안녕하세요, 서른 아홉번째 x-review 입니다. 이번 논문은 2023년도 ICCV에 게재된 Multi-modal 3D Object Detection with Object-Centric Fusion입니다. 그럼 바로 리뷰 시작하겠습니다 !
1. Introduction
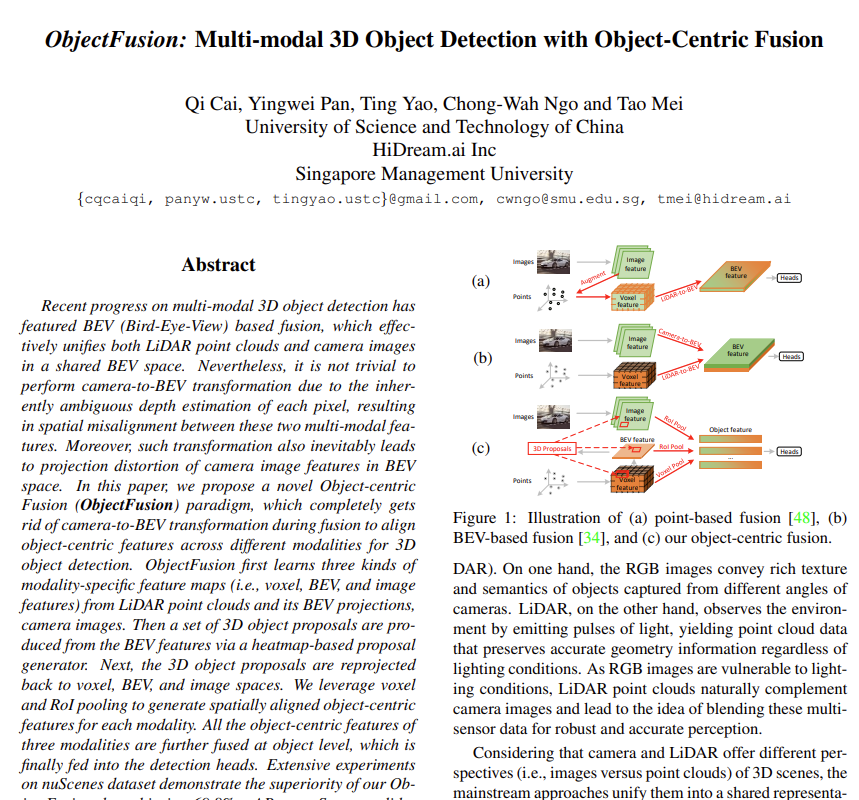
3차원 물체 검출은 3차원 공간 내에서 물체가 무엇이고 어디에 있는지 파악할 수 있는 가장 기본이 되는 task 중 하나이죠. 자율주행 관점에서 3차원 물체 검출은 주변 환경을 인지하는데 있어 중요한 역할을 하는데요, 그렇기 때문에 카메라 뿐만 아니라 다양한 센서를 활용해서 여러 환경에서 강인한 물체 검출을 시도하고 있습니다. 가장 대표적으로 카메라와 라이다 센서 융합을 예시로 들 수 있을 것 같습니다. 카메라는 여러 뷰의 이미지를 통해서 물체에 대한 texture와 semantic한 정보를 제공할 수 있고 반면에 라이다는 포인트 클라우드 형태로 데이터로, 이미지와는 다르게 장면의 기하학적인 정보를 제공할 수 있습니다. 서로 다른 형태로 데이터를 제공하는 이 두 센서의 정보를 합치기 위해 보통은 공유된 하나의 representation 공간으로 통합하게 됩니다. 이러한 융합 방식을 크게 두 갈래로 살펴볼 수 있는데, 먼저 포인트 기반의 융합 방식이 있고 두 번째는 가령이다로 취득한 포인트 클라우드 데이터를 projection해서 BEV 공간에서의 융합 방식이 있습니다. 먼저 전자 같은 경우에는 Fig.1(a)에서 볼수 있듯이 이미지를 3차원 공간으로 올려서 해당하는 이미지의 feature level 혹은 semantic score로 포인트가 augment 됩니다. 이 포인트가 이제 복셀 그리드를 거쳐서 BEV 공간의 feature로 변환됩니다. 그런데 이 전자의 방식은 포인트와 이미지의 일부분에만 연결되어 이미지가 제공하는 풍부한 semantic 정보를 완전히 활용하지 못한다는 한계점이 있습니다. 반면에 후자는 Fig.1(b)에서 볼 수 있듯이 이미지와 라이다를 각각 BEV feature로 변환해서 하나의 공유된 BEV feature로 합치는 방식 입니다. 전자에 비해 훨씬 개선된 성능을 보이곤 있지만 이미지에서 BEV 공간로의 변환에서 이미지 픽셀 별 depth를 추정하기 위해서 기존에 존재하는 detph estimation 알고리즘에 대한 의존도가 높다는 한계점이 존재합니다. 그렇다면 depth estimation 결과가 부정확하다면 공유된 BEV 공간에서 포인트와 이미지 픽셀 사이의 misalignment를 발생시킬 수 있습니다. 또한 이미지와 BEV feature는 데이터 특성이 매우 다른데, 이미지는 멀티 뷰에서 촬영되는 반면 BEV feature는 높이 dimentsion을 기준으로 top-down 방식으로 합쳐진다는 점 입니다. 그래서 이미지 feautre을 BEV 공간으로 바로 넘기게 되면 당연하게도 projeciton 왜곡이 발생할 수 밖에 없고 이미지가 가지고 있던 고유한 semantic 구조가 망가지게 됩니다.
그래서 저자는 이런 이전까지의 융합 방식들의 한계점을 해결하기 위해 이미지에서 BEV 공간과 같이 모달리티 간의 변환을 하지 않고 멀티 모달리티 간의 융합을 할 수 있는 방식에 대해 생각하게 됩니다. 그 결과가 바로 Fig.1(c)와 같이 물체 중심의 융합, 즉 논문에서 제안하는 ObjectFusion이 됩니다. 각 모달리티에서 물체 중심의 표현력을 얻고 물체의 바운딩 박스에 따라서 그 표현을 공간적으로 align 맞추는 것이 핵심이라고 합니다. 이를 통해 두 모달리티를 융합하는 과정에서 서로의 공간으로 변환하는 과정을 제거할 수 있었으며 물체 중심의 표현력을 합치게 됩니다. 이를 통해 ObjectFusion은 모달리티 별로 얻게 되는 고유한 feature들을 보존하면서 개선된 융합 결과를 낼 수 있었습니다.
2. Approach
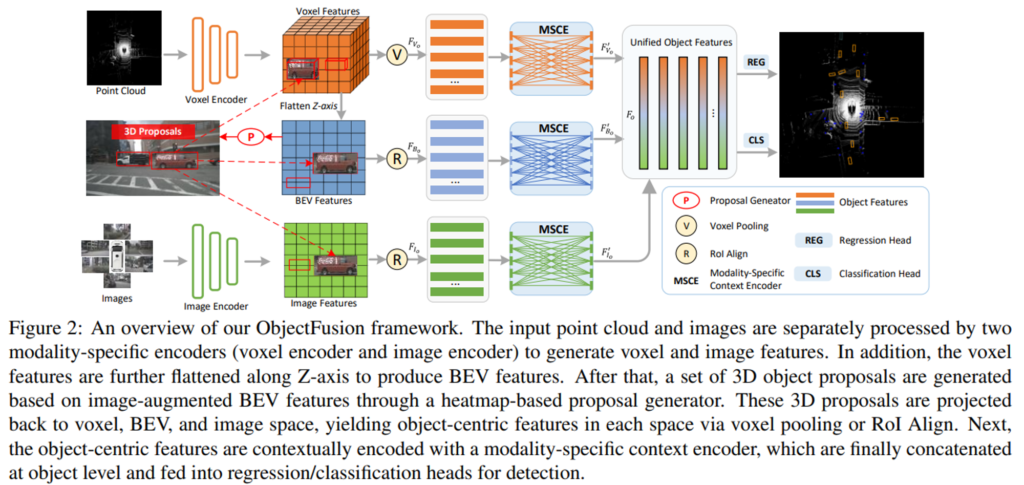
간략하게 파이프라인 먼저 살펴보도록 하겠습니다. Fig.2에서 볼 수 있듯이 ObjectFusion은 크게 세 가지 부분으로 나뉘어져 있습니다.
- 각 모달리티에 대한 표현력을 학습하는 복셀/BEV/이미지 인코더
- 라이다의 포인트 클라우드와 해당하는 멀티뷰 이미지가 입력으로 주어지면 각 포인트, 이미지 인코더를 통해 복셀 및 이미지 feature map을 추출하게 되겠죠. 그런 다음 복셀 feature 맵을 z축을 따라, 즉 height dimension에 따라 BEV feautre map을 생성합니다.
- 세 모달리티의 물체 중심 표현력을 합치는 fusion 모듈
- BEV feature map을 기반으로 3차원 물체에 대한 proposal을 생성합니다. 각 proposal에 대해서 3차원 박스를 복셀과 BEV, 그리고 이미지 공간으로 투영하고 모달리티 별로 feature map에서 물체 중심의 feature을 다시 추출합니다. 물체 중심의 feautre는 모달리티 별 context 인코더를 통해서 추가적으로 인코딩되어서 물체 간의 관계를 효과적으로 활용하고자 하였습니다. 그리고 통합된 물체 중심 feature가 결과적으로 detection head에 제공되는 것이죠.
- 3차원 박스 및 클래스를 예측할 detection head
2.1. Modality-Specific Encoders
그럼 첫번째 파트인 인코더 먼저 살펴보도록 하겠습니다. 포인트 클라우드와 이미지 데이터가 입력으로 주어지면 모달리티 별로 인코더를 구성하여 복셀, BEV, 그리고 이미지 공간에서의 feature을 추출한다고 했었죠. 각각의 인코더에 대해 설명하기 전에 기본적인 notation 먼저 정리하고 넘어가도록 하겠습니다.
- P = \{p_i | i \in [1, N_p]\} : N_p개에 해당하는 전체 포인트 클라우드 집합
- p : (x, y, z, r)로 주어지는 개별적인 포인트 클라우드
- I = \{I_n | I_n \in \mathbb{R}^{3 \times H \times W}; n \in [1, N_c]\} : N_c개에 포함되는 전체 멀티뷰 이미지
Voxel Encoder
먼저 P에 대해서 feautre를 추출하기 위해 포인트 클라우드를 복셀 형태로 처리하는 방법론인 VoxelNet을 활용하였다고 합니다. 이는 포인트 클라우드를 동일 크기의 복셀 그리드 공간으로 나누고 동일한 그리드에 포함된 포인트 좌표를 복셀 feature로 aggregation 하는 방식 입니다. 이러한 방식을 통해 sparse하고 불규칙한 밀도로 주어지는 포인트를 규칙적인 그리드로 변환할 수 있고 각 복셀에 feature 벡터를 표현할 수 있습니다. 그런 다음 백본 네트워크를 거쳐서 입력 포인트에 대한 복셀 feature F_v \in \mathbb{R}^{N_v \times C_v}와 복셀의 중심 featuer V_c \in \mathbb{R}^{N_v \times 3}을 추출하게 됩니다. ( N_v : 복셀의 수, C_v : 복셀 feature 채널을 의미합니다. )
BEV Encoder
앞서 위에서 추출한 F_v와 V_c를 이용해서 Z축을 기준으로 feature map을 쌓아서 동일한 X, Y 좌표의 복셀 feautre을 하나의 벡터로 합치게 됩니다. 이렇게 복셀 feature가 2D feature map으로 변환되고 2D CNN을 통해 BEV feature이 F_B \in \mathbb{R}^{C_B \times H_B \times W_B}을 추출합니다.
(C_B : BEV feature의 채널)
Image Encoder
I_n이 주어지면 2D 백본으로 swin transformer을 사용합니다. 멀티 스케일의 이미지 feature map을 백본을 통해 추출하고, 추가적으로 FPN을 사용해서 단일 스케일의 feature map인 F_{I_n} \in \mathbb{R}^{C_I \times H_I \times W_I}을 추출하네요. feature map은 원본 이미지 해상도의 1/8, 즉 H_i = H/8, W_I = W/8로 다운샘플링 합니다. 결국 N_c 이미지의 feature map을 합쳐서 전체 이미지 feature map F_I \in \mathbb{R}^{N_c \times C_I \times H_I \times W_I}을 만들게 됩니다.
2.2. Object-Centric Fusion
멀티 모달리티의 feature map을 합치기 위해 intro에서 말했듯이 기존에는 BEV 기반의 융합 방식을 사용하곤 했습니다. 그러나 이미지에서 BEV로의 변환에서 픽셀마다의 depth를 추정하기 위해 사전학습된 depth estimation 모델에 의존도가 높다는 한계점이 있었죠. depth 추정이 부정확해지면 이미지와 포인트 feature map 간의 공간적인 alignment가 맞지 않게 되는 문제로까지 이어져 detection 결과에까지 영향을 미치게 됩니다. 또한 이미지와 BEV 공간의 다른 특성 때문에 직접적으로 투영하게 되면 왜곡이 발생하게 된다고도 이야기했었죠. 그래서 이러한 문제를 해결하기 위해 새로운 물체 중심의 fusion 모듈을 제안하게 된 것 입니다. 먼저 BEV feature에서 히트맵 기반의 3차원 물체 propoal을 생성한 다음, 그 proposal을 복셀과 BEV 그리고 이미지 공간에 투영하여 각 차원에서 물체 중심의 feature을 추출합니다. 2단계로 물체 중심의 feature을 먼저 각 인코더로 추출하고, 각 proposal에 대해 합쳐진 물체 feature로 합치는 과정을 거칩니다.
Heatmap based Proposal Generator
여기서는 BEV feature을 입력으로 3차원 물체 proposal을 생성하는데, 이는 추가적인 물체 중심 feature를 추출하고 합치는 과정을 용이하게 합니다. 우선 추가적인 이미지 정보를로 BEV feature을 보완하기 위해 추가적인 이미지 정보를 통해 대부분의 TP가 마지막 detection head의 후보 집합에 포함되도록 하였는데요, 이는 기존의 BEVFusion이라는 방법론을 그대로 사용했다고 합니다. BEV feature로 먼저 히트맵 head를 활용해서 물체 클래스 별 objectness map S \in \mathbb{R}^{K \times H_B \times W_B}를 예측합니다. 그런 다음 초기 3차원 물체 쿼리의 위치로 여길 수 있는 S에서 objectness 점수가 가장 높은 상위 O (\{q^p_o|q^p_o \in \mathbb{R}^2; o \in [1, O]\})개의 위치를 선택합니다. 그리고 동일한 물체에 대해 중복되는 proposal을 없애기 위해서 상위 O개의 위치를 선택할 때 peak finding 알고리즘이라는 것을 통해 각 objectness map 위치에서 로컬한 최대값을 찾습니다. 그런 다음 그 최대값 위치의 F_B로부터 쿼리 feature \{q^p_o | q^p_o \in \mathbb{R}^2; o \in \}를 초기화 합니다. 그 후 트랜스포머 디코더 레이러를 사용해서 F_B를 물체 쿼리 feature q^f_o로 합칩니다. 여기서 물체 쿼리는 FFN을 통해 3차원 바운딩 박스 B = \{b_o | b_o = (x, y, z, w, l, h, \theta); o \in [1, O]\}로 디코딩 됩니다.
Object-Centric Voxel Feature
포인트 클라우드를 규칙적인 복셀 형태로 표현했을 때는 위치와 기하학적인 정보를 보다 정확하게 인코딩할 수 있다는 점 입니다. 그래서 복셀 풀링을 이용해서 주어지는 각 proposal의 복셀 feature F_V, 복셀 중심 V_C, 그리고 3차원 바운딩 박스 b_o에서 물체 중심의 복셀 feature을 추출하게 됩니다.
복셀 풀링 과정을 좀 더 자세하게 얘기해보면 b_o를 G \times G \times G 크기의 동일한 서브 복셀로 나누고 각 서브 복셀의 중심 포인트를 그리드 포인트로 간주하게 됩니다. 그런 다음 각 그리드 포인트에 대해 특정 반경 내에서 C_V와 가장 가까운 복셀을 찾고, F_V의 해당 복셀 feature을 그리드 포인트에 합칩니다. 마지막으로 모든 그리드 포인트의 feautre을 모두 합쳐서 proposal b_o에 대한 물체 중심의 복셀 primary feature인 \hat{F}_{V_o} \in \mathbb{R}^{C_v \times G \times G \times G}를 생성합니다. 이러한 과정을 식(1)과 같이 정의할 수 있습니다.

이렇게 feature을 구하고 나면 3D CNN을 거쳐서 최종적인 물체 중심의 복셀 feature인 F_{V_o}를 만들 수 있게 됩니다.
Object-Centric BEV Feature
sparse한 복셀 feature F_V와 비교해서 BEV feature F_B는 aggregation을 통해 훨씬 밀도 높게 컨텍스트 정보를 포함할 수 있는 포인트 클라우드 표현 방식에 해당합니다. BEV feature인 R^{C_B \times H_B \times W_B} shape으로 2D feature map으로 나타내고 2D RoI pooling을 이용하고자 RoIAlign을 사용해서 BEV feature map에서 물체 중심의 feature을 추출합니다. 3차원 바운딩 박스 b_o에서 8개의 모서리는 height 차원을 기준으로 BEV 공간으로 투영하게 됩니다. 그런 다음 BEV 공간에서 8개의 모서리를 모두 커버할 수 있는 최소 축이 align된 바운딩 박스 b^B_o \in \mathbb{R}^4는 b_o의 projection의 결과 입니다. 다음으로 RoIAlign은 이 b^B_o를 r x r 크기의 동일한 간격으로 하위 영역을 나누고, bilinear interpolation을 사용해서 F_B의 feature을 각 하위 영역으로 합치게 됩니다. 마지막으로 모든 하위 영역의 feature을 합쳐서 물체 중심의 BEV feature \hat{F}_{B_o} \in \mathbb{R}^{C_B \times r \times r}를 형성하며 이는 식(2)와 같이 정의할 수 있습니다.

물체 중심의 복셀 feature와 유사하게 이렇게 나온 feature을 2D CNN을 사용해서 최종적인 BEV feature인 F_{B_o}로 얻을 수 있습니다.
Object-Centric Image Feature

앞선 과정까지는 복셀과 BEV를 통해 물체의 기하학적인 정보를 취득할 수 있지만 물체의 texture와 semantic한 정보를 얻기에는 부족하죠. 그래서 이러한 정보는 이미지를 통해 얻고자 하게 됩니다. 이미지에서 물체 중심의 feature을 학습하기 위해 b_o를 카메라 이미지 평면에 projection해서 2D 바운딩 박스 b^I_o \in \mathbb{R}^4를 구합니다. 여기서 박스의 8개 모서리와 이미지에 투영된 b_o의 X, Y 좌표를 계산합니다. 이는 여러 이미지가 서로 다른 카메라 뷰에서 나오기 때문에 물체 중심 feature을 추출할 때 사용할 위치를 구해야 하기 때문입니다. 물체의 위치와 크기에 따라서 3차원 박스의 projection은 여러 카메라의 FoV에 속하거나 혹은 FoV의 외부에 속할 수도 있겠죠. 만약 모서리가 모든 카메라의 FoV 외부에 속하는 경우 b_o에 대한 해당 이미지 feature는 버리게 됩니다. 그렇지 않으면 투영된 모서리를 가장 많이 포함하는 이미지를 선택해서 물체 중심의 feature을 추출합니다. 이 과정에서 선택한 이미지 평면에서 AABB 형태의 박스를 계산하게 되는데요, AABB와 이미지 바운더리 사이의 교집합을 2D 바운딩 박스 b^I_o 삼아 물체 중심 feature \hat{F}_{I_o}를 학습합니다.
여기서 추가적으로 센서 misalignment를 고려해서 이를 완화하기 위해 간단하게 RoI 확대 작업을 수행합니다. Fig.3과 같이 이미지 평면에 투영된 2D 박스의 RoI 크기를 두 배로 늘리는데, 이는 이미지에서 추출한 물체 feature가 3D-2D 공간에서 완벽하게 align이 맞지 않는 경우에도 관심 물체를 포함시킬 수 있는 것 입니다. 마지막으로 이미지 공간에서 물체 중심의 이미지 feature F_{I_o}를 추출하기 위해 앞선 과정들과 마찬가지로 CNN과 RoIAlign을 사용한다고 합니다.
Two-stage Fusion Scheme
이제 복셀, BEV, 그리고 이미지 공간의 물체 중심의 feature를 구했으니 모달리티 간의 물체 및 표현력 학습을 위해 2단계의 융합 과정을 설계하였다고 합니다.
첫번째 단계에서는 모달리티 별 컨텍스트 인코더 (MSCE)를 통해 물체 feature가 동일한 모달리티에 있는 나머지 물체의 feature와 context화 하게 됩니다. 여기서 MSCE는 트랜스포머를 사용하며 식(3), (4), (5)를 통해 각 모달리티에서 feature들을 구할 수 있습니다.
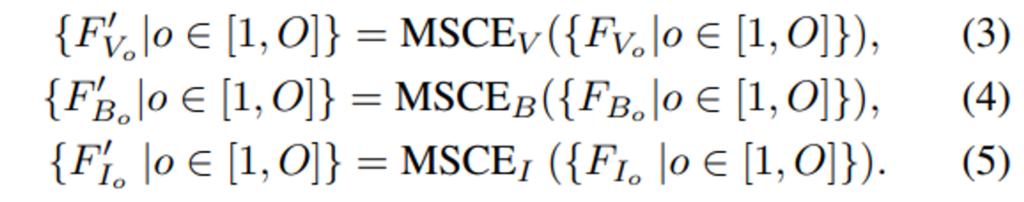
두번째 단계에서는 각 물체 proposal b_o에 대해 해당되는 물체 중심 feature을 세 가지 모달리티에서 합치고 FFN을 통해 최종적인 하나의 통합된 F_o를 구할 수 있게 됩니다.
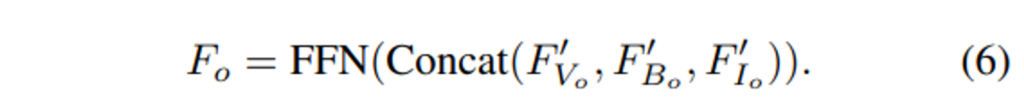
이러면 통합된 하나의 물체 중심 feature F_o는 다음 단계인 detection head에 제공되는 쿼리 q^f_o와 추가로 통합되며 전체 2단계 fusion 과정은 식(7)과 같이 동작하게 됩니다.
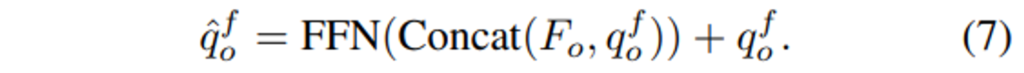
3. Experiments
실험은 3D detection에서 outdoor 데이터셋으로 사용되는 nuScenes를 사용하였습니다.
평가 메트릭은 mAP와 NDS를 사용하였는데요, 여기서 NCD는 mAP와 translation, scale, orientation, velocity 그리고 attribute 에러 등 기타 지표 결과를 가중 평균한 결과라고 합니다.
3.1. Comparisons with State-of-the-Art Methods
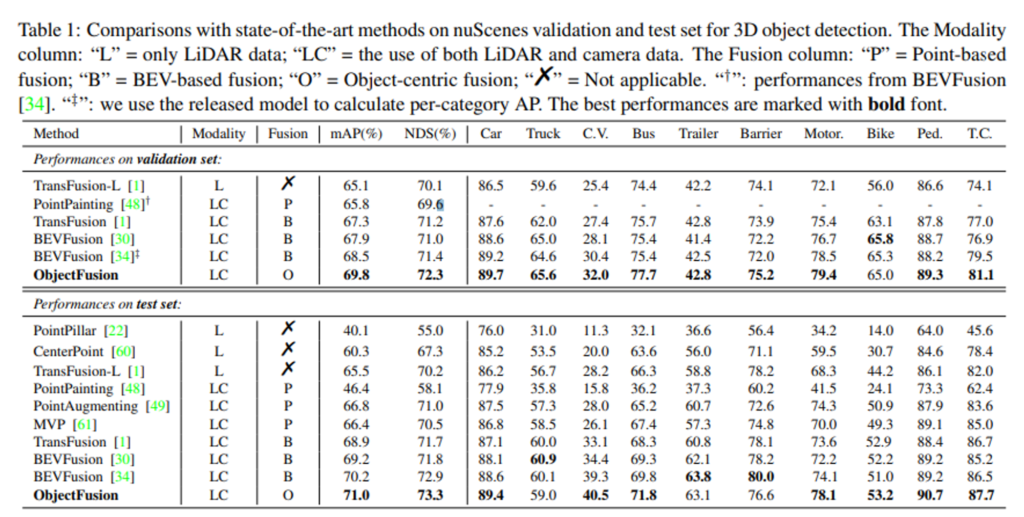
가장 먼저 nuScenes validation set에서 3D Object Detection 이전 SOTA 모델들과의 비교 실험 결과, Tab.1에서 볼 수 있듯이 새롭게 SOTA를 달성한 것을 확인할 수 있습니다. 멀티 모달리티 간의 정보를 융합하는 방식 (테이블에서 Modality 열의 LC를 의미)이 일반적으로 포인트 클라우드만을 사용하는 방식 (Modality 열의 L을 의미) 보다 더 나은 성능을 보이고 있습니다. 특히 포인트 기반의 융합 방식을 활용한 PointPainting은 앞서 intro에서 예시로 들었던 projection한 이미지의 semantic score의 일부로 포인트를 augment하는 방법론 입니다. ObjectFusion은 이러한 이전의 융합 방식들보다도 모달리티 간의 주요한 feature을 왜곡하지 않고 이미지의 풍부한 물체 레벨의 feature을 활용함으로써 이미지의 semantic한 정보 손실 없이 큰 폭을 가지고 성능 향상을 가지고 오면서 저자가 해결하고자 한 지금까지의 융합 방식의 한계점을 해결할 수 있었음을 입증하고 있습니다. 또한 BEV 기반의 융합 방식인 TrasnFusion과 BEVFusion과 비교해도 개선된 성능을 보이고 있네요.
특히 TransFusion은 BEV feature을 쿼리로, 전체 이미지 feature을 key, value로 할당해서 cross attention을 통해 융합을 수행하는데, 이런 다른 차원 간의 cross attention은 공간적인 alignment가 고려되지 않게 됩니다. 반면 ObjectFusion은 공간적으로 align된 멀티 모달리티의 feature을 물체 레벨에서 융합하기 때문에 성능 향상을 이룰 수 있었다고 저자는 분석하고 있습니다. 또한 BEVFusion은 이미지에서 BEV 공간으로의 변환에서 projection 왜곡이 발생할 수 있는 반면, ObjectFusion은 detection head에서 그러한 변환 없이 물체 중심의 융합을 진행하기 때문에 왜곡 없이 detection 성능을 향상시킬 수 있었습니다. intro에서 언급한 이전 방법론들의 문제점을 방법론들마다 언급하며 제안한 ObjectFusion이 어떻게 해결하여 성능 개선을 이루었는지 분석하고 있는 실험 결과가 인상 깊었습니다.
3.2. Detection Robustness Analysis
해당 파트는 ObjectFusion이 실제 환경에서 얼마나 강인하게 동작하는지에 보여주는 실험들의 결과 입니다. 자율주행 관점에서의 강인한 물체 검출이란 다양한 조도 변화 및 기후 환경 또는 검출하는 물체의 크기 등으로 측정할 수 있습니다.
Robustness to Lighting and Weather Conditions
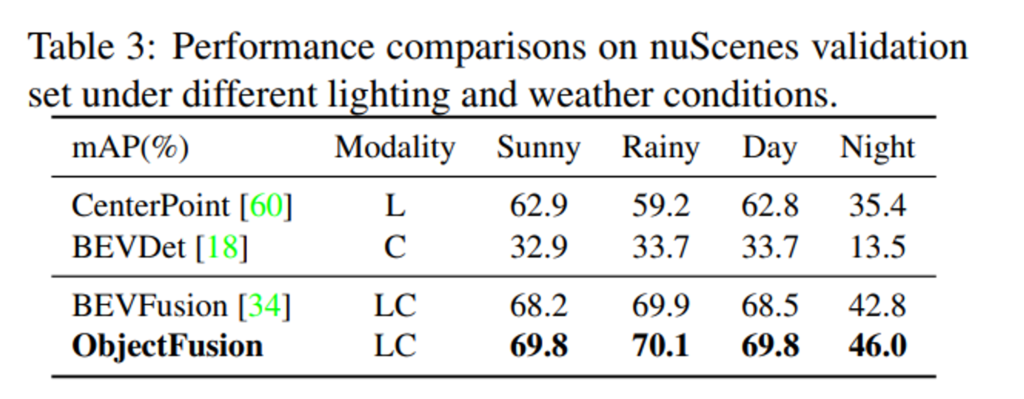
먼저 조도 및 날씨 변화에서의 detection 결과 입니다. 이러한 환경은 밤이나 안개가 끼게 되면 카메라로 물체를 찾아내기 어려워지는데, 이를 평가하기 위해 BEVFusion의 실험 세팅을 따랐다고 합니다. 먼저 nuScenes의 각 scene description에서 비와 밤 키워드를 찾아 validation set의 데이터를 맑음/비/낮/밤으로 나누었습니다. 이러한 세팅에서 평가했을 때 라이다 포인트만 사용하게 되면 CenterPoint는 맑은 날씨에 비해 비오는 날씨에서 성능이 하락하며 날씨 변화에 민감하게 반응하는 것을 볼 수 있습니다. 또한 카메라 이미지에 의존하는 BEVDet은 mAP가 13% 이상 낮아지면서 밤에서는 이미지만으로는 검출이 어렵다는 것을 알 수 있습니다. 이러한 이전 방법론들의 결과는 라이다나 카메라 이미지를 단독으로 사용하게 되면 여러 환경에서 모두 강인한 물체 검출은 어렵다는 것을 보여주는 반면, BEVFusion은 포인트와 이미지를 융합함으로써 단일 모달리티보다 모든 환경에서 성능이 크게 향상하고 있습니다. 여기서 공간이 정렬되도록 물체 레벨의 융합을 추가적으로 진행한 본 논문의 방법론이 BEVFusion보다도 나은 성능을 보이며 열악한 조도, 기후 환경에서도 깊이 추정 알고리즘에 의존도가 높은 BEVFusion보다 강인한 3차원 물체 검출이 가능하다고 증명하고 있습니다.
Robustness to Ego Distances and Object Sizes
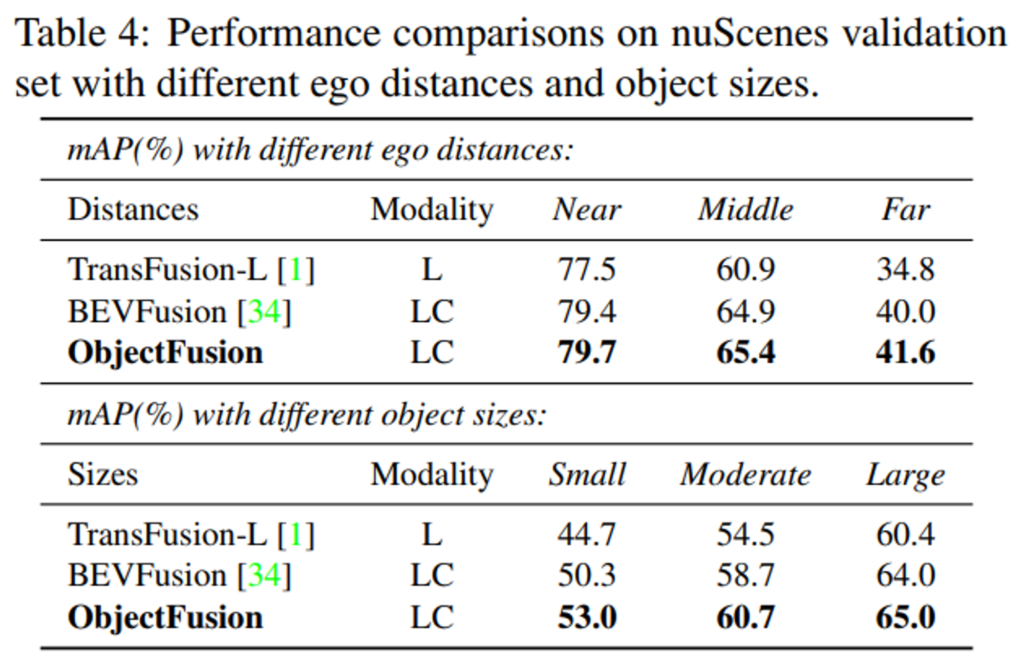
일반적으로 3차원 물체 검출은 ego 거리, 즉 센서와 차량까지의 거리 그리고 검출하는 물체 크기에 민감하게 반응하게 됩니다. 주로 사용하는 라이다 센서는 먼 거리에 있는 곳일수록 포인트가 급격하게 sparse해지며 작은 물체를 나타내기 어렵기 때문이죠. 본 논문에서는 어노테이션과 예측 ego 거리를 세 개로 분류해서 평가하고 있습니다.
- Near (0~20m), Middle (20~30m), Far (30m 이상)
또한 각 분류 카테고리에서 물체 크기의 분포를 찾아내어 3개의 물체 크기 레벨을 정의합니다.
- Small, Moderate, Large
이러한 평가 기준에서 실험한 결과, 라이다 단일 모달리티인 TransFusion-L은 거리와 물체 크기 변화에 따라 성능 변화가 크게 나타나는 것을 확인할 수 있습니다. BEVFusion은 이미지와 포인트를 융합하여 거리가 멀거나 작은 물체에서도 이미지 내에서 semantic한 정보를 찾아 어느 정도 향상된 결과를 보이고 있네요. BEVFusion과 비교해서 ObjectFusion은 성능은 향상시키면서도 또한 모든 카테고리에서 성능이 일관되게 나타나 안정적인 검출이 가능하게 됨으로써 물체 레벨의 융합이 ego 거리와 물체 크기 변화에도 강인하게 동작할 수 있다는 것을 알 수 있습니다.
3.3. Other Experimental Analysis
Ablation on Object-Centric Features in Different Spaces
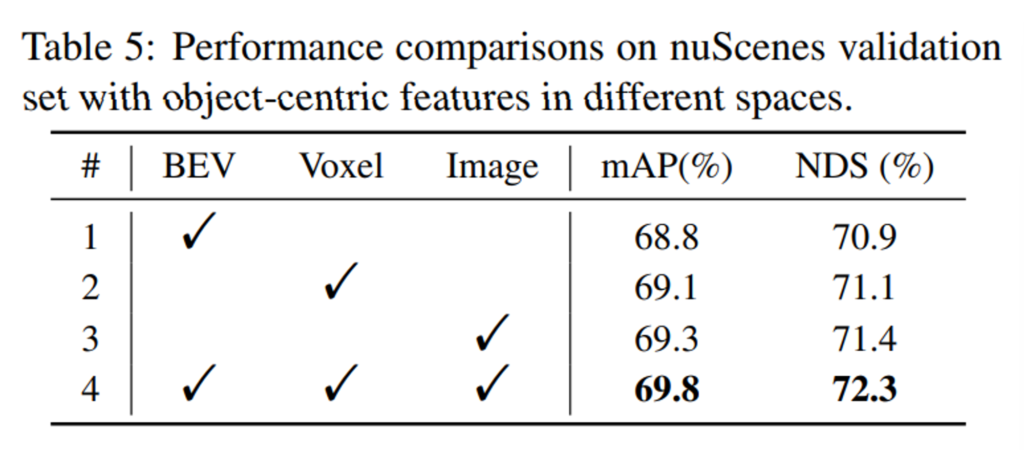
이제 ablation study로, 먼저 논문의 가장 큰 contribution인 모달리티 별 물체 레벨의 feature을 활용할 때의 효과에 대해 평가한 결과 입니다. 먼저 각각의 모달리티 공간에서 물체 레벨의 feature을 활용하면 모두 좋은 성능을 보일 수 있지만 그 중에서도 BEV feature는 더 디테일한 기하학적 정보를 제공하는 Voxel feature보다는 낮은 성능을 보이네요. 이미지 feature는 복셀보다 더 좋은 성능을 보이면서 이미지 feature에서 풍부한 텍스처, semantic 정보를 얻는 것의 중요성을 보여줍니다. 마지막으로 세 공간에서의 feature을 모두 합쳤을 때 가장 향상된 성능을 보이며 세 모달리티에서의 정보를 상호보완적으로 활용하는 것의 효과를 보여주고 있습니다.
Ablation on the Effect of Modality-Specific Context Encoder (MSCE)
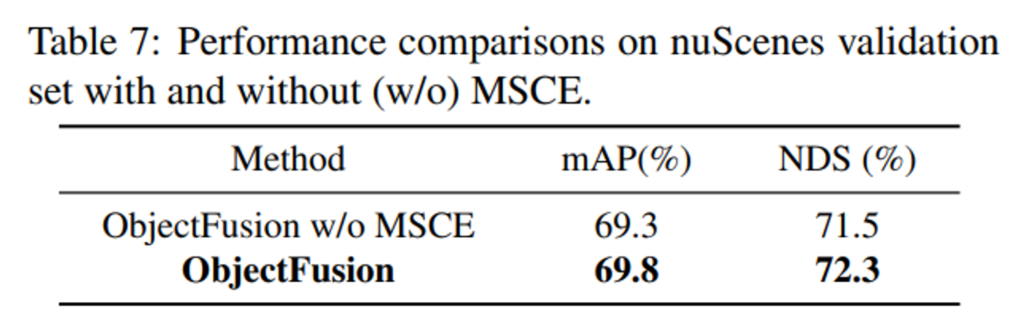
마지막은 제안한 MSCE의 효과를 보여주는 실험으로, MSCE는 cross attentio을 통해 공간의 물체 레벨 feature을 컨텍스트하게 인코딩할 수 있는 모듈이었습니다. Tab.7에서 볼 수 있듯이 MSCE는 ObjectFusion의 성능 향상에 긍정적인 영향을 주면서 물체 간의 관계를 파악하여 물체 레벨의 feature을 향상시키는 것이 중요함을 또 한번 강조하면서 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
몇가지 질문 드립니다.
BEV 공간이라는 표현이 생소한데, 이미지와 라이다 데이터의 공통 임베딩 공간을 의미하는 것일까요?? 또한 3D detection에서 많이 사용하는 개념인지도 궁금합니다.
또한 360도 촬영이 가능한 LiDAR에 대응되도록 multi-view 이미지를 활요하는 것으로 보이는데, multi-view 이미지는 파노라마로 만들어 사용하지는 않는 것인가요??
object feature는 class 개수가 아닌 상위 O개의 위치를 선택할 때 설정한 O개가 만큼으로 정의되는 것인가요??그렇다면 이 O라는 파라미터에 따른 실험 결과는 따로 없나요??