Introduction
Speech Emotino Recognition은 사용자의 음성에서 감정을 인식하는 task로, SER 기술은 Human-computer Interaction 분야에서 사용자 친화적인 환경을 구축하기 위해 사용된다고 합니다. 초기 SER 연구에서는 supervised learning으로 학습된 CNN, 혹은 RNN 모델을 통해 input audio의 spectrogram으로부터 emotional 특징을 추출하고자 하였습니다. 그러나 Automatic Speech Recognition과 같은 음성 task에서 사용되는 모델의 size가 증가하였고, 기존의 음성 감정 데이터셋은 이러한 대규모의 모델을 Supervised 방식으로 학습시키기에 충분하지 않았기 때문에, 데이터 부족 문제를 해결하기 위해 SER task는 Transfer Learning을 통해 large pretrained model을 fine-tuning하는 방식으로 수행되었습니다.
또 다른 접근 방식은 Multi-task Learning인데요, SER에서 Emotion은 음성에 내재된 단어의 의미, 억양, 발화자의 성별이나 발화 style 등 여러 요인의 영향을 받습니다. 이에 따라 기존 SER은 모델에 감정과 연관성이 있는 여러 요인에 대한 정보를 학습시키기 위해 SER과 관련된 다른 음성 task를 동시에 학습하였습니다. 그 중 Cai et al은 wav2vec 2.0 모델을 기반으로 ASR과 SER을 결합한 MTL 방법을 제안하였고, 언어적 정보를 학습하기 위한 ASR과의 MTL이 SER의 성능을 개선할 수 있음을 보였습니다.
그러나 ASR과 SER, 혹은 다른 attribute에 대한 recognition task의 target은 서로 다르기 때문에 이를 동시에 최적화 하고자 하는 MTL에서는 필연적으로 gradient conflict가 발생하게 됩니다. 예를 들어, ASR의 경우 음성 신호에서 text를 예측하는 것이기 때문에 언어적인 정보를 포함 할 수 있는 정도의 high-level feature를 학습하고자 합니다. 그러나 언어 정보는 speech의 style 혹은 gender와는 독립적이므로, 해당 task는 언어 정보가 아니라 보다 low-level feature를 학습하고자 할 것입니다.
이러한 conflict 문제를 해결하기 위해, 저자들은 two-stage finetuning 방법을 제안하였습니다. 1st stage에서는, 사전 학습 모델의 모든 파라미터를 SER과 ASR 작업에 맞게 fine tuning하여 모델이 언어 정보와 감정 정보를 추출하도록 학습합니다. 2nd stage에서는 앞 stage에서 ASR에 맞게 tuning된 main Transformer 모델의 파라미터를 고정시키고, gender recognition, style recognition, SER을 위한 adapter를 추가하여 다시 fine-tuning을 진행하였습니다. 저자들은 해당 방법이 IEMOCAP 데이터셋에서 기존의 단순 MTL 방법보다 SER 성능을 크게 향상시킬 수 있음을 실험을 통해 입증하였습니다.
Method
아래의 그림이 논문에서 제안하는 2stage finetuning 기법에 해당합니다.

Single-statge finetuning with MTL
먼저 일반적으로 사전 학습 모델을 MTL 방법론을 사용하여 fine tuning하는 과정에 대해 설명드리겠습니다. 논문에서는 main task인 SER 이외에도 감정 feature를 효과적으로 학습하기 위한 auxiliary tasks를 도입하였으며, 그 종류로는 ASR, gender recognition, style recognition을 사용하였습니다. ASR은 익히 아시는 바와 같이 입력 음성에 대응되는 text를 예측하는 것이며, gender recognition은 발화자의 성별을 예측하는 이진 분류 task이고, style recognition 역시 이진 분류 task로서 해당 음성이 지시된 연기(acted)인지 즉흥 대화(spontaneous)인지 예측하는 task입니다.
MTL은 위의 여러 task를 [그림 1]의 transformer layer와 같이 공통된 모델을 통해 수행하는 것이 됩니다. 어떠한 입력 audio의 waveform U가 주어지면, Transformer 레이어 f \in \mathbb{R}^{t \times d}에서 여러 task에 공통적으로 사용되는 latent feature를 추출합니다. 여기서 t는 utterance의 길이이고, d는 Transformer 레이어의 hidden dimension을 의미합니다.
논문에서 ASR은 FC layer를 통해 학습되며, loss로는 CTC를 적용하였다고 합니다. 또한 emotion, gender, speaking style recognition에는 시간 차원에 대해 mean-pooling을 적용하고, 각 task에 대해 별도의 FC layer을 사용하였으며, 각각의 FC 레이어에 대해 Cross-Entropy를 사용하였습니다. 이에 대한 각 task의 loss를 수식으로 나타내면 아래와 같습니다.

위의 [수식 1],[수식 2]에서 y_{\text{ASR}}는 input audio의 text label), y_e, y_g, y_s 는 각각 emotion, gender speech style의 클래스를 의미합니다.
MTL의 목적 함수는 main task와 auxiliary task 각각의 loss를 가중합한 것으로 구성됩니다. 본 논문의 main task인 emotion recognition과 다른 task간의 loss를 가중합한 MTL의 loss는 아래의 [수식 3]과 같이 나타낼 수 있습니다.

Adapters
본 논문에서는 사전학습 모델을 fine tuning 시 이전 모델의 파라미터는 학습하지 않는 대신, 모델 중간에 레이어를 추가하여 추가된 레이어만 학습하는 adapter를 사용하였습니다.
[그림 1]을 보시면 stage 1에서 학습된 모델은 stage2로 넘어갈 때 adapter가 추가되고, 동일한 구조의 adapter가 fc레이어 이후에도 추가되는 것을 볼 수 있습니다. 논문에서는 아래 그림의 오른쪽 부분과 같이 사전 학습된 transformer 레이어에 Bottleneck adapter와 Low rank adaptation을 추가하였습니다.

Proposed two-stage finetuning
논문의 저자들은 MTL을 사용하면 여러 task로부터 풍부한 정보를 학습할 수 있어 SER의 성능 향상에 도움이 될 수 있지만, 그 과정에서 여러 task의 learning objective, gradient magnitude를 조정하는 것이 challenge함을 언급하였습니다.
음성 데이터로 사전 학습된 large model의 경우 대부분 transformer를 기반으로 하고 있으며, 이러한 large pretrained model의 transformer layer는 음성의 언어적인 정보에 집중하는 경향이 있다고 합니다. 그러나 이러한 언어 정보는 음성 발화자의 gender 혹은 style과는 관련이 없기 때문에 언어 정보에 집중하는 ASR과 gender/style recognition task를 동시에 학습할 경우 learning object간의 충돌이 발생하게 됩니다. 이에 논문에서는 서로 다른 task에 대한 fine tuning을 단계별로 진행하는 two-stage finetuning 방법을 제안하였습니다.
첫 번째 stage에서는 [그림 1]의 좌측과 같이 pretrained model을 SER과 ASR에 finetuning시킵니다. 여기에서는 SER을 main task로, ASR을 보조 task로 사용하는 MTL방식의 fine tuning을 통해 언어 정보와 감정 정보를 transfomrer 기반의 모델에 embedding을 진행하였다고 합니다. 첫 번째 stage의 loss funciton은 아래의 [수식 4]와 같습니다.

두 번째 stage에서는 첫 stage에서 tuning된 모델을 freeze하고 adapter를 추가한 뒤 추가된 adapter에만 emotion, gender, style recognition task에 대한 학습을 진행합니다. adapter는 [그림 1]의 우측과 같이 앞 stage에서 학습된 transformer의 내부와 fc 레이어 직전에 위치하게 됩니다. 저자들은 새로운 task로 fine-tuning을 진행하여도 SER과 ASR에서 학습된 언어 및 감정 정보를 유지하도록 이와 같은 구조를 설계하였다고 합니다. 두 번째 stage의 loss funciton은 아래의 [수식 4]와 같습니다.

Feature fusion and self-contrastive loss
앞서 introduction에서 style과 gender는 emotion에 관련이 있는 특징이라고 말씀드렸습니다. 저자들은 이러한 감정과 관련된 음향 정보를 SER에 최대한 활용하기 위해 gender recognition 및 style recognition 모듈에서 도출된 latent feature x_g, x_s를 emotion classifier에 입력하였습니다. 이를 통해 감정을 예측할 때 style과 gender 정보를 직접 활용할 수 있었다고 합니다.
또한 추가로 self-contrastive loss(SCL)을 도입하여 emotion, gender, style의 latent feature에 해당하는 x_e, x_g, x_s의 embedding space를 align하였다고 합니다. 이는 input feature가 동일한 음성으로부터 학습되었기 때문에 각 task의 output feature들이 동일한 emotion category를 가진다는 점을 바탕으로, intra-class feature 간의 거리를 줄이는 방식으로 수행되었습니다. 제안된 SCL은 distance를 구하는 방식에 따라 SCL_{norm}과 SCL_{cos}의 두 가지이며, 각각은 아래의 [수식 6], [수식 7]과 같이 나타낼 수 있습니다.


두 번째 stage의 최종 loss는 [수식 5]에서 구한 L2에 SCL loss 중 하나를 더하는 것으로 구성됩니다.
Experiments
Dataset & Implementation details
논문에서는 실험에 IEMOCAP 데이터셋을 사용하였습니다. IEMOCAP은
Comparison of adaptation methods in single-stage finetuning
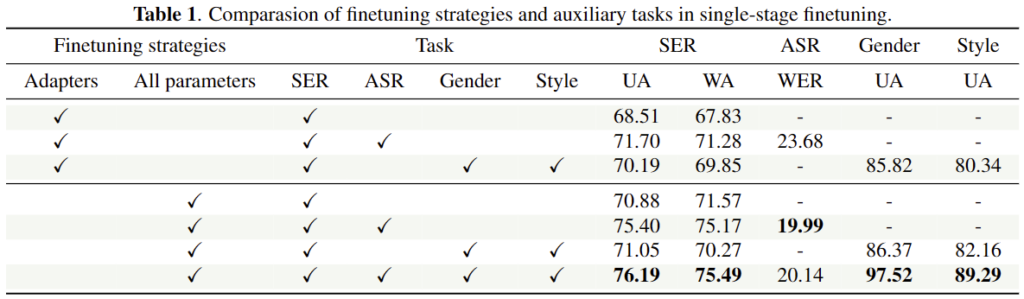
[표 1]은 다양한 task를 활용하여 single-stage 방식으로 fine tuning한 결과입니다. 이때 사전학습 모델의 전체 파라미터를 학습하는 것과 사전학습 모델의 파라미터를 고정하고 adapter만 학습하는 방식을 비교하였습니다.
우선 전체 파라미터를 tuning하는 경우, SER에 대해서만 fine-tuning을 진행하는 것 보다 ASR을 포함하여 학습하였을 때 SER의 UA가 4.52%가 향상된 것을 확인할 수 있습니다. 논문에서는 이를 퉁해 transformer를 ASR에 대해 학습시킴으로써 언어 정보를 embedding하는 것이 SER에 도움이 된다는 것을 강조하였습니다.
adapter tuning 방식을 사용하였을 때, 마찬가지로 ASR+SER인 경우에 성능 향상이 있었으나 Transformer 전체를 tuning했을 때보다는 낮은 성능을 보이는 것을 확인할 수 있습니다.
Results of two-stage finetuning with adapters

다음으로는 논문에서 제안하는 2-stage fine tuning에서 학습 전략에 따른 성능을 확인하기 위한 실험으로, 총 세가지의 setting으로 평가를 진행하였습니다. 먼저 setting1은 stage1, 2 모두 adapter에 대한 tuning만 진행하고, setting2에서는 두 stage 모두 모델 전체를 tuning하는 방식을 사용하였습니다. 마지막으로 setting3는 stage 1에서는 모델 전체를, stage 2에서는 adapter를 사용하였습니다.
[표 2]의 결과를 확인해 보면, setting 1에서 adapter tuning만 사용하는 경우 성능이 좋지 않았는데, 논문에서는 그 이유로 ASR에는 Transformer의 fine-tuning이 필수적으로 수행되어야 하기 때문이라고 하였습니다. 또한, setting 2는 [표 1]의 single stage 성능에 비해 그다지 개선되지 않았는데, 이러한 결과는 stage 1에서 ASR을 통해 획득한 풍부한 언어적 표현을 stage2를 학습하는 과정에서 잃었기 때문이라고 분석하였습니다.
결과적으로 setting 3와 같이 transformer encoder를 고정하고 adapter를 fine-tuning하는 것이 SER에 가장 효과적인 것을 보였습니다. 이는 [표 1]의 single stage 방법론의 최고 성능에 비해 1.04% 상승하였습니다.
Evaluation of proposed feature fusion and SCL

[표 3]은 논문의 feature fusion & self-contrastive loss에 대한 ablation 결과입니다. 이는 1 stage에서는 transformer encoder를 SER과 ASR에 대해 fine tuning하고, 2 stage에서는 gender recognition과 style recognition을 SER의 보조 task로 사용하여 adapter tuning을 수행하였을 때 2-stage에 scl의 추가 여부에 대한 실험으로 이해하시면 됩니다.
[표 3]의 결과를 보면, x^e, x^g, x^s를 concatenation방식으로 SER에 포함시키는 것은 x^e만 사용하는 것과 유사한 성능을 달성한 것을 확인할 수 있습니다. 반면에 SCL을 포함시키면 성능이 향상되는 것을 볼 수 있으며, 논문에서는 이러한 결과를 통해 SER을 위한 구별적인 특징 학습이 효과적으로 진행되었기에 SER의 성능 향상을 달성할 수 있었다고 분석하였습니다. 두 가지의 SCL loss 중에서는 SCLcos_{cos}가 SCLnorm_{norm}보다 더 좋은 성능을 보였습니다.
Comparison with sota approaches

마지막으로 [표 4]는 sota 방법론과의 비교 실험으로 동일한 실험 조건에서 서로 다른 ssl 방법론들을 적용하였을 때의 성능을 비교한 것입니다. 논문의 방식이 가장 뛰어난 성능을 보이는 것을 확인할 수 있습니다.
안녕하세요 천혜원 연구원님 리뷰 감사합니다.
두 번째 스테이지에서 adapter만 fine-tuning 했을 때 overfitting 될 위험은 없나요?
또한, adapter의 크기와 구조가 성능에 어떤 영향을 미치나요?
안녕하세요. 좋은 리뷰 감사합니다.
논문을 읽으면서 궁금한 부분이 있는데, auxiliary task로 ASR, gender recognition, style recognition을 적용했다고 하였는데 왜 이렇게 많은 task를 동시에 학습하고자 했는지에 대해서 조금 의문이 듭니다. 물로 multi-task learning이 본 논문에서 주요한 부분인 것은 알지만, 저렇게까지 많이 할 필요가 있을까? 라는 생각이 들며, 이를 줄였을 때는 성능이 낮게 나오는지에 대해서 궁금해집니다. 혹시 본 논문에서 따로 언급한 것이 있을까요?
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
auxiliary task로 ASR, gener, 그리고 style recognition을 사용했다고 설명해주셨는데, 실험에서는 gender와 style을 각각 추가한 버전은 없는 것으로 보아 혹시 두 task는 보통 같이 합쳐서 이렇게 auxiliary task로 수행되는 것인가요 ? 사실 multi task learning을 위해 이러한 task들을 추가했지만 결과적으로 봤을 때 오히려 Gender와 Style recognition을 추가했을 때 성능이 하락되는 것 같아 오히려 노이즈가 되는 것은 아닌지 의문이 드네요 .. 어떻게 생각하시는지 혜원님 의견도 궁금합니다.
감사합니다.