안녕하세요. 지난 리뷰에서는 Universal Segmentation, Segmentation의 모든 Task 에 대한 연구를 소개 드렸다면, 이번 논문에서는 Detection 분야에서 “모든 환경에서, 모든 객체를 탐지하고자 하는” 연구를 소개 드리고자 합니다. Task는 Segmentation에서 Detection으로 바뀌었지만, Universal이라는 관점에서 연구의 성숙도 때문일까요, Detection 분야에서는 소위 “특정 상황에 구애 받지 않고 모든 검출을 해내는 궁극의 Detector”에 대한 연구인 반면, Segmentation 분야에서는 아직 “특정 상황 (Task)에 대해 하나의 모델로 모든 상황을 대처하는”, 미묘한 차이가 존재합니다. Open-world 상황을 예시로 들자면, 최근의 Object detection 모델은 웬만하면 Closed-set 외의 Open-set, Open-world에 대한 모델 평가를 진행합니다. 비록 해당 논문이 Open-world 논문이 아님에도 해당 기조를 보이고 있습니다. 하지만 Segmentation에서는 여전히 Open-world 상황에서 성능이 워낙 저조하므로, Open-world에 대해서는 다소 덜 고려되고 있습니다.
예전 아버지와 대화에서 아버지가 어떤 연구를 하고 있는지 물어보아, 제가 “실생활에서 활용 가능한, 그러기 위해서는 학습하지 않은 대상도 인지할 수 있는 능력을 갖추어야 하므로, 이에 대해 인지하는 (Open-world) 연구에 관심을 가지고 살펴보고 있다.”라고 대답하니, 아버지께서 “그런 연구는 예전부터, 딥러닝의 궁극적인 목표이다. 해당 관점이 새로운 관점이 아닌, 과거부터 이어져 온, 딥러닝의 발전을 잘 모르는 일반인, 즉 소비자에게는 당연히 되어야 하는 기술이다.”라고 대답하셨습니다. 지금 생각해보니, 당연히도 우리는 그러한 Universal model을 만들어야 함은 알고 있었지만, 그간 기술과 함께 발전하다 보니 연구적으로, 그리고 스스로도 특정 상황에 국한된 연구만을 진행하고 있지는 않았나 생각합니다. 물론, 당시 상황 그리고 아직도 불가항력한 한계점이 존재하지만 Foundation, LLM 등 이전에는 상상도 하지 못한 기술로 발전해가는 모습을 보며 이제는 해당 연구에 대한 관심이 다시 한번 깊어질 시기가 아닌가 생각합니다.
본 논문에서는 UniDetector, Universal Object Detector를 제안합니다. 해당 모델은 수 많은 클래스를 감지하며, 모든 환경에서 객체를 인지 가능하도록 하는 일종의 Foundation Detector입니다. 해당 모델은 평가 시 Zero-shot에서 Supervised 방식의 Detector보다 좋은 성능을 보이며, 13개의 Detection dataset에서 3%의 학습 데이터만을 활용함에도 SotA의 성능을 보입니다. 그럼, 한 번 살펴보겠습니다.
Introduction
Universal object detection의 목적은 “detect everything in every scene” 입니다. 한 문장으로 설명되듯이 이전 연구의 문제점은 “large-scale benchmark dataset에서 category가 다양하고, 또한 scene (domain)이 다양하다”는 문제점이 있습니다. 이는 Open-world에서 unseen 객체에 대응하기에 어려우며, 해당 객체를 인지하기 위해서는 dataset을 다시 구성해야 하므로, 이는 detector의 일반화 능력을 제한합니다. 반면, 어린이는 새로운 객체 또는 새로운 환경에서도 일반화된 인지 능력을 보입니다. 그러므로 요즈음에는 universality, 보편성의 능력이 AI와 사람을 구분하는 장치가 되며, AI 연구는 사람과 유사해짐이 최종 목적이니 이들의 한계를 극복해야 합니다. 자고로 저자는 Universal object detector라 함은 “한 번 학습하면, 처음 보는 상황에도 추가 학습 없이 활용 가능하여야 하며, 이는 마치 사람의 인지 체계와 동일하게 작동하는 detector를 의미”한다고 주장합니다.
이러한 연구를 위해 detector는 연구 측면에서 두 가지 능력을 가져야 합니다. 첫 번째는 다양한, 여러 source의 image를 활용하며, 학습 시 heterogeneous label space, 즉 이질적인 label space에도 학습 가능해야 합니다. heterogeneous label space는 추후 방법론에서 다시 등장할 키워드기에 짚고 넘어가자면, 예를 들어 dataset A에서의 클래스는 ‘bike, bus, truck’이지만, dataset B에서 동일한 객체에 대해 클래스 명이 ‘bicycle, bus, trailor’로 라벨링 되어 있을 수 있습니다. 이처럼 여러 dataset을 활용하다 보면 annotator에 따라 혹은 라벨링 기준 등에 따라 서로 상이한 label sapce를 가지게 되며, 그 전에 일반적으로 dataset A와 B는 동일한 라벨링 구성 (개수, 대상)을 갖지 않습니다. 저자는 generalization, 일반화와 보편성을 위해선 여러 large-scale dataset에 대해 학습해야 하는데 (Foundation, LLM에서의 관점), 이 때 여러 dataset을 공동으로 학습하기 위해선 해당 heterogeneous label space에서 적절히 학습할 수 있는 방식을 찾아야 합니다. 저자는 또 하나, web-scale의 large-vocabulary dataset이 이들에 대한 해법 (우선적으로 object detection의 여러 dataset을 합친 수에 비해서도 그 수가 많기에)이 될 수 있으나, 그것들의 annotation이 noisy하며, 때로는 불일치 (이번 주차 현우/성준님의 세미나가 떠오르네요) 되는 경우도 다량 존재하므로 어렵다고 설명합니다 (또한, 우선은 해당 dataset에서는 bounding box에 대한 annotation은 일반적으로 존재하지 않습니다). 두 번째로는 open-world generalization입니다. 이는 제가 예전부터 관심을 가져 온 open-world (<-> closed-world) problem이다 보니, 족히들 알고 계시리라 생각합니다. 한 문장으로 요약하자면 “novel class에 대한 탐지 능력이 저하될 시, 이에 대한 성능 저하가 불가피하다”입니다. 저자는 해당 문제를 풀고자 OLN (이전 리뷰)과 굉장히 유사한 방식의 open-world detector 모델을 설계합니다. 우선, open-world 외에도 open-vocabulary가 있으며, 위 두 관점에서 저자가 실제로 풀고자 하는 바는 open-vocabulary로, 이들은 pure visual information, 즉 이미지만으로는 풀기 어렵습니다. 그렇기에 open-world 관점에서 unknown 객체를 인지하고, 해당 객체의 실제 카테고리를 아는 문제는 visual-language 방식을 통해 해결하고자 합니다. 모델 자체는 위에서 말씀드린 바와 같이 OLN의 구성을 기반으로 삼아 특별한 점이 없으나 하나의 관점, “그 때, 모델은 base class에 편향되어 novel class에 대해서는 under-confidence한 classification score를 보여 최종적으로 선택되지 않는다”는 생각에서 하나의 방식, “probability calibration to de-bias the prediction”을 제안합니다. 사실 해당 방식은 예전 open-world 논문에서 제가 생각했던 방식인데, 이렇게 2023년도에 논문으로 제안이 되었었네요. 마음 한 편이 아픕니다. 그럼 거두절미하고, 저자의 방법론을 살펴보겠습니다.
The UniDetector Framework
우선, 대전제는 이미지 I 에 대해 object detection은 해당 이미지의 라벨, \{(b_i, c_i)\}^m_{i=1} , ( b_i, c_i 는 각각 bounding box coordinate와 category label)을 예측합니다. 일반적으로 모델은 \mathcal{D}_{train} = \{(I_1, y_1), ..., (I_n, y_n)\} 의 이미지와 라벨로 구성된 단일 dataset을 활용하며, 해당 dataset의 test dataset, \mathcal{D}_{test} 에서 추론 결과를 벤치마킹합니다. 하지만 이처럼 단일 dataset이라함은 곧 closed-world로, dataset은 해당 dataset의 label space, \mathcal{D}_{train} = \mathcal{D}_{test} = L 에 한정됩니다. 저자의 핵심 목표는 다양한 source, \mathcal{D}_{train_1}, \mathcal{D}_{train_2}, ..., \mathcal{D}_{train_N}, 의 다양한 dataset에서 각각의 label space L_1, L_2, ..., L_N 의 heterogeneous label space를 동시에 학습할 수 있으며 추론 시에는 새로운 label space, L_{test} 에 대해 추론할 수 있어야 합니다.
문제 정의를 마쳤으니, Framework를 살펴보겠습니다. Framework는 크게 세 단계로 구성됩니다.
- Large-scale image-text aligned pre-training.
– 앞서 말한 바와 같이, 전통적인 object detection은 only-visual information, 즉 이미지 데이터에 대해서만 학습하였다면 open-world (vocabulary)에 대응하기 위해선 universality를 위한 language information이 필수불가결합니다. 저자 또한 language feature의 도움을 받아 일반화 능력을 구축하고자 하며, 이 때 image, text 데이터 간 alignment는 필수적이며 이들에 대해 학습한 이전 연구, RegionCLIP을 본 모델의 pre-trained parameter로 삼습니다. - Heterogeneous label space training.
– 본 과정에 대해 자세히 살펴보자면, 다음의 Figure 2를 살펴보겠습니다. 우선, 본 과정의 최종 목적은 위에서 말한 바와 같이 다중 source dataset을 학습시킬 수 있음에 있습니다. 이를 위해 세 방식을 고려할 수 있습니다.Figure2-(a)의 seperate label space는 multiple source train dataset에 대해 multiple model을 두는 방식, 즉 각 dataset에 대한 모델을 따로 두는 방식입니다. Test 시에는 L_{test} 에 대해 각 모델들이 각각 따로 예측을 수행하며, 이들의 결과를 합친다면 detection box의 offset이 정교해지는 효과가 있습니다. 하지만, N개의 dataset에 대해 N개의 모델이 존재해야하는 비효율성이 큽니다. 다음, Figure2-(b)는 모든 dataset의 label space를 통합합니다. 즉, N개의 dataset을 하나의 dataset으로 여기게 됩니다. 만약 전처리 과정에서 heterogeneous label space를 하나의 label space로 통합시키는 과정이 존재한다면, 이는 효과적일 수 있습니다. 단 하나의 backbone 네트워크만 필요하며, 단일 dataset으로 여겨지므로 Figure2-(a)와 달리 학습 시 mosaic, mixup과 같은 data augmentation 기법을 활용할 수 있습니다. 하지만 그만큼 dataset에서의 분포가 다르기에 학습이 불안정해질 수 있습니다.
저자가 제안하는 Figure2-(c), partitioned label space는 동일한 feature extractor, backbone,을 활용하면서도 각 dataset에 대해 classification layer만 따로 두는 방식입니다. classification에 앞서 pre-training한 language embedding을 활용할 수 있기에 추론 시에는 L_{test} 의 class label의 text embedding을 바로 활용하며, 각 label space 간의 label 충돌을 피할 수 있습니다. 이 때 추가적으로 고려해야할 점은 data sampler (dataloader)와 loss function인데, 일반적으로 dataset을 합치면 특정 클래스에만 분포가 과다한, long-tailed distribution 문제를 피하기 어렵습니다. 이 때문에 각 클래스의 수를 고려한 sampler(Class-Aware Sampler: CAS)나 또는 특정 클래스를 반복해서 부르는 sampler(Repeat Factor Sampler: RFS)를 고려할 수 있습니다. 하지만 이들은 closed-set의 가정에서만 효과적일 수 있으며, open-world 성능에는 영향을 주지 않습니다. 저자는 language embedding이 long-tailed distribution 문제에 대응 가능하다는 입장으로, 따라서 일반적으로 랜덤 추출하는 random sampler를 선택합니다. (이 문장은, 아마도 제 생각에 revision 이후 추가된 문장이 아닐까 생각합니다. 일반적으로 어떠한 dataloader sampler를 고르는지에 대한 이유가 담긴 문장은 처음 보는데, 보통은 experiments detail에 담긴 부분이 몇 문장으로 설명된 이유는 그 이유가 있지 않을까, 생각합니다)
두 번째로 loss function의 경우, 또한 long-tailed distribution을 고려하여 equalized loss나 seesaw loss를 고려할 수 있습니다. 하지만 이들은 큰 영향을 미치지 않으며, 대신 sigmoid-based loss가 더욱 효과적이라고 합니다. 그 이유는 based와 novel 카테고리에 대한 classification이 서로 간 영향을 미치지 않으며 (각각에 대해 0,1이므로), 반면 softmax의 경우 모든 카테고리에 대해 총합이 1이 되도록 연산되므로 이는 다시 말해 카테고리의 수가 많을 수록 비효율적입니다.


3. Open-world Inference
– 저자는 open-world에서 finetuning 없이 추론해야 함을 언급하며, 학습한 object detector와 test vocabulary로부터 추출한 language embedding을 활용합니다. 이 때, novel 카테고리는 학습 시 본 적이 없기 때문에, detector는 해당 카테고리의 객체에 대해 under-confidence한 결과를 보입니다. under-confidence란 곧 최종 예측에서 제외될 가능성이 높다는 의미입니다. 이를 극복하고자 저자는 probability calibration을 통해 base/novel 카테고리 사이 균형을 맞추길 원합니다.
위 probability calibration에 대해 먼저 짚고 넘어가겠습니다. L_{test} 의 test vocabulary의 language embedding과 함께, 학습한 detector는 finetuning 없이 바로 활용됩니다. 하지만 이미 detector가 base class에 대해 학습하였으므로 웬만해선 “모델이 이미 본 객체”에 대해 익숙해져있겠습니다. 이는 곧 classification confidence 관점에서 지배적인 영향력을 보이며, 모델이 novel class에 대해 무시하게 될 가능성이 높습니다. 이 말인 즉, open-world 상황에서 unknown 객체에 대한 성능이 굉장히 저조해지게 됩니다. 저자가 제안한 probability calibration은 prediction 이후 classification confidence에 대한 후처리로, 학습 과정에 포함되지는 않습니다. 해당 목적은 “base class에 대한 확률은 낮추고, 동시에 novel class에 대한 확률은 높임”에 있습니다. 그러므로, probability prediction의 밸런스를 맞춤이 중요하며 이를 위해 사전 확률을 활용합니다. 수식으로 먼저 살펴보자면 probability calibration은 다음과 같이 표현됩니다.

위 수식에서 중요한 점은 \pi^{\gamma}_{j} , prior probability, 사전 확률입니다. 수식은 예측으로 나오는 classification confidence를 사전 확률로 나눕니다. 문제는, 이 편향 수준이 어떻게 정의되는지에 대해 설명이 되어있지 않습니다. 그래서 제 추측으로는 아마 학습 시 모델이 특정 클래스에 대해 얼마나 높은 확률로 예측하는지를 편향 수준으로 정의하지 않았을까 생각합니다. 해당 사전 확률은 category j 에 대해 편향 정도 기록합니다. 사전 확률이 높다는 의미는 곧 모델이 특정 카테고리를 자주 보았다, 또는 편향되었다는 의미이므로, 이 사전 확률로 class confidence를 나눈다면 confidence는 다소 낮아질 것입니다. 그 반대로 자주 보지 않은 데이터는 사전 확률도 그만큼 낮을 것이기에 오히려 최종 예측 confidence는 높아질 것입니다.
위 p_{ij} 는 i번째 region proposal에 대해 class-specific한 예측 score를 반영합니다. 그러므로, 저자는 open-world generalization을 위해 class-agnostic한 특성을 추가로 고려하고 싶었으며, 그렇기에 다음 문단에서 소개드릴, class-agnostic한 CLN (Class-agnostic Localization Network)의 objectness score ( \eta_{i} )를 곱하여 최종 detection score ( s_{ij} )로 활용합니다. ( s_{ij} = p^{\beta}_{ij} \eta^{1-\beta}_{i} ).
decoupling proposal generation and RoI classification
이번에는 바로 위 문단의 class-agnostic localization network, CLN에 대해 설명합니다. 예전 OLN 논문 리뷰에서 다음의 네트워크를 보여드렸습니다 (Figure 3)
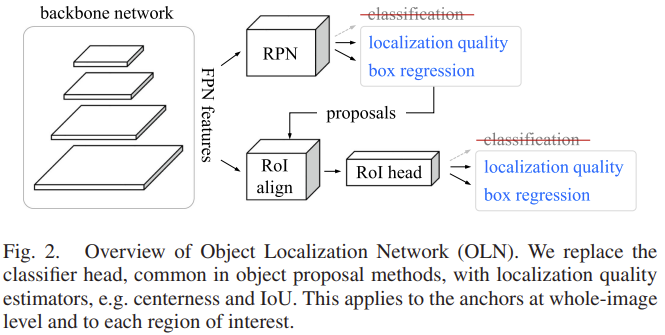
크게 다르지 않게 (실제로 코드를 보았는데, detectron2에서 해당 네트워크를 그대로 가져와 조금 추가한 데에 지나지 않습니다) 다음의 구성을 보입니다.

region proposal network, RPN은 class-agnostic한 특성을 보입니다 (binary to object/non-object). 반면, RoI Head는 특정 클래스를 예측합니다. 이들이 다르게 동작하기에, open-world 상황에서 둘의 다른 특성은 둘을 함께 학습 시에는 RoI Head의 classification에 대한 민감성 (특성)으로 인해 novel class를 탐지하기에 방해가 됩니다. 그러므로 저자는 두 과정을 분리시켜 학습하도록 합니다. 자세히는 RPN은 ImageNet pretrained parameter로 초기화하여 class-agnostic한 방식으로 학습하는 반면, 생성된 proposal를 활용하여 RoI Head는 image-text pretrained parameter로 초기화하여 unseen카테고리를 탐지하도록 기존의 Fast R-CNN 방식으로 학습합니다. 초기화하는 pretrained parameter가 다름이 독특한데, 저자는 이 두 종류가 서로 간 상호보완적인 정보를 가진다고 설명하며, universal object detection에 대해 더욱 이해력이 깊어질 수 있음을 설명합니다.
저자는 또한, 앞서 proposal을 만드는 과정에서 단순히 RPN만 참여함이 아니라 RoI Head도 proposal에 대한 score을 생성하도록 합니다. 이에 대한 부분이 위 그림에서 backbone에서의 feature가 RoI Head에도 참여된다는 모습에서 알 수 있습니다. 특히 localization confidence라는 부분이 곧 novel class에 대해 탐지하는 데 효과적인 기능을 하므로, RoI head에서 localization confidence를 내뱉으며, 해당 모듈에서도 binary class-agnostic classification을 수행하도록 합니다. 이를 통해 최종적으로 i번째 proposal에 대해 RPN에 해당 localization confidence는 둘의 localization confidence와 RoI Head의 classification score의 곱으로 연산됩니다. 이 값이 바로 위 probability calibration의 \eta , \eta_{i} = (s^c_i)^\alpha \cdot (s^{r1}_i s^{r2}_i)^(1-\alpha) 에 해당합니다. 제 논문의 실험을 위해 localization confidence를 어떻게 (정의)구하는지 코드를 한번 살펴봐야겠네요.
Experiments
열심히 달려왔습니다. 논문 내용이 이해하기에 어렵진 않았을 것이라 생각합니다. 본 저자는 제안하는 UniDetector의 universality를 증명하기 위해 open-world에서의 성능 평가와 동시에 전통적인 closed-set에서의 평가를 진행합니다.
이 때 학습한 dataset은 곧 heterogeneous label space에 영향을 미칠텐데, 저자는 COCO, Object365, OpenImages를 활용합니다. COCO는 80개의 카테고리, Object365는 COCO보다 더 방대한 양의 365개의 카테고리, OpenImages는 web-scale 수준의 500개 카테고리를 보유하나 해당 dataset은 다소 annotation의 대부분이 sparse하거나 또는 noisy (dirty)합니다. Test dataset으로는 long-tailed 분포로 유명한 LVIS, 그리고 ImageNetBoxes, VisualGenome dataset을 활용하여 open-world 성능을 평가합니다. ImageNetBoxes, VisualGenome는 처음 들어보았는데, 정말 시간이 갈수록 다양한 dataset들이 많이 존재하네요.

메인 벤치마킹 결과표입니다. Structure에서 S, U, P를 살펴볼 수 있는데, 위에서 설명드린 heterogenous label space를 어떻게 학습할 지에 대한 Figure2-(a),(b),(c)의 차이입니다. 해당 Structure에서 알 수 있는 부분은 P의 partitioned 방식의 성능이 가장 높으며, 위 방식은 LVIS에서 closed-world (supervised)에 비해 multiple source dataset을 활용한 zero-shot 방식의 성능이 더 높음을 보입니다. 주목할 점은 보통의 object detection 방식은 LVIS에서 평가 시 AP_{r} , rare (드문) 케이스의 성능은 낮은 편인데, 본 방식에서는 rare, common, frequency의 성능이 거의 유사하며 오히려 rare의 성능이 frequency보다 높습니다. 이 점에 대해 저자는 “probability calibration”이 관여했으며, rare의 성능이 높음은 다시 말해 open-world generalization이 높음을 시사한다고 설명합니다.

다음으로는 COCO에서의 closed-world 성능 결과입니다. 모델 구성을 보시면 특이한 점으로 요즘의 모델들은 모두 Transformer 기반의 attention을 어떻게 활용할 지에 대해 논의하는데, 이 이유는 Attention이 image-text 간의 alignment에 중추적인 역할을 하기 때문입니다. 하지만, 재밌는 점은 현재는 CNN-based 방법론입니다. 이 때도 text embedding을 활용하나, 이는 pre-trained된 파라미터 (RegionCLIP)을 활용함에 그칩니다. UniDetector는 그 어떤 방법론보다 더 높은 성능을 보입니다. 개인적으로 특이한 결과입니다. 해당 모델에서 특이하다 할 점은 없었는데, 처음에는 결과 표만 보고서 “아, 여러 dataset에서 학습한 후 COCO에서 재학습하였겠구나” 생각하였지만, 해당 결과는 단순히 COCO에서만 학습했기 때문입니다. 소위 말하는 “데이터 빨”도 아닌데, 어떻게 이런 결과가 나왔는지.. 저자는 해당 결과에 대해 다음과 같이 설명합니다. “해당 결과가 우리의 UniDetector가 generalization 뿐만 아니라 closed world에서도 효과적임을 보이며, 이는 곧 본 모델의 universality를 증명한다”. 아쉽네요, 본 성능이 나옴은 제 입장에서 굉장히 독특한데, 구조가 독특하지 않은 모델에서 어떻게 이런 독특한 결과가 나오게 되었을까요?

다음으로는 Table 3의 zero-shot 성능 결과와 Table 4의 open-vocabulary detection 결과입니다. 우선 zero-shot의 결과는 Transformer 기반의 GLIP보다 물론 많은 데이터를 활용하였지만, 좋은 성능을 보임이 고무적입니다. 이러한 결과는 우리에게 또 다른 바를 시사합니다. “Transformer가 물론 효과적인 모델임은 맞지만, 여전히 CNN 기반의 방식이 더 훌륭할 때도 많다”. 또한 Table 4의 open-vocabulray 결과는 RegionCLIP을 기반으로 하여 이 보다 높은 성능을 기대할 수 있으며, 특히 probability calibration 덕분에 novel class에서의 성능이 굉장히 높습니다. 성능만 보았을 때 우선 제 생각에 해당 모델이 정말 universal object detector임이 느껴져 흥미롭습니다. 이는 다음의 probability calibration을 통한 AP의 변화를 통해 확인됩니다. Probability calibration은 novel에 대한 성능이 높아짐은 충분히 기대할 수 있었는데, base에서의 성능이 낮아짐이 않음도 인상적입니다.

오랜만에 정말 괜찮은 논문 한 편을 읽은 기분입니다. 본 논문과 같은 논문들이 정말 CVPR급에 어울리지 않나 생각이 듭니다. 모든 모듈들이 유기적으로 연결된, 그러면서 저자가 독자를 잘 설득시키는 좋은 논문 한 편을 읽은 기분입니다. 이상 리뷰 마치도록 하겠습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Heterogeneous label space란 서로 다른 dataset에서 발생할 수 있다고 이해하였는데,,, 그럼 Figure 2의 세 방식에서 Figure 2-(b)는 전처리를 통해 모든 레이블은 맞추면서 Bounding box annotation에 대한 기준은 상이할 수 있는지 궁금합니다.
안녕하세요.
네 그렇습니다. 심지어는 Annotator가 단 한명이라도 그 날에 따라 Bounding Box에 대한 Annotation 기준이 다를 수도, 그 범위가 다를 수도 있습니다. (b)의 방식은 하나의 label space로 가정한다는 의미이니 dataset A에서는 “소”라고 되어 있을 때 dataset B에서는 “암소”, “황소”, “수소”라고 되어 있더라도 이들은 dataset A에 맞추어 “소”로 바꿔주는 작업이 필요하며, 이 때 어쩔 수 없이 bounding box에 대한 annotation은 처리하기 어렵습니다. 하지만 또 다르게 생각하면, 이 bounding box에 대한 annotation은 오히려 상이한 것이 보편성 측면에서 도움이 될 수도 있지 않을까 생각합니다.
리뷰 잘 읽었습니다.
Figure1의 학습 과정에서 우선 Image-text pretraining 을 진행한 후, heterogeneous label space training 부분에서 RPN, roi head 학습을 위해 추가적인 기법이 들어간 거 같은데, 그럼 이 단계에서 백본 (V, L) 은 어떻게 학습이 되나요?
감사합니다
안녕하세요.
아마 Figure2의 (b)를 말씀해주신 것으로 보입니다. 해당 Figure의 Class-agnostic Localization Network (CLN)은 Method에서 설명하는 Localization Network 즉, Unknown도 잘 찾기 위한 Network 구성이며 Language는 Freezed CLIP (RegionCLIP)으로, 이 둘 간의 Similiarity를 기반으로 학습됩니다. 이 때 백본은 위 Class-agnostic Localization Network의 백본에 해당되니, 실제로 Language에 대한 학습이 이루어진다고 보긴 어렵습니다.
아마 이는 Figure2의 (a)로 인한 오해가 발생하지 않았나 하는데, (a)는 (b)를 위해 Alignment Pretraining이 필요하다며, RegionCLIP을 활용하는 이유를 설명해준다고 이해해주시면 되지 않을까 생각합니다.
안녕하세요 좋은 리뷰 감사합니다.
우선 저자가 제안한 Heterogeneous label space training 에서 뒷단의 classifier를 데이터셋 마다 별개로 두는 접근의 참신성에 대해 상인님의 의견이 궁금합니다. 보통 DNN에서 앞단에서는 클래스를 공유하는 정보를 뒷단으로 갈수록 class specific(=Semantic)한 정보를 학습한다는 인사이트는 자명하게 퍼져있는 것 같습니다. 이러한 인사이트를 기반으로 다중 데이터셋 학습에 고려될 수있는 아키텍처라고 생각하는데, 이러한 접근이 해당 논문이 처음인가요? 제가 읽었던 Open-vocabulary 연구 중 DETIC[1]에서도 서로 다른 task의 데이터를 활용하기 위해 backbone만을 공유하는 접근을 활용하는데, 이러한 기존 연구 대비 해당 구조의 차별성을 본 논문에서는 어떻게 언급하는지 궁금합니다.
둘째로는 COCO를 활용한 closed-world 에서 Heterogeneous label space training이 어떻게 적용되었는지 궁금합니다 ㅎㅎ. Heterogeneous label space training가 서로 다른 데이터셋에 적용하기 위해 제안된 구조로 이해했는데, Table2의 실험에서는 해당 부분을 제외한 제안 사항에 대한 실험으로 이해하면 될까요..?
=======================================================================
리뷰에 대한 질문 외에도 해당 분야에 전문가인 이상인 연구원님께 의견을 여쭈어보고 싶은 것이 있습니다.
1. Open world 연구가 진행되면서 Few-shot Learning 과 해결되었다고 보고 있는지, 혹은 Few-shot Object Detection이라는 키워드가 Open-world/Open-vocabulary로 포함되는 기조인지 궁금합니다.
2. Open-world/Open-vocabulary 분야에서 Backbone/Baseline은 거의 Transformer/DETR로 굳어졌는지 궁금합니다. 혹시 ResNet backbone을 대상으로 연구되는 ([2]OWOD) 과 같은 연구는 이제 거의 없는지요?
아직 Open-world/Open-vocabulary에 대한 구별이 명확하지 않아 질문이 추상적인 것 같아 죄송합니다…
감사합니다!
[1] DETIC: Detecting Twenty-thousand Classes using Image-level Supervision, ECCV 2022, https://arxiv.org/abs/2201.02605
[2] OWOD: Towards Open World Object Detection, CVPR2021, https://arxiv.org/abs/2103.02603
안녕하세요. 리뷰 읽어주셔서 감사합니다.
제 견해에서 데이터셋 마다 classifier를 따로 두는 방식 자체는 별로 놀랍진 않았습니다. 즉, 이에 대한 참신성이 대단하다고 볼 수는 없습니다. 유진님의 말씀처럼 이전의 Weakly-supervised 등의 다양한 Task에서 여러 dataset에 대한 backbone 자체를 또는 weight를 공유하는 (siamese), 그러한 프레임워크는 이미 소개되었기 때문입니다. 다만, 제가 주목한 부분은 Heterogeneous label space에 대한 training을 어떻게 해야하는지에 대해 저자의 의도가 명확합니다. Multiple dataset을 활용한 연구는 이전에도 존재하였지만 일반적으로는 그들 간의 교집합 클래스만을 다루거나, 또는 사전에 정의한 특정 한, 두 가지의 클래스만을 다룹니다. 이는 보편성의 관점에서는 받아들여지기 어려운 부분이지만, 어떻게 보면 이전 Task들은 보편성에 집중하여 dataset을 다루지 않았기에 그 부분이 중요치 않았습니다. 하지만 본 논문에서 저자는 dataset taxonomy에 따라 서로 다른 multiple dataset을 어떻게 다뤄야하는지 (Heterogenous label space를 상정), 또 이들에 대해 어떤 모델 구성을 가져갈 지에 대해 다룬다는 점이 설득력 있었습니다.
두 번째로 COCO, 즉 Closed-set에서의 실험은 Training dataset이 COCO 단일이였기 때문에, Heterogenous label space는 다루지 않게 됩니다. 사실, 이 Heterogenous label space란 곧즉 multiple dataset이 존재할 때의 backbone과 classifier의 구조에 관심을 가질 뿐, 단일 dataset이라면 단순히 하나의 backbone, 하나의 classifier의 우리가 잘 아는 원래의 구성과 동일하다고 생각해주시면 됩니다.
================================================================================
1. 제 견해는 우선 사학은 없다는 주장입니다. Foundation model이 나옴에 따라 Detection, Segmentation은 이미 해결되었다고 보는 주장도 일부 이해되지만, 여전히 “그렇게 해서 실 생활에서 쓸 수 있는 수준인가”에 대한 대답은 못하기 때문입니다. 따라서, Few-shot Object Detection은 Open-world와는 조금의 궤가 다른 연구로 생각됩니다. 간단한 일례로 실제 공정/검수 부분에서는 Open-world/Open-vocabulary의 능력보다 어쩌면 본인들의 새로운 물품을 Few-shot으로 주어 기존의 Detector가 얼마나 잘 대응하는지, 완전 다르다면 얼마나 데이터를 모아야 활용 가능할지에 대해 고려할 수도 있다고 생각합니다. 물론, 연구 측면에서 대부분은 Few-shot에 비해 Zero-shot의 성능이 일반적으로 더 좋다면, Few-shot 연구에 대한 설득력이 떨어질 수는 있다고 생각됩니다.
2. 아닙니다. 아직 ResNet Backbone을 활용한 연구도 다수 존재합니다. 일례로 본 논문도 ResNet 계열이며, 특히 Human-device 등의 경량화 관점에서는 사실 Transformer모델은 높은 성능이 설득력이 떨어지기도 합니다. 하지만, 독특하게도 제가 읽어 본 모든 Open-vocabulary에서는 Transformer를 활용합니다. 아마 이는 Vision 분야의 연구자들이 Language에 대한 도움을 받고자 할 때, NLP 연구자들의 기조를 따를 수 밖에 없지 않나는 생각을 합니다. 일반적으로 이들은 Vision-Language Alignment가 필요하기 때문이며 그 때의 Attention 알고리즘은 매력적으로 와닿을 수 밖에 없음은 인정합니다.
* Open-world와 Open-vocabulary는 정의 자체는 “Vision-only”와 “Langugage-help”의 차이가 존재합니다. 특히 Open-vocabulary는 유저가 찾고자 하는 물체만 잘 찾아주면 되는 특수성도 존재합니다. 다만, 제가 지켜보고 있는 Universality, 보편성에 관한 Universal Recognition의 연구는 그 둘의 개념이 섞인, “학습하지 않은 객체를 찾고, 유저의 언어 입력 등을 활용하여 해당 객체가 무엇인지까지 찾아냄”을 고려 중에 있습니다. 사실, 이렇게 보았을 때 새로운 Task를 만듦이 어렵지는 않아보입니다. 다른 말로, 100명의 사람이 원하는 바는 서로 다른 100개가 될 수 있음이며, 이들을 충족하는 Task는 100개로 확장될 수 있습니다. 이 말은 다른 말로 그저 문제 정의를 어떻게 하는지에 따라 모두 인정될 수 있다는 의미이며, 이 100개의 Task를 아우르고자 하는 연구 중 하나가 이제 Universal Recognition가 될 수 있지 않을까라는 사견입니다.
안녕하세요, 이상인 연구원님. 좋은 리뷰 감사합니다. CNN기반인데도 가장 높은 성능을 보이는게 인상깊네요. 해당 부분에 대해 논문에 자세한 언급이 없는 것 같아 아쉽습니다.
한가지 질문이 있습니다.
해당 방법론에서 학습 과정에서 다른 데이터셋들에 대해 동일한 backbone을 사용하지만 classification layer는 다르게 사용합니다. 이렇게 학습된 여러 classification layer는 실제 inference에서는 사용되지 않고 backbone만을 사용하게 되나요? 그리고 학습 단계에서 RPN과 RoI Head도 함꼐 학습되는 것인가요?
안녕하세요 상인님 리뷰 감사합니다.
리뷰를 따라가던 도중 의문이 생겼는데, objectness score를 곱해주는 이유가 novel class도 평가해야 하기 때문인가요?
사전 확률로 class confidence를 나눈다는 점은 납득이 되지만 그 공간이 진짜 물체인지 에 대한 score가 왜 곱해져야 하는지 (있을 때와 없을 때의 차이) 감이 잘 안 옵니다!!