안녕하세요, 허재연입니다. 얼마 후 KCCV에 참석할 예정인데, oral 및 poster 논문들을 몇개 미리 파악하고 참석하고자 합니다. 오늘 다룰 논문은 이런 취지로 미리 논문들을 살펴보다 읽어본 것으로 오랜만에 calibration이라는 주제가 눈에 띄어 읽어보았습니다. 해당 논문은 논문은 연세대학교에서 작성해 ICCV2023에 게재한 논문이며 KCCV2024 3일차 oral session에서 다루어질 예정입니다.
Model Calibration(카메라 캘리브레이션 아닙니다)에 대해 익숙하지 않은 분들은 이전에 관련하여 다룬 리뷰[1][2]가 있으니, 참고하면 좋을 것 같습니다.
리뷰 시작하겠습니다.
Introduction
근래 활발한 연구 결과 현대 딥러닝 모델은 다양한 분야에서 좋은 성능을 보여주고 있습니다. 하지만 정확도가 높다고 실제 산업 현장에 바로 도입할 수는 없습니다. 자율 주행 차량이나 의료AI등 모델의 잘못된 예측이 매우 큰 피해를 야기할 수 있는 분야에는 모델의 예측이 얼마나 신뢰할 수 있는지 측정할 수 있어야 합니다. 바꿔 말하면, 모델의 예측이 불확실할 때 이를 수치적으로 알 수 있어야 합니다. Model Calibration에서는 모델의 정확도와 모델의 예측 확률 결과가 유사하다면 신뢰할 수 있는 모델로 봅니다. 모델이 확신하지 못하는 예측에 대해 낮은 confidence값을 출력할 테니 이 값을 믿고 활용할 수 있겠죠. 하지만 이전 연구 결과 현대 딥러닝 모델의 예측 confidence가 실제 accuracy보다 상당히 높아서 틀린 예측을 과신하는 현상을 보인다는 것이 알려져 있습니다(overconfidence). 이런 overconfidence를 방지하기 위해 모델의 confidence값과 실제 accuracy 값 사이 차이를 줄여 교정하는 것을 model calibration이라고 합니다. 1000번의 예측을 시켰을 때 700번의 정답을 내놓고 평균 confidence가 0.7이라면 잘 calibrated된 모델로 볼 수 있습니다.
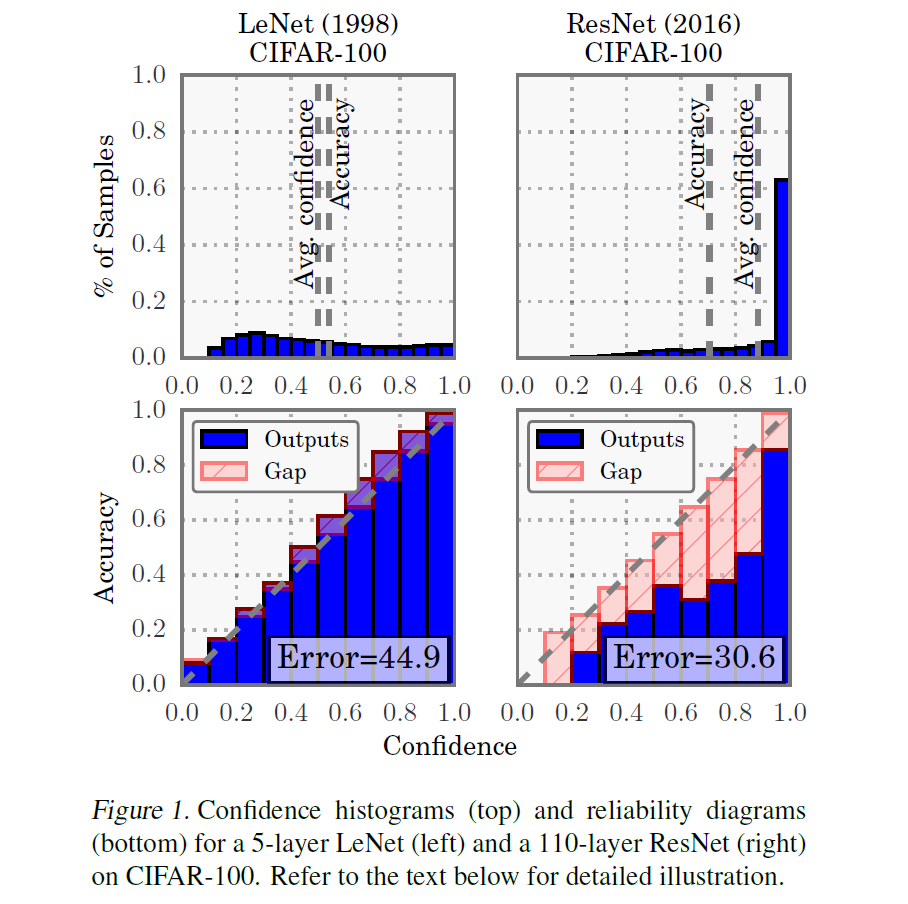
위 Figure1은 2017년 ICML에 게재된 현대 딥러닝 모델이 잘 calibration되지 않았다는 것을 밝힌 논문의 일부입니다. LeNet과 ResNet의 Confidence histogram 및 reliability diagram을 나타내 비교한 것인데, ResNet이 LeNet보다 Avg confidence와 Accuracy값의 차이가 크며 overconfidence한 경향을 보임을 확인할 수 있습니다.
많은 calibration 방법들이 지금까지 제안되었는데, 크게는 1. 사전학습된 모델의 miscalibrated probabilities를 직접 조정하는 Post-hoc 방법과, 2. 학습 도중 output probabilities를 calibrate하기 위해 cross-entropy loss에 추가적인 regulariation term을 추가하는 Training-time 접근법이 있었습니다. Post-hoc 방법은 바로 적용이 가능하긴 하지만 캘리브레이션 성능이 데이터셋과 학습 네트워크에 크게 좌우되며 training-test 간 distribution shift에 강건하지 못하다는 단점이 있습니다. Training-time 접근법으로는 label smoothing(LS), focal loss(FL), mixup을 활용하는 방법이 제안되었습니다. 본 논문에서 mixup을 활용합니다. 저자에 의하면 최근 mixup 기반 방법론들은 네트워크 캘리브레이션 자체에 대한 고려 없이 출력 확률값들을 soften하기 위해 입력 이미지와 학습 라벨값을 mixing coefficient에 따라 단순 interpolate했다고 합니다. 보간된 라벨들은 증강된 이미지에서 라벨 분포를 정확히 나타낼 수 없으므로 이러한 uncertain labels을 활용한 모델 학습은 calibration 성능을 저하시킨다고 설명하네요.
저자들은 이처럼 모델의 예측을 calibration하는데 단순 label값 mixture를 바로 사용하는 문제를 완화하는 RankMixup이라는 mixup기반 network calibration 방법을 제안합니다.


시작하기 전에 mixup에 대해 간단히 소개하자면 말 그대로 위 수식에 따라 두 이미지를 합성하는 데이터 증강 기법입니다. 합성 방법은 coefficient에 따라 두 raw image data를 linear interpolation하는 것이며, 학습 라벨도 동일한 coefficient로 interpolate하여 학습에 사용합니다. generalization 성능을 높이기 위해 활용되는 방법이라고 하네요. 관심 있으신 분들은 Manifold-Mixup이나 CutMix라는 키워드로 찾아보는 것을 추천 드립니다.

저자들은 증강되지 않은 raw image가 mixup된 이미지보다 더 높은 confidence값을 가질 것이라 가정하고, 이 아이디어를 구현하기 위해 raw image와 augmented image 간 mixup 강도 순위 관계 정보를 network calibration을 위한 supervisory signal로 활용했습니다.

Figure1을 보면 빨간 테두리 이미지는 증강 되지 않은 raw image이고, 파란색 dashed line 테두리 이미지는 강아지와 고양이 사진이 mixup된 이미지입니다. raw image는 mixup된 이미지보다 confidence값이 높을 것이고, mixup이 0.5:0.5와 같이 강한 이미지보다는 mixup coefficient가 0.9:0.1 정도로 약하게 적용된 이미지의 confidence값이 높은 것이라는 가정을 가지고 간다고 생각하시면 되겠습니다. mixup coefficient에 대한 confidence값의 순서 정보를 활용하겠다는 아이디어죠.
저자들은 우선 랭킹 관계를 보존하기 위해 mixup된 이미지들의 confidence가 raw sample들보다 낮아지도록 하는 mixup-based ranking loss(MRL)을 도입하고, 더 큰 mixing coefficient λ로 증강된 이미지가 더 큰 confidence를 가지도록 align하기 위해 정보 검색 분야의 normalized discounted cumulative gain(NDCG)을 기반으로 M-NDCG라는 loss를 도입합니다. 이는 coefficient와 confidence의 쌍이 misalign된 pair의 개수에 따라 패널티를 주게 됩니다.
이런 저자들의 방법이 좋은 성능을 보임을 다양한 실험으로 보였으며, 다음과 같은 contribution이 있다고 합니다:
- 우리는 네트워크 예측을 calibration하는데 사용되는 label mixture의 문제를 완화하기 위해 mixup 프레임워크 기반 RankMixup이라는 방법을 제안했다. 저자들이 알기로는 이 연구가 confidence calibration에 있어 이 문제를 다룬 최초의 연구이다.
- 우리는 mixture of label 대신 raw image와 augmented image 및 여러 augmented image들 사이 confidence 관계 정보를 활용할 것을 제안한다. 이 아이디어를 구현하기 위해 confidence와 mixing coefficient를 조정하여 관계를 보존할 수 있는 MRL 및 M-NDCG를 제안한다.
- 우리는 실험을 통해 다른 mixup기반 방법론들보다 좋은 성능을 보였다. 다양한 네트워크로 CIFAR, Tiny-ImageNet, ImageNet의 network calibration benchmark에서 경쟁력있는 성능을 보였다.
Method
RankMixup
mixup은 한 클래스에서 다른 클래스로 점진적으로 이동하는 smooth한 결정 경계를 제공해 regularized된 confidence(혹은 uncertainty)추정을 하게 하는데, 기존 많은 연구에서 mixup이 overconfident한 예측을 완화시켜 모델 캘리브레이션에 있어 개선된 확률 벡터를 출력하게 하는 것이 밝혀졌다고 합니다. 하지만 mixup 데이터셋 내부 interpolated label이 항상 augmented sample의 label mixture의 실제 분포를 모델링하지는 못하는데, 지금까지 네트워크 캘리브레이션 방법을 설계하는데 이를 고려하지 않았다고 합니다. 이 문제를 완화하기 위해 저자들은 raw sample와 augmented sample의 confidence 간 ordinal ranking relationship(증강하지 않은 raw sample이 더 높은 confidence를 가짐) 및 augmented sample들의 confidence 간 순서 정보를 활용합니다.

mixup 수식 (6)은 raw image xi에 일정량의 noise xj를 첨가한 것으로 해석할 수 있습니다. 이 때, 노이즈의 정도는 mixing parameter λ로 결정할 수 있습니다. 모델은 추가적인 노이즈로부터 발생한 uncertainty를 가지고 증강된 이미지의 클래스를 예측해야 하므로 augmented sample의 인식이 raw sample보다 어려울 것입니다. 믹스업은 증강 샘플에 대한 대상 라벨의 confidence를 λ로 조정하며 label mixture에 uncertainty를 부과하는데, 이 방법은 간단하긴 하지만 interpolated label을 바로 사용하면 모델이 적절하게 학습하는데 방해가 될 수 있다고 합니다. 이를 피하기 위해 저자들은 raw sample과 augmented sample 간 ordinal ranking relationship를 사용하며, raw sample이 augmented sample보다 식별하기 쉬움을 가정하여 다음과 같이 나타냅니다.

좌변은 raw image에 대해 class k에 대한 예측 확률 벡터이고, 우변은 augmented sample에 대한 class k의 예측 확률 벡터입니다. 저자들은 mixture of label 없이 모델이 이 관계를 학습하게 하기 위해 MRL을 고안합니다.
raw image와 augmented image간 관계 뿐만 아니라 여러 augmented image 간 confidence도 고려해야 합니다.

저자들은 mixing ratio λ가 감소함(0.9:0.1 -> 0.6:0.4)에 따라 증강된 sample이 더욱 인식하기 어려워질 것이라 가정하고 여러 augmented sample들 간에도 확신도 값 랭킹 관계 정보를 이용할 수 있을 것이라 분석했습니다(수식 8은 간결하게 표기하기 위해 i,j 두 augmented sample만 표기했지만, 더 많은 augmented sample들을 동시에 고려할 수도 있습니다). 수식 (7)과 (8)을 함께 작성하면 다음과 같이 나타낼 수 있습니다.

이러한 RankedMixup은 다양한 ranking 정보를 활용하여 network가 confidence 수준을 추측하는데 도움을 줄 수 있을 것이라고 합니다. 이 아이디어는 M-NDCG를 이용하여 구현되었습니다.
Training Loss
위에서 살펴본 정보들은 결국 loss로 구현되었으니 살펴보겠습니다. 모델 훈련에는 분류를 위해 CE loss가 사용되었고, 네트워크 캘리브레이션을 위해 MRL 혹은 M-NDCG가 parameter w로 밸런스를 맞춰 사용되었습니다. 학습을 위한 정답 정보로는(논문에서는 supervisory signal이라고 표현합니다) 분류를 위한 one-hot 라벨과 네트워크 캘리브레이션을 위한 augmented sample 및 ordinal ranking relationships(confidence 순위 정보)가 사용된다고 합니다.
MRL
Mixup-based Ranking Loss(MRL)는 위의 수식 (7)을 고려한 loss로, augmented sample의 confidence가 raw sample것보다 margin m 만큼 작도록 합니다.

여기서 margin m은 raw sample과 augmented sample의 confidence 간 불일치 강도를 조절하는데, 저자들이 말하는 margin을 사용하는 효과는 다음과 같습니다 :
- 정확한 불일치 값 자체에 패널티를 주기보다 confidence 간 순위 관계를 유지하도록 한다
- confidence discrepancy를 margin으로 조절하면 부정확한 label mixture의 uncertainty를 고려할 수 있다.
vanilla mixup방법은 augmented sample의 confidence가 label mixture에 의해 결정되는 overconfidence한 값에 도달할 때까지 패널티를 주지만, MRL은 신대로 간 불일치 절댓갑싱 margin 보다 낮을 때만 패널티를 주도록 합니다.
M-NDCG
더욱 더 많은 augmented sample들 간 비교가 필요하기 때문에 MRL만으로는 충분하지 않아서 추가적으로 augmented sample들간 confidence 랭킹 관계를 활용하는 M-NDCG를 추가적으로 도입합니다. M-NDCG는 여러 confidence값으로 ordinal ranking relationship 정보를 활용합니다. M-NDCG는 정보 검색(information retrieval) 분야에서 ranking quality를 평가하는 normalized discounted cumulative gain(NDCG)를 기반으로 한다고 합니다. 이는 얼마나 많은 검색 결과가 정답 랭킹 순서와 일치하는지를 측정하는데, discounted cumulative gain(DCG)를 ideal DCG(IDCG)로 정규화하여 계산된다고 합니다.

DCG는 각 검색 결과의 관련성 점수를 해당 순위로 가중하여 누적하고, IDCG는 비슷하게 계산되지만 ground truth 정보를 활용한다고 합니다. r_q와 rgt_q는 각각 Q 크기 결과 리스트의 q 위치에 있는 relevance 및 ground truth 점수라고 합니다(정보검색 분야는 잘 몰라서 논문에서 소개하는 내용대로 그냥 받아들였습니다. 배경지식이 없으니 이해하기 쉽지 않네요). 결국 정답 ranking값과 예측 ranking값의 일치도를 측정하는 것으로 받아들였습니다.

저자들은 prediction confidence와 mixing coefficients를 relevance score와 gt score로 활용하여 여러 confidence값이 (9)번 수식을 관계를 만족할 수 있도록 했습니다. Q개의 confidence pair와 mixing coefficient가 주어졌을 때 다음과 같이 계산된다고 합니다 :

t는 raw sample의 confidence value의 위치인데, 수식 (9)랭킹 관계에 따라 confidnece가 항상 내림차순의 첫번째에 위치하도록 하기 위해 1로 설정한다고 합니다. Q는 augmented samples의 수를 결정하는 하이퍼파라미터로, Q-1개의 augmented sample이 있게 됩니다. λgt_q는 크기를 기반으로 정렬된 mixing coefficient로, raw sample의 경우 1.0(top rank)으로 설정됩니다. 최종적으로 M-NDCG loss는 다음과 같습니다.

이 loss는 confidence와 mixing coeffients의 랭킹 순서가 서로 잘 정렬되어야 그 값이 작아지게 되어 mixup 강도에 대한 confidence 정렬 효과를 휴지하도록 합니다.
Experiment
저자들은 CIFAR10/100 , Tiny-ImageNet에서 주로 network calibration을 측정했으며 ImageNet에서 generalization 능력을 측정했습니다. calibration은 보통 Expected Calibration Error(ECE)로 측정하는데, confidence와 이에 해당하는 정확도의 절댓값 차이(error)를 측정하는 방식이기에 수치가 더 작을수록 좋습니다. ECE옆의 AECE는 Adaptive ECE입니다.

Table1은 SOTA calibration 방법론들입니다. 모든 데이터셋과 모델에서 SOTA를 달성하지는 못했는데, 저자들은 다음과 같이 해석합니다 : (1)제안한 방법론은 모든 mixup기반 방법론을 이겼다 (2) M-NDCG를 사용하는 방법이 ECE, AECE 모두에서 Tiny-ImageNet에서 가장 좋은 성능을 보여줬으며, CIFAR10/100에서도 경쟁력있는 성능을 보였다. 이는 confidence 간 ordinal ranking relationship 정보가 네트워크 캘리브레이션에 중요한 역할을 함을 뜻한다. (3)제안하는 방법론이 다른 ranking-based 방법론(CRL)을 크게 이기는 점에서, augmented sample 기반 더 복잡한 ranking 관계가 confidence를 추정하는데 더 도움이 됨을 알 수 있다 (4)저자들이 제안하는 방법론을 post-hoc 방법과 함께 사용하면 좋은 결과를 보이는데, 이는 서로 상호보완적으로 작용함을 뜻한다.
Table 2,3에서는 각각 ImageNet데이터셋 및 WideResNet 백본 사용 결과를 보입니다. 전반적으로 Table1과 비슷한 경향을 보이며, Table2에서 ImageNet에 대해서는 저자들이 제안하는 방법 중 M-NDCG가 가장 좋은 성능을 달성했습니다.


Table 5와 Figure2는 margin의 값을 어떻게 설정하는지에 관한 ablation study를 담았는데, margin값 설정에 대해 다양한 실험이 수행되었습니다. Figure2의 OE는 overconfidence error, UE는 underconfidence error를 뜻합니다.

오랜만에 calibration 쪽 논문을 리뷰했는데, 정보검색 분야 개념이 등장해 해당 부분의 이해는 쉽지 않았네요. calibration이 계속 연구되고 있다는것도 흥미로웠고, 아직도 classification task를 크게 벗어나지 못한 것 같아 아쉽습니다. 그리고 각 raw image 자체의 uncertainty가 고려되지 않은 점이 아쉽기는 하네요. 이만 리뷰 마무리하도록 하겠습니다.
감사합니다
안녕하세요 리뷰 작성해주셔서 감사합니다.
아래 표현에 대해 이해가 어려워 추가 설명을 요청드려도 될까요?
“Mixup은 한 클래스에서 다른 클래스로 점차 이동하며 결정 경계를 smooth하게 한다”
Label smoothing 에 대한 설명으로 이해하면 될까요? 제가 그동안 결정 경계에 대한 효과는 모르고 있었어서 질문 드립니다.
감사합니다.
음, 논문의 번역을 하는 과정에서 약간 잘못 작성한 것 같습니다. ‘mixup은 한 클래스에서 다른 클래스로 점진적으로 이동하는 smooth한 결정 경계를 제공’ 한다고 바꾸면 더 자연스럽겠네요. mixup의 Label smoothing에 대한 설명으로 이해하면 될 것 같습니다.