안녕하세요, 마흔다섯 번째 X-Review입니다. 이번 논문은 2022년도 ECCV에 게재된 Language Matters – A Weakly Supervised Vision-Language Pre-training Approach for Scene Text Detection and Spotting 논문입니다. 바로 시작하도록 하겠습니다. ?
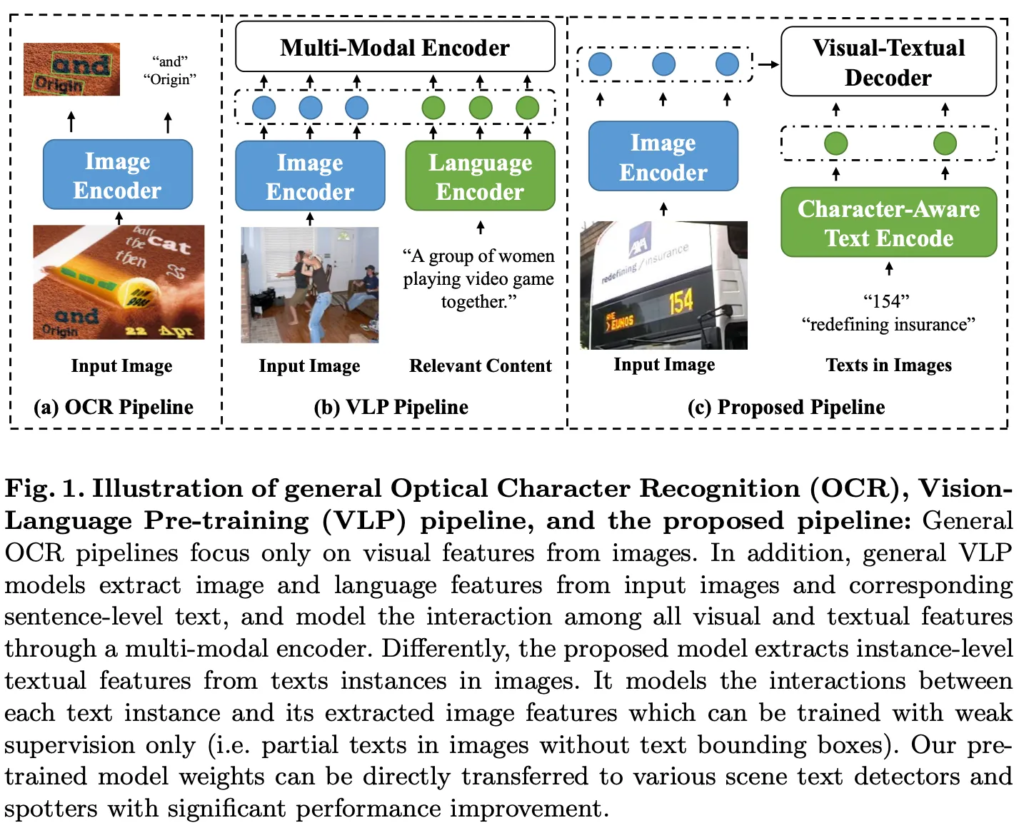
기존 대부분의 OCR 모델들은 figure 1의 (a)에서 볼 수 있듯이, 입력 영상을 image encoder에 태워 visual feature를 추출한 다음 이 feature를 가지구 detection과 recognition task를 수행하는 식으로 동작합니다. 하지만, 실제 사람은 글자를 읽을 때 visual feature 뿐만이 아니라 머릿속에 있는 언어 지식까지 활용을 해서 텍스트를 더 빠르고 정확하게 이해하는데요. 예를 들어, 특정 언어에 대한 사전 지식이 있는 경우에 그 언어로 쓰인 글자를 더 쉽게 찾아내고 읽을 수 있게 됩니다. 따라서 영상 내의 text를 잘 읽기 위해서는 visual 적인 정보 뿐만 아니라 textual 정보 둘 다가 중요하다고 말할 수 있겠습니다.
최근 Vision-Language Pre-training (VLP)는 여러 Vision-Language task에서 좋은 성능을 보여 왔습니다. 예를 들어, VQA나 Image-Text Retrieval과 같은 task 등등이 있겠죠. OCR 또한 language와 관련된 task이기 때문에 이런 VLP의 이점을 직관적으로 얻을 수 있지만, 다음의 두 가지 제약 조건이 있다고 합니다.
- Text instance 구조의 차이
VL task에서는 보통 이미지마다 하나의 문장이나 문단이 연결되어 있고 이 문단 안에서 단어 또는 구절(token)이 읽는 순서대로 배열됩니다. 반면, OCR task에서는 한 이미지마다 여러 text instance가 포함되며, 이 각각의 text instance 토큰끼리는 figure 1 (c)에 적혀있는 ‘redefining’과 ‘insurance’와 같이 종종 서로 밀접하게 관련이 있는 것들이 있고 ‘insureance’, ‘154’처럼 두 토큰이 무관한 경우가 있습니다. 이런 점이 일반적인 sequential한 방식으로 텍스트 정보를 인코딩하기 어렵게 만듭니다.
- content-relevant image-text pair
대부분의 VLP 모델은 이미지와 텍스트의 컨텐츠가 서로 관련된 쌍을 학습합니다. 예를 들어서 fig 1 (b)에 나온 사람들이 비디오 게임을 같이 하고 있는 영상과 “A group of women playing video game together”라고 하는 캡션처럼 웹에서 쉽게 얻을 수 있는 image-text pair를 사용하는 것이 일반적이죠. 이런 pair는 여러 VL task에서 좋은성능을 보였는데, OCR task에서는 이미지에 존재하는 text를 검출하고 인식하는 것이 목적이고 (c)에서 볼 수 있듯이 일반적인 VL task와 결이 살짝 다릅니다. OCR에서는 image와 그 안에 있는 text pair를 구축하는 것이 보다 더 어렵고, cost가 더 든다는 제약이 있다고 할 수 있겠습니다.
그래서 본 논문에서는 이런 제약을 해결하기 위해 텍스트 정보를 사용해서 visual text 표현을 학습하는 OCR Contrastive Language-Image Pre-training (oCLIP)을 제안합니다. 이 oCLIP은 기존 VLP와 다른 접근 방식을 사용합니다. Fig 1(c)에서 볼 수 있는 character-aware text encoder를 설계를 했는데 이 텍스트 인코더는 기존 VLP에서의 text encoder와 달리 각 text instance의 character(문자) 순서를 인코딩해서 language feature를 추출하는 인코더입니다. 이 인코더는 이미지 내의 다른 text instance들 간의 관계를 고려하지 않습니다. 즉, 각 text instance들이 독립적으로 인코딩되고 이로써 다른 text와 무관한, 관련이 없는 text들이 학습에 방해되지 않도록 하고자 하였습니다. 이 점은 앞서 말한 첫 번째 제약 조건을 해결하기 위해 제안된 점입니다.
또, visual-textual decoder를 제안해서 입력 이미지와 라벨이 있는 특정 text instance들 간의 relation을 보도록 하였습니다. 다시 말해 이미지 내의 모든 text를 대상으로 하는 것이 아니라 라벨이 있는 text instance간의 관계만 보겠다는 것인데, 이는 앞선 annotation할 때 cost가 든다는 두 번째 제약 조건을 해결하기 위헤 제안된 것입니다. 이 인코더 디코더 설계를 통해서 모델이 weakly-annotated data(text의 box없이 text instance만 label이 있는 경우)로부터도 효과적으로 visual text representation을 학습할 수 있게 됩니다.
본 논문의 contribution을 정리하자면 다음과 같습니다.
- language supervision을 사용해 효과적으로 visual-text representation을 학습할 수 있는 end2end 방식의 pre-training 네트워크 설계
- character-aware text encoder와 visual-textual decoder를 설계함으로써 text의 개별 instance 정보를 추출하고, text의 bbox 없이도 학습 가능
- 제안된 네트워크가 여러 벤치마크에서 좋은 성능 달성
2. Methodology
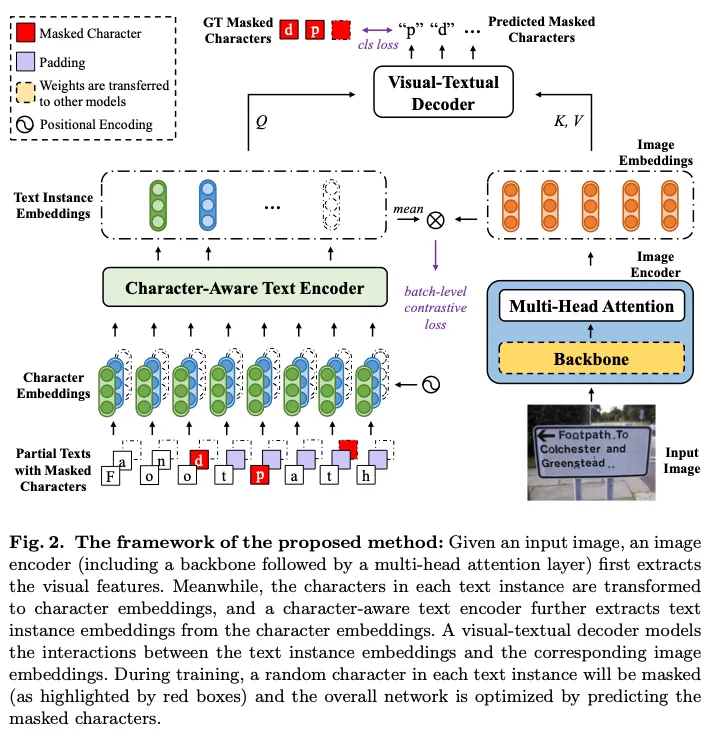
본 논문에서는 텍스트 정보와의 feature alignment를 통해 더 나은 visual representation을 학습하는 pre-training 기법을 제안하고 있습니다. 위 Fig 2에서 볼 수 있듯이 입력 영상에서 먼저 image encoder를 통해 image embedding을 추출하구요, 그 다음 character-aware text encoder를 사용해서 각 text instance의 character sequence를 인코딩해서 텍스트 정보를 추출합니다. 이렇게 추출된 visual, text feature들은 그 다음 visual-textual decoder에 들어가서 이미지의 visual feature와 개별 text instance의 feature간의 관계를 모델링하는 식으로 동작합니다. 학습시에 각 text instance에서 character를 랜덤으로 마스킹한 다음 추출된 visual text feature를 사용해 마스킹된 character가 무엇인지 prediction 하는 식으로 학습하게 됩니다. 정리하자며 Fig2에서도 보이듯이 입력 이미지에 “Footpath”, “To”, “and” 등등의 text instance가 존재하구 있구요 각 instance 예를 들어 “Footpath”에서는 p를 masking하고 “and”에서는 “d”를 마스킹하는 등 램덤으로 character를 마스킹하여 최종적으로 이 “p”, “d”를 예측하도록 하는 사전학습 방식을 제안하고 있습니다. 아래에서 논문에서 제안된 encoder, decoder에 대해 자세히 살펴보도록 하겠습니다.
2.1. Character-Aware Text Encoder
Intro에서 언급했듯이 일반적인 VL task에서는 text가 보통 text token 의 sequence로 구성된 문장 형태입니다. 따라서 VL task에서 사용되는 encoder는 이런 text를 순차적으로 인코딩할 수 있도록 설계되어 왔죠. 하지만 OCR task에서 다루는 이미지는 하나 혹은 그 이상의 text instance를 포함하는 경우가 많습니다. 근데 각 text instance 내의 token들 (즉, character) 서로 다른 text instance간의 token은 전혀 관련이 없을수도 있죠. 이런 이유로 저자는 일반적인 text encoder를 사용해서 text instance를 encoding하기는 어렵다 판단 후 character-aware text encoder를 설계하였습니다.
제안된 character-aware text encoder는 입력된 text instance를 character sequence로 간주를 하고 text instance level의 embedding을 추출합니다. 한 이미지 안에 n개의 annotation된 text T = {t_0, t_1, … t_{n-1}}가 있다고 가정한다면 각 text instance t_i는 character sequence t_i = [c_0^i, c_1^i, \dots, c_{k-1}^i]로 구성이 되겠고 각 character는 고정된 크기의 벡터로 임베딩된 후 학습된 positional encoding PE = [PE_0, PE_1, \dots, PE_k]를 추가해 각 text instance 내 문자들의 sequential한 정보를 반영합니다. 수식으로 표현하자면 아래 식1고 ㅏ같습니다.
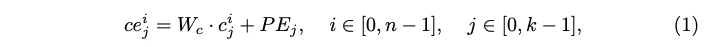
식에서 W_c는 character embedding입니다. i번째 text instance의 인코딩된 character embedding ce_i = [ce_0^i, ce_1^i, \dots, ce_{k-1}^i]은 transformer encoder로 들어가서 해당 text instance 내의 모든 character 간의 relation을 modeling한 후 이로부터 text instance emedding te_i을 추출해냅니다. 결과적으로, character-aware text encoder는 annotation이 되어 있는 text instance t = \{t_0, t_1, \dots, t_{n-1}\}에서 text instance embedding te = \{te_0, te_1, \dots, te_{n-1}\}을 추출하는 것이죠.

방금 설명한 character-aware text encoder는 text instance 쌍 간의 관계는 무시하는 인코딩 방식이었습니다. 위 Fig3은 image encoder의 attention layer에서 얻은 attention map을 시각화 한 것입니다. 보시면 일반적인 text encoder에서 text 정보를 추출하게 되면 모델이 text instance의 일부에만 attention합니다. 왼쪽이 입력 영상이고 가운데 사진들이 그에 해당하는데 예를 들어 ‘Footpath’라는 단어에서 ‘Foo’와 ‘th’에만 attention이 되어 있는데, 이는 일반적인 text encoder의 token이 여러 문자를 포함하고 있기 때문입니다. 그래서 모델이 recognition할 때 해당 text token에 가장 중요한 부분에만 집중하는 경향을 보이게 되죠. 반면에 본 논문에서 제안된 text encoder는 character level로 text를 encoding하기 때문에 image내의 모든 text 영역에 더 고르게 attention된 것을 볼 수 있습니다.
2.2. Visual-Textual Decoder
다음으로 제안된 visual-textual decoder에 대해 살펴보도록 하겠습니다. 기존 scene text pre-training방식은 모든 text instance에 대해서 bbox나 text label이 포함되어 있는 fully-annotated 데이터가 필요했습니다. 하지만 이런 annotation 작업은 cost가 너무 크도 데이터 자체를 모으기 어려운 경우가 많습니다. 이런 문제를 해결하기 위해 제안된 것이 visual-textual decoder입니다. 이 decoder는 입력 영상과 annotation이 달린 text instance간의 iteraction만을 모델링하고 annotation되어 있지 않은 text는 무시하도록 설계되었습니다. 이를 통해서 이미지 내의 일부 text에만 어노테이션된 경우에도 학습이 가능하죠.
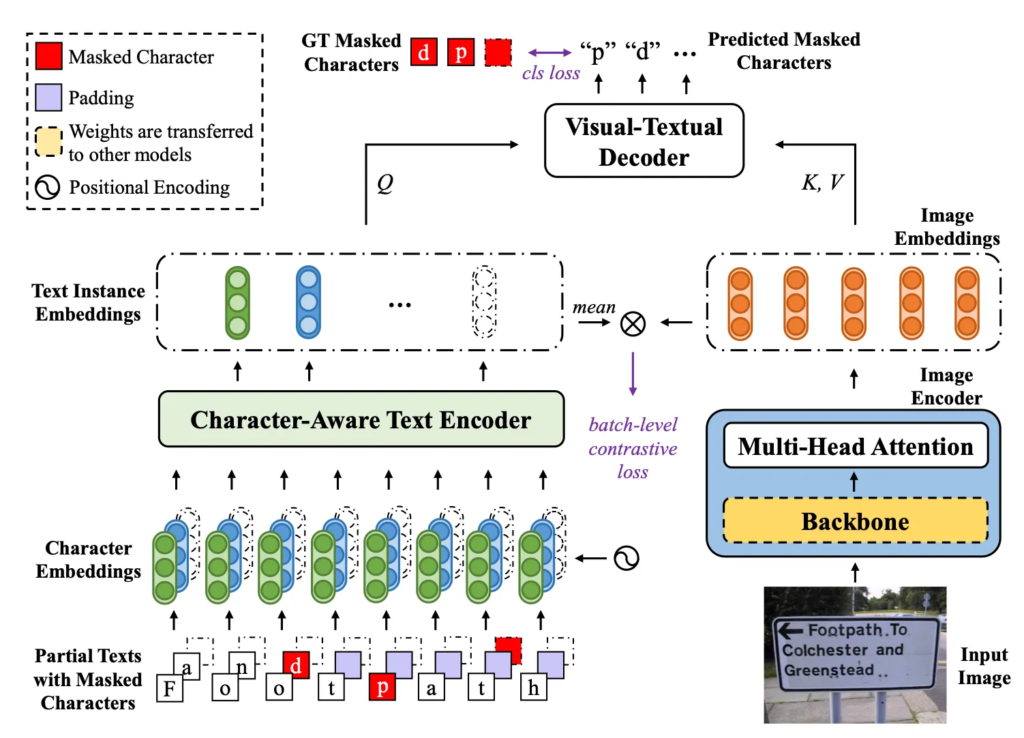
Fig2를 다시 끌고 오긴했습니다만, 보시면 입력 영상 I가 주어졌을 때 먼저 image encoder를 통해 image embedding ie을 뽑고 character-aware text encoder를 통해 text embedding te을 추출합니다. Visual-textual decoder는 이 ie와 te간의 relation을 학습해 visual representation을 향상하도록 학습되는데요. 구체적으로 text embedding te는 쿼리로, image embedding ie는 key value로 transformer decoder layer로 들어가게 됩니다. 이를 통해 각 text instance가 영상의 모든 위치에 attention하도록 한 것이죠. 이 때 self-attention layer를 제거해서 text instance간의 relation을 무시하고 주석이 없는 text의 영향을 받지 않도록 하였습니다. 최종적으로 이 visual-textual decoder는 학습하면서 각 text instance에서 masking되어 있는 character를 prediction하도록 학습됩니다.
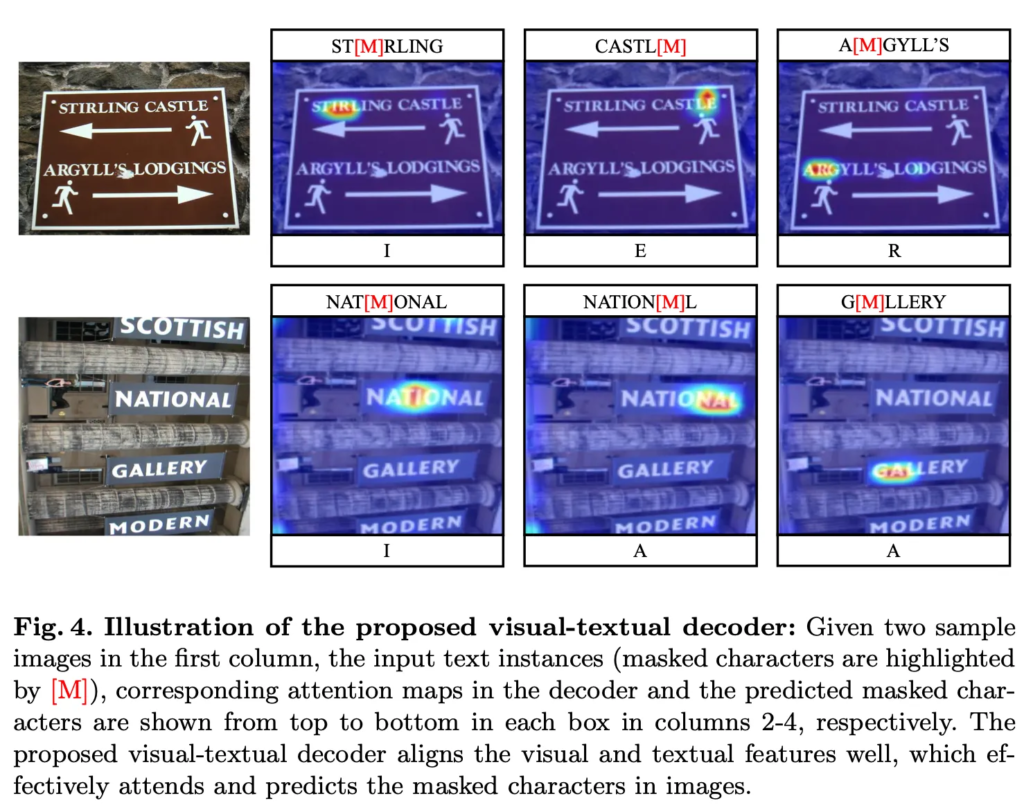
Fig4에서는 제안된 visual-textual decoder를 사용했을 경우의 attention map을 시각화해서 보여주고 있습니다. 보시면 attention된 부분이 masking 처리를 한 character의 부분이구요 보시면 ‘ST[M]RLING’에서 [M]이 mask category인데 여기 들어갈 I를 잘 prediction하고 있습니다. 이 그림에서 볼 수 있듯이 visual-textual decoder는 masking된 문자를 예측할 뿐만 아니라 이미지 내에서 해당 masking된 문자와 관련된 영역에 attention된 것을 볼 수 있는데 이를 통해 제안된 decoder가 visual 및 textual feature의 align을 맞춰서 masking 된 문자를 prediction함으로써 단순히 text 정보만을 사용하는 것보다 더 정확히 prediction할 수 있음을 보여줍니다.
2.3. Network Optimization
마지막으로 loss에 대해 살펴보겠습니다. 제안된 모델은 masking된 character가 포함된 text instance T와 image I를 입력으로 받아서 masking된 문자를 prediction한 결과를 optimization하는데, 이 masking된 character prediction을 classification task로 간주하고 cross entropy loss를 사용하였습니다.
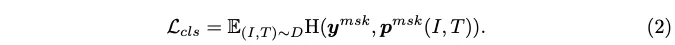
또, CLIP을 참고해서 batch level의 contrastive loss를 사용하였는데, train batch에서 N개의 이미지와 N개의 text가 주어지면, 모든 text와 image간의 N^2개의 (text, image) 쌍을 구성한 다음 N개의 쌍은 서로 매칭된 text와 image(positive)이고 나머지 N^2 - N 쌍은 관련이 없는 쌍(negative)입니다. 아래 식3과 같이 각 image와 text에 대해 softmax로 정규화 된 image-text, text-image similarity를 계산을 하구요
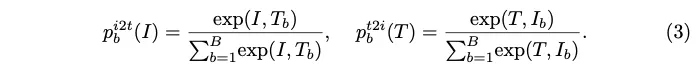
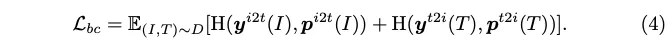
모델이 positive parit에서는 높은 similarity를, negative parit에서는 낮은 simialrity를 갖도록 학습합니다.
최종 loss는 아래와같이 classification loss와 batch level의 contrastive loss를 더한 것입니다.
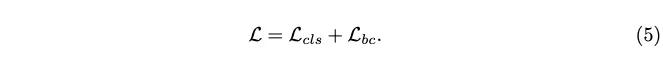
3. Experiments
Weakly Supervised Pre-training
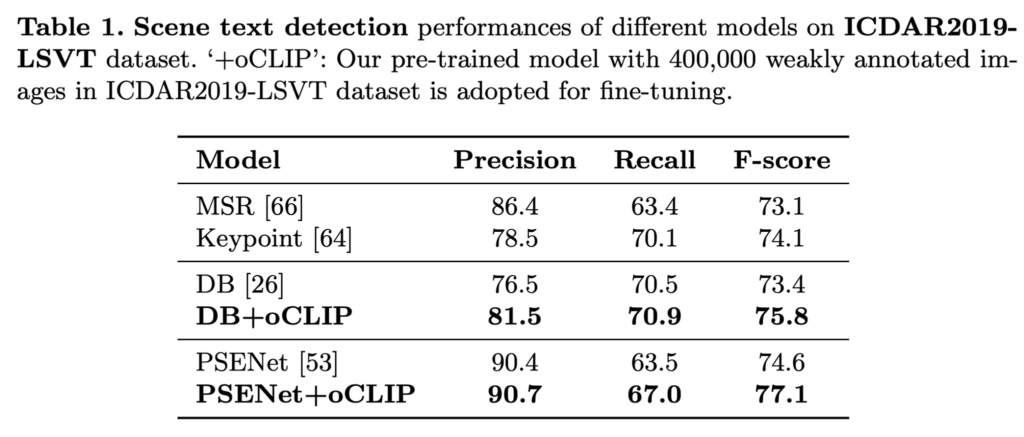
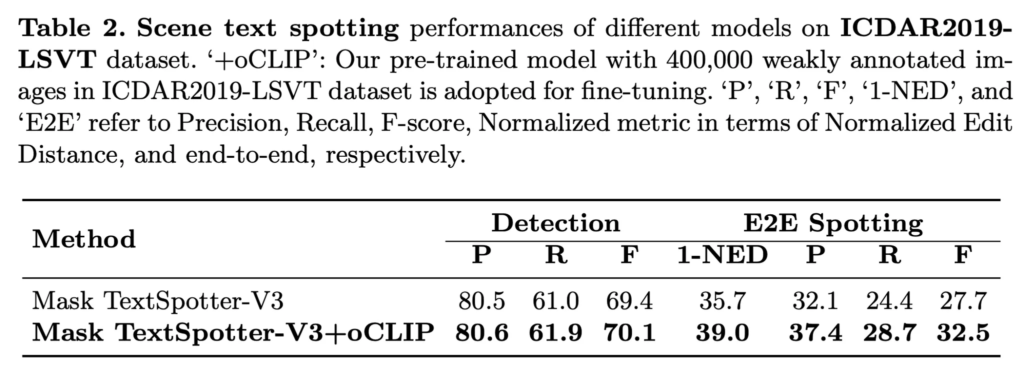
실험 부분입니다. 먼저 저자는 weakly annotated data에서 visual text representation을 학습하는데 있어서 제안된 방식의 성능을 평가했습니다. 먼저 weakly annotated된 40만 개의 image, 즉 한 이미지 내에 존재하는 모든 text에 대해서 어노테이션이 되어 있는 것이 아닌 일부만 되어 있는 40만개의 데이터로 모델을 pre-training한 후에 fully-annotated 데이터셋인 ICDAR2019로 detection과 spotting을 fine-tuning하였습니다. 결과가 위 table1, 2에서 나와있는데 table1이 detection 성능이구요 아래 table2가 recognition까지 수행한 e2e 결과입니다. 보시면 제안된 방식이 다른 기존 방식에 붙였을 때 조금의 성능 향상이 있는 것을 보이며 이런 weakly annotated data로부터 visual representation을 효과적으로 학습함을 시사합니다. 저자는 여기서 기존의 대부분 방식은 fully annotated image를 기반으로 pre-training을 하도록 설계되어 있기에 많은 양의 weakly annotated data를 제대로 사용하지 못한다는 점을 강조하고 있습니다.
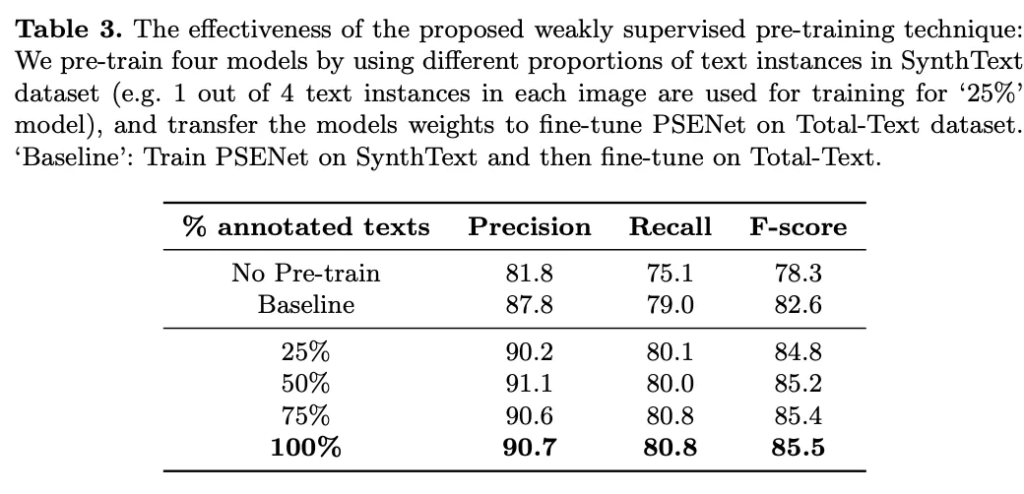
또, 저자는 SynthText 데이터셋을 사용해서 annotation된 text의 양이 모델의 성능에 미치는 영향을 확인하는 실험을 수행했습니다. 각 image에서 text instance의 25%, 50%, 75%, 100%를 random으로 선택해서 4가지의 annotation set을 구성을 했는데, 25%란 말은 한 이미지에 4개의 text가 들어 있다면 이 중 1개를 사용하여 학습한 것을 의미합니다. 먼저 사전 학습을 수행하지 않은 No pre-train 모델과 그냥 일반 pre-training방식을 사용해서 사전학습한 Baseline의 성능은 각각 78.3%와 82.6%입니다. 그 다음 제안된 방식을 사용하여 pre-training을 하는 모델 성능의 경우 25%에서 100%로 anntated 양이 늘어날수록 성능 향상을 보이며 기존 baseline과 비교해봤을 때도 25%만 사용한 경우가 더 높은 것을 볼 수 있습니다.
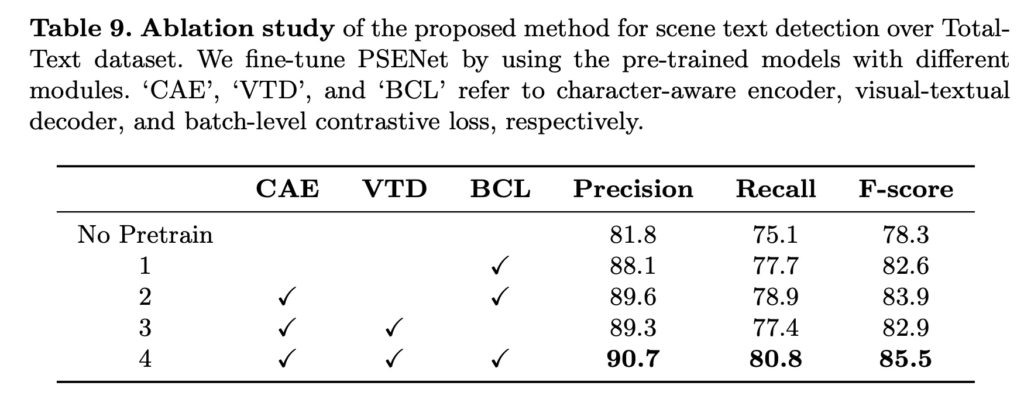
Table 9는 저자가 제안한 character-aware encoder인 CAE, visual-textual decoder VTD, batch-level contrastive loss BCL을 사용했을 때와 사용하지 않았을 때의 성능을 본 ablation study 실험 표입니다. 보시면 당연하게도 세 가지를 다 사용한 경우 성능이 85.5 F-score로 pre-train안했을 때의 성능 78.3보다 8.2의 성능 향상을 보이며 가장 높은 것을 확인할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
제안된 학습 방식이 랜덤으로 마스킹한 글자를 예측하는 식으로 동작하는것 같은데 이때 한 단어당 하나의 문자만 마스킹하도록 한 이유가 언급되어 있나요? 추가로, 제안된 디코더가 어노테이션이 되어 있지 않은 텍스트가 함께 존재하는 경우에도 무시하도록 함으로써 잘 동작한다고 하셨는데, 오히려 이런 점이 학습에 방해는 되지 않는지 궁금합니다.
안녕하세요 좋은 리뷰 감사합니다.
디코더쪽에서 self attention을 제거하여 text instance간의 관계를 일부러 모델링하지 않는 것으로 이해했는데 이에 대한 실험은 없는것인가요? 말씀해주신대로 한 이미지 내엔 관계 있는 애들도, 없는 애들도 고루 존재할 것 같긴한데 아무래도 한 이미지 내에는 서로 같은 맥락을 공유하는 택스트들이 많이 라벨링되어있지 않을까 싶어 여쭤보았습니다.