안녕하세요,
이번에는 6D pose estimation 테스크 중 category-level object pose estimation 관련 논문을 읽어보았습니다. 이번 Zero123-6D는 제목이 좀 특이 하긴 하네요. 이름을 왜 저렇게 지었는지는 언급이 없어 저도 잘 모르겠네요. 아무튼 이번 논문은 사전학습된 diffusion 기반 모델의 출력을 NeRF 기반의 모델의 입력으로 사용하여 3D CAD 모델을 얻을 수 있습니다. 이러한 view synthesis를 활용하는 방법론들이 많이 제안되고 있는 것 같습니다. NeRF가 아닌 최근에는 Gaussian splatting까지 최근에는 접목이 되는 추세입니다. 이렇게 multi-view geometry를 활용한 reconstruction을 통해 3D CAD 모델을 만들고, 이를 통해 6D pose를 추정할 수 있으므로, multi-view 정보만 줄 수 있다면 활용도는 무궁무진 할 것으로 보입니다.
Introduction
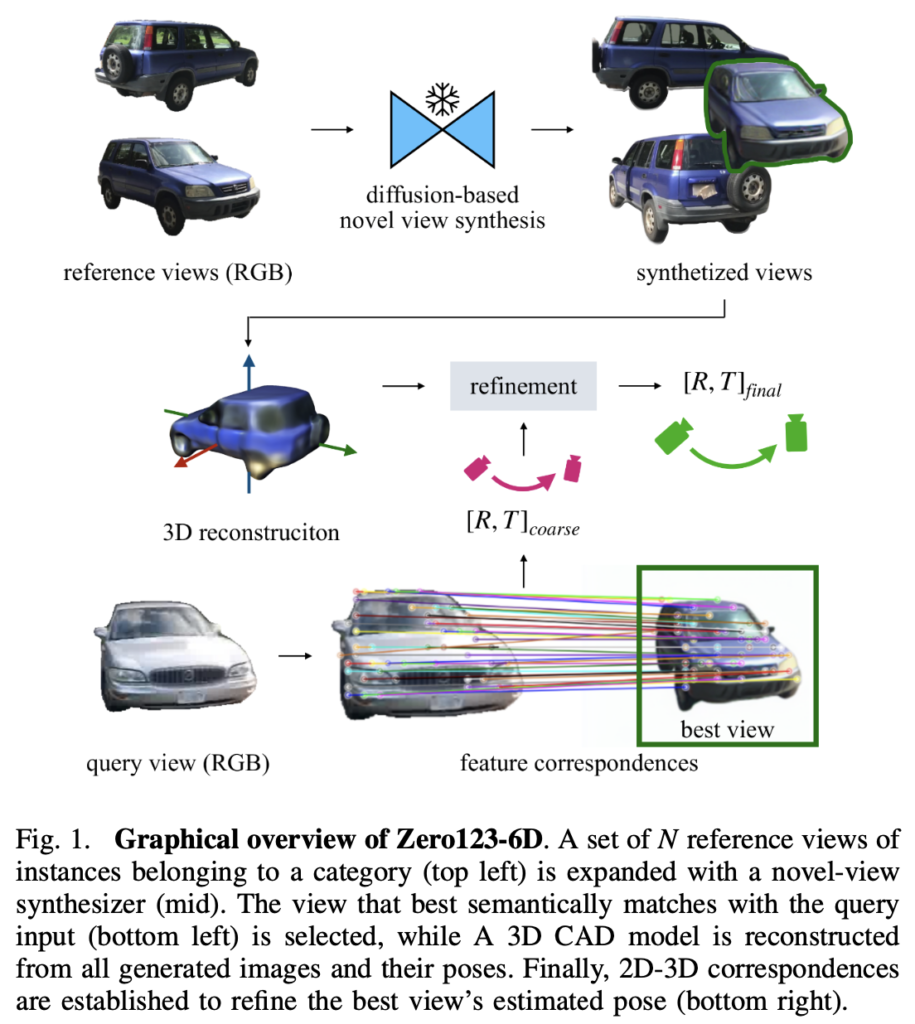
6D pose를 추정하는 것은 물체의 정확한 3차원 상 위치와 방향을 결정하는 여러 테스크에 포함됩니다. 해당 테스크는 로봇공학 및 증강현실을 포함한 수많은 어플리케이션에서 매우 중요한 역할을 하고 있습니다. instance-level pose 추정은 3D CAD 모델에 의해 제공되는 사전 지식이 있는 상태에서 동작하므로 CAD 모델에 매우 의존적이라고 볼 수 있습니다. 따라서, 수동으로 annotation을 해야하는 입장에서는 비용이 많이 들긴하죠. 반복적인으로 작업을 수행하는 산업 현장 외로 실생활에 사용되기에는 instance-level은 적절하지 않습니다.
대안으로 category-level에서의 pose 추정이 떠오르면서 물체에 대한 instance의 지식이 필요하지 않으며 동일한 클래스의 물체 전체에 걸쳐 모델을 일반화할 수도 있습니다. 이러한 category-level pose 추정은 지금까지도 꾸준히 연구가 되고 있으며, 최근 foundation 모델이 떠오르면서 새롭게 이를 활용한 방법론들이 제안되고 있습니다.
그렇게 foundation 모델을 활용하여 서로 다른 인스턴스 간의 의미론적인 상관관계를 생성함으로써 이러한 문제를 해결하려고 연구가 되고 있습니다. 선행 연구에서는 두 물체 사이의 특징 공간에서의 alignment는 pose alignment로도 이어진다는 사실을 입증하였습니다. 하지만, 단일 query 이미지와 가장 잘 alignment가 맞춰지는 reference view를 찾는 것은 쉽지 않겠죠. 이러한 한계점을 해결하기 위해 이번 Zero123-6D에서는 Zero-shot novel-view RGB synthesis를 위해 사전학습된 diffusion 모델을 사용하여 referecne view를 확장하여 사용할 수 있도록 합니다. CAD 모델을 reconstruction 하는 과정을 제외하고 해당 프레임워크에서는 학습 과정이 필요가 없습니다. 전체 파이프라인은 물체에 대한 단일 이미지(query)와 같은 카테고리의 reference 물체에 대한 sparse하게 존재하는 RGB 이미지만 있으면 됩니다. 이후 foundation 모델을 사용하여 feature간 대응을 생성하여 pose를 추정하게 됩니다.
contribution을 정리하면 다음과 같습니다.
- Zero-shot novel view synthesis를 위한 diffusion 모델을 활용하여 reference view를 증강시킴
- 선행 연구를 개선한 monocular RGB category-level pose 추정 방법론
- synthesis view를 활용하여 얻은 depth 정보를 활용하여 refinement 수행
Method
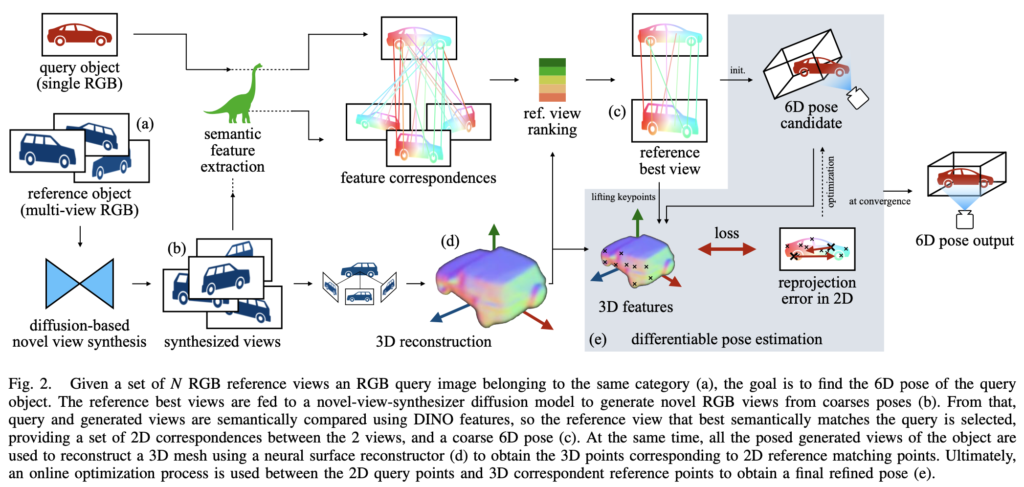
이번 Zero123-6D의 동작과정은 다음과 같습니다.
- RGB 이미지를 N개의 멀티뷰로 구성하고, 사전 학습된 diffusion 모델을 사용하여 Novel view synthesis를 얻음. 이를 reconstructor인 NeuS의 입력으로 주어 3D CAD 모델을 얻음
- DINOv1를 통해 reference 물체와 대상 물체 간 의미론적인 correspondence를 생성하여 매칭을 수행하여 가장 적절한 시퀀스(M, N개의 멀티뷰로 이루어진 집합으로 이해하시면 됩니다.) 내 이미지를 선택함. 이를 통해 coarse한 pose 추정치를 얻음
- 3D reference ↔ 2D query 간의 correspondence를 이용하여 coarse pose를 refinement 하는 과정을 수행함.
이를 정리하면 위 그림(2)와 같이 나타낼 수 있습니다.
Novel view synthesis
novel view synthesis를 생성하기 위해 이번 논문에서 사용한 모델은 diffusion 모델 기반인 EscherNet을 사용했다고 합니다. 특정 카메라 pose를 가지는 물체에 대한 1개 이상의 RGB 뷰와 내가 알고자하는 카메라 pose를를 가지는 시퀀스 viewpoint를 입력으로 주면 EscherNet에서 특정 pose에서 novel view synthesis를 생성할 수 있다고 합니다. 각 viewpoint를 생성하는 것은 입력으로 들어가는 RGB viewpoint와 해당 viewpoint에 대한 pose가 있을텐데요. 결국 이 입력으로 주는 camera pose에 대한 relative transformation에만 의존한다고도 볼 수 있을 것 같습니다. 이러한 diffusion 모델로부터 생성 과정이 끝나면 RGB 이미지와 global camera pose가 존재하는 시퀀스 M에 대해 reconstruction을 수행합니다. 여기서 사용되는 reconstructor는 NeuS라고 하네요. 해당 모델로부터 생성된 뷰포인트(reference)와 관련된 깊이 정보를 추출하고 pose를 개선하는 것에 유용하다고 합니다.
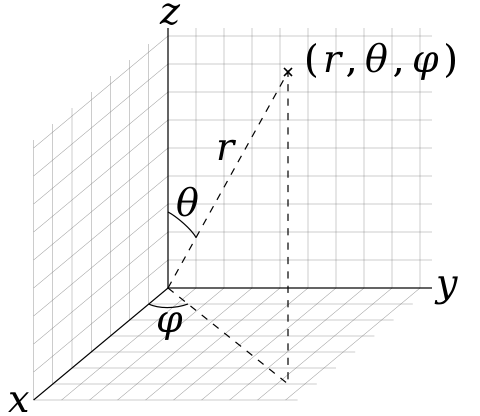
카메라 pose는 물체가 좌표계의 원점에 중심을 두고 있다고 가정하는 spherical 좌표계를 사용하며, 해당 좌표계에서 카메라의 위치는 각각 \theta, \phi, r(극값, 방위각, 반경)으로 나타낼 수 있습니다. 미적분학에 극좌표를 많이 다루었으니 비교적 친근한 좌표계인데요.
두 카메라의 위치를 각각 (\theta_{1}, \phi_{1}, r_{1}), (\theta_{2}, \phi_{2}, r_{2})라고 가정해봅시다. 그럼 두 카메라 사이의 relatative camera transformation은 각 변수에 대한 차로 계산할 수 있습니다. 즉, (\Delta \theta=\theta_{2}-\theta{1}, \Delta \phi=\phi_{2}-\phi_{1}, \Delta r=r_{2}-r_{1}) 로 표현할 수 있겠네요.
Feature extraction and view extraction
앞서 diffusion 모델을 사용하고 reconstructor를 RGB 이미지들을 렌더링 할 수 있었습니다. 이후 각각에 대한 의미론적인 특징을 추출하는 과정인데요. DINOv1을 사용하여 같은 클래스의 물체 간 의미론적 관계가 적용되는 category-level 테스크에 적합하다는 저자의 주장인데, related works에는 DINOv2를 언급하지만, 방법론에서 DINOv2를 적용하지 않은 이유에 대해서는 언급하고 있지 않습니다.
파운데이션 모델인 DINOv1을 사용하여 의미론적인 feature를 query 이미지 \mathbf {I_{q}}와 reference(synthetic view) \mathbf {I_{r}}에 대해 특징을 추출합니다. 이를 통해 soft nearest neighbor(SNN) 연산을 통해 query와 매칭되는 항목들을 설정하는 것에 활용할 수 있었다고 합니다.
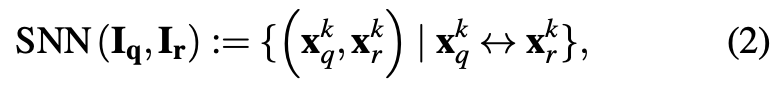
\mathbf x_{q}^{k} \leftrightarrow \mathbf x_{r}^{k}는 query와 reference에서 SNN을 수행했을 때 결정되는 Top k개의 correspondence에 대한 2D 픽셀 좌표입니다. k개의 대응은 추출된 query feature와 reference feature를 사용하여 계산됩니다. 그럼 sorting은 어떻게 진행한 걸까요?
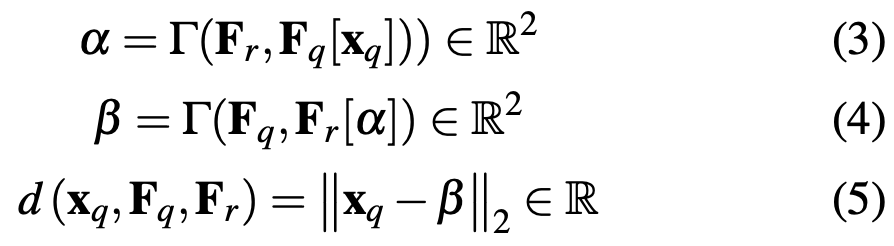
최종적으로 식(5)의 d를 통해 결정이 되게 되는데요. \mathbf F_{j}[\mathbf x_{j}]는 feature와 대응되는 좌표를 의미하고 여기에 function을 의미하는 \Gamma를 태워 특징 벡터 공간에서 가장 가까운 점을 찾는 것입니다. \alpha, \beta를 각각 찾은 다음 d를 통해 오름차순으로 \mathbf x_{k}^{q}를 정렬합니다.
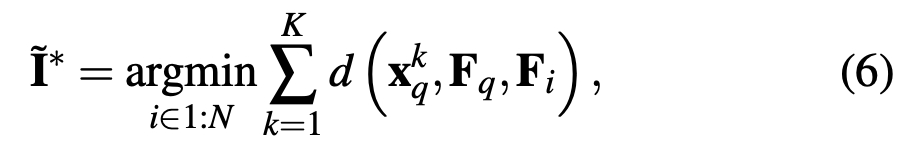
이후, query에 대한 뷰포인트와 reference 뷰포인트 간 Top k개의 가장 적절한 correspondence를 활용하여 식(6)을 통해 reference 집합에서 best 이미지 \mathbf I_{r}^{*}를 선택합니다. 이를 통해 query에 가장 가까운 reference 뷰포인트로부터 coarse pose를 얻을 수 있으며 이는 이후 반복적인 refinement를 수행하는 것에 사용되게 됩니다.
6D pose refinement
지금까지 설명한 6D pose를 추정에는 주요한 문제가 있는데요. RGB 이미지 정보만을 이용하여 pose를 추정했으므로 reference 이미지에 대한 깊이 정보를 활용하지 않았다고 볼 수 있습니다. 저자는 diffusion 모델인 EscherNet을 통해 멀티뷰를 합성한 Nerf 기반의 reconstructor인 NeuS을 활용하여 ray-marching 알고리즘을 사용하여 3D mesh를 생성할 수 있으므로 이를 활용하였다고 합니다. 해당 mesh에서 reference 집합에는 camera pose가 있으니 해당 camera pose에 대해 3D CAD를 렌더링하면 간단히 RGB 이미지와 align된 깊이 영상을 얻을 수 있습니다.
(Ray-marching : 컴퓨터 그래픽스에서 3D 장면을 렌더링하는 기법이라고 합니다. 물체의 경계가 명확하지 않은 상황에서 유용하게 사용된다고 하네요.)
위와 같은 과정을 통해 refinement를 어떻게 하였는지 살펴보겠습니다.
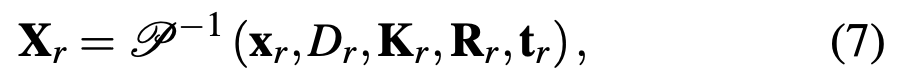
식(7)은 reference 이미지 I^*{r}에 대한 depth 이미지 \mathbf D{r}, 내부 파라미터 \mathbf K_{r}, 외부 파라미터 \mathbf R_{r}, \mathbf t_{r}가 주어졌을 때, matching이 이루어진 2D correspondence 집합 내 각 점 \mathbf x_{r}은 3차원으로 투영하도록 하는 의미를 나타내고 있습니다. 이렇게 간단히 2차원의 점들을 3차원으로 차원을 하나 올려주어 feature matching을 수행함으로써 coarse pose를 refinement 할 수 있습니다. 이전 방법론들은 Umeyama 알고리즘을 통해 3D-3D correspondence 매칭을 통해 aligment를 맞추는 수행할 수 있었겠지만 이번 방법론에서는 query 이미지에는 단일 RGB 영상만을 사용하므로 depth를 사용할 수 없습니다. 따라서, 2D-3D correspondence를 활용하는 방법을 사용해야겠네요. 단순히 반복하는 절차를 진행하는 것이 아니라, 학습가능한 최적화 알고리즘을 적용하였다고 합니다.
결국 최적화를 푸는 목적은 rotation, translation을 잘 하는 것입니다. 즉, 각 correspondence \mathbf X_{r} \leftrightarrow \mathbf x_{q}가 주어졌을 때 \mathbf r_{q}, \mathbf t_{q}를 최적화하는 것입니다. [1]에서는 불연속성이 없는 3차원 유클리드 공간에서는 회전을 파라미터화 할 수 없으므로 더 적절한 표현을 제안합니다. [1]에서 제안한 표현의 연속성은 수치를 최적화 하는 맥락에서 축에 대한 각도 또는 쿼터니언 보다 더욱 우수한 성능을 제공하는 것 뿐만 아니라 단위 행렬식을 가지는 3×3 크기의 직교 행렬보다 더욱 간단하게 표현할 수 있다고 합니다.
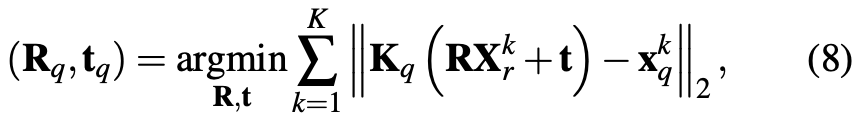
위 식(8)을 통해 matching된 점들에 대한 2D로 projection시켜 잔차를 계산하면서 rotation, translation을 모두 최적화를 진행합니다. 이러한 반복적인 과정을 최적화 함수인 Adam을 활용하여 [1]에서 제안한 표현을 사용함으로써 해당 pose 파라미터를 최적화하면서 점차 정렬을 하는 방식입니다.
[1] Y. Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 5745–5753.
Experiments
정량적 실험은 real-world에서 촬영된 CO3D(Common Objects in 3D) 데이터셋을 사용하였다고 합니다. 이는 150만개의 annotation 정보, 50개의 카테고리로 구성되어있습니다. CO3D 데이터셋의 평가데이터로 선택된 카테고리는 자전거, 자동차, 의자, 노트북, 오토바이를 선택했다고 하네요.
평가에는 rotation error에 대한 중앙값과 정확도가 포함됩니다. 정확도 같은 경우 rotation이 특정 threshold(해당 실험에서는 15, 30으로 선택) 이하로 떨어지는 추정치의 백분율로 계산됩니다. 결과는 카테고리별 및 모든 카테고리의 평균으로 나타냅니다. 또한, 저자는 제안한 방법론이 다양한 RGB 데이터셋에서 일반화할 수 있는 능력을 강조하기 위해 Objectron 데이터셋에서 정성적인 결과를 제시합니다. 식(8)에서 사용되는 반복적인 최적화 과정은 1000번을 수행한다고 하네요. 여기서 가장 오래 걸리는 과정은 3D CAD 모델을 생성하는 과정이긴 하나, 저자는 카테고리당 한 번만 수행하면 되는 과정이므로 어플리케이션 측면에서 봤을 때 실시간 요소에 영향을 미치지 않을 것으로 고찰을 하고 있습니다.
Quantitative results
저자는 방법론의 정량적 성능을 분석하기 위해 두 가지의 비교를 수행합니다. “선행 연구인 ZSP[2]의 depth를 사용하지 않는 버전과 비교하여 rotation error를 줄이는 데 있어 제안한 접근 방식이 성능의 향상이 있는지”와 “ZSP에서 depth를 사용하는 버전을 사용함으로써 제안한 방법론과의 성능 차이”를 비교합니다.
[2] W. Goodwin, S. Vaze, I. Havoutis, and I. Posner, “Zero-shot category-level object pose estimation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2022.
Comparison against depth-free approach
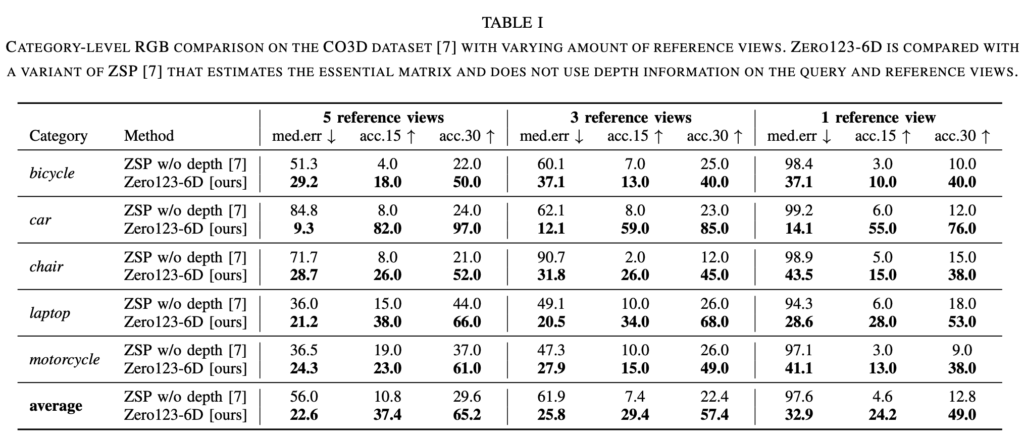
표(1)은 모든 CO3D 카테고리에 대한 전체적인 비교를 나타내고 있습니다. reference view가 하나만 있는 경우(가장 우측 열)에도 모든 지표에서 우수한 것을 볼 수 있습니다. 이러한 성능을 낼 수 있었던 이유는 zero-shot novel view synthesis를 통해 dense한 viewpoint 집합의 부족을 효과적으로 보완할 수 있었다고 볼 수 있을 것 같습니다. 또한, mesh를 reconstruction 과정하는 과정에서는 reference view에 대한 dense한 depth를 얻을 수 있으므로 이를 통해 robust한 2D-3D correspondence를 생성하여 최종적으로 refinment를 거친 pose를 얻을 수 있습니다.
Comparison against RGB-D approach
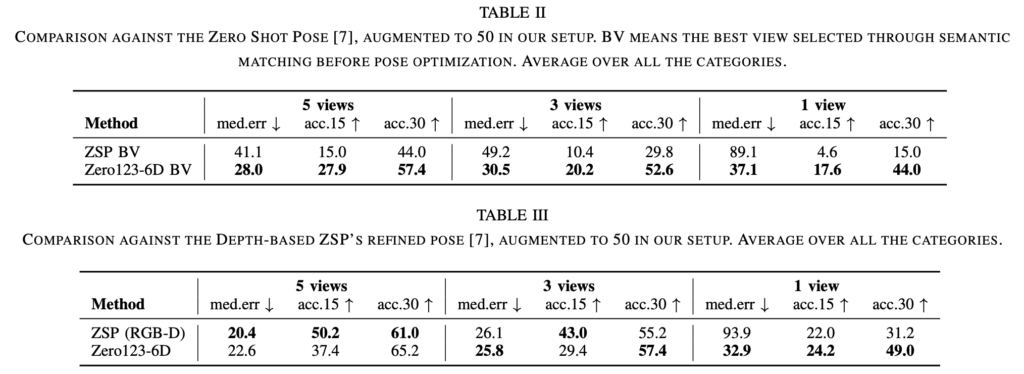
만약, query와 reference 둘 다 depth를 사용할 수 있는 경우에 대해 살펴보겠습니다. 표(2)의 BV(Best Viewpoint)는 matching 이후 가장 가까운 특징에 대해 선택된 이미지로 보시면 되겠습니다. 표(2)와 표(1)의 마지막 행과 비교하면 합성 이미지에서 해당 best viewpoint를 선택함으로써 depth를 사용하지 않는 ZSP보다 훨씬 우수한 성능을 보여주고 있네요.
또, 표(2)를 보면 diffusion 모델을 사용한 view synthesis를 통해 matching 과정에서 더 많은 이미지를 사용할 수 있으므로 ZSP에서는 최적의 뷰를 선택하는 방법보다는 결과를 크게 개선한 모습을 볼 수 있습니다. 동시에 이는 실제 이미지와 생성된 이미지 사이(sim-to-real)에 대한 갭 차이를 줄이는 효과도 있으므로 diffusion 모델이 해당 테스크에서 효과적이라는 것을 입증합니다.
표(3)에서 5개의 뷰포인트를 사용하는 경우, ZSP가 성능이 살짝 앞서는 모습이지만 viewpoint 개수가 줄어들수록 저자가 제안한 방법론이 오히려 성능면에서 더욱 앞서는 것을 확인 할 수 있습니다. Zero123-6D는 단 하나의 reference view만 사용할 수 있을 때 ZSP를 앞서버리네요. 3개의 view에서 1개의 view로 줄이니, 물체의 3D 구조를 적절히 이해하는 것으로 보이네요. 이를 보았을 때, depth cue가 적은 view에서는 보완하기에는 힘들어보이네요. 이를 통해 한계점은 물체에 대한 멀티뷰를 확보하기 어렵거나, 카메라가 고정된 경우에서는 문제가 될 수도 있을 것으로 보입니다.
Qualitative results
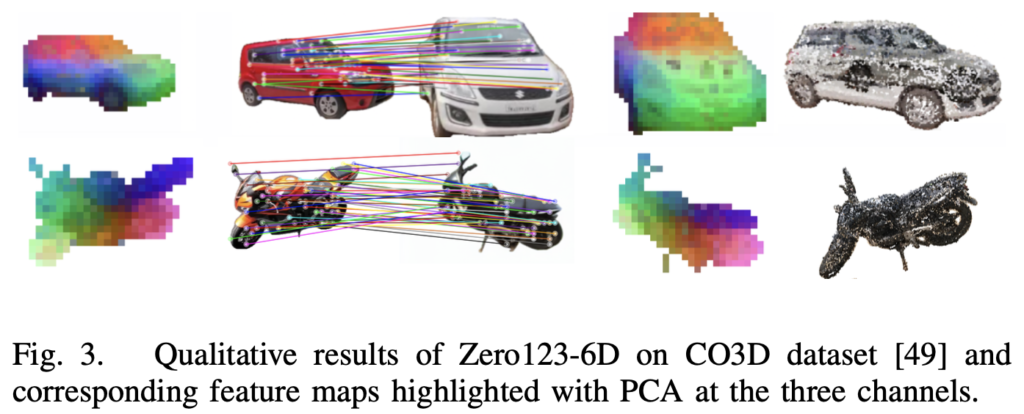

마지막으로 정성적 결과입니다.
그림(3)은 인스턴스에 대한 feature map과 그에 대한 best view를 보여주고 있습니다. best view에 대한 matching은 DINO를 통한 feature가 제공하는 의미론적 정보를 통해 가능하므로 PCA를 통해 시각화한 것으로 보면 되겠습니다. 추가적으로 그림(4)는 Objectron 데이터셋에서의 정성적 결과를 보여주고 있습니다. 해당 데이터셋은 CO3D 데이터셋과 다르게 RGB에 대응되는 depth가 없으므로 저자는 해당 결과를 통해 자신이 제안한 방법론에 대해 다시 한 번 강조하네요. 복잡한 시나리오에서 pose 추정을 위한 view synthesis을 통해 생성한 물체를 사용함으로써 유망한 연구 방향을 제시합니다.
Conclusion
이번 Zero123-6D는 단일 query 이미지와 같은 클래스에 속하는 RGB 이미지셋으로부터 category-level에서의 pose 추정을 수행하는 파이프라인을 제안합니다. zero-shot diffusion 모델과 NeRF-based reconstructor를 사용하여 3D CAD 모델을 얻을 수 있었습니다. 이후 DINO를 통해 correspondence를 얻어 이후 최종적인 refine된 6D pose를 얻을 수 있었습니다.
이상으로 리뷰 마치겠습니다.
감사합니다.
좋은 리뷰 감사합니다.
Zero-1-to-3라는 논문이 novel view synthesis 분야에서 꽤나 관심을 끌고있는 방법론 인 것으로 알고있는데
이를 6D Pose Estimation에 적용하여 논문 이름이 Zero-123가 아닐까 합니다.
해당 방법론이 category-level의 방법론이라고 하셨는데, diffusion-based novel view synthesis에 들어가는 reference object들은 특정 카테고리에 대한 여러 인스턴스들로 구성되어있는 것 인가요?? 만약 그렇다면 서로 다른 인스턴스들을 이용하여 생성된 novel view synthesis 결과는 일관성이 있을 지 궁금하고, 만약 그렇지 않다면(객체를 대표하는 인스턴스 하나라면) 대표적인 인스턴스를 선별하는 과정이 중요할 것 같은데 이를 고려하는 과정은 따로 없는 지 궁금합니다.
추가로 , 3D reconstruction 결과 만들어진(d) 3D feature는 NOCS와 같은 역할인가요??