CVPR 세미나에서 발표했던 것처럼, 이번주부터는 Multi-modal(Text, Image) model에 대해 리뷰해보려고 합니다. 가장 첫번째로 Meta의 LLM 모델인 LLaMA를 사용한 Vision-Language 모델인 LLaVA에 대해 다뤄보겠습니다.

- Conference: NeurIPS 2023 (Oral)
- Title: Visual Instruction Tuning [Paper]
- Authors: Haotian Liu, Chunyuan Li, Qingyang Wu, Yong Jae Lee
- Affiliation: University of Wisconsin–Madison, Microsoft Research, Columbia University
- Project Page: Github
- Code: Github
Background
Instruction Tuning
본 논문을 이해하기 위해, 제목 속에 있는 “Instruction Tuning” 에 대해 알아보겠습니다.
결론부터 말하자면, Instruction Tuning은 대형 언어 모델(LLM, Large-Language Model)을 Fine-tuning 하는 방법으로, 데이터에 특정 Instruction을 추가하여 모델의 성능을 향상시키는 기술입니다. 이를 통해, 모델은 인간의 지시(Instruction)를 이해하고, 이를 기반으로 적절한 응답이나 행동을 생성하도록 학습됩니다.
Traditional Language data
NLP에서는 seq2seq 표현 방식이 전통적으로 사용되었는데, 해당 모델의 입/출력은 시퀀스로 구성되었습니다. 보통 번역과 요약 태스크에 주로 사용되었고, 태스크에 대한 Instruction이 따로 명시되지 않았습니다.

상단의 그림 (a)가 바로 대표적인 예시죠. 특정한 명령어(Instruction) 없이도, 모델은 input 데이터가 들어오면, 알아서 output을 만들어냈습니다. 즉, 모델은 어떤 태스크를 수행해야할 지 미리 알고 있었죠.
그러나 이런 방식에서는 개별 모델이 특정 데이터 도메인에 맞춰 학습되거나, 여러 도메인에서 multi-task를 목표로 학습되더라도 다른 태스크로로 수행하라는 지시(Instruction)를 이해하지 못하기 때문에, 새로운 태스크로 일반화하기 어렵다는 한계가 있습니다.
Instructional Language Data
GPT-3는 프롬프트 튜닝(Prompt Tuning)을 통해 Few-shot, Zero-shot 등 다양한 일반화된 태스크를 수행할 수 있다는 점에서 큰 주목을 받았습니다. 여기서 프롬프트 튜닝은 모델에 특정 지시를 주어 작업을 수행하도록 하는 방법입니다. 예를 들어, “이 영화 리뷰의 감정이 긍정적인가요, 부정적인가요?”와 같은 Instruction을 모델에 주어 감정인식이라는 Task를 수행하게 되죠. 이 이후, 프롬프트 튜닝 말고도 더 좋은 성능을 내도록 수행하는 방식은 없을까 에 대한 고민이 시작되게 됩니다.
Google의 FLAN(Finetuned Language Models are Zero-Shot Learners) 논문에서 바로 Instruction Tuning이라는 방식을 제안하였는데요, 모델 학습 시 명시적으로 task instructions를 추가하기 시작했습니다. 바로 아래 그림을 통해 (a)와 다르게, Instruction이 추가되었음을 확인할 수 있습니다.

이는 새로운 데이터 형식인 지시-입력-출력 Triplets(instruction-input-output triplets)을 만들었고, 하나의 모델이 여러 작업을 특정 지시와 함께 수행하도록 학습할 수 있게 되었죠. 이러한 방식으로 학습된 모델은 평가 단계에서 새로운 작업을 보다 쉽게 일반화할 수 있습니다.

예를 들어, 요약과 번역을 모두 요구하는 새로운 작업을 모델이 학습 중에 본 적이 없더라도, 각각의 Instruction을 통해 새로운 작업을 수행할 수 있습니다. 이는 모델이 훈련 없이도 수천 개의 새로운 작업을 해결할 수 있게 하여, ChatGPT가 빠르게 인기를 얻는 이유 중 하나라고 할 수 있죠.
우리가 아는 Fine-tuning과의 차이점을 통해 Instruction Tuning 에 대해 정리하면 아래와 같습니다.
- Fine-tuning: 사전 학습된 언어 모델을 특정 Task에 맞게 조정하는 과정입니다. 예를 들어, 감정 인식, 번역 등의 특정 작업에 대해 모델을 작은 데이터셋으로 학습하여 성능을 높이는 것이죠.
- Instruction Tuning: 입력-출력 데이터셋에 지시(instruction)를 추가하여 모델을 학습시키는 방법입니다. 예를 들어, 번역 작업에 대해서는 “이 문장을 스페인어로 번역하세요”와 같은 명령이 추가되는 것이죠.
Instruction Tuning의 한계
간단한 방법으로 높은 성능을 가져온 Instruction Tuning일지라도, 몇 가지 한계점이 존재합니다.
- 데이터셋 구축의 어려움: Instruction Tuning을 위해서는 다양한 작업과 관련된 고품질의 지시 데이터셋이 필요합니다. 이러한 데이터셋을 구축하는 것은 시간과 비용이 많이 들며, 특히 많은 양의 레이블이 지정되지 않은 데이터를 수집하고 정제하는 과정이 복잡합니다.
- 지시 이해의 한계: 모델이 다양한 지시를 잘 이해하고 수행하기 위해서는 훈련 중에 충분히 다양한 예제를 경험해야 합니다. 그러나 현실적으로 모든 가능한 지시를 모델에 제공하는 것은 불가능하며, 특정 지시에 대한 이해 부족으로 인해 새로운 작업에서 성능이 저하될 수도 있습니다.
- 모델의 복잡성 증가: Instruction Tuning은 모델의 복잡성을 증가시키기도 합니다. 다양한 작업을 처리하기 위해 모델의 구조가 복잡해지고, 이는 학습 및 추론 단계에서 더 많은 계산 자원이 필요합니다.
지금까지 설명드린 부분은 모두 Text만을 입출력으로 가진 Instruction Tuning에 대한 내용이었습니다. 제가 지금 리뷰하려는 LLaVA는 Image-Text를 동시에 학습할 때, 이런 Instruction도 사용하고자 하는 논문인데요. 이미지가 더 있다는 측면에서 기존 한계를 더욱 어렵게 만들 것 같습니다. LLaVA는 이를 어떻게 개선했고, 모델 학습은 어떻게 진행되었는지 알아보겠습니다.
Introduction
인간은 세상과 상호작용할 때 여러 감각을 사용합니다. 예를 들어, 우리는 눈으로 보고 귀로 듣죠. 이와 비슷하게, 인공지능 연구자들은 시각과 언어 모델을 결합하여, 두 가지 기능을 동시에 수행할 수 있는 범용 AI 어시스턴트를 개발하고자 노력하고 있습니다. 이러한 모델은 이미지의 내용을 설명하거나, 이미지 속 객체를 인식하고 그에 맞는 답변을 제공하는 등의 작업을 수행할 수 있습니다.
그러나 이런 모델을 구축하는 데에 가장 큰 문제는 데이터셋에 있습니다. 기존 멀티모달 데이터셋은 단순히 “이미지-텍스트” 쌍으로 구성된 경우가 많죠. 앞서 Background에서 설명한 것처럼 Instruction을 통해 모델이 학습해야, 범용적인 Vision에 대한 질의응답이 가능한 어시스턴스를 만들 수 있습니다.
하여 본 논문에서는 Visual Instruction Tuning 기술을 통해, 이미지와 텍스트를 결합하여 Instruction을 따를 수 있는 모델인 LLaVA(Large Language and Vision Assistan)를 제안하였습니다. LLaVA는 시각 인코더와 대규모 언어 모델을 연결하여, 시각적 정보와 언어 정보를 동시에 처리할 수 있는 대형 멀티모달 모델입니다. 이는 ChatGPT와 GPT-4(only text)와 같은 언어 모델을 사용하여 다양한 시각적-언어적 데이터를 생성하고, 이를 기반으로 학습됩니다.
LLaVA Architecture
LLaVA의 모델 구조는 아주 심플합니다. LLaVa는 세 가지의 요소로 구성됩니다: 1) Language Model 2) Projection 3) Vision Encoder. 이 때, LLaVA의 목표는 사전 학습된 언어 모델(LLM)과 시각 모델의 기능을 효과적으로 활용하는 것입니다. 즉, 사전 학습된 비전과 랭귀지 모델이 이미 준비되어 있어야 합니다. 그리고 그 비전과 랭귀지 인코더를 서로 이어주는 것이 Projection 의 역할이죠
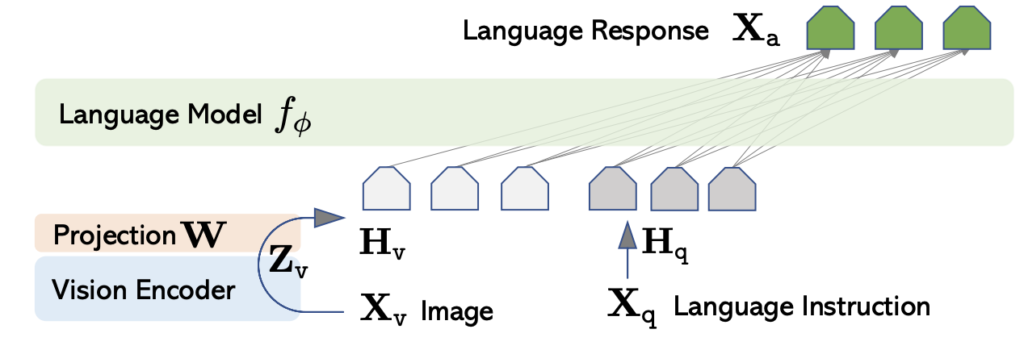
언어 모델 (Language Model)
- Vicuna: LLM으로 LLaMa 기반의 모델인 Vicuna를 사용합니다. Vicuna는 공개된 체크포인트 중에서 언어 작업에서 최고의 지시 수행 능력을 보유한다고 합니다.
비전 인코더 (Vision Encoder)
- CLIP ViT-L/14: 입력 이미지에 대해 사전 학습된 CLIP 비전 인코더 ViT-L/14를 사용합니다. visual feature를 추출하는 데에 활용합니다.
- 프로젝션 매트릭스 (Projection Matrix): Visual feature를 언어 임베딩 공간으로 변환하기 위해, 학습 가능한 프로젝션 매트릭스 W를 사용합니다. 이는 visual feature Z_v를 언어 임베딩 토큰 H_v으로 변환합니다. 아주 간단한 선형 연산으로 구성됩니다.
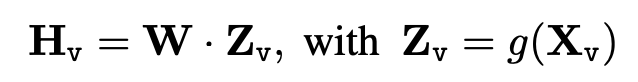
Vision 입력은 W를 통해 Text embedding space로 변환한 뒤, Text 입력과 함께 언어 모델의 입력으로 들어가게 됩니다. (즉, Visual, text 모두 llm 모델의 입력이고, 두 개의 입력을 결합한 output을 사용하는 것.) 이를 통해, 결국 해당 모델은 language model에 성능이 의존할 것 같다는 생각이 들긴 했습니다.
GPT-assisted Visual Instruction Data Generation
앞서 멀티모달에 최적화된 데이터셋이 부족함을 계속 강조드렸습니다. 특히, 멀티모달 Instruction-Following(Answer) 데이터는 생성 과정이 시간이 많이 걸리고 명확하게 정의되지 않아 한정된 양만 존재하죠.
따라서 저자는 이 문제를 GPT를 사용하여 해결하고자 하였습니다. 특히 GPT 시리즈가 텍스트 생성 작업의 성공을 거둔 것을 바탕으로, ChatGPT/GPT-4를 활용하여 다중모달 지시-따르기 데이터를 수집하는 방법을 제안합니다.
Simple way to expand an image-text pair
가장 간단하게 Instruction-Following 생성하는 방식은 다음과 같습니다: 이미지 X_v와 해당 캡션 X_c를 기반으로, 이미지 내용을 설명하도록 어시스턴트에게 지시하는 질문 X_q를 만들도록 요청하는 것이죠. “캡션 X_c처럼 설명하는 질문 X_q를 만들어봐” 그렇게 생성된 데이터 X_q는 instruction이 되고, 아래와 같이 Instruction-Following으로 모델을 학습할 수 있습니다.
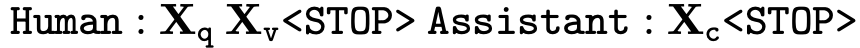
그러나 이 방식은 X_q, X_c가 서로 비슷한 경향을 가진다는 한계가 있습니다. 즉, 캡션에 있는 내용을 거의 그대로 가져다 쓰는 수준으로 생성해내기 때문에, 다양성이 떨어지고, 깊이 있는 리즈닝이 어렵습니다.

따라서 저자는 앞선 한계를 개선하고자, 새로운 Instruction pair를 생성하는 파이프라인을 제안하였습니다. 우선 X_c, X_v, X_b가 존재해야합니다. X_b는 Bounding box 좌표입니다. Bounding box는 상단 이미지와 같이 텍스트로 나타낸다고 합니다. (데이터셋은 COCO에서 가져왔다고 합니다)
새로운 Insturction pair를 생성하기 위해서는 사람이 직접 Instruction-Following 샘플인 (X_{q_1}, X_{a_1}) 한 개를 생성해야 합니다. 사람이 만들었다보니, diverse 하면서도 in-depth reasoning 까지 고려한 데이터 쌍이겠죠.
그 다음, 앞서 생성한X_{q_1}, X_{a_1}과 X_c, X_b를 함께 GPT의 입력으로 넣어서 새로운 X_{q_2}, X_{a_2}를 만들어내는 것이죠. 예를 들면 다음과 같이 입력을 넣을 수 있겠죠 "caption X_c, bounding box X_b, 그리고 instruction pair (X_{q_1}, X_{a_1})를 참고해서, (A, B, C) 스타일의 question, answer(X_{q_2}, X_{a_2})를 생성해". (이 때, BBox를 함께 제공하는 이유는 meta data 차원이라고 보면 될 것 같습니다)
여기서 높은 수준의 추론이 가능한 질문이 가능하도록, 3가지 스타일로 question answer 를 생성하도록 유도하였습니다. 위의 예시에서 (A, B, C)가 여기에 해당합니다.

첫 번째 스타일은 대화(conversation) 형식의 데이터 생성입니다. 주어진 이미지에 대해 어시스턴트와 인간이 대화하는 형태로, 이미지만 보고 직관적으로 이해할 수 있는 내용을 바탕으로 질문과 답변 쌍이 해당합니다. 예를 들어, 이미지 내 시각적 요소에 대한 질문을 포함하여 객체의 종류, 개수, 동작, 위치, 객체 간의 상대적 위치 등을 묻는 다양한 질문을 생성할 수 있습니다.
두 번째 스타일은 이미지에 대한 상세한 설명(Detailed Description)을 생성하는 것입니다. 이 과정에서는 이미지의 캡션과 객체 박스를 GPT-4에 입력하고, 주어진 이미지에 대한 상세한 설명을 생성하도록 합니다. 이를 통해 한 이미지에 대해 매우 자세하고 종합적인 설명을 얻을 수 있습니다.
세 번째 스타일은 심층적인 논리를 포함한 질문 및 답변(Complex reasoning)을 생성하는 것입니다. 이 방법에서는 단계별로 엄격한 논리가 포함된 이유를 요구하는 질문과 답변을 GPT-4를 통해 생성합니다. 동일하게 이미지 캡션과 객체 박스를 입력하고, 긴 프롬프트를 사용하여 깊이 있는 추론이 필요한 질문과 답변을 생성합니다.
아래 이미지가 바로 지금까지 설명한 Visual instruction 을 위한 데이터 생성에 사용한 prompt라고 합니다.


위의 세 가지 방법을 통해 총 158,000개의 고유한 Visual-Language Insturction-Following 샘플을 생성할 수 있었다고 합니다
- 58,000개의 conversation 데이터
- 23,000개의 Detailed Description 데이터
- 77,000개의 Complex reasoning 데이터
LLaVA Training
Instruction Tuning
각 이미지 X_v에 대해, 총 T번의 대화 턴이 포함된 멀티턴 대화 데이터를 생성합니다. 이 대화 데이터는 모두 어시스턴트의 응답으로 취급되며, 통합된 멀티모달 Insturction-following 시퀀스로 구성된다고 합니다. 이 과정은 아래 그림을 통해 확인할 수 있습니다.

LLM의 예측 토큰에 대한 Instruction Tuning은 원래의 Autoregressive Training Objective 를 사용합니다. 이 때 loss 계산 시에는 상단 그림 중 녹색 부분만 반영한다고 합니다.
앞서 T번의 대화 턴을 데이터 입력으로 제공한다고 하였는데, 첫번째 X^t_{instruct}만 X_v인 이미지를 제공하였습니다. 이를 수식으로 나타낸 것이 아래 그림과 같습니다.
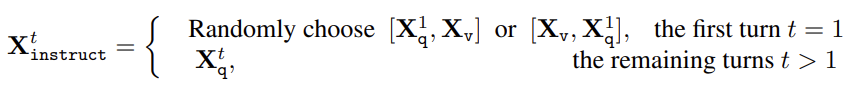
Pre-training dataset for project W
Image Feature를 Text embedding space와 맞춰주는 Projection W에 대해서도 학습이 필요합니다. 이 때, Align을 맞춰주는 것은 아주 중요한 문제이기 때문에, 총 두번 학습이 진행됩니다. 즉 사전학습된 Image-Text Encoder를 Freeze 한 채 W를 사전학습하기 위한 Pretrain-data를 준비한 다음 W를 학습하게 됩니다.
이 Pre-train data는 Simple way to expand an image-text pair 파트에서 설명한 가장 간단한 데이터 생성 방식을 사용하여 만들어진 것입니다. 앞서 저자가 제안한 데이터 생성 방식은, 사람이 Instruction을 생성한 다음 이를 기반으로 여러 Instruction pair를 만드는 것이 었습니다. 그에 반해 가장 단순한 생성 방식은 GPT에게 캡션 X_c를 사용해서 이 답변이 나올 만한 X_q를 만들어보라고 요청하는 것이었습니다
이제 준비가 다 되었으니, 순차적으로 모델을 학습해보겠습니다. 여기서 중요한건 Image Encoder와 Language Model은 그냥 가져다 쓴다는 것입니다. 또한 학습은 2-stage로 구성됩니다: (1) Projection W를 학습 (2) Fine-tuning End-to-End
Stage 1: Pre-training for Feature Alignment. Image Encoder와 Language Model은 Freeze 한 채로 W만 학습합니다. 이 모델을 학습하기 위해 CC3M 데이터셋을 사용하였으며 595,000개의 이미지-텍스트 쌍으로 필터링합니다. 이러한 쌍은 직전에 설명한 단순 데이터 확장 방법을 사용하여 Instruction-Following 데이터로 변환됩니다.
Stage 2: Fine-tuning End-to-End. Image Encoder 는 Freeze하고, Projection과 LLM의 사전 학습된 웨이트를 다시 학습합니다.
Experiments
Multi-chat bot
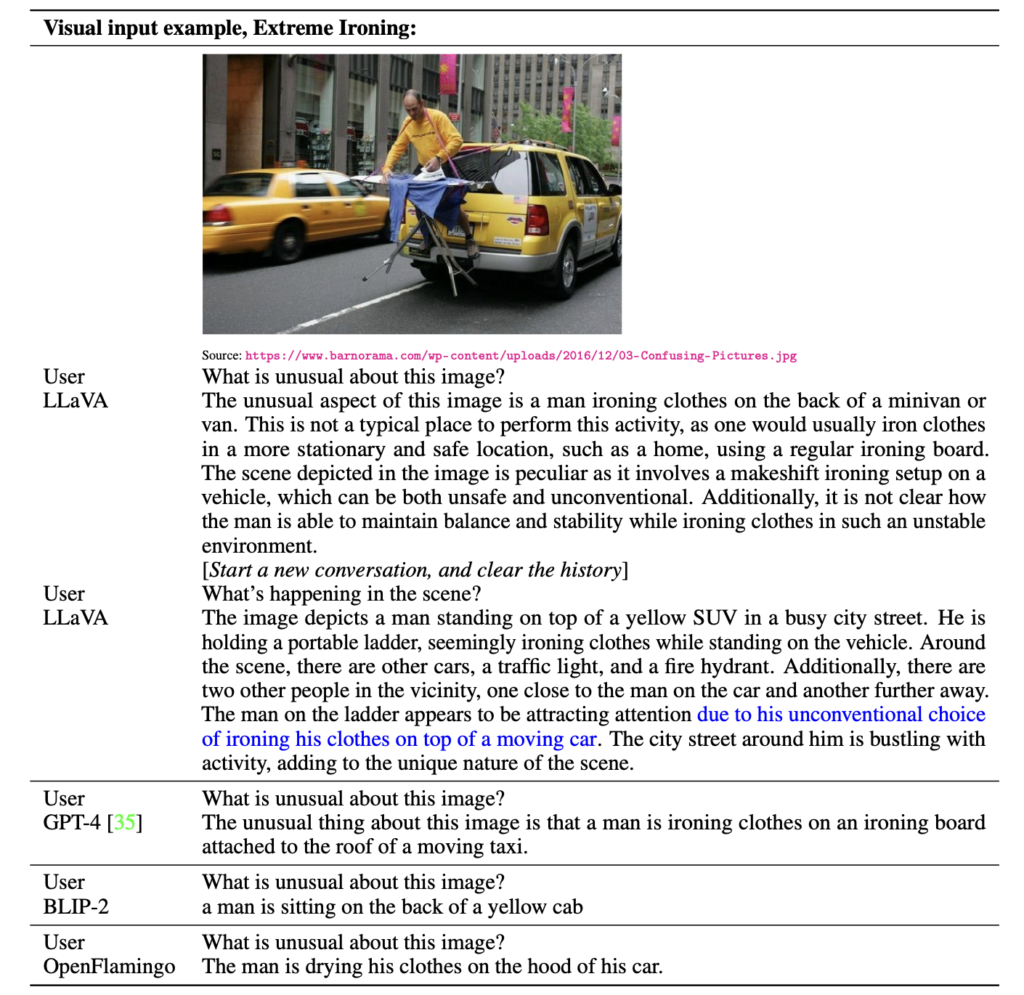
아래 그림들은 LLaVA, GPT-4, BLIP-2, OpenFlamingo 등의 모델이 시각적 데이터를 어떻게 처리하고 이해하는지를 보여줍니다. 각 모델은 주어진 이미지와 텍스트를 바탕으로 다양한 방식으로 질문에 답변하였는데, LLaVA와 GPT-4는 상세하고 논리적인 답변을 제공하는 반면, BLIP-2와 OpenFlamingo는 상대적으로 간단한 설명을 제공합니다.
LLaVA는 COCO로부터 합성한 적은 multimodal instruction-following dataset(~80K unique images)으로 학습했음에도 불구하고, multimodal GPT-4와 유사한 결과를 보였다고 합니다. BLIP-2와 Open Falmingo는 Instruction을 따르지 않는 결과를 보였죠.

Qauntitative Result
LLaVA의 성능을 체계적으로 평가하기 위해 GPT-4를 활용하여 모델의 지시 수행 능력을 정량적 척도로 측정하고자 하였습니다. COCO Val 2014 데이터셋에서 무작위로 30개의 이미지를 선택하고, 이전에 언급한 데이터 생성 파이프라인을 사용하여 세 가지 유형의 질문(대화, 상세 설명, 복잡한 추론)을 생성합니다.
LLaVA는 이 질문들과 시각적 입력 이미지에 기반하여 답변을 생성합니다. 한편, GPT-4는 질문과 정답 경계 상자, 캡션을 바탕으로 최고 성능을 나타내는 기준 예측(reference prediction)을 만듭니다. 두 모델로부터 응답을 얻은 후, 질문과 시각적 정보(캡션 및 경계 상자), 그리고 생성된 두 응답을 GPT-4에 입력합니다. 이때 GPT-4는 응답의 유용성, 관련성, 정확성 및 세부 수준을 평가하여 1에서 10 사이의 점수를 부여합니다. 점수가 높을수록 전반적인 성능이 우수함을 나타냅니다. 또한, GPT-4는 평가에 대한 포괄적인 설명을 제공하여 모델을 더 잘 이해할 수 있도록 돕습니다.
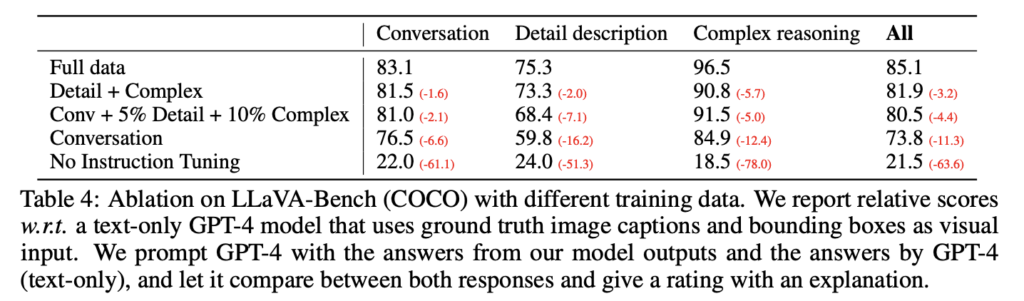
이 실험 결과는 다양한 유형의 데이터를 포함한 지시 튜닝이 모델의 전반적인 성능을 크게 향상시킬 수 있음을 보여줍니다. 특히, 모든 종류의 데이터를 고르게 사용하는 것이 가장 효과적임을 알 수 있습니다. 또한, 지시 튜닝이 없는 경우 모델 성능이 크게 저하된다는 점에서, 지시 튜닝의 중요성을 다시 한 번 확인할 수 있습니다.
아키텍처도 워낙 간단해서 그런지, Visual Instruction Tuning 을 위한 데이터셋 생성 과정이 가장 큰 Contribution 이라고 생각되는 논문입니다.
연구가 정말 빠르게 진행되고 있음을 해당 논문을 리뷰하며 실감하게 됩니다. GPT-4V(ision)이 2023년 3월, LLaVA는 2023년 4월에 공개되었는데, 저는 이제서야 이 논문을 리뷰하다니 너무 트랜드를 못따라가고 있는건 아닌지 부끄럽기도 하네요. 그와중에 Open-AI는 GPT-4o(mni) 이라는 음성까지 합세한 멀티모달을 공개하였으니.. 정말정말 빠르네요. 열심히 따라잡으려고 노력해야겠습니다
홍주연 연구원님, 좋은 리뷰 감사합니다.
요약하자면, Vision-Text pair를 생성하기 위해 GPT를 이용하며, 더 좋은 finetuning을 위해 instruction tuning을 하는 것으로 이해했습니다.
GPT로 데이터를 생성하는 것을 보니 궁금한 점이 생기는데, 이제 GPT가 상당히 수준 높은 text를 생성할 수 있는 것으로 알고 있습니다. 그럼 이제 음성이나 이미지, 비디오 등의 다른 modality와 pairing되는 자연어를 GPT로 생성하여 데이터셋을 구축하거나, text dataset 자체를 GPT를 통해 구축할수도 있지 않을까 하는 생각이 드는데요, GPT가 데이터셋 생성에 사용되는것이 일반적인 경우인지 알고 싶습니다.
감사합니다.
질문에 답변을 드리자면, GPT를 활용한 데이터 구축 및 생성이 아주 활발하게 진행되고 있습니다.
Self-Instruct with Strong Teacher LLMs 이라고 컨셉으로 알고 계시면 좋을 듯 합니다
안녕하세요 홍주영 연구원님. 좋은 리뷰 감사합니다.
해당 리뷰를 읽다보니 궁금한 점이 생기는데요, 얼마전까지 모델을 생성하는 인공지능에 대한 관심도가 높았다고 생각합니다. 혹시 인스트럭션 튜닝을 통해 이러한 문제가 해결되었다, 혹은 인스트럭션 튜닝이 이러한 문제의 해결책이 될것이다 라는 분위기가 있나요?
두번째로는 인스트럭션 튜닝에서 활용하는 GPT 생성 데이터에 대한 감독이 따로 이루어지는지 아니면 그냥 사용하고자 하는지 최신 동향이 궁금합니다
감사합니다
“해당 리뷰를 읽다보니 궁금한 점이 생기는데요, 얼마전까지 모델을 생성하는 인공지능에 대한 관심도가 높았다고 생각합니다. 혹시 인스트럭션 튜닝을 통해 이러한 문제가 해결되었다, 혹은 인스트럭션 튜닝이 이러한 문제의 해결책이 될것이다 라는 분위기가 있나요?”
-> 말씀하신대로, 이미지를 “이해”하는 것과 “생성”하는 것이 분리되어 연구가 수행되었습니다. 그러나 instruction이 등장하면서 이를 통합하는 모델 연구가 주목을 받았고 LLM과 같은 무엇이든 잘하는 Foundation 모델 연구가 주목을 받고 있고 연구가 활발히 되고 있는 것 같습니다.
“두번째로는 인스트럭션 튜닝에서 활용하는 GPT 생성 데이터에 대한 감독이 따로 이루어지는지 아니면 그냥 사용하고자 하는지 최신 동향이 궁금합니다”
-> 모든 데이터에 대해 사람이 검토하는지에 대한 명확한 언급은 없었으나, GPT-4에 쿼리하여 생성된 데이터를 큐레이션 하는 과정이 포함되어 있다는 언급을 통해 일부 데이터 검토가 이루어졌음을 어느정도 확인할 수 있을 듯 싶습니다