 가까워지는 방향으로 학습을 진행하게 되면 결국 모든 data point가 한 곳으로 수렴하는 collapse가 발생합니다. MoCo, SimCLR와 같은 방법론들의 경우 이를 막기 위해 수많은 negative pair를 필요로 하죠. 하지만 BYOL의 경우 두 예측값을 출력하는 모델 구조를 다르게 하여 collapse 문제를 해결하고 negative pair를 사용하지 않은 instance discrimination SSL이 가능하게 했습니다. DINO의 경우 여러 실험을 통해 momentum teacher output의 centering 및 sharpening으로 collapse를 피할 수 있었다고 합니다. 핵심은 teacher와 student의 output을 단순히 동일하게 출력해서 같게 만들지 않고, 출력 과정에 차이를 두는 것으로 이해하면 좋을 것 같네요