본 논문은 speech enhancement task를 다루는 논문이며, 그 중에서도 사전 학습된 large audio 모델을 사용할 때, 학습에 사용된 데이터(clean)과 downstream인 SE에 사용되는 데이터(noisy) 간의 domain gap을 feature normalization이라는 기법을 사용하여 줄여나가는 방법론에 해당합니다.
Introduction
Self-supervised 방식으로 학습된 large pretrained 모델은 다양한 분야에서 활용하고 있습니다. 자연어 처리 분야 뿐만 아니라 음성 처리 분야에서도 이러한 모델을 활용한 연구들이 활발하게 진행되고 있는데요, 방대한 양의 unlabeled 데이터로 학습된 representation을 통해 automatic speech recognition (ASR), speaker verification (SV), audio scene classification 같은 downstream에서 좋은 성능을 보여주었다고 합니다. 이에 최근에는 speech enhancement (SE)와 같은 생성 task에도 이러한 모델을 적용하기 위한 연구가 진행되었습니다.
그러나 SE task에 사전 학습 모델을 사용하려는 경우, domain mismatch 문제가 발생하게 됩니다.
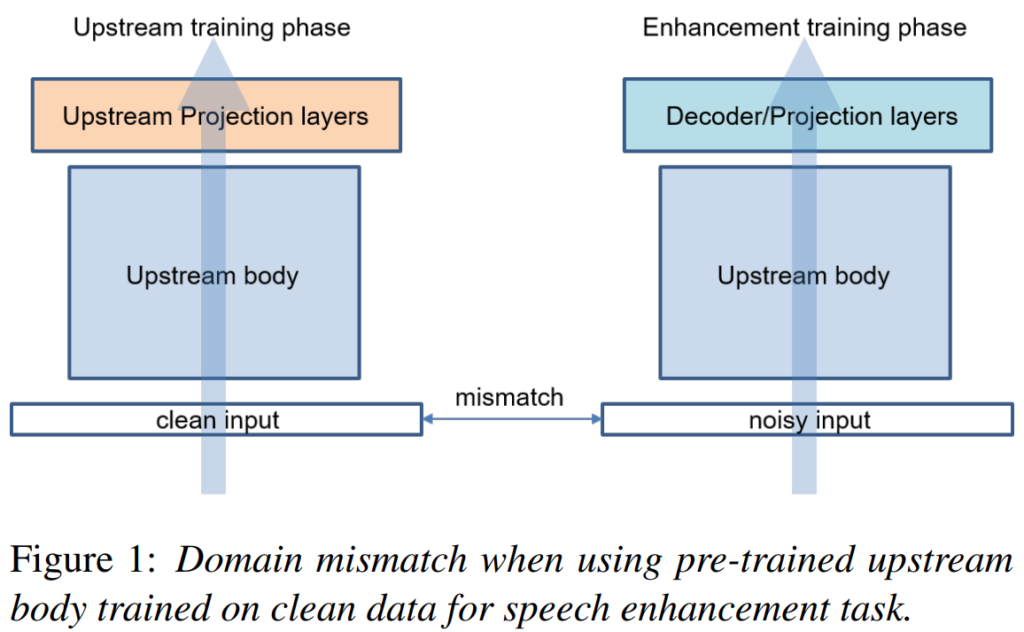
이러한 문제는 사전 학습과 downstream task의 도메인 차이로 인해 발생하는데, 그 원인은 [그림 1]과 같이, SE는 noisy 음성을 학습 데이터로 입력하지만, 일반적으로 음성 데이터로 사전 학습되는 모델은 clean 데이터로 학습되기 때문입니다. 이러한 차이를 완화하기 위한 방법으로는 사전 학습 단계에서 clean과 noisy 데이터를 함께 사용하여 학습하는 것이 있지만, 이는 결국 많은 양의 데이터와 학습 시간을 필요로 하게 되고, 공개된 대형 사전 학습 모델을 활용할 수 없다는 문제가 발생하게 됩니다.
이에 본 논문의 저자들은 downstream SE task에서 사전 학습 모델의 reperesentation의 활용을 용이하게 하기 위해 feature normalization 방법을 제안하였습니다. 간단히 설명드리자면 downstream으로 fine-tuning할 때 clean의 referential statistics로 noisy 데이터를 정규화하는 것입니다. 자세한 방법론은 아래 method 부분에서 설명드리겠습니다.
논문에서 저자들이 내세우는 contribution은 크게 두 가지입니다. 첫 번째는 SE task로 fine-tuning 시, 사전 학습 모델에 대해 추가적인 parameter 혹은 training loss를 도입하지 않고 더 좋은 성능을 달성할 수 있음을 보였습니다. 다음으로는 사전 학습 모델을 downstream에 직접적으로 적용할 수 있도록 하였다고 합니다.
Related Works
사전 학습과 미세 조정 사이의 domain mismatch는 downstream task의 성능 저하로 이어질 수 있는데요, 이러한 현상을 완화하기 위해 사전 학습 단계에서 downstream과 유사한 도메인의 데이터를 활용할 수도 있지만, 이를 위해서는 전체 모델에 다시 학습을 진행해야 하니 사전 학습 모델을 사용함으로써 얻는 이점이 사라지게 됩니다.
Domain mismatch 문제를 해결하는 일반적인 방식으로는 domain adaptation 도 있었습니다. 먼저 Domain Adversarial Training (DAT)은 domain classifier를 adversarial하게 학습시켜 representation이 domain context에 의해 식별되지 않도록 하는 방식으로, domain-specific ASR, SV 및 SE를 포함한 다양한 supervised tasks에 적용되었습니다. 그러나 DAT는 domain classifier를 학습시키기 위한 multi-task learning이 필요하였습니다. 또 다른 방식으로는 residual adapters 또는 auxiliary contrastive loss가 있었는데, 이는 domain adaptation을 위해 새로운 파라미터를 추가하거나 multi-task training 경로를 학습시켜 기본 모델 학습을 복잡하게 만들었다고 합니다.
대부분의 이전 연구들이 domain mismatch의 일반적인 사례에 초점을 맞추고 있는 반면, 논문의 저자들은 SE의 맥락에서 사전 학습된 모델이 학습된 도메인과 미세 조정되는 domain간의 domain mismatch에 특별히 초점을 맞추었습니다. SE 모델은 학습을 위해 clean speech와 noisy speech의 쌍을 사용하는데요, 사전 학습된 speech models이 clean data로 학습된다는 가정 하에, 미세 조정 데이터는 source-domain data (clean speech)와 target-domain data (noisy speech)로 구성된 쌍으로 처리될 수 있습니다. 따라서 미세 조정 중에 source-domain과 target-domain statistics를 모두 추출할 수 있습니다. 본 논문에서 저자들이 제안하는 방법은 추가적인 학습 가능한 변수나 사전 학습 단계를 요구하지 않고 이러한 추정된 statistics를 활용하는 것으로, 미세 조정 시, latent features의 statistics를 target-domain에서 source-domain으로 이동시키는 방식입니다. source-domain features에서 target-domain features로 모델을 조정하기 위해, 미세 조정 단계 동안 shifting factor를 점차 줄여나갔습니다.
Base Model
본 논문은 사전 학습된 large speech 모델을 활용한 SE task이므로 전체 모델 구조는 [그림1]의 오른쪽과 같이 upstream body와 downstream을 위한 decoder로 구성되어 있습니다.
논문에서는 upstream model로 Mockingjay 계열(Mockingjay, TERA)과 Wav2vec2.0 계열((wav2vec 2.0, WavLM, HuBERT)를 사용하였다고 하며, 모든 모델에 대해서는 각각의 원 논문의 base setup을 따랐다고 합니다. downstream에 해당하는 SE network는 각 모델의 구조에 따라 적절히 구현하였다고 언급하였습니다.
Base wav2vec 2.0 downstream
Wav2vec2.0 model은 이전 리뷰에서도 언급했던 모델로, CNN으로 구성된 multi-layer feature encoder와 transformer encoder로 이루어져 있습니다. Wav2vec2.0의 사전 학습에서는 feature encoder에서 추출된 latent feature를 quantize한 벡터 Q를 target으로 사용하고, latent feature를 transformer에 입력하여 얻은 context를 source로 사용합니다.
위의 Wav2vec2.0을 base로 할 때, 저자들은 downstream SE 모델을 transformer encoder와 feature encoder의 representation을 활용하는 U-Net style의 decoder로 설정하였습니다.
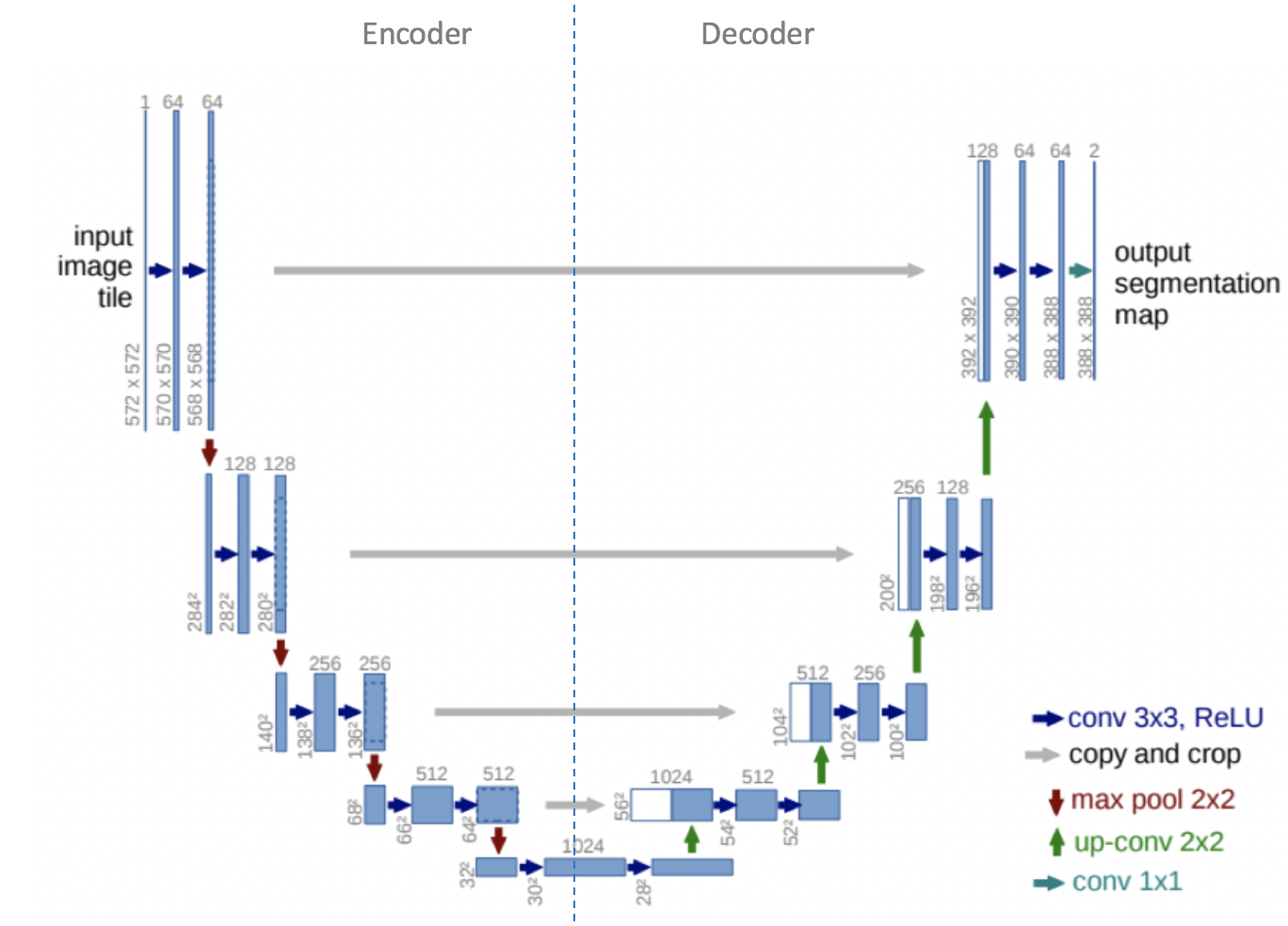
위 그림은 U-Net의 구조를 나타내는데요, 여기서 처음 up-conv가 진행되는 부분부터 decoder에 해당하며, 본 논문의 SE 모델은 wav2vec2.0 + decoder로 구성되고 u-net의 구조를 가지도록 설계되었습니다.
구체적으로, wav2vec2.0 transformer encoder의 첫 번째 레이어 출력값을 SE 모델의 bottleneck feature로 사용하였습니다. 추가되는 decoder 부분은 deconvolution layer로 구성하였으며, 역순으로 feature encoder layers의 출력과 짝을 이루도록 하였다고 합니다. 즉, Feature encoders의 출력은 차원 축소를 위해 point-wise convolutions에 전달되고, 해당 decoder features와 concatenation된 후 다음 deconvolution layers로 넘겨주게 됩니다.
Feature Extraction
논문에서 제안하는 feature extraction에 대해 설명드리겠습니다.
Encoder에서 출력된 d 차원의 latent feature X \in \mathbb{R}^d에 대해, 해당 feature의 평균과 표준 편차를 각각 \mu \in \mathbb{R}^d, \sigma \in \mathbb{R}^d이라고 할 때, normalized feature X_n는 새로운 목표 평균 \mu_n와 표준편차 \sigma_n을 사용하여 구할 수 있으며, 그 수식은 아래와 같습니다.
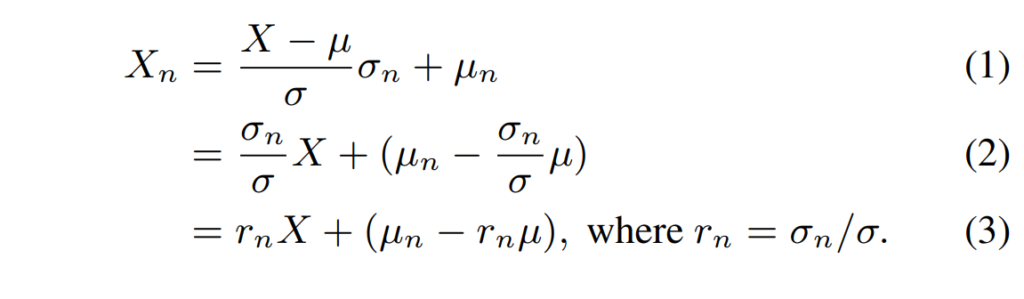
여기서 새로운 목표 평균인 \mu_n와 표준편차 \sigma_n은 만일 input이 clean인 경우 나타나게 될 통계값으로 본 논문에서는 noisy 데이터와 대응하는 clean gt를 통해 구할 수 있습니다.
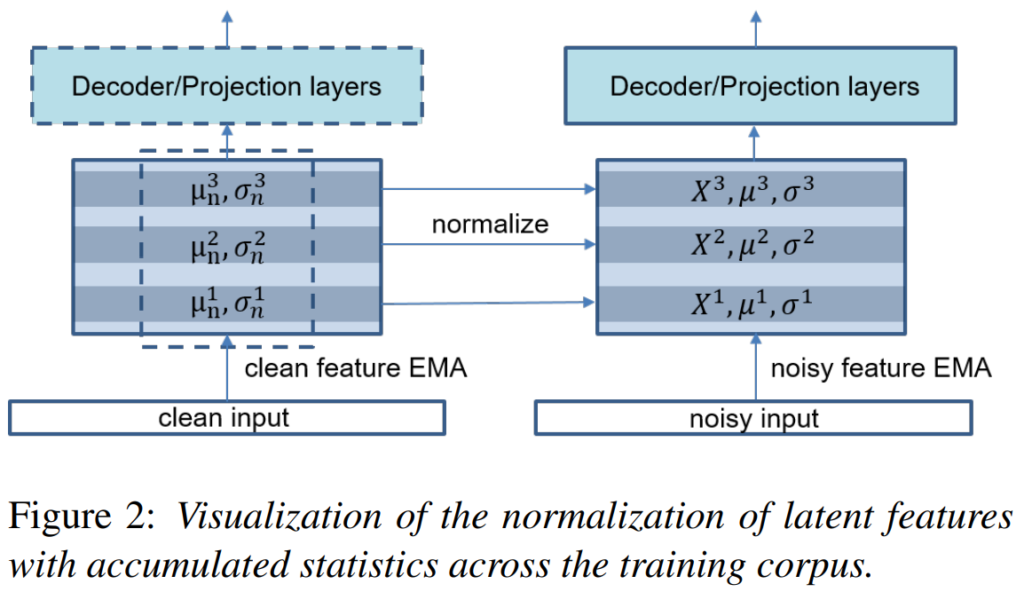
[그림 2]는 위 과정을 시각화 한 것으로 latent feature X를 정규화할 때 필요한 r_n, \mu_n 및 \mu와 같은 통계를 유지하는 제안된 feature normalization 방법을 보여줍니다. 정규화를 통해 (노이즈가 섞인) 입력 features는 해당하는 clean features와 동일한 통계를 따르게 됩니다. 각 feature의 통계를 training corpus에서 재귀적으로 추정하기 위해 exponentially moving average (EMA) 방법을 사용했습니다. 모델이 수렴에 가까워질 때 normalization 효과를 점차 줄이기 위해 scale factor k를 조절합니다. 이 단계에서는 normalization이 거의 이루어지지 않으며, 이 factor scheduling 방법은 평가 중에 모델이 추가적인 통계 파라미터 r_n, \mu_n 및 \mu를 필요로 하지 않음을 의미합니다. scale factor를 사용한 re-normalized feature \hat{X}_n은 다음과 같이 계산할 수 있습니다:
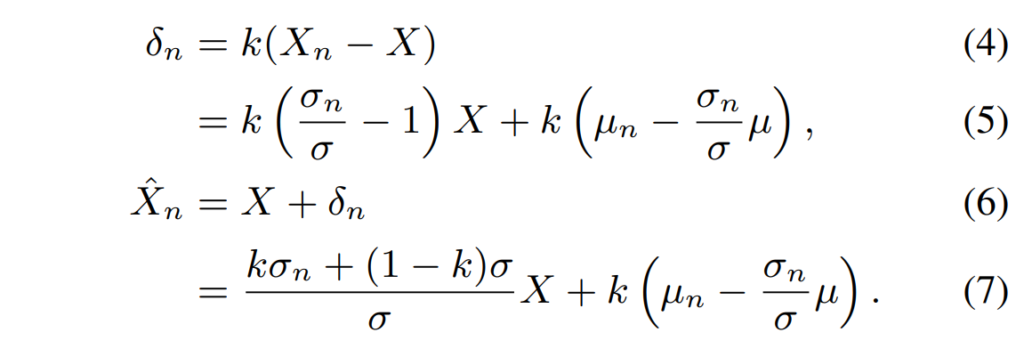
자세한 과정은 Algorithm 1에서 확인할 수 있습니다.

구현 관점에서 보면, Algorithm 1에서 layer_{frozen}으로 표시된 것처럼, 마지막 정규화가 발생하는 레이어까지의 upstream body를 복제하여 고정(frozen)된 상태로 유지해야 합니다. 고정된 레이어는 학습 상태에 영향을 받지 않는 clean latent features를 추출하는 데 사용됩니다. 각 레이어의 처음 부분에서 정규화가 발생하기 때문에 학습 중에 유지되는 추가적인 고정 파라미터의 수는 무시할 수 있습니다.
Experimental Setup
Data
논문에서 실험에 사용된 음성 모델들은 모두 Librispeech-960hr로 사전 학습된 모델이며, downstream에는 SE 데이터셋인 Voicebank-DEMAND를 사용하였습니다. 이때 Voicebank-DEMAND는 16kHz로 다운샘플링하였고, Mockingjay variants와 wav2vec 2.0 variants에 대해 각각 2초 혹은 1초 씩 cropping 하였습니다. Mockingjay variants는 50k iterations 동안 batch size 8로, wav2vec 2.0 variants는 100k iterations 동안 batch size 8로 학습하였고, 평가 metric은 WB-PESQ (wideband version of PESQ)와 STOI를 사용하였습니다. 해당 metric들은 음성의 전체적인 품질을 나타내는 정량적 지표로써, 0~4.5사이의 값을 가지고 클 수록 좋은 품질을 의미하는 것이라고 합니다.
Results
Results on downstream models
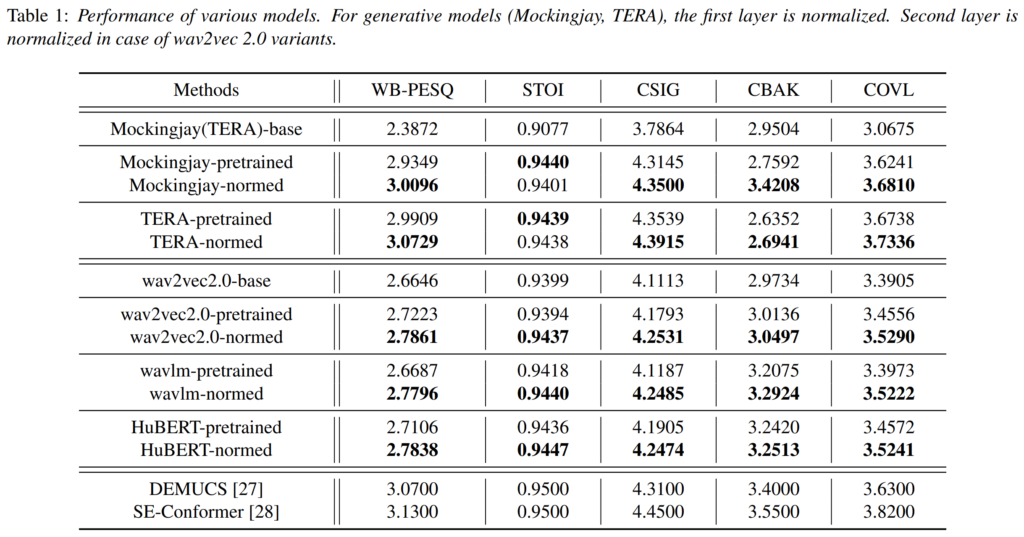
[표 1]은 feature normalization을 여러 upstream 모델에 적용한 결과로, “-base”는 random하게 가중치를 초기화한 모델을 의미하며, “-pretrained”는 Librespeech로 사전 학습된 모델을, “-normed”는 feature normalization이 적용된 모델을 의미합니다.
[표 1]을 보면 거의 모든 모델에서 feature normalization을 적용하였을 때 WB-PESQ와 STOI이 증가하였으며, 이는 feature normalization 방식이 모델에 구애받지 않고 범용적이라는 것을 나타내고 있습니다.
Effect of normalization layer
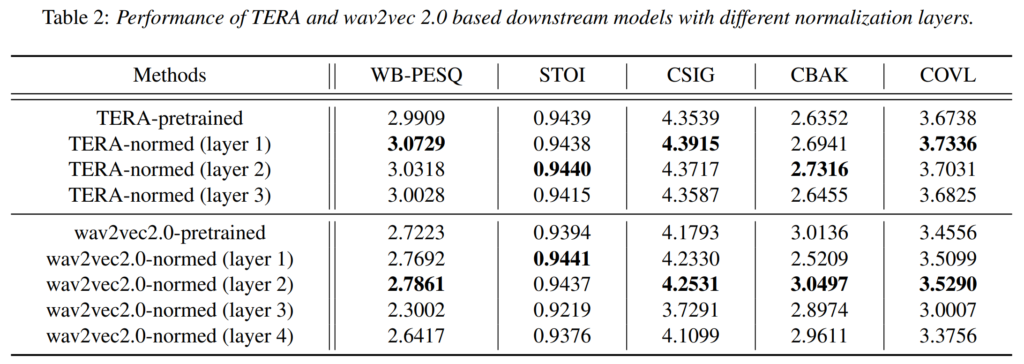
[표 2]는 TERA와 wav2vec 2.0의 각 레이어에 feature normalization를 적용했을 때의 결과로, 어떤 어떤 레이어에 정규화를 적용한 것이 효용성이 가장 좋은 것인지를 보여주기 위한 실험입니다. Wav2vec2.0의 Feature encoder에는 3*3 conv module이 4개 존재하는데 input에 가까운 순서대로 normalization을 적용한 것 같네요.
결과를 보면 lower 레이어에 normalize를 적용하였을 때 speech enhancement 성능이 증가하는 경향이 있는데요, 논문에서는 domain mismatch가 lower 레이어에서 가장 큰 영향이 있기 때문이라고 하였습니다.
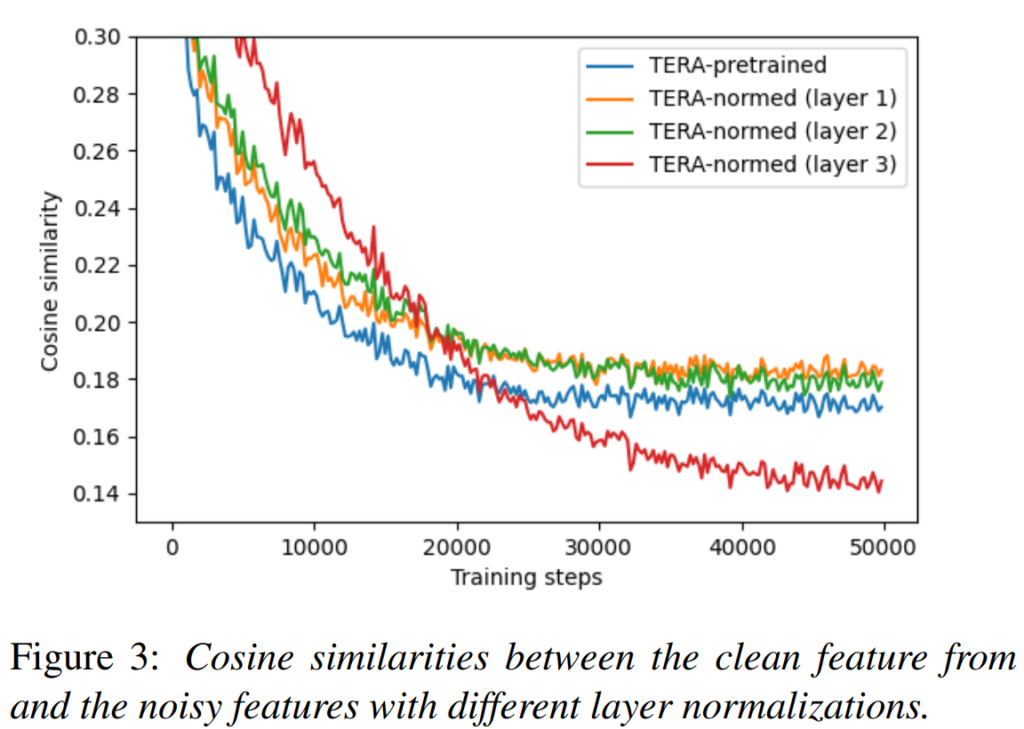
[그림 3]은 TERA 모델을 학습할 때 clean과 noisy 입력에 대한 encoder 출력값의 유사도를 비교한 것으로, feature normalization에 의해 각 레이어 발생하는 변화를 확인하기 위해 수행하였다고 합니다. 결과를 확인해 보면 normalize를 적용하지 않은 모델보다 normalize를 적용하였을 때 clean과 noisy의 feature 유사도가 높게 나타나고, 이는 레이어의 정규화가 upstream body의 clean feature semantics를 유지하고, fine-tuning 단계에서 domain adaptation이 이루어질 때 발생할 수 있는 catastrophic forgetting을 방지할 수 있음을 나타낸다고 합니다.
[그림 3]에서 주목할 점은 higher layer (layer3)에 정규화를 적용하면 학습 초기에는 두 feature간의 유사도가 높게 나타나지만 학습이 진행될 수록 급격하게 감소한다는 것으로, 논문의 저자들은 이를 통해 적절한 정규화 레이어 선택이 중요하며, 그렇지 못할 경우 오히려 사전 학습 모델의 일반화 능력을 잃게 할 수 있음을 언급하였습니다.
안녕하세요 혜원님 좋은 리뷰 감사합니다.
본 논문의 학습 과정에서 질문이 있는데 먼저 clean data로 학습하여 학습된 feature에서 평균과 분산을 구해서 noisy data를 normalize하는 건가요? 아니면 clean 음성과 noisy 음성 쌍을 사용하여 동시에 학습이 되는건가요?
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
이 논문에 대해서 같이 많이 다뤄봤고 했는데 bottleneck feature라는 말이 사실 이전부터 잘 와닿지가 않아서 설명 부탁드려도 될까요? 단순히 encodeing된 feature를 bottleneck feature라고 말하는 걸까요?
감사합니다.