안녕하세요, 서른여덟 번째 X-Review입니다. 이번 논문은 2024년도 TCSVT에 게재된 Pro-Tuning: Unified Prompt Tuning for Vision입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
large-scale dataset으로 사전학습한 모델을 downstream task에 맞게 조정하는 fine-tuning 방식은 여러 비전 task에서 좋은 성능을 보이긴 했지만, 여전히 실제 어플리케이션에 적용하기에는 두 가지 문제가 존재합니다. 먼저, 각 task마다 모델 파라미터를 별도로 업데이트하고 저장해야 하기 때문에 cost가 많이 든다는 문제점이 있구요, 두 번째로 이 fine-tuning 방식은 downstream 데이터의 품질에 크게 의존하게 되는데 실제 환경에서는 변형된 데이터가 존재할 수 있다는 점입니다.
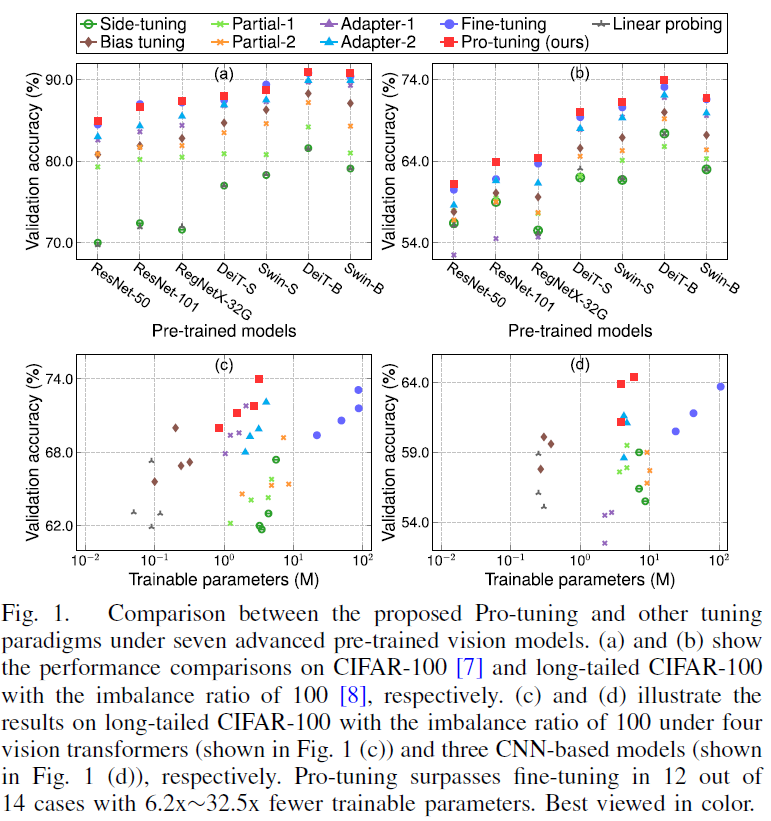
Fig1에서는 fine-tuning방식과 다른 tuning 방식들의 성능을 비교하여 보여주고 있습니다. 다른 튜닝 방식이라고 하면 후술할 내용이지만, 본 논문의 저자가 제안한 pro-tuning이라는 방식과 이외에 head만 제외하고 전부 freeze하는 linear probing이나, head와 몇 개의 layer만 update하고 나머지는 freeze한느 partial tuning 이나, adapter들이 존재합니다. 상단에 있는 (a), (b)는 일반 CIFAR100에서 실험을 수행하였고 하단의 (c), (d)는 데이터분포에 변형이 존재하는, 즉 class imbalance 문제가 있는 long-tailed CIFAR100데이터셋에 대해 수행되었습니다. 결과를 보시면, (a),(b)의 일반 CIFAR100에서는 fine-tuning(보라색 동그라미)가 꽤 괜찮은 성능을 보였습니다. 이와 비교했을 때 (c), (d)의 long-tailed CIFAR100에서는 17.7%~25.2%정도 정확도가 떨어지는데 이는 fine-tuning은 데이터의 품질이나 분포에 따라 성능이 크게 달라질 수 있다는 점을 시사합니다.
최근에 NLP 분야에서 prompt 기반의 학습 방식이 사용되고 있습니다. 일반적으로 prompt는 pre-trained된 모델을 downstream task로 유도하기 위해서 downstream input에 추가되는 task관련 description이라고 보면 되는데요, 이 prompt의 핵심 아이디어는 pre-trained model을 downstream task에 맞게 fine-tuning하는 것이 아니라 적절한 prompt를 설계함으로써 downstream task를 재구성해 원래 pre-train task와 유사한 방식으로 task를 수행하도록 유도하는 것입니다. 이 prompt tuning 방식은 주로 vision language 모델에 특화되어 발전해왔다고 하며, 저자는 순수 vision 모델에는 적용하기 어려운 부분이 있다고 합니다. 따라서 vision model을 위한 새로운 prompt tuning 방식을 개발해보자가 motivation이라고 보면 되겠습니다.
이에 따라 저자는 본 논문에서 pro-tuning이라고 하는 사전 학습된 모델을 다양한 downstream task에 적용하는데 사용하는 새로운 튜닝 방식을 제안하였습니다. 이 pro-tuining의 핵심은 앞서 언급한 prompt based tuning에 있으며, 원래의 모델은 freeze하고 특정 task에 맞는 visual prompt만을 학습합니다. 구체적으로 설명드리자면, pro-tuning은 각 입력 이미지에 대해 특정 prompt를 생성하는 prompt block을 구성하고 있는데 학습된 prompt를 각 input image의 중간 feature map과 blending함으로써 다양한 vision task를 수행하는 compact하고 robust한 downstream model을 생성할 수 있게 됩니다. 보다 구체적인 내용은 아래 method에서 설명드리도록 하겠습니다.
본 논문의 contribution을 정리하자면 아래와 같습니다.
- parameter-efficient한 튜닝 방식인 Pro-tuining을 제안함. 이 prompt 기반 튜닝 방식은 사전학습한 frozen 모델을 다양한 downstream task에 적용할 수 있다.
- CNN, ViT에 적용가능한 Pro-tuning은 적용하기도, 빼기도 쉬움.
- classification, detection, segmentation에서 pro-tuning 방식이 fine-tuning 성능을 넘음.
2. Pro-tuning
이제 본 논문에서 제안된 Pro-tuning의 아키텍처와 optimization 방식에 대해 설명드리도록 하겠습니다.
Overall Architecture
1) Basic Primitives
downstream data에 노이즈나, 손상이 있는 경우에도 freeze한 사전학습한 모델을 downstream task에 잘 적용할 수 있도록 하는 것은 중요합니다. 이를 위해 본 논문의 저자는 새로운 튜닝 방식인 vision prompt 기반의 tuning 방식인 Pro-tuning을 제안했습니다. 저자는 사전 학습된 모델은 freeze해 놓은 상태에서 각 downstream 입력에 대한 task specific prompt를 학습하도록 하는 lightweight한 prompt block을 제안하였습니다. 이 prompt block을 구성할 때 3가지의 원칙을 세우고 따르도록 했습니다. 낮은 parameter overhead, 강력한 표현력 및 배포 편의성을 용이하게 하는 것이 그 원칙입니다. 즉, 추가적으로 학습 가능한 parameter 수가 적어야 하며, powerful한 representation을 갖도록 하여 사전 학습된 모델이 새로운 downstream task에 빠르게 적응할 수 있도록 해야 한다는 것이죠 구체적으로 prompt-block은 1×1 conv와 5×5 depthwise conv, 1×1 conv로 구성되어 있습니다.
2) Integrated Vision System
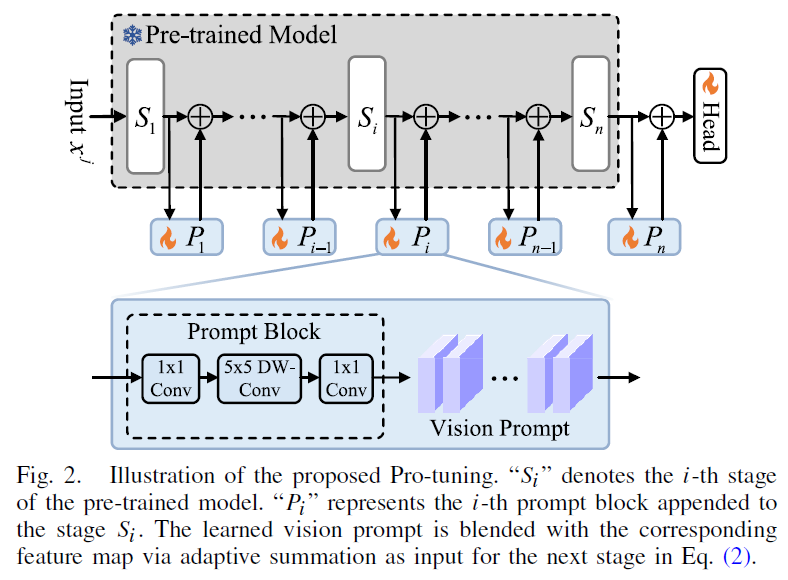
Pro-tuning에 대한 그림은 위 fig2에서 살펴볼 수 있습니다. 보시면 pre-trained model은 freeze한 상태에서 모델의 중간 중간 stage 마다 prompt block을 태우는 것을 볼 수 있습니다. Prompt block은 위에서 언급한것과 같이 단순하게 1×1 conv,. 5×5 depthwise conv, 1×1 conv 구조로 되어 있습니다.
3) Modeling Framework
결과적으로 전체적인 프레임워크는 다음 4가지 순서로 서술할 수 있습니다. 1) 각 downstream 이미지가 freeze된 사전학습 모델로 입력됨 2) 여러 stage마다 prompt block을 통해 task-specific한 vision prompt를 생성 3) 학습한 vision prompt와 그 다음 stage의 입력으로 들어가는 feature map과 blending. 4) pretrained model의 top layer에 output head를 추가해 최종 예측
이러한 방식으로 task-specific한 vision prompt를 얻음으로써 pre-train과 풀고자하는 downstream task 사이의 갭을 줄일 수 있게 되는 것입니다.
일반적으로 신경망 F는 Backbone G와 head H로 구성되는데요, 이는 F=H∘G로 나타낼 수 있습니다. 백본 G를 통과하고, 그 output이 head H를 통과하는 일반적인 구조입니다. 백본 G가 n개의 stage(S_i)로 구성되어 있고 입력 영상 x_j가 주어졌을 때 백본 G의 각 stage 별 output은 x_{j1}, x_{j2}, ,,, x_{jn}으로 정의할 수 있습니다. 이는 입력 영상이 백본을 통과하면서 각 stage마다 output으로 나오는 feature map을 나타내고 있는 것입니다.
Fig2를 보시면 이후 각 stage S_i에 연결된 prompt block P_i가 있습니다. 이 prompt block P_i는 해당 stage의 output feature map x_{ji}와 vision prompt P_i(x_{ji})를 결합해 새로운 representation \tild{x}_{ji}를 생성해냅니다. 이는 또 다음 stage의 input feature map으로 들어가게 되는 식으로 동작합니다. 식으로 보면 아래 식 1, 2, 3과 같습니다.
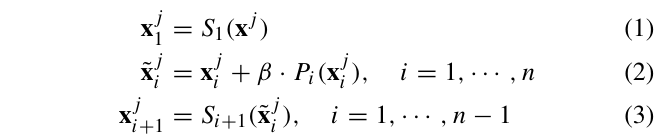
Optimization
이제 Pro-tuning 방식에서는 어떻게 pretrained 된 model G_ϕ를 최적화하는지 알아보도록 하겠습니다. 본 pro-tuning 방식은 pretrained model의 parameter는 고정한채로, 새로운 모듈의 파라미터 θ만을 학습하게 됩니다. ϕ는 freeze하는 parameter, θ는 학습하는 파라미터입니다. 즉, prompt block {P^i_θ}와 task-specific한 output head H_θ는 파라미터 θ로 parameterize되겠죠.
optimization의 목표는 task specific한 loss 함수, 예를 들어 image classification task라면 cross-entropy loss를 최소화하는 파라미터 θ를 찾는 것입니다. loss는 output head H_θ에서 계산되며, \tild{x}_{jn}와 gt label y_j사이의 오차를 계산합니다.
식으로 살펴보자면 아래와 같습니다.
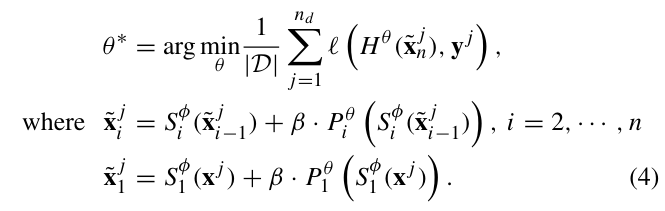
이렇게 학습 동안 prompt block과 network head에 대한 파라미터 θ만을 최적화하면서, pretrained model parameter인 ϕ는 최적화하지 않습니다. 이 과정에서 학습된 prompt는 task-specific한 prompt를 학습하기 위하여 pretrained된 parameter에서 인코딩된 지식을 추출하게 되는 것입니다.
3. Experiment
Experimental Settings
실험에서 사용한 데이터셋으로는 일반적으로 많이 사용되는 classification 데이터셋이 CIFAR10, CIFAR100과 Clothing1M, Caltech101, Stanford Dogs, Oxford-IIT Pets, Oxford 102 Flowers를 사용하였습니다.
또, class imbalance 상황에서의 성능을 비교하기 위해 long-tailed 버전의 CIFAR10, 100을 사용하였습니다.
평가지표로는 top 1 accuracy를 사용하였으며, 학습가능한 파라미터 수를 비교하도록 하였습니다.
추가로 baseline method같은 경우 fine-tuning과 partial fine-tuning, linear probing, bias tuning, side tuning, Adapter를 사용했는데요, 짧게 각각이 무엇인지 설명드리자면 partial fine-tuning은 model의 head와 몇 개의 layer만 update하고 나머지는 freeze한 것입니다. linear probing은 head만 제외하고 전부 freeze하여 학습하는 방식이구요, bias tuning은 모델의 head와 bias를 제외한 나머지를 freeze시키고 학습하는 방식이며, side tuning은 lightweight한 side network를 학습해서 freeze한 pre-trained model과 fusion하는 것입니다. 마지막으로 adapter는 기존 model에 mlp를 추가해서 학습하는 것입니다.
3.1. Comparisons with State-of-the-Arts
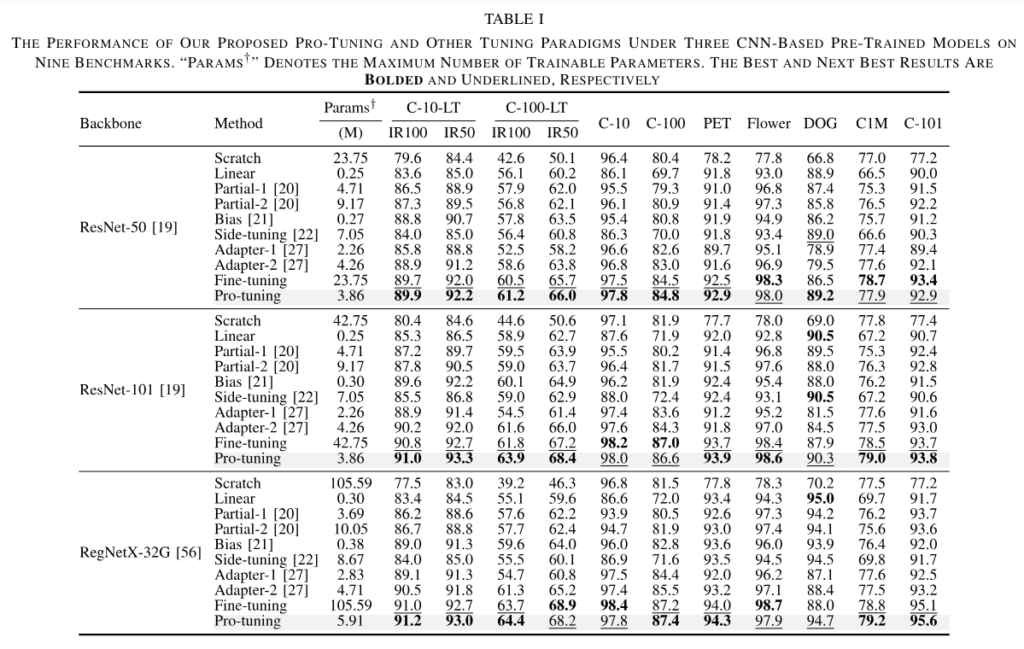
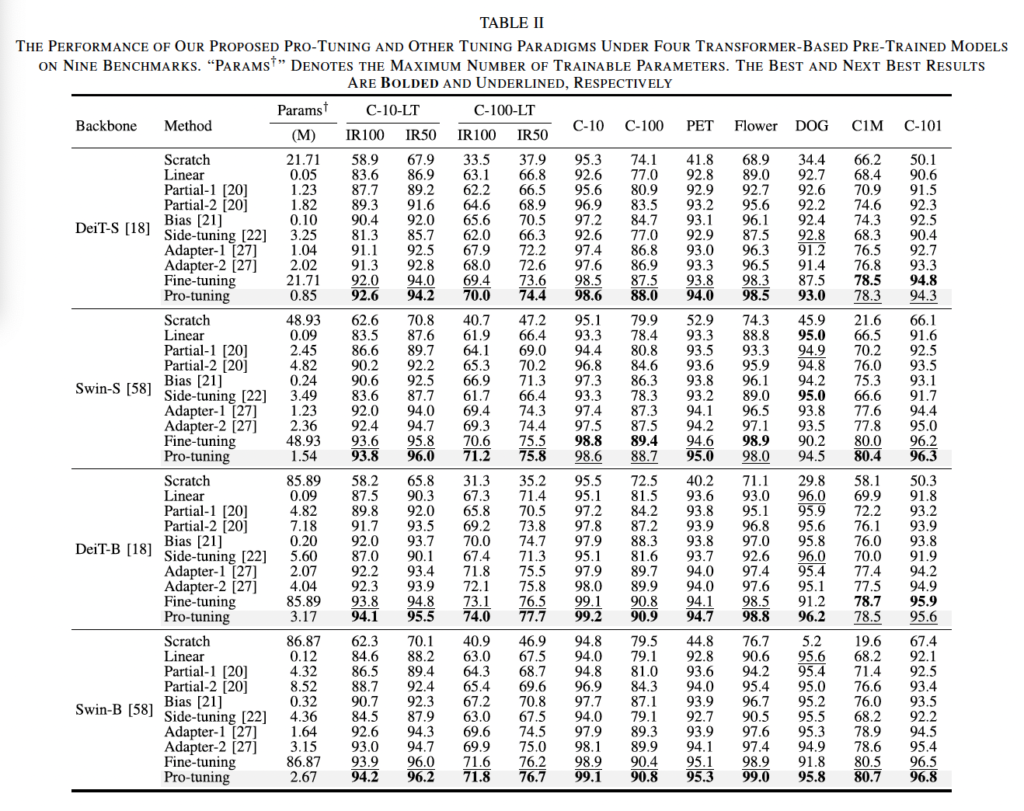
1) Class Imbalance Transferability
먼저, long-tailed CIFAR10, 100에 대한 실험입니다. 위에 있는 표1, 2에 그 결과가 나와있는데 각각 CNN based 사전 학습 모델에 대한 실험과 transformer based 사전 학습 모델에 대한 표입니다. 표에 적힌 C-10-LT, 100-LT가 long-tailed dataset이며, 그 아래 적힌 IR100, IR50은 imbalance ratio를 나타내는 것인데 예를 들어 IR100이라는 것은 가장 많은 데이터를 가진 클래스의 샘플 수가 가장 적은 데이터를 가진 클래스 샘플 수보다 100배 많다는 의미로 50보다 100이 imbalance가 더 심하다고 생각하시면 되겠습니다.
결과를 보시면 imblance ratio가 100인 long-tailed CIFAR100에서 pro-tuning이 fine-tuning에 비해 resnet101에서 accuracy가 2.1% 향상된 것을 볼 수 있으며, trainable parameter 수는 42.75 vs 3.86으로 약 11.1배 줄였다고 볼 수 있습니다. 추가로 좀 더 큰 parameter를 갖는 RegNetX-32G의 경우에는 pro-tuning은 IR100 C-100-LT에서 학습가능한 파라미터 수가 41퍼정도 감소하는 동시에 4.5% 성능이 향상되었습니다.
표2의 transformer 기반 모델의 경우, 대부분의 데이터셋에서 pro-tuning이 다른 튜닝 방식을 능가하고 있습니다. 특히 swin-B에서 ir50인 long-tailed CIFAR10의 경우 pro-tuning이 1.6배 적은 parameter를 사용해 side tuning에 비해 8.3% 높은 성능을 보이고 있습니다.
2) Generic Object Transferability
long-tailed dataset외에 다른 데이터셋에 대해서 봐보도록 한다면, 대부분의 상황에서 pro-tuning이 pre-trained 된 다양한 모델의 여러 튜닝 방식보다 가장 좋은 성능을 달성하였습니다. 특히, transformer based 모델에 대한 실험인 표2에서 DOG데이터셋 DeiT-B에서 27배 정도 적은 수의 tranable parameter로 fine-tuning보다 5.0%의 정확도 향상을 보이고 있습니다. 또, Swin-S에서 pro-tuning이 partial1에 비해 10.2의 성능 향상을 가져오면서 parameter 수를 37.1%까지 줄일 수 있었네요.
3.2. Ablation Study
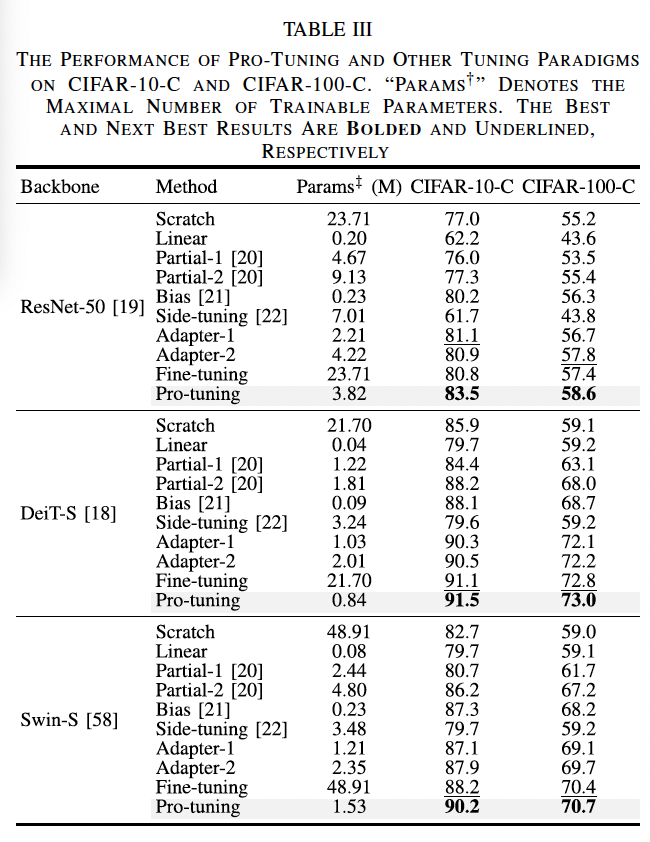
1) Image Corruption Robustness
이제 ablation study를 살펴보도록 하겠습니다. 먼저, image가 손상된 경우에서의 robustness를 보도록 하였는데요, 위의 표3을 보시면 pro-tuning은 CIFAR10-C resnet50에서 fine-tuning에 비해 2.7% 성능 향상을 보였고 파라미터 수도 약 6.2배 차이가 나는 결과를 보였습니다. 이외에 또, Swin-S에서 pro-tuning이 adapter2와 비교했을 때 성능 1% 향상했지만 parameter는 35% 줄인 결과를 보였네욥. 즉, 본 논문에서 제안한 pro-tuning이 영상이 손상된 경우에도 효율적으로 동작함을 보여주는 실험 표였습니다.
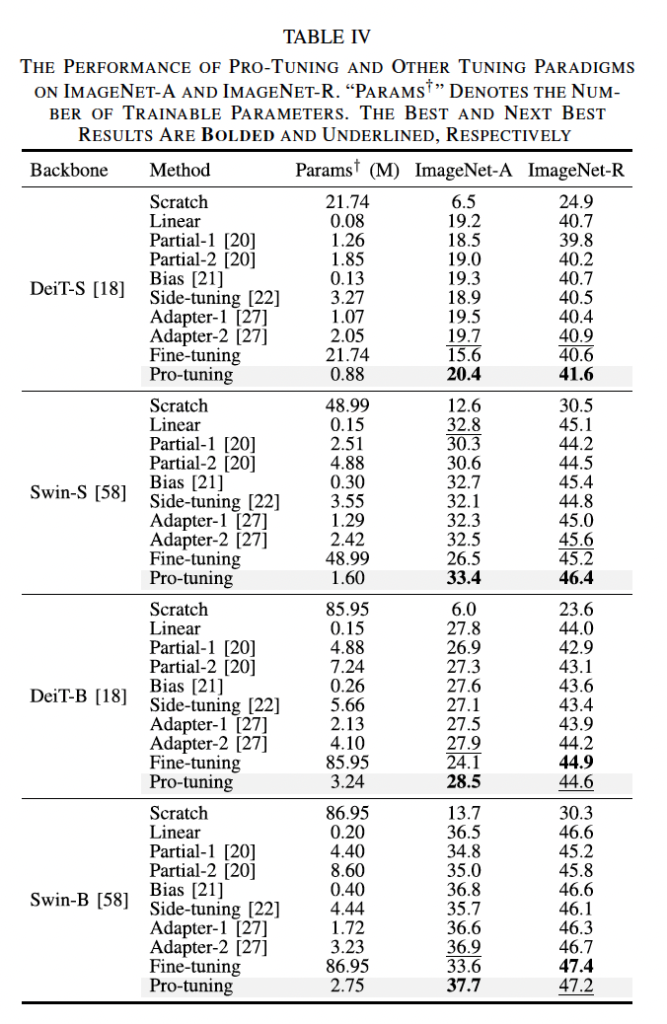
2) Natural Adversarial Examples
위 표는 ImageNetA, ImageNetR에 대한 실험 결과를 보여주는 표입니다. 이 ImageNet A 데이터셋은 natural adversarial 영상들로 구성되어 있기 때문에 다른 데이터셋에 비해서는 상대적으로 모든 튜닝 방법의 성능이 낮긴 합니다. 하지만, pre-trained 된 네 모델에서 Pro-tuning은 다른 tuning 방식보다 좋은 성능을 보이고 있습니다. 예를 들어서, DeiT-S에서는 find-tuning에 비해 파라미터 수가 25배정도 작으면서 4.8%의 성능 향상을 보였습니다.
3) Influence of More Pre-Training Methods
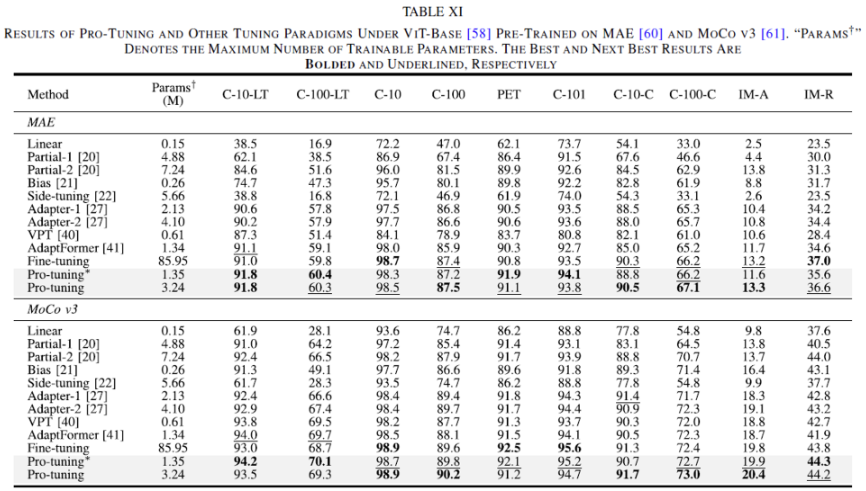
self-supervised 방식으로 pre-trained한 모델인 MAE와 MoCo v3에 대해서도 실험을 리포팅했는데요, 위 table을 보시면 10개의 데이터셋에 대해 실험을 수행했는데 그 중 8개 데이터셋에서 성능이 가장 좋았으며 동시에 최대 27배 정도 적을 수의 parameter로 tuning한 결과를 보입니다. AdaptFormer와 비교해봤을 때도 MAE 모델은 비슷한 파라미터 수로 1.2% 정도 더 정확한 결과를 보였구요, MoCo v3의 경우에도 그와 비슷한 양상을 보이고 있습니다.
3.3. Further Analysis
추가로 저자는 dense prediction task에 대해 pro-tuning의 효용성을 평가하기 위해 COCO 데이터셋에서의 object detection과 ADE20K 데이터셋에서의 semantic segmentation 실험을 수행하였습니다.
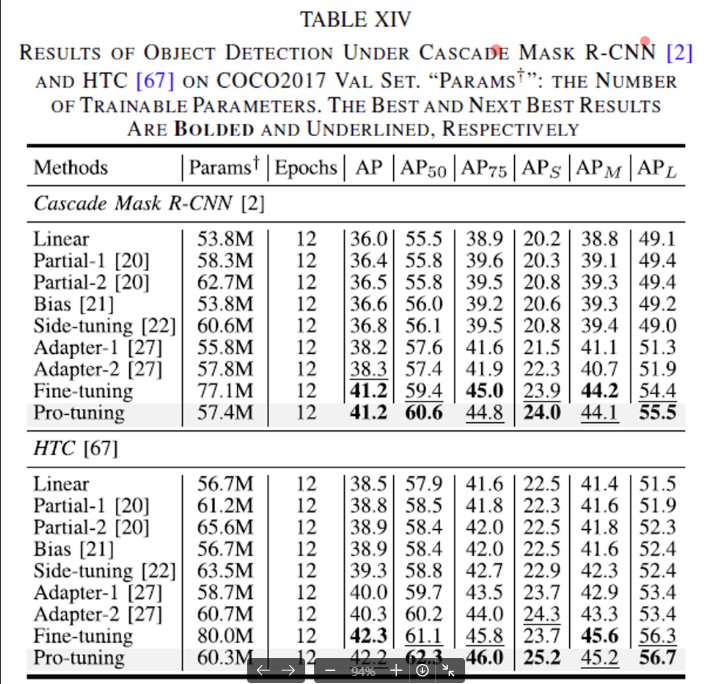
1) Object Detection
먼저, Object detection에 대한 실험 결과는 위 table 에서 살펴볼 수 있습니다. ResNet50을 백본으로 둔 Cascade Mask R-CNN과 HTC 모델에 대해 실험을 하였는데요, 결과를 보시면 Side-tuning이나 Adapter1, 2 등 여러 다른 튜닝 방식보다 성능이 더 좋은 것을 살펴볼 수 있으며, find-tuning과 유사한 혹은 더 높은 성능을 보임과 동시에 parameter 수를 약 25%정도 줄였다는 점을 확인할 수 있습니다.
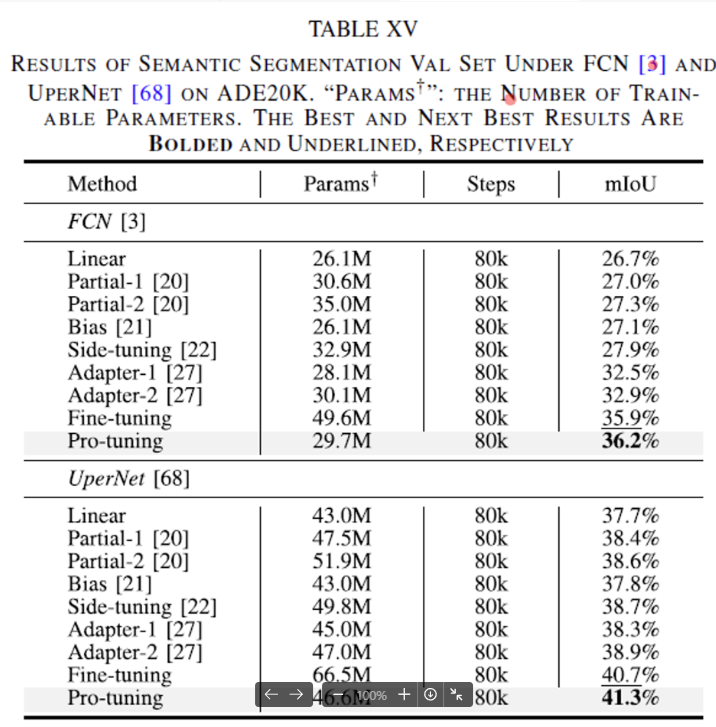
2) Segmentic Segmentation
다음으로 segmentation에 대한 실험 결과인데요, basline 모델로는 FCN과 UperNet을 사용하였으며 ImageNet1K로 ResNet50을 사전학습한 후 ADE20K 데이터셋에 대해 여러 튜닝 방식을 실험 후 비교하였습니다. 위 표가 semantic segmentation에 대한 실험 결과인데요, 보시면 pro-tuning이 FCN과 UperNet 모두 다른 튜닝 방식들과 비교했을 때 성능이 가장 높은 결과를 보였습니다. 특히, Partial2와 비교했을 때 약 9 mIoU 성능을 올린 동시에 파라미터 수를 15%정도 줄일 수 있엇네요.
안녕하세요 윤서님 좋은 리뷰 감사합니다.
본 논문에서 제안한 Pro-tuning은 Fine-tuning의 방식보다 효율적으로 튜닝할 수 있고 더 좋은 성능을 보이고 있는데 classification 말고도object detection이나 segmentation에 대한 실험 결과도 있을까요?
또한 사전학습된 모델이 지도 학습된 모델말고도 비지도 방식으로 학습된 모델로 실험한 결과가 있는지 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
네, object detection, segmentation에 대한 실험 결과도 있습니다. 실험 맨 아래에 추가해두도록 하겠습니다. 추가로 self-supervised pre-trained 방법론인 MAE와 MoCo v3에 대해 Pro-tuning을 실험한 table도 추가해놓았습니다.
안녕하세요 리뷰 잘 읽었습니다.
방법론에 대해 이해하기로, Vision prompt가 핵심으로 보이는데 Vision prompt를 만들어낸다는 과정을 조금 더 풀어 (예시와 함께) 설명해주실 수 있을까요?
“1) 각 downstream 이미지가 freeze된 사전학습 모델로 입력됨 2) 여러 stage마다 prompt block을 통해 task-specific한 vision prompt를 생성”에서, task-specific한 vision prompt란 예를 들어 object detection에서는 어떤 종류의, segmentation에서는 어떤 종류의 vision prompt이며 그 자세한 묘사의 정도는 어느 정도 될까요?
안녕하세요. 좋은 리뷰 감사합니다.
이게 세미나에서 많은 질문을 받았던 논문이군요ㅎㅎ 읽다보니 컨셉이 ‘vision-language model이 아닌 vision model에 적합한 tuning 기법을 만들어보자!’인거 같은데, 제 생각에 adapter와 비슷하지만 adapter라고 명명하지 않은 것이 adapter는 text 분야에서 시작해서 vision-language 분야에 적용된 것이라면 이 방법론은 vision 모델에만 적용하기 때문이라 생각하는데 이에 대해서 윤서님 생각이 궁금합니다.
감사합니다.