안녕하세요. 이번 리뷰는 24년 7월, arXiv에 공개된 depth estimation에 관한 논문입니다. 본 논문을 읽게 된 계기는 제가 주 담당자로 활동하는 센서 과제와 관련이 있는데, 해당 과제에서는 “무인이동체 운용 중, 이동장애물을 회피하기 위해 해당 장애물의 3차원 위치를 탐지”함을 목표로 합니다. 이 때 요구되는 사항은 3차원 위치이나, 3차원 위치를 토대로 시간 진행에 따른 장애물의 위치 변화를 알아내기 위함이므로 3d detection 태스크가 이상적이기는 하나, 그 속도가 느려 문제가 된다는 한계점이 존재합니다. 따라서 저희 연구실에서는 2.5d detection을 통해 속도의 한계를 극복하고자 하는데, 이 때 활용되는 입력은 rgb 이미지와 stereo depth 이미지가 존재합니다. stereo depth 이미지는 disparity 기반으로 생성되어 비교적 정확한 depth를 포함하는데, 두 이미지를 입력 받은 모델은 객체와, 객체에 해당하는 한 지점의 depth를 출력합니다.
이 때, 하나 고민하는 점은 “과연 입력 영상이 되는 rgb와 stereo depth 간 alignment(calibration)이 잘 되어있다는 보장이 있을까?”입니다. 즉, 두 영상의 정합이 올바르지 않다면 모델의 입장에서는 객체의 정확한 위치를 알아내기 매우 어려워지며, 또한 내부적으로 stereo depth 영상이 존재하나 depth를 예측한다는 의미에 대한 추가적인 해석이 필요하게 됩니다. 그렇다보니, 저는 단일 rgb 이미지만으로 depth estimation을 수행하는 연구가 존재하지 않을까 생각을 했는데, 우리가 잘 아는 depth anything과 같은 foundation model 기반의 depth estimation은 “relative” depth estimation에 해당합니다. depth estimation에 대해 저 또한 논문은 처음 읽어보기에 개념이 확립되어 있지 않은 분이 또 있으리라 생각하는데, depth estimation에서는 본 논문의 제목과 같이 “relative”와 “metric” depth estimation이 존재합니다.
“relative” depth estimation은 한 마디로, “나와 저 두 사람 (A,B) 간의 정확한 거리는 모르겠으나, 적어도 A가 B보다 가까이 있는 것을 예측”하는 태스크입니다. 즉, rgb 영상을 입력받아 영상 내 모든 픽셀들에 대해 상대적으로 가까운 지, 먼 지를 예측하게 됩니다. 반면, “metric’ depth estimation은 앞서 말한 제 과제에 핵심이 되는 “나와 저 두 사람 간의 정확한 depth를 예측”하는 태스크입니다. 이 때 정확하다는 의미는, 영어로는 metric scale, 한국어로는 미터법 단위로 즉 1M, 2M, 또는 10CM 단위까지, CM 혹은 M 단위의 실제 depth를 정확히 예측함을 의미합니다. 이 때 우리가 잘 알고 있는 바, 그러니 urp 시절의 calibration 주차를 떠올려 보겠습니다. 우리는 왼쪽 눈과 오른쪽 눈의 시차를 활용하여 객체와의 거리를 유추할 수 있습니다. 이 때 왼쪽 눈과 오른쪽 눈을 카메라에 비유한다면, 그 둘 사이의 거리 (baseline)을 활용한다면 객체와의 미터법 단위의 거리를 알아낼 수 있습니다. 하지만 만약 우리가 한쪽 눈 밖에 없다면, 그리고 하나의 카메라 밖에 없다면, 객체와의 실제 거리를 알아내기 위해서는 수학적으로 CM,M의 모델링이 필요한데 (두 카메라에서는 두 카메라 간의 거리가 CM,M로 표현되므로 수학적으로 모델링할 수 있었죠), 그렇지 않으니 이론적으로는 불가능한 일입니다. 하지만, 하나의 눈만으로도 두 객체 중 어느 객체가 나와 가까운지, 그렇지 않은지에 대한 정보는 인간의 일반적인 지식을 활용하여 유추해낼 수 있습니다.
이전의 연구들도 동일합니다. metric scale depth estimation을 위해서는 단일 rgb 이미지만으로는 힘듭니다. 이 때 필요한 정보는 위 문단에서 언급한 바와 같이 CM, M의 모델링을 위한 baseline, 또는 focal length, 그 외의 정보들을 활용할 수도 있겠죠. 즉, 이전의 방식들은 100% 정확하다 보장하긴 힘들더라도, relative depth estimation 이후 카메라 내/외부 파라미터를 활용하여 또는 정확한 거리의 지표가 되는 한 지점/객체를 활용하여 상대적 거리를 절대적 거리 스케일로 변환하는 작업을 진행하게 됩니다. 이 때 변환된다는 의미는 영어로 곧 “scale”을 의미합니다. 내 바로 앞의 물컵이 1M 거리에 있는 것을 안다면, 뒤의 아이패드가 물컵보다 2배 멀리 있다는 의미는 곧 2M 거리에 존재함을 알 수 있고, 그렇게 모든 픽셀 단위로 예측할 수 있죠. 이 scale이란 단어는 본 논문에 대한 설명에서도 핵심이 됩니다. 저 또한 depth estimation 논문은 처음이라, 여러 구글링을 통해 개념을 찾아보며 리뷰를 작성하는데, 부족한 점이 있지 않을까 걱정이네요. 이제 인트로덕션을 살펴보겠습니다.
인트로덕션
결국 핵심은 multi-view stereo에 비해, 단일 이미지로 수행하는 single-image depth estimation (SIDE)는 분명 활용성이 더 무궁무진합니다. 동일한 출력에 하나의 입력만 필요로 한다는데, 그 이점은 말하지 않아도 다들 아시리라 생각합니다. 하지만 multi-view stereo에 비해 저조한 성능을 보일 수 밖에 없습니다. 이유는 multi-view stereo에서는 geometric constraints, 즉 기하학적 제약이 존재합니다. 이 때의 제약은 연관성으로, 바로 위 단락에서 말씀드린 “양안으로 물체의 거리를 추정하는 방법”에 해당하는 그 이점들을 의미합니다. 저자는 multi-view stereo에 비해 SIDE를 ill-posed problem이라 표현합니다. (ill-posed problem에 대해 찾아보았는데, 이렇게 표현함이 참 한 단어만으로 이해가 잘 되는, 예쁩니다)
learning-based, 딥러닝이 소개된 이후 SIDE를 위해 두 방식으로 나뉩니다. 앞서 설명한 relative depth estimation (RDE)와 metric depth estimation (MDE)로, RDE는 “scale”에 독립적인 상대적 거리를 추출하지만 이는 실 생활 활용성이 MDE보다는 분명 저조하게 됩니다. RDE가 적용되기 어려운 태스크가 바로 요즘 뜨거운 화두의 robot grasping, 또는 이번 과제에서 요구되는 obstacle avoidance (장애물 회피)입니다. 이 외에도 존재하지만, 위 두 태스크는 객체와의 정확한 거리를 앎이 매우 중요합니다.
MDE 방법론들은 전통적으로 단일 image-depth 쌍의 이미지 데이터로부터 학습하여, 각 픽셀에 대한 metric depth를 regression합니다. 아주 쉬운 예시로, 픽셀들에 대응되는 feature map을 HW \times 1 로 projection하는 MLP를 통과한 이후, 말 그대로 각 픽셀들에 대해 gt와 regression 방식으로 학습시킨다는 개념으로, 우리가 알 수 있는 바는 “학습을 위한 명확한 supervision(또는 학습 신호)”가 존재하지 않습니다. 속된 말로, “모델아 해줘”죠. 또한 이들 방법은 indoor와 outdoor에 대한 scale의 차이에 대해 무지합니다. 해당 내용은 아래에서 다시 살펴보죠. 이후 등장한 방법은 depth를 histogram의 bin과 같이 이산화시켜 각 depth bin을 예측하도록 함입니다. 우리가 잘 생각해보면 min-max가 0~10으로 표현될 때, 각각을 정확한 depth로 regression하여 학습함보다 0~1, 1~2, ..와 같이 bin으로 나누어 해당 bin에 포함될 확률로 변환하여 학습한다면 근처 또는 다른 위치의 픽셀과 연관하여 학습할 수 있으므로 조금 더 정확한 분류 signal을 받을 수 있죠. 하지만 이 또한 직전에서 말한 “indoor와 outdoor 간 scale이 다름”에는 대응하기 어렵습니다.
이후, depth estimation 연구를 한다면 모두가 아는 Zoedepth에서는 indoor과 outdoor의 depth prediction을 각각 수행하도록 하는 prediction head를 둡니다. 또 다른 연구에서는 가장 확실하게끔 카메라 파라미터를 입력으로 주어 scale의 모호함을 풀거나, 다양한 시나리오를 품은 단일이 아닌 다중(indoor+outdoor) 데이터를 활용합니다. 저자는 하지만 그들의 방법론이 모두 “scene scale”을 모델링함에 부족하다고 생각합니다. 앞서 설명드린 내용처럼, scale을 안다면 RDE를 MDE로 변환시킴은 다소 쉽습니다. 다만, 그 scale이 여태 문제였는데 이전의 방법들이 점차 “데이터 박치기공룡”으로 변화해간다는 점을 문제 삼습니다. 즉, 다른 말로는 “그 중요한 scale을 모델링하여 예측해야하는거 아니냐”는 시선입니다. arXiv에 등재된 논문이지만, 좋은 발상으로 보입니다. (저자에 대해 잠깐 찾아보았는데, 2023년부터 매년 2-3편의 탑티어 저널/학회를 1저자급에서 등재시키는 착실한 중국 청년이네요)
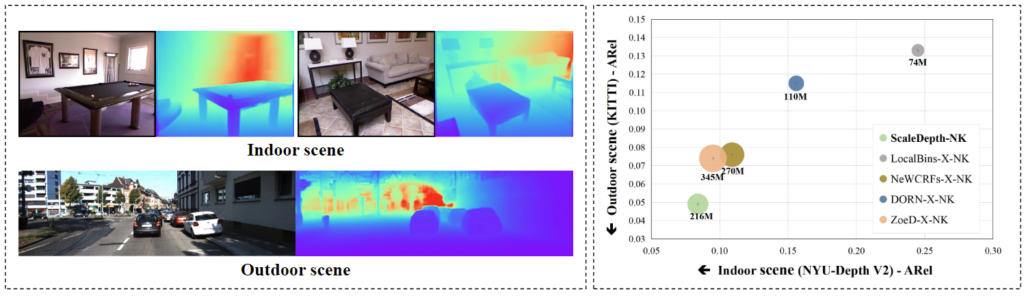
저자는 현존하는 MDE 방법들이 “다양한 range에서 정확한 depth를 예측할 수 있는 구심점”, “scene scale”의 영향력을 간과하고 있다고 꼬집는데, 조금 더 자세히 살펴보자면 (1) 우리는 scene에 대한 카테고리를 작은 범주에서는 “교실”, “행사장”, “고속도로”와 같이 또는 큰 범주에서는 “실내”, “실외”와 같이 정의할 수 있는데, 이들에 따라 depth에 대한 range (min-max 또는 객체간의)는 굉장히 크게 달라질 수 있습니다. 이 말은 반대로는 동일한 scene에서는 range에 대한 차이가 적음을 의미합니다. 아래 사진을 보시죠.

(a)에서 (e)까지, 어떤 scene인지에 따라 실 거리 차이가 달라집니다. 동일한 사진 크기로 맞추었으니, 화살표의 길이로 우리가 유추했을 때 (a)와 (b)는 물론 3차원 상 축을 고려하고서라도 유사한 화살표 길이에서 범위의 차이가 어마어마합니다 ((a)에서는 약 70M, (b)에서는 약 1M). 반면, (c)와 (d)에서는 교실이라는 동일한 공간에서 거리 범위/차이는 얼추 유사합니다. 이 차이로 인해 현존 MDE의 발전은 아직 Zoedepth의 “indoor/outdoor를 구분하여 각각 따로 진행”하는 수준에 머물러 있으며, 그러므로 만약 저자가 scene에 대한 scale을 명시적으로 모델링할 수 있다면, 이제 모델이 할 일은 단지 RDE밖에 남지 않았습니다. 그 RDE는 MDE보다 훨씬 쉬운 문제로, “데이터 박치기 공룡”의 대표적인 depth anything과 같은 foundation model이 존재합니다.
잠시 다른 이야기로 넘어와, 위 문단과 같은 문장이 “설득을 위한 논문적 문장 쓰기”의 예쁜 예시라고 생각합니다. 이런 논문의 리뷰들을 쓸 때는 항상 제가 글쓰는 방식에 대해서도 극찬하는데, 어찌되었든 아무리 좋은 방법론과 아무리 혁신적인 성능도, 그 설득력이 존재하지 않으면 코드를 제출하여 검증받지 않는 지금의 논문 시스템에서는 마치 허구, 허상과 같이 느껴지기 때문입니다.
다시 논문으로 넘어와, 그렇지만 또 단순히 scene의 카테고리에 대해서만 의존함은 scale을 알아내는데 조금 부족합니다. 그 이유는 곧 (c)와 (d)의 동일한 classroom 카테고리일지언정, 구조적으로 조금의 다름은 존재할 수 밖에 없습니다. 도장 찍어내듯 동일한 구조의 장면이 세상 어디있을까요. 그렇기에 저자는 “그들 scene 고유의 구조”에 영향을 받으며, 따라서 장면 내에서 얻을 수 있는 또 다른 추가적인 정보에 대해 고민하게 됩니다. 이가 바로 (e) Plants의 예시입니다. scene이 structural, 구조적 정보라면 semantic 정보는 객체가 될 수 있습니다. 이제 두 번째 주장 (2) 특정 장면에서, 동일한 카테고리의 객체 간 깊이가 다를 수 있음입니다. 우리가 읽을 때 이 문장은 당연하기에 해석이 어려울 수 있는데, (e) Plants의 예시에서 화분이 단 하나만 존재한다면 우리는 정확한 depth를 알아내기 위해 해당 객체 근처의 테이블, 의자와 같은 정보를 활용하기 위해 힘써야 합니다. 물론 굉장히 어렵긴 한데 한 번 이 문장을 이해해보길 바랍니다. “바로 위 만약 한 화분이 존재하는 예시는 다시 화분들이 2-3개 존재한다면, 하나의 화분의 semantic 정보를 위해 활용할 수 있는 다른 객체는 그 화분을 제외한 나머지 화분들이 될 수 있으며, 적어도 우리는 동일한 카테고리의 객체들의 정보를 활용함을 쉬운 접근법이 될 수 있습니다. 이는 마치, mask-rcnn에서 카테고리 별 mask를 예측하는 일로 치환하여 생각할 수 있으며 우리 또한 객체 카테고리에 대한 binary mask로부터 depth-related region에 대한 정보들을 알아낼 수 있습니다. 이들의 depth-related region에 대한 feature aggregating은 local한 구조를 모델링함에 도움이 되며, 또 다시 RDE에도 도움이 됩니다”. 바로 해당 문장을 이해한다면, 본 논문에서 어떤 방법론들이 활용될 지에 대한 감이 올 것입니다.바로 한 번 방법론을 살펴보죠.
방법론
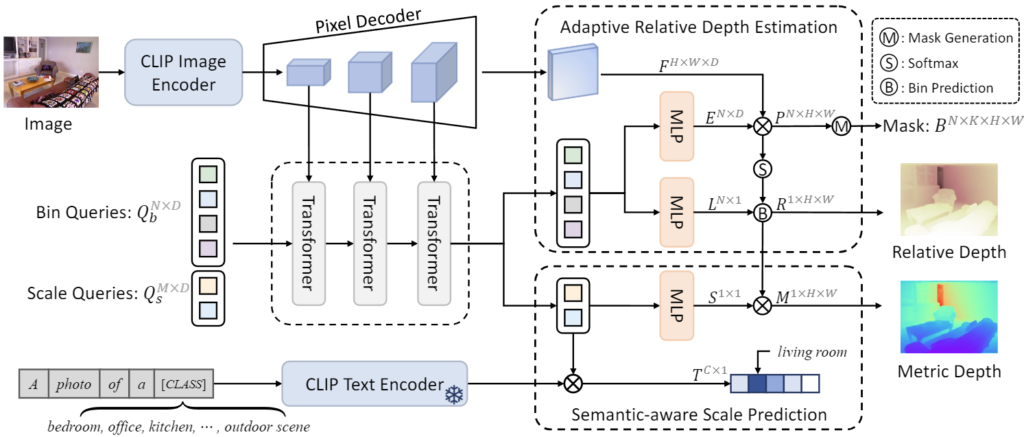
위 figure를 참조하며 전체적인 구성을 살펴보겠습니다. 위 figure를 보았을 때, CLIP이 사용되며 저자가 제안하는 Adaptive Relative Depth Estimation (ARDE)와 Semantic-aware Scale Prediction (SASP) 모듈이 존재하지만, 제 생각에서 핵심은 결국 Bin query와 Scale query입니다. 이 때의 bin과 scale은 위 단락에서 손 아프게 설명하였으니, 우리는 그들의 역할에 대해서는 잘 알고 있습니다.
우선 좌에서 우로, 전체적인 구성은 입력 rgb 단일 영상으로부터 CLIP Image Encoder를 통과시켜 multi-level features, \{F_l\}^3_{l=0} 을 추출합니다. Pixel Decoder에서는 각 feature를 project, flatten하여 각 level에서 feature vector, F \in \mathbb{R}^{HW \times D} 로 만들어 이들을 transformer layer에 입력으로 활용합니다.
여기까지는 우리가 아는 “영상으로부터 feature를 만들어, 원하는 형태로 변환시키는” 일반적인 구성이며, 이 때 transformer layer는 두 query, bin과 scale query를 활용하여 학습합니다. 본 논문명에 decomposing이 있음을 알 수 있는데, 저자는 MDE를 scale prediction과 RDE로 decomposing (분해)하기 위해 두 object query (DETR을 떠올립시다) 를 만듭니다. 자, 몇 번이나 설명하였지만 마지막으로 짚고 넘어가면 RDE에 정확한 scale이 있을 때, MDE에 대한 유추가 정확해지며 이 MDE에서의 한 방법이 RDE과 같이 픽셀 별 거리를 예측 시 histogram bin을 활용하여, 특정 bin에 포함될 확률로 치환시켜 학습한다는 방법에서 두 scale, bin이라는 단어의 개념을 다시 한 번 정립하겠습니다. scale queries, Q_s \in \mathbb{R}^{M \times D} 는 scale prediction에 관여하며 bin query, Q_b \in \mathbb{R}^{N \times D} 는 RDE에 관여하며, 이들로부터 입력받는 transformer layer는 이전 universal segmentation, omg-seg 리뷰에서 설명드린 Mask2Former의 masked attention을 활용하여 학습합니다. 자, 왜 masked attention일까요? 물론 masked attention이 masking된 영역에 대해서만 attention하여 segmentation 분야에서 특정 object에 대한 이해에 더 도움/효율적이라는 시각이 존재하지만, 본 논문의 입장에서 mask를 활용한다는 의미는 위에서 설명한 (e) Plants에서의 화분이 두/세 개 있을 때 한 화분에 대한 depth-related region을 다른 화분에서 획득할 수 있음과 관련됩니다. 즉, semantic한 정보는 RDE에서 요구되는데, 이 때 mask-rcnn에서 영감 받는 mask라는 개념이 곧 RDE에서의 객체 간 semantic 연관성을 활용할 수 있는 근거가 되기 때문입니다. 이해가 어렵다면, 위 (e) Plants 예시와 함께 설명한 문단을 다시 한 번 읽어보심을 권장합니다. 두 query는 이제, 저자가 제안하는 ARDE와 SASP 모듈을 통과하게 됩니다. 그 모듈들의 역할은 뒤에서 다시 설명드리며, 결과적으로 각 scale, bin query는 scale factor, S \in \mathbb{R}^{1 \times 1} 과 relative depth map, R \in \mathbb{R}^{1 \times H \times W} 를 예측합니다. 최종적으로, 우리가 원하는 MDE는 역시, RDE와 scale을 곱하면 얻을 수 있죠. 이는 scale이란 곧, 아주 쉬운 예로 relative depth map에서 1,2,3으로 예측되었을 때의 1이 몇 M인지를 표현하기 때문이죠. 이와 별개로, 학습 중에만 관여하는 text encoder가 활용됩니다. 이 text encoder는 어디에 쓰일까요? SASP, Semantic-Aware Scale Prediction Module에 대해 살펴보겠습니다.
Semantic-Aware Scale Prediction Module
논문 상으로는 ARDE 모듈이 앞서 오나, “왜 텍스트 정보가 필요할까?”에 대한 의문이 앞섭니다.
scale prediction, 그런데 semantic-aware를 곁들인을 위해, 모델이 global한 semantic 정보를 감지하기 위해 scene의 카테고리 정보를 활용합니다. 인트로덕션 부의 설명에서 (a)와 (b), outdoor와 indoor에서 RDE 상 유사한 거리 수준이 실제로는 얼마나 많이 다른지, 또한 동일한 classroom 카테고리에서는 유사한 거리를 보인다는 특성에 따라 scene에 대한 카테고리 정보가 중요함을 인지하였습니다. 실제로 이전의 연구, VPD 논문에서는 scene의 카테고리를 모델 입력에 직접적으로 활용하였습니다. 이와 대조적으로 저자가 제안하는 SASP 모듈은 이미지와 텍스트 정보의 유사성을 제약으로 활용하여, scale query가 해당하는 scene 카테고리의 텍스트 임베딩과 정합하도록 학습합니다. 이 접근법은 scale query가 global한 semantic 정보(scene의 카테고리)를 활용하도록 안내받으므로, 추론 시에는 scene 카테고리의 정보에 기대지 않고도 unknown 카테고리의 scene에 대해서도 일반적으로 잘 대응할 수 있습니다. 이 때 물론, CLIP을 활용하겠죠. 이는 텍스트 임베딩을 scale 예측에 직접 활용하기 보다, scale query에 대해 CLIP의 text encoder를 통과한 feature와 이전에 추출한 CLIP의 image encoder로 추출한 feature 간의 alignment를 수행함은 모델 입장에서 두 정보 (global-text, local-image)를 동시에 활용하여 도움이 됩니다.
Text-image 간 유사성을 계산하는 작업은, 우리가 이미 많이 들어 본 cosine similarity를 활용합니다. 이 과정은 scene에 대한 category, prompt를 “a photo of a [CLASS]”의 템플릿의 형태로 CLIP text encoder를 통과합니다. 이는 CLIP의 동작 과정과 동일하며, 또한 CLIP에서 하던대로 cosine similarity로 두 feature 간 유사성 점수를 내뱉습니다. 이 유사성 점수는, 다양한 scene에 대한 분류의 확률을 표현하겠죠. 그리고 이 정보는 학습 과정에서 supervised 방식으로 학습됩니다. 실험에서 저자는 28개의 scene 카테고리를 활용하였다고 하는데, 장면임을 생각하면 생각보다 많네요. 실험 파트에서 몇 개의 데이터세트를 활용한지 한 번 살펴보겠습니다.
위 과정들을 통해 scale query는 local/global한 semantic 정보를 지닌 semantic-aware scale query가 되었습니다. 저자는 이들을 projection하여 원래의 Q_s \in \mathbb{R}^{M \times D} 를 scale factor, S \in \mathbb{R}^{1 \times 1} 로 만듭니다. 이 scale factor를 활용하여, 최종적으로 metric depth map, M \in \mathbb{R}^{1 \times H \times W} 는 scale factor S, relative depth map R과 곱해진 값으로 정해집니다. 저자는 위 작업을 통해 이전의 direct method (scale에 relative depth를 곱하는, 이 때 scale은 카메라 파라미터를 통해 얻어짐), discrete regression-based method (historgram bin을 통해 relative depth map을 얻는)의 방법을 모두 활용하며, depth range (min-max)가 정해지지 않은 상황에서도 모델이 각 이미지에 대해 적응적으로 depth의 분포 및 실제 값을 예측할 수 있음을 주장합니다. 그럼 다시 돌아와, Adaptive Relative Depth Estimation (ARDE) 모듈을 살펴봅시다.
Adaptive Relative Depth Estimation Module
위 단락이 scale factor, S를 얻는 과정이였다면, 이번에 소개드릴 ARDE 모듈은 각 이미지에 대해 모델이 적응적인 relative depth map을 예측하는 방식입니다. 앞선 모델의 전체적인 구성과 바로 위 단락에서 bin query에 대해 이미 언급하였는데, 이처럼 저자는 bin을 활용하는 bin-based 방식을 활용합니다. 저자는 normalized depth space를 정의합니다. 이 depth space로부터 bin을 나누게 되며, 그 때의 normalized range는 0~1로 정의합니다. 즉, 0~1 사이 몇몇의 bin으로 나누어 예를 들어 0~0.1, 0.1~0.2, …, 0.9~1의 10개의 bin으로 나누어 각 relative depth value가 10개 중 어떤 bin에 속할지를 classification 방식으로 예측하는 태스크로 치환합니다. 저자는 bin query, feature에 대해 image feature와의 유사성을 계산하여 이미지의 모든 픽셀을 bin에 대해 분류하도록 유도합니다. 이 때 mask generation을 통해 각 객체에 대한 binary attention mask도 생성하며, 이 mask(depth-related region)들도 transformer layer에 입력시켜 bin query와 image feature 간의 interaction에 관여합니다. 결과적으로, ARDE 모듈은 scale이 존재하지 않는 형태의, scale-invariant relative depth를 예측하며 그 과정에서 image feature (+mask)를 aggregation하여 다양한 depth range에 대해서도 잘 생성하는 모습을 보입니다.
bin prediction에 있어, 이산화된 bin을 각 클래스들로 고려할 때, 출력 output bin query, Q_b \in \mathbb{R}^{N \times D} 를 두 MLP에 통과시켜 bin lengths, L \in \mathbb{R}^{N \times 1} 과 bin features E \in \mathbb{R}^{N \times D}를 생성합니다. 이후, bin lengths를 normalize하여 i번째 bin에 대한 central value를 다음의 수식으로 계산합니다.
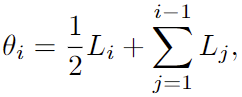
L_i 는 i번째 bin의 길이를 의미하며, 계산된 bin의 central value가 0-1의 depth space 내 relative depth의 클래스를 의미합니다. 이제 모든 픽셀들은 각각 central value들에 대해 어떤 central value, 클래스에 속할지를 예측하게 됩니다. 결과적으로 위 예측은 학습에 활용되고, 최종적으로는 relative depth map을 생성하는데 핵심이 됩니다.
이 때, 위 단락에서 mask를 활용한다는 설명을 드렸습니다. 이 attention mask 생성에 있어, depth-related regions의 feature들, bin과 image의 feature들을 aggregation하기 위해, 저자는 bin과 image feature 간 유사도에 대한 계산 (matrix multiplication)을 다음으로 연산합니다.
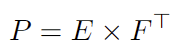
이 때 E는 bin feature, F는 (pixel decoder에서 추출한) image feature를 의미하며, 이렇게 생성된 attention mask는 모델이 ㅠbin (discrete)과 depth-related image feature의 aggregated feature에 대해 학습하게 되어, 저자는 이 때 적응적인 학습과 동시에 빠른 수렴이 가능함을 언급합니다. 아, 주의할 점은 이 attention mask는 bin query에 대해서만 작동하고 있으므로, 앞선 단락의 scale query와는 연관이 있지 않습니다. 이제 최종적으로 RDE만 남았습니다.
RDE 과정에서는 결국 bin에 대한 per-pixel classification probabilities가 연산되어야 합니다. per-pixel, 즉 이미지 (HxW)의 모든 픽셀에 대해 연산되는데, 그 때의 R은 다음의 수식으로 연산됩니다.
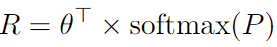
\theta^T \in \mathbb{R}^{N \times 1} 은 bin central에 해당하며, 위 문단에서 구한 P (probabilities)는 E와 F의 matrix multiplication으로 최종적으로 P \in \mathbb{R}^{N \times H \times W} 의 shape을 가지고 있으니, 이들을 곱연산하면 최종적으로 R \in \mathbb{R}^{1 \times H \times W} 의 depth map shape을 가지게 됩니다. 다시 한번 주의할 점은, 이들은 0-1의 normalized depth space 상의 relative depth map입니다. 최종적으로는 앞서 설명드린 바와 같이, 위 relative depth map에 scale factor S를 곱하면 끝!입니다.
Loss function도 그다지 어렵지 않습니다. 저자는 이미 이전에 쓰이던 Scale-Invariant (SI) loss와 CLIP에서의 Text-Image (TI) similarity loss를 동시에 활용하며 후자는 텍스트와 연관된다는 특성에서, scale query의 supervised 학습에 활용됩니다. Pixel-wise Depth Loss, SI loss에 대해서는 다음의 수식으로 구성됩니다.
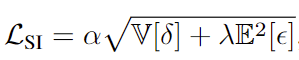
모든 픽셀에 대한 \delta 의 variance와 \epsilon의 expectation의 합으로 표현된 loss, \mathcal{L}_{SI} 는 ground truth depth와 예측된 depth 간의 차이로 표현됩니다. variance와 expectation (log)를 활용한다는 점을 제외하고선, 단순히 regression loss입니다. 이제, 실험을 살펴보겠습니다.
실험
우선, 위 loss functioni에서 눈치채셨겠지만 모델 학습을 위해서는 rgb 이미지와, (metric-scale) depth 이미지가 필요합니다. 이를 위해 데이터 세트는 indoor 환경의 NYU-Depth V2, outdoor 환경의 KITTI, 그리고 zero-shot evaluation을 위한 8가지의 unseen 데이터 세트 (SUN RGB-D, iBims-1Benchmark, DIODE Indoor, HyerSim (여기까지 indoor), Virtual KITTI 2, DDAD, DIML (Outdoor, DIODE Outdoor (여기까지 outdoor) 데이터 세트를 활용합니다. 이들에 대해서는 zero-shot evaluation을 진행하므로, depth range가 존재하지 않습니다.
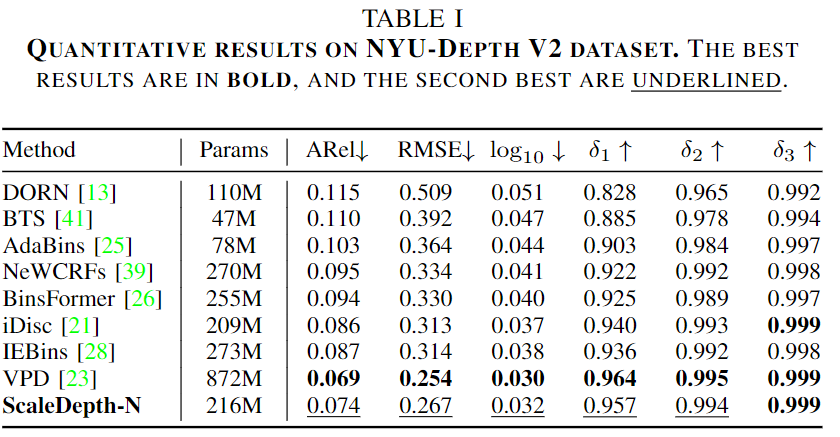
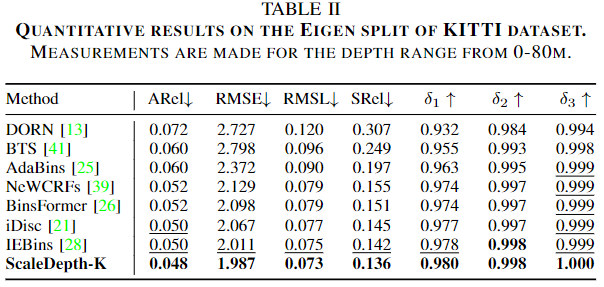
우선 NYU-Depth V2에서의 MDE 성능입니다. 저자는 해당 데이터 세트에서 10M까지를 유효한 추정 범위로 삼아, 성능을 평가하였는데 여태 MDE의 논문을 읽은 적 없는 저로써는, 해당 성능을 보았을 때, 물론 모든 방법론이 단일 이미지 기반인지는 확인하기 어려우나 전체적으로 성능이 매우 우수한 태스크구나 하는 생각이 들었습니다. 해당 결과는 80M까지를 유효한 추정 범위로 하는 다음의 KITTI에서의 성능도 동일한 경향을 보입니다.
다음으로는 저자의 의도대로, Zero-shot evaluation 성능에 대한 표입니다. 해당 표를 보면 supervised 학습 방식의 성능과는 유의미한 차이가 존재하지만, 이들은 모두 unknown scene이기에, 이들에 대해서도 일반화가 잘 되어있는 모습을 알 수 있습니다. 하지만, 표를 보았을 때 사실 다른 논문들도 대부분 잘 하네요.
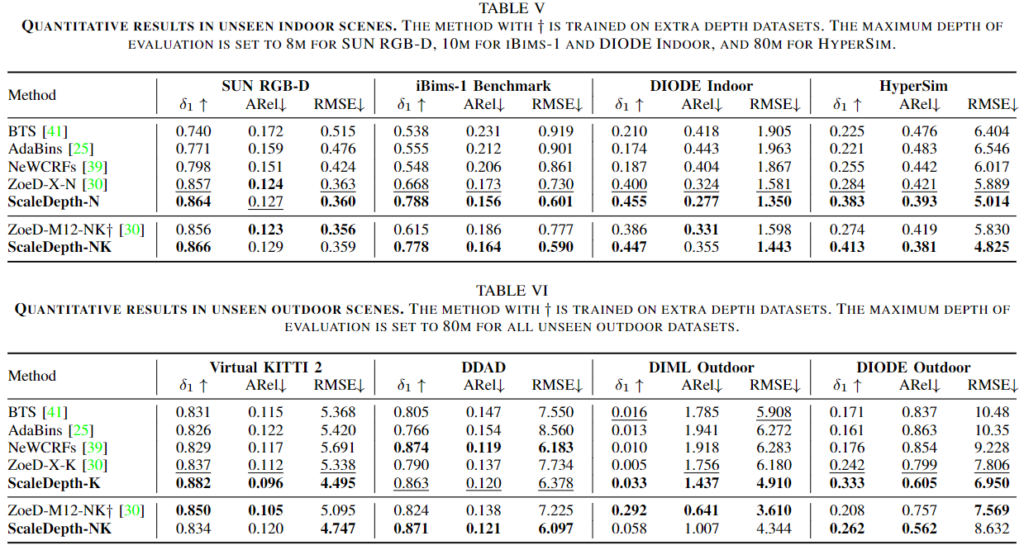
위 세 결과를, 다음의 정량적 결과로 보며 마무리하겠습니다. 본 논문 이후, Apple에서 며칠 전 발표한 DepthPro라는 논문이 있는데, 해당 논문이 MDE에 최적화된 논문으로 보여, 빠르게 읽어보아야겠습니다. 그럼, 리뷰 마치겠습니다.


RDE의 scale 문제에 관심이 많았는데 좋은 논문 리뷰 감사합니다.
몇 가지 질문 남기고 가겠습니다.
Q1. 논문의 핵심적인 컨셉이 영상 내 의미론적인 정보를 토대로 scale을 구분할 수 있다는 것이 핵심적인 컨셉인 것 같습니다만… 조금 애매한 부분이 예시의 동일한 화분이 존재하는 경우에는 설득이 되나… 동일하지 않은 객체들이 존재하는 경우에는 저자가 언급한 철학이 동작할지에 대해 의구심이 듭니다… 해당 부분에 대한 연구원님의 생각이 궁금합니다.
Q2. RDE에 대해 ill-posed problem라고 언급했으나, 대다수의 깊이 센서들은 측정 거리가 제약되어 있습니다. 또한, 먼거리를 측정한다고 하더라도 KITTI처럼 0-80m로 깊이 값을 필터링하여 사용합니다. 너무 먼 거리에서 측정된 정보는 정확도가 떨어지기도 하고, 노이즈일 가능성이 있기에 센서의 정확도가 확보되는 거리까지만 필터링하여 사용하죠. 그렇기에 RDE의 스케일 값은 필터링되는 범위를 기준으로 학습을 진행된다면 큰 문제가 없을 것 같다고 생각이 듭니다.
정리하면 RDE 알고리즘을 indoor와 outdoor에서 모두 사용하는 것이 아니라면, 타겟 깊이 센서의 깊이 범위에 맞춰서 스케일 값을 고정하여 RDE로 학습을 진행하고, RDE로 예측된 RD에 최대 깊이 범위의 값을 가하여 metric depth로 변경하면 되는 것이 아닌가 싶습니다.
질문을 다시 정리하면, 센서 과제가 특정 환경 (i.e. outdoor)과 특정 깊이 센서의 깊이 범위를 타겟으로 한다면 해당 기법이 꼭 필요한지 모르겠습니다. 해당 주장에 대한 연구원님의 반박 혹은 생각을 듣고 싶습니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
Q1. 말씀해주신 바와 같이, 한 영상 내를 기준으로 동일하지 않은 객체들이 존재하는 경우에는 저자의 주장 중 하나인 “동일한 객체에서의 연관성 정보”를 취득하기 어려우므로, 이 경우에는 원하는 대로 동작하기 어렵다고 저 또한 생각합니다. 다만, 다소 일반적인 데이터 세트들에서는 한 장면 내 동일한 객체가 둘 이상 등장하는 경우가 빈번하다는 것을 생각할 때, 위의 방식으로 학습하는 방식이 활용 시에도 도움이 될 수 있다고 생각합니다.
Q2. 말씀하신 바와 같이, RDE로 예측된 RD에 센서의 최대 깊이를 곱하는 방식을 통해 MD로 변환함도 가능합니다. 다만 센서 과제에서 고민하던 바는 “그러한 카메라 파라미터를 활용하는 방식과, 단일 RGB 영상에서 바로 MD를 추론하는 방식에서 무엇이 더 효율적일까”를 고민하고 있습니다. 본 논문은 그러면서 읽어본 하나의 논문이며, 물론 교수님과 논의 시에도 해당 방식이 실제로 활용해보고 별로다 싶으면, 전달받은 카메라 파라미터를 곱하여 활용하는 방식 또한 고려 중에 있습니다.
다만, 다음 주에 리뷰 쓰려 한 논문, 최근(10일전) 애플에서 발표한 depth-pro라는 논문이 있는데, 해당 논문도 본 논문과 같이 RGB 이미지로부터 MD를 직접 예측하는 방식인데 해당 논문이 정확도도 더 높은 것 같아 한 번 보려합니다. 감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
한가지 간단한 궁금점이 있는데, 예시로 나와있는 화분의 경우, 다중의 화분이 근처에 있다면 동일한 클래스에 대한 도움을 받을 수 있지만,, 만약 객체들이 겹쳐있는 경우나 객체 간의 거리가 꽤나 먼 경우에는 어떻게 영향을 받아 계산이 되는 건가요 ?
좋은 리뷰 감사합니다.
1. 전체 architecture 에서 clip text encoder만 freeze 이고 image encoder는 학습을 하나요? freeze(얼음결정) 표시가 없어서 질문드립니다.
2. 결국 본 논문의 핵심 contribution은 단일 rgb image 로 부터 metric depth 를 예측하기 위해 이전 VPD 논문과 유사하게 category 정보(clip)를 사용하지만, 단순 text embedding 을 그대로 사용하는 것이 아닌 더 나아가서 query를 transformer layer에 태운 feature 를 활용하여 similarity를 계산하는 것이 맞을까요?
3. text와 image의 cos sim 구하는 부분에서 계산된 pixel-level similarity 확률맵을 supervised 로 학습한다고 되어있는데, category 레벨로의 학습이라고 한다면 cross-entropy loss로 계산하는 건가요? semantic seg와 동일하게, pixel-level로 분류 loss를 계산한다는 뜻인가요?? 그러면 dataset도 pixel-level class 정보가 필요하겠군요?
4. scale query Q_s(MxD) 가 MLP 를 통과하여 갑자기 S(1×1) 이라는 값이 뙇 나오는 것으로 보여지는데, MxD를 flatten 시켜서 그냥 output channel=1로 만드는걸까요? 제 직관으로 clip은 semantic information과 관련이 있는데,,, 위 3번이 맞다면 절대적인 metric depth scale값을 학습하기 위한 명확한 signal이 존재하나? 라는 생각이 듭니다. 본 논문에서는 물론 intro에서 화분을 예시로 들면서 절대적인 depth scale 예측을 위해 semantic 정보가 필요합니다~~ 라는 식으로 서두를 깔았지만, 결국 MLP layer 하나가 scale 예측을 담당하는 것이죠? 이에 대한 학습 signal도 제 3번 질문이 맞다면 category 분류 loss에 의해 부여되는 것이구요.
(하하 질문이 좀 장황한 감이 있네요,, 그만큼 관심가지고 흥미롭게 읽었다는 뜻입니당)