오늘 리뷰할 논문은 CVPR 2023년도에 발표된 TTA 분야의 논문입니다.
이전 방법론들과 비교했을 때 효율성 측면을 더욱 고려하여 모델 구조를 설계하고, 추가적으로 error accumulation, catastrophic forgetting 문제까지 완화하는 방법론을 주장한 논문입니다.
바로 리뷰 시작하겠습니다.
1. Introduction
TTA 분야의 연구는 최근 활발하게 진행되고 있습니다. TTA 의 특성 상 on-device setting을 고려하기 때문에 성능 뿐만 아니라 효율성 측면도 함께 고려가 되고 있죠.
이런 효율성을 위해 ICLR 2021-TENT 에서는 나머지 주요 parameter는 freeze한 채 BN layer 만을 update 하는 전략을 제시하였고, 이후 논문들에서도 해당 전략을 많이 채택하고 있습니다.
여담으로 전체 parameter 대신 BN layer만을 update하는 방식이 물론 효율성 측면에서도 좋지만, 모델 성능의 forgetting 측면에서 볼 때에도 훨씬 좋다고 합니다. online TTA 상황에서 gt 없이 설계한 entropy 기반의 signal을 통해 full parameter를 update하게 되면 오히려 모델이 collapse 될 확률이 높다고 하네요.
이렇듯 앞선 연구에서는 모델 전체 parameter 중 BN layer parameter 만을 update 하는 방식이 흔히 적용되었는데, 본 논문에서는 이 마저도 그다지 효율적이지 않다고 주장합니다. 이전 방법론들이 BN parameter 만을 update에 사용한 이유는 결국 learnable parameter를 줄이기 위함이였는데, 본 논문에서는 간단한 실험을 통해 learnable parameter 말고 메모리를 많이 차지하는 주범이 있다고 말합니다. 바로 activation layer 입니다.
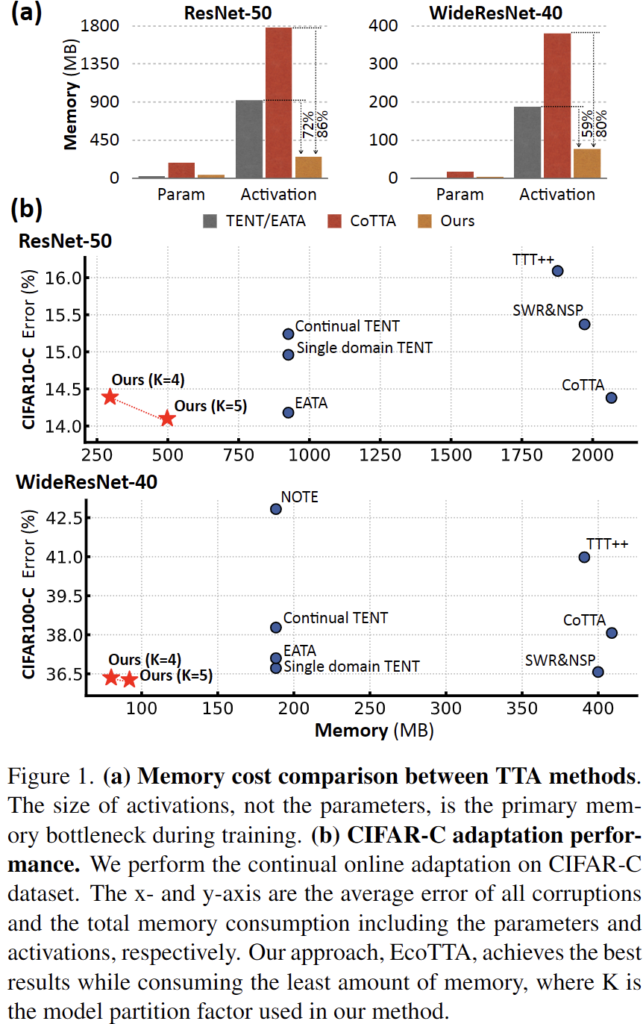
위 그림의 (a) 를 보시면 두 모델에 대해 각각 i) 전체 parameter와, ii) activation layer 가 차지하는 메모리를 비교하였습니다. 이를 통해 학습(TTA) 이 진행되는 과정 속에서 메모리 관점에서의 bottleneck은 parameter가 아니라 activation 이라는 점을 확인하였습니다.
(NIPS 2020의 TinyTL 이라고 하는 on-device learning 분야 논문에서 activation layer가 메모리적 bottleneck 이라는 것을 처음 밝혔긴 한데, 해당 개념을 TTA 기법에 적용하였다고 보시면 될 듯 합니다.)
(Tinytl: Reduce memory, not parameters for efficient on-device learning)
그리하여 이런 메모리적 bottleneck을 해결하는 방향으로의 기법을 설계하여 (b)에서 보시는 것과 같이 성능 및 메모리 측면에서 모두 좋은 결과를 달성하였습니다.
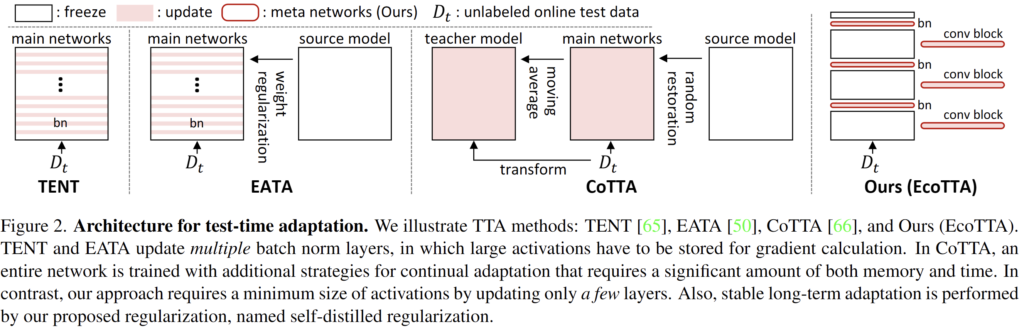
제안하는 기법에 대해선 method 단락에서 설명 드리겠지만 간단하게 설명드리자면 backward에 관여되는 activation layer를 줄이기 위해 단순히 update 하는 layer의 수를 줄이는 것입니다.
가령 위 그림 속 TENT 를 보시면 모델 전체 구조 중 bn layer 전체에 대한 update를 수행하였다면 본 논문에서는 전체 모델을 K개 (약 3~7) 의 block으로 나누고, 나눠진 경계에 대한 bn layer 만을 update 하는 방식을 사용합니다.
이를 통해 관여되는 activation layer의 수가 확 줄어들면서 메모리 효율성이 향상됩니다.
또한 TTA 분야의 고질적인 challenging issue인 catastrophic forgetting 및 error accumulation을 방지하고자 self-distilled regularization 기법을 설계합니다. 이에 대해서도 method 에서 설명 드리겠지만 간단하게 컨셉적으로만 설명하자면, 초기 source-pretrained 모델의 knowledge를 활용해서 모델에게 regularization을 부여함으로써 초기 knowledge를 유지하도록 하는, 이에 따라 model collapse를 방지하는 그런 역할을 수행합니다,
2. Method
2.1. Memory-efficient Architecture
Prerequisite
Introduction에서 언급드린 이전 on-device learning 분야의 논문, TinyTL 을 참고하여 모델이 forward 및 backward를 수행하는 과정 속에서 관여되는 것을 수식적으로 표기합니다. 그리고 이를 통해 activation이 memory 관점에서의 bottleneck이라는 것을 언급합니다.
전체 모델 중 i번째 linear layer의 weight와 bias를 각각 W, b 라고 표기합니다. 또한 해당 layer 기준 input, output feature를 각각 f_i, f_{i+1} 이라고 합니다. forward 수식을 표기해보면 f_{i+1} = f_iW+b 가 되겠죠.
그리고 아래 수식에서 i+1번째 layer에서 i번째 layer로의 backward backpropagation 을 표기한 것이 좌측, weight에 관여되는 gradient 를 의미하는 것이 우측입니다.
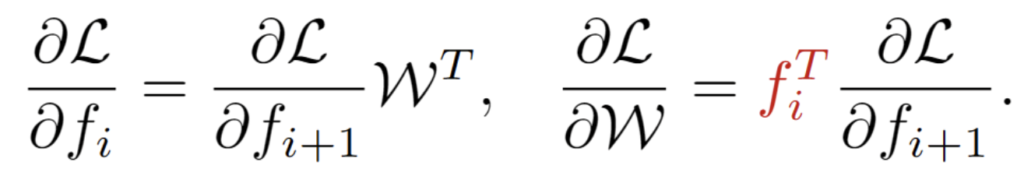
위 우측 수식을 통해 우리가 알 수 있는 것은, i번째 learnable layer의 weight W 의 gradient 를 계산하기 위해서는 해당 layer의 입력인 f_i 정보를 저장해야 함을 의미하고, 이 과정 속에서 activation layer 또한 관여되겠죠. 즉 이런 learnable layer가 많을수록 관여되는 activation layer도 많아짐을 뜻합니다.
그리하여 본 논문에서는 이런 learnable layer를 줄이기 위해 전체 bn layer를 update에 모두 사용하는 것이 아니라, 전체 모델을 K개의 구조로 나눈 후 그 사이사이의 K개 bn layer만을 update에 사용합니다. (intro-figure 2 & 아래 figure 3 참고)
Before deployment
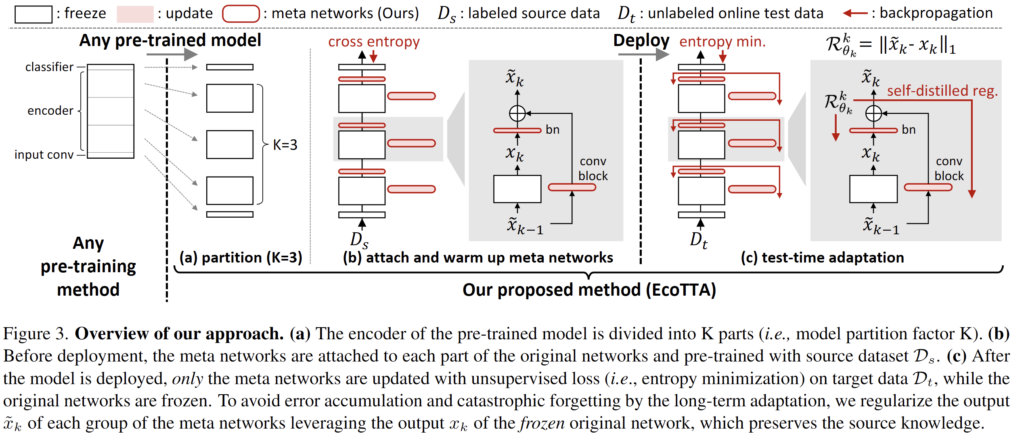
모델 구조는 위 그림 (a),(b)를 보시면 됩니다.
(a) 우선 pre-trained model을 K개의 part로 나눕니다.
(b) 그리고 각 part 사이사이에 가벼운 meta network를 부착합니다. 이는 하나의 bn layer와, 하나의 conv block(Conv-BN-ReLU) 로 구성됩니다.
모델을 real world 에 online deploy 시키기 전, source dataset을 사용하여 offline에서 K개의 meta network를 적은 epochs로 pretrain 하는 과정을 거칩니다. meta network를 제외한 original network는 freeze 시킵니다. 이를 warm-up 과정이라고 지칭하며, 이전의 많은 TTA 연구들에서도 deploy하기 전 source dataset을 사용해서 모델을 offline pretrain 하곤 했습니다. Test 상황에서 source dataset에 접근하는 것은 아니기에, TTA의 기본 전제를 해칠 위험은 없습니다.
Pre-trained model partition
최근 몇몇 TTA 연구들에서 주장하는 바에 의하면 TTA 수행 속 모델 전체를 update하는 것 보다, 모델 내 shallow layers 일부를 update 하는 것이 더 효과적이라고 합니다. 그리하여 본 논문에서도 K개의 meta network를 제외한 나머지는 freeze 하는 것이지요.
(K는 실험적으로 선정하게 됩니다.)
After deployment
전체적인 최적화 방식은 이전 연구들과 동일합니다. supervised signal이 없기 때문에 entropy minimization 을 수행하죠. 또한 entropy가 높은 test sample은 오히려 TTA의 성능에 악영향을 끼친다는 이전 EATA의 연구 결과를 차용하여, entropy가 pre-defined threshold H_0 보다 낮은 test sample 에 대해서만 entropy minimization을 수행합니다. 아래 수식으로 말이죠.
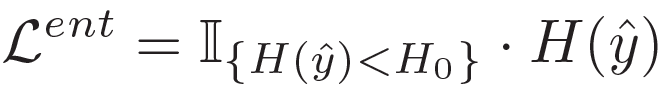
또한 이후 단락에서 설명드리겠지만, catastrophic forgetting 및 error accumulation를 완화하고자 본 논문에서는 regularization loss term을 설계합니다. 그리고 이를 반영하여 최종 loss function을 구성합니다.
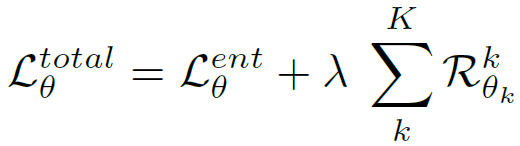
2.2. Self-distilled Regularization
long-term continual TTA 세팅에서 모델은 연속적으로 많은 test sample들을 마주하고, gt가 없는 상황 속에서 unsupervised loss (ex. entropy) 를 설계해서 모델을 최적화해나갑니다. 이러한 과정 속에서 unsupervised loss 자체의 부정확성 때문에 catastrophic forgetting 및 error accumulation 문제가 TTA의 고질적인 문제점으로 지적되어왔습니다. 그리고 이를 완화/해결하고자 많은 노력들을 가하고 있구요.
본 논문에서는 이를 해결하고자 꽤나 직관적이면서도 효과적인 self-distilled regularization 이라는 기법을 제시합니다. 이해를 위해 위 전체 figure 중 일부를 캡쳐해서 설명을 진행하겠습니다.
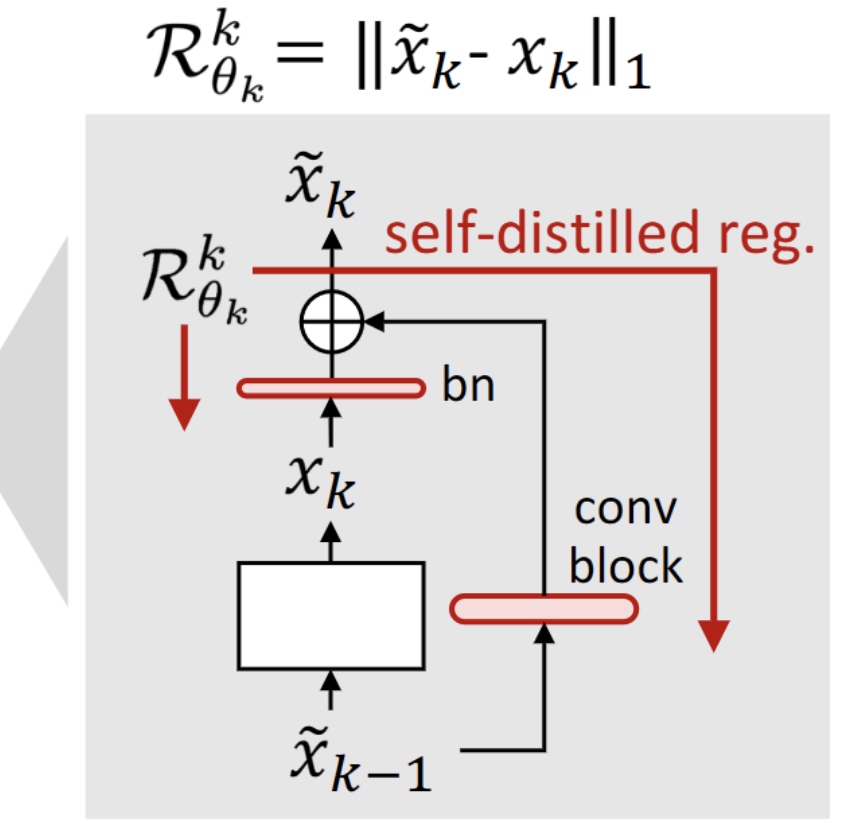
성공적인 TTA를 위해서는 meta network의 output인 \tilde{x}_k 에 error 가 누적되면 안되고, 기존 source knowledge의 forgetting도 진행되면 안됩니다. 그리하여 \tilde{x}_k 에다가 regularization을 부여하기 위해 x_k 를 사용합니다. x_k를 잘 살펴보시면 실제 update되는 블럭(bn, conv block) 을 거치지 않은, 즉 기존 source pre-trained block만을 통과하여 생성됩니다. 즉 source pre-trained knowledge를 잘 반영하고 있을 것이며, 이를 통해 \tilde{x}_k 에 regularization을 부여한다면 catastrophic forgetting 방지도 가능하겠죠. 또한 original model(source pre-trained model)의 class 분별력이 그대로 적용되기에 error accumulation 또한 방지됩니다.
(일반적으로 error accumulation로 인해 class 분별력을 잃게 됩니다)
저자들은 위 regularization term을 통해 효과적이면서도 효율적인 TTA가 가능하도록 합니다. 실험적으로도 이 효과를 증명했구요.
3. Experiment
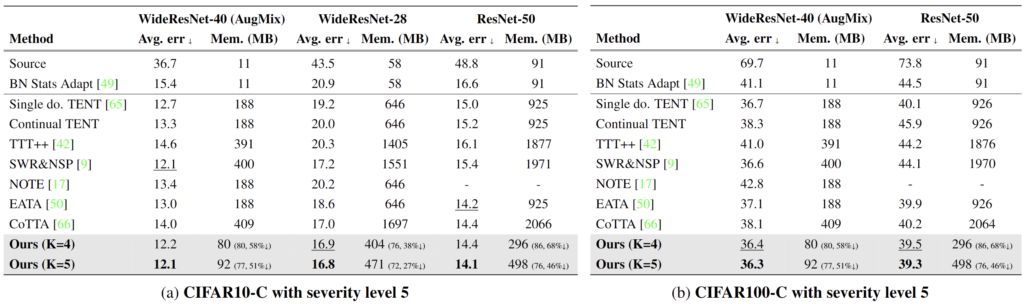
우선 classification에서의 실험입니다.
(a) 는 CIFAR10 to CIFAR10-C 의 결과를 , (b)는 CIFAR100 to CIFAR100-C 의 결과를 리포팅하고 있습니다.
ours 방법론에 대해 크게 K=4, 5개의 meta network를 사용하여 타 방법론과의 비교를 수행하였습니다. EATA과 CoTTA 방법론과 비교하였을때 성능적으로도 향상이 일어났지만, 특히 메모리적 효율성이 많이 증가한 것을 알 수 있습니다. 또한 deploy 전 모델을 pre-trained 하는 과정에서 Augmix 와 같은 strong augmentation 을 적용하였을때에도 효과를 톡톡히 보았다는 실험적 결과를 보여줍니다. TTA라는 기법 자체가 test time 에 보지 못한 sample 에 대해서도 prediction 을 잘 해야하기 때문에 source 에서 augmentation을 적용해서 이에 대한 강건성을 부여한다고 생각하면 되겠네요.
(다만 Augmix 의 유무에 대한 실험 비교는 없기에 이에 따른 직접적인 이점에 대한 정확한 판단은 어렵습니다)
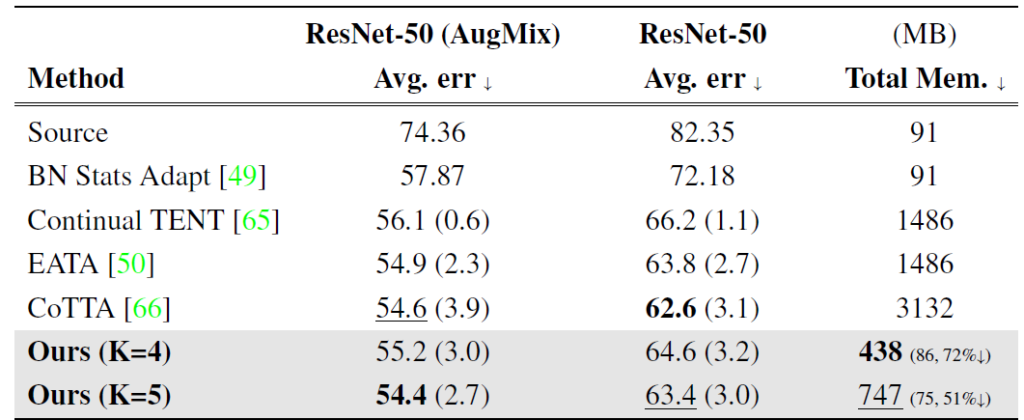
네, Augmix에 대한 직접적인 비교가 없다고 말씀드린 순간, ImageNet to ImageNet-C 실험에서는 Augmix의 유무에 따른 동일 백본 실험을 수행했네요 ㅎㅎ..
해당 실험을 통해 TTA 모델을 offline source pre-train 시키는 과정에서의 data augmentation의 중요성을 저 스스로 알게 되었네요. 모든 방법론에 대해 Augmix를 적용하였을 때 많게는 15%나 error 가 하락하네요. (wow..!!)
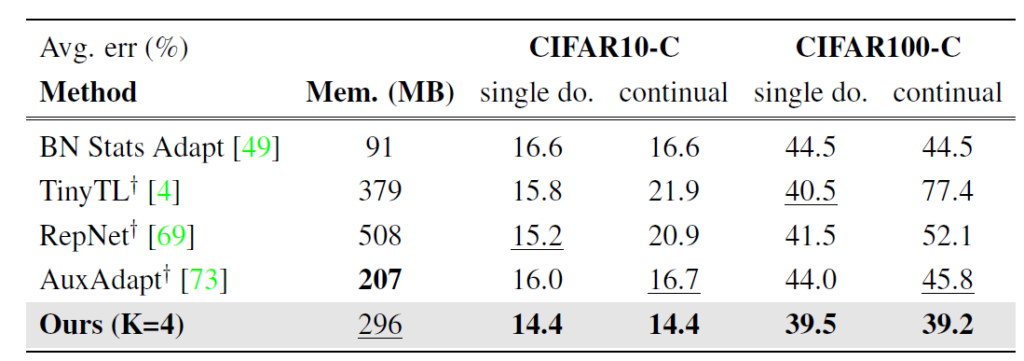
위는 on-device learning 방법론들과의 비교 실험입니다.
TinyTL, 그리고 RepNet은 on-device learning 방법론이며, on-device 상황에서 target sample에 대해 supervised 학습을 하는 방식으로 모델이 최적화됩니다. 즉 target data에 대해 gt label이 필요하다는 것이죠. 하지만 TTA 기법은 target gt가 없는 상황 속에서 실험을 진행하기 때문에 fair한 비교를 위해 on-device method의 supervised loss를 entropy minimization과 같은 unsupervised loss로 대체하여 비교 실험을 진행했다고 합니다.
실험 결과에서 알 수 있다시피 TinyTL, 그리고 RepNet의 continual 성능을 보면 ours 대비 많이 낮은 것을 확인할 수 잇습니다. continual 상황을 타겟으로 설계된 방법론이 아니기에, 점차적으로 모델 성능이 하락한 것이죠.
반면 AuxAdapt는 ours와 유사하게 pre-trained network는 freeze한 채로 small network를 추가하여 이를 update 하면서 adaptation 을 수행하는 방법론입니다. 모델 전체를 update하는 것이 아니기에 앞선 TinyTL, 그리고 RepNet과 비교했을 때 error accumulation 문제는 덜 겪는 모습을 continual 성능을 통해 알 수 있습니다.
그럼에도 ours 와 비교했을 때에는 성능적으로 차이가 꽤나 나는것을 확인할 수 있습니다.
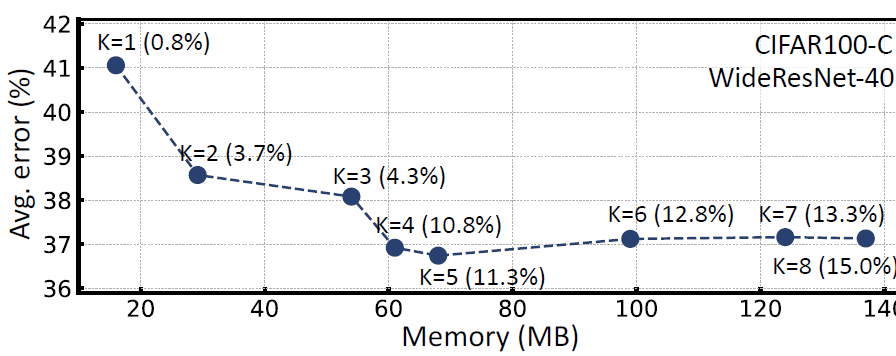
위 figure는 meta network의 수 K와 관련된 ablation 실험입니다.
x축은 메모리, y축은 classication error를 의미하며, 괄호 안의 % 는 기존 source model 대비 parameter의 상승 비율을 뜻합니다.
K=1,2 와 같이 작은 K값에 대해서는 사실상 모델 중간중간에서 output feature map 이 거의 adapt되지 않기 때문에 성능적으로 아쉬운 결과가 나오고 있습니다. 어떻게 보면 당연합니다.
반면 K=6,7 이상의 큰 값에 대해서는 이미 error rate 가 seturation 되었기 때문에 굳이 이렇게 많은 meta network를 구성할 필요가 없다고 합니다. 메모리 적으로도 손해이구요.
그리하여 저자는 K=4 혹은 5의 값으로 설정했다고 합니다.

본 논문에서는 TTA 성능을 semantic segmentation 에 대해서도 평가합니다. cityscapes 에 대해 source pre-trained 된 모델을 4가지 날씨 변화에 대해 TTA 하는 결과를 리포팅합니다.
continual 한 상황 속 round 가 후반으로 진행됨에 따라 Continual TENT 에 비해 error accumulation 및 catastrophic forgetting 을 잘 해결했음을 볼 수 있습니다.
그런데 round1과 round10과의 성능 차이가 소수점만 아주 조금 다른것으로 보아… adapt라기 보다는 source knowledge 유지! 에 좀 초점이 가 있는거 같긴 합니다만, 제가 느끼기에 이 현상은 최신 continual TTA 방법론들에서 대부분 나타나는 현상인 듯 합니다.
아무래도 어줍잖게 adaptation 하다가 model collapse가 발생할 바에, 아주 조금 adapt만 해서 기존 source 지식을 잘 유지하자! 가 TTA의 기저가 된 느낌이랄까요?
오늘은 Continual TTA 분야의 논문에 대해 읽어보았습니다.
한국인 저자이기도 하고, 작년 publish 된 논문인데 인용수가 40을 넘어섰기에 언젠가 읽어봐야겠다는 생각을 가지고 있었습니다.
저자의 contribution 2개중 특히 2번째 self-distilled reguralization term 부분이 꽤나 인상깊었습니다. 사실 직관적이긴 합니다. source pre-trained knowledge 를 계속 보존하기 위해 regularization term을 부여하는 것이죠. 하지만 이를 meta network 의 2가지 output 사이에서 feature level에서, self-distilled 하게 설계한 포인트는 꽤나 신박했습니다.
이 논문이 arXiv 버전 기준으로 appendix까지 포함해서 실험 table이 20개나 되는, 아주 실험적으로 풍부한 논문인 것을 리뷰 작성 후에야 알게 되었습니다. 리뷰에는 넣지 못한 실험들이 많지만, TTA 분야에서의 저자의 고찰을 파악하고 싶은 마음이 크기에 다음주 중으로 appendix까지 모두 읽어 보는것을 목표로 삼고 있습니다. 이후, 리뷰에 추가할 만한 양질의 내용이 있다면 수정하도록 하겠습니다.
감사합니다.