안녕하세요, 서른 일곱번째 x-review 입니다. 이번 논문은 2023년도 ICCV에 게재된 Shape Anchor Guided Holistic Indoor Scene Understanding 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
3차원 scene에 대한 understanding은 어플레케이션 관점에서 semantic한 scene 모델을 제공하는 굉장히 포괄적인 task 입니다. 이 task의 초기 연구는 공간 구조와 물체의 형태를 커버하는, 물체 검출로부터 reconstruction으로 가는 프레임워크를 따랐습니다. 좀 더 연구가 진행되고 난 후에는 semantic한 scene을 reconstruction하기 위해서 공간의 레이아웃 추정, 물체 검출, 그리고 shape 예측을 한번의 forward로 수행할 수 있는 end-to-end 학습 방법이 제안되었습니다. 최근에는 raw 포인트 기반의 3D detection 및 instance reconstruction이 가능해지면서 sparse한 포인트에서 물체를 검출하고 모델링하는 방향으로 연구가 많이 진행되고 있는데, 포인트 클라우드에서 얻을 수 있는 기하학적 정보를 통해서 현재 semantic scene reconstruction의 성능을 향상시키고 있다고 합니다. 그러나 현재의 방법론들의 한계점이 존재하는데요, (1) 물체 검출 단계에서 노이즈가 많은 instance feature 학습 (2) reconstruction을 위한 sparse 포인트 클라우드에서 instance를 찾는 어려움을 꼽을 수 있습니다. 이러한 두 가지 한계점이 여전히 높은 퀄리티의 semantic reconstruction을 하는데 bottleneck으로 적용하고 있습니다.
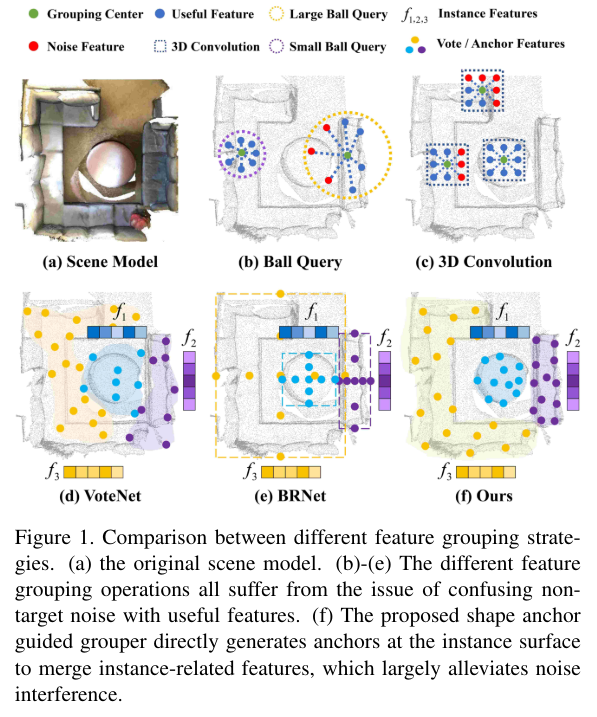
3D Object Detection에서는 제가 여러 논문에서 리뷰하였듯 물체마다의 instance한 표현력을 학습하기 위해서 포인트 레벨이나 feature 레벨에서 그룹화를 진행하게 됩니다. 기본적으로 Fig.1 (b)와 (c)처럼 볼 쿼리, 3D convolution가 있는데, 그룹화하는 범위가 고정되어 있어 흔히 큰 노이즈가 발생하거나 feature가 섞이는 문제가 발생할 수 있습니다. 범위에 대한 제약을 주지 않기 위해서, 이제 VoteNet과 VoteNet을 변형한 여러 모델들이 등장하여 물체 표면에 존재하는 raw 포인트들을 물체의 실제 중심에 위치하도록 이동시키고 그 상태로 물체의 feature를 클러스터링하는 voting 방식을 설계하였습니다. 이렇게 VoteNet을 비롯한 voting 기반 방법론들은 기본적인 연산들에 비해 고정된 범위를 사용하지 않아 비교적 flexible 하다고 볼 수도 있습니다. 그러나 Fig.1 (d)와 같이 실제 instance에 해당하지 않는 많은 outlier까지 포함시킨 그룹화 영역을 생성하는 경우가 발생하게 됩니다.
따라서 BRNet [10]은 거친 박스 제안에 의해 주어진 대표 포인트를 중심으로 샘플링하여 그룹화 공간을 제한합니다. 그럼에도 불구하고 박스형 그룹화 영역의 제한으로 인해 그림 1 (e)와 같이 물체의 모양이 불규칙한 경우 샘플링 포인트가 목표치를 훨씬 벗어날 수 있습니다. 이런 검출 단계에서의 그룹화 단계가 이슈가 되는 이유는 reconstruction 단계에서 물체 포인트를 찾을 때 outlier가 포함되지 않는 것이 물체를 reconstruction 하기 위한 전제 조건이 되기 때문 입니다. 그래서 이때까지의 방법론들은 추가적인 foreground 분류기를 사용하거나 혹은 샘플링 방식을 사용하지 않기 위해 detector를 instance segmentation으로 대체하여 물체 포인트를 샘플링해왔습니다. 그러나 instance를 찾는 space에서 많은 물체가 아닌 outlier가 존재하면 instance semgentation은 어려워질 뿐만 아니라 서로 다른 instance가 겹쳐지고 배경 포인트를 전경이라고 잘못 분류할 가능성이 높아지겠죠.
본 논문은 한계점으로 꼽은 (1), (2)는 사실 서로 연관되어 있는 하나의 문제이며 이는 feature를 그룹화 하는 과정에서 outlier를 제거할 수 있으면 해결 가능하다고 정의합니다. 그래서 Fig.1(f)와 같이 feature를 그룹화하는 영역을 물체의 shape 분포에 맞추어서 표면에 대한 앵커를 생성하는 shape anchor guided learning strategy (AncLearn)을 제안하고 있습니다. 표면 앵커의 기하학적 정보를 통해 물체 proposal을 예측하기 위해서, 로컬한 중심 feature을 합치고 reconstruction 과정에서 segmentation을 사용하지 않으면서 샘플링할 수 있는 shape aware search space를 구성할 수 있다고 하는데, 이는 방법론에서 더 자세히 살펴보도록 하겠습니다. 여기서 본 논문의 main contribution을 살펴보고 인트로 마치도록 하겠습니다.
- reconstruction 중 물체 검출과 instance 포인트를 찾기 위해서 발생하는 노이즈 발생 문제를 동시에 해결하기 위한 shape anchor guided learning strategy (AncLearn) 제안
- 제안한 AncLearn는 전체적인 scene understanding을 위한 물체 검출, 레이아웃 추정, 그리고 instance reconstruction을 수행
- 여러 실험을 통해 높은 퀄리티의 semantic scene reconstruction 결과를 입증
2. Method
간단한 파이프라인 먼저 살펴보도록 하겠습니다. Fig.2가 논문에서 제안한 AncRec의 전체적인 프레임워크로 semantic scene reconstruction을 수행하게 됩니다. 먼저 검출 단계에서 포인트 feature을 그룹화 하기 위해 두 개의 브랜치가 존재하는데, 이 두 브랜치에서 물체와 전체 scene을 감싸는 벽에 대한 localization을 수행합니다. 그 다음 물체의 shape anchor을 활용해서 물체의 mesh를 예측하기 위한 instance geometry prior 샘플링을 수행합니다. 마지막으로 찾은 바운딩 박스와 pose에 맞추어 구성한 room 레이아웃에 물체 mesh를 배치하여 semantic scene 모델을 reconstruction하는 것이 전체적인 동작 흐름 입니다.
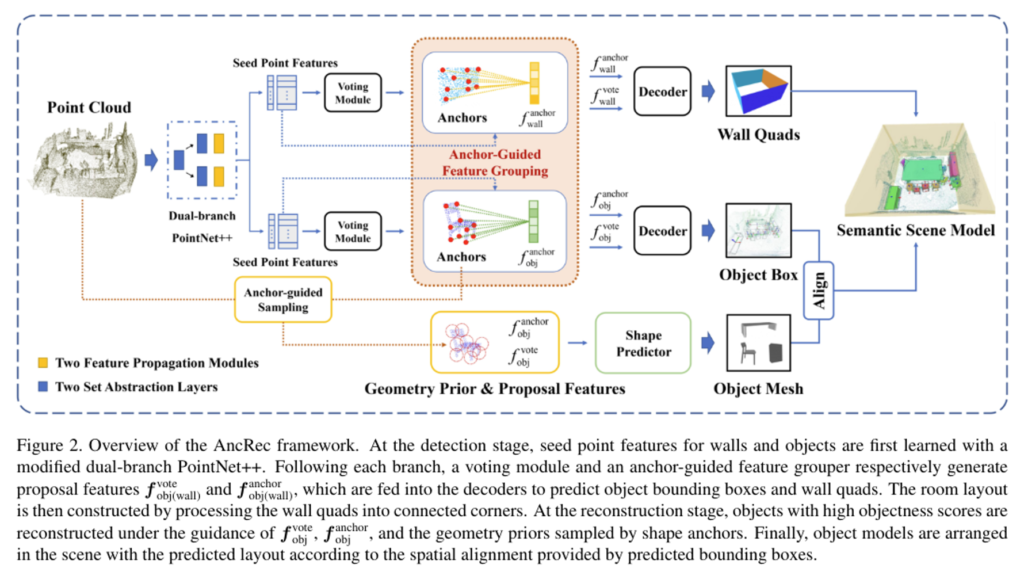
2.1. Shape Anchor-guided Instance Detection
이제 단계별로 자세히 살펴볼건데, 그 중 먼저 그룹화 과정에 대해 설명드리도록 하겠습니다. VoteNet의 네트워크 구조를 두 개의 브랜치로 나누어 한번의 forward를 통해 물체와 벽에 대한 localization을 동시에 수행합니다. VoteNet의 voting 방식은 proposal을 생성하는데 적합하지만, intro에서도 말씀드렷 듯 voting 기반의 예측은 outlier로 인해 낮은 그룹화 결과를 만들기도 합니다. 따라서 강인한 instance 감지를 위해서 중심 feature을 학습하는 anchor 기반의 feature grouper을 설계하였다고 합니다.
2.1.1. Anchor-guided Feature Grouper
Fig.3이 feature Grouper에 대한 설명으로, 벽과 물체에 대한 두 개의 브랜치 중 물체 감지 브랜치를 예시로 들고 있습니다. 해당 알고리즘은 voting 모듈이 포함되어 있으며 결국 방향이 있는 3차원 바운딩 박스를 예측하게 됩니다.
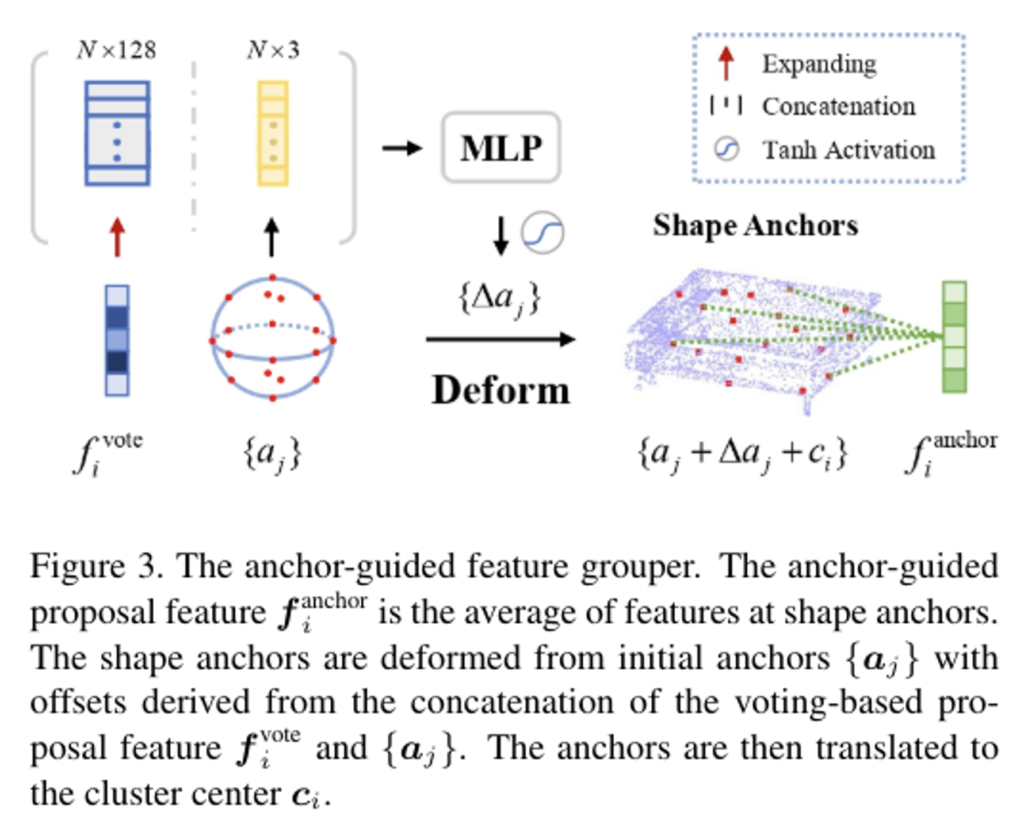
그럼 이제 Grouper의 동작 과정을 단계별로 살펴보도록 하겠습니다.
1단계: Anchor Generation
우선 voting으로 주어진 proposal feature f^{vote}_i \in \mathbb{R}^{128}이 주어지면 Grouper는 i번째 물체 후보 (proposal을 의미)의 shape을 나타내는 shape anchor을 생성합니다. 구체적으로 얘기해보면, 기본적으로 이런 grouping에서 사용하는 게 ball query라고 얘기를 했었습니다. 그 때 사용하는 단위 ball의 표면에서 균일하지만, 랜덤하게 N개의 초기 앵커 A = \{a_j \in \mathbb{R}^3 | j = 1, . . ., N\}를 선택합니다. 이 초기 앵커를 deformation layer를 통해 초기 앵커를 i번째 물체 후보의 표면으로 이동 및 변환하는데, 이는 식(1)과 같이 정의할 수 있습니다.

deformation layer는 MLP와 활성화 함수를 타고 나온 offset \vartriangle a_j만큼 a_j를 이동 시키고 voting 모듈이 클러스터링 해놓은 중심 후보 c_i에 변형된 앵커를 배치하는 것 입니다.
deformation layer의 학습은 식(2)와 같이 정의한 Chamfer ditance loss를 통해 진행됩니다.
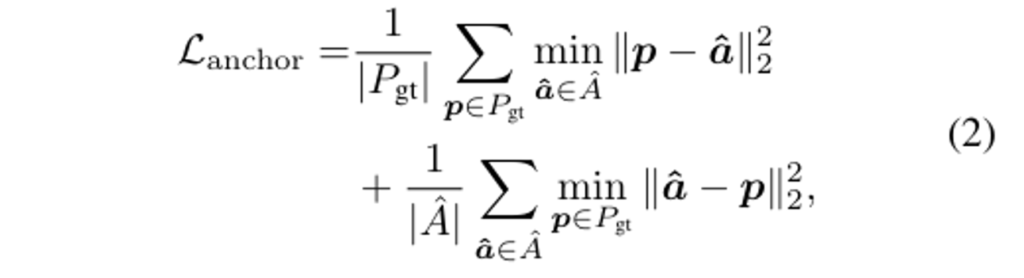
- \hat{A} : scene과 align된 3D mesh
- P_{gt} : scene과 align된 표면 포인트 집합
\hat{A}와 P_{gt}를 통해 각 anchor는 i번째 물체 표면에 맞게 학습될 수 있으며, 클러스터링의 중심인 c_i 역시 gt로 주어지는 표면에 대한 포인트 집합을 통해 개선될 수 있습니다. 또한 전체 표면 포인트를 사용한 supervision으로 인해 가려져서 보이지 않던 구조(가령 바닥 위에 올려져 있는 물체의 바닥 표면)를 커버하기 위한 컨텍스트 정보를 활용할 수 있습니다.
2단계: Feature Grouping
앞선 1단계의 Grouper는 MLP를 통해 시드 포인트 feature, 즉 두 개의 브랜치에서 추출한 feuatre를 각 anchor에 propagation 하게 됩니다. deformed anchor는 Fig.3에서 보이는 것처럼 주로 물체 표면에 위치할 거기 때문에 propagation을 위한 시드 포인트 feature는 물체과 관련된 영역에서 선택할 수 있습니다. 1단계에서는 결국 물체에 대한 각각의 shape anchor \hat{a}_j를 계산하고 2단계에서 그 shape anchor들의 feature을 평균내어 노이즈가 감소한 proposal f^{anchor}_i \in \mathbb{R}^{128}를 얻게 됩니다.
3단계: prediction Fusion
이제 두 개의 디코더를 사용해서 i번째 물체 후보에 대해 f^{vote}_i로 물체 클래스를, f^{anchor}_i로 바운딩 박스 파라미터를 예측합니다. 이렇게 설계한 이유는 voting 기반 proposal인 f^{vote}_i가 여러 context 정보를 고려해서 선정된 반면, f^{anchor}_i는 좀 더 물체 자체에 초점을 맞추었기 때문이라고 합니다. 디코더를 거쳐서 추정된 각 파라미터들은 \Theta^{vote}_i와 \Theta^{anchor}_i로 표시되며, 식(3)과 같이 learnable한 가중치로 평균내어 최종 i번째 물체에 대한 예측 파라미터 \Theta_i를 얻을 수 있습니다.
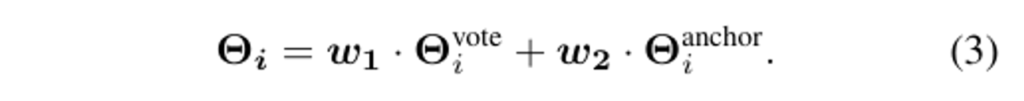
이렇게 3 단계로 나누어져 진행하여 검출된 물체의 속성은 노이즈에 대한 강인함을 가진다고 분석할 수 있다고 하네요. 추가적으로 설명은 물체 검출 브랜치 기준으로 했지만, 벽 instance의 앵커 생성도 유사한 방식으로 동작합니다. 조금 다른 점은 벽은 서로 연결되어 있는 구조이기 때문에 이를 고려하여 attention 연산을 추가해서 정확한 레이아웃 추정을 하고자 했다고 합니다.
2.1.2. The Detection Training Loss
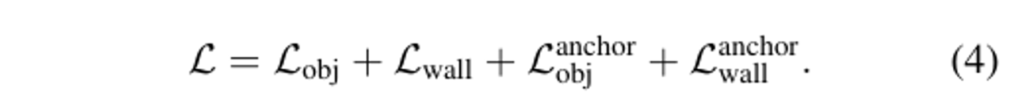
- L_{obj} : 물체 검출 loss
- L_{wall} : 벽 quad loss L^{anchor}_{obj}
- L^{anchor}_{wall} : positive 물체와 벽 후보에 대한 anchor deformation 학습을 위한 supervision loss (Chamfer distance loss)
위의 anchor 기반 instance 검출에 대한 loss는 식(4)와 같습니다.
++ 참고로 벽 quad loss라는 건 indoor scene에서 정확한 벽 구조를 복원하기 위해 사용되며, 벽의 구조를 사분면 혹은 사각형 형태로 모델링하는데 중점을 두게 됩니다.
2.2. Anchor-guided Object Reconstruction
입력 스캔의 instance 포인트는 reconstruction을 위한 기하학적 prior로 사용됩니다. 이전 연구에서는 intro에서 이야기하였듯 instance 포인트 샘플링을 위해 segmentation을 수행했어야 했는데요, 이는 한계점 (2)로 지적한 것처럼 search space에서 물체가 아닌 포인트, 즉 노이즈가 존재하기 때문에 정확한 instance segmentation가 어려워집니다. 그래서 본 논문에서는 shape anchor을 활용해서 노이즈 간섭이 거의 없는 search space를 구성함으로써 물체 포인트 위치를 파악할 수 있도록 하였습니다.
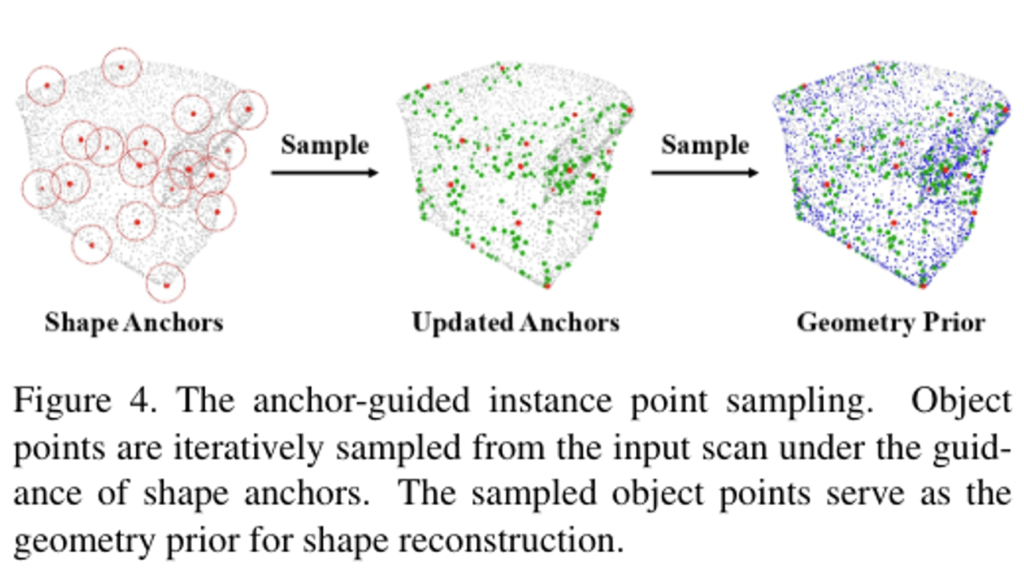
구체적으로 Fig.4와 같이 살펴보면, 먼저 원본 scene에 대한 스캔에다가 검출 단계에서의 positive shape anchor를 추가하여 물체의 구조적인 정보를 추가합니다. (Shape Anchors)
shape anchor가 추가된 스캔에서 각 앵커를 기준으로 특정 반경 내에 있는 포인트를 선택하는데, 선택한 포인트들은 해당 앵커 집합에 포함되며 search space를 확장하게 됩니다.
이를 반복적으로 수행하면 결국 물체의 shape을 따라 기하학적인 prior를 완성할 수 있습니다. (Updated Anchors → Geometry Prior)
이런 앵커 기반 샘플링은 search space를 물체 shape에 딱 맞게 조정해주면서 별도의 segmentation 모듈 필요없이 물체의 shape을 효율적으로 생성할 수 있습니다. 실험에서는 샘플링 반경을 앵커 사이의 최소 거리로 설정하여 샘플링 과정을 두 번 반복하였다고 합니다.
이렇게 생성한 Geometry prior는 대응하는 proposal feature f^{vote}_{obj}와 f^{anchor}_{obj}와 매칭되고 ResPointNet이라는 네트워크를 통해 shape 임베딩 feature f^{shape}_{obj}를 인코딩 합니다. f^{shape}_{obj}를 디코더의 입력으로 넣어 canonical 좌표에서 쿼리 포인트의 거리를 예측합니다. 이러한 과정을 마치고 나면 마지막으로 Constructive Solid Geometry (CSG)라는 기법을 사용해서 shape 표면을 추출하게 됩니다.
2.3. Semantic Scene Reconstruction
여기까지 진행되고 나면 instance detector와 shape predictor의 앵커 기반 결과를 통해 semantic scene 모델을 구성할 수 있습니다. 먼저 병합 기법을 사용해서 검출한 벽 quad를 모서리를 연결하여 공간 구조를 구축합니다. 그 다음 objectness가 높은 물체 모델을 선택해서 예측된 3차원 바운딩 박스에 align을 맞추어 구축한 공간 내에 배치합니다. 그럼 재구성한 레이아웃과 scene에 align 맞는 물체 shape 조합으로 구축할 수 있는 것 입니다.
3. Experiments
3.1. Experiment Settings
3.1.1 Dataset
본 논문의 실험은 indoor scene understancing을 위해 Scan2CAD와 SceneCAD 데이터셋을 GT로 ScanNetV2에서 진행하였습니다.
(1) ScanNetV2
- 1513개의 indoor 포인트 클라우드로 구성된 벤치마크 데이터셋
(2) Scan2CAD
- 방향 정보가 포함된 3차원 바운딩 박스를 사용해서 ShapeNet 모델을 ScanNet의 해당 물체 instance에 일치시키며 align 맞추는 데이터셋
(3) SceneCAD
- ScanNetV2 scene을 스캔해서 3D 레이아웃 어노테이션 제공
4.2. Comparison and Analysis
Scene Reconstruction
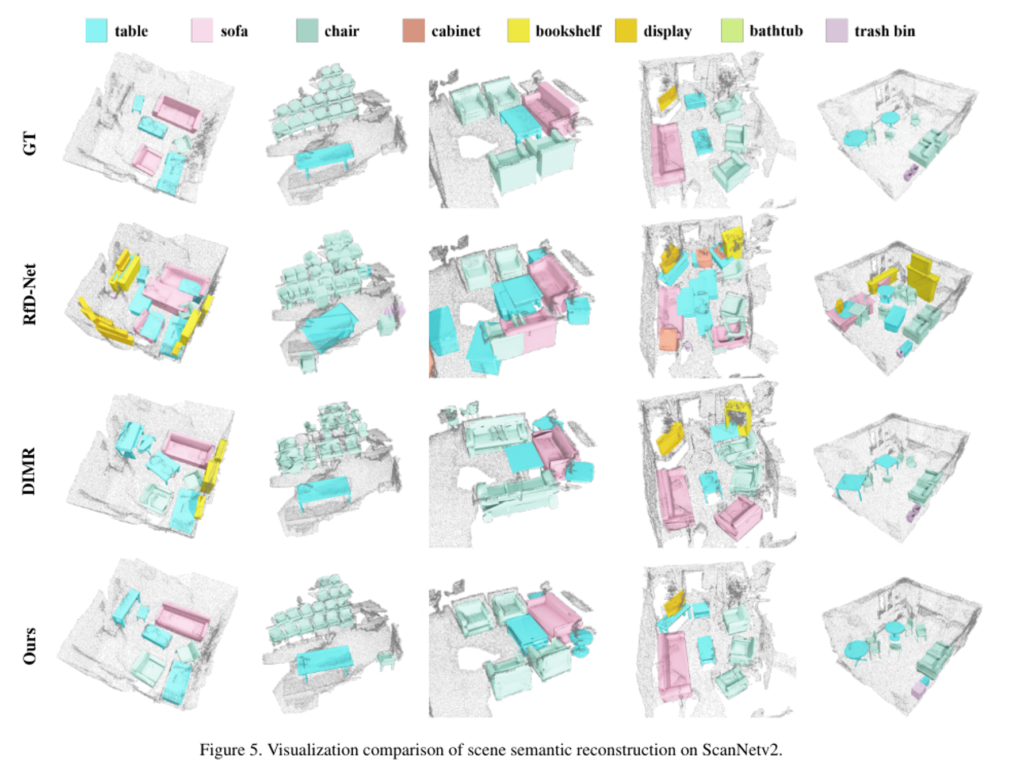
비교할 방법론으로는 RfD-Net과 DIMR을 선택하였는데, RfD-Net은 VoteNet의 voting 모듈로 생성한 proposal에서 segmentation을 통해 instance 포인트로 물체의 shape을 예측합니다. 반면 DIMR은 복잡한 instance segmentation 백본을 타고나온 instance 포인트로 물체 모델을 형성하게 되죠.
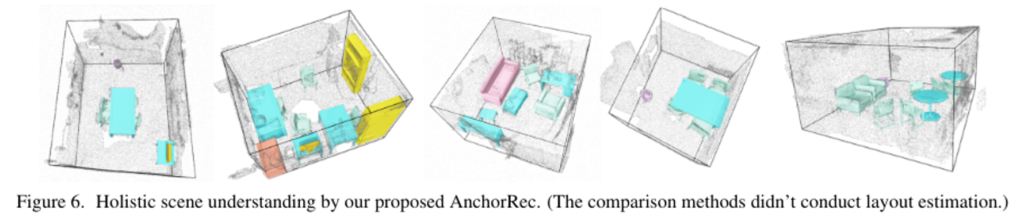
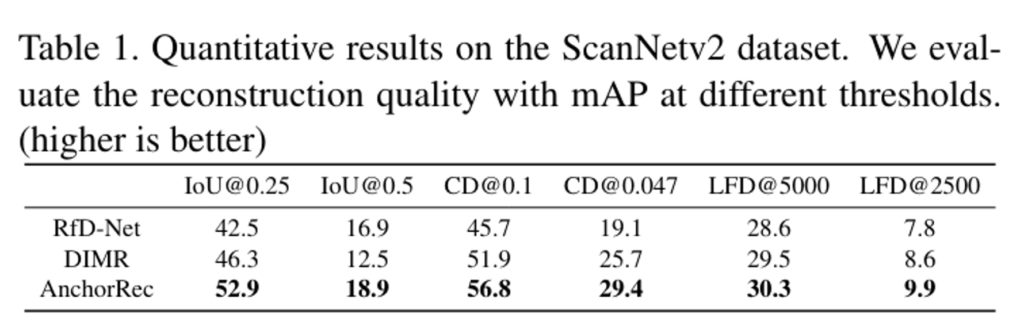
Fig.5를 먼저 보면 본 논문에서 제안한 AncRec는 노이즈가 많은 포인트에서 물체를 안정적으로 찾아내고 reconstruction하여 물체에 대한 정확한 localization과 shape을 제공하고 있습니다. 또한 AncLearn이 물체에 초점을 맞춘 proposal의 feature 학습 방식은 다른 비교 방법론들보다 잘못 검출하여 생성한 모델이 더 적은 것을 확인할 수 있습니다. Tab.1은 정량적 비교를 보여주는데, 모든 평가 메트릭에서 AncRec이 SOTA를 달성하고 있습니다. 타 방법론들은 레이아웃 추정을 수행하지 않았기 때문에 Fig.6을 통해 정성적으로 scene understanding 결과를 보여주고 있습니다.
semantic scene reconstruction은 굉장히 상위 레벨의 task이기 때문에 downstream task 중 scene parsing과 object reconstruction에 대해서 추가적인 실험을 진행하였다고 합니다.
Scene Parsing
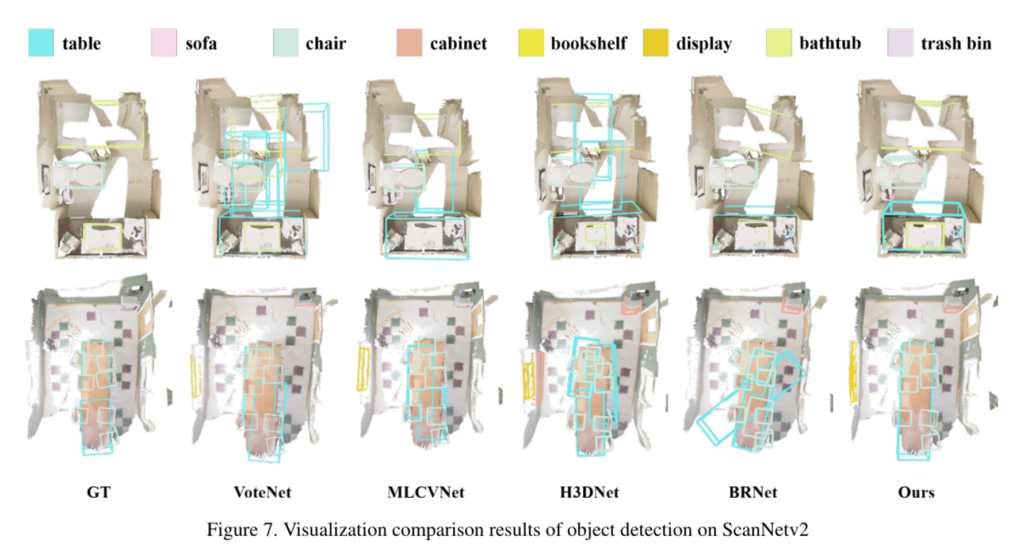
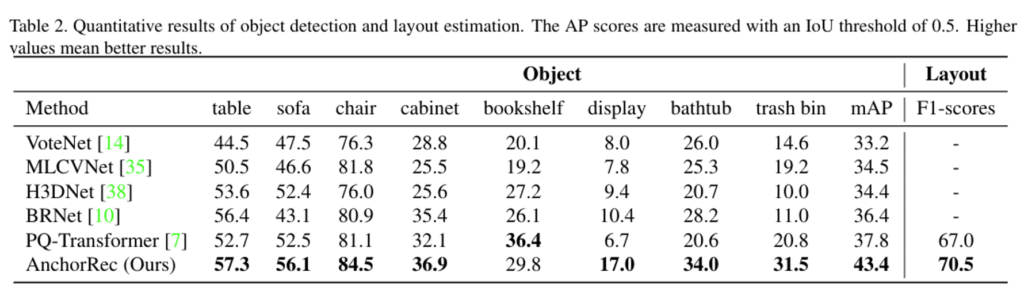
8개의 클래스 물체 검출과 레이아웃 추정에 대해서 최신 방법론들과 비교하고 있습니다. Tab.2를 보면 bookshelf를 제외한 타 클래스에서 모두 성능 향상을 이루었으며 특히 디스플레이, 욕조, 그리고 쓰레기통은 큰 폭을 가지고 성능이 개선된 것을 확인할 수 있습니다. 이러한 결과에 대해 저자는 이전에 고정된 범주의 그룹화가 아닌 AncRec를 통해 flexible한 그룹화를 수행하면서 다양한 크기와 불규칙한 shape을 가진 물체를 감지하는데 효과적으로 작동할 수 있었다고 분석하고 있습니다.
또한 레이아웃 추정도 최신 방법론인 PQ-Transformer와 비교하여 개선된 성능을 보여주는데, 그 과정에서 크고 얇은 벽을 localization 하는데도 적용할 수 있었다고 합니다.
Object Mesh Reconstruction

Tab.3은 클래스 별 물체 reconstructio에 대한 성능을 평가한 실험 입니다. 평가는 예측한 물체 mesh가 scene에 align된 GT와 얼마나 일치하는지가 기준이 됩니다. 결과적으로 5가지 클래스와 전체 mAP에서 우수한 성능을 보였는데요, 다른 task에 비해 이전 방법론들과 큰 차이를 두지 못하는데 이에 대한 저자의 분석이 없는 점이 아쉽네요 ..
3.3. Ablation Studies
AncLearn for Object Reconstruction
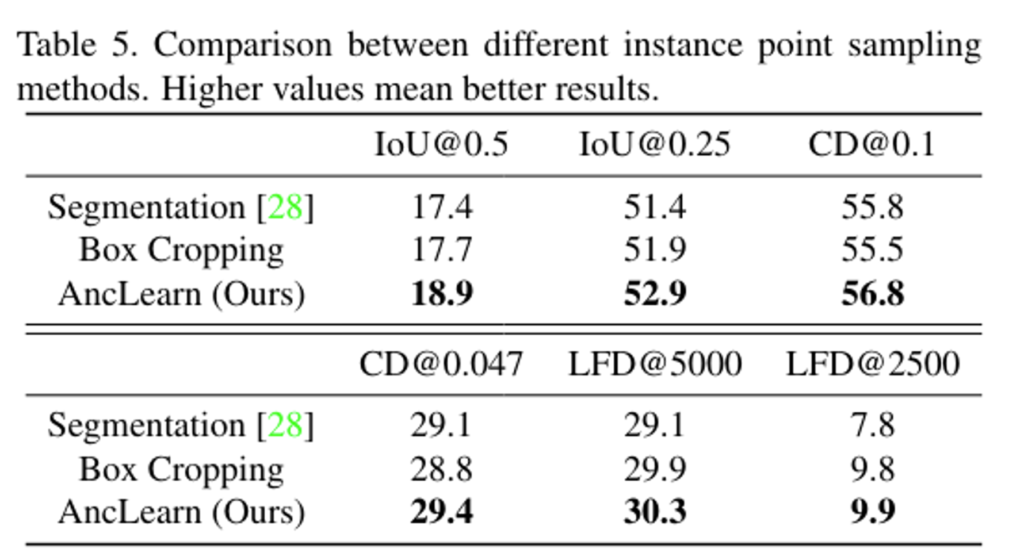
AncRec의 shape predictor에서, recosntruction을 위한 geomety prior으로 instance 포인트를 샘플링하는 작업을 수행합니다. AncRec의 instance 검출기를 사용해서 AncLearnd르 RfD-Net에서 사용되는 segmentation 및 박스를 crop하여 샘플링하는 방식과 비교하고 있습니다. Tab.5를 통해 모든 메트릭에서 AncLearn이 유용한 geometry prior를 활용함으로써 이전 방법론들보다 개선된 결과를 보여주고 있는 것을 확인할 수 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
1. semantic scene reconstruction 테스크 자체를 제가 잘 몰라서 질문을 드립니다. 식 (1) 같은 경우 tanh과 같은 활성화 함수를 사용하는 특별한 이유가 있나요?
2. segmentation을 수행하기 위해 anchor에 대한 guide가 되게 중요해 보입니다. 그럼 해당 논문에서 사용하는 detector는 무엇인가요? 선행연구인 BRNet에서 사용한 것과 동일한 detector를 사용하는 건가요? 잘 찾아야 적절하게 segmentation을 수행할 것 같은데 SAM과 같은 foundation 모델을 사용하는 건가요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. tanh와 같은 활성화 함수를 사용한 것은 scene reconstruction task 때문에 사용한건 아니고 단순 deformation layer 구조 구성이라고 이해해주시면 좋을 것 같습니다.
2. detector는 여기서 포인트 클라우드가 들어오면 두 개의 브랜치 (PointNet++)을 사용해서 벽과 물체에 대한 각각의 voting 모듈을 통해 물체 anchor feature을 찾는 과정을 의미합니다. voting은 VoteNet 방식을 그대로 들고왔고, 여기서 RGB 이미지를 사용하는건 아니기 때문에 SAM과 같은 foundatio model을 사용하진 않습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문 리뷰를 읽으면서 anchor가 굉장히 중요한데, 초기에 anchor가 어떻게 만들어지는지에 따라서 성능이 매우 달라질수도 있지 않을까 라는 생각을 하였습니다. 여기에 추가로 초기 앵커 수에 따라서도 성능 변화가 매우 클 것 같다는 생각도 하였는데, 이와 관련한 성능 리포팅은 없을까요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
초기 anchor를 만드는 방식은 논문에서는 ball 표면에서 랜덤하게 N개의 앵커를 뽑는다고 말했었는데, 추가적인 언급은 없었지만 제 생각에는 아마 Farthest Point Sampling(FPS)를 사용한 것 같습니다. 해당 방법이 포인트에 대해서 가장 표면의 shape을 잃지 않고 샘플링할 수 있는 방식인데요, 제 생각에도 샘플링 개수에 따라서는 어느 정도 성능 변동이 있을 것 같습니다. 그렇지만 아쉽게도 이와 관련된 ablation study는 리포팅되어 있지 않았습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
물체를 대상으로 voting하는 과정에 대해서는 이해가 되는데 이를 벽으로 바꿔서 생각해보니 잘 이해가 되지 않아 질문드립니다… 벽은 물체와 같이 어떤 표면이라는 속성이 굉장히 애매하다는 생각이 드는데, 벽에 대해서도 동일하게 위에 답글에서 말씀해주신거처럼 FPS라는 과정을 통해 포인트가 샘플링이 되는걸까요 ?!?? 물체의 feature라고 할 만한 부분이 벽에서는 두드러지지 않는데 물체 voting과 마찬가지로 잘 워킹하는지 의문이 듭니당 .
감사합니다 !