
안녕하세요. 허재연입니다. 요즘 KAIST PD dataset만을 가지고 어떻게 하면 detection의 가중치 초기화를 잘 할 수 있을지 고민하고 있습니다. 아무래도 KAIST 데이터셋의 크기가 ImageNet과 비교하면 상당히 작기 때문에 ImaegNet으로 사전학습한 가중치와 비교하면 성능이 떨어집니다. 따라서 사전학습을 통해 ImaegNet가중치의 성능과 최대한 근접하게 성능 개선을 하는 것을 목표로 하고 있습니다. 기존에는 classification에 대한 논문을 주로 읽었었는데, task가 detection으로 넘어오면서 생각보다 추가적으로 고려해야 하는 부분이 많더군요.
해당 논문은 object detection task에 대해 ImaegNet 가중치 초기화에 대해 탐구한 논문으로, detector 초기화 관련 논문을 찾아보다 발견했습니다. 꽤 예전 논문이긴 하지만, 저자들이 상당히 유명한 연구자들이고 주제도 제가 고민하고 있는 부분과 연관이 있는 점이 눈에 띄어서 읽어보게 되었습니다. ResNet의 Kaiming He야 다들 잘 아실테고, 공저자인 Ross Girshick과 P.Dollar도 FAIR에서 Kaiming과 계속 함께 좋은 연구를 하신 분들입니다. 이들 연구팀의 대표적인 성과로는 R-CNN, Fast R-CNN, Faster R-CNN, YOLO, FPN, COCO, Focal loss, FPN, MoCo, MAE, Segment Anything, Panoptic Segmentation로 비전 학계에 큰 획을 그은 것들이 많습니다.
본 논문에서는 실험을 통해 (COCO 데이터셋의 detection 및 segmentation에 대해) 하이퍼파라미터 튜닝이 제대로 되어 있고 모델이 수렴할 수 있도록 충분한 오래 학습을 진행하게 되면 random 초기화가 ImageNet pretrained weight을 사용하는 것과 비교해 뒤지지 않는 성능을 낼 수 있다는 것을 보여줍니다. 저자들은 실험 결과 ImageNet 사전학습 가중치를 이용하는 것이 훈련 초기 빠른 수렴을 도와주긴 하지만 딱히 정규화 효과를 제공하거나 최종적으로 개선된 성능을 보장하지는 않는다고 합니다. 새로운 방법론을 제안하는 논문은 아니라 실험 및 이에 대한 결과 해석이 주를 이룹니다. 이 논문이 나온 뒤 1년 뒤 MoCo가 제안되었는데, 해당 연구팀은 계속 좋은 가중치 초기화에 관심을 가지고 있었던 것 같습니다. 함께 논문 내용을 살펴보겠습니다.
Introduction
CNN은 사전학습된 visual representation에서 유용한 정보를 전이학습을 통해 target task에 잘 전달할 수 있다는 점에서 컴퓨터 비전에 혁명을 일으켰다고 합니다. 이 특성을 활용해 대규모 데이터셋(주로 ImaegNet)에서 사전학습을 거친 후 전이 학습을 통해 목표로 하는, 학습할 데이터가 적은 target task에 fine-tuning하는 것이 일반적인 패러다임으로 굳어졌으며 이 방법을 통해 object detection, image segmentation, action recognition 등 다양한 task에서 SOTA를 달성할 수 있었다고 합니다.
얼핏 보면 이미지넷과 같은 대규모 데이터셋으로 보편적인 feature representation을 사전학습 하는 것으로 컴퓨터 비전의 문제를 해결할 수 있는 것처럼 보였지만, 반드시 그런 것은 아니라고 합니다. object detection과 같은 특정 task에서는 사전학습 데이터셋 크기의 증가에 따라 성능 향상이 미미하였으므로, 이 방법이 최선인지에 대해서는 의문점이 남아있었습니다. 본 논문에서는 이러한 사전학습 패러다임에 의문을 제기하고 다양한 object detection 및 instance segmentation에 대한 실험을 수행하며, 결론적으로 COCO 데이터셋에 대해 사전학습 없이 랜덤 초기화(scratch)를 사용하여도 object detection 및 instance segmentation에 대해서 충분히 경쟁력 있는 성능을 달성할 수 있다고 합니다. 학습에는 최적화를 위해 적절한 정규화 기법이 사용되었으며, 사전 학습의 부재 효과를 상쇄하기 위해 충분히 길게 학습하였습니다.
저자들이 확인한 사항을 요약하면 다음과 같습니다 :
(1) 이미지넷 사전학습이 학습 초기 수렴 속도를 상승시켜 주지만, 랜덤 초기화를 이용하더라도 이미지넷의 사전학습+finetuning을 거친 만큼의 충분한 학습 시간이 주어진다면 이미지넷 사전학습에 필적하는 성능을 달성할 수 있다고 합니다. 만약 그럴 수 없는 상황이라면 사전학습을 활용해 low/mid level feature를 충분히 학습해야 할 필요가 있습니다.
(2) ImageNet 사전학습은 target task/metric이 지역/공간적으로 민감한 예측을 수행해야 할 때 크게 이점을 가질 수 없다고 합니다. 사실 이는 어찌보면 당연하다고 생각될 수 있는데, 이미지넷과 같은 분류 기반 사전학습만으로는 지역적 특징에 민감한 target task를 수행하기 충분한 공간적 특징을 확보하기 힘들기 때문인것으로 보입니다.
이러한 결과는 당시에는 꽤 충격적인 실험 결과로 받아들여진 듯 합니다. 결과적으로는 target task에 대한 훈련을 수행할 수 있는 충분한 리소스가 주어지지 않는 환경에서는 이미지넷 사전학습이 유용하며 이미지넷은 그 가용성 덕분에 좋은 리소스로 여겨져 왔지만, 이후 컴퓨터비전 커뮤니티가 더 많은 학습 리소스를 확보할 수 있다면 (특히 사전학습과 목표 태스크 간 갭이 큰 경우)target task에 알맞는 데이터를 수집하는것이 좋을 것이라고 합니다. 이 논문은 ‘이미지넷 사전학습 가중치가 짱이다!’ 라고 생각하던 당시 연구자들이 이미지넷 사전학습에 대해 다시 한번 생각해보는 계기가 되었다고 합니다.
여담으로, 이후 2020년부터는 다양한 사전학습 방법(주로 비지도 학습)이 제안되었으며, 몇몇 비지도 사전학습 방법은 이미지넷 사전학습에 필적하는 결과를 보였습니다. 단순 contrastive learning은 이미지 분류 영역에서 보통 성능 평가를 하게 되고, detection, segmentation 분야에서는 다소 부족한 성능을 보이는 경향이 있었는데, 결국 사전학습을 수행할 때는 어떤 target task에 사용할건지 염두하고 설계하는것이 필수인 것 같습니다.
Methodology
저자들은 목표는 개선된 모델 구조를 제안하는 것이 아니라, ImageNet 사전학습의 효과를 분석하는 것입니다. 이 영향을 잘 이해하기 위해서는 최대한 통제된 환경에서 모델 수정 없이 학습을 진행하는것이 필요합니다. 실험에는 필요하다고 판단되는 2가지 요소(정규화 및 학습 기간)만 수정이 가해졌는데, 세부 사항은 다음과 같습니다:
Normalization
이미지 분류와 마찬가지로 object detector에도 normalization이 중요한 역할을 합니다. 현대 신경망에는 주로 사용되는 배치 정규화는 object detector의 학습에
Object detector는 이미지 분류기보다는 일반적으로 높은 해상도의 이미지를 입력으로 받습니다. 제한된 메모리 환경에서는 이미지 하나 당 용량이 커지므로 배치 사이즈를 줄여야 하는데, 작은 배치 사이즈는 배치 정규화의 정확도를 떨어뜨릴 수 있습니다. 만약 사전학습을 이용한다면 파인튜닝 단계에서 배치 통계 정보를 고정된 파라미터로 활용할 수 있으므로, 이 이슈에 대처할 수 있습니다.
Convergence
scratch부터 학습하는 방법으로는 ImageNet 사전학습으로 초기화된 모델만큼 빠른 수렴을 기대할 수 없습니다. 일반적으로 ImageNet 사전학습 단계에서는 100만개 이상의 데이터가 100번 이상 반복적으로 학습되는데, 학습 과정에서 semantic한 정보 외에도 파인튜닝 단계에서 재학습할 필요가 없는 edge, texture와 같은 저수준 특징을 학습할 수 있습니다. 반대로 모델을 처음부터 학습하면 저수준 및 고수준 특징을 모두 학습해야 하므로 모델이 잘 수렴하기 위해서는 보다 많은 학습 기간이 필요합니다. 따라서 공정한 비교를 위해서는 사전학습이 진행된 학습 시간을 함께 고려해야 합니다.
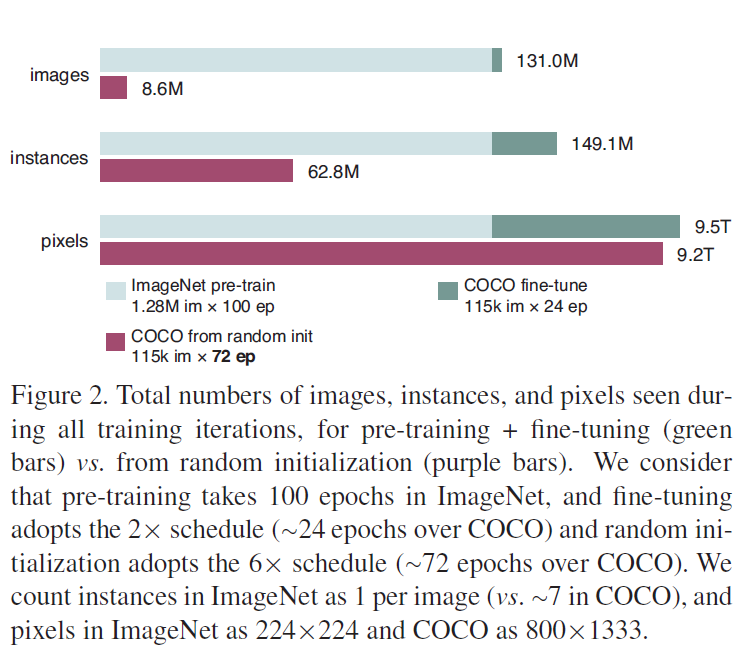
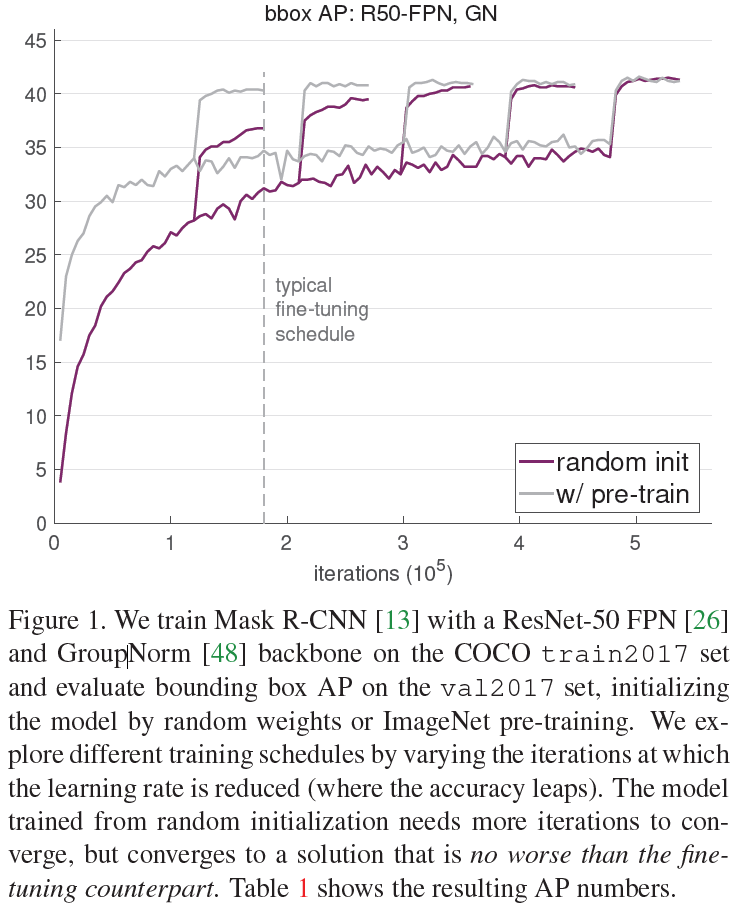
Figure 2에서는 COCO에서 처음부터 학습된 경우 사전학습을 이용하는 것보다 3배 더 많은 학습을 하는 것을 볼 수 있지만, ImageNet 사전학습을 거친 것을 함께 고려하면 훨씬 적은 학습으로 동일한 성능을 달성한 것으로 볼 수 있습니다. 해당 표에서도 random 초기화를 한 모델이 finetuning에 필적하는 성능을 보이기 위해서는 보다 많은 훈련 기간이 필요한 것을 확인할 수 있습니다.
Experiment
저자들은 scratch부터 학습하는 효과에 대해 정확히 알기 위해서 baseline system에서 최소한의 수정만 가하고자 했다고 합니다. 전반적인 베이스라인은 위에서 언급한 normalization과 training iteration만 제외하고 Mask R-CNN을 따릅니다.
Architecture : 모델은 ResNet, ResNeXt, FPN 백본 기반 Mask R-CNN이 사용되었습니다. frozen batch norm을 대체하여 Group Normalize와 SyncBN(GPU간 통신으로 메모리 이슈 극복)를 사용하였으며, 공정한 비교를 위해 사전학습한 모델을 파인튜닝할 때도 동일한 정규화 기법이 적용되었습니다.
Learning rate scheduling : 본래 Mask R-CNN은 90k iteration(1xschedule) 혹은 180k iteration(2x schedule)동안 feintuning되었습니다. 본 논문에서는 보다 긴 학습(540k iterations -> 6xschedule)에 대한 실험도 수행되었으며, 학습 기간의 길이에 관계 없이 마지막 60k및 20k iterations에서 각각 10배씩 LR를 감소시켰다고 합니다. 저자들은 큰 learning rate로 오랫동안 학습시키는게 좋았으며, 작은 LR로 너무 오래 학습시켰을때는 overfitting이 관찰되었다고 합니다.
Results and Analysis
첫째로, 가장 놀라웠던 것은 COCO 데이터만을 가지고 scratch부터 학습하였을 때 사전학습 후 파인튜닝한 성능을 따라잡을 수 있었다는 것이라고 합니다.
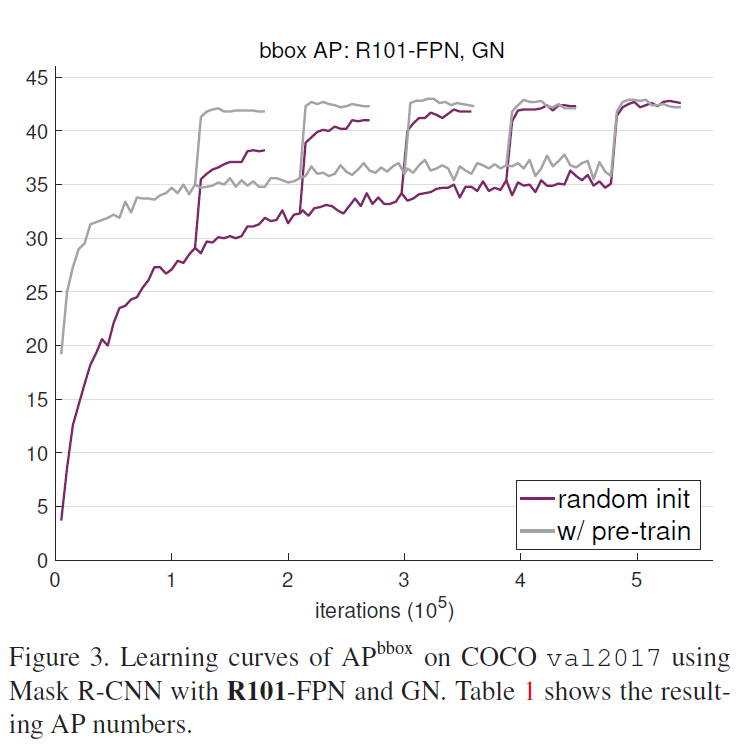
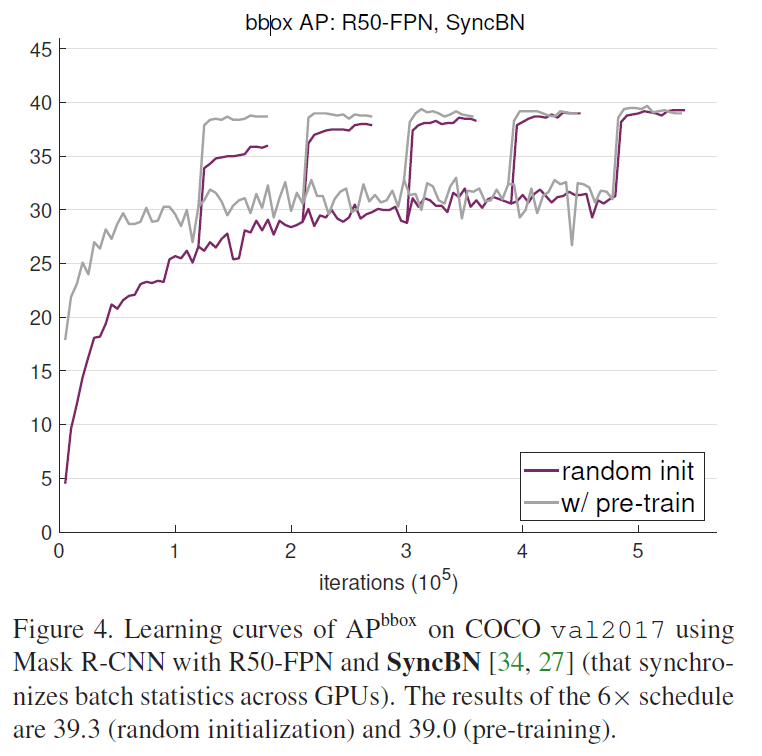
위 각각 Figure에서는 random 초기화 후 학습도니 것과 ImageNet 사전학습 후 fine-tuned 된 성능을 비교하였습니다. 2x부터 6x까지 5개의 서로 다른 학습 기간(schedules)동안 학습된 것이 표에 나타났습니다(동일한 한 모델의 서로 다른 5개의 스케줄을 같은 plot에 겹쳐 나타내었습니다). 중간중간 AP곡선이 팍 튀는 것은 각각 스케줄에서 learning rate가 감소한 부분이며, 그 끝이 각각 스케줄의 최종 성능 결과입니다. Figure 1,3,4에서 다음과 같은 비슷한 양상을 확인할 수 있습니다 :
(1) 일반적인 파인 튜닝 스케줄(2x)는 사전학습된 모델이 최적으로 수렴되는데 충분합니다. 하지만 이런 훈련 주기는 랜덤 초기화부터 학습되는 모델에는 충분하지 않으며 단기간 훈련된 결과는 사전학습된 모델에 미치지 못합니다.
(2) scratch부터 학습된 모델은 5x ~ 6x의 충분한 학습 기간이 주어지면 사전학습 후 파인튜닝한 모델의 성능을 따라집을 수 있습니다.
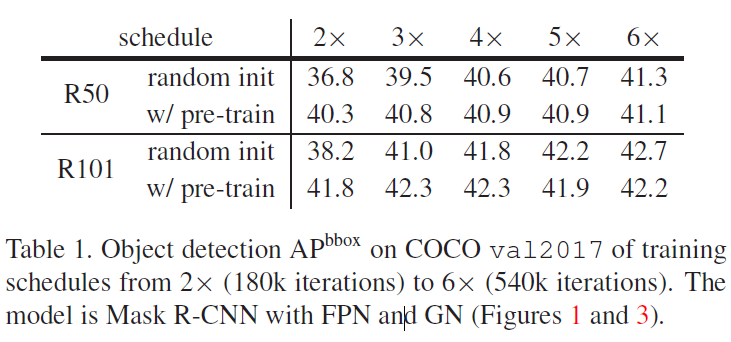
standard COCO 학습 셋에 대해, ImageNet 사전학습이 target task에 대한 빠른 수렴을 도와줄 수 있지만, 최종 detection 성능 개선에 대한 이점을 찾을 수는 없었습니다.
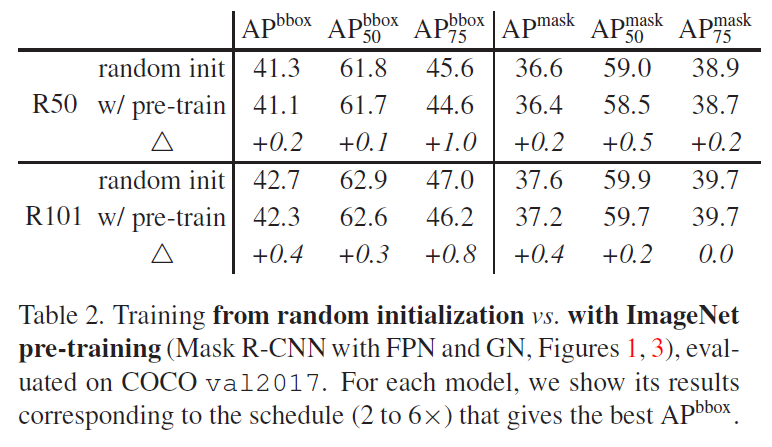
Table 2에서는 random 초기화와 ImageNet 사전학습의 결과를 다양한 지표에 대해 비교한 것인데, 해당 실험에서도 scratch부터 학습한 모델이 사전학습을 이용한 것과 비슷한 최종 AP를 기록한 것을 확인할 수 있습니다.
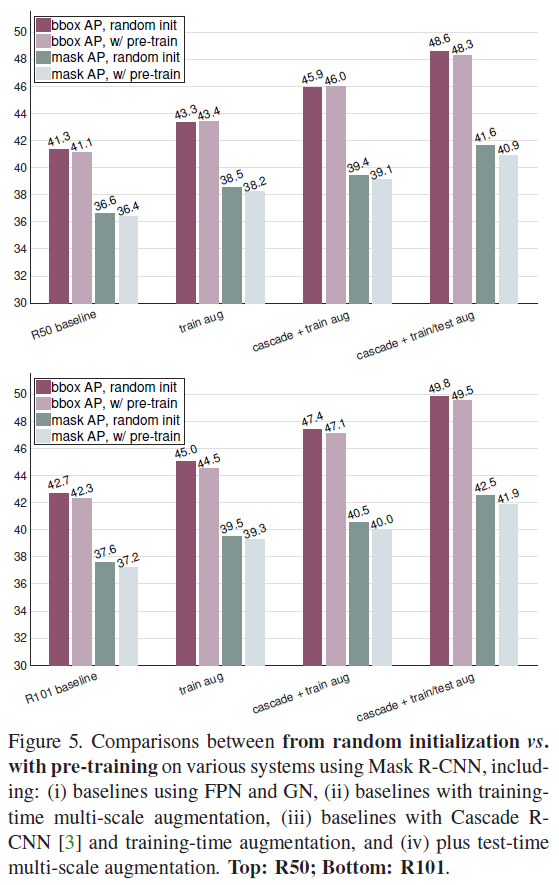
Figure 5는 Augmentation과 Cascade R-CNN에 대한 적용 실험 결과입니다. 위쪽은 R50, 아래쪽은 R101에 대한 표입니다. 데이터 증강을 적용시키면 수렴을 위해 더 긴 학습이 필요하므로 학습 기간을 더 늘려주었다고 합니다. Casecade R-CNN은 처음 보는건데 localization 정확도를 올리기 위한 방법 중 하나로 2 extra stage를 추가한 것이라고 합니다. 단순히 Mask R-CNN의 마지막 stage에 mask head를 추가했다고 하네요. 다양하게 실험 조건을 바꿔보았음에도 사전학습을 거친 모델이 랜덤 초기화부터 학습한 모델보다 월등히 좋은 최종 성능을 보이지는 않습니다.

COCO human keypoin tdetection task에 Mask R-CNN을 학습시켰을때도, scratch부터 학습한 결과가 (크게 느리지 않게) 사전학습을 거친 모델의 성능을 따라집을 수 있었습니다. keypoint detection은 보다 fine spatial localization에 민감한 task라고 합니다. 저자들은 해당 실험을 통해 명시적으로 localization 정보를 많이 갖고있지 않는 ImageNet 사전학습 방법이 keypoint detection에는 크게 도움이 되지 않는다고 분석하였습니다(low-level feature를 이미 학습하고 있는 정도의 이점만 있는 것으로 보입니다)
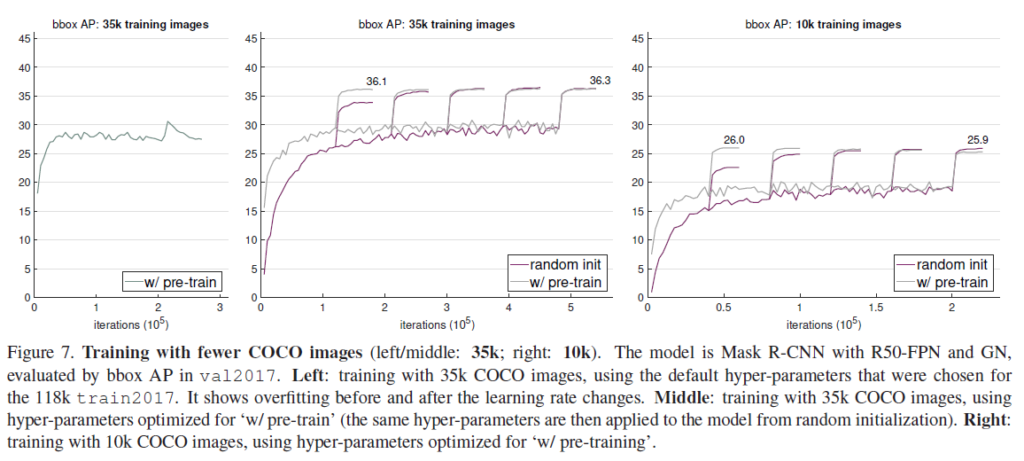
이번에는 적은 수의 데이터만 가지고 학습을 한 결과입니다. 꽤나 놀라운 결과인데, COCO의 10%만을 가지고 scratch부터 학습한 결과가 사전학습을 거친 성능에 비해 뒤떨어지지 않는다는 것입니다 .
왼쪽과 가운데는 전체의 1/3 수준인 35k개의 COCO 학습 셋을 이용한 것이고, 오른쪽은 그보다 작은 10k개를 사용하여 학습한 것입니다. 특히 왼쪽 표에서 learning rate 조정 전/후 오버피팅 현상이 관찰되는데, 저자들은 이를 두고 이미지넷 사전학습이 오버피팅을 줄이는데는 도움이 되지 않는다고 합니다. 적은 수의 데이터만으로 이미지넷 사전학습 가중치를 이용한것과 동등한 성능을 달성하는게 놀랍습니다. 이미지넷 사전학습으로 이점을 얻을 수 있는 표현력을 확보하기에는 충분한 데이터 크기가 아니었을까 싶네요.
하지만 이런 경향이 계속 보이는것은 아닙니다. 학습 이미지를 더욱 줄이면(1k) 이미지넷 사전학습을 이용하는 것이 더 좋은 결과를 보인다고 합니다.
Conclusion
위의 내용을 요약하면 다음과 같습니다 :
- scratch부터 학습하기 위해서는 수렴을 위해 더욱 긴 학습이 필요하고
- 많은 경우 scratch부터 학습하는것이 ImageNet 사전학습 가중치를 이용하는것보다 떨어지는 성능을 보여줄 수 있으며
- ImageNet 사전학습 가중치는 target task 학습 수렴 속도를 빠르게 해 주는 이점이 있고
- ImageNet 사전학습 가중치를 이용하는것이 오버피팅을 방지하는 효과는 확인할 수 없었으며
- target task가 localization 정보에 더욱 민감할수록 ImageNet 사전학습의 이점이 덜하다
저자들은 다음과 같은 결론을 내립니다.
‘이미지넷 사전학습이 필요한가?’ – 만약 충분한 양의 target data와 계산 리소스를 가지고 있다면, 그렇지 않다. 이미지넷 사전학습은 학습의 빠른 수렴을 도와주지만 (target data의 개수가 극히 적은 상황이 아니라면)최종 성능에 있어서는 도움을 주지 못한다.
‘이미지넷 데이터셋은 도움이 되는가?‘ – 그렇다. 수렴속도를 빠르게 해줄 수 있으며 특히 target task를 학습시킬 데이터가 부족하거나 적절하지 못할 때 큰 도움을 줄 수 있다. 또한 사전학습된 가중치는 연구 사이클을 줄일 수 있고, 보다 편하게 원하는 성능을 달성하는데 도움이 된다.
그리고 좋은 visual representation의 확보에 대한 향후 연구로 개선이 있으면 좋겠다는 말과 함께 논문이 마무리됩니다.
보통 좋은 사전학습을 거친 가중치를 이용하면 충분한 훈련 기간을 거친 최종 성능에서도 더 나은 결과를 보일 수 있다는 것으로 알고 있었고, 이미지넷은 대표적인 좋은 visual representation 중 하나로 알고 있었습니다. 하지만 target task가 분류가 아닐 때는 이미지넷 데이터셋이 최종 성능 결과에 크게 도움이 되지 못한다는 것을 새로 알게 되었습니다. target data가 충분하다면 어떤 가중치를 사용해서 초기화해도 비슷한 결과가 나온다는 결론인데, KAIST data는 수렴하지 못한 것 보니 데이터셋의 크기가 충분하지 못했거나, 아니면 훈련 iteration이 충분하지 못했거나 둘 중 하나인 것 가테요. 가중치 초기화 관련 논문을 더 살펴보며 추가적인 고민을 해 봐야겠습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사합니다.
Results and Analysis의 Fig3,4에서 그래프가 중간에 끊기던데 이는 동일한 모델에 대해 학습 기간만 달리하여 성능을 측정한 것인가요?
중간에 그래프가 급격하게 상승하는 부분은 lr이 감소한 부분이라고 설명해주셨습니다. 본문에서 5개의 서로 다른 학습 기간 동안 학습 기간의 길이에 관계 없이 동일하게 lr을 감소시켰다고 하셨는데 lr이 감소한 부분에서 그래프가 나뉘는 이유가 무엇인가요?
감사합니다.
각각은 동일한 모델에 대해 서로 다른 기간동안 학습을 한 것입니다. x2 ~ x6까지 개의 learning schedule을 적용하여 비교한 것이죠. 성능이 튀는 부분은 learning rate를 줄인 부분인데, learning rate를 조정하는 것은 본문에서 말했듯 학습 기간의 길이에 관계 없이 마지막 60k및 20k iterations에서 각각 learning rate를 감소시킨 것입니다. 5개의 learning 길이에 대해 각각 학습이 끝나기 일정 iteration 전에 learnign rate 조절을 했다고 생각하시면 되겠습니다.
감사합니다.
안녕하세요 재연님
상세한 리뷰 덕에 논문을 잘 이해했습니다.
좋은 리뷰 감사합니다.
URP과정에서 pretrained를 제대로 불러오지 못한채로 학습을 돌렸다가
결과가 하나도 예측을 못했던 경험이 있어서 더 재밌게 읽었던것 같습니다.
imagenet 사전학습을 사용하면 edge, texture와 같은 저수준 특징의 정보는 잘 학습하지만
“target task/metric이 지역/공간적으로 민감한 예측을 수행해야 할 때 크게 이점을 가질 수 없다”라는
부분이 잘 이해가 가지 않았습니다.
imagenet은 classification을 위해 학습된 모델이여서 단순히 객체의 label만 예측만 하므로
semantic segmentation와 같이 pixel level의 정보를 담은 사전학습보다
지역/공간적 의미를 적게 가지고 있다고 이해하면 될까요?
이를 이해하기 위해서는 retrieval / classification과 같은 instance 단위에서 이뤄지는 task와, segmentation/detection과 같은 이미지의 국소적인 영역 특징이 중요하게 사용되는 dense prediction task를 구분하여 생각해야 합니다.
classification이나 retrieval 같은 task는 이미지 한 장 전체를 하나의 벡터로 요약하고, 해당 data instance 전체를 다른 data instance(이것도 이미지 한 장 전체에 대한 feature가 되겠죠)와 비교하는 task입니다. 이미지의 국소 부분에 대한 정보가 덜 담겨도 task를 수행하는데 크게 문제되지 않죠.
하지만 이미지의 국소적인 영역을 잘 예측해야 하는 object detection이나 segmentation같은 task를 수행하기 위해서는, 이미지 전체가 아닌, 각 부분에 대한 local feature를 잘 추출해야 합니다. 이런 task를 잘 수행하기 위해서는 모델이 local feature를 잘 추출하도록 학습이 되어있어야 합니다. 따라서 instance 단위 task(classification이나 이미지 단위의contrastive learning 등)에서 사전학습한 모델은 별다른 튜닝 없이 dense prediction task에 바로 적용시키면 예측 능력이 크게 떨어집니다.
예시로, OVOD 등의 분야에서 정우님이 여러 번 들었을 CLIP의 경우 image feature와 alt-text(이미지 캡션이라고 생각하시면 됩니다) pair로 local 특징에 대한 별다른 고려 없이 instance 단위 contrastive learning 으로 사전학습한 기법이기에, 별다른 튜닝 과정 없이 바로 zero-shot 예측을 때려버리면 dense prediction task를 잘 수행하지 못합니다.
결론적으로, imagnet classification으로 사전학습된 가중치는 detection/segmentation에 중요하게 사용되는 local feature를 잘 모델링하는 능력이 떨어지기 때문에 추가적인 finetuning이 필요하다고 이해하시면 좋을 것 같습니다.