이번 리뷰 논문은 CAT-SAM이라는 SAM의 지식을 유지하면서 특정 도메인에 효율적으로 적응시키는 기법을 소개한 논문입니다. RGB 특화된 태스크 외에도 비 RGB에서도 적응적인 결과를 보여주고 있습니다. 추가로 데이터 효율성을 고려하여 few-shot을 기반으로 설계된 논문입니다.

Intro
Segment Anything Model (SAM)은 1.1 billion 마스크와 11 million 영상으로 학습되어져 매우 놀라운 zero-shot segmentation 성능으로 비전 분야 외에도 로보틱스, 의료, 자율주행, 기타 산업계 등 다양한 분야에서 활발히 활용되어지고 있습니다. 이 뿐만이 아니라, points, boxes, masks를 geometric prompts로 받아 영상 분할이 가능하며, 다양한 상황에 걸친 다양한 다운스트림에서 잠재적으로 fine-grained mask segmentation이 가능함을 보이고 있습니다.
허나, SAM은 종종 학습 데이터의 범주를 벗어나는 상황에서 높은 퀄리티의 예측을 실패하는 경우가 발생합니다. 예를 들어 항공 영상, 메디컬, intricate structural images와 같이 도전적인 RGB 도메인이나 X-ray, Sonar, Synthetic Aperture Radar와 같이 비 RGB 영상이 입력될 경우를 볼 수 있습니다.
이러한 문제를 해결하기 위해서 다양한 연구들이 진행되어져 왔습니다. 가장 흔한 방법은 SAM을 fine-tunning 시키는 것이지만… SAM을 미세 조정하기 위해서는 정말 많은 데이터가 필요로 합니다. 특히나 위에서 예시를 들은 도메인들은 데이터를 구하기가 쉽지 않죠…
저자는 이러한 문제를 해결하기 위해서는 few-shot target sample 만을 이용하여 효율적으로 SAM을 적응시키는 것이 중요하다고 합니다. 저자는 prompt tunning 기법과 adaptor 기법에 영감을 받아 2가지 방식의 미세 조정 기법을 소개합니다.
단순하게 2 가지 미세 조정 기법들을 적응시키기에는 추가적인 문제점이 존재합니다. SAM의 특성상, 영상 특징을 추출하는 image encoder와 영상 특징으로부터 mask를 예측하는 mask decoder 간의 서로 다른 크기로 인한 불균형으로 제대로 된 최적화된 적응이 수행이 어렵습니다.
저자는 이를 해결하기 위해 새로운 ConditionAI Tunning network (CAT-SAM)을 제안합니다. 주된 기여는 다음과 같습니다. 1. 여러 가지 도전적인 다운스트림에 대해 SAM을 효과적이고 데이터 효율적으로 조정할 수 있는 onditional tuning network인 CAT-SAM을 제안합니다. 무거운 image encoder와 가벼운 mask decoder의 시너지 효과와 데이터 효율을 효과적으로 조정할 수 있는 decoder-conditioned joint tuning structure인 CAT-SAM 내에 prompt bridge를 설계합니다. 2. 입력 공간에 learnable prompt tokens을 도입하고 lightweight adapter networks.를 삽입하는 두 가지 대표적인 튜닝 전략에 prompt bridge를 내장하여 두 가지 CAT-SAM variants를 제시합니다. 3. 11개의 다양한 segmentation datasets에 대한 실험을 통해 CAT-SAM은 one-shot에서도 일관되게 우수한 이미지 세분화를 달성합니다.
Method
Preliminaries of SAM
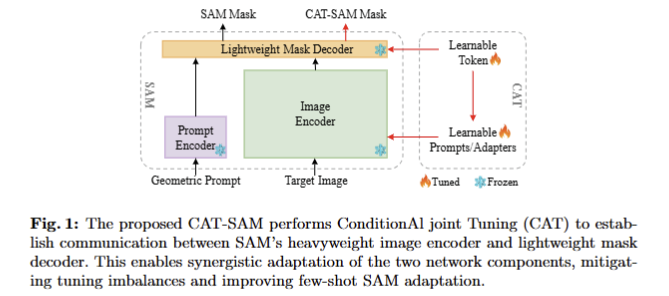
SAM은 각 영상을 3개의 key modules로 추정합니다. 먼저, image embeddings을 추출하는 heavyweight image encoder (i.e. ViT), geometric prompts으로부터 prompt embeddings를 생성하기 위한 prompt encoder, 두 embedding을 입력 받아 segmentation mask를 예측하는 lightweight mask decoder로 구성됩니다.
CAT-SAM
CAT-SAM은 SAM을 다양한 다운스트림 태스크에서 적응적으로 사용하기 위해 디자인된 ConditionAI Tunning network를 의미합니다. 특히, 강력한 zero-shot 능력과 geometry 프로픔트 유연성을 가진 SAM의 능력을 보존하면서 오직 few-shot annotated traget만을 이용하여 효율적인 적응을 시키는 것을 목적으로 합니다.
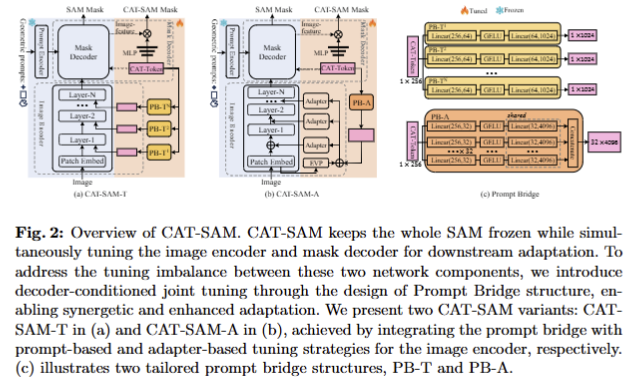
저자는 이를 위해서 SAM을 고정하고 SAM의 image encoder와 mask decoder를 동시에 tuning해야지만 few-shot target samples에서 대표 정보를 캡처하여 SAM을 효과적으로 조정할 수 있도록 합니다. 그러나 동시에 tuning하기에는 heavyweight image encoder (308.3 M parameters for ViT-L)와 lightweight mask decoder (4.1 M) 사이의 불균형으로 인해 어려움이 발생합니다. 이는 few-shot target samples만을 이용하여 적응을 수행하는 경우에 최적화로 이끌지 못하는 원인이라고 저자는 주장합니다. 저자는 이를 해결하기 위해서 decoder-conditioned joint tuning을 제안합니다. 해당 기법은 불균형 문제를 완화하기 위해서 encoding tuning과 decoding tuning 연결한 구조로 구성됩니다. 구체적으로 저자는 도메인 특화된 특징을 mask decoder에서 image encoder로 맵핑하는 lightweight network인, prompt bridge를 제안합니다. 해당 bridge를 통해 SAM 내 두 네트워크 요소 간 균형 잡힌 tunning을 통해 적은 수의 샘플과 심지어 one-shot에서도 SAM이 효율적인 적응을 수행하도록 합니다.
저자는 fig 2와 같이 흔하게 사용되는 tunnning 기법들을 이용하여 decoder- conditioned joint tuning에 적용한 두개의 CAT-SAM-T와 CAT-SAM-T를 제안합니다.
Tuning Image Encoder.
- SAM’s Image Encoder는 \mathcal{V} 로 정의하고 K 개의 transfoermer layers \mathcal{V} \(\[E_{i-1}\]\), i= 1, 2, ..., K 로 구성됩니다. 먼저, (H, W) 크기를 가진 입력 image I를 M fixed-size patches로 분리합니다. 그리고 patch embeddings E_0 \in \mathbb{R}^{M \times d_{\mathcal{V}}} 로 사영시킵니다. Patch embedding E_{i-1} 은 i^{th} transforemr layer에 순차적으로 입력되어집니다. 이는 아래와 같이 표현됩니다.
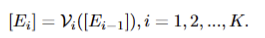
- CAT-SAM-T: fig 2-(a)와 같이 각 레이어에 입력되는 patch embedding과 함께 learnable toekns \{ P_i \in \mathbb{R}^{d_\mathcal{V}} \}_{i=0}^{K-1} 를 같이 입력합니다. 이러한 새로운 learnable toekns은 \mathcal{V} 의 각 transformer layers에 도입되고 adaptation process을 통해 업데이트됩니다:
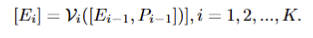
- CAT-SAM-A: fig 2-(b)와 같으며, 해당 기법은 adaters [1]을 기반으로 구성됩니다. adaters는 각 transfoermer layer 마다 추가되는 liethweight sub-network 구성됩니다. (해당 sub-network는 linear down-projection, a nonlinear activation function, a linear up-projection, and a residual connection으로 구성됩니다.) 저자는 해당 기법에 high-frequency image information을 적용시킨 EVP [2]을 적용합니다. 해당 기법은 영상에 Fast Fourier Transform and its inverse을 적용한 I_hfc를 image encoder와 동일한 patch로 쪼개고 원본 영상에서 추론된 image embeddings E_0을 각각 convolutional layers and linear layers project를 통해와 동일한 c-dim으로 사영시켜 F_{hfc}, F_{pe} 를 추론합니다. 그 후, element-wise addition을 진행합니다. 해당 값은 각 transfomer layer i에는 이전 출력값 E_i-1에 구성된 Adapt_i에 입력되어져 출력된 값이 element-wise addition이 되어져 입력됩니다. 이는 다음과 같습니다.
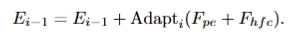
[1] Houlsby, N et.al. “Parameter-efficient transfer learning for nlp” PMLR 2019
[2] Liu, W. et.al “Explicit visual prompting for low-level structure segmentations” CVPR 2023
Tuning Mask Decoder. Decoder에 대한 tunning 기법은 HQ-SAM[3]을 기반으로 합니다. 구체적으로, Fig 5와 같이 SAM의 pre-trained decoder 전체를 freeze하고 learnable CAT-Token (1×256)을 원래 SAM의 output token과 prompt token을 concat하여 CAT-SAM의 mask decoder에 입력됩니다. SAM과 동일하게 2개의 decoder layers를 통과하고 업데이터된 CAT-Token을 3개의 MLP에 태워 동적 가중치를 생성합니다. 추가로 [3]과 동일하게 image encoder의 6th, final layer에서의 output image features를 업샘플링을 수행합니다. 최종적으로 SAM의 결과와 3개의 MLP를 태워 나온 가중치를 dot product하여 최종 mask를 생성합니다.
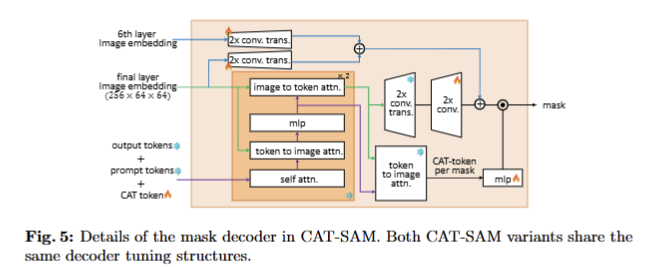
+ CAT-Token은 오른쪽 하단 CAT-token per mask에서 생성된 가중치를 활용하는 것으로 보입니다. 코드 레벨로 분석했지만 아직 잘모르겠습니다… 더 찾아보고 업데이트 하도록 하겠습니다.
[3] Ke,L et.al, “Segment anything in high quality” arXiv 2023
Decoder-Conditioned Joint Tuning.
저자가 제안하는 decoder-conditioned joint tuning은 두 가지 prompt bridging로 Fig 2-(c)와 같이 PB-T, PB-A로 구성됩니다.
- CAT-SAM-T. 먼저, prompt bridge PB_i^T 는 two-layer MLP로, mask decoder의 CAT-Token Q를 image encoder의 각 transformer layer i에 투영하고 P_i by \tilde{P}_i^T = PB_I^T\(Q\) 를 대체하는 single learnable token을 출력합니다. 이렇게 맵핑된 toekns은 다음과 같이 image encoder에 직접 적용됩니다.
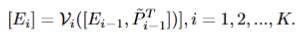
- CAT-SAM-A. prompt bridge PB^A 는 CAT-Token Q를 F_{pe}, F_{hfc} 와 동일한 크기를 가진 \tilde{P}^A = PB^A\(Q\) 로 맵핑되며, 각 값은 element-wise add되어 다음과 같이 모든 adapter에 가해집니다. PB-A는 Fig 2-(c)와 같이 독립적인 연산을 수행하기 위해서 c개의 linear down-projection layers로 구성됩니다.
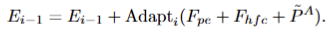
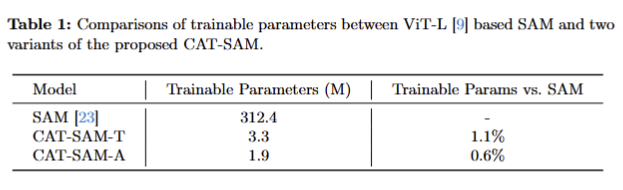
Tab 1은 각 기법에서 사용되는 trainable parameter에 대한 수치로 효율성을 보입니다.
Training and Inference
학습 중에는 targets에 대한 mask와 geometric prompts를 입력으로 하여 학습을 진행합니다. 학습 중에는 BCE loss and dice loss를 통해 최적화를 진행합니다. 학습에 사용되는 geometric prompts는 bbox, randomly selected points, coarse maks를 혼합하여 학습을 진행합니다. 추가로 HQ-SAM에 따라 coarse mask에 gaussian noise를 추가하여 학습을 진행했다고 합니다.
Experiments
Experimental Setup
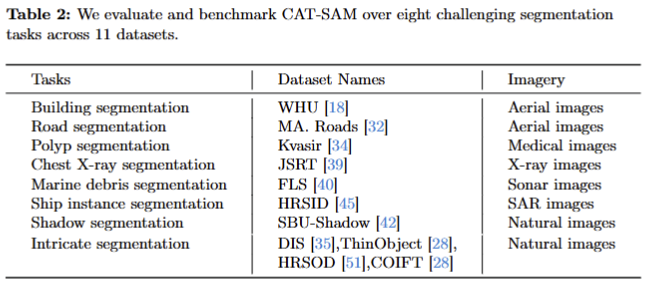
- Datasets. CAT-SAM에서 tab 2와 같이 11개의 다양한 도전적인 영상 분할 태스크에서 실험을 진행합니다. 해당 데이터 셋 내에는 비 RGB 데이터 셋도 포함됩니다.
- Evaluation Metrics은 너무 다양해서 실험 논문 참조 부탁합니다… 하하…
- Implementation Details. ViT-L을 사용, GPU는 A6000, one-shot->1 GPU, few-shot-> 4 GPUs를 이용. 공정한 평가를 위해 평가에는 geometric prompts의 입력으로 ground truth boxes를 사용함.
Ablation Studies.

Tab 3에서 보이는 바와 같이 PB-T와 PB-A를 적용을 통해 큰 성능 향상되는 경향으로부터 encoder, decoder의 불균형이 해소하는 것을 보이고 있음
Comparison with the State-of-the-Art
- one-shot
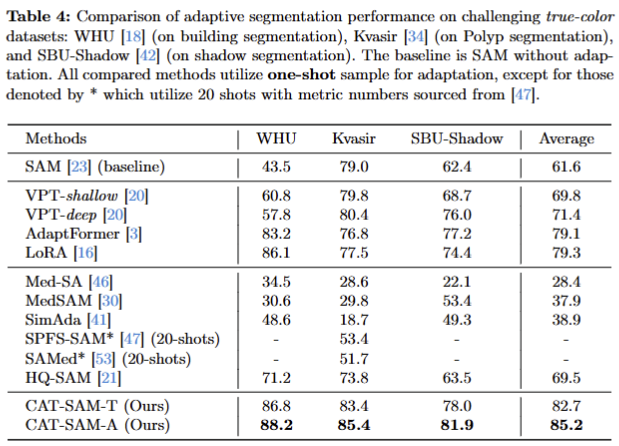
- one~few-shot and full-shot. CAT-SAM과 SAM을 제외한 기법들은 full-shot에 해당
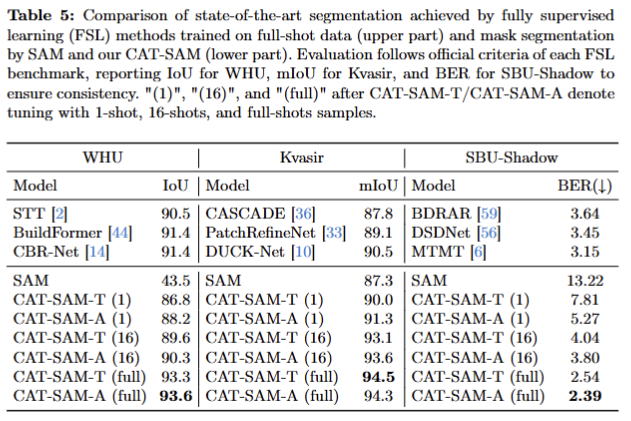
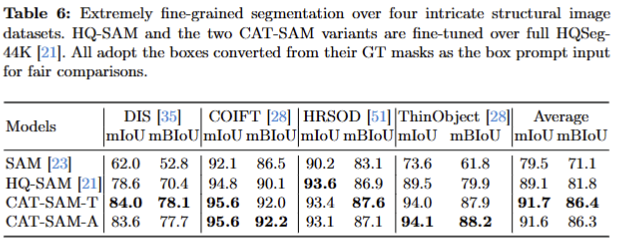
- HQ-SAM과 비교한 실험. 해당 방법론은 HQ-SAM을 기반으로 한 기법임. HQ-SAM을 뛰어넘는 성능을 보임. 해당 실험에서는 HQ-SAM과 동일하게 HQSeg-44k에서 full-shot을 수행한 다음에 비교 실험을 진행함.
CAT-SAM for Non-RGB Domains
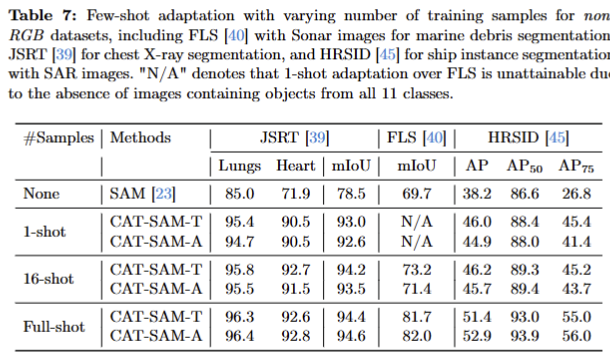
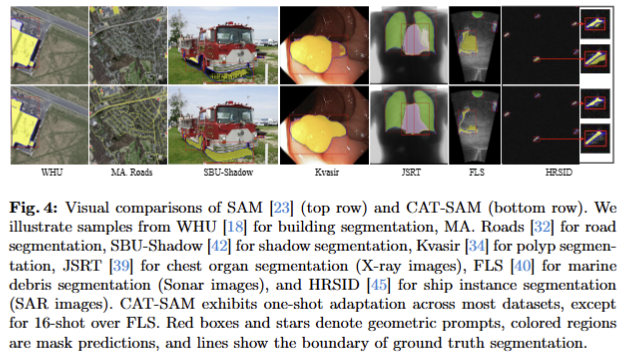
비 RGB에서의 성능을 tab 7과 정성적인 결과, fig 4에서 확인 가능합니다.
CAT-SAM은 foundation model이 비 RGB에서 효과가 있음을 제대로 증명한 논문이라고 봅니다. 그래서 Oral이 된 것 같아요. 해당 논문의 여파로 foundation model을 비 RGB에 적용하기 꺼려하시던 분들도 도전하실 것 같습니다. 저도 해당 기법을 이용해서 실험을 진행 중이며, 생각보다 결과가 나오는 것 같습니다… 좋은 결과가 나와 좋은 논문 작성하여 좋은 소식 전달하도록 노력해보겠습니다. ㅌㅌ