안녕하세요. de-biasing 방법에 대한 세 번째 논문입니다. 소개했던 앞선 연구에서는 bias 특징을 갖지 않는 bias-conflicting 데이터에 대한 학습 가중치를 높여 de-biasing을 진행했습니다. 그러나 bias-conflicting 데이터는 전체 데이터에서 비중이 매우 적은 경우가 많습니다. 본 연구는 de-biasing의 핵심인 bias-conflicting 데이터를 augmentation을 통해 증강하는 방법을 제시합니다. 그럼 소개를 시작합니다.
논문 소개
앞선 리뷰에서 많이 다루었지만, 처음 글을 접하는 분을 위해 “편향”개념에서 부터 다시 소개하겠습니다
(데이터셋 편향) 딥러닝 모델은 종종 주된 타깃을 학습하면서 그와 강하게 연관된 주변 속성에 의존하여 학습하는 경향이 있습니다. 데이터셋에서 의도하지 않은 속성이 타겟과 연관성을 지닌 현상을 데이터셋 편향(dataset bias)이라고 부르며, 편향된 데이터셋에서 학습된 모델은 일반적으로 새로운 데이터셋에 대해 일반화 능력이 떨어집니다. 예를 들어, 새 이미지를 분류하는 모델이 훈련 데이터에서 새가 주로 하늘을 배경으로 등장하는 것을 학습했다면, 이 모델은 새가 풀밭이나 다른 배경에 있을 때 올바르게 인식하지 못할 수 있습니다. 이처럼 데이터셋 편향의 문제는 모델이 타깃 클래스(예, 새)보다는 편향 속성(예, 하늘)을 더 잘 학습하게 되는 것입니다.
(기존 해결책) 데이터셋 편향이 야기하는 문제를 해결하기 위한 기존 방법들은 특정 편향 유형을 미리 정의해야 한다는 한계를 가지고 있습니다. 예를 들어, 텍스처나 색상과 같은 편향 요소를 사전에 파악하고 이를 기반으로 모델 de-bais를 진행하는 것이 일반적입니다. 그러나 이러한 접근법은 다양한 편향 유형에 일반화하기 어려우며, 새로운 유형의 편향에 대해 효과적이지 않을 수 있습니다. 이에 대한 해결책으로 사전적인 편향 유형 정의 없이 de-biasing 하는 방법으로 bias-conflict 데이터를 탐색하고 이에 대한 학습 가중치를 높이는 방법입니다. bias-conflict 데이터란 편향적 특징을 포함하지 않는 데이터로, 하늘(편향 속성)과 강하게 연관된 새(타깃) 라는 편향을 갖는 데이터셋에서 “하늘에 있지 않은 새” 같은 이미지가 이에 해당합니다. 앞서서 소개한 방법에서는 각 논문이 제시한 Easiness score를 통해 기존 데이터셋에 많이 포함되지 않아 학습하기 어려운 특성을 갖는 bias-conflict 데이터의 가중치를 높였습니다. 한편 해당 논문은 augmentation을 활용하여 학습할 데이터가 충분하지 않다는 bias-conflict 데이터의 활용 정도를 높였습니다. 기존 augmentation 방법과 다르게 해당 논문은 2개의 분리된 Encoder를 통해 고유 속성(intrinsic attributes, 특정 클래스를 고유하게 정의하는 속성)과 편향 속성(bias attributes, 편향를 유발하는 주변 속성)을 명확하게 분리하여 활용하여 de-biasing 성능을 높였습니다.
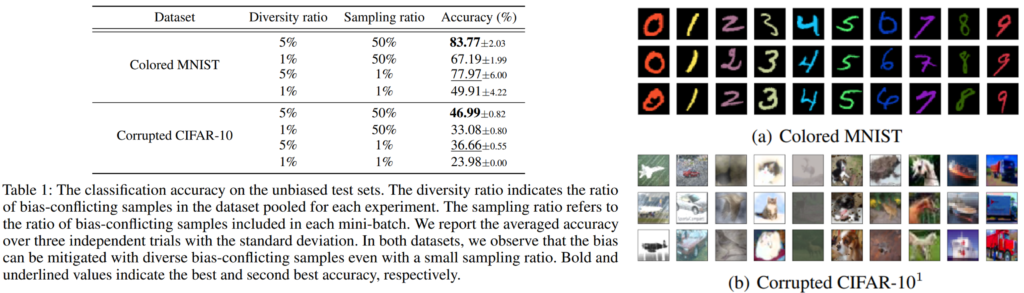
(연구 동기) 본 연구에서는 앞서서 소개했던 연구와 다르게 데이터셋 자체의 다양성을 augmentation을 통해 확장했습니다. 이러한 접근법의 근거로 토이 데이터(Colored MNIST, Corrupted CIFAR-10)를 활용해 de-biasing에서 데이터 다양성의 중요성을 다루었습니다. Colored MNIST, Corrupted CIFAR-10 데이터에 대해서는 앞선 리뷰[Link]에서 활용했던 데이터로, 자료1의 우측에서 볼 수 있듯이 고유 속성을 제외한 편향 속성(a의 색, b의 택스처)을 갖는 데이터셋 편향이 발생한 데이터 입니다. 표에서 Diversity ration는 bias-conflicting 데이터가 전체 데이터셋에서 차지하는 비율을 나타냅니다. 다양성 비율은 1% 또는 5%로 설정되었습니다. 또한 Sampling ration는 bias-conflicting 데이터의 활용 정도로, 각 미니배치에서 포함된 bias-conflicting 데이터의 비율을 나타냅니다. 이 값은 1% 또는 50%로 설정되었습니다. 실험을 통해서 확인할 수 있듯이 bias-conflicting 데이터의 비율이 낮을수록, 단순히 기존의 편향 샘플을 반복하는 것이 아니라 다양성을 높여 더 어려운 편향 상충 샘플을 학습해야 함 확인할 수 있으며, 단순히 bias-conflicting 데이터에 대한 가중치를 높이는것으로 모델 편향 문제를 해결할 수 없음을 알 수 있습니다. 이러한 실험 결과를 통해 논문은 bias-conflicting 데이터를 증강하는 방법으로 de-biasing 방법론을 설계했습니다.
*토이 데이터: 연구에서 현상의 분석을 위해 사용하는 다루고 분석하기 쉬운 작은 데이터
방법론 소개
이 논문에서는 편향을 제거하기 위해 분리된 표현 학습(Disentangled Representation)과 특징 수준의 데이터 증강(Feature Augmentation) 구조를 포함한 방법을 제안합니다. 이 방법의 핵심은 데이터의 본질적 속성과 편향된 속성을 분리하여 학습하고, 이를 활용해 다양한 bias-conflicting 데이터를 생성함으로써 모델의 편향을 해소하는 것입니다. 아래의 Figure 1은 이 방법의 전체적인 흐름을 시각적으로 보여주며, 알고리즘을 통해 전체 프로세스를 확인할 수 있습니다.
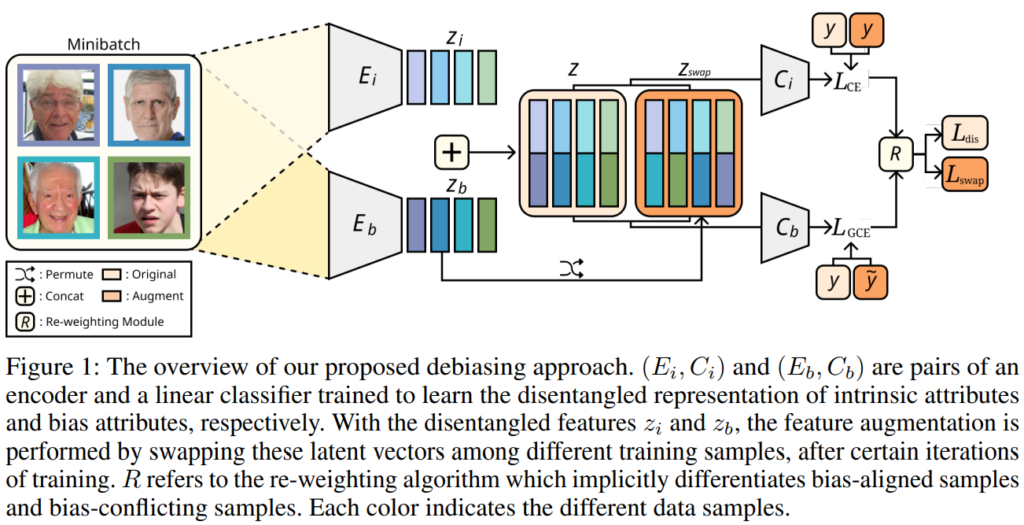

먼저 Figure1에서 확인할 수 있듯이 방법론에서는 데이터셋에 포함된 본질적 속성과 편향 속성을 분리하여 추출하는 두가지 인코더( Intrinsic Encoder (Ei), Bias Encoder (Eb))를 포함합니다. 두 인코더를 활용하여 하나의 이미지가 임베딩 되면, 해당 임베딩 특징을 입력으로 하는 분류기(Linear Classifiers (Ci, Cb))가 타깃 클래스에 대한 예측을 수행합니다. 자세한 학습 방법은 목적함수와 함께 알아보겠습니다.
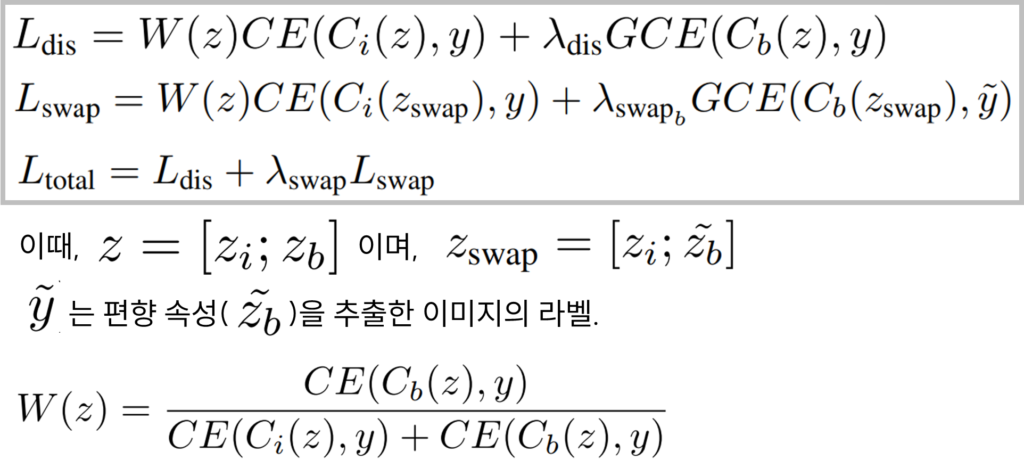
먼저 L_dis은 이미지 xi에 대한 두 인코더의 출력(z_i, z_b)를 단순 결합한 feature로 이미지 xi에 해당하는 라벨 y에 예측이 수렴하도록 학습하며 앞선 리뷰에서 소개한 LfF[Link]와 같이 GCE Loss를 통해 편향 인코더를 학습하도록 했습니다. 또한 고유 인코더가 bias 특징을 학습하지 않도록 LfF에서 제안한 de-biasing 가중치 W를 적용했습니다. 다음으로 L_swap은 feature augmentation을 수행한 feature에 대한 학습을 위해 설계된 Loss 입니다. 해당 Loss는 이미지 xi에 대한 고유 인코더의 z_i과 다른 이미지 xj에 대한 편향 속성 인코더의 출력 z~_b을 결합한 feature에 대한 목적함수로, 고유 인코더 학습을 위해서는 최종 예측이 xi에 대한 라벨인 y와 가까워지도록 학습하고, 편향 인코더 학습을 위해서는 편향된 속성에 집중하도록 최종 예측이 xj에 대한 라벨인 y~와 가까워지도록 설계했습니다. 또한 L_dis와 마찬가지로 Easiness score인 W와 GCE를 활용하여 편향 인코더는 편향 특징에 집중하고, 고유 인코더는 고유적 특징에 집중하도록 설계했습니다. 마지막으로 L_total은 아키텍처의 전체 목적함수입니다. λ는 하이퍼파라미터로 설계한 가중치이며, 이를 통해 두 Loss(L_dis, L_swap)을 결합했습니다.
또한 저자는 고유 속성과 편향 속성의 분리가 정확하지 않은 학습 초기부터 augmentation을 적용하면 swap feature가 학습의 노이즈로 작동할 수 있음을 고려햐여 augmentation을 초기부터 적용하지 않는 scheduling을 적용했습니다. 실험에 사용된 데이터셋(Colored MNIST,Corrputed CIFAR10, BFFHQ) 기준으로 모든 데이터셋에 대해 10K iterations 을 진행하기 전까지 augmentation(L_swap)을 적용하지 않고 L_dis를 통한 모델 업데이트만을 수행했습니다. 이러한 scheduling의 효과는 아래 실험의 Ablation studies에서 확인할 수 있습니다.
실험
본 논문의 실험 부분에서는 제안된 방법의 성능을 검증하기 위해 기존 연구에서 비교를 위해 많이 사용하는 합성 데이터셋인 Colored MNIST,Corrputed CIFAR10와 real-world 데이터셋인 BFFHQ를 활용하여 실험을 진행합니다. 제안 방법론의 우수성을 보이기 위해 기존의 편향 해소 방법들 대비 우수한 성능을 발휘하는지를 확인하는 비교실험(Table2)과 Ablation studies(Table3), 그리고 다양한 시각적 분석들을 포함합니다. 먼저 우수성을 보이는 기존 방법론과의 비교실험을 확인해보겠습니다. Ration는 bias-conflicting 데이터가 전체 데이터에서 포함되는 비율이며 bias types을 사전에 정의하지 않은 직접 비교 방법론(LfF, Vanilla, Table2 상단의 x 표시)에 대해 가장 높은 성능을 보였음을 실험을 통해 보여 우수성을 검증했습니다. (Colored MNIST에서 압도적인 개선 성능을 보인 ReBias는 보다 큰 데이터셋에서 MNIST를 타겟하여 검증되었던 방법으로, 실혐 결과를 통해 다른 데이터셋에 대한 확장은 아직 추가적인 연구가 필요함을 확인할 수 있습니다.)
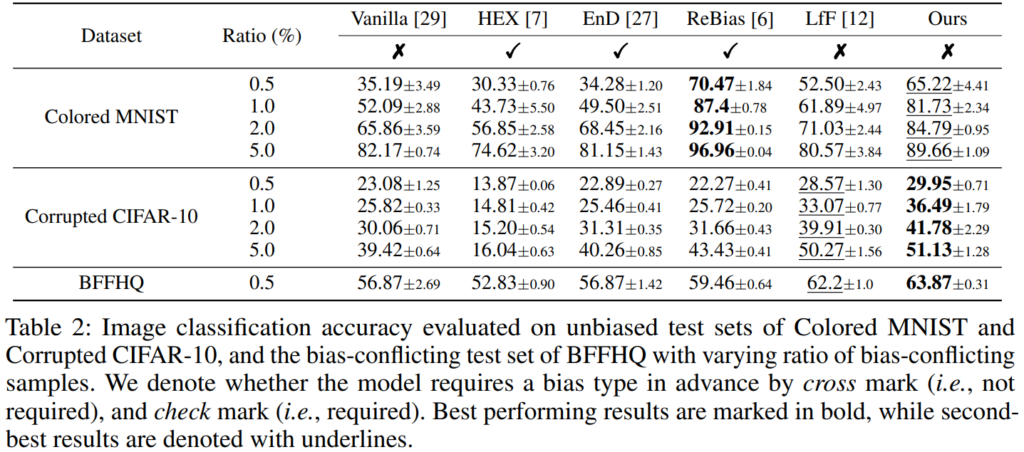
다음으로 Ablation studies 입니다. 제안하는 방법이 실험에 사용된 모든 데이터셋에 대해 일관적으로 성능향상에 기여함을 확인할 수 있습니다. 아래의 실험에서는 특히 본 논문에서 제시하는 것처럼 두 개의 Encoder를 도입하여 분리는 것 만으로도 de-biasing 효과를 낼 수 있다는 점을 확인할 수 있습니다.
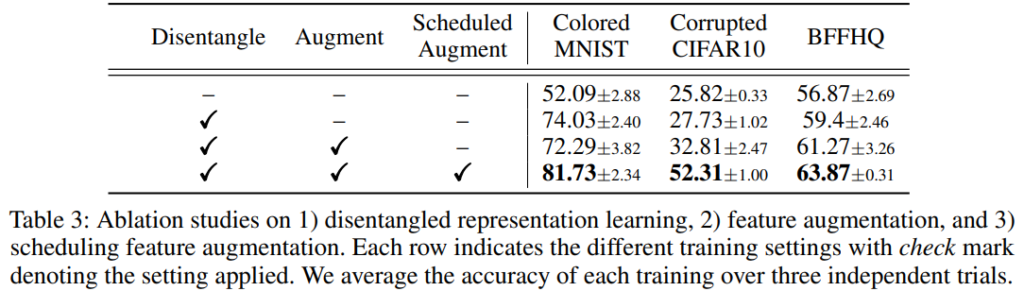
위를 통해 논문에서 소개한 주요 실험 결과에 대한 소개를 마쳤습니다. 다음으로 분석 실험에 대해 소개하겠습니다. 아래의 Figure 4는 제안한 방법에서 Encoder의 효과를 명확하게 확인할 수 있습니다. 행의 header에서 제공하는 편향 특징과 열의 header 에서 제공하는 고유 속성의 결합으로 생성된 결과를 시각화한 결과이며, 학습을 통해 설계된 고유 인코더와 편향 인코더가 의도한대로 동작함을 확인할 수 있습니다.

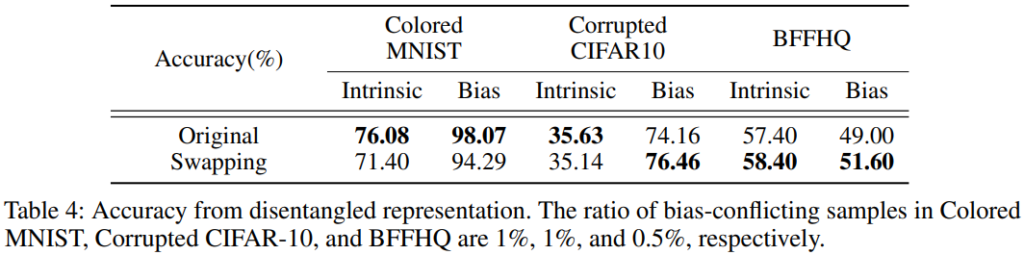
다음은 제안한 encoder 구조를 통한 disentangled representation의 정량적 평가 결과입니다. 비록 작은 데이터셋인 Colored MNIST의 경우 Swapping을 통한 데이터 증강을 적용하지 않은것이 더욱 좋았지만, real-world datasets에 가까워질 수록(BFFHQ) 데이터 증강을 통한 성능향상이 있었음을 보입니다. 또한 각 Encoder가 실제로 클래스와 연관된 어떠한 Feature를 추출함을 확인할 수 있는 실험입니다.
본 리뷰를 마지막으로 세미나에서 다루었던 de-biasing 관련 논문의 소개를 마쳤습니다. 해당 방법론은 앞서 소개했던 것처럼 Augmentation 구조를 통해 편향 문제를 해결하였으며, 설계된 Encoder 구조가 의도와 같이 타깃 고유값(예, “새”와 같이 클래스에 해당하는 정보)과 편향 특징(예, “하늘”과 같이 의도하지 않게 새 클래스와 연관된 정보)을 잘 추출함을 확인할 수 있었습니다. 또한 세미나에 질문에서 나왔던 것, 학습 초기에 encoder 의 출력이 노이즈로 작용할 것을 염두하여 scheduling을 적용했음을 알 수 있었습니다. Augmentation을 활용한 모델 de-biasing에 관심있는 분은 참고하셔도 좋을것 같습니다. 감사합니다.
안녕하세요 황유진 연구원님
좋은 리뷰 감사합니다.
그림 4가 결국 Debiasing에 대한 효과를 알 수 있는 이미지인거 같은데요,
이미지 생성을 위해서는 어떤 방식을 썼는지 궁금합니다!
안녕하세요 주영님 좋은 질문 감사합니다.
해당 이미지는 ResNet18 아키텍쳐를 통해 디코더를 설계하여 생성한 이미지 입니다. LSGAN[1]의 adversarial loss를 사용해 학습했다고 합니다.
Reference
[1] ICCV2017: Least Squares Generative Adversarial Networks
안녕하세요 유진님 좋은 리뷰 감사합니다.
이 논문에서는 데이터셋 편향 문제를 해결하기 위해 고유 속성과 편향 속성을 분리하여 학습하는 접근법을 제안하고 있는데 딥러닝 모델이 학습하는 동안 타깃 클래스와 연관된 주변 속성을 더 의존해서 학습하는게 문제라면 Diffusion Model을 사용해서 데이터의 편향 속성을 다양하게 해주는 방식으로 데이터 augmentation을 진행할 수 있을 것 같다는 생각이듭니다. 혹시 Table2에 나와있는 방법론들이나 Debiased 연구에서 Diffusion Model을 활용해서 문제를 해결하는 연구도 진행이 되고 있나요?
감사합니다.
안녕하세요 의철님 좋은 질문 감사합니다.
Diffusion Model을 활용한 연구 진행은 아직 접한적은 없습니다만, Generation Model을 통해 데이터 증강을 한 연구는 있습니다. 그러한 연구들과의 차이점은 encoder를 이용해 타깃의 고유속성 특징과 편향 특징을 명시적으로 분리함에 있으며, 이러한 Disentangled Feature 의 de-biasing 효과를 Ablation studies를 통해 확인하면 더욱 좋을것 같습니다.
안녕하세요 유진님 좋은 리뷰 감사합니다.
de-bias 태스크에 있어서 데이터 자체의 Intrinsic 속성과 bias 속성을 각각의 인코더를 통해 분리하여 어떤 임베딩 벡터를 추출하고, 이를 feature level 에서의 swap augmentation을 활용하여 섞어줌으로써 보다 데이터 편향문제에 있어 보다 안정된 모습을 가져올 수 있었다 라고 이해했습니다.
읽던 중 randomly permute에 대해 한가지 생각이 떠올랐습니다.
Z_swap을 만들기 위해 randomly permute를 해주는 데, 완전 randomly permute 대신 cross-attention 방식으로 모델에게 더 어렵게(?) 두 임베딩 벡터 간의 정보를 섞으면 어떻게 될까 궁금하다는 생각이 들었습니다.
물론 본 논문은 기존의 intrinsic 속성 임베딩과 bias 속성 임베딩을 잘 분리할 수 있기 때문에 서로 permute해주는 것이 크게 유의미했던 것 같은데, 만약에 cross-attention을 통해 두 속성 임베딩 간 상호 관계 중 align이 안 맞는 부분에 더 weight을 줘서 loss를 구성하고, 서로의 속성 간의 상관관계가 낮은 부분은 오히려 둘의 임베딩이 더 잘 분리되었다는 식으로 간주하고 weighted randomly permute를 해주면 de-bias 성능이 더 좋지 않을까란 생각입니다.
제가 모르는 게 많은 입장에서 틀린 생각일 수도 있겠지만, 혹시 이런 식의 흐름도 가능한 생각일까요? 유진님의 개인적인 의견이 궁금합니다. 뭔가 터무니없어 보이거나 이해가 틀린 것 같다면 알려주시면 감사하겠습니다..!
감사합니다.
안녕하세요 좋은 질문 감사합니다.
우선 제시해주신 방법이 가능할 것이라 생각합니다.
다만 학습 초기에는 편향 특징과 고유 특징의 분리가 불확실하며, 너무 어려운 augmentation의 경우 학습에 오히려 해가 될 수 있으므로, 학습 초기 단계가 아니라 충분히 학습이 진행된 이후에 제안 방식을 적용한다면 추가적인 성능향상이 있을 수 있다고 생각합니다
감사합니다.