
안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 DETReg라는 Self-Supervised Learning 방법론을 제안한 논문입니다. SSL 중에서도 특히 Object Detection을 염두한 논문으로, Detector로 DETR을 사용합니다. 리뷰 시작하도록 하겠습니다.
Introduction
컴퓨터 비전에 있어 Self-Supervised Learning 분야는 별다른 label값이나 human annotation 없이 raw image set만을 가지고 이미지 데이터에 대한 좋은 표현력을 확보하는 것을 목표로 합니다. 특정 task에 직접 활용할 수 있는 명시적인 GT값이 없으니 새로운 task를 정의해 학습하는 방법을 많이 사용합니다. pretext task를 활용하거나 contrastive learning 등 다양한 방법을 이용해서 모델이 이미지 데이터에 대한 특징과 표현력을 학습할 수 있도록 활용하고, 이렇게 학습한 파라미터를 transfer learning하여 downstream task에 적용해 fine-tuning하는것이 일반적인 프레임워크 구조입니다. 주로 제안되는 굵직한 방법론들의 성능 싸움은 ImageNet classification 부분에서 이루어졌는데, classification task의 경우 이미지의 spatial한 특징이 중요하지 않다 보니 detection이나 segmentation과 같은 이미지의 부분적인 요소를 고려하는 dense prediction task를 위한 방법론들이 필요하다는 목소리가 꾸준히 있어 왔고, 몇몇 방법론들이 제안되어 왔습니다.
Object Detection은 컴퓨터 비전에 있어 기초적이고 중요한 task이지만, 좋은 모델을 학습시키는데는 사람이 annotation한 양질의 대규모 데이터셋이 필요합니다. 원하는 응용 분야에 알맞는 데이터셋을 구축하는데는 시간과 비용이 많이 소요되며, 사람의 사진이나 의료 영상과 같은 보안이나 프라이버시에 민감한 분야에서는 적절한 데이터를 수집하는 것부터 어려울 수 있습니다. 다행이도 최근에 Self-Supervised Representation Learning 기술이 많이 발전해 이미지에 대한 적절한 표현력을 가지도록 학습시키는데 필요한 labeled data 양을 상당히 줄일 수 있었고, object detection 분야도 그 덕을 많이 보았습니다.
이러한 발전에도 불구하고, 저자들은 최근 방법론들이 object detection을 위한 좋은 표현력을 학습하는데 object detection network 전체를(특히 localization 및 region embedding 부분) 학습시키지 않고 visual backbone만 학습시키는 경향이 있기에 그 능력에 제한이 있다고 합니다. SwAV, ReSim, InsLoc과 같은 당시에 제안된 최신 방법론들은 detection network를 사전학습 시키는데 이미지 분류 기반 사전학습과 동일하게 CNN backbone만을 초기화 하였습니다. 당시 UP-DETR이라는 방법론이 detection 구조 전체를 사전학습시키기는 했지만 이미지에서 object를 localize하지 않고 random image region을 활용한다는 한계점이 있었다고 합니다.
본 논문에서 저자들은 기존 사전학습 방법론들과는 다르게 object를 동시에 localize / encode하는 방법을 배우는 unsupervised pretraining 방법인 Detection with Transformers using Region priors (DETReg)을 제안합니다. DETReg는 물체의 위치를 찾는 object localization task와 물체의 시각적 요소들을 인코딩하는 object embedding task을 포함하여 detection network 전체를 사전학습 하도록 합니다. 이 방법으로 사전학습을 한 뒤 마지막 object classification head를 적은 수의 label로 미세조정하면 기존 방법론들보다 좋은 성능을 달성할 수 있다고 합니다.

Figure 1은 기존에 제안되었던 방법론인 SwAV와 UP-DETR을 저자들의 DETReg와 정성적으로 비교한 그림입니다. SwAV와 같은 Self-Supervised 사전학습 방법은 detector의 backbone만 초기화하기 때문에 이후 검출기의 localization 부분은 랜덤 초기화를 해야 합니다. 기존에 제안되었던 UP-DETR의 경우에는 검출기 전체를 사전학습하기는 하지만 사전학습이 random region을 기반으로 진행되기 때문에 사전학습 이후 의미있는 object localization을 하기는 힘들다고 합니다. 반면 저자가 제안하는 DETReg의 경우는 object-centric pretraining을 통해 검출기 구조 전체를 사전학습하기 때문에 사전학습 이후에 어느정도 object localization 능력을 갖출 수 있다고 설명합니다.
DETReg의 object localization task는 class-agnostic한 bounding box의 학습에 활용하기 위해 간단한 region proposal 방법을 사용합니다. 여기에는 학습용 데이터가 조금만 필요하거나 아예 필요 없으며, 높은 recall을 가질 수 있는 방법을 활용할 수 있습니다. 저자들은 DETReg에 여러 region proposal 방법 중 RCNN에서 사용되었던 selective search 알고리즘을 활용합니다. selective search는 다들 아시다시피 2-stage detector에서 Region Proposal Network가 사용되기 이전 region proposal을 위해 사용되었던 비지도학습기반 영역 제안 알고리즘으로, 색상과 질감 등으로 계층적으로 영역을 합치는것을 반복해 물체가 있을 영역을 제안합니다. DETReg의 사전학습 단계에서는 class-agnostic한 detector 학습을 위해 이러한 region priors를 활용합니다.
DETReg의 object embedding task는 object region에서 추출된 각 self-supervsed image embedding을 예측하는 것을 목표로 합니다. SwAV와 같은 self-supervised image encoder는 변환 불변한 임베딩을 학습하므로 detector가 이러한 값들을 예측하도록 학습하는 것은 불변성을 detector의 임베딩에 distill하게 할 수 있다고 합니다. 따라서, object embedding head는 translation이나 image cropping과 같은 변환에 강건한 representation을 학습할 수 있다고 있다고 설명합니다.
저자들은 DETReg 방법론을 MS COCO, PASCAL VOC, aerial images dataset, Airbus Ship Detection과 같은 벤치마크에서 평가를 진행했으며 baseline들보다 성능이 개선되었고 특히 anotated data의 양이 적을 때 좋은 결과를 보였다고 합니다.
Related Work
related work 부분에서는 Self-Supervised Learning, DETR, Region Proposal에 대해 소개합니다. 간단하게 살펴보고 넘어가도록 하겠습니다.
Self-Supervised Learning
최근 제안된 Self-Supervised Learning 방법론들은 supervised learning 방법으로 학습된 것만큼 좋은 transfer learning 결과를 보여줄 만큼 발전했습니다. 하지만 이렇게 학습된 representation은 image classification에는 잘 전이되지만 object detection이나 instance segmentation같은 인스턴스 수준의 task에는 분류만큼 큰 개선을 보이지 못했다고 합니다. 이에 object detection에 대한 적용을 고려한 사전학습 방법들이 제안되고 있기는 하지만 대부분 backbone만을 사전학습하는 방법들이었습니다. 이러한 방법론들과는 달리 저자가 제안한 방법론은 detection network 전체를 사전학습합니다. 이미지 패치 기반으로 백본만을 사전학습 하는 방법으로는 모델이 이미지의 어느 위치에 어떤 object가 있는지 학습하는데 한계가 있습니다. 저자들은 region priors를 이용한 weak supervision을 도입해 이러한 부분을 개선했다고 주장합니다.
End-to-end object detection
DETR은 트랜스포머 구조를 기반으로 기존 detector들이 갖고 있던 anchor generation, NMS, 후처리와 같은 요소들을 없애 end-to-end object detection이 가능하도록 고안되었습니다. 하지만 모두 알고 계시듯 오리지널 DETR은 수렴속도가 매우 느리고 작은 물체에 대한 검출 능력이 떨어지기에 DETR에 deformable attention module을 도입해 이런 문제를 완화한 Deformable DETR이 제안되었습니다. DETR은 이미지 패치에 대한 특징 벡터를 attention과 feed-forward layer를 반복적으로 거치게 해 N개의 object를 검출합니다. 여기서 N은 사전에 설정된 최대 검출 개수이고, 만약 이보다 적은 물체가 검출된다면 검출되지 않았다고 패딩됩니다. 디코더의 마지막 계층에서는 N개의 image-dependent query embedding 벡터를 출력하고 , 각 벡터는 bounding box 좌표와 object category를 예측하는 head를 통과해 detection을 수행합니다. 학습 과정에서는 GT set과 prediction set 간 이분 매칭이 이루어져 학습됩니다(배경에는 no object로 매칭됩니다)
Region proposals
detection 및 localization task에 있어 region proposal 방법론들은 오랜 기간 많은 연구가 진행되었다고 합니다. 특히 grouping 기반 방법론인 Selective Search와 window scoring 기반 방법인 Objectness 방법론은 널리 알려져 있고 OpenCV와 같은 주요한 라이브러리에서 지원하기 때문에 활용하기 쉽다고 합니다. 이 중 selective search 방법은 superpixel을 greedy한 방법으로 각 영역의 색상, 질감, 엣지 등의 연속성을 기반으로 반복적으로 병합하여 proposal을 생성하는 방법이고, Objectness는 multi-scale saliency, color contrast, edge density와 같은 시각적 단서를 활용해 영역을 제안하는 방법론입니다. 저자들은 해당 분야가 학습 기반 방법론들로 그 트렌드가 많이 이동하긴 하였지만, 학습 데이터를 아주 조금 필요로 하거나 아예 필요로 하지 않는다는 점에서 여전히 이점이 남아있다고 합니다. selective search를 채택한 이유가 궁금했었는데 Hosang et al이 예전에 다양한 region proposal 방법론들은 조사하였을 때 Selective Search가 recall 부분에 있어 가장 좋은 결과를 보였기 때문이라고 하네요. 따라서 저자들은 weak supervision으로 사용한 영역을 생성하는데 selective search 방법론을 사용합니다. 알고리즘 적용의 목표가 좋은 region을 proposal하는 것이기에 selective search가 아닌 다른 방법을 사용해도 상관은 없다고 합니다.
Method
DETReg
DETReg는 object detector를 region localization 및 embedding 부분까지 포함하여 전체를 사전학습 할 수 있는 self-supervised learning 방법입니다. 전반적으로는 unsupervised region proposal generator(selective search)로 만든 proposal과 모델이 예측한 object localization을 매칭하는 동시에 feature embedding을 대응하는 self-supervised image encoder에서 나온 embedding에 정렬합니다. 해당 프레임워크의 키 아이디어는 DETReg가 사전학습하는 pretext task를 지도학습 방법으로 object detector를 학습하는것과 비슷하게 설계해 object detectior로 사전학습한 representation을 전이하는 것을 용이하게 했다는 것입니다.

Object Localization Task
DETReg의 object localization 사전학습 단계에서는 class-agnostic한 bounding box supervision을 위해 간단한 region proposal 방법인 selective search를 사용합니다. region proposal 방법론으로 image로부터 높은 recall의 region proposal set을 얻습니다. 이렇게 얻어진 region proposal은 recall은 높지만 클래스 카테고리 정보는 가지고 있지 않으며 precision은 낮습니다. 우리가 관심 있는 object뿐만이 아니라 배경의 다양한 요소들에 대한 region도 generate하는것에 대해서 저자들은 모델이 다양한 부분들을 볼 수 있으므로 noisy한 라벨이 있을때에도 시각적 요소들을 잘 학습할 수 있을 거라고 설명합니다. 제한된 물체뿐만 아니라 다양한 요소들을 사전학습 단계에서 볼 수 있으니까 더 풍부한 표현력을 갖출 수 있긴 하겠네요. 이렇게 생성된 unsupervised region proposal들을 가지고 detector의 box prediction과 비교해 loss가 작아지도록 학습합니다. DETR의 Bipartite Matching을 region proposal로 생성한 수도 라벨로 수행한다 라는 느낌이네요.
Object Embedding Task
object detector의 지도학습에서는 모든 박스에 객체의 class category가 주어지지만 unsupervised learning에서는 이 정보를 활용할 수 없습니다. 저자들은 이에 이를 학습하지 않고, object embedding 자체를 학습하도록 합니다. 각 box region bi를 따로 encoder를 태워 embedding zi를 얻고 이를 DETReg 임베딩의 target으로 활용합니다(Figure2의 검정 화살표). 인코딩 네트워크는 BYOL이나 DINO와 같은 방법으로 함께 학습할 수 있긴 하지만, 저자들은 학습의 안정성을 위해 image transformation에 강인한 사전학습된 SwAV pretrained model을 사용하였다고 합니다. object embedding z를 예측하기 위해서 DETR query embedding vi를 object embedding zi로 변환시키는 MLP를 추가적으로 도입하였고, L1 loss를 활용하여 DETR query를 임베딩한 것과 region proposal을 encoder에 태워 얻은 임베딩을 학습하였습니다.
DETReg Pretraining
DETReg는 3가지 prediction head를 갖고 있습니다(Figure2 참고). bounding box를 예측하는 f_box, box가 object일지 배경일지 예측하는 f_cat, 그리고 object embedding을 만드는 f_emb입니다. DETR의 특성상 학습 과정에서 box의 개수 M보다 DETR query 개수 N이 항상 커야 하며, 각 box의 라벨은 {0,1}중 하나로 할당됩니다. 각 박스가 region proposal이면 1, padded proposal이면 0입니다. 이제 region proposal 및 사전학습된 인코더에서 출력된 박스 좌표, 카테고리, 임베딩 벡터 튜플을 DETR의 출력과 매칭하면서 학습을 진행하게 됩니다. 매칭은 DETR의 학습과 동일하게 헝가리안 알고리즘을 사용한 이분 매칭으로 진행됩니다.

L_match는 DETR 및 Deformable DETR의 학습에서 사용되었던 pairwise matching cost matrix입니다. σ는 permutation으로, 최적의 matching cost에 해당하는 매칭이라고 생각하시면 됩니다. 최적의 σ를 사용하여 loss는 다음과 같이 구성됩니다:

L_class는 cross-entropy 혹은 Focal loss로 구현된 class loss이고, L_box는 L1 loss 및 GIoU loss기반으로 만들어진 bounding box loss입니다(DETR의 학습 loss를 생각하시면 됩니다) 마지막으로 L_emb 은 위에서 언급했듯 L1 loss를 사용하여 다음과 같이 정의됩니다.

Experiment
기본적인 세팅으로는, 우선 DETReg의 백본을 SwAV기반 ResNet50을 사용했으며 f_emb 및 f_box의 MLP는 256차원의 2계층 MLP로 구성했다고 합니다. output size는 f_emb가 512이고 f_box가 4(좌표값)입니다.
사전학습 데이터셋으로는 ImageNet-1K를 사용했고, 벤치마크로 MS COCO, PASCAL VOC, Ship Detection dataset, Airbus dataset이 사용되었다고 합니다. detector로는 DETR 및 Deformable DETR이 사용되었으며, 비교군으로는 기존에 DETR 벤치마크 중 SwAV 및 UP-DETR이 사용되었습니다.

Table 1의 결과, MS COCO 벤치마크에서 DETReg가 일관적으로 다른 사전학습 방법론들보다 좋은 성능을 보여줍니다. selective search를 활용하는게 너무 나이브한 방법이 아닌가 생각했었는데 DETR의 학습과 유사한 사전학습 프레임워크를 구성해서 그런지 꽤 성능이 좋네요.

Table 2는 PASCAL VOC 및 Airbus Ship dataset에 대한 Object detection finetuning 결과입니다. 여기서도 DETReg가 다른 방법론들보다 좋은 성능을 보여줍니다. 개인적으로 왜 UP-DETR이 빠졌는지 궁금한데, 딱히 언급이 없네요. 실험을 따로 안해봤거나 성능이 딸려서 빼지 않았나 개인적으로 추측해봅니다
Object Detection in Low-Data Regimes
해당 실험에서는 annotation data가 적은 세팅에서 DETReg가 얼마나 잘 작동하는지 보여줍니다. Deforable DETR로 ImageNet-1K로 5epoch 사전학습 했을 때의 세팅이라고 합니다.

해당 실험에서의 다른 비교군인 InsLoc, ReSim은 모두 Object Detection을 고려한 사전학습 방법론들입니다. 학습 데이터가 현저히 적을 때부터 8192개가 될 때까지 DETReg가 다른 방법론들보다 좋은 AP를 보여줍니다.
Few-shot Object Detecion

Few-Shot Object detection 실험은 Deformable DETR을 ImageNet-1k에 대해 5epoch 사전학습 시킨 상태로 수행되었습니다. 모델은 60 base class에 대해 학습되었으며 20 novel category에 대해 성능이 평가되었습니다. Table3을 참고하면 DETReg가 small backbone에서는 가장 좋은 성능을 달성했으며, large backbone에서도 30shot result에서는 SOTA를 달성했습니다(10shot은 성능이 아쉽네요). 다른 방법론들은 학습을 위해 복잡한 기법을이 들어갔지만, DETReg은 단순한 finetuning만 가했다고 합니다.

Table 4에서는 DETReg로 학습했을 시 model이 풍부한 base class data로 학습하지 않았더라도 경쟁력있는 few-shot 성능을 달성할 수 있음을 보여줍니다. TFA는 abundant base class data로 훈련된 기존의 finetuning 방법인데 DETReg가 base class data에서 추가적인 supervision 없이 이를 능가하는 것을 어필합니다.

Table 8은 기존에 제안된 다양한 방법론들과 pascal voc benchmark에서 비교한 전체 table입니다. detector는 Faster-RCNN, DETR, Deformable DETR이 사용되었습니다. 다양한 사전학습 방법론들과 Deformable DETR 조합에서 저자들이 제안한 DETReg가 가장 좋은 결과를 보여줍니다.
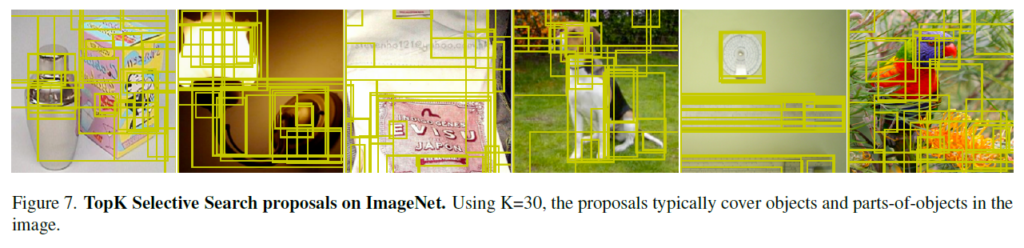
Figure 7 은 Selective Search 결과로 생성된 proposal을 시각화 한 것입니다. 비지도 학습 방식으로 질감, 색상, 엣지 등의 연속성을 기반으로 슈퍼픽셀을 통합하며 만들어진 proposal들인데, object가 아닌 다른 부분도 많이 잡고있긴 하지만 object에 집중해서 제안하는 경향을 보입니다.
Conclusion
DETR을 활용하는 Self-Supervised Learning 논문을 처음 읽어보았습니다. 기존의 방법들과는 다르게 DETR의 학습 방법을 차용한것이 꽤나 새로웠습니다. 다음에는 해당 논문에서 비교되었던 UP-DETR을 읽어 볼 예정입니다.
감사합니다.
안녕하세요 허재연 연구원님 리뷰를 읽다 질문이 있어 댓글 남깁니다.
해당 논문은 저자가 제안하는 DETReg는 그동안 괄시(?)받던 Locailization Head 초기화 부분을 다룬 Self-supervised learning 기법을 다룬 것 같습니다.
Object Localization Task 설명하는 부분에 대한 질문입니다.
“우리가 관심 있는 object뿐만이 아니라 배경의 다양한 요소들에 대한 region도 generate하는것에 대해서 저자들은 모델이 다양한 부분들을 볼 수 있으므로 noisy한 라벨이 있을때에도 시각적 요소들을 잘 학습할 수 있을 거라고 설명합니다.”
라고 하셨는데, Object 가 아닌 영역에 박스를 친 부분에도 도움되는 정보가 있다는 것 같습니다.
다만 Selective Search 결과를 보면 과하게 많은 영역에 박스쳤던 것이 생각나서..
(1) 그냥 무자비하게 많은 박스가 모두 도움이 된다는 것인가요?
(2) 이를 증명하기 위해서는, Object box만으로 학습한 것과 Nosiy라고 불리는 box로 학습한 것을 비교하는 등 근거가 필요할 것 같습니다.
이에 대한 설명이 있나요? 설명이 없다면, 논문에는 그냥 쓰는 말은 없을텐데 저자는 어떤 이유에서 그런 주장을 한 것인가요?
(3) 다음 리뷰에는 본 논문과 관련 없는 DETR의 Bipartite Matching 과 같은 내용이 나온다면 이게 어떤 방식인지, 아주아주 간단하게라도 다뤄주면 이해하는 데 더 좋은 리뷰가 될 것 같습니다.
(4) Ablation Study에 Selective Search를 통한 Localization Head 학습 여부에 대한 성능은 없나요? 얼마나 성능 향상을 가져왔는지 궁금해지네요.
(5) 마지막으로 Selective Search도 특정 Threshold가 있는 것으로 아는데 Threshold 차이에 대한 성능은 없나요?
Experiment 부분이 조금 빈약한 것 같아서 다음에는 보다 더 풍성하게 다뤄주시면 좋을 것 같습니다
(CVPR인데 실험이 이것밖에 없지는 않겠죠?)
(1) 해당 부분에서 region proposal method로 생성된 box들은 높은 recall을 보여주기는 하지만 낮은 precision을 갖는다고 합니다. 해당 부분에서 정확히는 ‘non-object box들의 content가 object box들보다 더 다양하기 때문에 모델이 noisy label이 주어졌을 때에도 시각적 특성을 인식을 수 있게 훈련될 것으로 예상된다’ 라고 합니다. region proposal이 object가 아닌 다른 영역을 많이 제안하지만 그렇기에 object가 아닌 영역의 visual content도 충분히 학습이 가능하다는 뜻으로 받아들였습니다. 이런 맥락에서는 다양한 박스를 활용하는 것이 다양한 시각적 상황 정보를 줄 수 있다고 볼 수 있을 것 같습니다.
(2) 저도 해당 부분이 궁금해서 추가적으로 언급한 부분이 있나 찾아봤는데, 해당 부분에 대한 추가적인 언급이나 실험은 없었습니다. 본문에서도 이에 대해 단언하기보다는 ‘모델이 이러한 부분을 학습할 수 있을 것이라 예상된다’라는 언급 이외에 추가적인 설명은 없었습니다. 주장이라기보다는 저자들의 추측에 가까운 것 같습니다.
(3) DETR은 object detection 문제를 bounding box와 category라는 set G={(B0,C0),(B1,C1),…,(Bn,Cn)}를 예측하는 set prediction task로 정의합니다. 이 때 기존의 detector들과 달리 priors가 없으니 GT set과 모델의 예측 set 간 매칭을 하는 방법이 필요한데, 이 일대일 대응을 찾는 방법이 이분 매칭(bipartite matching)입니다. DETR에서는 이 방법으로 헝가리안 알고리즘을 사용합니다. 이후 리뷰에 이런 부분들이 있다면 언급하고 넘어가도록 하겠습니다.
(4) region proposal 방법들에 대한 localization head 학습에 대한 ablation은 딱히 없었습니다. 사실 related work에서 objectness라는 다른 proposal 방법도 소개하고 region proposal에는 다른 방법을 사용할 수도 있다고 설명하기에 적어도 objectness라는 방법에 대한 비교 실험이 있기를 기대했는데.. 없어서 아쉬웠습니다. selective search 적용 여부에 따른 학습 후 성능 차이가 아닌, selective search와 DETReg의 검출 결과 비교는 있었네요.
(5) selective search의 threshold에 대한 언급은 따로 없었습니다. 라이브러리의 디폴트 값을 사용한 것 같습니다. top-k의 k값은 30으로 설정되어 있었습니다.
experiment 부분이 빈약다고 느껴 추가했으며, 이후에는 더 자세히 다루도록 하겠습니다.
안녕하세요. 리뷰 잘 읽었습니다.
1) Pretraining 과정에서 Padded proposal이란 무엇인가요?
2) DETR에서는 Hungarian matching이 활용되었는데, 설명 중에 pairwise matching이 Hungarian matching을 의미하나요? 아니면 다른 방식인가요?
(1) 매칭에 대한 pseudo label에서 selective search로 지정되지 않은 부분이라고 생각하시면 될 것 같습니다. DETR query N개에 대해서, N개의 tuple을 얻기 위해 y를 패딩한다고 이해하시면 됩니다.
(2) 이 논문에서 이분 매칭을 위한 방법은 DETR과 동일하게 hungarian algorithm이 사용되었습니다.
안녕하세요. 좋은 리뷰 감사합니다. Region proposal 방식으로 selective search를 선택한 이유로 이전 선행 연구에서 여러 region proposal 방법론을 조사했을 때 selective search가 recall 부분에서 가장 좋은 결과를 보였기 때문이라고 했는데 그때 selective search와 같이 비교된 방법론들이 무엇인지 궁금합니다. 이 region proposal 방법론은 보통 recall을 기준으로 성능을 판단하는 것인가요 ? 또 본 논문에서 이런 다양한 region proposal 방식에 대한 ablation study는 없었는지 궁금합니다.
감사합니다.
What makes for effective detection proposals? 라는 논문에서 selective search 및 다양한 region proposal 방법을 비교합니다. 저도 잘 몰랐는데, 찾아보니 Bing, CPMC, EdgeBoxes, Dndres, Geodesic, MCG, Rahtu .. 등등 다양한 기법들을 비교하였습니다. 이런 proposal들은 object를 담고 있어야 하니 recall이 중요한 평가 지표가 된 것 같습니다. 모든 proposal 전략은 selective search를 사용했으며, 다른 방법들에 대한 ablation은 없었습니다.
감사합니다.