안녕하세요 박성준 연구원입니다. 오늘 제가 리뷰할 논문은 Not All Inputs Are Valid: Towards Open-Set Video Moment Retrieval using Language으로 Video Moment Retrieval을 Open-Set으로 확장시킨 첫 연구입니다. Open-Vocabulary Object Detection, Open-Vocabulary Segmentation 등 많은 분야에서 open-set 연구가 많이 진행되고 있는데, Video Moment Retrieval 논문을 서베이하던 중 Video Moment Retrieval을 Open-Set 상황으로 확장한 논문이 ACM MM 2024에서 공개되어 논문을 리뷰하게 되었습니다.
Introduction
Video Moment Retrieval(VMR)은 untrimmed video에서 자연어 쿼리에 해당하는 구간을 반환하는 task입니다. 기존의 VMR 연구들이 좋은 성과를 보여주고 있음에도 불구하고 저자는 아직 실생활에 적용하기 위해서는 많은 한계점이 존재한다는 점을 지적하고 있습니다. 저자는 특히 실생활에서 VMR 즉, 비디오 내 구간검색이 사용되기 위해서는 사용자가 실제 영상 내에 존재하지 않는 상황이 텍스트 쿼리로 주어지게 된다면, “영상 내에 해당 구간이 존재하지 않음”을 반환해야하지만, 현존하는 연구들은 모두 closed-set에서 VMR이 진행되기에 한계점이 있다고 말합니다. 또한, 이러한 closed-set에서의 연구는 텍스트와 영상을 모델링하는 과정에서 데이터셋의 특성에 편향될 수 있기에, 일반화 능력이 떨어진다는 점을 지적하고 있습니다. 저자는 위와 같은 문제를 바탕으로 open-set에서의 VMR의 필요성을 강조하고 있습니다. 저자가 제안하는 open-set에서의 VMR은 만약 영상 내 존재하지 않는 구간이 텍스트 쿼리를 통해 주어진 경우, irrelevant query라는 것을 사용자에게 반환하게 됩니다. 즉, 영상 내 쿼리에 해당하는 구간이 없을 경우, 억지로 구간을 반환하지 않습니다. 기존의 연구들은 데이터셋의 한계도 존재하긴 하지만, 이러한 문제를 제기하지 않았고 연구가 진행되지 않았음을 지적합니다.
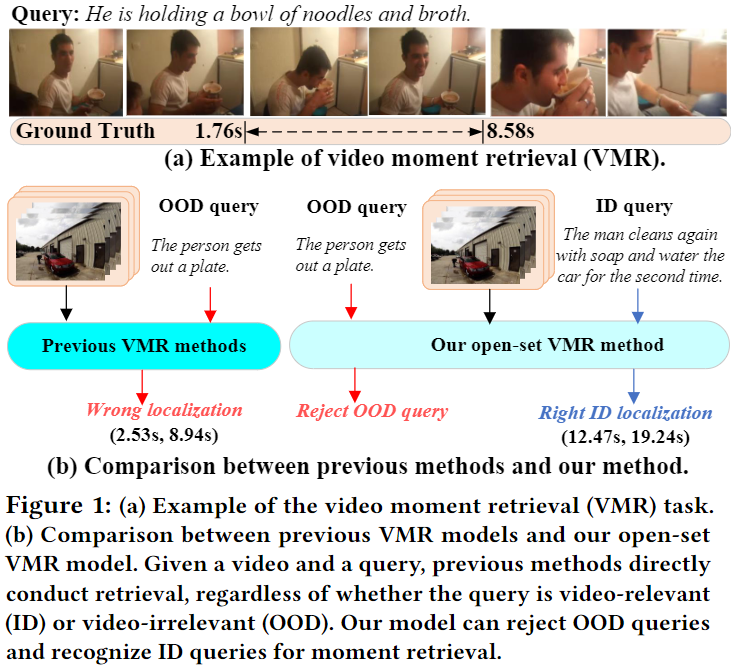
위의 Figure 1은 앞서 설명한 저자가 기존의 방법론들이 가지고 있었던 문제를 보여주며, 자신들이 제안하는 open-set에서의 VMR이 closed-set이 가지던 문제를 해결하는 것을 시각화하여 보여주고 있습니다. 기존의 방법론은 적절하지 않은 쿼리가 untrimmed 영상과 함께 주어지는 상황에서도 억지로 특정 구간을 반환하기에 wrong localization문제가 있었음을 설명하고 있고, 자신들이 제안하는 open-set VMR은 적절하지 않은 쿼리 즉, Out-Of-Distribution(OOD) 쿼리가 주어진 상황에는 localization을 진행하지 않고, 적절한 쿼리가 들어온 상황에서만 localization을 진행하게 됩니다.
저자는 open-set VMR을 OS-VMR로 새로 정의하며 OS-VMR이 갖는 3가지 challenge를 설명하고 있습니다.
- 어떻게 In-Distribution(ID) 쿼리들의 분포를 계산할 것인가?
- OOD와 ID 쿼리의 정확한 boundary(OOD 쿼리와 ID 쿼리 분포의 경계선)를 구분할 것인가?
- 어떻게 ID 쿼리들에 해당하는 영상 내 구간을 반환할 것인가?
위 3가지 challnges를 해결하기 위해 저자는 multi-variate(다변량) 가우시간 분포 assumption을 기반으로 ID쿼리들의 분포를 학습하기 위해 normalizing flow를 구성하는 multi-layer coupling block를 설계했습니다. 다음으로 저자는 여러 쿼리의 uncertainty 점수와 log-likelihood 분포를 기반으로 ID와 OOD를 구분하는 경계를 정합니다. 이때 triplet 손실함수를 추가로 사용하여 경계를 잘 정할 수 있도록 합니다. 다음으로 저자는 ID 쿼리에 해대 video-query 매칭과 frame-query 매칭을 위해 cross modal 상호작용을 수행합니다. 마지막으로 저자는 미리 정의한 proposal을 바탕으로 positive-unlabeled 학습을 통해 정확한 target 구간을 반환할 수 있습니다.
이에 따른 저자의 main contribution은 다음과 같습니다.
- 저자는 기존의 연구들이 고려하지 않았던 open-set에서의 VMR 즉, OS-VMR을 제안합니다. OS-VMR은 쿼리에 해당하는 구간을 반환하는 것뿐만 아니라 해당 쿼리와 영상이 관련이 있는 지, 없는 지에 대한 판단도 수반되기에 더욱 challenging한 task입니다.
- OS-VMR을 수행하기 위해 저자는 ID와 OOD 쿼리를 구분하고 ID 쿼리를 활용해 구간 검색을 수행하는 OpenVMR 프레임워크를 제안합니다.
- 저자는 3가지의 기존에 많이 활용되던 데이터셋인 ActivityNet Captions, Charades-STA, TACoS데이터셋에서 open-set, closed-set 상황에서 기존 SOTA 모델들에 비해서도 더 높은 성능을 달성했음을 보여줍니다.
Method
먼저, 기존의 closed-set에서의 VMR은 untrimmed video V와 query Q가 주어지면 V 내에서 Q에 해당하는 구간을 반환합니다. 이는 closed-set에서만 학습되고 closed-set에서만 수행되기에 untrimmed video V와 무관한 쿼리(OOD)를 처리하는 능력이 부족합니다. 하지만, OS-VMR은 untrimmed video V와 무관한 쿼리는 구간 반환을 거부하는 기능이 추가된 task로 기존 VMR보다 더 현실적인 구간 검색을 제공합니다.
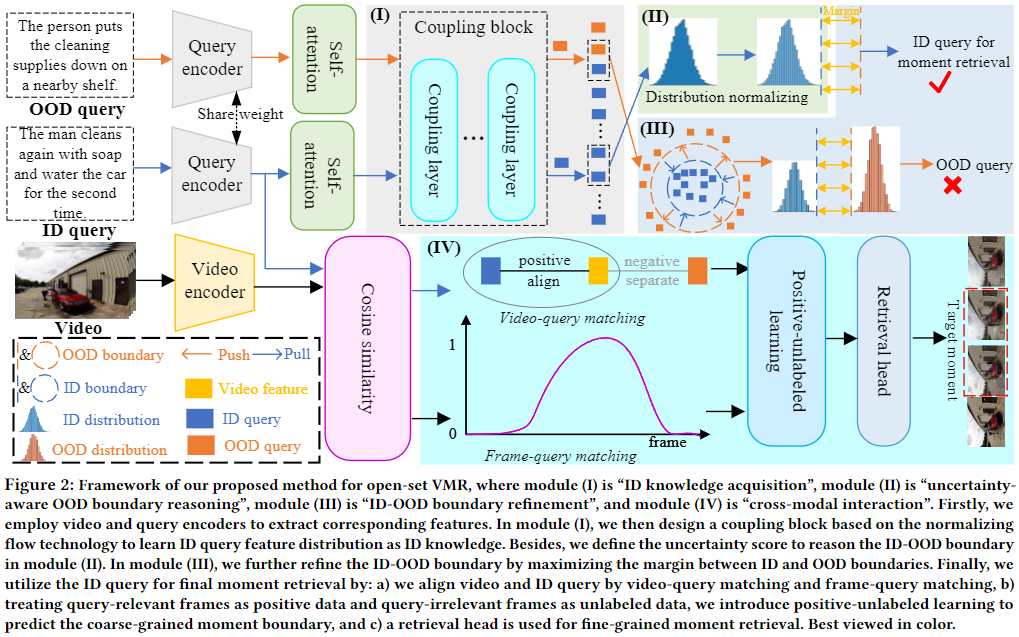
위 Figure 2는 저자가 제안하는 OpenVMR(OS-VMR task 수행가능한 프레임워크)의 전반적인 구조를 보여주고 있습니다. Introduction에서 설명한 것과 같이 먼저 쿼리의 분포를 파악해 ID인지, OOD인지 구분합니다. 그 후, OOD 쿼리는 구간을 반환하지 않고, ID 쿼리는 Cross Modal 상호작용을 통해 ID 쿼리에 해당하는 영상 내 구간을 반환합니다.
Preparation
Video Encoder. untrimmed video V가 N_v개의 프레임으로 주어졌을 때, 먼저 저자는 사전학습된 C3D를 통해 frame-wise 특징을 추출합니다. C3D모델은 video에서 자주 활용되는 backbone 모델로 꽤 오래된 모델로 최근에는 더 발전된 video backbone모델들이 많이 존재하긴 하지만, 해당 논문에서는 C3D모델을 사용했네요. long-range dependencies를 다른 backbone들에 비해 더 잘 담고 있기 때문에 해당 backbone을 사용했다고 설명하고 있습니다. 간단하게 생각해 비디오에서의 VGG정도의 역할을 하는 backbone모델이다 정도로 생각해주시면 될 것 같습니다. 추출한 특징은 수식으로 V = \{v_i\}^{N_v}_{i=1} \in \mathbb{R}^{N_v \times d}로 나타낼 수 있으며, d는 차원수를 나타냅니다.
Query Encoder. untrimmed video와 마찬가지로 query Q가 N_w개의 단어로 주어졌을 때, 저자는 Glove embedding을 활용하여 단어들을 벡터로 변환합니다. 그 후 Bi-GRU layer를 사용하여 word-level query 특징을 추출합니다. 수식으로 W = \{w_j\}^{N_w}_{j=1} \in \mathbb{R}^{N_w \times d}로 나타낼 수 있으며 d는 마찬가지로 차원수를 의미합니다. 전체 쿼리를 다루기 위해서는 Skip-thought parser를 통해 sentence-level query 특징 q \in \mathbb{R}^d로 나타냅니다.
ID Knowledge Acquisition
ID Knowledge Acquisition은 ID 쿼리와 OOD 쿼리를 구분할 수 있는 모델을 만들기 위해서 필요한 과정입니다. 이를 위해서 저자는 Normalizing Flow를 활용합니다. 먼저, 입력 쿼리 q를 학습가능한 함수 \Phi를 사용해 \mathbb{R}^d의 공간에 매핑시킵니다. 이때 \Phi(q)는 다차원 공간에서의 분포를 따르게됩니다. 이 분포를 통해 저자는 ID 쿼리들의 분포를 파악하게 됩니다. Normalizing Flow는 입력 데이터를 여러번의 단계를 거침으로 점진적으로 데이터 분포를 변화시켜 복잡한 데이터의 분포를 간단한 가우시안 형태의 분포로 변환시키는 것을 의미합니다.
multiple coupling layer를 통해 Normalizing Flow 과정을 거치게 되는데 각 layer에서 q가 입력으로 들어오면 \Phi_c를 출력합니다. 이 과정에서 c번째 layer에서 변환된 출력을 k_c라고 하고, 그 전 layer의 출력은 k_{c-1}입니다. 이러한 과정을 여러번 거치는 것으로 최종적으로 ID 쿼리의 분포는 가우시안 분포의 형태로 표현할 수 있고 위 과정을 수식으로 나타내어 입력 쿼리의 log-likelihood는 다음과 같습니다.
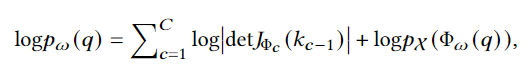
여기서 J_{\Phi_c}는 \Phi_c에서의 Jacobian 행렬로, 각 layer에서의 변환 과정에서 입력과 출력 사이의 변화를 의미합니다. p_0는 가우시안 분포로 가정된 기저 분포(base distribution)을 의미하고 det J_{\Phi_c}는 Jacobian 행렬의 행렬식(determinant)로, 변환 과정에서의 변화율을 의미합니다. 즉 위에서 설명한 여러 layer를 거치며 입력 q가 가우시안 형태의 분포로 변환하는 과정을 나나내고 있습니다.
위 과정을 최적화하기 위한 방법으로 log-likelihood를 사용하는데 ID가 최대한 잘 맞도록 모델을 학습하는 것을 의미합니다. 이를 위해 결국 각 layer에서의 \Phi가 가우시안 분포를 따르도록 하고, log-likelihood를 최대화하는 방향으로 학습을 진행합니다. 이때 ID 쿼리의 분포는 p(x)는 multi-variate 가우시안 분포를 따르며 다음과 같이 표현됩니다.
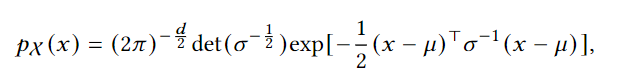
x는 변환된 쿼리 벡터를 의미하고, \mu는 평균 벡터, \sum는 covariance 행렬을 의미합니다. 위 수식을 통해 log-likelihood를 최대화 하기 위한 손실함수는 다음과 같이 정의됩니다.
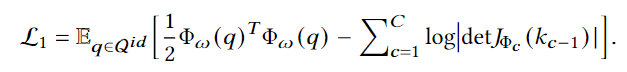
위 손실함수는 가우시간 분포의 특성을 기반으로 Normalizing Flow를 통한 각 coupling layer에서의 변환과정을 포함하고 있으며, 각 layer에서의 Jacobian 행렬식도 고려하는 손실함수입니다.
OOD Boundary Reasoning
앞선 ID Knowledge Acquisition에서는 ID 쿼리들의 분포는 Normalizing Flow를 활용해 가우시안 형태의 분포로 변환하여 ID 쿼리들의 분포를 학습했습니다. OOD Boundary Reasoning에서는 ID쿼리들과 OOD쿼리들의 분포 사이에 경계선을 설정하여 ID와 OOD를 구분합니다. 이때 경계선을 구분하기 위해서 uncertainty 점수를 기반으로 경계를 선정하고 log-likelihood를 통해 ID, OOD를 판별합니다.
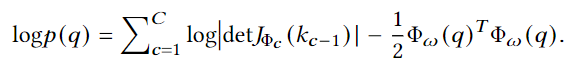
먼저 OOD 쿼리 또한 위 수식을 통해 log-likelihood를 계산할 수 있습니다. 계산 된 log-likelihood를 기반으로 uncertainty 점수를 구할 수 있습니다. uncertainty 점수는 log-likelihood를 기수 함수로 변환하여 다음과 같이 정의됩니다.
u(q) = {\max}_{q}(\exp(\log p(q)) - \exp(\log p(q))
이 uncertainty 점수는 쿼리가 얼마나 certain한지를 나타냅니다. 즉, log-likelihood가 높을수록 ID에 가까우고 낮을수록 OOD에 가깝습니다.
위 점수를 기반으로 일정 비율의 쿼리들을 기준으로 경계를 설정합니다. 해당 논문에서 저자는 5%의 비율을 채택하여 사용합니다. 즉, log-likelihood의 상위 5%값을 \log p_{id}라고 설정하고 이를 기준으로 OOD의 경계를 설정합니다. 이 경계값을 b_{ood}라고 정의하고 저자는 A라는 하이퍼 파라미터를 사용해서 OOD의 경계를 설정합니다. b_{ood} = b_{id} - A 이 방식을 통해 ID와 OOD를 구분하는 경계를 설정합니다. 즉, 정리하면 쿼리를 Normalizing Flow를 통해 가우시안 분포의 형태로 표현한 뒤, 특정 비율(5%)를 설정하여 임계값을 정해 임계값을 기반으로 ID와 OOD를 구분하게 됩니다.
ID-OOD Boundary Refinement
위에서 경계값을 설정했지만, 저자는 좀더 명시적으로 ID와 OOD를 구분하기 위한 loss를 설정하여 ID쿼리와 OOD쿼리 사이의 경계를 좀 더 명확히 합니다. 즉, ID와 OOD의 서로 다른 Discriminative Feature를 더 잘 학습할 수 있도록 하는 손실함수를 설정합니다.
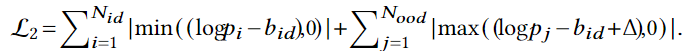
해당 함수는 triplet loss로 OOD 중에 log-likelihood 값이 b_{ood}보다 큰 쿼리들은 ID와 가까워 보일 수 있기 때문에 경계로부터 더 멀리 떨어뜨리고, ID 중에 log-likelihood 값이 b_{id}보다 작은 쿼리들은 uncertainty가 크기 때문에 더 ID에 가까워지도록 합니다.
N_{id}와 N_{ood}는 각각 ID와 OOD 쿼리의 개수를 의미하고, \log p_i는 ID 쿼리의 log-likelihood 값, \log p_j는 OOD 쿼리의 log-likelihood값을 의미합니다.
저자가 말하길 log-likelihood값은 굉장히 넓은 범위에서 표현될 수 있기에 log-likelihood 값들을 [-1, 0] 범위에 있도록 정규화하는 것으로 계산을 더 효율적으로 할 수 있는 동시에 경계를 더 명확하게 구분하여 ID 쿼리와 OOD 쿼리의 차별성을 높일 수 있다고 합니다. 따라서 저자가 사용하는 triplet loss는 ID와 OOD를 더 잘 구분하고, 정확한 모델을 학습할 수 있도록 유도하는 손실함수입니다.
Cross-Modal Interaction and Training
ID와 OOD를 구분했으니 ID를 통해 비디오 내 쿼리에 해당하는 구간을 반환하기 위한 학습과정입니다. 비디오-쿼리 매칭은 주어진 영상 쿼리 간의 관련성은 계산하여 매칭하는 것으로 ID 쿼리에 해당하는 구간을 반환합니다. 여기서 비디오와 쿼리는 global 표현과 frame-level과 word-level로 변환되어 사용됩니다. 이는 coarse-grained level과 fine-grained level에서 정확하게 쿼리에 해당하는 구간을 반환하기 위함입니다. global 특징은 코사인 유사도를 통해 학습됩니다.
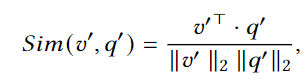
당연하지만, v'와 q'는 비디오와 쿼리의 global 특징입니다.
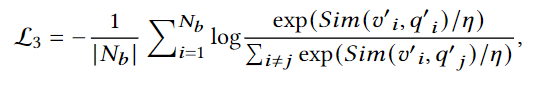
손실함수 또한 일반적인 contrastive 학습의 수식과 동일합니다. 해당 손실함수는 coarse-grained level에서 비디오와 쿼리를 매칭시키는 것을 목표로 하는 손실함수입니다.
쿼리와 프레임 사이의 매칭을 위해서는 쿼리와 관련이 있는 프레임, 쿼리와 관련이 없는 프레임을 각각 positive, unlabeled로 구분지어서 쿼리와 유사도를 계산합니다.
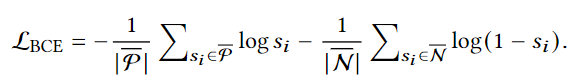
결국 프레임들 중에 positive와 unlabeled를 구분하는 BCE loss를 통해 계산됩니다. s_i는 positive frame의 예측 확률입니다. 이 손실 함수는 positive 프레임을 최대화하고, unlabeled 프레임을 최소화하는 방향으로 학습을 진행합니다. 즉, positive 프레임은 쿼리와 관련성이 높다는 신호를 주고, unlabeled 프레임은 관련성이 낮다는 신호를 주게 됩니다. 이 과정을 거친 후에는 regression 손실한수를 사용해 반환하는 구간의 start, end timestamp를 정밀화합니다. smooth l1 loss를 사용합니다.
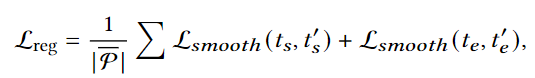
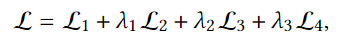
전체 손실함수는 위에서 설명한 모든 손실함수를 합하여 사용합니다.
Experiments
저자는 ActivityNet Captions, Charades-STA, TACoS 데이터셋에서 평가를 진행합니다. 모든 데이터셋은 closed-set과 open-set으로 구분하여 평가를 진행합니다. 위 3가지 데이터셋 모두 기존 closed-set VMR에서 자주 활용되던 데이터셋입니다.
Table 1.은 각 데이터셋에서 closed-set과 open-set을 어떻게 평가했는지를 보여주는 표로, open-set의 경우, ActivityNet Captions(ANC), Charades-STA(CS), TACoS 데이터셋의 쿼리뿐만 아니라 다른 데이터셋에서의 쿼리도 가져와 평가를 진행하며, 다른 데이터셋에서의 쿼리를 OOD로 설정하여 평가합니다.
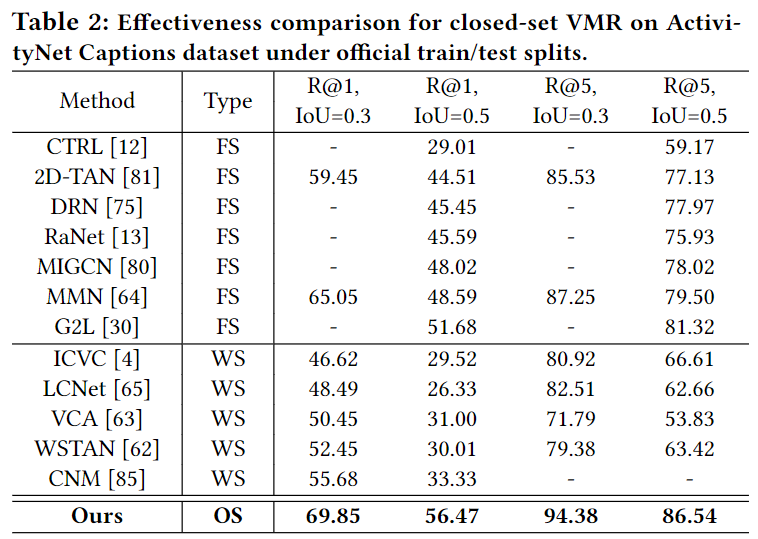
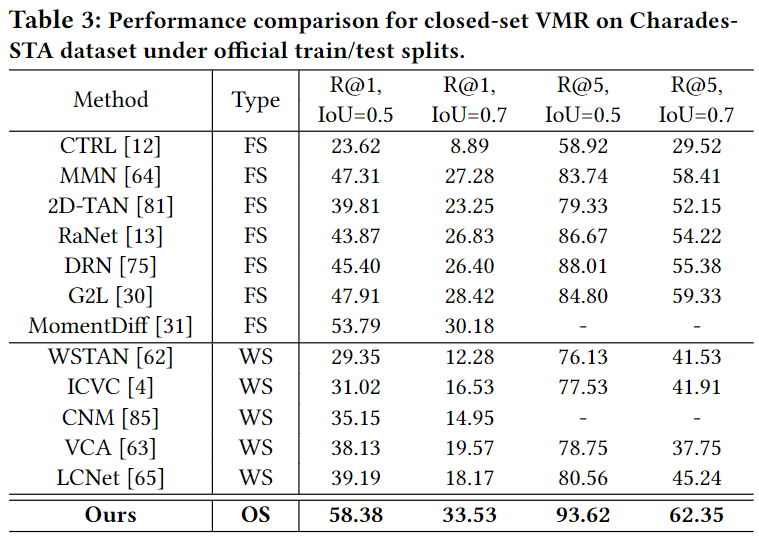
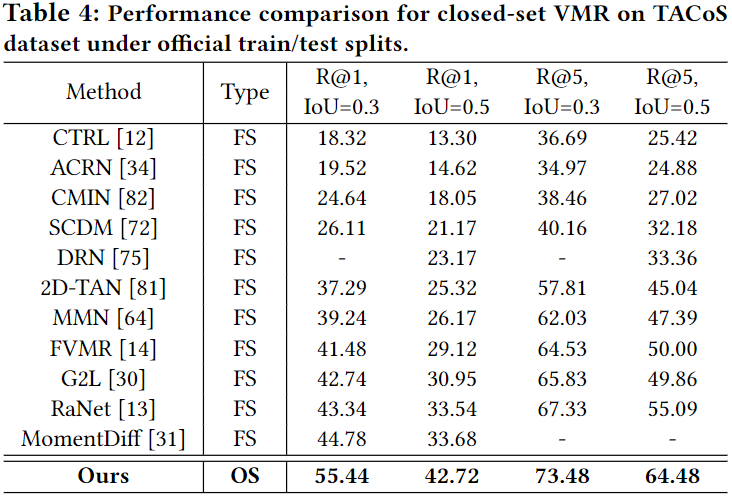
Table 2, 3, 4는 각 데이터셋에서의 모델의 성능을 보여줍니다. FS는 fully-supervised로 레이블이 모두 주어진 상황, WS는 weakly-supervised로 부분적인 정보만을 활용하여 학습한 것을 의미합니다. 보통 VMR에서의 weakly-supervised는 영상과 쿼리는 주어지고, 정확한 구간이 주어지지 않는 것을 의미합니다. 아무튼 OS는 저자가 제안하는 open-set 상황을 의미합니다. 표 2, 3, 4는 모두 closed-set에서의 평가를 의미합니다.
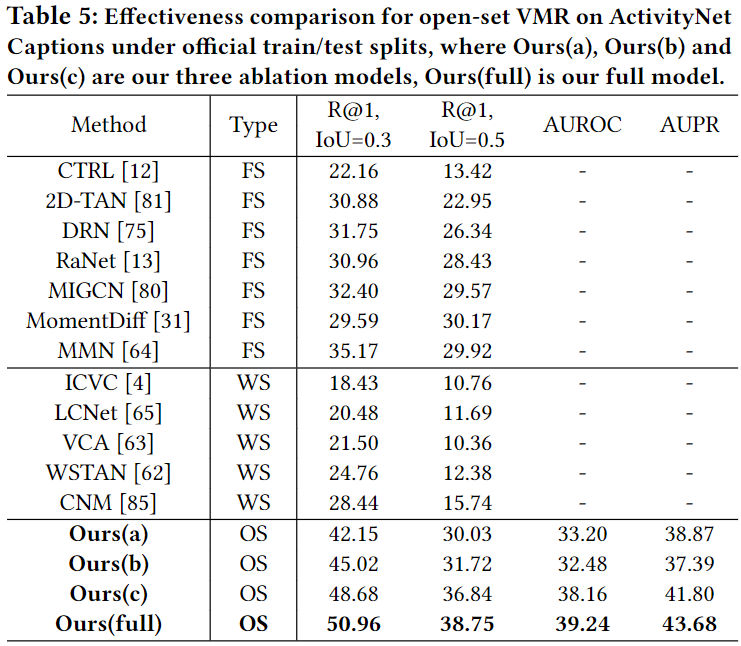
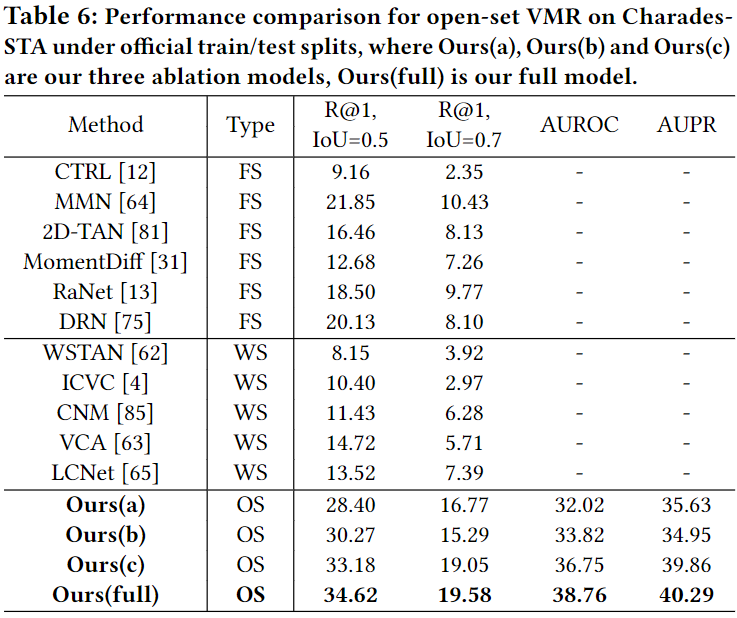
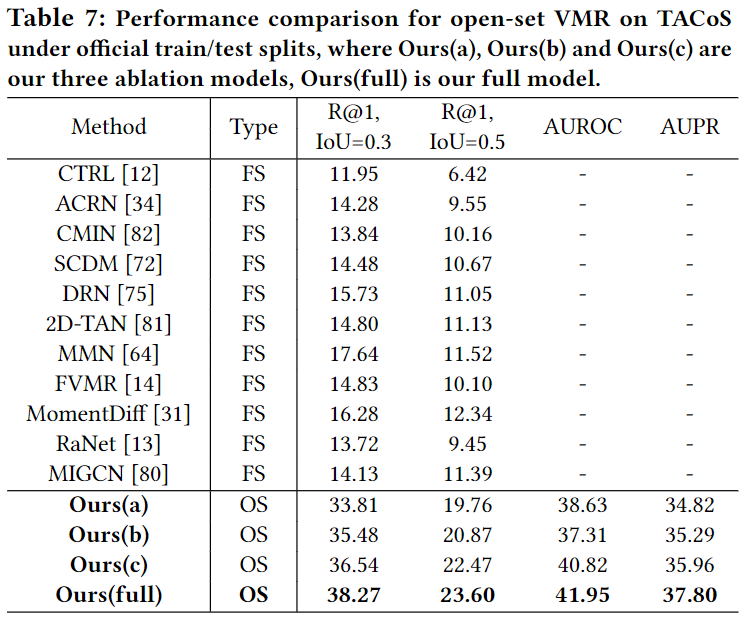
Table 5, 6, 7은 open-set에서의 성능입니다. Ours(a),(b),(c)에 대한 설명은 밑의 ablation에서 하겠습니다. 사실 OpenVMR이 가장 성능이 좋을 수 밖에 없는게 기존 연구들은 open-set을 전혀 고려하지 않았었기에, 다른 방법론들에 비해서 굉장히 좋은 성능을 보여주고 있습니다. 다른 방법론들보다 좋다라기 보다는 open-set상황을 고려하니 고려하지 않을 때보다 이정도의 성능 차이를 보여준다라고 생각해주시면 될 것 같습니다. 추가로 기존의 VMR에서는 사용하지 않던 AUROC와 AUPR도 평가지표로 활용했는데 AUROC는 Area Under the Reciever Operating Characteristic curve이고, AUPR은 Area Under the Precision-Recall curve입니다. 둘다 분류모델의 성능을 나타내는 지표로 AUROC는 ROC곡선 밑의 면적을 의미하고, AUPR은 PR곡선 밑의 면적을 의미합니다. ID와 OOD 분류를 얼마나 잘하는 지를 나타내는 지표입니다.

Figure 3.은 실제로 정성적으로 보여주는 결과로, 다른 연구들은 OOD 쿼리들이 들어와도 억지로 구간을 반환하지만, OpenVMR은 구간을 반환하지 않는다는 것을 보여줍니다.
Ablation Study
위 실험에서 Ours(a), Ours(b), Ours(c)가 존재했었는데, 각 모델들은 OpenVMR의 각 구성요소를 제외한 성능입니다. 순서대로, ID Knowledge Acquisition모듈, Uncertainty-aware OOD Boundary Reasoning 모듈, ID-OOD Boundary Refinement 모듈을 제외한 성능입니다. 각각의 구성요소가 중요한 역할을 하는 것을 성능을 통해 증명하고 있습니다. ID Knowledge Acquisition모듈이 가장 큰 성능 향상을 가져왔으면, 이는 ID의 분포, 경계를 정교하게 구축하는 데 매우 중요한 역할을 한다는 것을 보여줍니다.
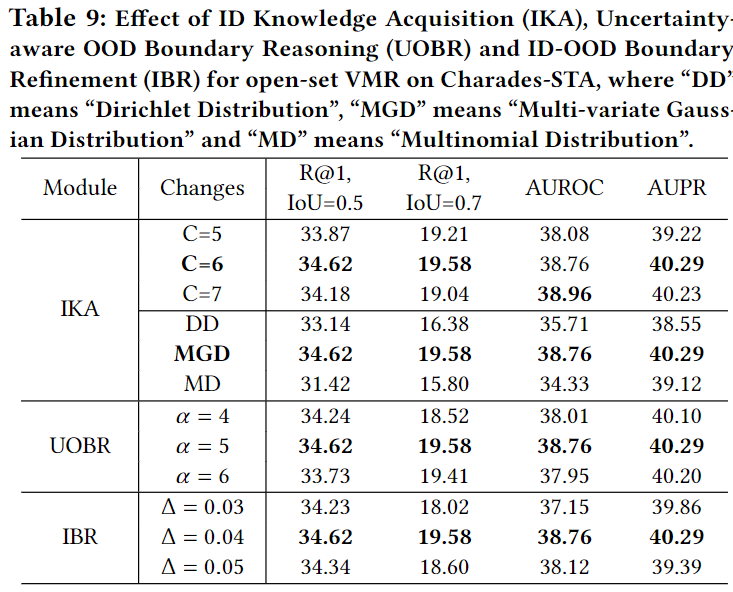
Table 9.는 각 모듈에서 사용한 하이퍼마라미터에 대한 Ablation Study입니다.
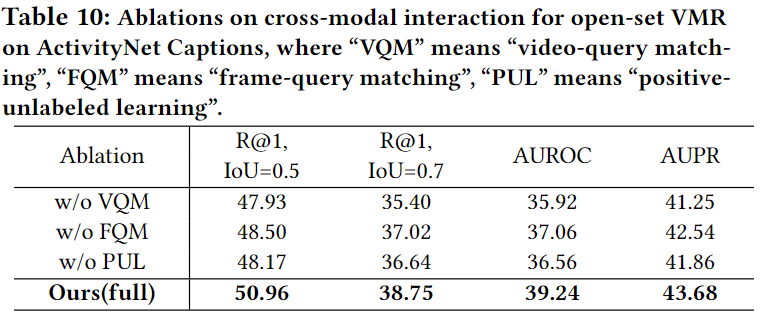
Table 10.은 video-query 매칭(VQM), frame-query 매칭(FQM), positive unlabeld 매칭(PUL)에 대한 ablation study입니다. 저자는 ablation을 통해 저자가 제안하늠 OpenVMR에서의 모든 과정과 모든 모듈이 중요한 역할을 하고 있음을 강조하며 논문을 마칩니다.
Conclusion
논문 리뷰를 마무리하며 개인적으로 논문에서 살짝 아쉬운 부분이 있었는데 평가를 진행하는 과정에서 다른 데이터셋에서의 쿼리라고 하더라고 영상 내 쿼리에 해당하는 구간이 존재할 수도 있는데 그 부분에 대한 고려를 저자가 하지는 않았다는 점입니다. 물론 다른 데이터셋에서의 쿼리가 다른 데이터셋에 적용할 때에 영상 내 해당하는 구간이 없을 수도 있지만, 없더라면 저자가 한번 논문에서 언급을 해줬으면 좋을 것같은데 언급이 하나도 없어서 이게 정말 open-set에서의 적합한 평가인지 의문이 생기네요.
또한 방법론 자체가 쿼리의 분포만으로 ID와 OOD 쿼리를 구분하기에 데이터셋 내 쿼리들의 분포에 의존하는 경향이 크다는 한계점이 있다고 생각합니다. 영상과 쿼리를 비교하여 연관성이 적은 경우, OOD라 판단하는 것이 아니라서, 각 데이터셋의 쿼리 분포에 크게 의존하고 있고 영상의 특징을 고려하지 않은 채 쿼리를 ID, OOD로 구분한다면 real world에서 적용하기 어렵다고 생각됩니다. 저자가 정의한 기존 연구들이 실생활에서의 적용하기 어렵다는 문제를 OpenVMR 모델도 그대로 가지고 있는 한계점이라고 생각되어 정말로 open-set 상황을 해결한 것인지, 또 저자가 제안하는 방법론이 정말로 실생활에 적용되기에 적합한 방법론인지에 대해 의문이 생깁니다. 연구를 위한 연구(?)라는 생각이 드네요. 그래도 ECCV 2024에 accept되기도 했고, open review를 읽어보니 몇 리뷰어들도 평가를 하는 데에 있어 한계점을 지적하기는 했지만, 기존에 없었던 open-set에서의 VMR을 제안한다는 점과 실제로 성능이 좋다는 점을 고려하여 좋게 리뷰해준 것 같습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
방법론 마지막 부분에 언급된 positive unlabeled learning과 관련하여, unlabeled 샘플의 학습을 위해 pos 또는 neg로 할당하는 과정이 있는 것으로 알고있습니다. 논문에 이 과정과 관련된 설명은 없나요? 그냥 gt 라밸링 되어있는 구간은 P, 안되어있는 구간은 n으로 두었다면 pul이라 하기 어려웠을 것 같아 여쭤봅니다
안녕하세요 현우님 좋은 댓글 감사합니다.
저자는 positive구간이 아닌 backgound에 대해서 전부 unlabeled로 여긴 후에 similarity score를 기반으로 thresholdimg을 통해 negative와 positive로 구분하여 학습하고 있습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
해당 방법론이 open-set 상황을 중점으로 방법론을 설계하고 실험했기 때문에 다르 방법론은 open-set을 고려하지 않았으니, 해당 방법론에서 open-set에서 성능이 높게 나오는 것은 어찌보면 당연하다 생각이 드는데, closed-set 상황에서도 성능이 매우 높게 나와서 더욱 대단한 방법론이다라는 생각이 드는데요. 어떤 부분이 closed-set에서 성능을 올렸는지 ablation study를 봤는데 open-set 상황에서만 ablation study가 있어서 따로 closed-set에서의 ablation은 없나요? 아니면 이와 관련한 성준님의 생각이 궁금합니다.
안녕하세요 주연님 좋은 댓글 감사합니다.
저자가 제안하는 프레임워크에서 closed-set에서의 성능이 좋은 이유는 아무래도 cosine-similarity를 통한 positive 매칭이 효과적이었던 것 같습니다. 기존 방법론들과의 성능차이가 적은 이유를 저자가 논문에서 명확하게 설명하고 있지는 않지만, 제 생각으로는 positive와 unlabeled로 나눠 contrastive 학습을 하는 PU 학습이 효과가 있었을 것이라 생각이 됩니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
제가 잘 모르는 키워드라 질문이 조심스럽습니다만, 혹시 open-set과 유사하지만 다른 의미를 갖는 키워드 (ex, open-voca)가 비디오 분야에서 따로 사용되나요? 다시말하면, open-set에서 학습된 데이터에 대한 모델의 성능만을 보장하는 연구와, open-set에서 발생하는 새로운 분포의 데이터에 대한 예측을 가능하게 하는 연구가 혹시 다르게 진행되고 있는게 아닌가 궁금합니다.
해당 연구가 open-set을 제대로 다루고 있는지에 대해 생각해보다가 궁금하여 질문남깁니다
질문이 부족하여 혼란을 드렸다면 죄송하네요.. 감사합니다
안녕하세요 유진님 좋은 댓글 감사합니다.
먼저 open-vocabulary와 같은 키워드가 VMR에서 활용되지는 않습니다. Video Question Answering(VQA)와 같은 비디오 task에서는 open-vocabulary라는 키워드가 사용되지만 해당 task를 제가 팔로우 업 하지는 않아서 어떠한 방식으로 연구되어왔는 지는 잘 모르겠습니다. 확실하지는 않지만 open-set 연구에서는 모델의 성능을 보장하는 연구와 새로운 분포의 데이터에 대한 예측을 가능하게 하는 연구에 대한 리포팅을 모두 진행하지만, 어느 성능에 초점을 두고 있냐에 따라 다르게 진행되는 것 같습니다.
감사합니다.