제가 이번에 리뷰할 논문은 object-centric learning이라는 분야에서 중요한 논문으로 여겨지는 논문입니다. 먼저 object-centric learning이란, 실제 환경에서 영상에 해당하는 장면은 여러 객체들의 composition이라는 컨셉을 가져와서 물체들에 대한 표현을 학습하는 분야입니다. 이러한 object-centric learning은 영상을 변형하는 등의 task에 적용가능하며, 객체에 대한 표현을 학습할 수 있다는 것은 영상 내의 특정 객체의 자세를 추정하는 6D Pose Estimation에도 도입이 가능할 것이며, 그 외에도 다양한 테스크에서 영상 내 객체에 대한 이해라는 관점에서 활용 가능할 것이라 생각하여 리뷰하게 되었습니다.
Abstract
영상에 대한 object-centric representation을 학습하는 것은 low-level의 특징으로 효율적이고 추상적인 추론을 가능하도록 하지만, 기존 방식들은 대부분 객체의 compositional한 특성을 포착하기보다도 영상으로부터 분포를 학습하였습니다. 해당 논문은 Slot이라는 객체에 대한 표현 방식을 학습하기 위한 slot attention을 모듈을 제안하며, 이러한 slot은 task-dependent한 추상적인 표현으로, slot간의 교체가 가능하며 여러 객체들에 대한 표현은 조합(composition)이 가능하다는 특성이 있습니다. 저자들은 unsupervised 방식의 객체 탐지와 supervised 방식의 property prediction 태스크에서 실험을 통해 slot attention이 unseen객체로의 일반화가 가능함을 실험적으로 입증하였습니다.
Introduction
Object-centric representation은 시뮬레이션 시스템이나 visual reasoning 등 다양한 응용 태스크에서 효율성과 일반화를 향상시킬 수 있는 잠재력을 가지고 있으나, object-centric learning을 위한 데이터나 모델 구조를 학습하기 위한 별도의 네트워크 구조가 요구되어 많은 연구들이 object-centric learning을 간과하는 경우가 많았다고 합니다.
이러한 문제를 해결하기 위해 본 논문에서는 Slot Attention 모듈을 제안하여 영상에 대한 representation(논문에 따르면 perceptual representations이라는 표현을 쓰고, CNN의 출력이자 Slot Attention의 입력되는 feature를 의미합니다)과 객체에 대한 표현인 slot을 분리하였다고 합니다. Slot Attention은 반복적인 attention 매커니즘을 통해 slot이라는 벡터를 출력하게 되고, 이렇게 생성된 slot은 특정 객체나 속성에 특화되지 않도록 하여 미학습 객체에도 일반화가 가능하다고 합니다.(저자들은 slot이 어떤 객체라도 바인딩 될 수 있는 공통의 표현 형식이라고 표현합니다.)
또한, Slot Attention은 간단하고 쉽게 네트워크에 포함 가능하며 본 논문에서는 Image Reconstruction과 Set Prediction이라는 다운스트림 task를 통해 모듈의 활용 가능성을 보였습니다.
본 논문의 contribution을 정리하면 다음과 같습니다.
- CNN을 통해 구한 perceptual representation과 object-centric한 representation 사이의 Slot Attention 모듈 제안
- unsupervised 방식의 객체 탐지에 적용하여 SOTA와 유사하거나 더 좋은 성능을 달성하였으며, 메모리 효율 및 학습 속도를 높임
- Slot Attention 모듈이 객체의 segmentation을 위한 GT를 사용하지 않고 attention 매커니즘을 통해 개별 객체에 대한 표현이 가능하도록 하는 학습 방식임을 실험적으로 입증함
Methods
아래의 Figure 1은 Slot Attention 모듈에 대한 도식화와 object discovery 및 Set prediction에 attention 모듈을 적용한 네트워크 구조를 나타냅니다.
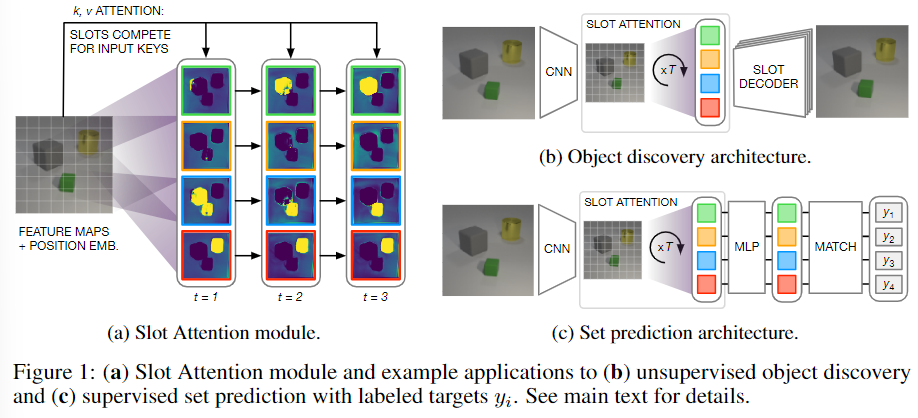
a. Slot Attention
Slot Attention이 해당 논문에서 제안된 모듈로, N개의 입력 feature 집합(CNN의 output) inputs \in \mathbb{R}^{N⨉D_{inputs}}을 객체를 표현할 수 있는 Slot이라는 K개의 출력 vector 집합으로 매핑하는 모듈입니다. Slot Attention은 반복적인 attention 매커니즘으로 매핑을 수행하며, random하게 초기화 된 slot을 각 iteration t=1, ... ,T 마다 입력 feature의 특정 부분을 바인딩한다고 합니다. 이때, 초기화는 가우시안 분포로부터 랜덤하게 샘플링을 하였으며, 이를 통해 test 과정에 slot의 수가 다른 경우로도 일반화가 가능하였다고 합니다. 또한 각 iteration마다 slot은 Soft max 기반의 방식을 통해 입력의 일부를 표현하였으며 반복적으로 표현을 업데이트합니다.

위의 Algorithm 1은 Slot Attention에 대한 pseudo code로, input을 D_{slot} 차원을 가지는 K개의 slot으로 매핑하는 과정입니다. CNN으로 구한 input feature와 가우시안 분포에서 랜덤으로 초기화하여 K개의 slot을 설정한 뒤 Attention 매커니즘을 이용해 input feature와 slot을 매핑합니다.
- 입력에 대해 normalization을 적용
- 입력에 가중평균을 적용하여 slot에 집계 (pseudo clode의 7,8번 줄과 아래의 식 (1),(2))
- 학습된 GRU를 이용하여 slot을 업데이트
- residual MLP를 통해 GRU의 출력을 변형
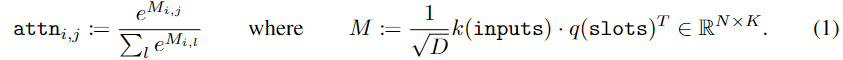
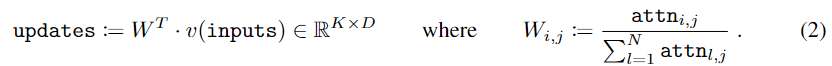
여기서 GRU는 LSTM에서 발전된 RNN 프레임워크로, LSTM보다는 더 간단한 구조입니다. 또한, 저자들에 따르면 residual MLP을 통해 GRU의 출력에 변형을 줄 경우 성능이 개선된다는 것을 발견하여 각 slot마다 독립적으로 적용하였다고 합니다.
b. Object Discovery
slot attention은 입력 feature를 벡터 집합으로 변환하므로 autoencoder 구조의 unsupervised object discovery의 encoder로 활용 가능하며, autoencoder는 이미지를 slot으로 표현하고 이를 종합하여 다시 이미지 공간으로 decoding하여 원본 입력 영상을 복원하는 방식으로 학습 가능합니다. 즉, slot은 autoencoder의 encoder와 decoder 사이의 representation 역할을 하며, decoder는 각 slot이 이미지의 일부만 복원하도록 한 뒤, 전체를 결합하여 재구성된 이미지를 생성하도록 합니다. 다음은 object discovery를 위한 네트워크의 구조입니다.
- Encoder
- CNN 백본과 Slot attention으로 구성
- Decoder
- 각 Slot은 spatial broadcast decoder^{[1]}를 이용하여 개별적으로 2D grid로 디코딩 됨
- 각 그리드는 CNN을 통해 WxHx4 크기의 이미지로 디코딩됨(WxH는 이미지의 폭과 높이, 4채널은 RGB와 alpha mask로, alpha mask는 여러 slot들의 표현을 decoding 한 결과를 종합할 때 사용)
- Softmax를 이용하여 slot 전체에 대한 alpha mask를 정규화 한 뒤 가중치로 사용하여 각 slot들을 하나의 RGB 이미지로 결합
[1]Nicholas Watters, Loic Matthey, Christopher P Burgess, and Alexander Lerchner. Spatial broadcast decoder: A simple architecture for learning disentangled representations in VAEs. arXiv preprint arXiv:1901.07017, 2019
c. Set Prediction
본 논문에서는 입력 이미지와 장면의 물체를 설명하는 예측 대상(target)이 주어졌을 때 이 예측 대상을 찾습니다. 이때 예측 대상의 순서가 랜덤하므로 기존의 방식으로는 임의의 순서에 대응하기 위해 K!개의 representation이 요구되었다고 합니다. 그러나 Slot Attention에서는 Slot의 출력이 무작위이며(특정 슬롯이 정해진 객체나 타입을 표현하는 것이 아님!) 입력 순서와 독립적이기 때문에 이러한 문제를 해결할 수 있었다고 합니다. 다음은 set predictiond을 위한 네트워크의 구조입니다.
- Encoder
- CNN 백본과 Slot attention으로 구성
- Classifer
- 각 slot에 MLP를 적용하여 class를 예측함
- 헝가리 알고리즘을 통해 예측된 class와 label을 일치시킴
Experiemtents
본 논문은 Slot Attention 모듈을 평가하기 위해 2가지 다운스트림 태스크에서 평가를 수행합니다.
Datasets
먼저 Objecft Discovery 실험에 사용한 데이터 셋은 CLEVR(with Mask), Multi-dSprites, Tetrominoes3가지 입니다. CLEVR(with Mask)는 CLEVR 데이터 셋에 segmentation을 위한 mask 정보가 추가된 데이터로 7만장을 학습 데이터로 사용합니다. 이때, CLEVR6은 CLEVR 데이터 중 6개 이하의 객체들로 구성된 영상만으로 재구성된 데이터 셋, CLEVR10은 원본 데이터 셋을 의미합니다. Multi-dSprites와 Tetrominoes는 6만장의 데이터를 학습하며, 320개의 test 데이터로 평가를 수행합니다.

Set Prediction에 이용한 데이터는 원본 CLEVR 데이터로 렌더링된 객체의 70K를 학습, 15K를 validation으로 사용하며 각 이미지는 3~10개의 객체를 포함하도록 구성됩니다. 영상 내 객체에 대한 속성(위치, 모양, 재질, 색상, 크기) 정보가 주어집니다.

Object Discovery
기존 연구를 따라서 decoder로 생성한 alpha mask와 GT segmentation 마스크에 대해 평가를 수행하며, 평가 지표는 Adjusted Rand Index (ARI) score를 사용합니다. ARI는 cluster 사이의 유사성을 측정하는 점수로, 일치할 수록 1에 가까운 값을 가지게 됩니다.(alpha 마스크로 구한 특정 객체에 대한 마스크가 segmentation 마스크와 일치하는 지를 평가한다고 생각하시면 될 것 같습니다.)

- 위의 Table1과 Figure 2는 정량적 결과로, 당시의 SOTA 방법론과 비교했을 때 성능이 더 좋다는 것을 확인할 수 있습니다.(1행이 저자들이 제안한 방식)
- CLEVR6을 학습하기 위해 IODINE 방법론의 경우 16GB의 RAM으로 이루어진 V100 4개를 사용하였으나 저자들이 제안한 방법론은 1개만 이용하였으며,
- 8개의 V100을 병렬적으로 이용할 경우 IODINE는 약 7일이 소요되고 저자들이 제안한 방식은 약 24시간이 소요되었다고 합니다.
- 이를 통해 학습 시간과 메모리가 효율적임을 어필합니다.
- Slot Attention은 학습 과정에 3번의 iteration을 사용하였으며, 추가로 test 과정에 iteration을 증가시킬 경우의 모델의 일반화 성능을 평가하였으며, 이에 대한 결과를 Figure 2로 나타내었습니다. 실험 결과를 통해 iteration 수가 늘어날 수록 성능이 개선됨을 보였습니다.
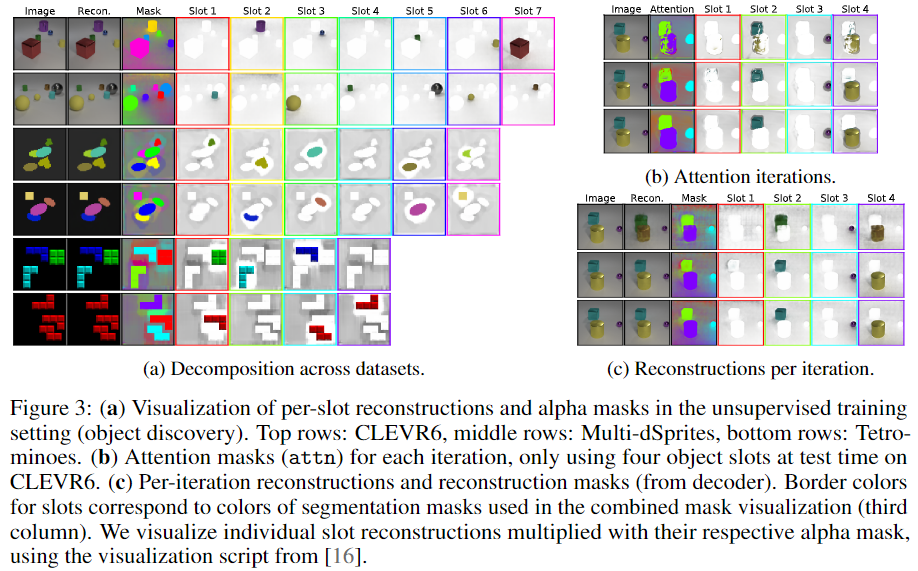
- 위의 Figure 3은 발견된 객체에 대한 segmentation결과를 시각화 한 것입니다.
- 결과를 보시면 객체의 수가 slot보다 적을 경우 다수의 slot을 비워두고 배경만 학습하는 것을 확인하실 수 있습니다. (해당 결과가 굉장히 인상적이였는데, 해당 방법론이 객체를 구분할 수 있다는 점을 실험적으로 보인 것이라고 생각합니다..)
- 오른쪽 그림들은 iteration마다 slot에 대한 attention과 reconstruction 결과를 시각화 한 것으로, 첫번째 iteration에서는 여러 객체가 slot에 매핑되어있으나 iteration이 증가할 수록 특정 객체에 대해서만 매핑이 된 결과를 확인하실 수 있습니다.

- 추가로 slot attention이 색상 정보에만 의존하는 것인 지 확인하기 위해 입력 영상을 greyscale 이미지로 변경하여 실험을 진행하였으며, Figure 4를 통해 색상 정보에만 의존하지 않는다는 것을 확인하였습니다.
Set-Prediction
기존 연구를 따라 object detection에서 사용하는 AP(Average Precision)를 이용하여 평가를 수행하였으며, 이때 distance threshold 내에 정확히 동일한 속성을 가진 객체가 존재해야 올바른 예측으로 판단한다고 합니다.
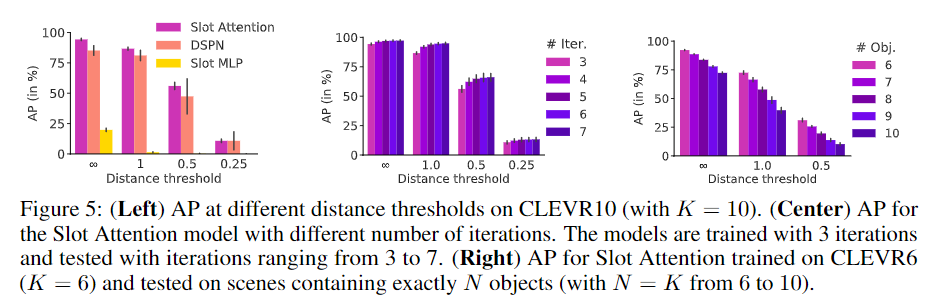
- 왼쪽 그래프는 CLEVR10 데이터에서 다양한 distance threshold에 대한 AP로, 기존 방법론 대비 비슷하거나 개선된 성능을 나타냅니다.
- 가운데 그래프를 통해 Test과정에 iteration 횟수를 늘릴 경우 성능이 향상됨을 확인할 수 있습니다.
- 오른쪽 그래프는 CLEVR6 데이터로 학습한 뒤, 더 많은 객체가 존재하는 영상에 대해 평가를 수행한 결과로, 객체 수가 증가할 수록 성능이 저하되는 경향이 있다는 것을 확인하실 수 있습니다.
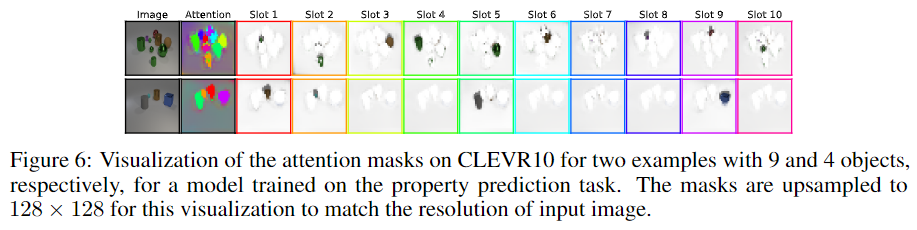
- Figure 6은 각 slot의 attention map을 시각화 한 것으로, 각 slot마다 서로 다른 객체에 대해 표현하고 있다는 것을 확인하실 수 있습니다.
- 특히, 해당 방법론은 segmentation mask를 이용하지 않고 학습을 수행하였다는 점에서 GT mask 없이도 객체를 분할하여 학습이 가능함을 보입니다.
해당 방법론은 영상으로부터 객체를 표현하기 위한 representation을 구할 수 있도록 학습을 수행합니다. 해당 방법론의 경우 segmentation mask를 사용하지 않고도 특정한 객체를 표현할 수 있다는 것이 인상적이였으며, 영상 내 객체에 대한 정보를 추정하고자하는 다양한 task에서 객체에 특화된 특징을 표현할 수 있다는 점에서 활용 가능성이 높다고 생각되며, 해당 논문의 후속 연구들도 조금 더 공부해보려합니다..
안녕하세요. 이승현 연구원님. 좋은 리뷰 감사합니다!
세미나에서 봤지만, slot에 대해서 잘 이해가 가지 않는 부분이 있어 질문 드립니다. slot은 attention을 이용해 계산되므로 결국 학습의 대상이고, 학습을 하다 보면 아무래도 GT label에 쏠린 예측을 할 것 같은데, 어떻게 ‘특정 객체나 속성에 특화되지 않도록 하여 미학습 객체에도 일반화’ 할 수 있는 것인가요??
그리고 사전학습된 slot을 이용하면 open-world에서 unlabeled object를 검출할 수 있는 것인가요?
Slot의 알고리즘을 완벽히 이해했다면 해결되는 질문인것 같긴 한데, 이해가 쉽지 않네요…
감사합니다.
질문 감사합니다.
먼저, ‘특정 객체나 속성에 특화되지 않도록 하여 미학습 객체에도 일반화’가 가능하다는 내용에 대해 설명 드리겠습니다. K개의 slot이 특정 객체나 타입으로 사전에 정의되어있지 않으며, 학습 과정에서 임의의 slot이 임의의 객체를 표현하도록 학습되기 때문입니다. 이러한 점에서 영상에서 추출된 CNN feature를 low-level에서 표현하는 방식을 학습하고 이는 미학습된 객체가 주어져도 동일하게 작동하기 때문입니다.
또한, 두번째 질문은 앞서 답변드린 내용에 대한 연장선으로 보입니다. slot attention을 학습시켜 미학습 객체에서도 탐지를 수행하며 제가 이해한 바로는 (open-world라는 용어를 사용하지는 않았으나)open-world로 확장 가능하다는 것을 어필하는 것으로 이해하였습니다.
안녕하세요 이승현 연구원님 리뷰 잘 읽었습니다
“Slot Attention은 반복적인 attention 매커니즘을 통해 slot이라는 벡터를 출력하게 되고, 이렇게 생성된 slot은 특정 객체나 속성에 특화되지 않도록 하여 미학습 객체에도 일반화가 가능” 하다고 하셨는데,
slot attention 이 왜 어떤 객체라도 바인딩될 수 있는 공통의 표현 형식을 학습할 수 있는건가요?
그나저나 학습 데이터는 6만장인데, 평가 데이터는 320개…
이렇게 불균형한 분포를 보이는 이유가 따로 있나요…?
너무 적은 평가데이터셋 개수로 인해, 신뢰성 있는 평가라고 할 수 있을 지 의문이 생겨 질문드립니다.
마지막으로 지금 하고 계신 연구에 Object Centic Learning을 적용할 수 있으신가요?
질문 감사합니다.
‘slot attention 이 왜 어떤 객체라도 바인딩될 수 있는 공통의 표현 형식을 학습할 수 있는’ 것인지에 대한 답변을 드리자면, K개의 slot이 특정 객체나 타입으로 사전에 정의되어있지 않으며 학습 과정에서 임의의 slot이 임의의 객체를 표현하도록 학습되기 때문입니다. 즉, 사전에 정의되어있는 class의 객체가 아니더라도 작동 가능하게 됩니다.
데이터 셋의 경우는 해당 논문이 베이스라인으로 삼았던 논문인 IODINE[1]과 동일하게 세팅한 것으로 보입니다.
저는 Object-centric Learening이라는 것이 물체 자체에 대한 정보를 표현할 수 있고, 정해진 객체가 아닌, 임의의 객체에도 정보를 추정할 수 있다는 점에서 6D Pose Estimation에 적용이 가능할 것이라 생각하여 해당 컨셉을 도입해볼 계획입니다.
—–
[1]Klaus Greff, Raphaël Lopez Kaufman, Rishabh Kabra, Nick Watters, Christopher Burgess, Daniel Zoran, Loic Matthey, Matthew Botvinick, and Alexander Lerchner. Multi-object representation learning with iterative variational inference. In International Conference on Machine Learning, pages 2424–2433, 2019
안녕하세요 승현님, 좋은 리뷰 감사합니다. 일전의 세미나에서 완벽히는 이해되지 않았던 slot이라는 개념이 조금 와닿게 된 것 같습니다.
질문 사항이 몇 가지 있습니다.
1. 본 논문의 object discovery는 unsupervised 방법론끼리 비교한 것으로 이해했습니다. cluster 사이의 유사성을 확인하는 ARI라는 score가 그래서 사용된 것인지 궁금합니다.
혹시 unsupervised 와 supervised 방법론의 성능 차이를 비교한 실험도 있나요?
2. 학습된 GRU를 이용하여 slot을 업데이트 한다고 햇는데 이때 학습된 GRU는 무엇에 대해 어떻게 학습된 건가요?
3. 데이터셋의 객체 속성 GT는 영상 내 객체에 대한 속성(위치, 모양, 재질, 색상, 크기) 정보 5가지만 가지고 있는데,
이것이 물체 자체만 보면 visual적인 표현을 잘 함유할 수 있다고 생각이 들면서도, 해당 데이터셋이 가진 한계가 느껴지는 게 올려주신 데이터셋 예시만 봤을 땐 foreground와 background가 매우매우 명확하게 분류되어서(완전 전부 흰 단조로운 배경), fore & back-ground가 복잡하거나 잘 구분이 안 될 수도 있는 그런 challenge한 데이터셋은 아닌 것 같다고 판단이 듭니다. 혹시 그 당시 저자들이 이러한 부분에 대한 limitation이라던가 어떠한 언급은 없었나요?
slot이 정말 임의의 unseen 객체에 대한 표현력을 학습하여 어떤 물체든 잡는데에 contribution을 주려면 그런 전경과 배경에 대해서 단조롭지 않은 상황에서도 잘 판단해야될 것 같다는 생각이 들었습니다!
감사합니다.
질문 감사합니다.
1. 우선 이야기 하신대로, unsupervised 방식 뿐만 아니라, 해당 방법론은 slot이 임의의 객체에 대해서도 표현이 가능하다는 점에 집중하였기 때문에(slot이 특정 class를 표현하는 것이 아니며, 영상 내의 객체들을 구분하여 표현할 수 있다는 것을 보이고자 한 것으로 보입니다.) Clustering 평가 방식을 도입한 것으로 이해하였습니다. 또한, 논문에서 object discovery에 대한 supervised 방식은 하께 비교하지 않고 있습니다.
2. GRU는 LSTM의 변형으로, 더 간단하게 설계된 네트워크로, reconstruction된 결과를 통해 구한 loss를 업데이트 하는 과정에 함께 업데이트 되는 것으로 보입니다.
3. 데이터 셋이 단조롭기는 하지만 해당 논문이 2019년 논문으로 해당 분야의 초기 방법론으로, 데이터 셋이 단조로운 것에 대한 언급은 따로 하고 있지 않습니다.
안녕하세요, 좋은 리뷰 감사합니다.
object-centric learning이라는 건 결국 slot attention으로부터 feature를 representation을 하는 테스크라고 이해를 하였습니다.
Object Discovery 섹션에서 말씀하신대로, Auto encoder(AE)와 뭔가 컨셉이 겹치는 것 같은데요.
결국 AE도 복원을 한다는 컨셉이라 헷갈리네요.. 결국 attention map을 사용하는 것을 사용할 때 feature를 사용하는 건 동일한 거 같은데..
iteration 마다 다른 attention map을 여러 개 사용한다라는 게 가장 큰 차이점일까요? 제가 놓친 게 있는 것 같아 질문 남깁니다.
감사합니다.
질문 감사합니다.
AE도 복원한다는 컨셉이 동일하기는 하지만, 해당 방법론은 slot을 통해 특정 객체를 표현한다는 점이 특징이라고 생각합니다. 저자들도 직접적으로 feature를 이미지 reconstruction에 이용하기보다, 영상에 대한 representation과 객체에 대한 표현인 slot을 slot attention을 통해 분리하였다고 이야기하고 있습니다.
또한 iteration마다 다른 attention map을 사용한다는 게 차이점은 아니고, iteration마다 attention map을 이용하여 시각화해보니, 특정 객체에 집중되어있더라는 것을 보인 것으로 이해하시면 좋을 것 같습니다.