추천 독자
Active Learning 연구에 관심이 있으며, 이를 Object Detection 연구로 확장하고 싶은 사람.
Contribution
- Generalized Method
제목에도 나타났듯이 Plug and Play 가능한 방법론으로, 다양한 object detection architectures에 적용이 가능하며, 2-stage 방법론(Faster R-CNN), 1-stage 방법론(RetinaNet, SSD), anchor-free 방법론(FCOS, ATSS, DDOD)에 성공적으로 적용이 가능함을 실험을 통해 보였음. - Performance
COCO 데이터셋과 Pascal VOC 데이터에서 기존 Active Learning for Object Detection 방법론 대비 높은 성능을 보임.
사전지식
# Active Learning:
Active Learning은 기계 학습의 한 방법론으로, 학습 중인 모델이 가장 유용하다고 판단하는 데이터를 선택하여 학습에 활용하는 접근법이다. 이는 특히 학습 데이터 구축의 효율성을 높일 수 있는 효과적인 방법이다. 특히 Pool based Active Learning은 레이블이 없는 데이터 풀(Unlabeled Pool)에서 모델의 학습 성능을 가장 효과적으로 높일 수 있는 샘플을 예측하여 학습에 사용함으로써, 최소한의 데이터로 최대의 성능을 끌어내는 것을 목표로 한다. 이때, 성능을 효과적으로 높일 수 있는 데이터셋은 High Uncertainty와 Diversity 기반으로 정의된다. High Uncertainty 데이터가 고가치인 이유는, 모델이 해당 데이터에 대한 예측이 불확실(uncertainty)하므로 해당 데이터에서 학습할 정보가 많을것이라는 가정이 있다. 반면 Diversity 기반으로 가치를 산출하는 것은 전체 데이터의 분포를 대표할 수 있는 데이터를 산출하기 위한 것으로, 분포 기반 선출(Diversity based Sampling)이라고 불린다.
Active Learning의 기본 프로세스는 다음과 같다:
- 초기 학습 데이터: 초기에는 소량의 라벨이 지정된 데이터가 주어짐
- 모델 학습: 주어진 라벨 데이터로 초기 모델을 학습
- 데이터 선택: 모델이 예측한 결과 중에서 가장 불확실하거나 데이터 셋을 대표할 수 있는 샘플을 선택
- 레이블 요청: 선택된 샘플의 레이블을 전문가(오라클)에게 요청
- 반복: 새롭게 라벨이 지정된 데이터를 포함하여 모델을 재학습시키고, 이 과정을 반복
# Active Learning for Object Detection:
Active Learning은 Classification 테스크에 집중해서 연구되고 있었다. 따라서 기존의 방법론은 Object Detection data의 특징인 Multi-instance에 대한 대응을 주로 다뤘다. 소개하는 연구는 Localization과 Classification을 동시에 다루며 예측의 최종값인 bounding box와 예측의 확신도를 이용해 가치 평가를 진행하기에 다양한 architecture에 plug and play 형식으로 동작할 수 있다는 특징이 있다.
제안점
해당 논문의 제안 지점은 Object Detection Task에서 데이터 가치를 산출하는 방법이다. Plug and Play를 위해 네트워크에 의존적인 Loss, gradient, feature map이 아닌, detection 결과를 활용해 가치를 산출하였다. 제안하는 방법은 Plug and Play Active Learning(이하, PPAL)이다. 해당 방법론은 아래의 Figure 1에서 확인할 수 있듯이 2 단계로 이루어져 있다. 1단계로 제안하는 Difficulty Calibrated Uncertainty Sampling(DCUS)를 통해 Pool에서 예측의 불확실성이 높은 데이터를 선별하는 Uncertainty-based Sampling(불확실성 기반 샘플링)을 진행하고, 1단계에서 선출한 후보를 기반으로 Category Conditioned Matching Similarity(CCMS)로 데이터 간의 유사도를 산출한 공간에서 대표성을 띄는 데이터를 선별하는 Diversity-based Sampling(분포기반 샘플링)을 진행한다.
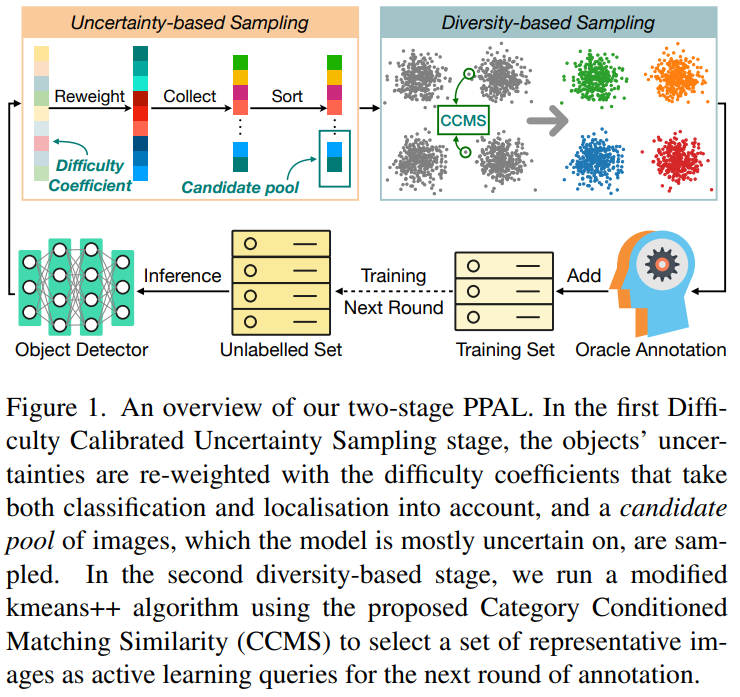
# Stage1: Uncertainty-based Sampling
*위 글에서 <<높은 난이도=High Uncertainty=높은 불확실성=어려운 데이터=고가치 데이터>>은 동치로 이해하시면 됩니다
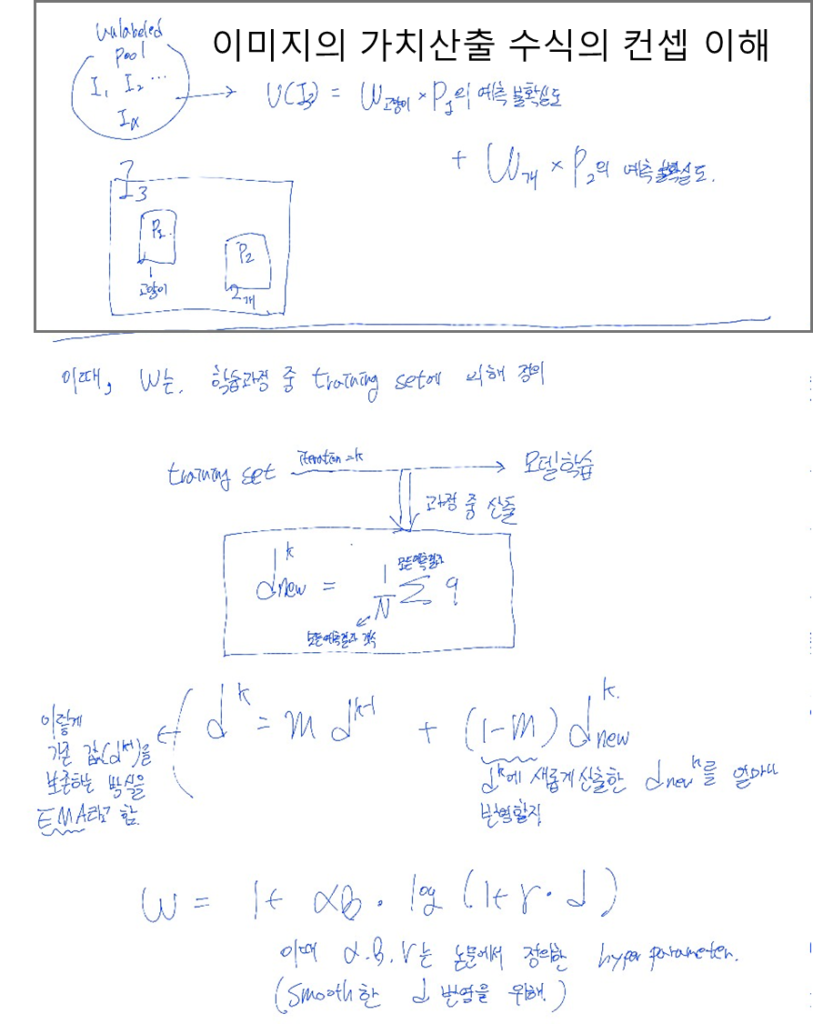
Stage1은 데이터의 *난이도를 고려해 어려운 데이터를 Stage 2의 후보 데이터로 보내기 위한 단계이다. 이미지의 Uncertinty를 산출하는 방식은 아래 도식1과 같다. K번의 학습 Iteration 중 예측을 활용해 클래스 별 어려움 정도(w)를 정의하고, 해당 지수를 활용해 라벨이 없는 데이터 풀(Unlabeled Pool)에서 이미지(I)의 가치(U( · ))를 도출한다. 이때, K 번의 Iteration 동안 학습 불안정성으로 인한 문제를 방지하기 위해 최종 어려움 정도(w)를 학습 전반에서 도출된 어려움 정도를 고려하도록 exponential moving average (EMA) 업데이트 방식을 이용한다.

아래는 도식1의 수식을 conceptual하게 이해하기 위한 보충 설명이다.
도식1의 방식으로 Stage1에서는 Localization과 Classification을 모두 고려하여 Uncertainty Score를 계산하였고 High Uncertainty 순으로 정렬된 데이터 중 예산(최종으로 선별할 데이터 갯수)에 δ배수 만큼 선택하여 Stage2의 후보데이터로 넘어간다. 본 논문에서 δ=4 이며, PPAL을 사용시 3<δ<6로 설정할 을 권고한다.
# Stage 2: Diversity-based Sampling
Diversity Sampling은 unlabeled dataset이 real world의 데이터 분포를 따른다는 가정이 있다. 해당 가정 하에, 전체 unlabeled dataset의 분포를 대표할 수 있는 최소한의 subset을 선별하는 것이 Diversity Sampling의 목표이다. PPAL은 unlabeled data를 나타내는 공간을 새롭게 정의했다고 볼 수 있다.
PPAL에서는 데이터를 나타내는 공간을 정의하기 위해 데이터간 유사도를 활용하였는데, 제안하는 유사도 산출방식은 Category Conditional Matching Similarity(CCMS)로, 하단 도식2의 우측 상단 그림과 수식 S( · )와 같다. 기존의 embeding feature을 활용하여 image-level의 유사도(L2 norm, Cosine)를 산출하는 방법과 다르게 instance-level의 유사도 계산 방식을 제안하였다. 두 이미지의 예측 instance에서 같은 class로 예측한 instance 간의 embeding feature 유사도를 cosine 유사도를 활용해 산출하고, 이를 모두 평균한 것이 S( · )라고 이해하면 된다. 이렇게 정의한 공간을 활용해 최종 데이터를 산출하는 방식은 도식2의 붉은 박스와 가장 오른쪽의 수식과 같다. Stage2의 후보로 입력된 데이터 집합 H의 subset Q’들 중, 이미지간 유사도가 가장 낮은 집합 Q를 하나 선별하는 것이다. 이때 H에서 서브셋 Q’를 정의하는 방법은 k-Center-Greedy를 활용했다.
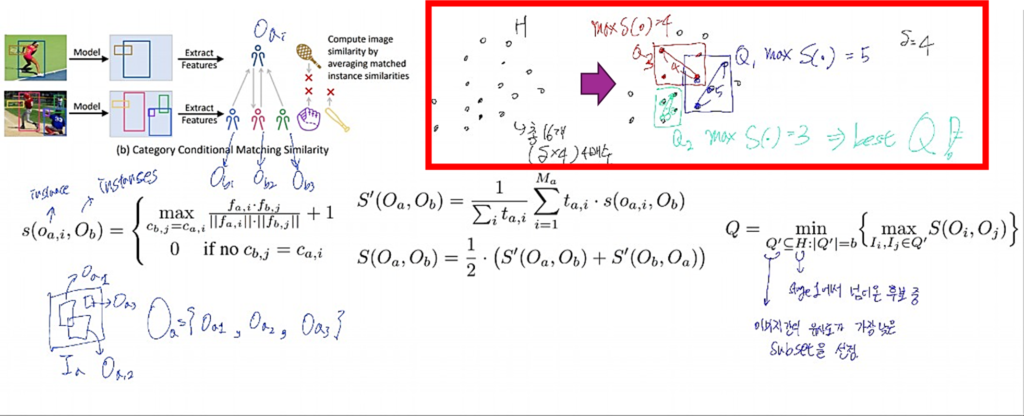
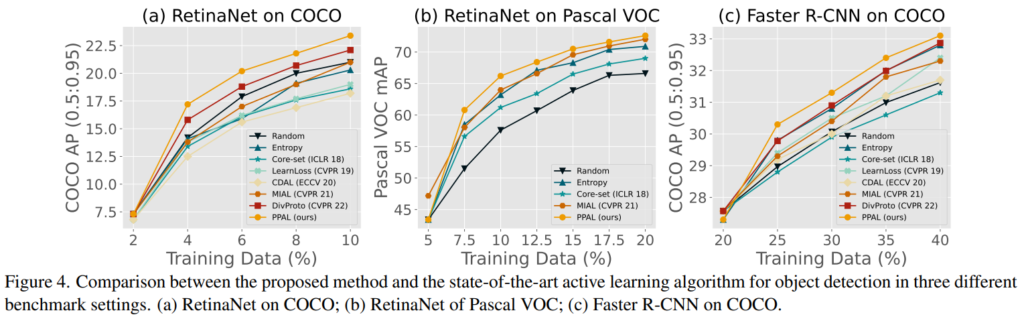
입증
Contribution에서 언급하였듯이 다양한 objet detection 구조에 적용하여 비교 방법론 대비 높은 성능 개선을 보였다. Pascal VOC와 COCO 데이터를 활용했으며 다양한 구조(Faster R-CNN, RetinaNet, SSD, FCOS, ATSS, DDOD)에 적용한 결과를 보였다. 모든 결과를 담기에는 글이 너무 길어질 것 같아, SOTA와 비교하기 위한 세팅에서 대표적인 실험의 결과만을 아래에 추가했다.
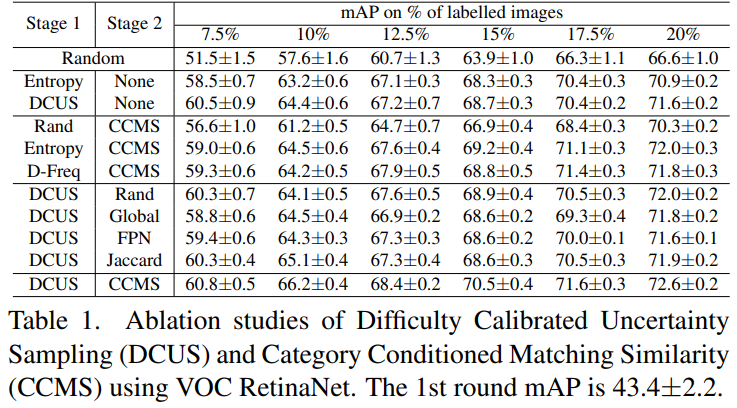
아래는 논문에서 제시한 ablation studies이다. Stage1과 Stage2의 효과를 보이기 위해 설계되었으며, 제안하는 Uncertainty scoreing 방식인 DCUS를 대체하기 위해 Random, Entropy,D-Freq(클래스 빈도수/GT 활용해 모든 training set 내의 class의 빈도수가 동일하도록 설계)를 비교하였다. 또한 제안하는 Diversity 계산 공간인 CCMS의 당위성을 증명하기 위해 Random과 Global(image level 유사도), FPN(강화된 Global/모든 feature pyramid layer의 image level 유사도 합산), Jaccard(이미지에서 예측한 카테고리의 유사도)를 비교하였다. 개인적으로 유사도를 활용한 공간 자체가 의미있으려면 Global, FPN, Jaccard가 모두 Rand보다 높은 성능을 보였어야 한다고 생각하는데, 그러지 않은점이 아쉽다. 이러한 아쉬운점을 저자도 보충하고 싶었는지, Why is CCMS better than global similarity? 라는 제목의 분석도 논문에 존재했다.
Why is CCMS better than global similarity?
아래는 CCMS가 global similarity보다 좋은 이유에 대해 시각적으로 보이는 그림이다. Detection box의 예측을 유사도 계산에 활용하면서 시각적이 아닌 의미론적으로 유사한 데이터를 고려할 수 있게 된 것이다. 4행의 야구관련 예시가 비교하는 유사도 방법론의 차이를 가장 잘 보여주고 있다. 수많은 후보 데이터 중 야구를 대표하는 데이터를 산출할 때 그라운드가 있는 모든 데이터를 고려하는 것이 아니라, 야구와 관련있는 데이터 중에서 대표성이 있는 데이터를 고가치 데이터로 선별하도록 설계하므로 카테고리 내에서 의미론적으로 대표성을 띄는 데이터를 선별 할 수 있게 된 것이다.

느낀점
Active Learning 연구를 Object Detection에 잘 확장한 논문 같다. 기존 방법론 Active Learning for Object Detection 연구 역시 훌륭하지만, Detection Task의 모든 요소를 고려해서 설계되었다고 하기 부족한 부분이 있었는데, 해당 연구는 간단한 방법으로 Object Detection Dataset의 특징인 multi-instance를 고려할 뿐 만 아니라, Localization Task까지 고려할 수 있도록 설계되었다. 개인적으로는, 기존의 Image Classification을 위해 설계된 CNN 구조를 Semantic Segmentation으로 확장한 FCN[Paper]연구의 느낌을 받았다. Object Detection Task로 확장할 때 베이스라인으로 가장 먼저 고려하고 싶은 논문이다.
아쉬운점은 Classification에 집중하여 설계된 기존 Active Learning 방법이 feature map 등을 사용해 좋은 성능을 보인 방법론이 있다. 이러한 방법론을 해당 연구에 확장할 수 있는 방법이 잘 떠오르지 않는다.