안녕하세요, 마흔 네번째 x-review 입니다. 이번 논문은 2024년도 ECCV에 게재된 Unlocking Textual and Visual Wisdom: Open-Vocabulary 3D Object Detection Enhanced by Comprehensive Guidance from Text and Image 입니다.
그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
현재 3차원 물체 검출은 학습 때의 물체들이 테스트에서도 검출 대상 물체로 나타난다는 전제 하에 수행되고 있습니다. 그런데 이런 전제는 real-world 관점에서 장면 내에 물체가 매우 다양하고 시간이 지나면서 확장될 수 있다는 사실을 반영하지 못하고 있습니다. 이런 관점에서 3차원 물체 검출에서의 open-vocabulary(OV)는 새로운 환경에서 본 적 있는 물체는 물론이고 이전에 본 적 없던 물체들까지 잘 검출하기 위해 필요한 task가 되었습니다.
모든 OV-3DET 논문에서 얘기하듯 이미지 기반의 방법론들은 웹 규모의 이미지-텍스트 쌍을 가진 대규모 데이터셋을 구축하고 있는 반면, 3차원에서는 학습 데이터의 부족이 OV를 수행하는데 어려움을 주고 있습니다. 그렇지만 여러 선행 연구들을 통해 VLM이나 LLM과 같은 이미지와 언어 기반의 대규모 사전학습 모델의 등장으로 OV-3DET에도 활용될 수 있는 방향이 제시되기 시작했습니다. 가령 OV3DET는 이미지 바운딩 박스를 생성해서 3차원 공간으로 사영해 3차원 바운딩 박스를 생성하고, CLIP을 통해 이미지-텍스트 feature 공간을 align 맞추는 방식으로 연구가 수행되었습니다. 또한 저도 리뷰했었던 가장 최근에 등장한 CoDA라는 방법론은 3차원 feature는 인스턴스 레벨에서 이미지 feature에, 카테고리 레벨에서는 텍스트 feature에 align을 맞추면서 OV를 수행하였습니다.
이러한 연구들이 등장했지만 한편으로는 FM을 완전히 3차원 도메인에서 활용하지는 못했는데, CoDA를 예로 들어보면 새롭게 만들어진 3차원 물체를 필터링하기 위해 VLM만을 사용하여 물체를 찾기 위해 사용할 수 있는 어노테이션에 학습된 class-agnostic한 3차원 물체 검출기에 의존도가 높아집니다. OV3DET 또한 VFM에 크게 의존하면서 막상 기하학적인 정보를 제공해줄 수 있는 3차원 입력 데이터의 중요성을 간과하였다고 하네요.
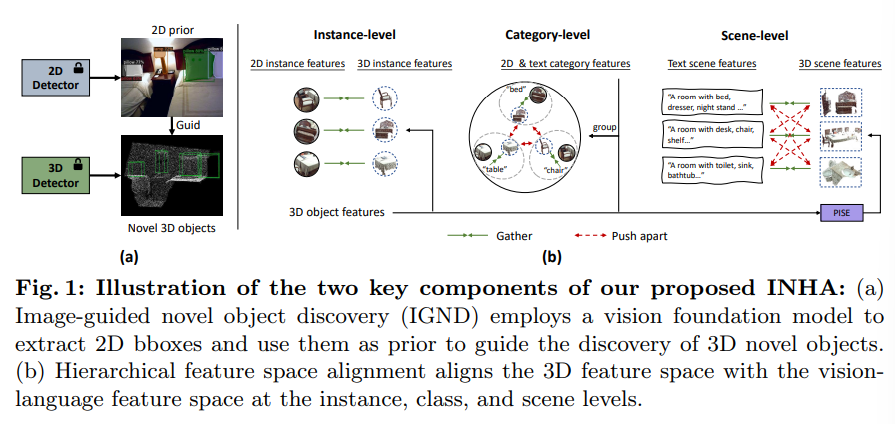
이런 기존 방법론들의 한계점을 해결하기 위해 본 논문에서는 새로운 Image-guided Novel class discovery and Hierarchical feature space Alignment (INHA)라는 방법론을 제시하여, FM을 사용해서 OV-3DET를 위해 텍스트와 이미지 정보를 최대한 활용하고자 하였습니다. Fig.1을 보시면 INHA는 크게 두 가지 구성을 나뉘는데, 먼저 Fig.1(a)와 같이 VFM의 일반화된 성능을 활용하고자 기존 이미지 레벨에서의 OV 검출기를 사용하여 먼저 이미지에서 물체를 먼저 찾습니다. 찾은 물체의 중심 픽셀을 초기 시드 개념으로 활용하여 추가적인 3차원 물체 proposal을 생성하고, 이미지 바운딩 박스를 신뢰할 수 있는 새로운 물체를 선택하는데 사용하고 있습니다. 발견한 새로운 물체는 기존의 물체들과 합쳐서 3차원 검출기를 재학습함으로써 class-agnostic한 검출기 성능을 향상시킬 수 있었다고 합니다.
다음으로 Fig.1(b)를 보면, feature 공간의 alignment를 맞추는 구조를 계층적으로 설계하여 인스턴스, 카테고리, 장면 레벨에서 각각 VLM feature 공간과 모두 align을 맞춥니다. 장면 레벨의 alignment를 맞추는 이유는 여러 모달리티에서 나타나는 클래스 관계를 찾기 위함이라고 합니다. 각 장면에서는 나타나는 물체 집합이 있기 때문에 이 집합을 장면에 대한 텍스트 설명과 직접적으로 비교할 수 있게 됩니다. 이를 위해 3차원 장면 feature을 추출하고 이를 설명 텍스트의 임베딩과 align 맞추는 Permutation-Invariant Scene feature Extraction (PISE) 모듈을 추가적으로 설계하였다고 합니다.
이제 본 논문의 contribution을 정리하고 방법론으로 넘어가보도록 하겠습니다.
- language, vision 기반 FM을 통해 텍스트와 이미지로부터의 표현력을 이용하는 새로운 INHA 프레임워크 제안
- image-guided novel object discovery (IGND) 알고리즘을 통해 유의미한 3차원 정보를 VFM으로부터의 이미지 정보와 효과적으로 통합
- PISE 모듈을 설계하여 장면 안에서 나타나는 클래스 사이의 관계 파악, 여러 레벨에서의 계층적인 feature space alignment 방식 제안
- SUN RGBD와 ScanNetV2 데이터셋에서 OV-3DET SOTA 달성
2. Method
2.1. Problem Definition
장면 레벨로 포인트 클라우드 P = \{p_i \in \mathbb{R}^3\}와 이미지 I \in \mathbb{R}^{3 \times H \times W}가 입력으로 주어집니다. 각 장면 안에서의 물체들은 O_{3D} = \{(B_n, c_n)\}^N_{n=1}로 주어지는데 B_n \in \mathbb{R}^7로 3차원 바운딩 박스를 의미하며 c_n \in C는 물체의 클래스를 나타냅니다.
주어지는 물체들 중에 몇 물체는 라벨이 주어지는 초기에 어노테이션해서 제공하는 베이스 물체 O^B_{3D} = \{(B^B_j, c^B_j)\}로 정의하는데, c^B_j는 베이스 라벨 풀 C^B에 속합니다. 반대로 라벨링 되지 않고 새로운 물체는 O^N_{3D} = \{B^N_k, c^N_k)\}로 정의하며 마찬가지로 c^N_k는 새로운 라벨 풀인 C^N에 해당하는 라벨 입니다. C^B와 C^N을 합쳐서 전체 라벨 풀인 C로 정의할 수 있습니다.
본 논문의 목적은 베이스 물체와 새로운 물체를 OV 상황에서 3차원 검출을 잘 수행하는 것이 되겠습니다.
2.2. INHA Overview
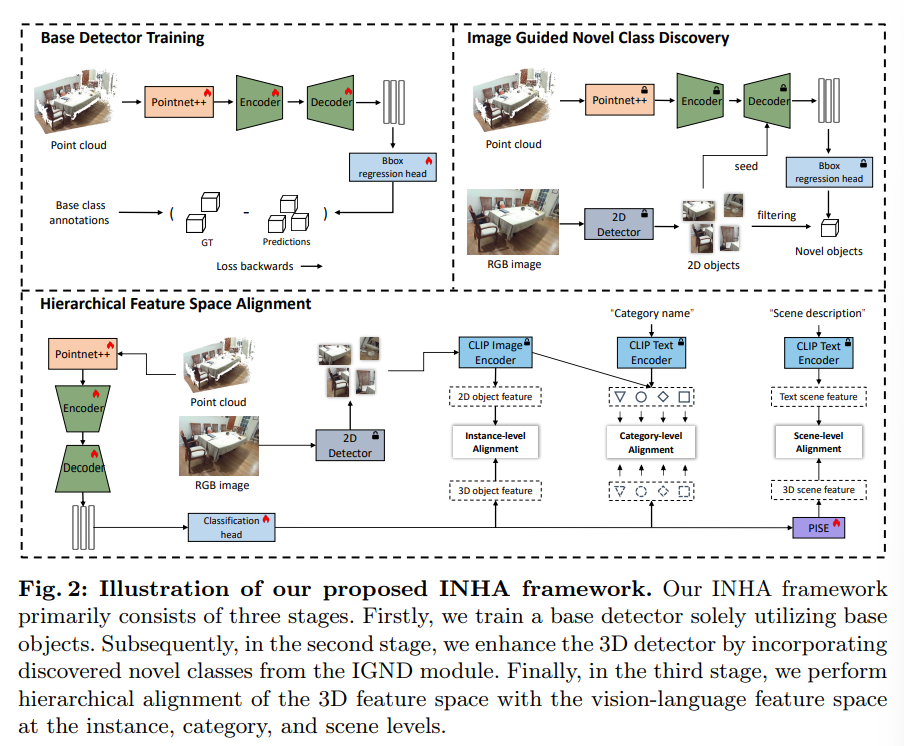
Fig.2가 INHA의 전체적인 프레임워크인데 여기서 pointnet++과 Encoder, Decoder는 기본적으로 3DETR 구조를 따르고 있습니다. INHA의 학습 프레임워크를 크게 세 가지로 나눌 수 있습니다.
첫 단계로 class-agnostic하게 3차원 물체 검출기를 classification 모듈을 제거하고 바운딩 박스 regression loss만으로 학습을 수행합니다. 이렇게 학습을 하고 나면 검출기는 클래스 정보와는 상관없이 포인트 내에서 물체를 검출할 수 있게 됩니다.
두번째 단계에서는 이제 새로운 물체를 찾기 위해 2D 검출기와 3D 검출기를 함께 사용합니다. 2D 검출기에서 발견된 물체는 3D 검출기를 재학습하기 위해 사용되며 이 과정을 통해 3차원 검출기는 새로운 클래스를 발견하는 능력을 향상 시킬 수 있게 된다고 합니다.
마지막 단계로 계층적인 구조를 제안하며 여러 레벨에서의 feature 공간을 align 맞추게 됩니다.
이제 각각의 단계를 자세하게 살펴보도록 하겠습니다.
3.3. Image-Guided Novel Class Discovery
이미지는 실내 환경에서 clutter된 물체들을 찾는데에 semantic한 정보를 제공하며 도움을 줄 수 있기 때문에 본 논문에서도 OV 2D 검출기를 사용해서 이미지 안에서 발견되는 매우 작거나 occlusion된 새로운 물체를 찾고자 합니다. 예를 들면 멀리 있어서 포인트에서는 정보가 손실이 되어 찾기 어려운 물체도 2D 검출기를 사용하면 단 몇 개의 픽셀을 이용해서 보다 쉽게 발견할 수 있기 때문 입니다. 3차원 검출기는 이제 반대로 기하학적인 정보를 제공하면서 예측에 있어서 더 정확한 위치 정보를 파악할 수 있다는 장점이 있습니다. 이런 상호보완적인 두 모달리티 정보를 잘 활용하기 위해 설계한 것이 Imag-Guided Novel Class Discovery (IGND) 모듈을 의미합니다. 해당 모듈에서는 사전학습된 OV 2D 검출기인 Detic를 사용해서 이미지로부터 물체 레벨의 정보, 즉 2차원 바운딩 박스를 찾습니다. 이런 이미지 상에서의 정보가 3차원에서 새로운 물체를 발견하기 위한 가이드로 제공될 수 있도록 3차원 데이터와 합치게 됩니다.
그럼 어떻게 이미지 정보를 3차원에서의 새로운 물체 검출의 가이드로 사용할 수 있을까요 ?
- Image-Guided Query Seed Initialization
먼저 3차원 물체 proposal을 형성하기 위한 추가적인 쿼리 시드로 이미지에서의 물체 중심을 3차원 공간으로 올립니다.
구체적으로 3DETR은 여러 포인트의 위치 정보를 쿼리 시드로 사용해서 3차원 물체 proposal을 하는데, 물체에 상관없이 랜덤 샘플링하거나 FPS 방식을 사용합니다. 쿼리 시드의 퀄리티가 새로운 물체를 찾는데 굉장히 영향을 많이 끼치기 때문에 본 논문에서는 OV-2D 검출기의 결과에서 추가적인 쿼리를 얻기 위해 2차원 물체의 중심을 3차원 공간으로 전달하는 것 입니다. O_{2D} = \{(b_m, c_m)\}^M_{m=1}을 이미지에서 검출한 M개의 물체라고 하면, b_m \in \mathbb{R}^4는 바운딩 박스가 되는데 여기서 바운딩 박스의 센터를 3차원 공간으로 보내줍니다. 이렇게 전달된 중심 위치는 3차원 포인트가 되어 위치 임베딩으로 인코딩 되고 쿼리 시드로 추가됩니다. 추가된 쿼리 시드는 디코더의 입력으로 같이 들어가면서 새로운 물체를 찾는데 이용될 수 있습니다.
- Image-guided Novel Object Selection
포인트와 이미지 사이의 같은 장면 안에서의 기하학적인 상관관계는 두 검출기의 결과를 연결할 수 있는 요소로 간주할 수 있습니다. 그래서 먼저 예측한 3차원 물체 박스를 \hat{3D}를 이미지 좌표로 사영합니다. 그 사영된 박스를 \hat{b}로 정의하고나서 2D 물체의 가이드에 따라 새로운 물체를 찾게 됩니다. 이미지에서 검출한 2D 박스 b_m에 대해 \hat{b}와 가장 많이 겹치는 박스를 매칭합니다. 그러고 나서 임계값을 걸어서 매칭된 샘플을 필터링하거나 혹은 베이스 물체에 포함된다면 제외합니다. 이렇게 새로운 물체를 선택하는 기준을 식(1)과 같이 정리할 수 있습니다.
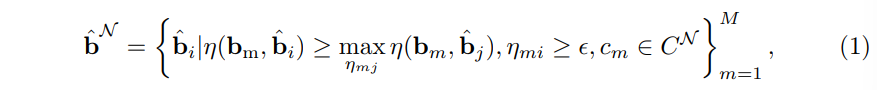
- \eta_{i,j} = \eta{(b_i, b_j)} : 두 박스 사이의 IoU
- \epsilon : 낮은 IoU 값을 가지는 매칭을 필터링하기 위한 임계값
이 과정을 거쳐서 선택되는 새로운 물체 \hat{b}^N와 대응하는 3차원 상의 박스가 결국 새로운 물체의 메모리에 저장되고 3차원 검출기에서 베이스 물체와 함께 재학습에 사용되는 것 입니다.
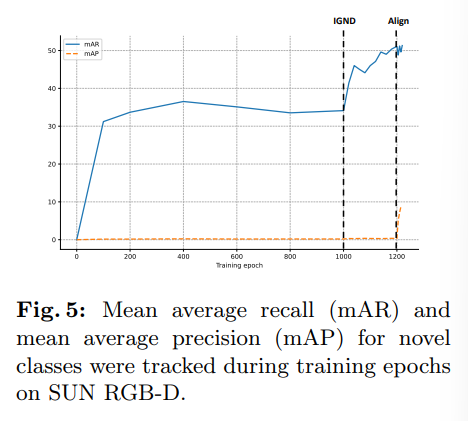
결국 정리하면 시드로 예측 자체에 관여를 하고, 예측한 결과들을에서 좀 더 신뢰도 있는 결과를 뽑기 위해 필터링 느낌으로 이미지 박스를 한 번 더 사용하게 되는 것이죠. 그 결과 Fig.5처럼 새로운 클래스의 recall 비율을 향상시킬 수 있었다고 합니다.
2.4. Hierarchical Corss-modal Feature Alignment
이제 VLM을 사용해서 계층적인 구조를 설계하여 3차원 feature 공간의 align을 맞추는 과정을 살펴보도록 하겠습니다. alignment는 말씀드린 것처럼 instance, category, 그리고 scene 레벨로 각각 맞추게 됩니다.
- Instance-level 3D-Image Alignment
이미지와 포인트가 같은 scene 내에서 shape과 같은 기하학적인 정보를 통해 자연스럽게 상관 관계를 형성하고 있다는 점을 기반으로, 3차원 물체 feature을 instance 레벨에서 2D 물체 feature와 연결합니다.
f^{3D}가 3차원 물체 feature이고 f^{2D}가 VLM인 CLIP으로부터 만들어진 crop된 이미지 feature라고 할 때, 식(2)와 같이 두 feature를 L1-norm loss를 사용해서 계산합니다.
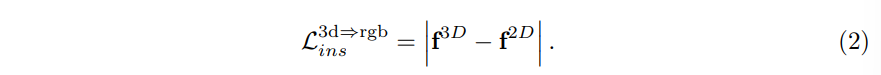
이런 instance 레벨에서의 alignment는 아직까지는 language 도메인에서의 클래스 정보는 고려하지 않은 채로 3D feature와 이미지 feature 사이만의 일관성을 강조하고 있습니다.
2. Class-level Cross-modal Alignment
여기서 이제 카테고리 레벨로 vision-language feature와 3D feature 사이의 align을 맞추게 됩니다. 먼저 이전 연구의 방식을 가져와서 세 가지 모달리티의 feature을 클래스 별로 나누어 conrastive learning을 사용해서 같은 클래스의 feature는 가까워지고 다른 클래스의 feature는 멀어지도록 학습합니다.
구체적으로 세 가지 모달리티의 feature 집합 S의 각각 feature들을 \{g_i\}^S_{i=1}로 나타내고 \{c_i\}^S_{i=1}로 그 feature들에 대한 클래스 라벨을 정의합니다. 이 집합 안에서 같은 클래스 샘플로 positive 쌍을 구성하고, 다른 클래스 샘플들로 negative 쌍을 구성해서 식(3)와 같은 contrastive loss를 계산합니다.
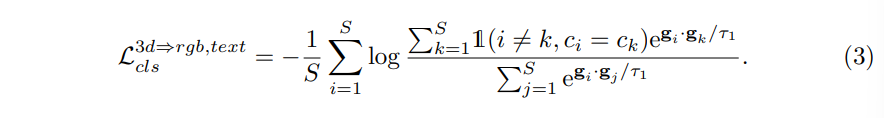
- \tau_1 : temperature parameter
- \mathbb{1}(\dot) : 조건을 만족할 때는 1, 아니면 0을 반환하는 indicator function
3. Scene-level Cross-modal Alignment
논문에서 계속해서 얘기는 장면 내의 발생하는 상관 관계들이 있는데, 또 하나는 특정 물체들은 장면 내에서 공존할 가능성에 대해서도 이야기합니다. 예를 들면 장면이 만약에 방일 때, 침대는 옷장과 같이 나타날 가능성이 높지만 반대로 냉장고와 같이 같은 공간에 있을 확률은 적을 것 입니다. 이런 상관 관계를 scene 레벨에서 모달리티 간 feature 공간의 alignment을 맞추는데 활용했다고 합니다. 여기서는 3D scene feature을 텍스트 scene feature와 alignment를 맞추는데, 그러기 위해선 우선 텍스트 scene feature을 생성해야겠죠.
이를 생성하기 위해 먼저 장면 내에 존재하는 모든 클래스를 포함하는 scene 레벨의 캡션을 생성합니다. 이 캡션은 CLIP의 텍스트 인코더를 타고 scene 레벨의 텍스트 feature인 z^{text}을 생성할 수 있습니다.
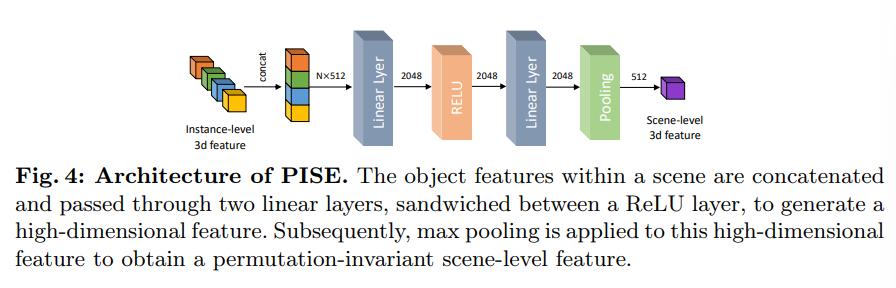
그 다음으로 scene 레벨에서 3D feature는 아직 추출하지 않았기에 이를 위해 Permutation-Invariant Scene-level feature Extraction (PISE) 모듈을 도입합니다. 이 모듈을 통해 장면 내 각각의 물체 레벨 3차원 feature를 합치고 합친 feature을 고차원의 공간으로 사영합니다. 이 과정에서 permutation invariance를 위해 Fig.4처럼 모듈 안에서 고차원의 feature에 대해 max pooling을 적용합니다.
PISE 모듈을 타고 나온 3D feature z^{3D}와 앞서 생성한 텍스트 scene feature 사이의 align을 맞추기 위해 식(4)와 같이 contrastive loss를 계산합니다.
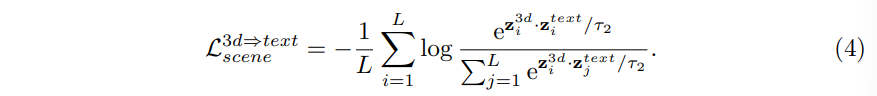
- L : 배치 내에 scene의 수
- \tau_2 : temperature parameter
이제 각 레벨에서의 alignment를 맞추기 위한 구조를 설계하였는데 전체 alignment loss를 정의하면 식(5)와 같습니다.
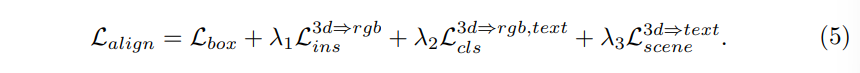
3. Experiment
3.1. Datasets
실험에는 두 개의 indoor 데이터셋을 사용했는데 먼저 SUN RGB-D에서는 총 46개의 물체 클래스 중에서 10개의 가장 주요 클래스를 베이스 클래스로 삼고, 나머지 36개이 클래스를 새로운 클래스로 정의하였습니다. ScanNetV2는 200개의 클래스를 가지고 있는데 그 중 마찬가지로 10개의 주요 클래스를 베이스 클래스, 그 다음으로 많이 다루는 50개의 클래스를 새로운 물체로 정의하였습니다.
추가적으로, ScanNetV2에서 본 논문은 기본적으로 OV3DET의 세팅을 따르면서 모든 클래스에 대해 학습된 수도 라벨을 사용합니다. 하지만 비교하는 모델인 L3DET는 이와 다르게 seen 클래스 학습에는 10개의 클래스를, unseen 클래스에서는 또 다른 10개의 클래스를 사용합니다. fair comparison을 위해 검증에서 OV3DET와 L3DET 사이에 겹치는 새로운 클래스 10개를 선택하였고 이 벤치마크를 ScanNet-10으로 정의하였습니다.
3.2. Main Results
Results on SUN RGB-D
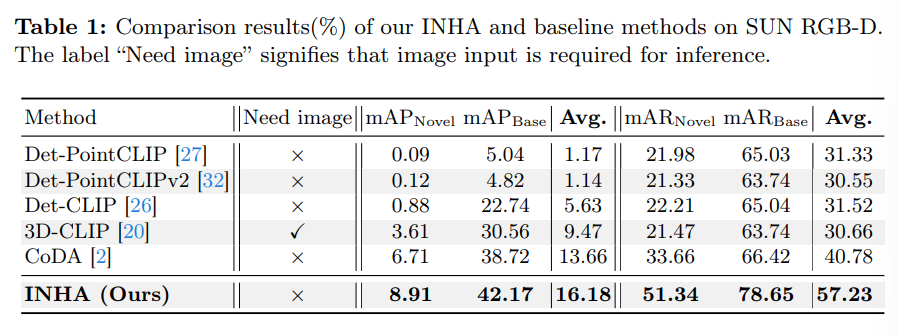
Tab.1은 SUN RGB-D에서의 결과로 base 클래스와 새로운 클래스에 대해 모두 본 논문의 방법론이 가장 높은 성능을 달성하였습니다. 특히 SOTA 방법론인 CoDA와 비교했을 때 mAP_{novel}에서의 거의 30% 이상, mAP_{Base}에서도 10% 이상의 성능 차이를 보이고 있는데요, 이는 INHA가 기본적으로 더 물체를 잘 검출할 뿐만 아니라 vision-language feature와 feature space의 align을 맞추었기 때문이라고 강조하고 있습니다.
Results on ScanNetV2
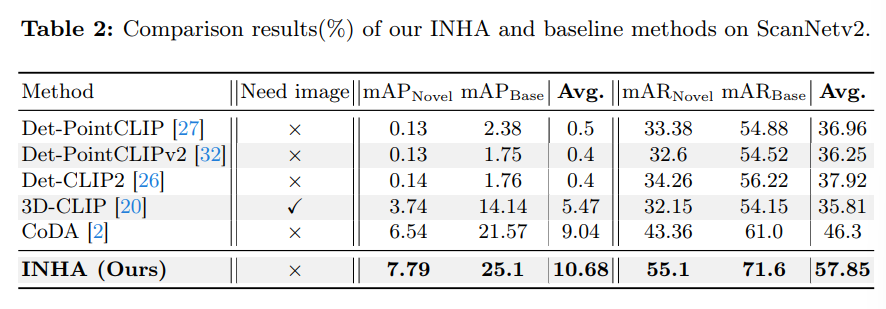
Tab.2는 ScanNetV2에 대한 실험 결과로 SUN RGB-D와 마찬가지로 두 클래스 결과에서 모두 SOTA를 달성하였습니다. 아직 3D에서의 OV 연구가 초기 단계라 나오는 논문마다 이전 방법론 대비 성능 향상의 폭이 굉장히 크네요 .. 여기서도 novel에 대해 거의 19%의 성능 향상을 이루고 있습니다.
3.3. Results on ScanNet-10
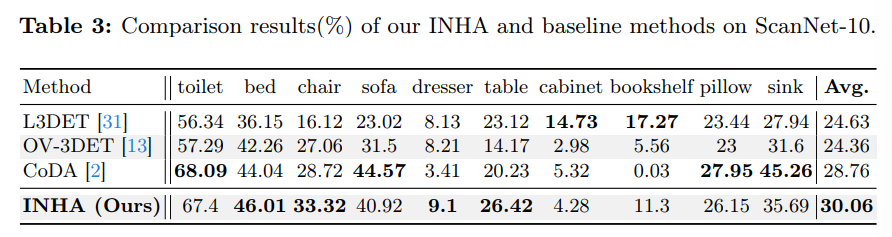
다음 Tab.3은 논문에서 설정한 ScanNet-10에서의 벤치마킹 결과 입니다.
OV3DET와 같이 모든 클래스에 대한 수도 라벨을 만들기 위해 2D 검출기를 이용하고 본 논문에서도 동일한 수도 라벨링 세팅을 이용합니다.
L3DET는 10개의 base 클래스에 합성 데이터를 사용해서 새로운 카테고리로 확장하는데, 이런 차이가 나는 세팅에서 공평한 비교를 하기 위해 겹치는 10개의 novel 클래스를 선택한다고 합니다. Tab.3에서 보이는 클래스가 바로 선택된 새로운 클래스 10개를 나타냅니다.
결과적으로 해당 세팅에서 클래스 별로는 성능 차이가 날 순 있지만 전체 mAP에서는 가장 높은 성능을 달성하였다곤 하지만, 해당 벤치마킹에 대해서는 별 다른 언급이나 분석이 추가적으로 있진 않네요.
3.4. Ablation Study
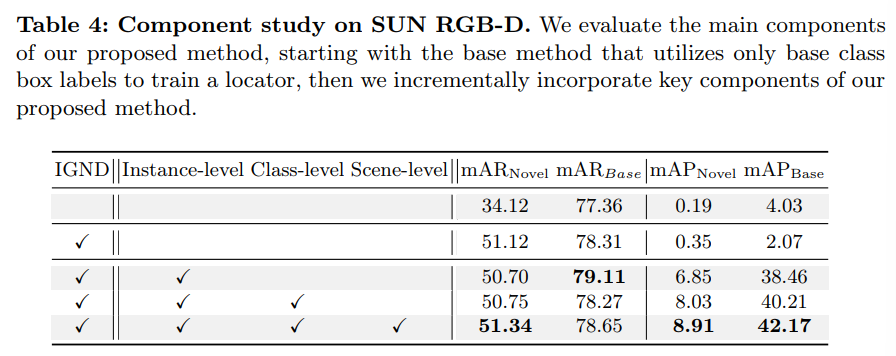
Effect of Image-Guided Novel Class Discovery
제시한 INHA 방법론에서 우선 IGND 모듈의 효과를 ablation study로 보여주고 있습니다. IGND 모듈을 추가함으로써 새로운 물체를 발견하는데 많은 도움이 된다는 걸 mAR_{Novel}을 통해 성능적으로 확인할 수 있습니다. 앞서 방법론에서 Fig.5를 통해 recall 비율을 향상시킬 수 있다는걸 보여주었었습니다. 이런 mAR의 성능 향상을 통해 이미지 기반의 새로운 물체를 발견하는 모듈의 효과를 강조할 수 있습니다.
Effect of Hierarchical Cross-modal Feature Alignment
Tab.4에서 또 하나 볼 수 있는 것은 계층적인 feature alignment 방식의 효과 입니다. instance부터 각 레벨의 alignment를 맞추는 과정을 거칠 수록 점진적으로 성능이 향상되는 것을 확인할 수 있습니다. 또한 Fig.5에서도 마찬가지로 계층적인 모달리티 feature 공간 alignment를 활용하면 IGND만을 적용했을 때 보다 novel 클래스에 대해서 높은 mAP를 달성한다는 것을 알 수 있습니다.
Effect of Image-guided Query Seed Initialization

마지막으로 이미지에서의 검출 결과를 3차원 검출기의 시드로 활용한 방식에 대한 ablation study 입니다. 쿼리 시드의 사용이 없을 시에는 새로운 클래스에 대한 있을 때 보다 recall 성능이 하락하면서 이미지 차원에서의 물체 중심으로 만들어진 추가적인 쿼리의 중요성을 확인할 수 있습니다. 이미지 정보를 활용함으로써 모델이 더 많은 물체를 찾고 3차원 검출에서 이미지 모델을 사용하는 효과를 보여주고 있습니다.
좋은 논문 리뷰 감사합니다.
몇 가지 질문 남기고 가겠습니다.
Q1. 3D detection도 ovd로 넘어가려는 시도가 활발히 진행되고 있는 것 같습니다. 근데 SUN RGBD 데이터 셋에서 novel을 구분하는 것 같은데 데이터 셋을 어떻게 나눠서 진행하나요? SUN RGBD 자체에 클래스가 그렇게 많은 것 같지 않은데 어떻게 구분했는지 궁금합니다.
Q2. Tab 1을 보면 INHA 모델의 need image에 x라고 표시되어 있습니다. 이는 해당 모델의 추론 단계에서 영상이 필요 없다는 걸까요? 맞다면 추론에서 어떻게 적용하는지 궁금합니다. 아니라면… 무슨 의미인가요?
Q3. 해당 모델의 프레임워크가 굉장히 복잡해 보입니다. 사용된 컴퓨팅 파워가 뭔지 궁금합니다.
좋은 리뷰 감사합니다.
미학습 객체 인식을 위한 테스크는 다양한 경우에 vocabulary 안의 객체를 인식할 수 있어야 한다고 생각하는데, 해당 방법론은 scene level의 카테고리들을 상관관계로 보고 학습한다고 하여 어떻게 보면 상황적으로 관련 있는 객체에 집중할 수 있으나 한편으로는 예상치 못한 객체가 존재할 경우 이를 간과하게 될수도 있지 않을까 하는 생각이 듭니다. 이에 대한 건화님의 의견이 궁금합니다.
또한, Table1에서 CoDA와 비교했을 때, mAP_novel에서 30% 성능 차이가 난다고 하셨는데 어떤 수치를 봐야하는 지 모르겠습니다.. mAR을 의미하신걸까요??
안녕하세요 건화님 좋은 리뷰감사합니다.
제안된 방법론은 2D 이미지에서 얻은 정보를 이용해 3D 객체 검출기에 성능을 향상 시키는 방법을 사용하고 있습니다.
실험 테이블을 봤을 때 새로운 객체에 대한 탐지 능력도 향상된 것을 확인할 수가 있는데 방법론에 조금 의문이 생겨 질문남깁니다.
제안된 방법론에서 2D 객체 검출기가 이미지에서 잘못된 또는 불필요한 객체를 탐지해서 이 정보를 3D 공간으로 변환했을 때 3D 객체 후보가 너무 많아지거나 부정확한 후보들이 포함되어 불필요한 정보가 증가하지 않을까 하는 의문이 들었습니다. 또한 탐지된 객체 수가 늘어나면 이를 처리하는 데 필요한 계산 비용도 늘어날 것 같은데 논문에서는 이를 방지하는 추가적인 장치가 있을까요?
감사합니다.
안녕하세요 건화님 리뷰 감사합니다!
리뷰를 읽던중 이해가 어려운 부분이 있어서 질문드립니다. 혹시 contrastive loss와 allignment loss를 조금만 풀어서 설명해주실 수 있으신가요? 같은 클래스의 feature는 가까워지고 다른 클래스의 feature는 멀어지도록 학습한다는 개념과 allign을 맞춘다는 개념이 와닿지가 않습니다..