오늘도 마찬가지로 Online Continual TTA 분야의 논문으로 찾아왔습니다.
ICML 2024에 게재된 논문이고, 코드 정리가 되게 잘 되어 있어서 코드도 돌려볼 겸 선정하게 되었습니다.
(+ 저자가 한국인이네요.)
1. Introduction
초기 TTA 연구는 A domain에서 모델을 학습시킨 뒤 online 상황에서 B domain에 대해 추론 및 adaptation을 동시에 수행하도록 설계되었습니다. 다만 real-world 상황에서 모델이 마주할 수 있는 상황은 B에 한정되지 않죠. C, D, E 그리고 다시 B. 이런식으로 여러 domain들이 연속적으로 변화하게 됩니다.
이러한 연속적인 domain 변화에 잘 대응하고자 하는 연구 분야가 continual TTA 입니다. 이 중 on-device 상황에서 실시간으로 TTA를 수행하는 것이 online continual TTA 이구요. 제가 관심있어하는 분야입니다.
최근 online continual TTA 분야의 핵심적인 challenge 사항은 크게 아래 2가지로 정리 가능합니다.
i) forgetting problem
ii) computational efficiency
우선 forgetting 문제입니다. continual TTA에서 항상 거론되는 문제로, 지속적인 domain 변화에 맞춰 모델을 update 해나가는 과정 속 되려 기존 source trained knowledge를 까먹어 버리는 것입니다. 최악의 상황에서는 모델이 완전 구렁텅이(?) 로 빠져서 성능의 degradation이 엄청나게 발생하는 경우도 있습니다. 따라서 기존 지식은 적절히 유지하며 새로운 domain 에 대해 잘 적응해 나가는 그 balance를 잘 유지하는 것이 핵심입니다.
두번째는 뭐 당연한 소리지만, 아무래도 online TTA 연구 자체가 on-device 상황에서 많이 사용될 수 있는 기술이기에 계산 효율성을 고려해야 합니다.
이 2가지 문제와 adaptation 성능 사이의 trade-off 관계를 잘 고려하여 최적의 모델을 선정하는 것이 online continual TTA 의 핵심 사항이라 할 수 있습니다.
저자들이 intro figure에서 표현한 기존 연구들과 자신들의 차이점 및 장점에 대해서 살펴보겠습니다.
intro figure에 대한 자세한 설명은 없기에, 제 배경 지식으로 간단하게나마 설명드리겠습니다.
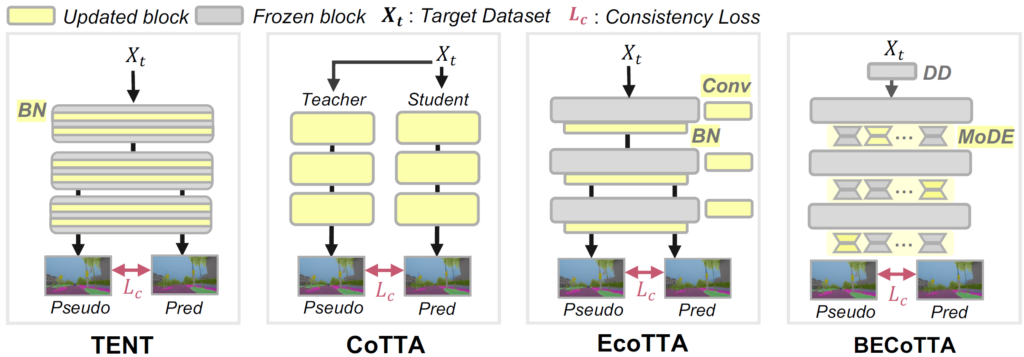
TENT
TTA의 baseline 격 논문입니다. test gt가 없는 상황 속에서 entropy minimization 전략을 채택하였죠. 또한 효율성을 위해 모델 전체가 아닌 BN layer parameter의 update만을 수행합니다. 하지만 이는 continual 상황을 고려하지 않았다는 문제가 있죠.
CoTTA
이름부터 Continual 이 들어갑니다. TENT 와 동일 저자이며, Continual domain shift 를 고려한 TTA 방법론을 제안하였죠. 안정성을 위해 mean teacher 구조를 채택하였고, catastrophic forgetting 이슈 해결을 위해 TTA 수행 도중 모델의 parameter 일부(약 1%)를 초기 상태로 restore 해 버리는 꽤나 극단(?) 적인 기법을 설계합니다. 이 restore 기법으로 얻는 성능향상이 꽤나 커서 개인적으로 놀랐습니다.
다만 CoTTA는 구조적으로도 알 수 있다시피 연산량이 매우 많습니다. Student와 Teacher 2개로 구성되어 있구요, 모델 전체 parameter를 update 하게 됩니다.
EcoTTA
Efficient CoTTA, 줄여서 EcoTTA 입니다. KAIST RCV 에서 CVPR 2023에 투고한 논문입니다. 기존 CoTTA가 너무 연산적으로 비효율적이라 이를 해결하기 위해 새로운 구조를 설계하였죠. EcoTTA는 모델을 크게 K개의 덩어리로 나눕니다. 위 그림에서 K는 3입니다. 그리고 백본모델 중간중간에 K개의 meta network를 삽입합니다. 해당 meta network는 shallow conv block과 bn layer로 구성됩니다. 구조적으로는 매우 간단하죠.
TTA가 수행되면서 해당 meta network의 update가 수행되게 됩니다. 부가적으로 forgetting 해결을 위한 regularization term도 설계되었는데 위 그림에서 이는 표현되지 않았습니다.
Ours
본 논문에서는 EcoTTA 뿐만 아니라 앞선 방법론들은 continual domain shift 상황 속 마주하는 domain이 서로 상이함에도 불구하고 동일한 module을 태워서 forward 및 backward를 수행하기 때문에 suboptimal한 지점으로 수렴할 수 있다고 합니다. 가령 EcoTTA 의 경우만 봐도, domain별로 개별적인 module을 구성한 것이 아닌, 모델 내 특정 지점에서 그냥 하나의 meta network를 구성하였죠.
그래서 본 논문에서는 domain 이 상이하다면 서로 다른 module로 통과해야 최적의 지점으로 수렴할 수 있다고 주장하며, backbone의 각 블럭에 MoDE 라고 하는 블럭을 특정 갯수만큼 사전정의 하게 됩니다.
(뒤에서 설명드릴 내용이지만, Online TTA 상황 속 마주하는 domain의 갯수를 모르기 때문에 MoDE의 갯수는 실험적으로 미리 pre-define 하여 고정해두어야 합니다. 어떻게 보면 limitation 일 수 있겠네요.)
본 논문에서 제안하는 요소는 크게 2가지입니다. 첫번째는 Mixture-of-Domain Low-raknk Experts (MoDE) , 그리고 두번째는 Domain-Expert Synergy Loss 입니다. 이들에 대해선 method 단락에서 자세히 설명하는 것으로 하겠습니다.
2. Method
2.1. Domain-Augmented Initialization
위에서 언급한 2가지 제안 사항에 대해 살펴보기 전, source pre-trained 과정에 대해 잠시 살펴보겠습니다.
일반적으로 TTA의 동작 과정은 1) Source dataset에 대해 학습, 2) on-device 상황 속 test 단계에서 마주하는 continual domain shift 에 대한 TTA 수행.
2번 과정에서는 gt 정보를 사용할 수 없기 때문에 TTA에서는 1번 과정에서 어느 정도의 풍부한 정보를 학습하였고, 이 학습된 정보가 TTA 수행 과정 속 얼만큼 잘 보존되는 지가 매우 중요합니다.
source pre-trained 과정 시 풍부한 정보를 미리 학습해두기 위해 위에서 설명드린 EcoTTA (Song et al., CVPR 2023) 에서는 Augmix 방식으로 source dataset에 augmentation을 적용하여 robust한 사전학습을 수행합니다. 해당 논문에서 제공하는 classification TTA결과에 의하면, Augmix 적용 유무로 인해 약 9% 정도의 error 차이를 보이니… source pre-trained 시 augmentation 등의 기법으로 다양하고 강인한 정보를 잘 학습해 두는 것이 매우 중요한 것을 알 수 있습니다.
EcoTTA와 동일하게 본 논문에서도 source pre-trained 수행 시 사전 augmentation 을 진행합니다. 본 논문에서는 이를 Source Domain Augmentation (SDA) 과정이라 칭합니다.
SDA 과정이 기법적으로 복잡하진 않습니다. 이전 style tranfer나 transformation 기법들을 그대로 사용하는 것이죠. 위에서 설명드렸다시피 test 단계에서 gt를 사용할 수 없는 Online TTA의 특성 상 여러 augmentation 을 적용한 source knowledge 습득이 성능적으로나 컨셉적으로나 매우 중요하다고 강조합니다. deploying 이전에 domain-specific information을 얻을 수 있다고 언급하네요.
2.2. Mixture-of-Domain Low-rank Experts (MoDE)
저자들은 Mixture-of-Experts (MoE) 라고 하는 이전 연구들의 기법에서 아이디어를 착안합니다. 그리고 여러 experts들의 cooperation & specialization 을 기반으로 동작하는 CTTA framework를 설계합니다.
좀 길긴한데 이를 Inputdependent Online Blending of Experts for Continual Test- Time Adaptation (BECoTTA) 라고 칭합니다. 그리고 제안하는 BECoTTA는 앞선 MoE 에서 착안하여 사전학습 된 ViT 백본의 각 블럭 사이사이에 Mixture of Domain low-rank Experts (MoDE) 라고 하는 shallow한 layer를 추가합니다. (마치 adapter처럼 말이죠.)
MoDE의 구조 또한 간단합니다. 크게
i) 입력 sample을 D개(하이퍼파라미터) 중 하나로 구분하는 Domain Discriminator DD,
ii) D개의 routers G (G_1,,, G_D)
ii) N개의 lightweight experts A (A_1,,, A_N)
로 구성되어 있습니다.
아래 그림에서 전체 구조를 살펴보실 수 있습니다.
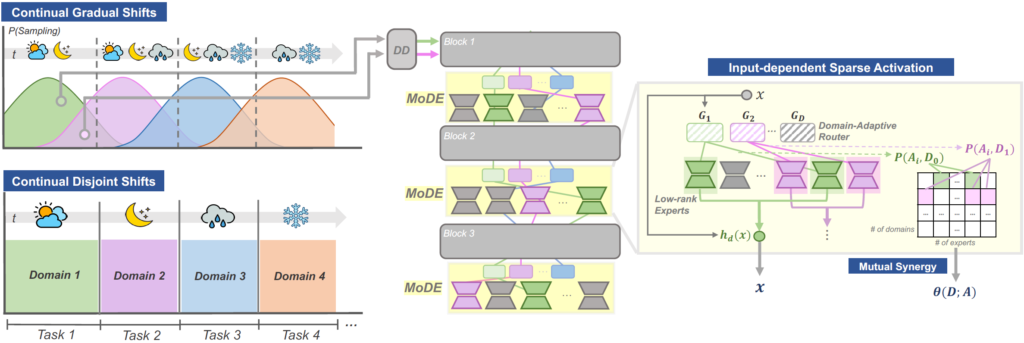
Domain Discriminator (DD)
좌측과 같은 Continual TTA 상황에서 실시간 입력으로 들어오는 test sample에 대해 Domain Discriminator (DD) 를 사용하여 어떤 domain인지를 판별하게 됩니다. 총 D개(하이퍼파라미터) 의 domain 중 하나로 분류하는 DD 는 2.1.절에서 설명드린 initialization 과정에서 미리 사전학습되며, TTA 수행 단계에서는 freeze 시킵니다.
Domain-Adaptive Routing
DD 에 의해 domain의 종류가 결정되었다면, 이를 총 N개로 사전 정의한 expert(전문가) 에게 연결(routing) 해 주어야 합니다. 이를 위해 D개의 router 를 설계합니다.
router와 expert 의 관계성, 그리고 이들의 역할은 직관적입니다. 입력으로 들어오는 sample들은 어떤 domain인지에 따라 개별적인 layer를 통과시켜야 더 효율적입니다. 즉 해당 domain을 전문적으로 다루는 expert 를 사용하여야 합니다. 그리고 이런 expert들을 할당해 주기 위한 것이 router 입니다.
router의 동작 수식은 아래와 같습니다.
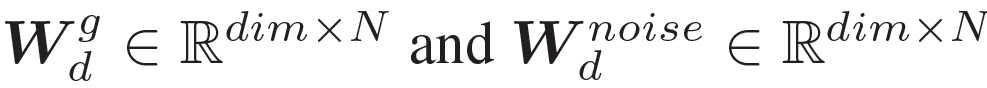
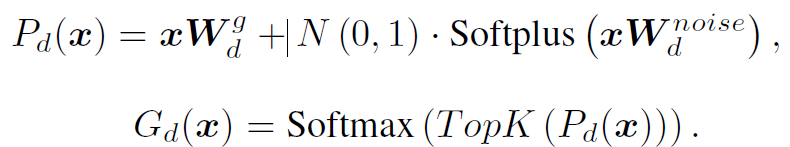
위 수식을 통해 입력 test sample 과 관련이 없는 expert에게는 가중치를 0으로, 관련성이 높은 expert에게는 더 높은 가중치를 부여하는 router 를 설계할 수 있게 됩니다. 그리고 이런 expert 를 기반으로 아래 수식을 통해 MoDE layer의 최종 output을 설계할 수 있게 됩니다.
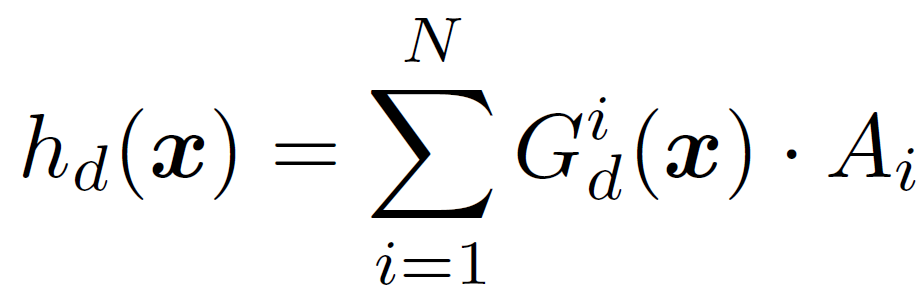
router G와 expert A를 함께 조합하여 현재 입력 sample과 가장 관련성이 깊은 expert 들의 조합으로 최종 output 을 도출할 수 있는 것입니다.
The design of Low-rank Experts
위 단락을 통해 router와 expert의 관련성 및 동작 원리에 대해 설명드렸습니다.
그렇다면 expert의 구조는 어떠할까요?
매우 간단합니다. lightweight를 위해 두 shallow 한 layer와 activation function으로만 구성됩니다. 아래처럼 말이죠.
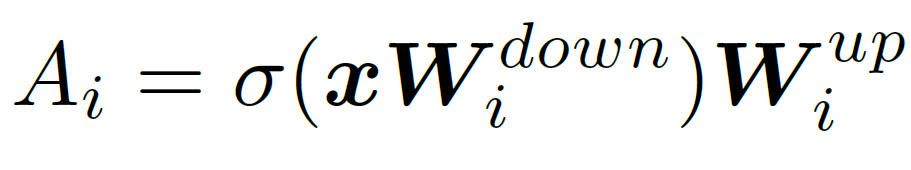
dimension을 기준으로 dim을 r 차원으로 down 시킨 후, activation 을 통과시키고, r차원을 다시 dim 으로 up 시킵니다.
Maximizing Domain-Expert Synergy
각 domain-expert 들의 협업/synergy 를 위한 추가 설계입니다.
저자들은 night과 같은 독특한 domain을 담당하는 expert는 타 experts들과 고립시키고, 반면 snow와 fog 등 상대적으로 유사한, similar visual contexts를 가지는 domain을 담당하는 expert 들 끼리는 collaboration 해야 한다고 주장합니다.
이를 위해 앞선 router의 출력을 사용하여 Domain-Expert Synergy loss 를 설계합니다.
router의 output G를 i번째 전문가 A_i의 특정 도메인 d에 대한 할당 가중치로 간주한다면, P(A_i|d) 를 계산할 수 있게 됩니다. 이후에 베이즈 정리를 사용하여 아래를 계산할 수 있다고 합니다.
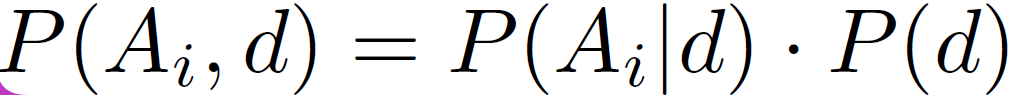
위 식에서 P(d)는 도메인 d의 발생 빈도를 나타냅니다. 대부분의 실제 시나리오에서 P(d)를 사전 정의하는 것은 불가능합니다. 따라서 본 논문에서는 P(d)를 uniform distribution으로 가정합니다. 다음으로, 도메인과 전문가 간의 mutual dependency를 측정하고 최대화하기 위해 아래 확률 모델링을 채택합니다.
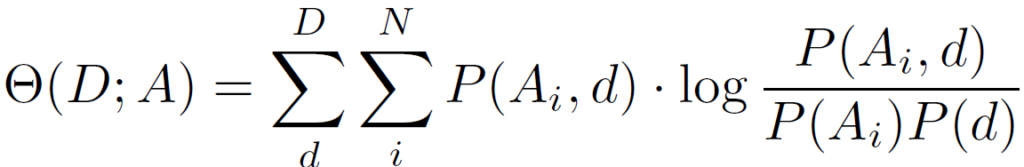
위 식에서 P(A_i,d) log P(A_i,d) 를 최대화하게 되면 조건부 분포 P(A_i|d)가 더욱 sharp 해 져서 domain과 expert 사이의 dependency를 더욱 잘 파악할 수 있다고 합니다.
위 domain-expert synergy loss는 model initialization 과정에서 적용됩니다.
(이번 단락은 제 역량 이슈로 설명이 많이 부족합니다..)
실제 TTA 수행 단계에서는 앞선 연구들ㄹ과 동일하게 entropy minimization 전략을 채택합니다. 또한 이 과정 속에서 forgetting과 error accumulation을 해결하기 위해 output의 confidence 를 기반으로 filtering 을 수행하여 entropy 가 일정 threshold 이하인 sample에 대해서만 loss를 계산합니다.
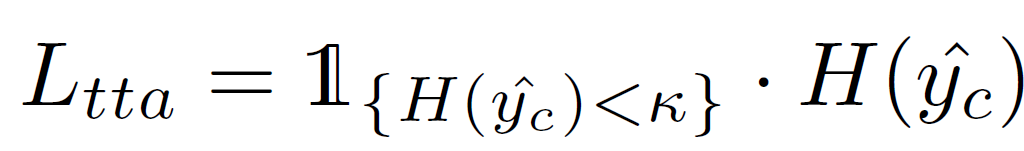
Experiment
Datasets
Continual Disjoint Shifts (CDS) benchmark
fog, night 등의 상황이 disjoint 하게 딱딱 변화하면서 연속적으로 domain이 변화하는 상황을 담고 있습니다.
CDS 는 크게 balanced weather shift를 포함하는 CDS-Easy와, imbalanced weather & area shifts를 담고 있는 CDS-Hard 시나리오로 구성됩니다. 이 중 CDS-Easy는 앞선 연구들에서 흔히 벤치마킹 하던 상황이고, CDS-Hard는 본 논문에서 real 상황을 위해 새롭게 imbalanced scenario를 설계하여 제안한 벤치마킹 입니다.
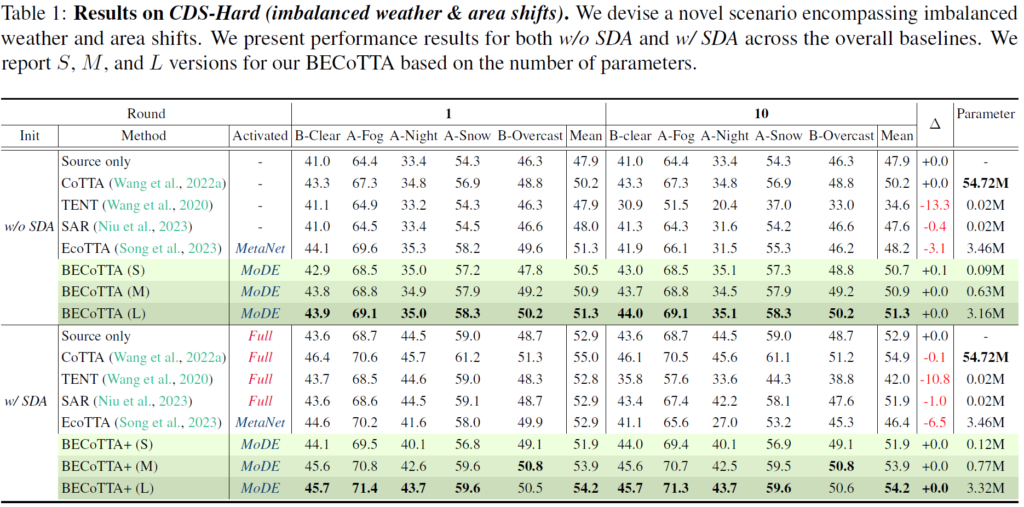
Source Domain Augmentation (SDA) 과정의 적용 유무에 대해 각각 실험을 수행하였습니다.
TENT의 경우 continual 상황을 고려하여 설계한 기법이 아니기에 round 1에 비해 10에서 큰 폭의 성능 하락이 발생합니다. source pretrained 모델에 대해 아무런 TTA를 수행하지 않고 그저 평가만 진행하는 source only 보다도 훨씬 더 낮은 성능을 보이고 있네요. forgetting 문제가 이렇게나 무섭습니다.
Continual TTA의 baseline인 CoTTA의 경우 round 1 -> 10으로 TTA가 지속적으로 수행됨에 따라 성능이 꽤나 준수하게 유지되는 것을 볼 수 있습니다. continual TTA의 challenging issue인 forgetting issue에 대해 어느정도 잘 해결한 것이죠. 하지만 parameter 수가 너무나도 많은 것이 큰 단점입니다.
SAR의 경우는 효율성을 강조한 방법론이라 parameter 수는 ours 보다 적은데, 성능적으로는 조금의 forgetting 문제를 겪고 있습니다.
EcoTTA는 본 논문과 가장 유사한 방법론을 제안한 논문입니다. 나머지는 Freeze 하고 shallow한 meta network만 update 하는 방식이죠. 해당 방법론 보다 더 효율적이면서 forgetting 이슈는 잘 해결한 것을 볼 수 있습니다.
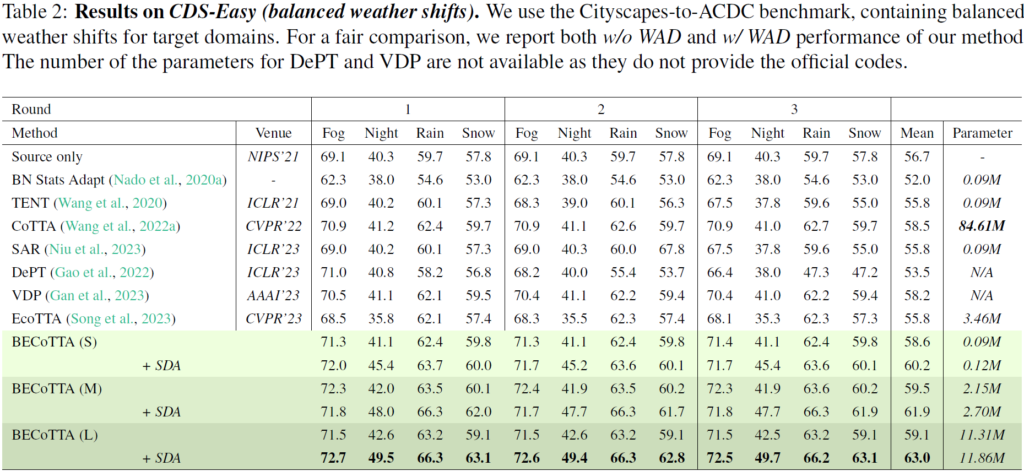
일반적으로 타 논문들에서 벤치마킹을 수행하는 CDS-Easy 상황입니다.
3 round 동안 TTA가 수행이 되며, 각 domain 변화에 대해 성능이 각각 측정된 것을 볼 수 있습니다.
음.. 그런데 위 table을 보면서 갑자기 든 의문점이 있습니다. 사실 이상적인 TTA라 함은 test time때 들어오는 새로운 sample 에 대해 점차적으로 adaptation을 수행하면서 성능이 천천히라도 향상되는 그런 흐름을 보여주는 것이라 생각됩니다. 하지만 위 table에서 CoTTA, SAR, Ours 등 최신 방법론들 각각에 대해 1->3라운드로 진행하면서의 성능 변화를 살펴보면 동일 domain(1라운드 Fog->2라운드 Fog->3라운드 Fog) 에 해당하는 성능 변화가 거의 없는것을 볼 수 있습니다. 뭔가 forgetting issue를 해결하려고 모델을 거의 update 해 버리지 않는달까요.,.? 그런데 뭐 그만큼 continual domain shift 상황에서의 forgetting 문제가 챌린징한 것이며, 어줍잖게 모델을 큰 폭으로 update 해 버리면 성능 하락이 빡 일어나 버리니 다들 조금씩만 모델을 update해 나가는 것 같습니다.
Continual Gradual Shifts (CGS) benchmark
앞선 두 벤치마킹보다 더욱 더 real 한 상황을 반영하기 위해 저자는 새롭게 CGS 라고 하는 벤치마크를 제안합니다. 이는 매우 간단합니다. clear->snow 로 넘어가는 상황에서 기존 disjoint한 벤치마크는 1 frame 만에 바로 domain이 변화했다면, 이 gradual 한 상황을 담은 CGS 벤치마크에서는 그 날씨가 변화하는 과정도 soft하게 반영하겠다는 것이죠.
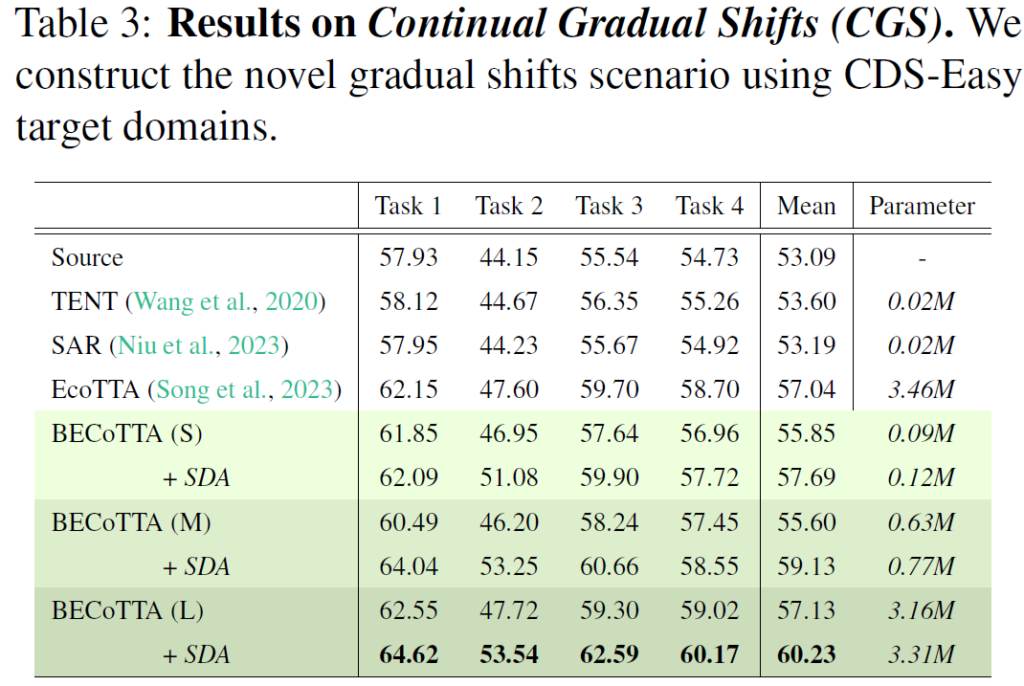
앞서 설명드린 table 1,2에 해당하는 domain Disjoint Shifts 상황보다,
위 table에서 저자가 새롭게 제안하는 continual gradual shift 상황이 훨씬 더 real world와 결이 맞다고 생각됩니다. 실제 상황에서도 날씨 등의 domain이 변할 때 급격히 변한다기 보다는 서서히 변화하기 때문이죠.
이렇게 새롭게 제안한 벤치마킹에서도 앞선 방법론과 비교해서 효율성 및 성능 측면으로 강인한 성능을 달성하고 있습니다.

본 방법론은 domain discriminator DD를 통해 domain d를 예측하고 이에 따라 router 및 expert 를 선정합니다. 따라서 DD의 역할이 꽤나 중요한데요, 그렇기 때문에 DD를 학습하는 initialization 단계에서 source augmentation 을 수행하는 SDA 가 필수적입니다.
좌측 (a) 그림을 살펴보시면 x 축으로의 SDA 적용 종류에 대해 y축 – target domain과의 연관성을 보여주고 있습니다. 뭐 clear, bright, dark, blur 등 여러 SDA를 수행하게 되면 이와 연관되는 target domain과 높은 유사성을 보인다는 것을 간단히 보여주는 것입니다.
그리고 우측은 각 요소별 ablation 입니다. 놀랍게도 DD의 적용 유무가 성능 변화에 거의 영향이 없네요. 음..
그리고 MoDE 의 경우 당연하게도 큰 폭의 성능 향상을 보이고 있습니다.
다만, MoDE 구조와 동작 방식의 경우 기존 MoE 연구들의 구조를 그대로 차용한 것이라 뭐 구조적인 novelty는 없지만, 타 분야 연구를 적용해서 가능성은 충분히 보여줬다고 생각합니다.
성능 및 효율성 측면에서는 매우 적절한 연구라 생각됩니다.
다만 experts의 수인 N, 그리고 router를 통해 선정하는 expert 수 K 를 사전 정의해 주어야 한다는 단점이 존재합니다.
이에 대해 입력 domain 의 특징을 예측해서 adaptive 하게 점차적으로 expert의 수를 늘려나가는 식으로 설계한다면 좀 괜찮지 않을까 라는 생각이 드네요.
리뷰 마치도록 하겠습니다.
감사합니다.