
안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 2024년 CVPR workshop에서 발표된 논문으로, DETR 구조를 활용해 multispectral detection을 수행하는 모델을 제안하였습니다. 바로 리뷰 시작하도록 하겠습니다.
Introduction
Object Detection은 이제 수많은 분야에서 응용될 수 있는, 컴퓨터 비전의 보편적이고 대표적인 task 중 하나가 되었습니다. 하지만 모두 아시다시피 object detection task를 실제 환경에서 수행함에 있어 가시광선 센서를 이용한 RGB 영상만을 활용하는 것은 주변 환경의 변화(우천, 안개, 조도 변화)에 크게 영향을 받는다는 한계가 있고, 연구자들은 이를 보완하기 위해 날씨나 조도 변화에 비교적 강인한 적외선(IR) 센서를 함께 이용하고자 시도해왔습니다. 직관적으로 생각해보면 RGB와 IR 영상을 상호 보완적으로 함께 활용하는것이 정확도를 높일 것 같지만, 실제로 IR과 RGB의 feature를 효율적으로 추출 및 fusion하는데 있어 modality 간 불일치를 해결하는 것이 큰 난관입니다. 지금까지 수많은 multispectral object detection 방법론이 이 문제를 해결하기 위해 제안되었습니다. 두 모달리티를 다루기 위해 detection netowrk의 dual-branch 구조가 도입되긴 했지만 이전 방법론들은 시간적으로, 공간적으로 정렬된 IR과 RGB 영상 pair를 함께 사용해야 한다는 한계가 있었습니다(rgb-thermal 같 feature align이 잘 맞지 않으면 detection에 있어 성능 저하가 발생합니다).
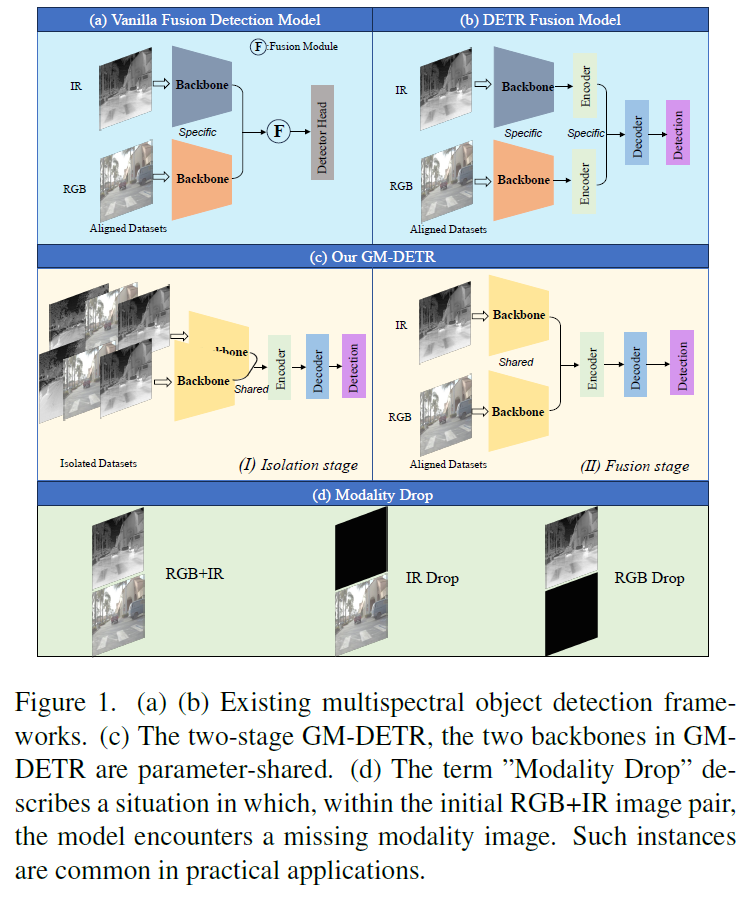
Fig1의 (a)와 (b)과 같이, 기존 방법론들은 IR과 RGB 데이터를 학습 세션에 바로 fusion하게 되는데, 이런 학습 전략을 사용하게 되면 모델이 IR-RGB의 각 modality에 대한 종합적인 이해 능력을 갖추는것이 아닌, two-stream input만을 다룰 수 있도록 그 능력이 제한된다고 합니다. fig1의 (d)와 같은 modality drop 상황에서는 single-modality dataset으로 학습된 모델보다 그 성능이 크게 떨어지는 것이죠. 저자들은 이 문제를 해결하고 각 IR 및 RGB 데이터셋을 완전히 활용하기 위해 multispectral object detection에 2단계 학습 전략을 제안합니다(Fig.1의 c). 첫번째 단계에서는 isolated dataset으로 학습하여 IR과 RGB modalities에 대해 향상된 feature를 추출할 수 있도록 합니다. 이후 두 번째 단계에서는 aligned dataset을 활용하여 fusion 학습을 하게 됩니다.
feature extraction을 위한 백본은 파라미터를 공유하게 되며, 이후 두 encoder를 사용하여 각 모달리티의 feature를 독립적으로 추출합니다. Detection task에는 DETR기반의 새로운 object detector를 사용합니다. DETR의 인코더는 백본으로부터 CNN feature를 입력받고 Transformer 구조를 활용하여 feature를 고차원 representation으로 변환합니다. 이 때 서로 다른 모달리티의 CNN feature에 self-attention을 수행하기 위해 저자들은 modality-Specific Feature Interaction(MSFI)모듈을 고안하였습니다. 이후에는 Cross-Modality-Scale feature Fusion (CMSF) module을 도입하여 IR과 RGB 모달리티로부터 추출한 정보를 통합하게 됩니다. 이런 fusion process는 mutli-scale fused feature를 출력하고, 이후 decoder에 입력되는 구조로 설계되었습니다. 전반적인 모델의 구조는 아래 method에서 더 자세하게 살펴보도록 하겠습니다.
저자가 주장하는 contribution을 요약하면 다음과 같습니다 :
- 우리는 mutispectral object detection을 위한 2-stage 학습 전략을 소개한다
- 우리는 효과적인 fusion encoder를 통해 두 모달리티를 통합하는 GM-DETR이라는 multispectral object detection 방법을 제안하였다. 여기서 MSFI 모듈은 서로 다룬 모달리티로부터 global 정보를 추출하기 위해 만들어졌고, CMSF 모듈은 모달 및 스케일 한 정보를 효율적으로 통합하기 위해 만들어졌다.
- FLIR와 LLVIP 데이터셋에서 수행한 실험에서 우리가 제안한 방법은 SOTA 방법론을 뛰어넘는다
Related Work
related work에는 multispectral object detction에 대한 내용이 소개되어 있는데, 연구실 사람들이라면 익히 알고 있을만한 내용이 소개되어 있습니다. 기본적으로 multispectrla object detection task는 적외선(IR) 및 가시광선(RGB)이미지의 fusion을 이용하고자 하는 알고리즘으로, 자율주행이나 감시 등의 응용 분야에서 연구되었으며, 현존하는 방법들은 대부분 픽셀 단위로 align된 IR / RGB 이미지 데이터를 기반으로 연구되었습니다. 데이터셋으로는 FLIR, KAIST, LLVIP를 소개하는데, 여기서 FLIR와 KAIST는 자율주행 driving scene으로 구성된 데이터셋이고 LLVIP는 감시(CCTV 뷰라고 생각하면 될 것 같네요) vision에서의 보행자 검출 다룹니다. KAIST 데이터셋은 다들 잘 아실테고, FLIR는 다른 데이터셋과 다르게 픽셀 단위 align이 잘 맞지 않는 데이터셋이라는 한계가 있습니다.
multispectral detection 알고리즘들은 기본적인 detector(Faster-RCNN, Yolo계열, RetinaNet, DETR등)를 기반으로 만들어지는데, 핵심은 IR과 RGB 두 모달리티의 정보를 어떻게 통합하는지에 있습니다. 여기서 통합이라 함은 early-fusion, mid-fusion, late-fusion 등 feature fusion을 의미합니다. early fusion은 RGB(3채널)-Thermal(1채널)을 합쳐 4채널 이미지로 만들고, 이를 기존 detection network에 입력합니다. 최근에는 IR과 RGB를 3채널 합성 이미지로 만드는세 generation 방법을 사용하기도 한다고 합니다. Mid fusion은 중간 feature layer에서 동작하는데, 두 모달리티의 상관관계를 잘 활용할 수 있는 방법으로 알려져 있습니다. Late fusion은 두 디코더의 출력을 합성하는 방법으로 추가적인 후처리 시간이 필요하다고 합니다.
기존 연구들은 어떻게 IR과 RGB 정보를 잘 합성하는지에 집중하여 연구가 진행되었는데, pixel-aligned IR,RGB 데이터셋을 이용했기에 실제 활용 시나리오 에서 발생할 수 있는 modality drop과 같은 상황에 대처하기 힘들다고 합니다.
Method
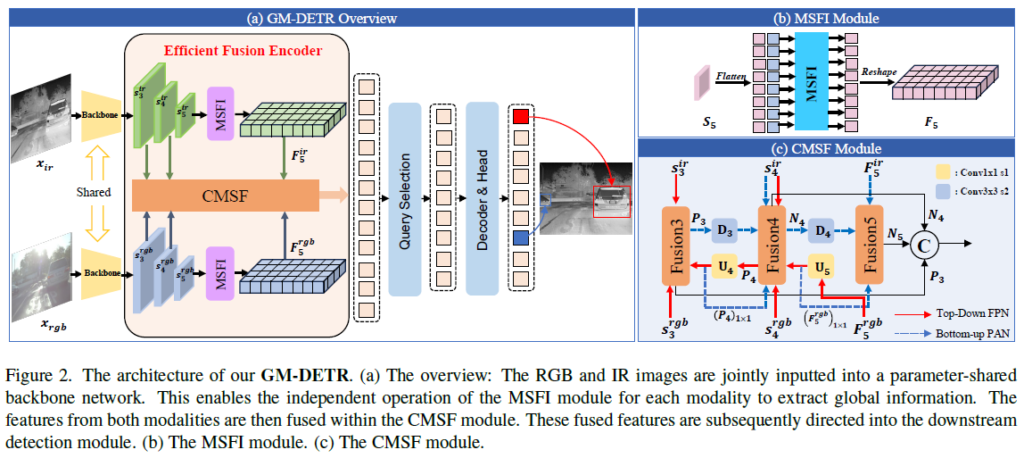
GM-DETR은 최초의 real-time으로 동작하는 DETR인 RT-DETR을 기반으로 만들어졌으며, CNN backbone 및 Transformer Decoder는 이 구조를 사용한다고 합니다. 전반적인 구조를 살펴보면 Fig.2에서 볼 수 있듯 2개의 parameter-shared backbones, efficient fusion encoder, prediction heads가 있는 Transformer decoder로 이루어졌습니다. visible, infrared image 쌍 {x_{ir}, x_{rgb}}는 파라미터를 공유하는 두 CNN 으로 입력되어 two-stream으로 특징을 추출합니다. 이후 백본의 마지막 3단계 RGB, IR feature인 {S_{3}^{ir}, S_{4}^{ir}, S_{5}^{ir}, S_{3}^{rgb}, S_{4}^{rgb}, S_{5}^{rgb}} 를 encoder의 input으로 사용되고, multi-scale multispectral feature를 통합하고 image feature sequence로 전달하기 위해 Efficient Fusion Encoder를 도입하였습니다. 이후에는 Query Selection을 통해 인코더 출력 시퀀스에서 정해진 수의 image feature를 initial target queries로 선택하게 됩니다. 이렇게 선택된 쿼리들은 디코더를 거쳐 detection 결과를 만들어내게 됩니다.
제안하는 모델의 2-stage 학습 과정은 1. Isolation stage와 2. Fusion stage 로 나뉘게 됩니다. 이 두 과정에서는 서로 2 타입의 데이터를 사용하게 되는데, Paired IR and RGB datsaets {x_{ir}, x_{rgb}, y}는 label y가 rgb,ir 이미지에 함께 사용되는 Fusion stage에 사용되고, 각각 따로 annotation된 IR 및 RGB 데이터셋 {x_{ir}, y_{ir}}, {x_{rgb}, y_{rgb}}는 Isolation stage에 사용됩니다.
Efficient Fusion Encoder
Efficient Fusion Encoder 구조는 Fig2에서 묘사된것과 같이 Modality-Specific Feature Interaction(MSFI) module과 Cross-Modality-Scale feature Fusion(CMSF) module이라는 두 모듈로 구성됩니다.
Modality-Specific Feature Interaction module (MSFI)
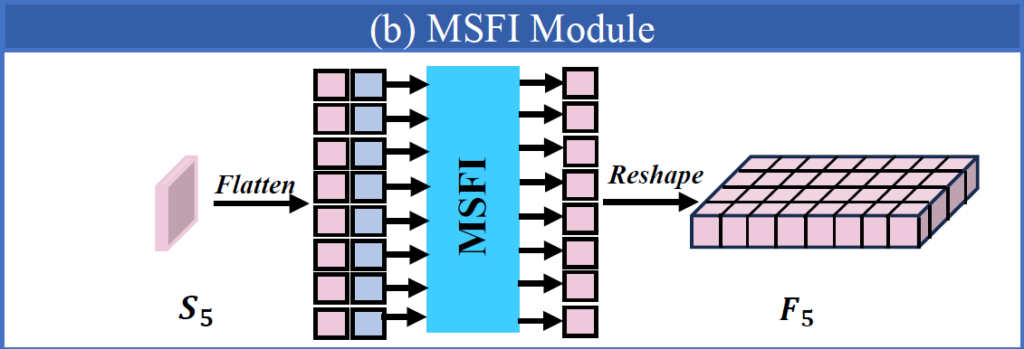
이 모듈은 풍부한 의미론적 정보를 담고 있는 고수준 feature layer인 {S_{5}^{ir}, S_{5}^{rgb}}에만 적용됩니다. 이런 high-level layers에 self-attention을 적용하는것은 이미지 내부 다양한 요소의 관계를 포착하는 능력을 향상시켜 객체를 탐지하고 인지해야 하는 이후 모듈에 도움을 줄 수 있습니다. 모듈에서 처리되는 과정은 다음과 같습니다 :
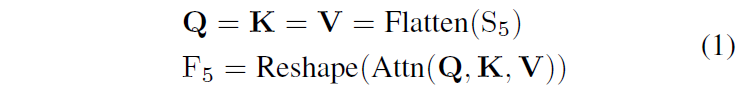
Attn은 multi-head self-attention이고, Reshape은 Flatten을 거꾸로 수행하는것이라고 생각하시면 됩니다. F_{5}의 shape은 S_{5}와 동일합니다.
Cross-Modality-Scale feature Fusion module (CMSF)
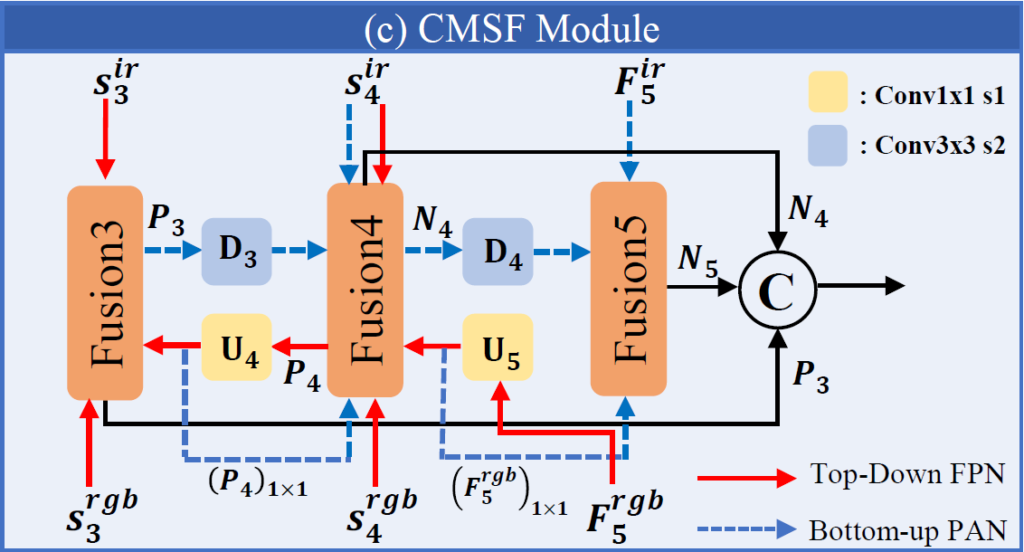
저자들은 RGB 및 IR multispectral 영상의 특성에서 영감을 얻어 cross-modality, cross-scale feature fusion을 위한 모듈을 제안합니다. 구조는 PANet 과 같은 구조를 사용하며, 1.Top-Down FPN과 2.Bottom-Up PAN이라는 두 branch로 구성됩니다. 먼저 풍부한 feature connection 정보를 가지는 F_{5}^{rgb} 를 사용해서 top-down upsampling을 수행하고 이후 IR feature들을 통합하기 위해 S_{4}^{ir}과 F_{5}^{ir}를 사용해 bottom-up downsampling을 수행합니다. 결과적으로 이 모듈에서는 RGB 및 IR 모달리티 모두의 multiscale 정보를 합성하는 feature pyramid를 만들어냅니다. FPN 처리 과정은 다음과 같이 나타낼 수 있습니다 :
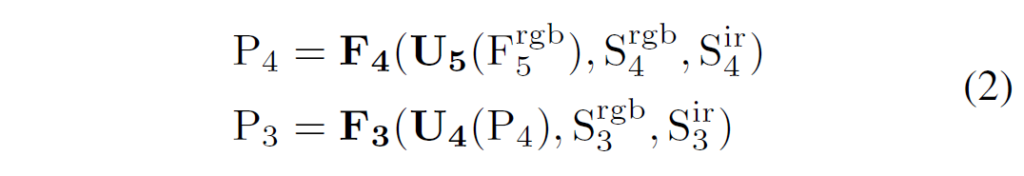
U_{4} 와 U_{5}는 둘 다 upsample 연산 이후 1×1 convolution layer가 이어지고, F_{3}(·, ·, ·)과 F_{4}(·, ·, ·)는 multi-level features를 concat하는 FPN fusion blocks입니다. 이 블럭들은 1x1conv를 사용해서 두 output path를 만들고, 이를 거친 output들은 element-wise 덧셈 연산으로 합쳐집니다.
한편, PAN process는 다음과 같이 나타낼 수 있습니다 :
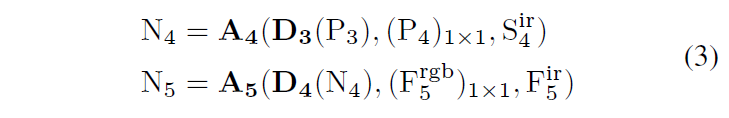
D_{3}과 D_{4}는 stride 2인 3×3 conv 연산으로 downsampling을 수행하며, A_{4}와 A_{5}는 PAN fusion block으로 위에서 설명한 FPN fusion block과 비슷합니다.
마지막으로, Efficient Fusion Encoder의 출력으로 나오는 multi-scale fused features output {P_{3}, N_{4}, N_{5}}은 RT-DETR의 Transformer decoder로 입력되어 detection을 수행합니다.
Two-Stage training
DETR의 훈련에는 많은 데이터가 필요하다고 알려져 있습니다. 하지만 multispectral object detection을 위한 데이터셋은 그 양이 많지 않죠. 이 때문에 저자들은 detection model의 RGB와 IR 모두에 대한 특징 추출 능력을 향상시키기 위해 Isolation stage를 도입했습니다. 학습은 Isolation stage와 Fusion stage 두 단계로 나눠서 진행되며, 학습 전략은 Figure 1의 (c)와 같습니다.
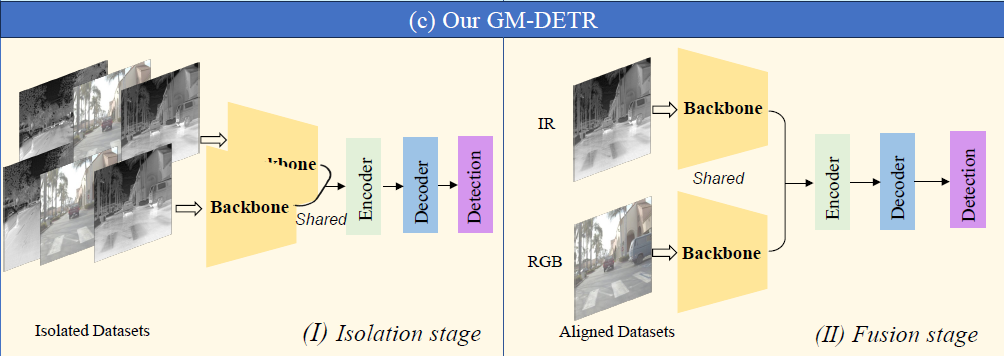
Isolation stage
Isolation stage에서 저자들은 IR과 RGB 모두에서 특징 추출을 잘 수행할 수 있게 하고자 하였습니다. 이를 위해 IR과 RGB 데이터셋을 합쳐 통합된 데이터셋을 만들어 모델의 two-stream 입력에 동일한 이미지가 복사되어 입력되게 하였습니다. 이 단계에서 사용되는 데이터는 Fusion stage에서 사용되는 데이터와는 독립적으로 align이 맞지 않는 데이터를 활용하거나, 다른 IR / RGB 데이터셋을 이용할수도 있다고 합니다. 단일 모달리티만으로 구성된 데이터를 활용할 수 있게 하여 학습 데이터 부족이라는 한계를 완화한 시도로 볼 수 있을 것 같습니다.
Fusion stage
Fusion stage는 우리에게 익숙한 일반적인 multispectral detector를 학습하는 과정입니다. 이 단계에서는 기존 multispectral 방법론들처럼 모델에 시간적, 공간적으로 aligned된 이미지 데이터를 입력하고, 모델은 학습 과정에서 RGB과 IR 데이터에 대한 공통 label y로 학습됩니다. 이 단계에서는 모델이 가시광선 및 적외선 영상으로부터 feature를 잘 fusion하여 detection을 수행할 수 있는 능력을 갖추기를 기대합니다.
Training losses
Isolation stage와 Fusion stage에서의 가장 큰 차이점은 입력 데이터 스트림이며, 수행하는 task는 object detection으로 동일합니다. 따라서 이 두 단계에서는 동일한 object detection loss를 사용합니다.
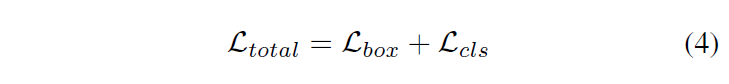
Experiment
저자들은 aligned FLIR와 LLVIP 데이터셋에서 평가를 진행했으며, 2단계 접근법의 이점을 실험하기 위해 Isolation stage에서 FLIR와 LLVIP 데이터를 합쳐서/분리해서 실험을 진행했다고 합니다.
LVIP 데이터셋은 15,488개의 aligned 이미지 pair를 제공하는 보행자 검출 데이터셋으로, driving scene이 아닌 위에서 내려다보는(CCTV 뷰와 같은) 영상으로 구성된 데이터셋입니다. FLIR 데이터셋은 본래 많은 unaligned image와 IR 이미지만을 위한 annotation을 제공하여 학습에 어려움이 있었지만 저자들은 [ICIP2020] MULTISPECTRAL FUSION FOR OBJECT DETECTION WITH CYCLIC FUSE-AND-REFINE BLOCKS 에서 제공하는 aligned version을 활용하여 5,142 이미지 쌍에서 4,129 pairs는 학습용으로, 1,013개는 평가용으로 사용햇다고 합니다. 해당 데이터셋에는 person, car, bicycle이라는 3가지 class가 있습니다. 다음 Table 1은 FLIR 데이터셋에 대한 벤치마크입니다.
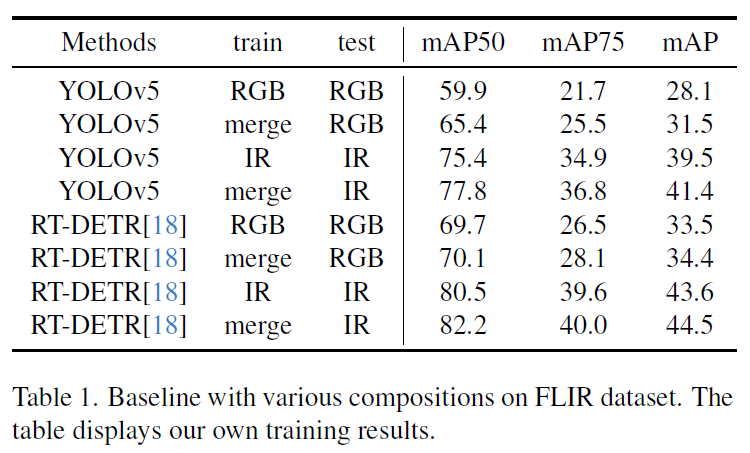
저자들은 두 모달리티 영상을 합쳐서 학습시키는게 모델에 정말로 긍정적인 영향을 미치는지 확인하기 위해 YOLOv5와 RT-DETR 모델로 merged FLIR dataset에 대해 실험을 수행하였습니다. 결과는 Table 1과 같습니다. 본래 베이스라인은 모델을 각각 IR / RGB로 학습시키도 동일 도메인 이미지로 평가를 진행한 것이고 이를 merged dataset으로 학습한 모델과 비교하였습니다. 실험 결과 전반적으로 YOLOv5보다 RT-DETR이 좋은 성능을 보였으며 train단계에서 단일 도메인만을 사용하지 않고 merged set을 활용한 것이 더 좋은 성능을 보임을 확인할 수 있습니다.
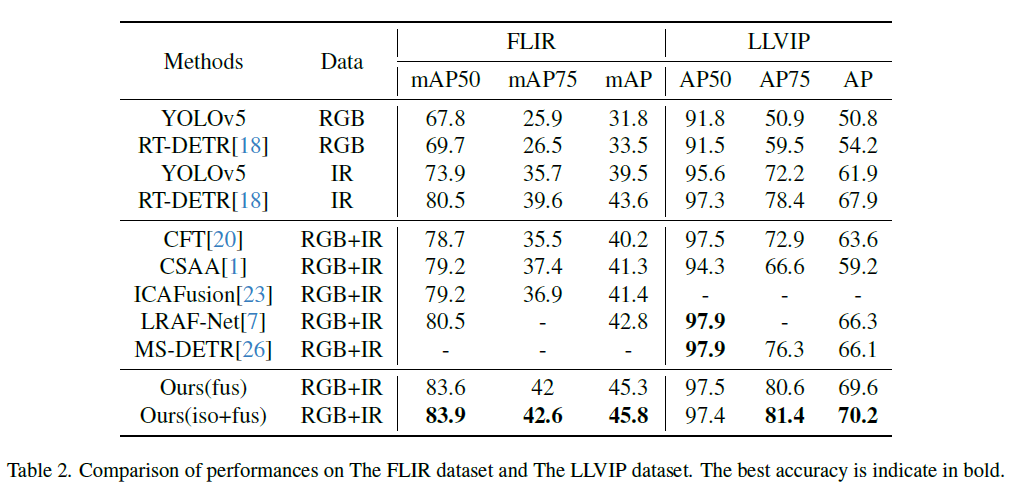
학습 데이터의 다양성을 고려해, 저자들은 두가지 학습 전략에 대해 실험을 진행했습니다. 우선 기존 연구와 유사하게 Fusion Stage로만 학습을 진행하였고(표에서 Ours(fus)로 표기), 두번째로는 학습 단계의 Isolatoin stage에서 IR와 RGB를 병합해 학습한 다음 Fusion stage에서 추가적으로 학습하여 결과를 보였습니다(표에서 Ours(iso_fus)로 표기). Table 2를 보시면 FLIR 및 LLVIP 데이터셋에 대해 저자가 제안한 방법이 기존 방법론들보다 개선된 결과를 보이거나 SOTA에 매우 근접한 성능을 내는 것을 확인할 수 있습니다. 또한 isolation stage를 추가한 것이 fusion stage로만 학습한 모델보다 개선된 성능을 보여 2-stage 학습 전략이 유효함을 확인할 수 있었습니다. 비교군에 있는 MS-DETR은 Deformable DETR 기반 multispectral detector라고 합니다.
Input Ablation study
실세계에서 multispectral detector를 사용하는 상황을 가정해보면 (센서 고장이나 occlusion 발생 등으로)모달리티 한 쪽입력이 정상적으로 들어오지 않는 상황이 발생할 수 있습니다. 저자들은 이러한 modal drop 상황에 대한 실험을 수행하였습니다. 데이터 인풋은 single modality image를 복사해서 입력하였다고 합니다.
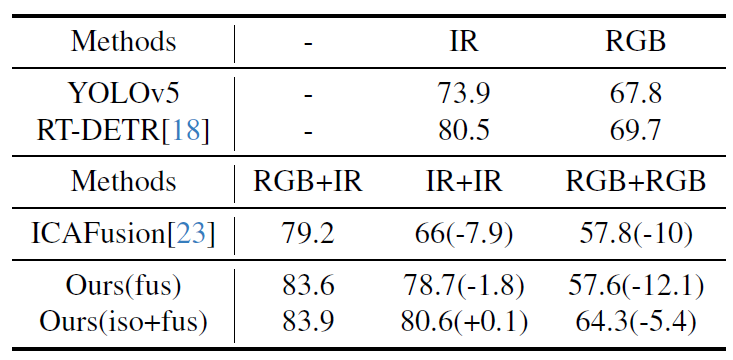
비교군으로 선정된 ICAFusion은 비슷한 문제 상황을 다루는 모델이라고 하는데, 이와 비교해 저자가 제안한 방법은 하나의 input만을 입력하였을 때 성능 저하가 비교적 적다는 것을 확인할 수 있습니다. 하지만 modality drop 상황을 가정하려면 하예 한 쪽 stream에는 완전히 블랙아웃된 이미지를 넣어야 하는 것 아닌가? 하는 생각이 드네요. 학습할 때 복사해서 학습을 했으니 당연히 평가에서도 좋은 성능을 보이지 않은것인가 하는 의문이 듭니다.
Module Ablation Study
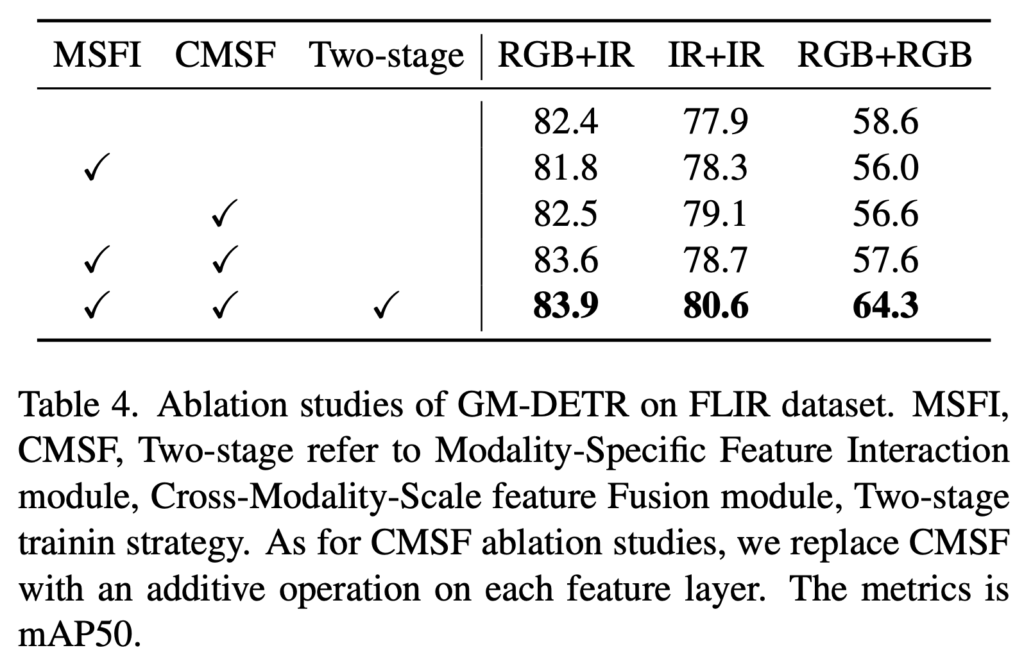
FLIR 데이터셋의 RGB+IR, RGB+RGB, IR+IR 데이터 입력을 사용해 저자가 제안하는 프레임워크의 각 모듈들에 대한 Ablation입니다. MSFI와 CMSF 모듈을 모두 사용하고, isolation stage와 fusion stage를 모두 사용하는 것이 결과적으로 모든 데이터 input에 대해 가장 좋은 성능을 내는 것을 확인할 수 있습니다.
Conclusion
DETR을 활용한 Multispectral detector가 궁금해서 읽어본 논문이었습니다. CNN backbone과 마찬가지로 2-stream input을 받고 fusion을 활용하는 구조는 동일했지만, fusion에 attention을 활용한 점이 눈에 띄었네요. 그리고 workshop 논문이라 그런지 약간 아쉬운 부분이 있긴 했습니다. modality drop issue를 언급하길래 아예 한쪽이 blackout된 상황에서 유동적으로 한쪽 input을 최대한 활용할 수 있는건가 기대했는데 그냥 동일한 input을 복사해서 detection하기에 기대했던 솔루션은 아니었습니다. 그리고 사전학습 단계에서 dataset을 통합해서 학습한 것도 그냥 학습 데이터 수를 늘려서 성능이 개선된 것이 아닌가.. 합니다. 그래도 최신 multispectral detector의 동향을 살펴볼 수 있다는 점에서 의미 있는 논문이었습니다.
감사합니다
안녕하세요 허재연 연구원님 좋은 리뷰 감사합니다.
2-stage 학습에서 Isolation 단계는 통합된 데이터셋에서 동일한 이미지가 복사되어 입력된다고 언급해주셨는데, 결국 같은 이미지 2개를 입력으로 넣어주는 것을 의미하나요? 만약에 동일한 이미지 2개를 넣는 것이라면 cross-modality, cross-scale feature fusion이 큰 효과를 보지 못할 것으로 예상되어 fusion stage에서의 학습에 의존할 것 같은데 흥미롭네요. 재연님이 experiment에서 언급해주신것처럼 image 하나와 blackout된 이미지를 활용하는 modality drop 상황(Figure 1. (d))에서의 학습 혹은 평가는 없는 건지 궁금합니다. 또 isolation stage와 fusion stage에서의 두번의 학습이 isolation -> fusion 혹은 fusion -> isolation 과 같이 학습하는 순서에 따른 성능 차이가 있는지 궁금합니다.
감사합니다.
결론부터 말하면 isolation stage에서는 동일한 이미지를 복사해서 같은 이미지 2개를 넣어주는게 맞습니다. RGB-IR 도메인 간 feature fusion 능력은 이 이후인 fusion stage에서 확보한다고 이해하는게 좋을 것 같습니다. 이 이외에 modality drop을 가정한 추가적인 실험은 없습니다.
stage간 순서에 대해서는 아무래도 isolation stage가 1.multispectral dataset이 너무 작음 + 2.modality drop에 대비해야 함 이 두가지 이슈에 대한 사전학습 느낌이라 fusion stage를 먼저 시도한 실험은 없었습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
리뷰에서 본 논문이 “기존 방법론을 사용하게 되면 모델이 IR-RGB의 각 modality에 대한 종합적인 이해 능력을 갖추는것이 아닌, two-stream input만을 다룰 수 있도록 그 능력이 제한된다고 한다”고 소개해주셨는데, 여기서 종합적인 이해 능력의 의미가 궁금합니다.
제 이해가 부족했는지 모르겠지만, 본 논문을 간단하게 요약하면 기존 fusion 방법론이 modality drop 상황에 취약하니, 모든 모달리티의 데이터셋을 활용해 pretrain한 backbone을 사용하므로서 이를 해결한 것으로 이해했습니다.
여기서 걱정이 되는것은, 제안한 방식으로 학습하면 두 모달리티의 상호보완적 정보가 아닌, 두 모달리티의 공유되는 정보에만 집중되도록 학습되는 것이 아닐까? 하는 걱정이 듭니다. 즉, 상호보완적 정보를 잘 이용해 모달리티간의 정보를 종합적으로 고려할 수 있는 모델이 아니라 공통된 소량의 정보(라인 등)에만 집중하여 modality drop 상황만을 잘 해결하는 모델 설계가 아닐까 걱정됩니다.
물론 Table2가 제안한 방법론이 제안한 퓨전 방법이 효과 있음을 보이는 증거가 될 수 있겠지만, 제시한 성능이 랜덤성 등을 고려했을때 명확한 증거가 될 수 있는 정도인지 궁금합니다. 밤/낮 상황을 모두 다른 데이터셋을 통한 성능평가가 퓨전의 효과를 볼 수 있는 좋은 세팅 중 하나라고 생각되는데, 퓨전 자체의 효과를 분석할만한 정보가 더 있을까요?
둘쨰 질문으로는 FLIR에 대한 alignment 를 어떻게 해결했는지 궁금합니다. 본 논문에서는 Fusion stage 학습시에 해당 문제는 어떻게 다루고 있나요?
마지막으로 Isolation stage 학습이 많은 데이터를 필요로하는 DETR의 훈련의 해결책으로 제시되었다고 말씀해주셨는데, 소량의 두 도메인 데이터셋을 합치더라도, 학습 데이터가 충분할 정도의 스케일이 되는지 궁금합니다. 일반적으로 DETR 학습시에 어느정도 스케일의 데이터셋을 활용하는지, RGB, Thermal을 모두 활용하면 기존 DETR 학습시에 활용하는 데이터셋 스케일과 유사해지는지 궁금하네요..
논문에서 해당 stage 학습시에 단일 모달리티만으로 구성된 데이터를 활용할 수 있어 효과적이라고 언급했다고 소개해주셨는데, 다른 추가적인 데이터셋을 활용한 보충 실험은 혹시 있었는지 궁금합니다.
감사합니다.