안녕하세요. 박성준입니다. 오늘 제가 할 리뷰는 KCCV 2024 포스터 및 오랄 발표 논문으로 video understanding 연구를 진행한 CAST 논문입니다.

먼저 Video Action Recognition는 영상 내 사람의 행동을 구별하는 task로 대게 동사와 명사로 구성된 여러 action class 중에서 영상 내 사람의 행동과 일치하는 action을 분류하는 비디오 코어 연구입니다. 즉, 영상이 입력으로 들어오면 영상 내 사람의 행동을 action class로 반환하는 task입니다.
Introduction
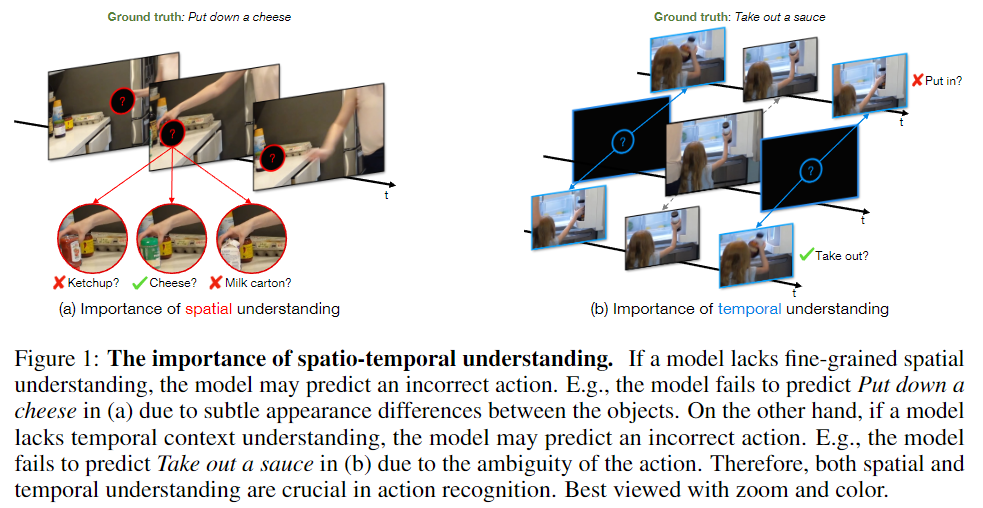
영상에서 사람의 행동을 잘 인식하기 위해서는 비디오의 공간 정보(spatial context)와 시간 정보(temporal context)를 잘 이해하는 것은 필수적입니다. Figure 1 (a)는 공간 정보가 부족한 경우에 영상 내 행동을 제대로 판단하지 못하는 상황을 보여줍니다. Figure 2 (b)는 시간 정보가 부족한 경우에 영상 내 행동을 제대로 판단하지 못하는 상황을 보여줍니다. 이처럼 영상 내 행동을 잘 인식하기 위해서는 공간 정보와 시간 정보를 모두 잘 이해할 수 있어야 한다는 것은 자명한 사실입니다. 하지만, Transformer 기반의 방법론들로 공간 정보와 시간 정보를 밸런스 있게 다루는 것은 아직까지도 challenging한 문제로 남아있었습니다. 이미지와 비교해 영상은 시간 정보가 추가되기에 많은 학습 데이터가 필요하고 연산량도 늘어가기 때문입니다. 따라서 대부분의 Action Recognition 모델들은 영상에 대한 공간 정보, 시간 정보의 밸런스가 맞지 않았고 선행 연구들은 이러한 부분에 대한 고려가 부족했습니다.
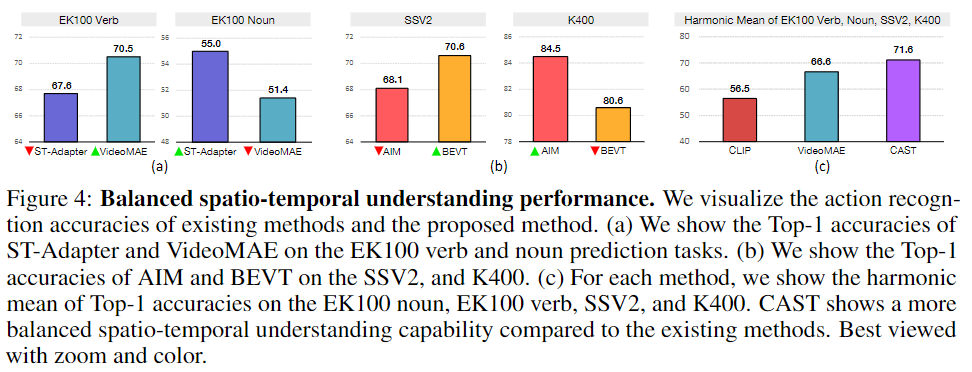
Figure 4에서 확인할 수 있듯이 공간 정보에 편향된(static-biased) 데이터셋에서 좋은 성능을 보여주는 모델이 시간 정보에 편향된(temporal-biased) 데이터셋에서는 성능이 좋지 않고, 그 반대로 시간 정보에 편향된 데이터셋에서 좋은 성능을 보여주는 모델은 공간 정보에 편향된 데이터셋에서 좋지 않은 성능을 보이고 있습니다 (Verb, SSV2: 시간 정보에 편향된 데이터셋, Noun, K400: 공간 정보에 편향된 데이터셋). 자세한 실험 결과는 Experiments 및 Ablation Study에서 다시 다루겠습니다.
다시 돌아와 저자는 이러한 문제를 해결하기 위해 밸런스 있게 공간 정보와 시간 정보를 다루는 방법 중에 하나로 RGB 이미지와 Optical Flow를 활용하는 멀티모달 학습을 소개합니다. Optical Flow는 영상 내 프레임 간의 차이 정보라고 생각해주시면 될 것 같습니다. 저자는 이러한 RGB이미지와 Optical Flow를 이용해서 공간 정보와 시간 정보를 밸런스 있게 활용할 수 있지만, 이 방법은 Optical Flow Estimation으로 인해 연산량이 과하게 커진다는 점을 지적합니다.
따라서 저자는 RGB만을 활용해 빠른 연산이 가능하면서 동시에 공간 정보와 시간 정보를 밸런스 있게 활용하는 two-pathway 구조의 CAST(Cross-Attention Space and Time)모델을 제안합니다. CAST는 공간 정보를 다루는 spatial-expert model과 시간 정보를 다루는 temporal-expert model을 활용하고 각 model의 정보를 교환하여 시너지를 활용하는 모델입니다. 저자는 실험을 통해 cross-attention을 수행하는 것이 정보를 교환하는 데에 있어 가장 효과적이었음을 밝히며 cross-attention을 사용하고 bottleneck구조를 사용하여 효율성(적은 연산량)을 챙겼습니다. CAST는 공간 정보에 편향된 데이터셋과 시간 정보에 편향된 데이터셋 모두에서 밸런스 있는 좋은 성능을 보여줍니다.
이에 따른 저자의 Contribution은 다음과 같습니다.
- 저자는 기존의 연구들이 간과하던 공간 정보와 시간 정보의 밸런스를 챙기면서 동시에 computation efficient한 two-stream 구조의 CAST를 제안합니다.
- CAST는 다양한 데이터셋에서의 실험을 통해 기존 방법론들이 가지고 있던 공간 정보, 시간 정보 불균형의 문제를 가장 효과적으로 해결했음을 보여줍니다.
- 다양한 ablation study를 통해 CAST의 구조가 space정보돠 time정보를 밸런스 있게 다루는 가장 효율적인 방법이었음을 보여줍니다.
Method: Cross-Attention in Space and Time
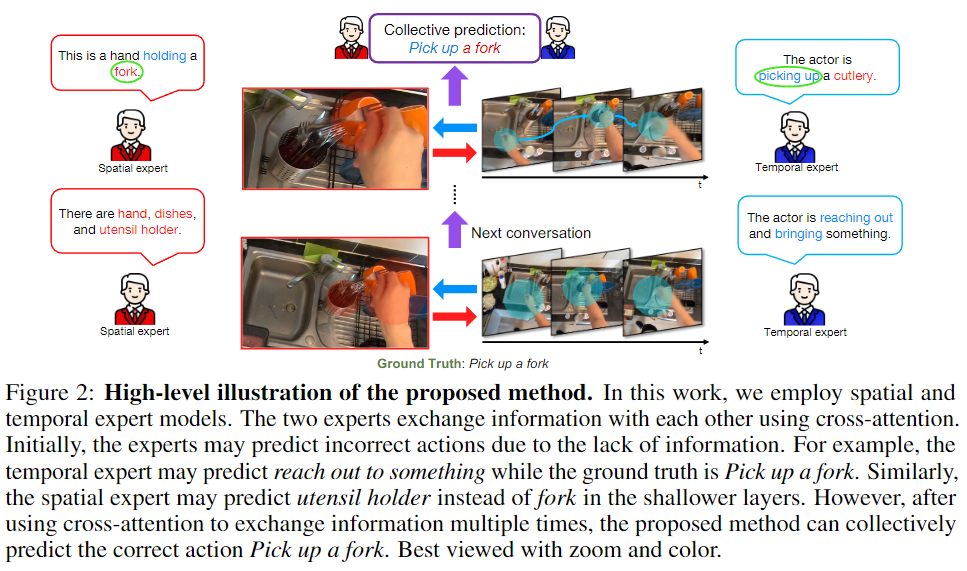
Figure 2 는 Introduction에서 간략하게설명했던 CAST 모델의 작동방식을 high-level 설명으로 보여줍니다. Spatial Expert와 Temporal Expert는 각각 공간 정보, 시간 정보를 활용해 영상 내 행동을 예측합니다. 하지만, 각 Expert는 상대방의 정보가 부족하기에 단일 모달리티로는 정확한 예측을 수행할 수 없습니다. CAST는 중간에 각 Expert의 정보를 혼합하는 Cross-Attention을 활용해 두 모달리티의 정보를 혼합하여 정확한 예측을 수행합니다.
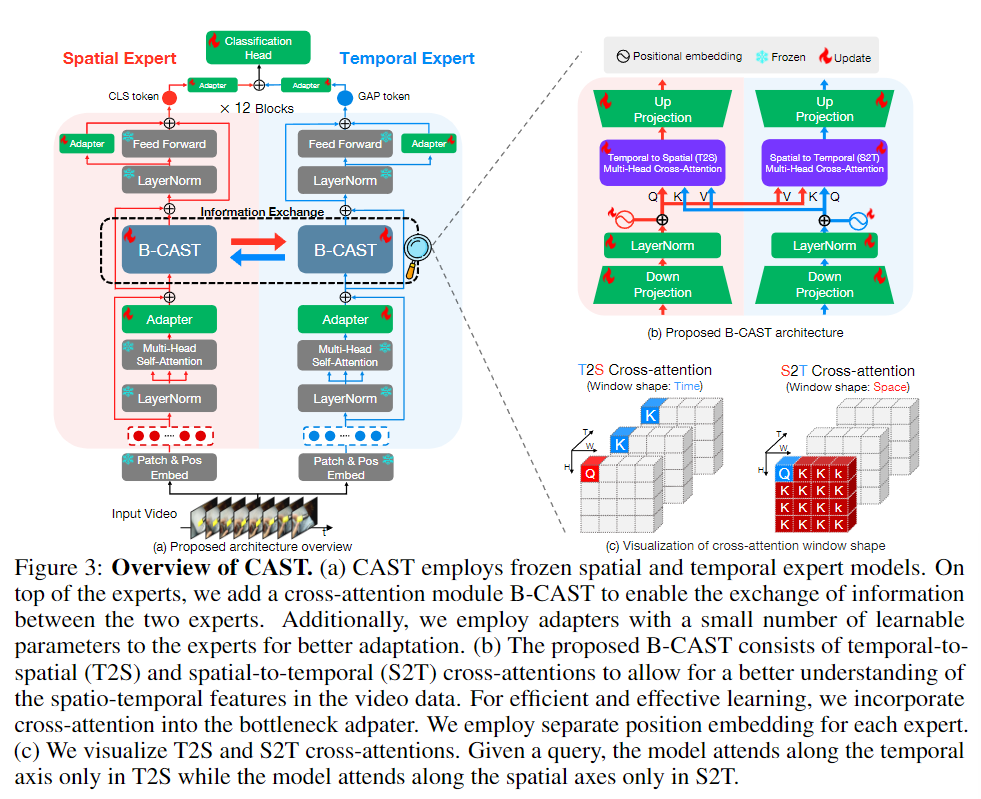
CAST는 위의 high-level 설명에서 소개된 것처럼 frozen spatial model과 frozen temporal model을 사용합니다. 두 expert(model)간의 정보 교환을 위해 B-CAST(Bottleneck-Cross Attention in Space and Time) 모듈을 사용해 각 expert(model)의 정보를 교환하는 것으로 공간 정보, 시간 정보를 더 밸런스 있게 학습합니다. frozen model을 사용한다고 했는데 저자는 학습을 위해 Adapter 계층을 활용해 학습합니다. Adapter와 Bottleneck 구조를 사용하는 것으로 computation efficient하다는 것을 강조합니다. 여기서 사용하는 spatial expert와 temporal expert는 12 블록으로 구성된 트랜스포머 기반의 모델로 vision transformer 모두 사용 가능합니다. CAST는 spatial expert로 CLIP을, temporal expert로 VideoMAE를 사용합니다. KCCV2024에서 직접 저자에게 baseline 모델로 어느 ViT기반 모델을 사용해도 되는데 CLIP과 VideoMAE를 사용한 이유에 대해 질문했었는데 논문 라이팅 시점(2023년 6~8월)에서 후술할 Spatial-biased 데이터셋과 temporal-biased 데이터셋에서의 SOTA 모델을 사용했고 각각 space와 time 정보를 잘 다루는 모델을 사용했고 별다른 이유는 없었다고 합니다.
아무튼 CAST는 이러한 backbone모델을 각 expert로 활용하여 학습합니다. 입력으로 영상이 들어오게되면 patch tokenizer를 통해 패치로 변환하고 포지셔널 임베딩을 더해 input X를 생성합니다. input X가 들어오게 되면 layer norm과 함께 Multi-Head Self-Attention 연산을 수행합니다. MHSA는 MHSA(X) = Softmax((XW_Q)(XW_K)^T)XW_V) 연산을 거칩니다. W_Q, W_K, W_V는 각각 쿼리, 키, 밸류 projection 행렬입니다. 따라오는 adapter 연산은 linear down, up projection 행렬과 함께 다음과 같이 정의됩니다. ADAP(X) = \sigma(XW_D)W_U
B-CAST는 bottlenect구조 안에 포지셔널 임베딩을 더해 expert끼리의 cross-attention 연산을 수행합니다. T2S와 S2T연산을 통해 temporal 정보를 spatial expert에게, spatial 정보를 temporal expert에게 전달합니다. T2S 연산은 다음과 같습니다.
\Phi_S(Y_s^{(l)},Y_t^{(l)}) = \sigma(MHCA(E_x+LN(Y_s^{(l)}W_{D,s}),E_t + LN(Y_t^{(l)}W_{D,t})))W_{U,s}W_{D,s}, W_{U,s}는 각각 spatial expert를 위한 linear down-, up-projection행렬이고, E_s, E_t, \sigma(\cdot)는 각각 spatial expert, temporal expert를 위한 포지셔널 임베딩, 그리고 GELU활성화 함수입니다. S2T 연산 또한 T2S 연산과 동일합니다.
B-CAST의 출력을 B^{(l)}이라고 할 때, FFN을 거쳐 Classification Head에 전달합니다.
X^{(l+1)} = B^{(l)} + FFN(LN(B^{(l)})) + ADAP(LN(B^{(l)}))마지막으로 Classification Head에서는 각 expert의 출력을 CLS와 GAP 연산을 통해 fused token Z를 생성해 예측에 사용합니다.
Z = ADAP(CLS(X_s^{(12)})) + ADAP(GAP(X_t^{(12)}))학습 손실함수로는 일반적인 CrossEntropyLoss를 사용합니다.
Experiments
저자는 CAST모델의 실험결과를 다음 3가지 관점에서 보여주고 있습니다.
- 제안하는 CAST와 기존 SOTA 모델들과의 성능 비교
- CAST가 spatial 정보와 temporal 정보를 밸런스 있게 다루고 있는가
- ablation을 통한 제안하는 모델 구조의 효율성 및 성능 비교
구체적인 실험 결과에 앞서 저자의 모델이 수행하는 task에 대해서 설명드리겠습니다. CAST는 리뷰 초반부에서 설명한 것처럼 Action Recognition을 수행합니다. Action Recognition은 영상 내 사람의 행동을 분류하는 task입니다만 저자는 특별하게 일반적인 Action Recognition 외에 Fine-Grained Action Recognition을 추가하여 저자의 contribution인 spatial, temporal 정보를 밸런스 있게 다루고 있음을 증명하고 있습니다.
먼저, 일반적인 Action Recognition에 대해서 저자는 두개의 데이터셋을 활용하여 실험 결과를 보여줍니다. 첫 데이터셋은 Something-Something-V2(SSV2) 데이터셋으로 명사 ___ 명사의 형태로 구성되어있는 주석에서 명사와 명사 사이의 mask에 알맞은 action을 분류하는 데이터셋으로 영상내 temporal 정보를 통해 행동을 분류해야하는 temporal reasoning 능력을 필요로하는 데이터셋입니다. 두번쨰 데이터셋은 Kinetics-400(K400) 데이터셋으로 영상 내 사람의 행동을 분류하는 데이터셋으로 SSV2만큼 temporal reasoning 능력을 요구하지는 않지만, 영상 내 객체를 구분해야해 spatial 정보를 잘 이해해야하는 데이터셋입니다. 저자는 이 두 데이터셋을 각각 temporal biased 데이터셋, static biased 데이터셋으로 정의해 SSV2와 K400 데이터셋에서의 성능을 모델이 temporal 정보, spatial 정보를 잘 활용하는 지에 대한 분석에 사용합니다.
Fine-Grained Action Recognition은 일반적인 Action Recognition만으로는 spatial, temporal 정보를 밸런스 있게 활용한다는 contribution을 주장하기에 부족하다고 생각한 저자가 새로 고안해 추가한 실험입니다. (여담으로 논문 리뷰 과정에서 일반적인 Action Recognition에서 temporal biased, spatial biased 데이터셋으로 정의하고 비교하는 것 만으로는 밸런스 있다는 것을 주장을 뒷받침하는 근거로는 부족하다는 리뷰를 받게 되어 추가로 실험을 진행했다고 합니다.) Fine-Grained Action Recognition은 EPIC-KITCHENS-100(EK100)데이터셋을 활용하게 됩니다. EK100 데이터셋은 K400 데이터셋과 마찬가지로 동사, 명사 쌍으로 구성된 사람의 행동으로 주석이 되어 있는데 저자는 동사와 명사를 따로 예측하도록 구성하여 하나의 action label을 분류하는 SSV2와 K400보다 더 challenging한 EK100-Verb와 EK100-Noun을 구성하여 성능을 실험합니다.
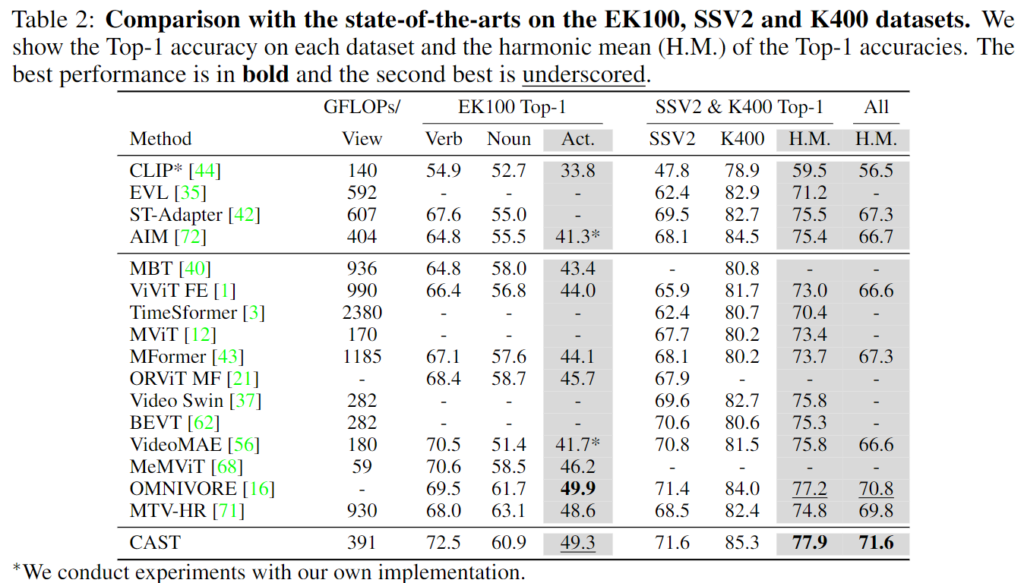
위 Table 2.는 앞서 설명드린 Action Recognition과 Fine-Grained Action Recognition에서 기존 모델과의 성능 비교입니다. 기본적으로 Top-1 예측에 대한 정확도로 성능을 리포팅하고 있고, EK100에서의 Verb와 Noun 성능, 그리고 Action은 각각 Verb와 Noun을 따로 예측한 예측값의 정확도 입니다. EK100에서 verb의 성능은 제일 좋고 Noun의 성능도 상위권에 속하는 것을 확인할 수 있습니다. 종합적인 Action에서의 성능은 SOTA는 아니지만 두번째로 높은 성능을 보여줌으로 CAST의 강력함을 보이고 있습니다. SSV2와 K400에 대해서는 각각의 성능 모두 SOTA를 달성했고, 두 데이터셋에서의 조화평균(H.M.) 결과와 모든 데이터셋 (SSV2, K400, EK100)에서의 조화평균 또한 SOTA를 달성한 것을 확인할 수 있습니다. 주목할만한 점을 조화평균을 사용해 결과를 리포팅한 점인데 저자는 조화평균은 lower-performing task에 더 높은 가중치를 주는 평균 방식이기에 여러 데이터셋에서의 성능을 밸런스 있게 다루고 있음을 보여주는 데에 가장 효과적인 산술방식임을 주장하여 조화평균을 사용했다고 말합니다. 일반 적인 평균 방식은 특정 데이터셋에서의 성능이 높다면 다른 데이터셋에서의 성능이 낮더라도 평균값은 크게 떨어지지않아 밸런스 있는 성능을 보이는 데에 사용하는 지표로는 부적절하다고 판단해 조화평균을 도입했다고 합니다.
저자는 CAST가 temporal biased 데이터셋(SSV2, EK100-Verb)와 static biased 데이터셋(K400, EK100-Noun) 각각에서의 성능도 SOTA에 견줄만한 성능을 달성함과 동시에 조화평균에서 SOTA를 달성함을 보이며 RGB데이터만으로 temporal 정보와 temporal 정보를 밸런스 있게 다루고 있다는 것을 증명합니다.
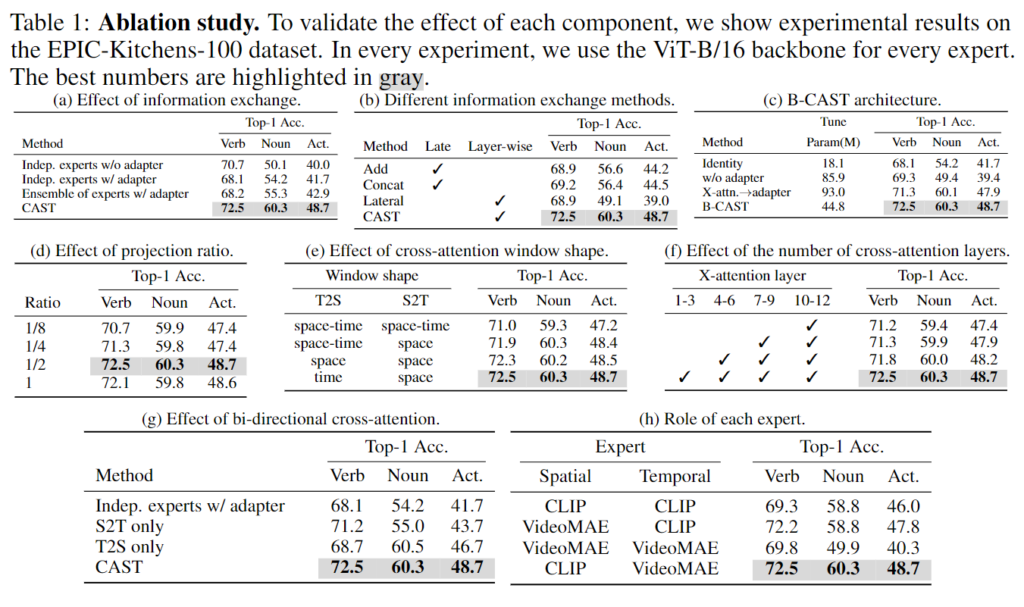
Table 1.은 저자가 CAST의 구조가 가장 효율적으로 temporal 정보와 spatial 정보를 밸런스 있게 다루는 구조라는 것을 증명하기 위한 ablation study입니다. 굉장히 많은 실험을 통해 CAST의 구조가 가장 효율적인 구조임을 증명합니다. 모든 ablation study는 EK100에서의 실험으로 동사, 명사, 행동 모든 성능을 보여줌으로 모델의 spatial 성능, temporal 성능, 둘을 합한 성능까지 다양한 성능을 한번에 보일 수 있는 벤치마크로 저자가 CAST의 contribution(temporal 정보와 spatial 정보를 밸런스 있게 다룸)을 한눈에 잘 보여주는 실험으로 EK100을 택해 보여줍니다.
(a)는 정보 교환의 효과에 대한 ablation입니다. Indep.은 모두 정보 교환을 하지 않는 구조를 의미합니다. 어찌보면 당연하지만, adapter의 유무와 상관없이 정보교환이 없다면 유의미한 성능 차이를 보여주지 못합니다. ensemble을 하는 것은 noun에서 성능 개선을 보이기는 하지만 제안하는 CAST의 구조가 verb, noun, action 모두에서 가장 좋은 성능을 보여주는 것을 확인할 수 있습니다.
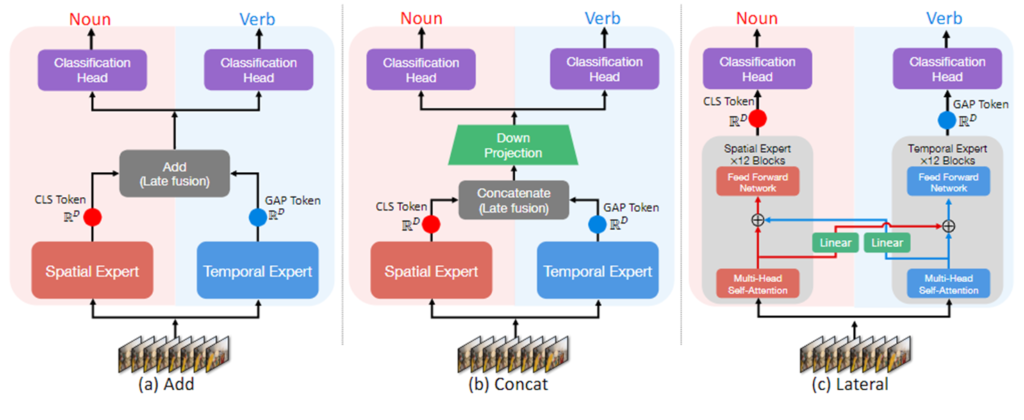
(b)는 정보 교환을 하는 방식에 대한 ablation입니다. 위 그림은 ablation에서 해당하는 구조를 보여주는 그림으로 add는 element-wise addition, concat, lateral fusion의 구조를 보여줍니다. add과 concat은 직관적이니 넘어가고 lateral connection은 기존의 2-pathway 방법론에서 가끔 쓰이던 방식으로 SlowFast(내 리뷰 링크 넣기) 등에서 활용되던 방식입니다. 각 계층마다 서로의 도메인으로 정보를 linear 모델을 통해 projection시켜 정보를 교환하는 방식입니다. lateral connection이 위 방법 중에 제일 낮은 성능을 보여주는 것이 인상적이네요. 저자가 이에 대한 고찰을 논문에는 적지 않아 KCCV2024의 포스터에서 물어본 결과, layer마다 정보를 교환하는 것이 결국 각 모달리티에 대한 이해를 낮추는 결과를 초래한 것 같지만, 논문에 리포팅하기에는 정량적으로 뒷받침할 근거가 없이 뇌피셜(?)로 내린 결론이라 추가하지 않고 결과를 통해 효과적이지 않았다고만 말합니다. 결국 Cross-Attention(w/ bottleneck)구조가 정보를 교환하는 데에 가장 효율적이라는 것을 잘 보여주는 실험 결과입니다.
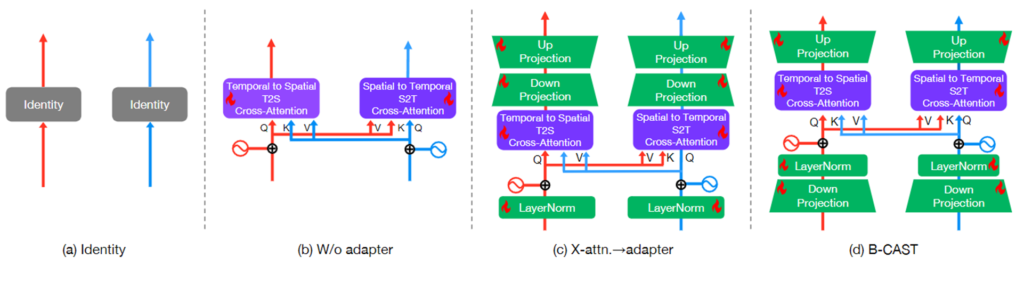
(c)는 B-CAST의 구조에 대한 ablation입니다. identity는 정보 교환을 하지 않는 baseline이라고 생각해주시면 될 것 같습니다. 저자가 제안하는 B-CAST의 구조처럼 bottleneck구조 안에 cross-attention을 하는 구조가 연산량, 성능 모두에서 가장 좋은 모습을 보여주며 두가지 토끼를 모두 잡은 것을 보여줍니다.
(d, e, f, g)는 각각 bottleneck구조에서 projection ratio, cross-attention의 window shape, cross-attention layer의 개수, bi-directional cross-attention에 대한 ablation입니다.
마지막으로 (b)는 저자의 각 expert backbone을 어떠한 모델을 사용했는지에 대한 ablation study입니다. CLIP과 VideoMAE를 사용했을 때가 제일 좋았으며, 눈 여겨볼 점으로는 두 expert로 같은 모델을 사용했을 때는 비효율적이라는 점입니다. 아무래도 각 backbone을 freeze하고 사용하다 보니 같은 모델을 expert로 사용했을 때에 성능이 크게 오르지는 않는 것 같네요. 위에서도 살짝 언급했었지만, CLIP과 VideoMAE를 사용한 이유는 결국 CLIP의 static biased 데이터셋인 K400에서의 성능이 좋고 VideoMAE는 temporal biased 데이터셋인 SSV2에서 성능이 좋았기 때문에 backbone으로 선정했다고 합니다.
실험 결과 이후 저자는 마지막으로 CAST의 문제 정의부터 temporal, spatial 정보를 잘 다루는 것을 강조하고 마지막으로 ViT기반의 모델을 backbone으로 사용할 수 있음을 강조하며 video understanding 분야에서 널리 사용될 수 있음을 강조하며 논문을 마무리합니다.
이번 KCCV를 통해 NIPS에 게재된 논문의 방법론뿐만 아니라 구체적으로 방법론의 구조를 어떻게 설계했는지, 실험을 어떤식으로 진행하여 저자의 contribution을 강화할 수 있었는지 등을 알 수 있었습니다. 제가 연구하고 있는 Moment Retrieval은 비디오의 정보와 텍스트의 정보를 어떻게 잘 다룰 수 있는지에 집중하는 task로 비디오의 코어 연구인 video understanding와는 연관이 적어 보일 수 있지만, 논문의 motivation부터 방법론 설계, 실험을 통한 증명까지 비디오에 대한 이해 뿐만 아니라 논문이 작성되고 우수 학회에 게재되기까지의 과정 및 그 사이의 저자의 고찰을 알 수 있어 뜻 깊었던 것 같습니다. 포스터 및 오랄 발표 이전에 논문을 읽고 직접 저자와 많이 소통했던 논문이라 꼭 리뷰하고 싶었던 논문이었습니다. 이것으로 리뷰를 마치겠습니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
그래도 학회에 다녀온 뒤 시야가 넓어지셨음을 스스로 느끼는 것 같아 좋은 것 같습니다.
방법론 설명해주실 때 백본으로 clip과 videomae를 사용했다고 말씀해주셨는데, 이들의 사전학습된 가중치를 가져와 freeze해두고 사용한 것이 맞나요? 기존 action recognition에서 사용하던 백본은 무엇인지와 만약 둘이 다르다면 공정한 비교가 가능한 것인지에 대해 궁금합니다.
안녕하세요 현우님 좋은 댓글 감사합니다.
CAST는 Spatial Expert로는 Clip과 Temporal Expert로는 VideoMAE를 백본으로 사용했고, 사전학습된 가중치를 가져와 freeze한 후에 adapter를 활용해 학습을 진행합니다.
CAST의 경우, Spatial Expert와 Temporal Expert의 가중치를 불러와 사용하기에 각각의 Spatial과 Temporal Expert에 사용하는 백본을 정하여 사용하지만, ViT기반의 모델이라면 CLIP과 VideoMAE가 아니어도 사용할 수 있습니다.
기존 action recognition 연구에서의 방법론들은 대부분 Transformer(ViT, Swin Transformer 등) 기반의 모델을 scratch부터 학습하는 경우가 많기에 백본 모델이 어떠한 특정 모델이라 말하기는 어려울 것 같습니다. 백본 모델을 일치시키고 변인 통제한 완전한 공정한 비교는 불가능할 것이라 생각되지만, 논문에서 저자는 GFLOPS/Views 비교를 통해 성능과 연산량에 대해 리포팅하는 것으로 기존 방법론들에 비해 비교적 적은 연산량으로도 효과적인 성능을 내는 것을 리포팅하고 있습니다.
감사합니다.