안녕하세요. 박성준 연구원입니다. 오늘 리뷰할 논문은 아직 아카이브에만 등재되어있긴하지만, Moment Retrieval task에 MLLM을 활용해 SOTA를 달성한 Mr.BLIP 모델입니다. 논문의 양식을 보아 ECCV에 제출할 것으로 예상되는 논문입니다.
Introduction
최근 많은 사전학습된 Large Language Models (LLMs)의 성공은 자연어 task뿐만 아니라 이미지, 비디오를 포함하는 많은 모달리티를 활용하는 Multimodal Large Language Models(MLLMs)의 연구로 이어졌습니다. 이러한 시각적 특징과 텍스트의 특징을 모두 활용할 수 있게 하는 MLLM의 발전은 Image Captioning, Visual Grounding과 같은 task들에 적용될 수 있습니다. 하지만, 높은 계산 및 주석 비용으로 인해 비디오 데이터에 대한 사전 학습으로 확장시키는 것에는 어려움이 있었습니다. 따라서, 비디오 task에서 활용하기 위한 연구로 CLIP과 같은 이미지-텍스트 사전학습 모델을 전이학습을 통해 비디오-텍스트로 fine-tuning하는 등의 방식으로 활용했습니다. 이러한 연구들은 Video Captioning, Video-Text Retrieval과 같은 task에서 좋은 성능을 보여줬지만, Moment Retrieval에서는 아직 많이 활용되지 않고 있습니다. Video moment retrieval에서는 untrimmed video(정제되지 않은 raw 비디오로 사람이 임의로 조작하지 않은 비디오를 의미함)에서 자연어 쿼리에 해당하는 정확한 구간을 반환하는 것을 목표로 합니다. 더 정확하게는 주어진 자연어 쿼리에 해당하는 여러 events의 정확한 시간적 위치에 대한 이해가 필요합니다.
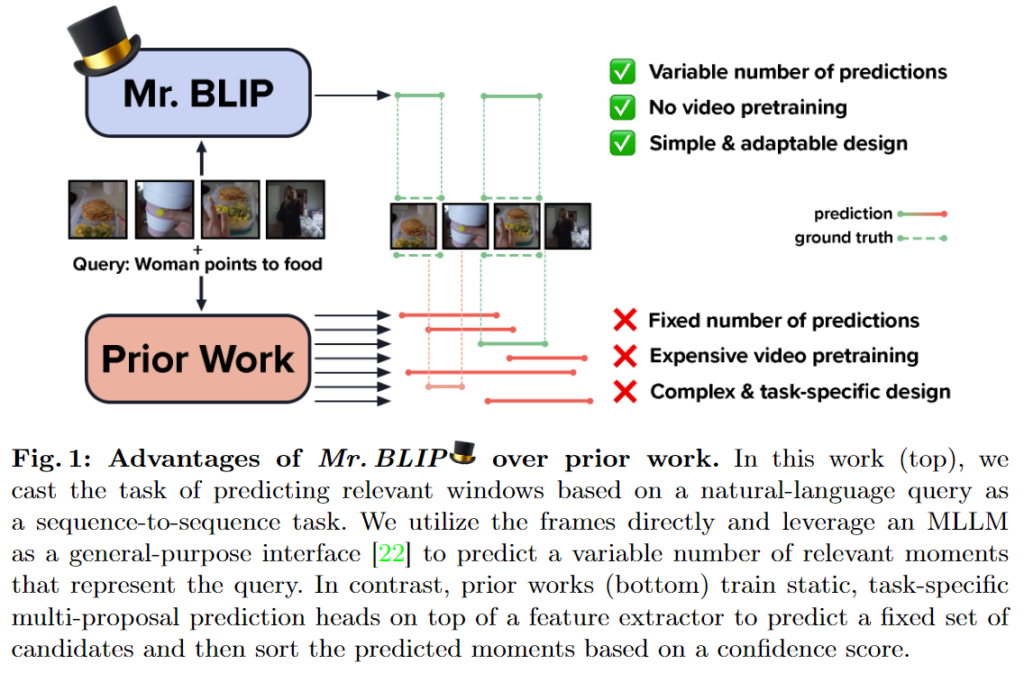
Figure 1. 에서 소개하는 Prior Work에서는 imgae-text align된 feature를 fusion하고 추가적인 task-specific prediction head를 학습해 고정적인 크기의 정답의 가능성이 있는 후보군을 생성합니다. 그런 후에 confidence 점수를 통해 top-k 개의 window를 선정하는 것으로 최종 세트를 선택합니다. 하지만 저자는 이러한 방식이 실제로 고정된 후보 셋이 주어졌을 때에 적절한 수의 relevant window를 선택하는 것을 만족스럽지 않다고 지적합니다. 아마 실용적인 관점에서 top-k 즉, k를 보통은 1 내지는 5로 설정하게 되는데 저자는 1, 5와 같이 직접 정해주는 방식이 비효율적이라고 생각하는 것 같습니다. 저자는 이러한 방식에서 벗어나 sequence-to-sequence 방법으로 cast한 첫 논문이라는 것을 강조하며 generative MLLM의 놀라운 능력(surprising effectiveness)을 입증합니다(여기서 논문 제목을 따왔네요). 이러한 방식은 고정된 moment proposals의 제약을 방지합니다(Figure 1. 의 하단 오른쪽에 서술되어 있습니다). 저자가 제안하는 모델은 다양한 간격 수를 예측할 수 있어 고정된 수의 후모가 주어졌을 때 하위 집합을 선택하는 모호성을 제거할 수 있다고 합니다. 또한 image-test 사전 훈련된 MLLM을 사용하는 것으로 사전학습이 필요하지 않다는 장점이 있습니다.
위의 내용을 바탕으로 하는 Mr.BLIP의 contribution은 다음과 같습니다.
- moment retrieval을 open-ended sequence-to-sequence 문제로 casting하여 사전학습된 image-text MLLM을 활용합니다.
- 입력 비디오의 이벤트에 대한 시각적 이해를 돕기 위해 novel multimodal input sequence를 제안합니다.
- 많은 Moment Retrieval 벤치마크에서 SOTA를 달성했습니다. (Temporal Action Localization task에서도 SOTA를 달성했다고 언급하지만 논문의 전반적인 내용이 Moment Retrieval에 집중하고 있어 TAL에 대한 내용은 흐름상 중요한 내용이 아닌 경우 넘어가겠습니다)
- 마지막으로 다양한 실험을 통해 Mr.BLIP모델의 성능 및 디자인을 제안합니다.
Mr.BLIP
Moment Retrieval은 untrimmed video에서 open-ended 자연어 쿼리에 해당하는 relevant moments를 localize하는 task입니다. 따라서 다양한 events의 상황적, 시간적 관계를 효과적으로 모델링해야합니다. 하지만, 저자는 비디오의 dense한 정보들로 인해 단일 pass-through 모델로는 비디오의 모든 프레임을 context로 활용하는 것은 계산상 불가능하다고 말합니다. 따라서 저자는 이러한 문제를 해결하기 위해서 moment retrieval을 언어 모델링 작업으로 casting하고 MLLM의 상황별 이해 능력을 활용하여 비디오를 나타내는 프레임의 의미론적, 시간적 특징을 이해합니다.
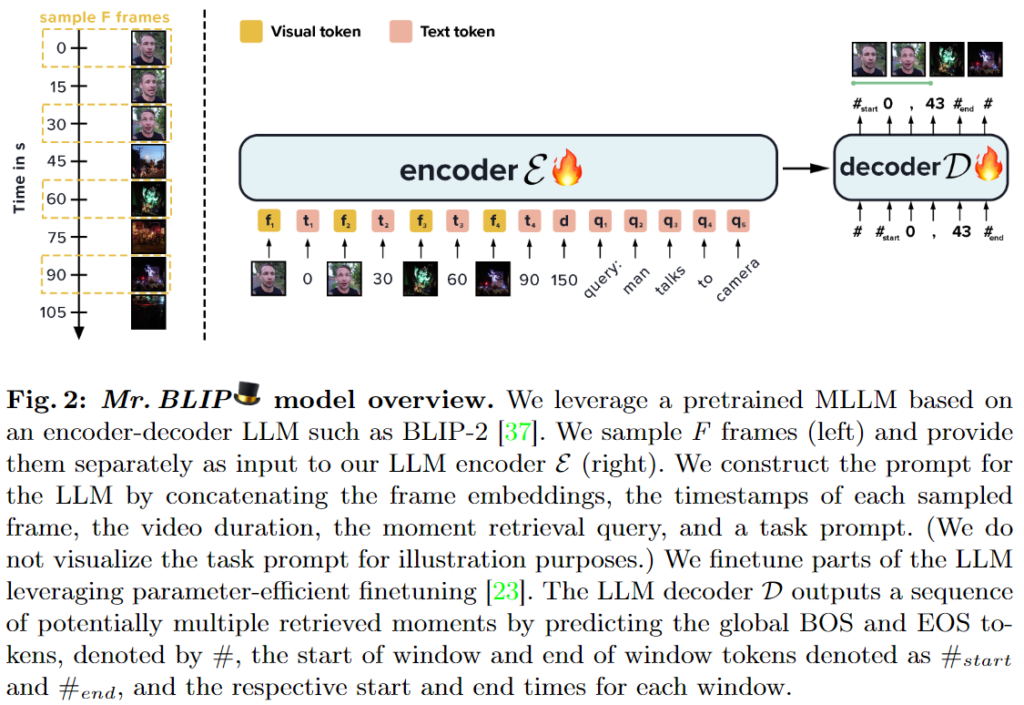
Fig.2는 Mr.BLIP 모델의 전반적인 구조를 보여줍니다. Mr.BLIP은 LLM(BLIP)의 인코더, 디코더로 구성되어있습니다. 모델이 굉장히 간단한데 먼저 비디오를 F프레임으로 샘플링하고 LLM의 입력으로 사용합니다. 위의 그림에서 확인할 수 있듯이 인코더의 입력은 각각의 프레임들과 시간을 알려주는 timestamp 그리고 자연어 쿼리입니다. LLM을 fine-tuning하는 것으로 학습했고 디코더를 통해 나오는 출력은 start token, 시작 timestamp, 끝 timestamp, end token입니다.
저자는 Video Moment Retrieval을 위해 주어진 자연어 쿼리에 해당하는 시각적 정보를 해석할 수 있는 MLLM의 활용가능성을 탐구합니다. untrimmed video와 쿼리 사이의 상황적, 시간적 관계를 포착할 수 있는 모델을 설계합니다. 이를 위해 저자는 기존의 방식에서 벗어난 novel multimodal input sequence를 제안해 비디오의 샘플링된 프레임이 주는 의미론적 context, 시간적 context 그리고 자연어 쿼리를 활용합니다. 저자는 입력과 출력 모두 시간적 context를 모델링하는 여러 방법이 존재하며 각 방법마다 성능에 많은 영향을 미친다고 말합니다. 저자가 실험을 통해 알아낸 바에 의하면 시간은 절대 초로 모델링하고 프레임들과 끼워넣는 방식이 가장 좋았다고 말합니다.
저자는 시각적 정보와 언어 정보를 모두 최대한 활용하기 위한 backbone으로 BLIP2를 사용했습니다. BLIP2는 현재 image-text corpus로 학습된 현재 SOTA MLLM이라고합니다. 저자는 학습을 위해 frozen LLM과 BLIP2의 frozen 이미지 인코더와 이미지 인코더와 마지막 구성요소 사이에서 훈련가능한 translation unit인 Q-Former를 사용했다고합니다.
수식적으로 표현하면, Mr.BLIP의 입력은 프레임 f_n, timestamp t_n (n =1,\dots, F), 비디오 시간 d, 자연어 쿼리 q그리고 task prompt p입니다. 저자가 사용한 task promt는 ‘Given the video and the query, find the relevant windows. Relevant windows:’입니다. 출력은 여러개의 relevant windows m이고 각 relevant window y=[[t^1_{start}, t^1_{end}], [t^2_{start}, t^2_{end}], \dots]의 형태로 각 relevant window의 시작점, 끝점 정보를 담고 있습니다. 저자는 relevant window를 표현하는 방식으로 시작점과 끝점, 중간 지점과 window의 크기 와 같은 여러가지 방식이 있지만, 시작점과 끝점을 사용하는 것이 결과적으로 가장 좋았다고 말합니다. 또한 모든 timestamp정보는 소수점 첫자리에서 반올림해 정수로 사용했다고 합니다. 추가적으로 저자가 사용한 LLM은 Flan-T5로 BLIP2와 같은 공간에 임베딩되는 LLM이라고합니다.
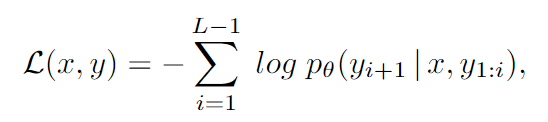
학습할때 손실함수는 task input x와 decoder target text y에 대하여 위의 standard maximum likelihood 목표에 맞게 최적화합니다. L은 decoder sequence길이이고, p_{\theta}는 출력 text의 확률 분포입니다. 또한 parameter-efficient finetuning 기술LoRA를 사용했습니다.
Experiments
Charades-STA, QVHighlights, ActivityNet Captions 총 3개의 데이터셋에서 실험했으며 3 데이터셋 모두 untrimmmed video와 자연어 쿼리로 구성된 Moment Retrieval에 적합한 데이터셋입니다. 사용한 평가지표는 Recall@K입니다. Recall@K는 GT와의 IoU가 임계값을 넘어가는 top-K개의 확률입니다.
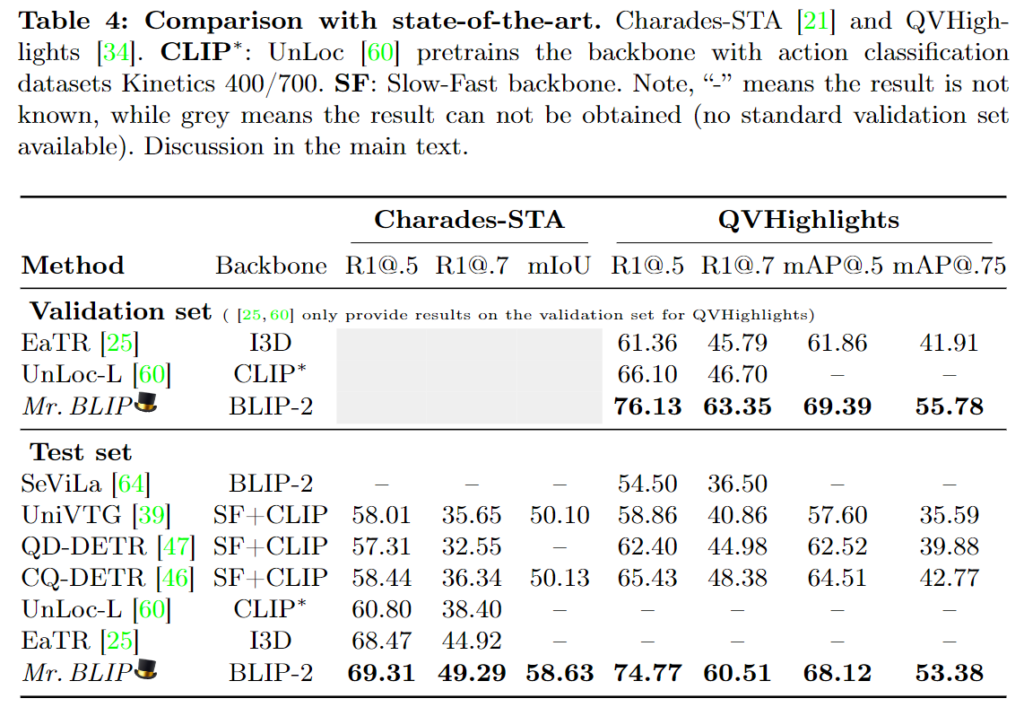
저자는 Mr.BLIP이 Charades-STA 데이터와 QVHighlights 데이터셋 모두에서 SOTA를 달성했음을 강조하고 있습니다. 주목할만한 점은 QVHighlights 데이터셋에서의 성능이 기존 SOTA 모델인 CG-DETR에 비해서도 전체적으로 약 10퍼센트 정도의 성능 향상을 이뤄내는 모습을 보여줬습니다. QVhighlights에서의 성능 상능폭에 비하면 Charades-STA 데이터셋에서는 SOTA를 달성하기는 했지만 소폭 상승하는 모습을 보여줬습니다. 저자는 위에서의 open-ended multimodal sequence-to-sequence 입력을 적용한 첫 모델임을 강조하며 저자가 제안하는 방식의 강력함을 강조하고 있습니다. 하지만 다른 모델들이 backbone 모델이 BLIP2 현 SOTA image-text 모델을 사용하지 않았으므로 fair comparison이라고 보기는 어려울 것 같습니다. 쨋든 높은 성능 향상폭이 인상적이긴합니다.
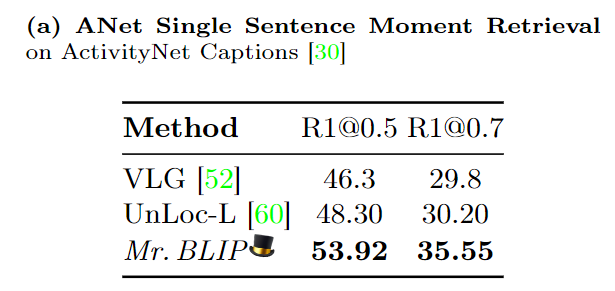
ActivityNet Captions에서도 좋은 성능을 달성하며 저자가 제안하는 방법의 강력함을 다시한번 강조합니다.
Ablation Study
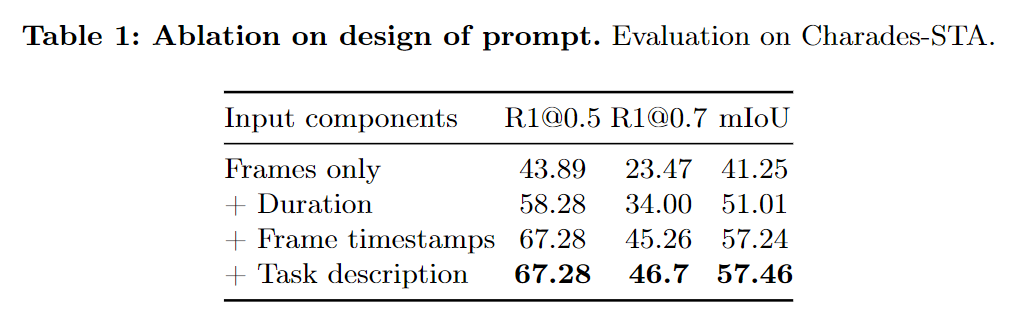
먼저 입력 sequence의 디자인에 따른 ablation study입니다. 저자가 제안하는 입력 방식에서 각각의 prompt를 추가할 때마다 성능이 오르는 모습을 보여줍니다. 좀 아쉬운 부분은 사실 저자가 제안하는 방법론들은 적용했을때 성능도 물론 중요하지만, 다른 방법 예를 들면 task description prompt를 다르게 했을 때와의 성능 비교 혹은 기존 방법과의 ablation이라던지 저자가 왜 이러한 입력 sequence를 선택해서 적용했는 지에 대한 설득이 부족한 것 같아 살짝 아쉽습니다.
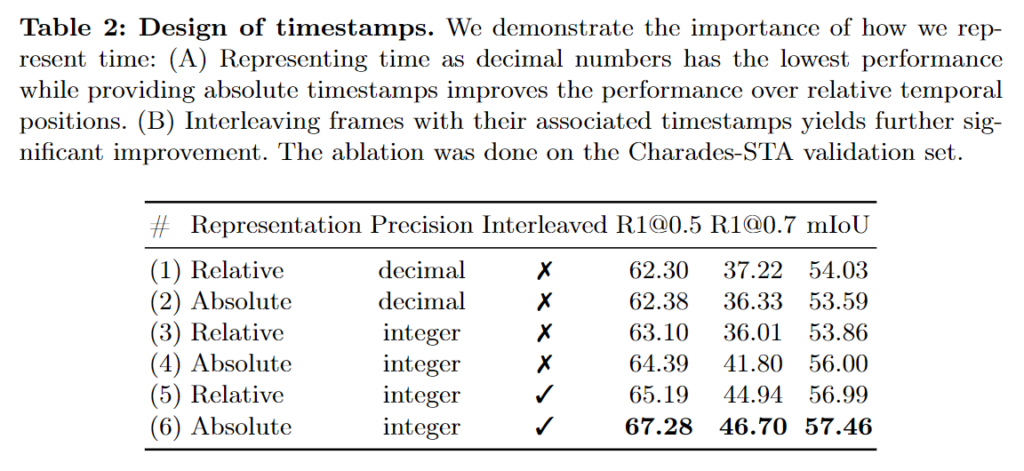
두번째 표는 시간을 표현하는 방식에 대한 ablation입니다. interleaved는 프레임들 사이사이에 시간 정보를 넣을 때와 사이사이가 아닌 프레임들 정보를 전부 입력하고 그 뒤에 시간 정보를 넣었을대의 성능입니다. precision은 시간 정보를 소수점(decimal) 혹은 점수(integer)로 입력했을 때의 성능입니다. 절대 초의 정보로 프레임들 사이사이에 정수의 형태로 입력했을 때의 성능이 제일 좋은 것을 확인할 수 있습니다. 저자가 왜 입력에서 절대초로 프레임 사이사이에 활용했는지는 알 수 있었지만, 실험적으로 증명하고 저자가 성능이 이렇게 나온 것에 대한 고찰에 대한 언급이 없어 살짝 아쉬웠습니다.
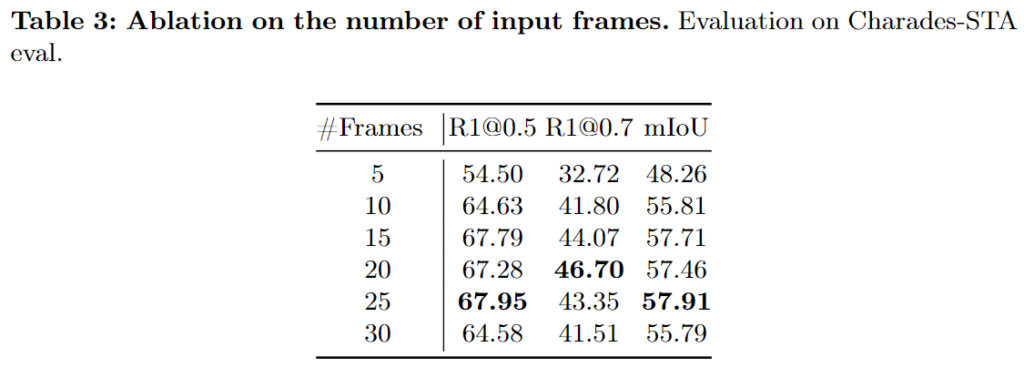
마지막으로 프레임의 수에 대한 ablation입니다. Charades-STA 데이터셋에서의 실험 표이고 25프레임을 사용했을때에 성능이 제일 좋은 것을 확인할 수 있습니다. 표에는 없지만 QVHighlights 데이터셋에서는 60프레임을 사용하는 것이 제일 좋은 성능을 보여준다는 언급이 있습니다. QVHighlights의 데이터셋은 초당 30프레임으로 150초의 분량의 영상으로 데이터셋이 구성되어 있습니다. Mr.BLIP 이전 Moment Retrieval에서의 SOTA 모델인 CG-DETR을 포함한 M-DETR 기반의 방법론들은 모두 2초 길이의 moment query를 생성하여 사용했는데 Mr.BLIP에서도 60프레임 즉, 2초 길이의 프레임의 성능이 제일 좋은 것으로 보아 QVHighlights 데이터셋에서는 2초 분량으로 나눠 입력으로 사용하는 것이 제일 좋은 성능을 보이는 것을 확인할 수 있습니다. QVHighlights 데이터셋을 분석해봐야겠지만, 정확히 2초 분량으로 나누는 것이 왜 성능이 제일 좋은지에 대한 분석이 필요할 것 같습니다. (데이터셋을 분석하고 코드를 분석할 때 유심히 봐야할 것 같습니다) 쨋든 비디오 프레임의 개수에 대한 ablation을 마지막으로 Mr.BLIP의 실험적 분석은 마무리됩니다. 모든 ablation study가 Charades-STA 데이터셋에서 실험한 결과인 것이 인상적이네요. QVHighlights 데이터셋이 가장 최근에 공개된 데이터셋으로 기존 연구들은 ablation study를 QVHighlights 데이터셋에서의 실험 결과를 가져올 때가 많았는데 개인적인 생각으로는 성능의 상승폭을 고려했을 때에 QVHighlights 데이터셋에서는 이미 SOTA를 달성했고 Charades-STA 데이터셋에서의 성능이 기존 SOTA 모델인 EaTR의 성능을 이기지 못해 여러가지 방법들을 고려했기에 Charades-STA 데이터셋에서의 ablation을 위주로 작성된 것이 아닐까싶습니다.

마지막으로 정성적 결과입니다. 쿼리와 영상에 따라 모델이 예측 구간을 반환합니다. 예측을 잘 한 경우만 보여주는 것이 아니라 예측이 올바르지 못한 경우도 정성적 결과에서 보여주는데 5.의 예측 실패의 이유로 모델은 여자가 상점 안에 확실하게(clearly) 있는 구간을 반환했는데 실제 GT구간에서 여자는 멀리 있어 시각적으로 명확하지(clearly) 않기에 모델이 예측을 실패했다고 저자는 말하고 있습니다. 실제 영상의 모델의 예측 구간에서 여자는 모자를 이미 쓰고 있기에 모델이 헷갈렸다고 볼 수 있을 것 같습니다.
Conclusion
저자는 사전학습된 MLLM BLIP2를 사용함으로 Moment Retrieval task에서 MLLM을 잘 활용하는 것은 앞으로의 Moment Retrieval 연구에서 중요한 과제 중에 하나가 될 것이라 언급하며 자신의 연구가 앞으로의 연구에 영감이 되길 바란다고 언급하고 있습니다. 한계점으로는 사전학습된 MLLM을 사용하기에 BLIP2가 갖고있는 어떠한 bias나 고정관념(stereotype)의 존재를 배재할 수 없다는 것을 언급하며 사용할 MLLM의 선정에 유의해야한다고 언급하며 논문을 마칩니다.
사실 자극적인 논문 제목과 높은 성능 상승폭에 홀려 논문을 읽었고 제안하는 입력 방식이 최초로 시도했고 실제로 성능을 많이 개선했다는 점에서 의미있었지만 기존 모델과 다른 backbone 모델을 사용했고 구조자체가 굉장히 심플하기에 실제로 제안하는 입력 방식이 효과가 좋은 건지 단순히 backbone 모델의 성능이 좋아 성능이 높은 것인지 분간하기가 힘드네요. 개인적으로 BLIP이 아닌 다른 MLLM으로도 실험한 내용이 있었으면 좋았을 것 같습니다(그렇다면 방법론의 이름이 Mr.BLIP이 아니었겠지만 ㅎㅎ) 쨋든 흥미로운 논문이었고 GPU를 A100 8개를 사용해서 170시간이나 걸려서 학습을 하는 모델이라 원복은 힘들 것 같고 이런 방법도 있구나(?) 하고 앞으로의 moment retrieval 연구에서 참고할 수 있을 것 같습니다.
감사합니다.
안녕하세요.
BLIP-2는 이미지 인코더 -> Q-Former -> LLM 형태의 구성으로 알고있습니다. 진짜 encoder-decoder 구조를 갖는 MLLM인 T5와 같은 모델과는 애초에 decoder만 사용하는, 즉 구조가 다른 모델로 알고있는데, 본문에서 학습시키는 encoder, decoder는 각각 무엇인지 궁금합니다.
그리고 요즘 LLM fine-tuning을 위해 LoRA 방법론을 많이 사용하는데, 리뷰에서 단순히 LoRA를 사용했다고 언급하고 넘어가기엔 거대 모델의 학습을 그나마 가능케하는 중요한 방법론이라 어떻게 동작하는 것인지 간단하게라도 적어주시면 좋을 듯 합니다.
감사합니다.
안녕하세요 현우님 좋은 댓글 감사합니다.
BLIP2는 이미지 인코더 -> Q-Former -> LLM의 형태로 구성되어있어 LLM이 encoder-based 구조인지, encoder-decoder 구조인지에 따라 LLM의 입력 형태가 달라지게 됩니다(encoder-based의 경우에는 Q-Former의 출력을 projection시킨 벡터, encoder-decoder 구조는 Q-Former의 출력을 projection시킨 벡터 + prefix text). Mr.BLIP의 경우에는 encoder-decoder 구조의 LLM인 T5을 사용하여 이미지 인코더와 Q-Former를 거친 비디오의 특징과 prefix text 대신에 timestamp, duration, prompt 를 추가한 입력 시퀀스를 입력하게됩니다. 저자가 학습하는 encoder과 decoder는 위 과정에서 LoRA를 사용하여 LLM을 fine-tuning하는 것으로 LLM의 출력을 모델의 예측으로 학습이 진행됩니다.
LoRA방식은 LLM의 attention 연산의 파라미터가 많은 것을 행렬곱연산의 가중치를 freeze한 후에 낮은 차원의 추가 레이어를 더해 전체적인 연산량을 줄이는 방법입니다. 일반 적인 fine-tuning이 아니라 추가적인 레이어만을 학습하는 것으로 연산량을 줄이지만 성능의 하락폭도 적어 많은 파라미터가 존재하는 LLM을 학습할 때 자주 사용되는 방법입니다.
감사합니다.