이번 논문은 3D scene representations에 foundation model의 특징 정보를 학습시킴으로써, 장면에 대한 의미론적 이해가 가능하도록 하는 것을 목표로 합니다. 더 나아가, 언어, point, bbox 등 프롬프트를 입력으로 받아 3D 장면에 대한 분할 혹은 편집이 가능한 결과를 보여줍니다.
해당 논문을 이해하기 위해서는 [SIGGRAPH 2023] 3D Gaussian Splatting for Real-Time Radiance Field Rendering, [CVPR 2024 Spotlight] LangSplat: 3D Language Gaussian Splatting을 보시는 것이 좋을 것 같습니다.
+ 위 두 논문을 이해하고 계신다면 해당 논문은 매우 쉽습니다…
++ 해당 논문에 대한 리뷰를 작성하는 중에 모호한 부분이 발생하여 미완성된 감이 있습니다. 해소되면 바로 글 수정하도록 하겠습니다.
Intro
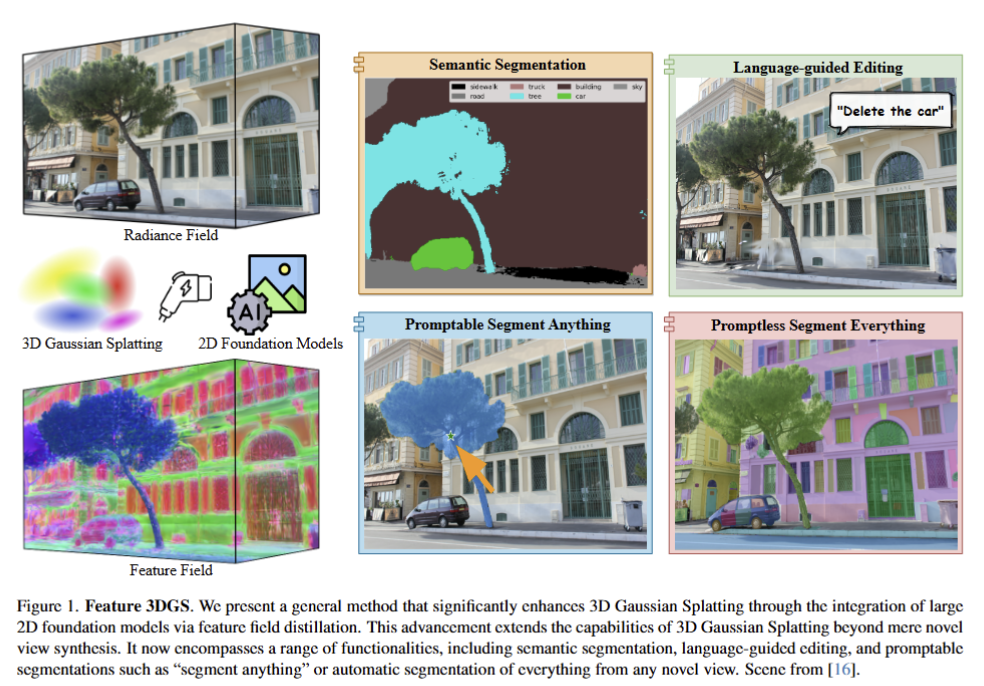
3D scene representations과 관련된 기술들은 최근 NeRF와 같은 Neural Radiance Fields 기법을 통해 빠르게 발전했습니다. 하지만 이러한 기술들은 고해상도의 장면을 재구성하는 데 큰 계산 자원을 필요로 하며, 주로 시각적 정보에만 집중되어 있어 의미론적 인식과 세그멘테이션 작업에 한계가 있었습니다. 이로 인해 3D 장면에서의 의미적 이해와 편집이 필요한 응용에서는 성능과 효율성의 문제가 부각되었습니다.
특히, 2D foundation model(e.g. CLIP, SAM)이 2D 이미지에서 탁월한 성능을 보여주고 있지만, 이를 3D 공간에 적용하는 방법은 여전히 초기 연구 단계에 머물러 있습니다. 3D Gaussian Splatting(3DGS)는 이러한 시각적 표현을 효율적으로 처리할 수 있는 새로운 방식으로 떠오르고 있지만, 여전히 의미 정보를 통합하여 세그멘테이션이나 언어 기반 편집을 지원하는 데 있어 부족함이 존재합니다.
이에 따라 Feature 3DGS는 3D Gaussian Splatting(3DGS)을 확장하여, 2D foundation model에서 학습된 고차원 의미 필드를 3D 공간에 증류(distillation)하는 Feature Field Distillation 기법을 제안합니다. 이를 통해 3D 장면에서의 세그멘테이션 및 언어 기반 편집이 가능해집니다. 또한, Parallel N-Dimensional Gaussian Rasterizer를 도입하여 의미론적 정보와 시각적 정보를 병렬로 처리하고, Convolutional Speed-Up Module을 통해 고차원 특징 맵의 렌더링을 빠르고 효율적으로 수행할 수 있도록 설계되었습니다. 이러한 기법들은 빠른 처리 속도와 실시간 상호작용을 지원하며, 3D 장면에서의 의미론적 인식과 편집을 크게 향상시켜 다양한 응용 분야에서 활용될 수 있는 가능성을 제시합니다.
Method
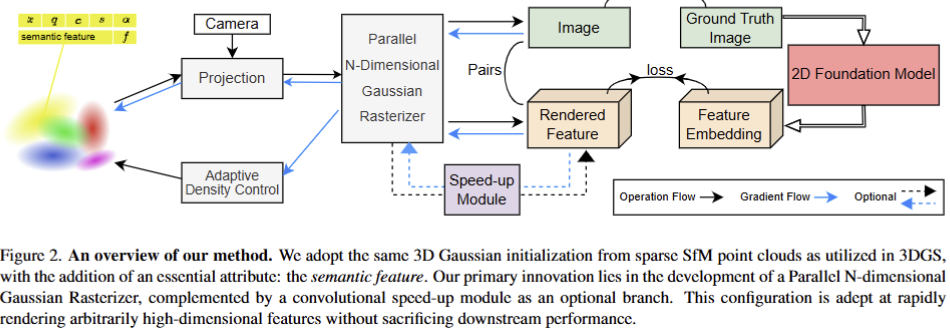
Feature 3DGS는 3D Gaussian Splatting(3DGS)에 고차원 의미 필드를 결합하여, 2D foundation model에서 학습한 의미 정보를 3D 공간에 증류하는 방법을 제안합니다. 이를 통해 3D 장면에서 세그멘테이션, 언어 기반 편집과 같은 의미론적 작업을 가능하게 합니다. 전반적인 파이프라인은 fig 2에서 확인 가능하며 해당 기법은 다음 세 가지 주요 구성 요소로 이루어져 있습니다.
High-Dimensional Semantic Feature Rendering
3DGS는 기본적으로 Structure from Motion(SfM)을 통해 초기 포인트 클라우드를 생성하고, 이를 기반으로 3차원 공간 내에서 가우시안 분포로 장면을 표현합니다. 각 포인트 [lataex] x \in \mathbb{R}^3 [/latex]는 가우시안의 중심으로 표현되며, 3D 가우시안은 3차원 공분산 행렬 \Sigma 로 정의됩니다. 이 공분산 행렬은 카메라 좌표계로 변환되며 다음과 같은 수식으로 나타낼 수 있습니다:
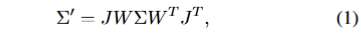
여기서 W는 world-to-camera transformation matrix, J는 투영 변환의 Jacobian입니다. 해당 공간에서은 공분산 행렬은 실제 세계를 투영하기 때문에 양의 값을 가져야만 합니다. 이를 반영하기 위해서 공분산 행렬은 rotation R과 scale S로 분해되어지며 다음과 같이 표현됩니다.
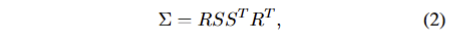
또한, rotation과 scale은 각각 쿼터니언 q와 scale factor s에 해당하며, 3D 가우시안은 텍스쳐 정보를 학습하기 위해서 opacity value \alpha 와 (색상 정보에 대한 복잡도 향상을 위해 제안되어진) 3차 spherical harmonics (SH)까지 최적화를 수행합니다.
최종적으로 각 픽셀에 대한 색상 C와 특징 값 F_s를 volumetric rendering을 통해 계산합니다. (여기서 F_s의 s는 student에 해당) 해당 수식은 다음과 같습니다:
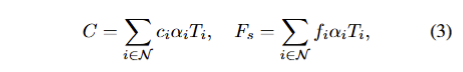
여기서 T_i = \prod_{j=1}^{i-1} (1 - \alpha_j)는 transmittance을 의미합니다. 이 과정은 전방에서 후방으로depth order의 순서로 진행됩니다. 이를 통해 3D Gaussian Splatting은 Θ_i = {x_i, q_i, s_i, α_i, c_i, f_i}로 표현되며, 고차원 feature field를 3D 장면에 매끄럽게 통합하여 다양한 뷰에서 렌더링할 수 있게 됩니다.
+ 위 내용은 클래식한 3DGS에 대한 내용을 이전 리뷰를 참고하시면 좋을 것 같습니다. 추가되는 내용은 특징 값 f_i \in F_s 하나라고 생각하시면 됩니다.
Parallel N-Dimensional Gaussian Rasterizer
저자가 제안하는 또 다른 핵심 구성 요소는 Parallel N-Dimensional Gaussian Rasterizer입니다. 이 래스터라이저는 RGB 이미지와 고차원 특징 맵을 병렬로 렌더링하며, 타일 기반의 래스터화 과정을 사용해 픽셀 단위로 3D 가우시안 분포를 처리합니다. 해당 방식은 16 × 16 타일로 화면을 나누어 각 타일을 독립적으로 처리하며, 특징 맵과 RGB 이미지가 동일한 해상도로 렌더링되도록 보장합니다.
+ 말이 복잡한데… 그냥 3DGS에서 사용하는 래스터화에 feature도 같이 예측했다고 보면 됩니다… 해당 방법이 가능한 이유는 3DGS가 학습하고 평가하는 환경을 이해해야합니다. 3DGS는 공간을 표현하는 것을 목적으로 하기 때문에 정적으로 고정된 장면이 학습 데이터이자 평가 데이터에 해당합니다. 즉, 같은 물체만 본다는 거죠. 그렇기에 특징 값이 틀려지는 경우가 없습니다. 그냥 공간 정보와 색상 정보를 토대로 feature를 외우는 거라고 보면 됩니다. 그러니깐 아주 간단한 방법이 가능한거죠.
Convolutional Speed-Up Module
고차원 특징 맵을 렌더링하는 과정에서 발생하는 계산 비용을 줄이기 위해, Convolutional Speed-Up Module을 도입하였습니다. 이 모듈은 저차원의 특징 맵을 먼저 렌더링하고, 이를 lightweight convolution decoder를 통해 고차원 특징 맵으로 업샘플링하는 방식으로 성능을 최적화합니다. 이 과정에서 사용되는 loss는 photometric loss와 feature loss의 조합으로, 수식은 다음과 같습니다:
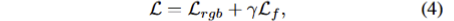
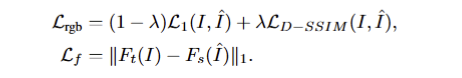
여기서 L_{rgb} = (1 - \lambda) L_1(I, \hat{I}) + \lambda L_{D-SSIM}(I, \hat{I}), L_f = |F_t(I) - F_s(\hat{I})|_1입니다. 여기서, F_t는 foudnation model의 feature map에 해당합니다. 이러한 방식을 통해 고차원 의미 필드와 RGB 이미지를 동시에 최적화하여, 학습 및 추론 속도를 개선하면서도 성능을 유지할 수 있습니다.
+ 해당 파트에서 사용된 lightweight convolution decoder는 1×1 convolution으로 구성됩니다. 차원만 변경하는 거죠. 이렇게 단순하게 적용해도 가능한 이유는 위에서 언급한 바와 같이 고정된 장면에 동일한 위치의 물체만 등장하기 때문에 가능한거라고 봅니다.
Experiment
Novel View Semantic Segmentation

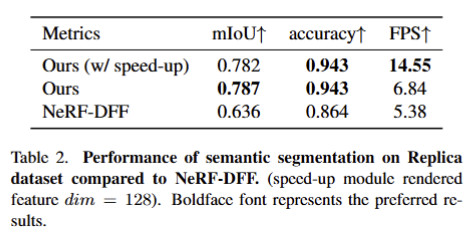
해당 실험에서는 새로운 카메라 뷰에서 의미론적 세그멘테이션을 평가했습니다. 실험 결과, 3D Gaussian Splatting을 사용한 방법이 더 빠르고 세밀한 세그멘테이션을 가능하게 했습니다. 특히, LSeg와 SAM을 기반으로 한 Feature Field Distillation을 통해 객체 경계가 더 정확하게 처리되었으며, NeRF-DFF와 비교해 성능이 뛰어났습니다.
Tab 2에서 보이는 바와 같이 Replica Dataset에서의 세그멘테이션 성능을 보여주며, mIoU 0.782, FPS 14.55로 NeRF-DFF에 비해 향상된 성능을 기록했습니다. Fig 3-(b)에서 NeRF-DFF와 비교한 새로운 뷰에서의 세그멘테이션 결과를 시각적으로 보여주며, 우리의 방법이 더 고품질의 세그멘테이션을 제공함을 확인할 수 있습니다.
Segment Anything from Any View


SAM 모델을 사용해 Promptable/Promptless 세그멘테이션을 테스트하였습니다. fig 5에서 박스 프롬프트와 포인트 프롬프트 기반 세그멘테이션에 대한 NeRF-DFF와 비교 가능한 정성적 결과를 볼 수 있으며, Fig 4에서는 단순하게 novel view image에 단순하게 SAM을 적용한 Fig 4-(a)와 저자가 제안한 기법 Fig 4-(b)에 대한 추론 속도에 대한 결과를 확인 할 수 있습니다. 저자가 제안한 방법 1.7배 더 빠르게 수행되었으며, 세그멘테이션 품질을 유지하면서도 속도가 크게 향상되었습니다.
Language-Guided Editing

해당 실험에서는 CLIP 텍스트 명령을 통해 객체를 편집하는 작업을 수행합니다. 예를 들어, “바나나 추출”, “자동차 삭제”와 같은 명령을 통해 3D 장면 내 객체를 편집 가능성을 보입니다. Fig 6에서는 NeRF-DFF의 편집 결과를 비교하며, 제안한 기법에서 더 좋은 결과를 보여주고 있습니다.
Ablation Studies
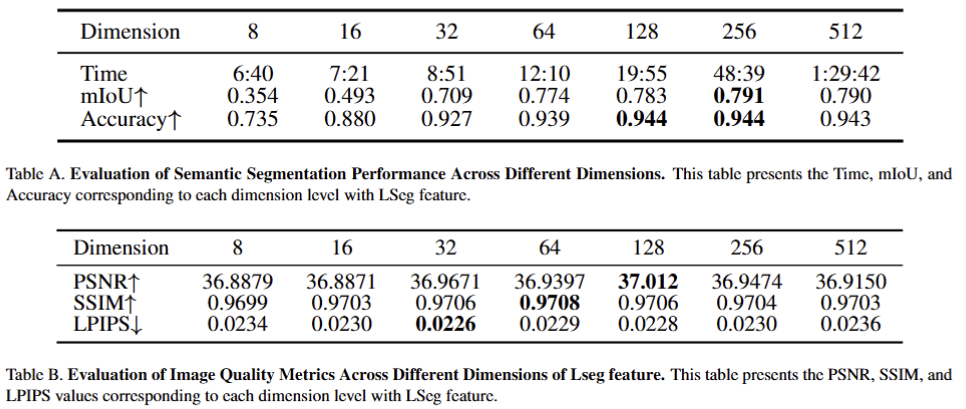
Tab A와 Tab B에서는 Convolutional Speed-Up Module이 각각 LSeg에 대한 distill을 수행 했을 때 성능에 미치는 영향을 결과 입니다. 저자는 128차원으로 다운 샘플링 했을 때, 좋은 효율을 보인다고 주장합니다.
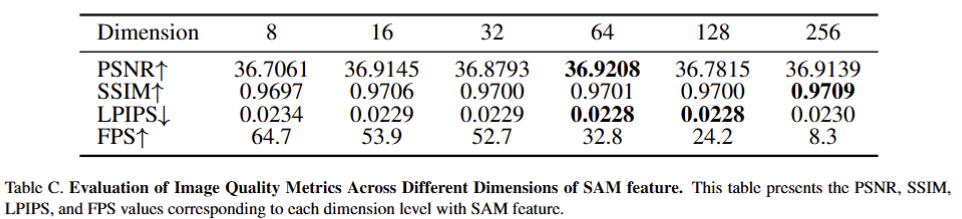
SAM에 대한 증류 결과는 Tab C와 같습니다. 저자는 64차원에서 가장 좋은 효과를 보였다고 합니다. (공평한 비교를 위해 해당 실험을 제외한 모든 실험은 128 차원에서 진행하였다고 합니다.)
해당 기법과 유사한 기법인 LangSplat과 차이점은 feature와 color에 대한 학습을 동시에 진행했는가 여부인 것 같습니다. 근데 좀 아쉬운 점이 해당 논문에서 사용한 학습 기법이 모호한 부분이 있습니다. 일단 speed-up 모듈을 따로 학습을 한건지… 아니면 통합인지 그럼 왜 optimizer를 따로 두었는지… 이외에도 여럿 있긴 합니다. 모호한 부분이 해소가 된다면 리뷰 내용을 업데이트 하도록 하겠습니다.