이번 리뷰는 NeRF를 이어 Novel View Synthesis 분야에 큰 획을 그은 3D Gaussian Splatting (3DGS)에 대해서 다루고자 합니다.
Intro
3차원 공간을 표현하는 가장 대표적인 방법인 mesh와 point는 2차원 영상 공간에 사영 (rasterization*)을 하기가 매우 용이하며, 또한 명시적으로 GPU/CUDA 기반의 래스터화를 수행하기에 적절한 3차원 장면 표현 방법 입니다. 하지만 부족한 정보로 인해 새로운 뷰를 생성하기 어려움이 존재합니다.
* rasterization (래스터화)는 2차원 영상 공간에 사영시키는 것에 더해 픽셀을 고려하여 비트화시키는 방법이라고 이해하시면 됩니다.
이런 한계를 극복하기 위해서 Neural Radiance Field (NeRF)는 연속적인 장면 표현을 기반으로 촬영된 영상과 카메라 포즈의 volumetric ray-marching을 이용해 Novel View Synthesis (NVS)을 예측하는 MLP를 최적화하는 방법을 이용합니다. 최근 NeRF 기법에서는 연산 효율성을 위해 voxel, hash 그리고 grid와 같이 사전 정의된 공간에 저장된 값들을 보간하는 방식으로 연속적인 표현을 구현하는 방법을 이용하는 추세입니다. 하지만 이러한 방법들은 연속적인 뷰를 생성하기 위한 효율적인 최적화가 가능하지만, 렌더링에 필요한 확률적인 샘플링에는 여전히 비용이 많이 들고 노이즈가 존재할 수 있습니다.
저자는 이러한 두 관점에서 장점을 결합한 기법을 제안하고자 합니다. 이는 3D Gaussian 표현을 이용하여 SOTA 수준의 시각적 품질, 훈련 시간을 보이며, tile-based splatting 기법을 통해 실시간 렌더링을 보입니다. 또한, 1080p 해상도에서도 SOTA를 보입니다.
저자가 제안한 기법은 3가지 구성 요소를 기반으로 구성됩니다. 먼저, 유연하고 표현력이 풍부한 장면 표현을 3D Gaussian을 사용한 것을 제안합니다. NeRF와 유사하게 Structure-from-Motion (SfM)으로 보정된 정보들을 입력**으로 사용합니다. SfM을 통해 추정된 sparse point cloud를 사용하여 3D gaussian set을 초기화 합니다.
[** 3차원 포인트 클라우드 (structure)와 카메라 포즈 (motion)을 입력으로 사용합니다. 추가로 대표적인 SfM 라이브러리인 COLMAP에서는 카메라 외부/내부 보정까지 동시에 진행합니다.]
+ 기존 NeRF가 아닌 point-based 기법들은 Muti-View Stereo (MVS)를 요구하는 반면에 저자는 초기 위치에 대해 랜덤 초기화를 적용했을 때도, NeRF-synthetic datasets에서 높은 퀄리티를 보여줌.
또한, 3D Gaussian은 differentiable volumetric representation이기 때문에 2D로 투영하고 NeRF와 동일한 이미지 형성 모델인 standard ?-blending을 적용하면 보다 효율적으로 래스터화할 수도 있다고 합니다. (해당 기법을 기본 파이프라인으로 가지고 갑니다.)
두 번째 구성 요소는 3D gaussian의 속성- 3D position, opacity ?, anisotropic covariance, spherical harmonics (SH) coefficients -을 최적화하면서 adaptive density control steps을 통해 3D gaussian를 추가하거나 때때로 제거하는 작업을 수행합니다. 해당 절차는 장면을 적절하게 간결하고 구조화되지 않도록 하면서 정확한 표현으로 생성하도록 합니다.
세 번째 요소는 병렬적인 GPU 연산을 통해 빠른 연산이 가능하도록 하는 tile-based rasterization에 영감을 받은 실시간 렌더링 기법입니다. 저자가 제안한 3d gaussian은 point와 동일한 수준에서 가시적인 정렬과 ?-blending이 가능하기 때문에 보다 빠르고 정확한 backward pass가 가능해집니다.
다음은 저자가 요약한 기여에 해당합니다. 참고하시길 바랍니다.
- The introduction of anisotropic 3D Gaussians as a high-quality, unstructured representation of radiance fields.
- An optimization method of 3D Gaussian properties, inter- leaved with adaptive density control that creates high-quality representations for captured scenes.
- A fast, differentiable rendering approach for the GPU, which is visibility-aware, allows anisotropic splatting and fast back- propagation to achieve high-quality novel view synthesis.
Method
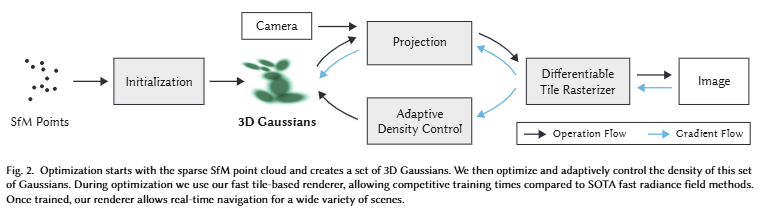
Point-Based Rendering and Radiance Fields. 본격적으로 3DGS를 다루기 전에 본 내용을 이해하기 위해서는 알고 가야 하는 내용이 있습니다. 해당 기법의 모티브는 인트로에서 다룬 바와 같이 래스터화에 용이한 point와 같이 일반적인 표현 방법과 NeRF의 장단점을 적절하게 합치는 것이 목적이라고 언급하였습니다. 기존 point-based methods는 연결되지 않고 불규칙하게 구성된 geometry sample들을 효율적으로 렌더링 하는 것을 목적으로 합니다. 해당 방법은 추출된 기본 데이터에 충실하지만 불연속성을 가지고 있기 때문에 희소성을 극복하지 못하여 구멍이 발생하고, 적응적인 대응이 부족해 앨리어싱이 발생합니다. 이러한 한계를 극복하기 위한 방법 중으로 원형 혹은 elliptic discs, ellipsoids, surfels 형태를 가진 픽셀보다 큰 범위의 point primitives를 이용하여 문제를 해결하고자 합니다. 최근에는 이러한 표현들을 미분 가능하도록 바꾸고자하는 움직임이 있었습니다. 가장 대표적인 흐름은 CNN을 이용한 기법으로 빠른 렌더링이 가능하나 특징이 없거나 빛의 반사가 일어나는 경우과 같은 어려운 장면에 대해서는 over- or under-reconstruction이 발생합니다.
point-based ?-blending과 NeRF 스타일의 volumetric은 본질적으로 동일한 image formation model을 가집니다. 구체적으로는 color C는 ray에 따라 volumetric rendering이 된다는 가정을 가집니다.
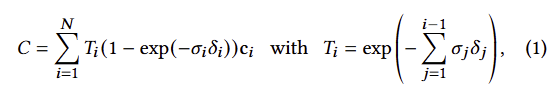
여기에 density ?, transmittance ?, color c에 대한 샘플들은 intervals ??에 따라 ray 따라 취해집니다. 이는 아래와 같이 정리됩니다.
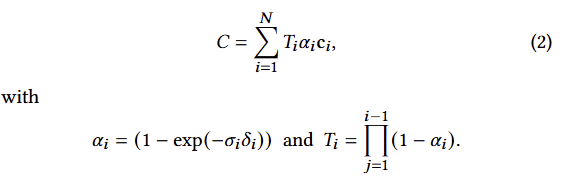
일반적으로 신경망 기반의 point-based 방법론들은 아래와 같이 픽셀과 겹치는 N 개의 정렬된 포인트를 혼합하여 color C를 계산합니다.
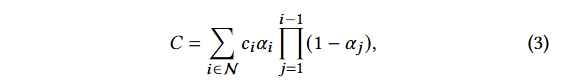
여기서 c?는 각 포인트의 색상, ??는 학습된 포인트별 opacity에 covariance Σ를 곱한 2D 가우시안으로 evaluating**하여 주어집니다. (**evaluating은 확률 분포인 가우시안에서 값을 도출한다로 이해하시면 됩니다.)
NeRF 기반의 수식 2와 point-based 방법론의 수식 3을 보면 image formation model이 동일 한 것을 알 수 있습니다. 그러나 렌더링 알고리즘은 매우 상이합니다. NeRF는 empty/occupied space을 암시적으로 나타내는 연속 표현 기법에 해당합니다. 수식 2에서 샘플을 찾기 위해서는 높은 연산의 무작위 샘플링이 수행되어야만 합니다. 저자는 point-based의 이전 연구에서 point를 opacity와 positions로 구성하여 NeRF의 기하학적인 관점으로 생성, 제거, 변위가 가능한 기법을 기반으로 수용하고자 합니다. 더 나아가 tile-based rendering과 fast sphere rasterization을 수행한 이전 연구를 수용합니다. 위에서 언급한 분석을 토대로 저자는 conventional ?-blending을 유지하면서 volumetric representation의 장점을 가지기를 원합니다. 저자가 제안하는 래스터화에는 가시성 순서를 기반으로 수행하면서, 픽셀의 모든 splats에 대한 그래디언트를 역전파가 가능하고 anisotropic splats을 래스터화하는 방법을 제안합니다.
DIFFERENTIABLE 3D GAUSSIAN SPLATTING
저자의 목표는 법선이 없고 희박한 point set에서 시작하여 고품질의 NVS를 허용하는 장면 표현으로 최적화하는 것 입니다. 이를 위해 미분 가능한 volumetric representation의 속성을 상속하는 동시에 매우 빠른 렌더링이 가능하도록 하되, 구조화되지 않은 명시적인 primitive (기본 요소)가 필요합니다. 이를 위해 저자는 미분 가능하고 ?-blending을 이용 2D splat으로 쉽게 투영 가능한 3D gaussian을 선택합니다. 해당 가우스는 월드 좌표계에서 정의되어 3D covariance matrix Σ과 centered at point (mean) ?에 의해 아래와 같이 정의됩니다.
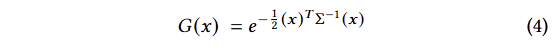
해당 가우시안은 블렌딩 과정에서 ?로 가해집니다. 그러나 렌더링을 위해서는 3D gaussian을 2D로 투영해야만 합니다. 여기서 viewing transformation ?이 주어지면 카메라 좌표계의 covariance matrix Σ’은 다음과 같이 주어집니다.
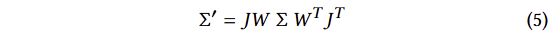
여기서 ?는 the Jacobian of the affine approximation of the projective transformation에 해당 합니다. 허나, 이전 연구에서 Σ’의 3 번째 열과 행을 무시한 2×2 variance matrix가 법선이 존재하는 평면에서 시작하는 것과 동일한 정보를 얻을 수 있는 것을 통해 아주 간단하게 3d gassuan의 covariance matrix Σ을 최적화가 가능합니다. 또한, 물리적인 공간에서는 positive semi-definite하기 때문에 이에 따른 제약을 겁니다. 3D gaussian의 공분산은 타원체의 구성을 설명하는 것과 유사합니다. 이를 기반으로 scaling matrix ?, rotation matrix ?을 통해 이에 대응 되는 corresponding Σ를 아래와 같이 구하는 방법으로 표현을 변경합니다.
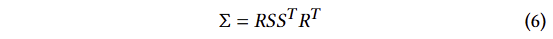
두 factor의 독립적인 최적화를 위해 스케일링을 위한 3D vector s와 회전을 나타내는 quaternion ?로 별도로 저장합니다. 이를 통해 효율적인 anisotropic covariance 표현이 가능해집니다. 정성적인 결과는 fig 3에서 확인 가능합니다.

OPTIMIZATION WITH ADAPTIVE DENSITY CONTROL OF 3D GAUSSIANS
앞서 새로운 3차원 표현 방법인 anisotropic 3d gaussian을 제시했다면 해당 세션에서는 해당 표현을 이용해 NVS를 정확하게 표현하기 위한 최적화를 설명합니다. 여기서는 각각의 가우시안의 positions ?, ?, covariance Σ와 SH coefficients representing color ?에 대한 최적화하여 뷰에 따른 장면을 올바르게 캡처하고자 합니다. 또한, 최적화를 더 잘 표현하기 위해 가우시안의 density를 제어하는 단계와 동조합니다.
Optimization. 최적화는 새로운 뷰에서 합성된 영상과 훈련 셋 내 영상과 비교하여 학습을 진행합니다. 허나, 3D와 2D의 투영은 필연적으로 모호성이 발생하게 됩니다. 그렇기에 해당 최적화에서는 create geometry와 destroy or move geometry가 반영되어야만 합니다. 또한, 소수의 큰anisotropic Gaussians.으로 넓은 homogeneous areas을 캡처할 수 있기 때문에 3D Gaussians covariances 의 품질은 표현의 컴팩트함에 매우 중요합니다. (구체적인 방법은 다음 섹션에서 다룹니다.)
이를 위해서 먼저, 저자는 연산 효율성과 실시간성을 확보하기 위해서 SGD 기반의 최적화를 위해 CUDA 기반의 병렬 연산이 가능하도록 CUDA 프로그래밍을 수행합니다. 여기서 ?에 대한 시그모이드 함수를 사용하여 [0, 1) 범위로 제한하여 부드러운 기울기하고 동일한 사유로 공분산에도 exponetial activation을 가합니다.
초기 가우시안은 각 축의 값이 동일한 isotropic Gaussian이라고 가정합니다. standard exponential decay scheduling을 사용하지만 position에 대해서만 사용됩니다. 또한, loss는 L1과 D-SSIM을 사용합니다. 이는 아래와 같습니다.
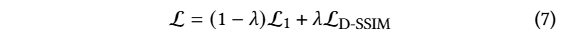
? = 0.2를 사용했다고 합니다.
Adaptive Control of Gaussians. 여기서는 SfM의 희소한 포인트로 초기화된 희소한 가우시안 셋들의 밀도를 적응적으로 조절하여 밀도 높은 장면 표현이 가능하도록 합니다. 먼저 최적화에 대한 warm-up이 끝난 다음에 threshold ??보다 ?가 낮은 가우시안들은 매 100 iter마다 제거합니다.
저자가 목표하는 적응형 컨트롤은 빈 영역도 채워야만 합니다. 여기서는 기하하적 특징이 누락된 영역 (under-reconstruction)과 가우시안이 장면에서 넓은 영역을 덮는 영역 (over-reconstruction)에 초점을 맞춥니다. 저자는 두 요소 모두 높은 view-space positinal gradients를 가지고 있는 것을 확인하였다고 합니다. 직관적으로 아직 구성되지 못한 혹은 재현하지 못하는 영역에 대해 수정하기 위해 가우시안을 이동시키려고 하기 때문이라고 합니다.
저자는 이러한 특징을 이용하여 threshold ?pos (저자는 0.0002 사용)을 임계값으로 사용하여 view-space gradient를 가진 가우시안을 이용합니다. 전반적인 흐름은 fig 4에서 확인 가능합니다.
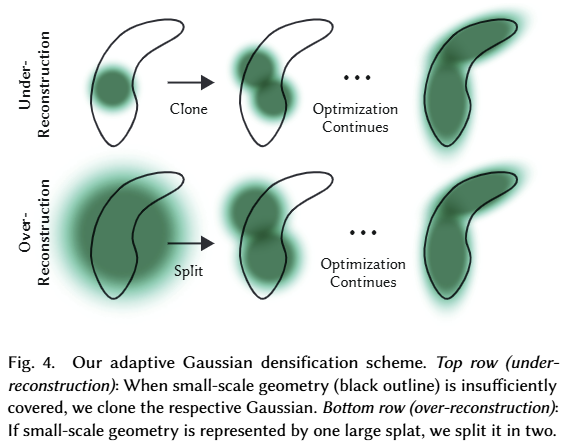
under-reconstructed regions에 존재하는 작은 가우스들은 새롭게 생성되어야 하므로 동일한 크기의 복사본을 만들고 gradient 방향으로 가우스를 복제합니다.
반면에 큰 가우스들은 두 개의 새로운 가우시안으로 대체하고 스케일들은 실험적으로 결정된 scale factor ? = 1.6로 나눕니다. 기존 가우시안의 PDF를 이용하여 위치를 선정합니다. (해당 부분들은 코드 리뷰 후, 디테일 추가 필요)
첫번째 경우는 시스템의 총 volum과 가우시안의 수를 늘려야 하는 필요성을 감지하고 처리하는 반면에 두번째는 총 volum은 유지하면서 가우시안의 수를 늘립니다. 이러한 최적화는 입력 카메라에 가까운 플로터로 인해 정체 될 수 있습니다. 즉, 가우스 밀도가 예기치 못하게 증가할 수 있습니다. 이러한 현상을 해결하기 위한 트릭으로 저자는 3000 iter 마다 ?를 0에 가깝게 초기화를 진행합니다. 최적화에서는 culling approach 방식으로 ?_?보다 작은 ?를 제거하여 유의미한 가우시안만 남기도록 합니다. 또한 월드 공간에서 큰 가우시안과 뷰 공간에서 큰 공간을 차지하는 가우시안을 주기적으로 제거합니다.
FAST DIFFERENTIABLE RASTERIZER FOR GAUSSIANS
해당 섹션에서는 anisotropic splats를 포함하고 ?-blending을 허용하는 빠른 렌더링과 정렬 기법을 소개합니다. 저자는 guassian splat의 tile-based rasterization을 설계하여 전체 이미지의 기본 요소를 한 번에 미리 정렬함으로써 기존 ?-blending의 단점이었던 픽셀 별 정렬 비용을 절감합니다.
해당 기법은 영상을 16×16의 타일로 분할한 다음 view frustum과 tile에 대한 3D gaussian에 대한 선별을 진행하는 것으로 시작됩니다. 구체적으로 view frustum교차하고 99% confidence를 가지는 가우시안만 유지합니다. 추가적으로 너무 가깝거나 너무 멀리 있는 가우시안들은 제거합니다. 그런 다음 겹치는 타일 수에 따라 각 가우시안 인스턴스를 인스턴스화하고 각 인스턴스에 view space depth와 타일 ID를 결합하는 키를 할당합니다. 이를 이전 연구에서 제안된 single fast GPU Radix sort를 이용해 정렬합니다.
정렬 후, 각 타일에 따라 깊이에 따른 첫번째와 마지막 splats 리스트화 합니다. 래스터화를 위해 각 타일에 대해 스레드 블록을 시작합니다. 모든 픽셀에 대한 ?가 1이 되면 스레드는 종료됩니다.
Experiments
Implementation.
– python-Pytorch+custom CUDA kernel for rasterization+NVIDIA CUB sorting routines for the fast Radix sort
– “warm-up”을 4배 더 자은 영상으로 250 iters, 500 iters를 수행
– SH coeff는 4개의 밴드를 사용하며, 1000 iters마다 1개의 밴드를 추가함
Results and Evaluation


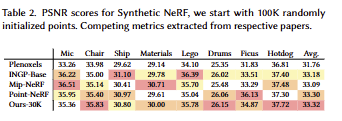
성능 측면에서의 SOTA, 속도 측면에서의 SOTA를 모두 이기는 결과를 보여주며, 7k와 30k의 성능과 속도의 trade-off를 보여줌
Ablations
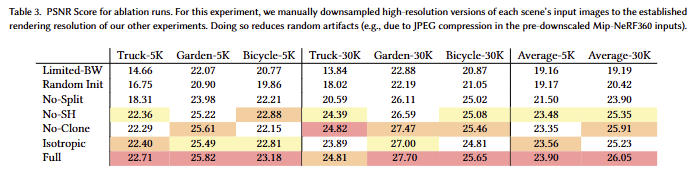
Initialization from SfM

랜덤 초기화한 포인트에서 시작해도 좋은 퀄리티를 보여줌으로써, 해당 3d gussian의 3차원 표현 잠재성을 보임
Densification

split이 없으면 큰 가우스들을 억제하지 못해 배경이 흐릿해지며, clone을 제거하면 구성되지 못한 영역에 대해 디테일한 표현력이 떨어지는 것을 보임
Unlimited depth complexity of splats with gradients.

왼쪽은 역전파 수행을 10개의 가우스로 제한한 결과로 역전파의 효과를 보임
Anisotropic Covariance.

isotropic을 자세히 보면 원들이 보이는 것을 토대로 유연한 표현력이 다소 떨어지는 것을 보임.
Spherical Harmonics. Tab 3을 통해 SH coeff의 효과를 확인 가능
논문이 테크니컬 리포터처럼 작성된 경향이 없지 않아서… 이해하기 위해서 다른 논문들을 무조건 읽어야만 했습니다. 아마… 새로운 프레임워크를 제시하는 것이다 보니, 디테일한 설명들은 넘기고 더 필요한 내용들을 설명하다보니 그런 것 같긴해요… 넘치는 내용들이 제한된 용량 안에 담기다 보니 꾸역꾸역 채워진 느낌 같다고 해야하나…
어찌되었든 이해가 안되는 부분은 언제든 질문 주시면 답변하도록 하겠습니다.
상세한 리뷰 감사합니다.
Gaussian splatting을 돌리면서 다른 NeRF기반의 방법론들 보다 훨씬 빠른 속도로 reconstruction 을 수행하는 것 뿐만 아니라 퀄리티까지 더 좋은 결과를 보이는 이유를 이번 세미나와 더불어 이번 리뷰를 통해 이해가 되었네요.
궁금한 점은 빠른 속도로 수행하는 것이 tile-based rasterization 과정을 통한 빠른 sorting 덕분이라고 보이는데, 16×16 패치의 형태로 영상을 분할하여 연산을 수행하는 것이 빠른 게 confidence score가 99%가 아니면 다 버리기 때문이라고 보면 될까요? ViT도 비슷하게 16×16 패치의 형태로 자른 영상을 입력으로 사용하는데 이러한 ViT가 연산량 측면에서 비용이 꽤 큰 것과 유사한 상황이라고 생각이 들어서 질문을 드립니다.
감사합니다.
Q1. 궁금한 점은 빠른 속도로 수행하는 것이 tile-based rasterization 과정을 통한 빠른 sorting 덕분이라고 보이는데, 16×16 패치의 형태로 영상을 분할하여 연산을 수행하는 것이 빠른 게 confidence score가 99%가 아니면 다 버리기 때문이라고 보면 될까요? ViT도 비슷하게 16×16 패치의 형태로 자른 영상을 입력으로 사용하는데 이러한 ViT가 연산량 측면에서 비용이 꽤 큰 것과 유사한 상황이라고 생각이 들어서 질문을 드립니다.
A1. 음… 빠른 속도?는 sorting 덕분이라고 보기엔 어렵습니다. tile로 rasterization을 수행하는 이유는 batch 연산이라는 장점과 vit의 특성으로 인해서 나온 기법이라고 보면 됩니다. sorting은 가까운 가우신안이 시차에 큰 영향을 주기 때문에 이를 먼저 고려하기 위해 수행하는 것이죠.