안녕하세요. 오늘 리뷰할 논문은 OVOD task를 다룬 Retrieval-Augmented Open-Vocabulary Object Detection입니다. CVPR 논문들을 뒤져보다가 마침 궁금했던 OVOD task를 고려대학교, 삼섬 리서치에서 작성한 논문이 있길래 OVOD task도 팔로우업 할 겸 논문을 읽게 되었습니다. 그럼 리뷰 시작하겠습니다.
Introduction
OVOD는 Open-vocabulary object detection으로 open-set 카테고리(모델이 훈련 중 보지 못한 새로운 카테고리)에 해당하는 객체들을 검출하는 것을 목표로 하는 task입니다. 저자는 이러한 OVOD가 학습 과정에서 나타나지 않은 객체를 평가 시에는 검출해낼 수 있어야 하기에 굉장히 challenging한 task임을 강조하며 사전학습된 Vision-Language Model(VLM)의 정보를 사용하는 것으로 새로운 카테고리를 인식해낼 수 있다고 합니다.
VLM의 정보를 사용하는 방법 중에 하나는 Knowledge Distillation입니다. Knowledge Distillation 방법은 직역하면 정보 증류로 사전 학습된 큰 네트워크(Teacher Network)의 정보를 실제 사용할 작은 네트워크(Student network)에 전달하는 것으로 중요한 정보를 추출하는 방법입니다. 즉, 사전학습된 VLM의 정보를 객체 검출기에 전달하는 방법입니다. 몇 연구들은 검출기의 더 나은 alignment를 위해 Knowledge Distillation과정에서 image-level이 아닌 region-level로 단를 매칭시키려고 노력했습니다. 더 나아가 몇 연구들은 검출기의 새로운 카테고리에 대한 일반화 능력을 향상시키기 위해서 수도 라벨링을 사용했습니다. 이때의 수도 라벨링은 추가적인 단어 셋과 시각 특징을 매칭하여 region proposal을 하는 방법으로 ‘positive’ 카테고리에만 집중한다는 특징이 있습니다. 저자는 다양한 단 셋을 위해 ‘negative’ 카테고리들을 포함시키고 verbalized concepts를 활용하는것으로 OVOD 프레임워크를 개선할 수 있다고 주장합니다.
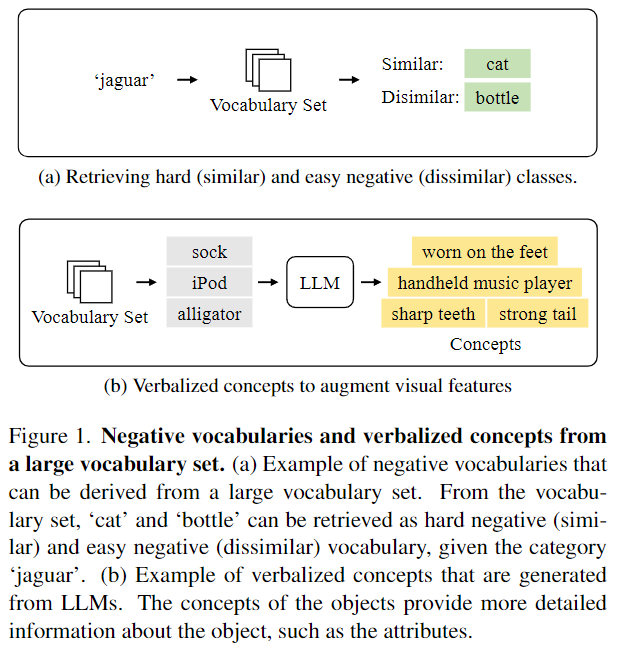
Figure 1. 에서 (a)는 positive와 함께 negative를 활용하는 모습을 보여줍니다. figure의 예시를 보시면 jaguar와 비슷한 cat을 positive로 비슷하지 않은 bottle을 negative로 활용합니다. 이러한 negative를 활용하여 loss를 augment합니다. 구체적으로 어떻게 augmnet하는지는 밑의 Method에서 설명하겠습니다. Figure 1. 에서 (b)는 LLM을 활용하여 클래스의 특징을 verbalized concepts로 일반화하는 방법을 보여줍니다. 이는 각 클래스의 정보들을 더해주는 것으로 효과적인 표현을 학습하는 데 사용합니다. 위 방법들은 모두 어휘 집합을 더 효과적으로 사용하는 것으로 새로운 카테고리를 탐지하는 성능을 향상시키는 방법입니다.
저자는 큰 어휘 집합에서 어휘의 개념을 검색하고 손실함수와 시각적 특징을 증강합니다. 각 방법을 Retrieval-Augmented Losses (RAL)과 Retrieval-Augmented visual Features (RAF) 모듈을 통해 구현했으며 두 모듈을 합한 Retrieval-Augmented Lossed and visual Features (RALF) 프레임워크를 제안합니다.
RAL은 주어진 정답 레이블을 통해 유사성을 기반으로 hard nagative와 easy negative를 검색합니다. 그 후 정답 레이블과의 거리를 통해 추가 loss를 최적화합니다. RAF는 좀 더 풍부한 정보를 얻기 위하여 LLM을 사용합니다. LLM을 통해 verbalized concepts를 추출하여 concept store에 저장합니다. 그리고 저장된 concept store에의 정보를 통해 시각적 특징을 증강하게 됩니다.
Method
Open-vocabulary object detection (OVOD)는 기존 객체 검출기의 객체의 위치를 식별하고 (localize) 분류하는 (classify) 기능을 사전 학습의 범주를 벗어나는 객체(범주)에 대해서도 검출할 수 있게 하는 task입니다. 일반적으로 OVOD는 카테고리의 범주에 구애 받지 않게 하기위해 Region Proposal Network(RPN)을 사용합니다. region proposal 이후에는 사전 훈련된 vision-language model(VLM)을 활용한 zero샷 학습 방식을 통해 광범위한 범주(클래스)를 분류합니다. 구체적으로 region proposal r이 주어지면, r을 통해 region 임베딩 e_r \in \mathbb{R}^d를 추출하고 유사성을 계산하거나 카테고리 T(c) \in \mathbb{R}^d의 텍스트 임베딩을 통해 zero샷 분류를 수행합니다. 수식에서 T는 텍스트 인코더이고, c는 클래스입니다. 즉, 제안된 region에 있는 객체를 VLM을 통해 검출하고 사전에 정의된 클래스 혹은 새로운 클래스를 텍스트 인코더를 통해 임베딩함으로 유사성 계산 혹은 zero샷 분류를 수행합니다.
Retrieval-Augmented Losses and visual Features (RALF)
저자가 제안하는 RALF는 위에서 설명한 파이프라인을 따라가는 동시에 두가지 모듈 RAL, RAF를 추가했습니다. RAL은 semantic similarity를 통해 negative 어휘를 검색하고 loss를 강화합니다. RAF는 검색된 어휘(proposal된 region의 객체를 VLM을 통해 검색해 얻은 텍스트)의 verbalized concepts를 통해 시각적 특징을 강화합니다.
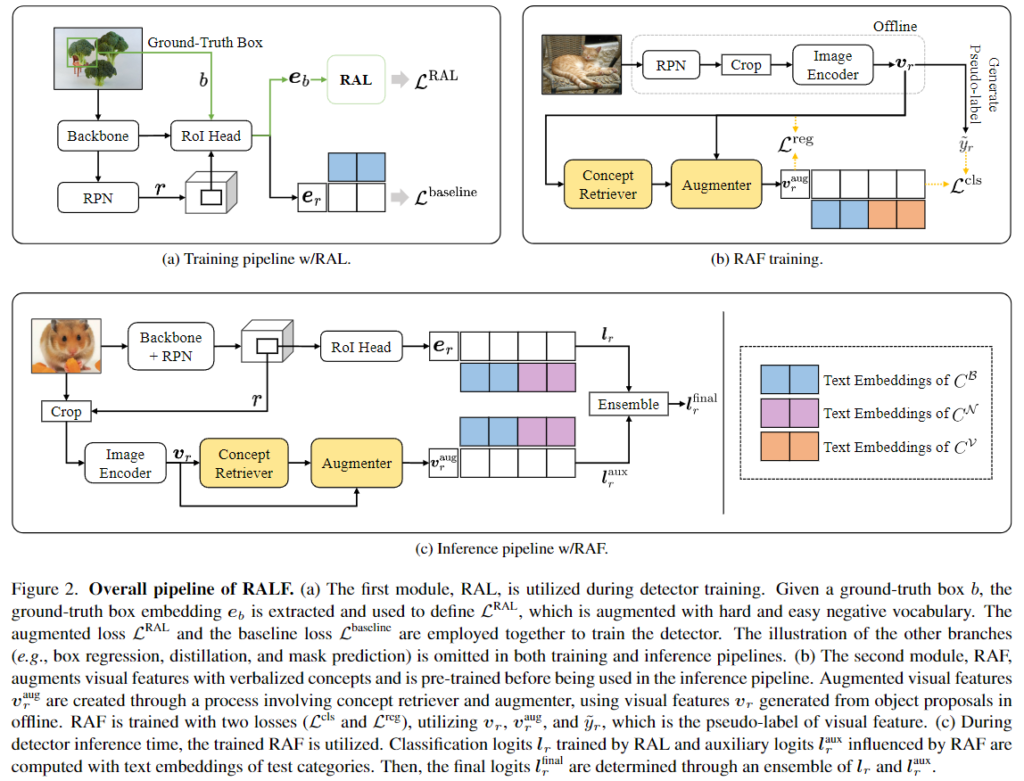
Figure 2.는 저자가 제안하는 RALF의 파이프라인을 보여주는 그림입니다. (a)는 첫 모듈인 RAL을 보여주고 있습니다. 검출기를 학습시킬 때에 활용됩니다. GT b가 주어지면 GT 임베딩 e_b를 추출하여 손실함수L^{RAL}을 정의하는 데에 사용되며, hard, easy 어휘를 통해 강화됩니다. 강화된 손실함수L^{RAL}과 baseline 손실함수 L^{baseline}은 검출기 학습에 사용됩니다. (b)는 두번째 모듈인 RAF를 보여주고 있습니다. LLM을 통해 사전학습된 verbalized concepts을 추출하고 시각적 특징을 강화해 inference에 사용됩니다. 강화된 시각적 특징 v^{aug}_r은 시각적 특징 v_r을 사용해 concept retrieval, augmenter를 통해 생성됩니다. RAF는 분류, 회귀 손실함수 두개를 사용하여 학습됩니다. (c)는 inference할때 RAL로 학습한 분류 로짓 l_r과 RAF를 통해 강화된 l^{aux}_r을 앙상블하는 것으로 최종 로짓 l^{final}_r을 결정합니다. Figure 2. 에서 C^B, C^N, C^V는 각각 base 카테고리, novel 카테고리 그리고 Vocabulary Store를 의미합니다.
Retrieval-Augmented Losses (RAL)
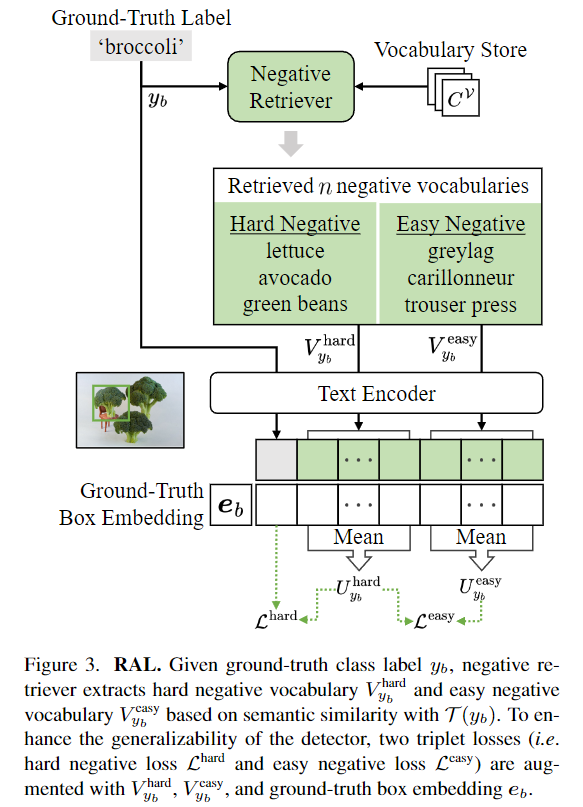
RAL은 vocabulary store를 통해 기존의 base 클래스, novel 클래스를 모두 잘 검출할 수 있도록 검출기의 일반화 성능을 올려줍니다. 위 Figure3.에서 RAL의 구조를 설명하고 있으며, GT 라벨을 vocabulary store를 통해 GT의 의미론적 유사성에 따른 Hard Negative와 Easy Negative 어휘들을 추출해 GT box 임베딩에 GT의 텍스트 임베딩, Hard Negative의 텍스트 임베딩 그리고 Easy Negative의 텍스트 임베딩을 더해줍니다.
저자는 일부 어휘가 모든 base 카테고리에 대해 지속적으로 높거나 낮은 유사성 점수를 갖고 있다는 것을 발견했는데 이러한 경우에는 손실함수를 강화하는 데에는 효과가 적다고 합니다. 따라서 이러한 문제를 해결하기 위해서 측정된 유사성 점수의 분산을 기반으로 어휘를 필터링하는 방식을 채택했으며, 밑의 수식을 통해 순위를 결정해 hard과 easy를 구분합니다.
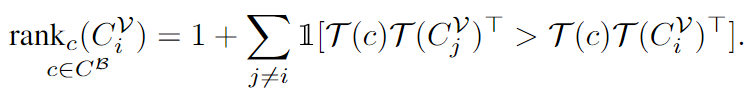
T(c)는 카테고리 c의 텍스트 임베딩이고, C^V는 hard 혹은 easy negative vocabulary를 의미합니다. 저자는 이중에 분산이 상대적으로 작은 ranking을 제외한 후에 상위 m개, 하위 m개의 어휘를 각각 hard neagitve와 easy negative로 선정했습니다. hard negative는 기본적으로 GT와 유사한 어휘들로 구성되어 GT와의 구분이 어렵기 때문에 hard이고, easy는 GT와 유사성이 낮아 구분이 쉽기에 easy negative입니다.
수식으로 확인하면, 저자는 먼저, GT의 임베딩 e_b와의 average cosine 유사성을 계산합니다.
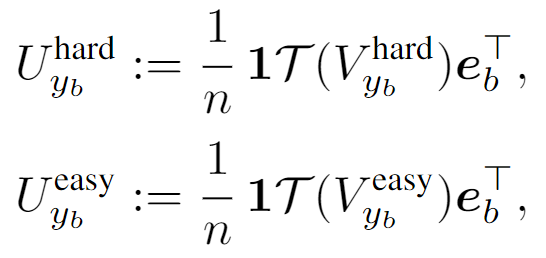
여기서 굵은 T 앞의 1은 주어진 n개의 어휘 중에 하나를 의미합니다(where 1 \in \mathbb{R}^n given n vocabularies 라고 설명하는데 제대로 이해한건지 헷갈리네요). 암튼 각각이 average 코사인 유사성을 의미하고 손실함수는 밑과 같이 정의됩니다.
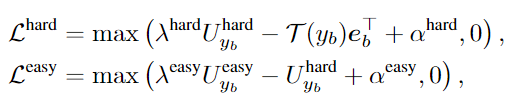
위 손실함수는 margin loss로 hard negative loss는 e_b가 V^{hard}_{y_b}보다 y_b와 더 유사성을 갖도록 학습하고, easy negative loss는V^{hard}_{y_b}가 V^{easy}_{y_b}보다 y_b와의 유사성이 크도록 학습합니다.
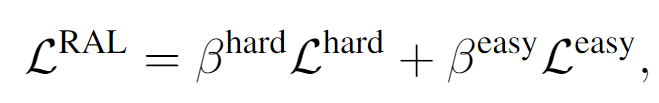
RAL 모듈의 최종 손실함수는 두 loss를 합한 형태로 결국 풍부한 어휘를 통해 여러 negative를 생성하고 easy neagative보다는 hard negative가, hard negative보다는 모델의 예측이 더 GT와 유사성을 가지게 학습함으로 손실함수를 강화합니다.
Augmented visual Features (RAF)
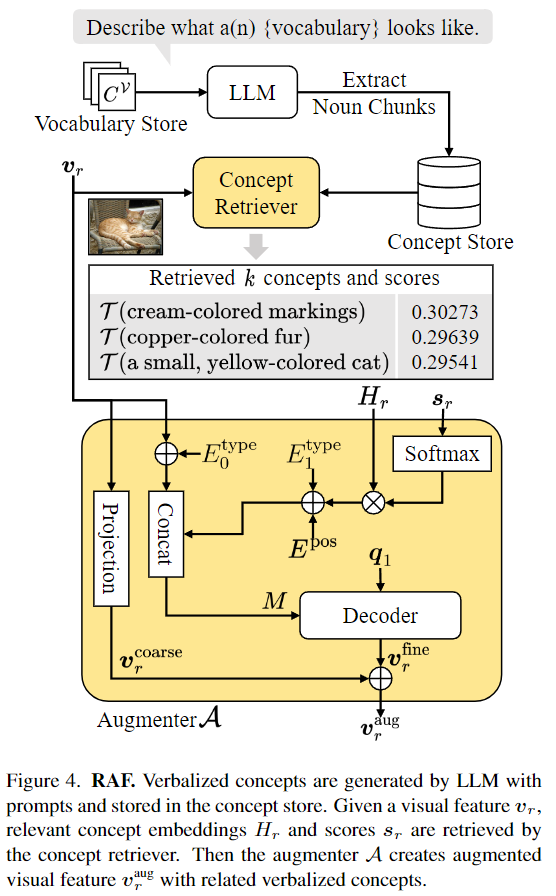
Figure 4.는 RAF 모듈을 보여줍니다. 직관적이었던 RAL과 달리 RAF는 조금 복잡해 보이지만 알고보면 그리 복잡하진 않습니다. LLM에 ‘Describe what a(n) {vocabulary} looks like’라는 프롬프트를 활용해 객체를 설명하는 여러가지 특징들을 concepts store에 저장합니다. 이때 전치사와 같은 의미 없는 단어들을 제거하고 유의미한 의미를 갖는 명사들만 concept store에 저장합니다. 그 후 concept retriever를 통해 시각적 특징을 강화하기 위한 concepts를 검색하게 되는데 concept 임베딩 H를 T(concepts)를 통해 얻고 시각적 특징 v_r와 코사인 유사도를 계산하여 가장 관련성이 높은 k개의 concepts를 반환합니다. 이때 반환하는 값은 concept의 임베딩 H_r과 해당 점수(코사인 유사도 점수)s_r를 반환합니다. 반환된 값과 시각적 특징 v_r는 concepts augmenter의 입력으로 사용됩니다.
Augmenter는 말그대로 시각적 특징을 강화하는데 시각적 특징을 linear projection만 하는 coarse한 특징 b^{coarse}와 concept retrieval의 출력값인 verbalized concepts와 시각적 특징을 concat한 특징 M을 키, 밸류로 쿼리 임베딩(시각적 특징 v_r)을 쿼리로 트랜스포머 디코더를 거친 fine-level 특징 v^{fine}_r를 더해 시각적 특징을 강화합니다.
M을 수식으로 표현하면 다음과 같습니다.
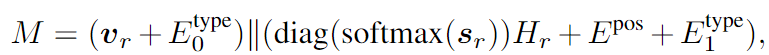
diag()는 diagonal matrix function을 의미하고, ||는 concatenate를 의미합니다. E_{pos}는 얼마나 많은 concept들이 활용되었는지를 결정하는 positional 임베딩, E^{type}는 v_r과 concept retirever를 통해 검색된 concept을 구별하기 위한 type 임베딩입니다. 디코더는 일반적인 트랜스포머 디코더와 같은 구조로 크로스 어텐션, FFN으로 구성됩니다.
RAF는 위의 과정을 통해 시각적 특징을 강화합니다. 즉, 시각적 특징을 설명하는 verbalized concepts(명사)를 생성하고 시각적 특징을 융합하여 coarse와 fine 레벨의 정보를 모두 합한 강화된 시각적 특징을 얻는 모듈이 RAF입니다.
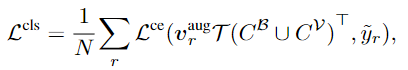
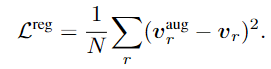
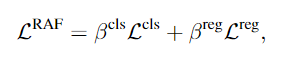
다른 수식은 직관적이지만, 분류 함수가 좀 어렵게 생겼는데(?) y_r은 pseudo region proposal이고, v^{aug}_rT(C^B \cup C^V)는 위의 Figure 2. (c)의 l^{aux}_r입니다. L^{reg}는 정규화 함수로 증강된 특징에 의해 모델이 과적합되는 것을 방지하고 일반화 성능을 올리기 위해 사용합니다.
Experiments
저자는 RALF 모델을 COCO, LVIS두 데이터셋에서 실험했습니다. OVOD에서 COCO는 48개의 base category와 17개의 novel category로 설정합니다. 여기서 novel category는 학습 시에는 레이블로 주어지지 않지만, Inference 단계에서 추가되어 OVOD를 수행합니다. LVIS는 866개의 base category와 337개의 novel category로 구성됩니다. 저자는 RAF 모듈에서 LLM으로 GPT3을 사용했고, 객체 검출기의 backbone으로는 ResNet50을 사용하는 Faster-RCNN을 사용했습니다. 저자는 RAF 모듈의 학습을 위한 region proposal로 OADP, Object-Centric-OVD, Det-Pro로 baseline을 사용했습니다. 세 region proposal 방법 모두 기존 연구들로 현재 성능이 좋은 세 모델을 baseline 및 backbone으로 삼은 것 같습니다. 여튼 세가지 region proposal에 따라 마지막에 출력하는 로짓의 범위가 다르기 때문에 앙상블 방법 또한 다릅니다.
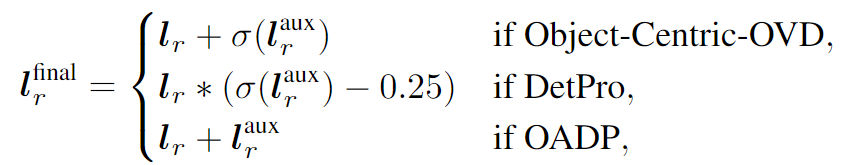
각 방법론에 따른 앙상블 방식은 다음과 같습니다. \sigma는 sigmoid 함수를 의미합니다.
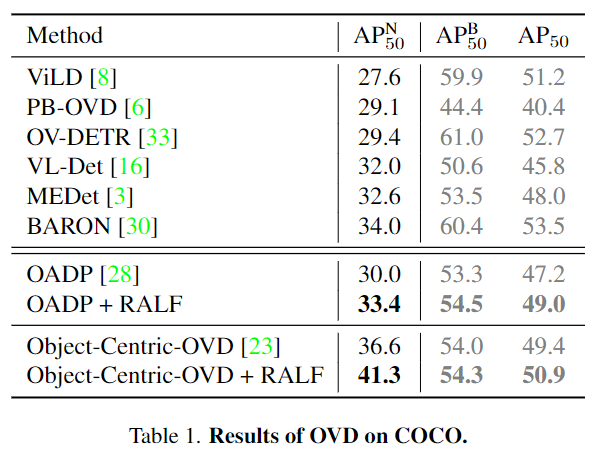
AP^N, AP^B는 각각 novel 카테고리, base 카테고리를 의미합니다. COCO에서 저자는 Object-Centric-OVD에 RALF를 plugged in했을 때(합해서 사용했을 때) SOTA를 달성했으며 novel 카테고리에서만 성능이 오른 것이 아니라 base 카테고리의 성능 또한 올랐습니다. OADP에 적용시켰을 때에도 유의미하게 성능이 올랐음을 저자는 강조하고 있습니다.
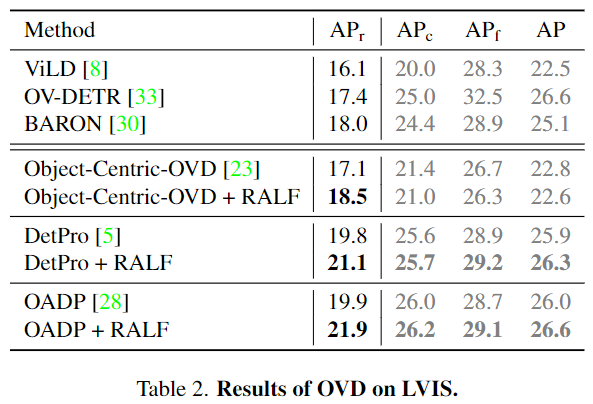
AP_r, AP_c, AP_f는 각각 rare, common, frequent로 클래스의 등장 빈도에 따은 AP입니다. OVOD에서 AP_r이 novel 카테고리로 활용됩니다. LVIS에서는 저자가 RALF 방법론의 성능을 증명하기 위하여 Det-Pro를 추가적으로 실험했습니다. Object-Centric-OVD에서 AP_r을 제외한 다른 AP는 오히려 성능이 약간 안좋아지기는 했지만, AP_r의 성능은 2AP나 올랐고 OADP와 DetPro에서는 모두 성능이 크게 올랐음을 강조하고 있습니다.
Ablation Study
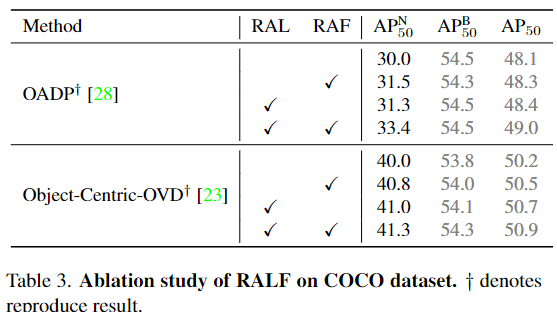
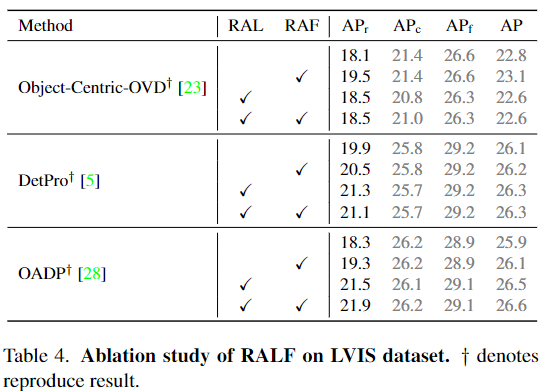
저자가 제안하는 방법론인 RAL과 RAF에 대해 ablation을 진행했고, RAL은 COCO의 base 카테고리에 대해서도 성능저하가 일어나지 않는 좋은 일반화 성능을 가지고 있고, LVIS에서는 base 카테고리들은 약간 성능이 낮아졌지만, novel 클래스에서는 유의미하게 성능이 올랐음을 저자는 강조하고 있습니다. RAF의 경우에는 모든 baseline에서 성능이 올랐으며 기존 카테고리들에 대한 성능도 유지됨을 강조하고 있습니다.
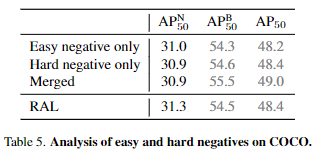
Table 5.의 실험은 hard negative와 easy negative를 다루는 방식에 따른 성능으로 ‘Merged’는 RAL과 다르게 easy와 hard를 구분짓지 않고 더해서 실험한 성능입니다. 아무래도 OVOD task는 novel 카테고리에 대한 검출기 성능을 올리는 것이 목적이기에 RAL 방법이 기존 카테고리에서는 성능이 낮아져도 novel 카테고리의 성능이 올랐기에 좋은 방법이라고 저자는 말하고 있습니다. 근데 개인적으로는 성능의 상승, 하락 폭을 봤을 때 그냥 Merged가 성능이 더 좋은 것 같아 보입니다. 성능을 보니 OADP에 RAL을 적용했을 때의 성능으로 실험 결과를 보여주고 있는데 Table 5.에서도 baseline 성능을 추가해줬으면 좋겠네요.
개인적으로 각 RAL 혹은 RAF의 ablation뿐만 아니라 RAL 모듈에서 유사성 점수의 분산을 기반으로 어휘를 필터링할 때와 하지 않을 때의 비교라거나 RAF 모듈에서 LLM의 프롬프트를 다르게 했을 때의 실험과 같이 각 RAL과 RAF 내의 여러가지 방법들에 대한 ablation이 있을 줄 알았는데 그냥 RAL과 RAF 모듈만 ablation하고 넘어가서 아쉬웠습니다. 그래서 Supplementary를 찾아보니 손실함수 내 하이퍼파라미터 \lambda에 따른 비교와 다른 하이퍼파라미터, vocabulary의 사이즈의 비교만 존재하고 모듈 내 방법들의 실험결과는 없어 조금 아쉽습니다.

마지막으로 RALF의 정성적 결과와 함께 저자는 RALF가 여러가지 방법론에 쉽게 더할 수 있고, base 카테고리의 큰 성능 하락 없이 novel 카테고리의 성능을 개선시킬 수 있는 일반화 성능이 좋고 범용성이 좋은 방법이라고 강조하며 논문을 마칩니다.
감사합니다.
안녕하세요 성준님 좋은 리뷰 감사합니다.
Augmented visual Features (RAF)에서 질문이 있습니다. Fig4의 과정을 살펴보면 시각적 특징 vr 과 concept 임베딩 H에 대해 코사인 유사도를 계산하여 가장 관련성이 높은 k개의 concepts를 반환한다고 설명해주셨습니다. 그런데 시각적 특징 벡터 vr 과 LLM 모델을 거친 텍스트 벡터 H는 서로 다른 도메인에서 추출된 특징이므로 코사인 유사도를 계산하는게 타당한 방법인지 의문이 생겼습니다. 코사인 유사도는 벡터 간의 유사성을 측정하는데 일반적으로 사용되는 방식인데 혹시나 서로 다른 도메인에 대해서 추출된 벡터들의 유사성을 측정하는 기법이 추가적으로 있을까요?
감사합니다.
안녕하세요 의철님 좋은 댓글 감사합니다.
RAF 모듈에 따로 서로 다른 도메인을 맞춰주는 constrastive learning등의 방법은 소개되지 않습니다. RAL 모듈과 RAF 모듈 모두 plug-in 방식으로 사용되는 모듈로 기존에 존재하는 OVOD 방법론에 추가하여 성능을 개선하는 모듈입니다. backbone으로 사용하는 OVOD 방법론에서 시각적 특징과 텍스트 특징이 이미 align이 되어있음을 가정하고 사용하기에 추가적인 도메인을 맞춰주는 과정을 포함하지 않고 있는 것으로 판단됩니다.
감사합니다.
안녕하세요. 성준님!
좋은 리뷰 감사드립니다.
OVOD란 테스크에 대해서 궁금했고, 앞으로 저희 팀에서 진행할 2.5D 디텍션에서 최종 목표를 OVOD로 보고 있어서
해당 리뷰를 관심있게 읽어보았던 것 같습니다.
아직 해당 분야에 대해서 논문을 읽어보지 않은 터라, 기본적인 배경지식에 대한 질문이 좀 많습니다… 하하
(1) Introduction 부분에서 “더 나은 alignment를 위해 Knowledge Distillation과정에서 image-level이 아닌 region-level로 단를 매칭시키려고 노력했습니다.”라고 말씀해주셨는데요. 여기서 말하는 alignment가 의미하는 바가 무엇인지, 또한 이미지 레벨이 아닌 region level 매칭을 하는 것이 무엇을 의미하는 것인지 궁금합니다.
(2)Figure 2.의 inference시 출력으로 나오는 최종 로짓이 의미하는 바가 디텍션 결과가 되는 것인가요?
(3) 해당 부분에 대한 이해가 불완전해서 옳은 질문을 하는 것인지 모르겠지만 ㅠ.
뭔가 손실함수 부분에서 회귀 손실함수쪽의 수식을 통해서 저자의 의도를 이해 해보았을 때, VLM보다 상대적으로 작은 모델인 [RPN+Crop+Encoder]구조를 띄는 모델이 예측하는 v_r이 VLM을 이용해서 verbalization을 통해 강화된 v_{r}^{aug}가 유사해지도록 하는 것으로 VLM로 부터 작은 모델로 Knowledge Distillation이 일어난다고 이해했는데 맞나요? 결론적으로 RALF를 다른 OVOD 모델에 플러그 인을 함으로서, 해당 모델이 VLM과 유사한 표현력을 지니는 특징을 뽑을 수 있게 되는 것인가요?
감사합니다.
안녕하세요 현석님 좋은 댓글 감사합니다.
image-level이 아닌 region-level로 단어를 매칭시킨다는 것은
1. Object Detection의 경우 이미지 내에 있는 객체를 검출하고 분류하는 것을 목표로하는 task입니다. 저자가 말하는 region은 이미지 내에 객체가 존재할 수 있는 지역으로 단순하게는 bounding box라고 생각하시면 될 것 같습니다. Object Detection task의 특성상 이미지 전체에 집중하여 이미지를 분류하는 것이 아닌 이미지 내 특정 region(객체가 있는 지역)을 분류하므로 전체 이미지의 coarse한 정보가 아니라 이미지 내 region의 fine-grained 정보에 align을 맞추는 것을 목표로 한다는 것을 의미합니다. align을 맞춘다 혹은 alignment의 사전적 의미는 정렬인데 여기서는 클래스를 나타내는 텍스트의 정보와 region의 시각적 특징이 같은 임베딩 공간에 매핑한다로 의역하시면 좋을 것같습니다.
2. 최종 로짓은 다른 검출기의 출력과 마찬가지로 예측 박스의 좌표, 객체의 클래스를 나타내는 로짓입니다(eg., {class, x1, y1, w, h}).
3. 우선 해당 손실함수는 현석님이 생각하신 것과 반대로 v_r^{aug}를 v_r에 가까워지도록 유도하는 손실함수 입니다. 논문의 말을 인용하면 “We encourage augmented visual feature v_r^{aug} to similar to the original visual feature v_r using regularization loss Lreg”이라고 말하는데, 이는 데이터 증강을 이용한 정규화에서 자주 사용되는 방식으로 모델이 원본 데이터v_r과 증강된 데이터 v_r^{aug}에서 일관된 출력을 생성할 수 있게 해 결국 모델이 데이터의 특징을 더 잘 이해할 수 있게 하고 다양한 데이터에 대해 일관된 출력을 생성해 과적합을 방지, 일반화 성능이 향상되는 방향으로 학습되도록 유도하는 정규화함수로 이해해주시면 될 것같습니다. PS. 제가 L_reg에 대한 설명을 본문에서 하지 않았네요. 본문에도 내용을 추가해두었습니다.
감사합니다.