안녕하세요, 서른일곱 번째 X-Review입니다. 이번 논문은 2021년도 Sensors에 게재된 R-CenterNet+: Anchor-Free Detector for Ship Detection in SAR Images입니다. 바로 시작하도록 하겠습니다. ?
1. Introduction
Synthetic aperture radar (SAR)는 지상 및 해양에 대해 공중에서 레이다를 쏜 다음 반사되어 돌아오는 시간차를 처리해 지상지형도나 지표를 곽측하는 시스템입니다. 이 SAR은 하루종일, 날씨가 어떻든 간에 해양 환경의 이미지를 제공할 수 있기 때문에, 해양 감시 및 모니터링에 널리 사용되어 왔습니다. 이때 이 해양 감시의 중요한 테스크로 SAR 영상에서의 선박을 검출하는 것이 있습니다.
SAR 이미지는 보통의 다른 영상과 몇 가지 차이점이 존재하는데요. 먼저, 영상에 노이즈가 좀 껴있다는 점과 지형 변화에 따른 위상 오류가 있어 영상의 품질이 저하되고, 기하학적인 왜곡이 있다는 점입니다. 그래서 이 SAR 영상을 이해하는 것과 해석하는 것이 매우 어렵기 때문에 자동으로 SAR 영상 내의 target을 인식하고자 하는 노력이 있어왔습니다. 잘은 모르겠지만, threshold 방식이나, statistics 방식, trasformation 방식 등을 사용했다고 하는데, 이 방식들이 작은 물체나, 복잡한 씬에서 성능이 좋지 못하다는 이유로 최근에는 딥러닝 기반 방식을 도입하였습니다.
딥러닝 기반 방식은 크게 Faster R-CNN, SSD와 같은 anchor 기반 방법론들과 CenterNet, FCOS 등과 같은 anchor-free 방법론들로 나뉩니다. Anchor 기반 방법론들은 RPN이라고 하는 region proposal network를 통해 많은 수의 후보 영역(객체가 있을법한)들을 생성해내게 되고, 이 영역들을 CNN에 태워 최종적으로 객체의 bbox와 class를 예측하게 됩니다. 이런 종류의 방법론들은 높은 성능을 보이는 대신 시간이 많이 소요된다는 특징이 있죠. 반면, Anchor free 방법론들은 후보 영역을 미리 생성하지 않고, 바로 bbox의 위치와 class를 regression하게 됩니다. 그렇기 때문에 anchor 기반 방법론보다 더 빠르다는 장점이 잇고, 이는 real-time으로 처리하기에 좀 더 적합하다는 의미가 되겠죠.
지금까지 SAR ship을 real-time으로 검출하고자 하는 연구가 많이 있어왔는데요, 이 SAR 영상은 다른 일반적인 영상과는 다르게 target인 선박 자체가 영상 내에 sparse하게 존재합니다. 이런 영상의 특징을 고려해보자면, anchor-free 방법론을 사용하는 것이 속도가 더 빠르겠죠. 영상 내에 target이 얼마 없는데 수 많은 anchor들을 생성하는 것은 비효율적일테니까요. 그렇기에 이 anchor free 방법론들로 SAR ship을 검출하는 선행연구가 존재했지만 이 연구들은 4가지의 챌린징한 문제를 겪고 있었습니다. 바로, time cost가 크다는 점과, small ship 검출, 복잡한 배경, 선박에 대한 정확한 크기와 축 정보가 부족하다는 점인데요.
본 논문의 저자는 이런 문제들을 해결하고자 이른바 R-CenterNet+ 이라고 하는 detector를 제안하였습니다. 이 R-CenterNet+은 small ship에 대한 성능을 향상시키는데 집중하여 어텐션 방식 기반의 백본 네트워크를 제안하였습니다. 또, 선박과 복잡한 배경과의 구별력을 키우기 위해 FEM이라고 하는 feature map을 refine하는 모듈을 제안했구요, 마지막으로 ship의 회전 각도와 관련해 어노테이션을 한 후, 모델에도 angle regression 브랜치를 추가하여 선박의 회적 각도를 모델이 예측할 수 있도록 하였습니다. 모델의 디테일한 부분은 추후 Method단에서 다루도록 하겠습니다.
2. Data
Method 소개를 드리기 전에 간략하게 SSDD 데이터셋과 AIR-SARShip이라고 하는 두 데이터셋을 소개하고 넘어가도록 하겠습니다.
2.1 SSDD Dataset
SSDD데이터셋은 처음으로 공개된 선박 검출용 SAR 영상입니다.
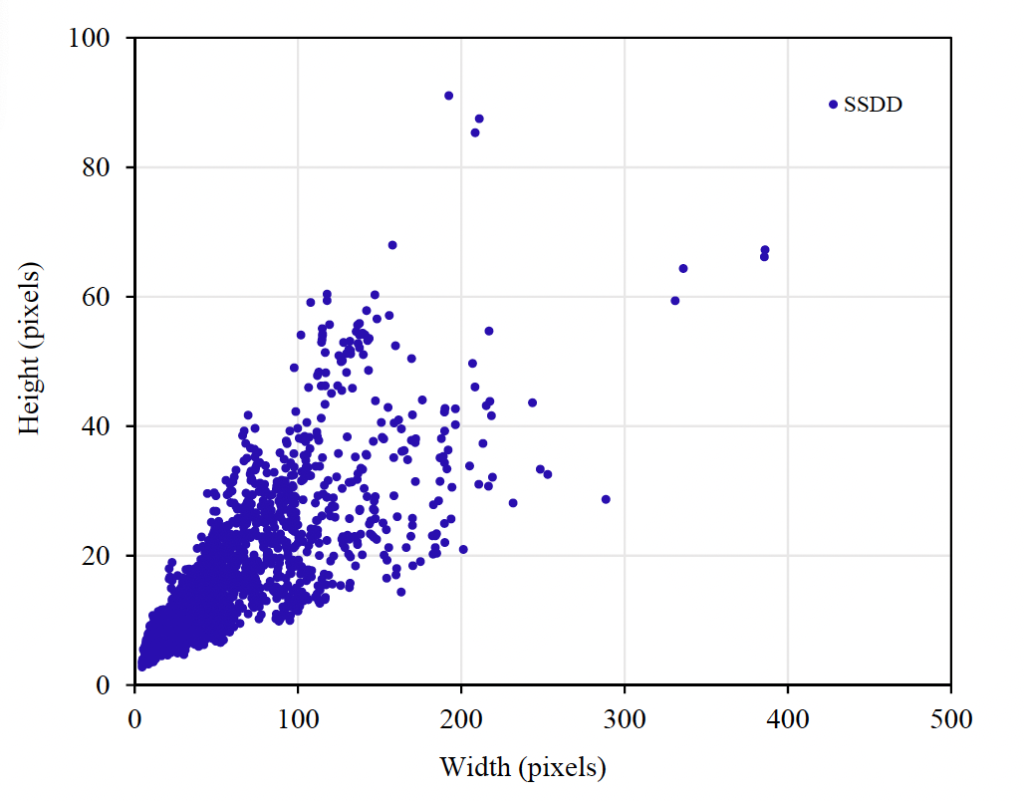
위 Figure1에는 이 SSDD dataset에서 선박의 픽셀 크기 분포를 살펴볼 수 있는데요, 보시면 주로 작은 크기의 ship들로 구성된 것을 알 수 있습니다. 게다가 이 선박의 크기 자체도 굉장히 다양한데요, 가장 작은 선박 크기가 7×4 크기이고 가장 큰 크기가 381 x 69 정도라고 합니다.
다양한 크기를 갖는 선박들의 성능을 향상하기 위해 pixel size에 기반하여 SSDD dataset의 ship들을 나눠봤는데, 32×32 미만 픽셀은 small로, 64×64 미만은 medium으로 64×64 이상은 large ship으로 나눴습니다. 이렇게 나눈 multiscale ship 통계 결과는 밑에 table2와 같습니다.

또, 추가적으로 저자는 inshore ship 즉, 연안에 있는 선박들이 해안에 있는 선박보다 배경이 더 복잡하기 때문에 검출하기 어려운 점을 고려하여 이 inshore에 대한 성능도 향상시키고자 하였고 그에 따라 데이터셋을 inshore과 offshore로 나눠 통계를 내어 보았습니다.
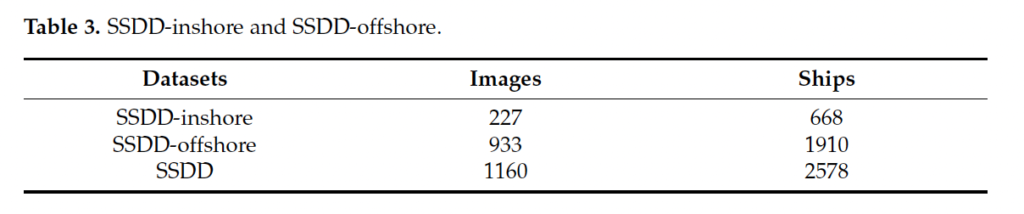
결과는 table3과 같은데, offshore(해안)에 있는 배들이 연안보다 더 많은 것을 볼 수 있습니다 .
또한, SSDD 데이터셋은 많은 큰 크기의 선박에 비해 상대적으로 적은 수의 small ship들이 밀집되어 있는데요, 이런 데이터의 불균형은 모델이 큰 배에 더 많은 집중을 하게 되어 결과적으로 여러 밀집된 작은 배들을 하나의 큰 배로 잘못 인식할 수 있기 때문에 이런 문제를 해결하기 위해 학습 과정에서 작은 선박들이 밀집된 영상에 대해 oversample을 수행합니다.
SSDD 데이터셋은 많은 큰 배에 비해 상대적으로 적은 수의 작은 배들이 밀집되어 있는 것으로 구성되어 있습니다. 이러한 데이터의 불균형은 모델이 큰 배에 더 많은 주의를 기울이도록 만들고, 결과적으로 여러 개의 밀집된 작은 배들을 하나의 큰 배로 잘못 인식하게 되어 심각한 누락 검출(missed detections)을 일으킬 수 있습니다.
이러한 문제를 해결하기 위해, 훈련 과정에서 작은 배들이 밀집된 이미지에 대해 오버샘플링(oversample) 데이터 강화를 수행합니다. 오버샘플링은 데이터셋 내에서 특정 유형의 이미지(여기서는 작은 배들이 밀집된 이미지)를 인위적으로 늘려 모델이 그러한 경우에 더 많은 주의를 기울일 수 있도록 하는 기술입니다. 이렇게 함으로써, 모델은 작은 배들에 더 잘 반응하도록 훈련될 수 있습니다. 오버샘플링 방법은 “Figure 2″에서 설명되어 있습니다.

oversample은 단순히 위 fig2와 같이 작은 배들이 밀집되어 있는 영상을 3배로 넣어 학습했다는 것입니다. 다음으로 AIR-SARShip Dataset에 대한 소개를 해야겠지만,, 크게 유의미한 부분도 아니고, 데이터셋 분석도 앞선 SSDD 데이터셋과 유사하므로 패스하도록 하겠습니당.
3. Materials and Methods
이제,, 방법론에 대한 부분입니다. 제안된 모델은 anchor-free detector인 CenterNet을 기반으로 한 모델이며, 전반적인 framework는 아래 fig4에서 살펴볼 수 있습니다.
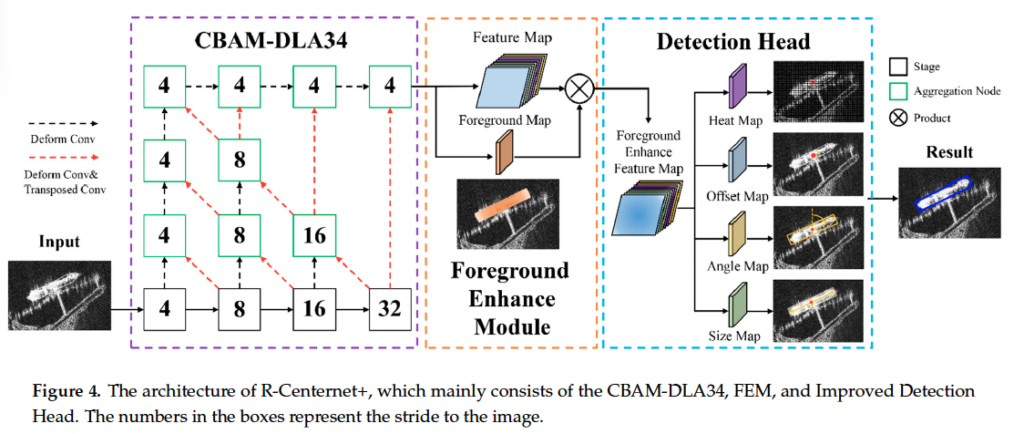
짤막하게 설명드리자면, 먼저 CBAM-DLA34라고 하는 백본 네트워크를 통해 ship feature를 추출한 다음, 이 feature map들을 FEM에 태워 feature map의 foreground를 향상시키는 작업을 거칩니다. 마지막으로 center point 좌표와 object 크기, offset 그리구 rotation angle을 regression하게 됩니다.
3.1. CBAM-DLA34
앞에서 언급했었는데, 이 SAR 영상은 영상에 speakle한 노이즈가 존재해서 feature를 추출하는 것이 좀 어려워 small ship에 대한 성능이 낮다는 특징이 존재합니다. 그러므로 본 논문의 저자는 lightweight한 어텐션 모듈인 CBAM을 좀 변경한 CBAM-DLA34를 백본 네트워크로 삼았습니다. CBAM은 다들 아시겠지만,,, channel attention 모듈과 spatial attention 모듈로 구성됩니다.
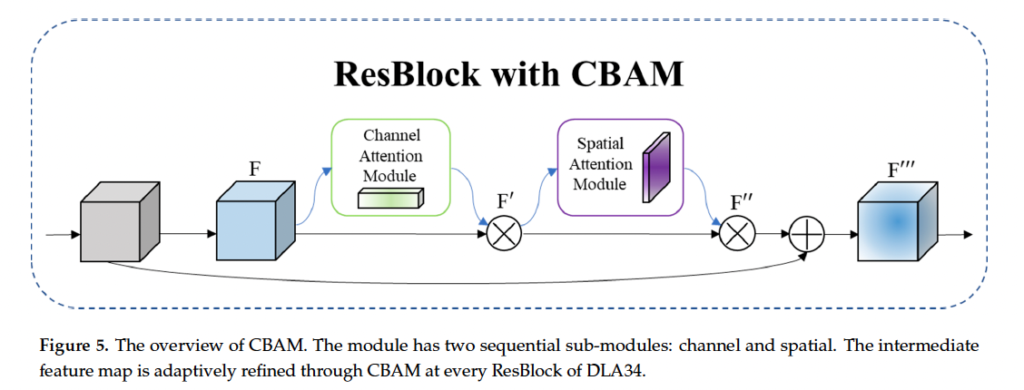
CBAM 오버뷰는 위 fig5에서 확인하시면 되구요…. 논문에 CBAM에 대한 설명이 자세히 적혀 있지만,, 간략하게 설명하고 넘어가도록 하겠습니다. 먼저 channel attention module은 3가지 step으로 구성됩니다. 1. spatial 차원에 대해 global average pooling과 max pooling을 각각 태웁니다. H x W x C shape을 갖는 feature를 입력으로 넣었을 때 1 x 1 x C shape의 feature map이 두 개 나오게 되겟죠. 2. 그 다음 MLP를 각각 태운 다음 두 feature map을 더합니다. 3. 마지막으로 sigmoid를 통해 channel attention weight M_c를 얻어냅니다. 식으로 보자면 아래와 같습니다.
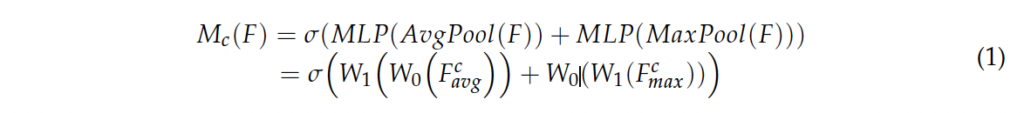
다음으로 spatial attention module을 설명드리자면, 1. channel dimension에 대해 global average pooling과 maximum pooling을 각각 태워 H x W x 1 shape을 갖는 feature map 두 개를 생성합니다. 2. channel축으로 두 feature map을 concat한 다음, 7×7 커널 사이즈를 갖는 conv를 태운 후 3. sigmoid 함수를 거쳐 최종적으로 spatial attention weight인 M_s를 얻어냅니다.
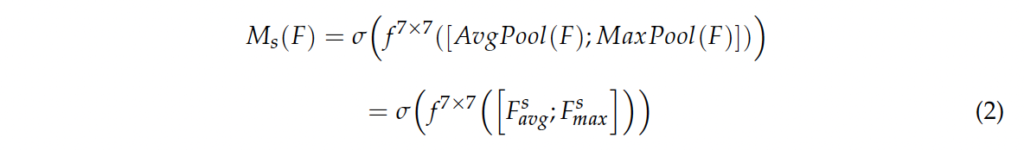
식으로는 위 식2와 같습니다.
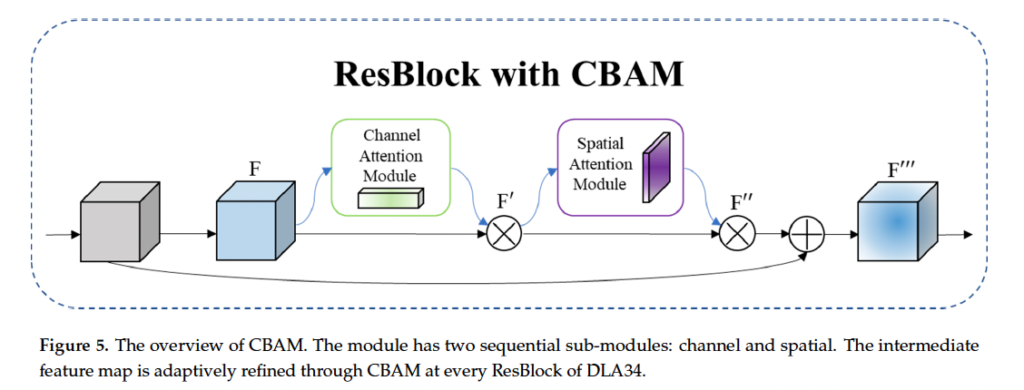
전체적으로 보면, 먼저 conv를 태워 feature map을 얻게 되구요, 이 feature map F을 channel attention module의 입력으로 넣어서 channel attention feature M_c를 얻어낸 다음, input feature map F와 elment-wise로 곱해서 feature map F’를 생성합니다. 이후, spatial attention module의 입력으로 F’를 넣어서 spatial attention feature M_s를 얻구요, 이전에 입력으로 넣은 F’와 곱해서 F’’를 생성한 다음 최종적으로 shortcut connection을 통해 F’’’을 얻어냅니다.
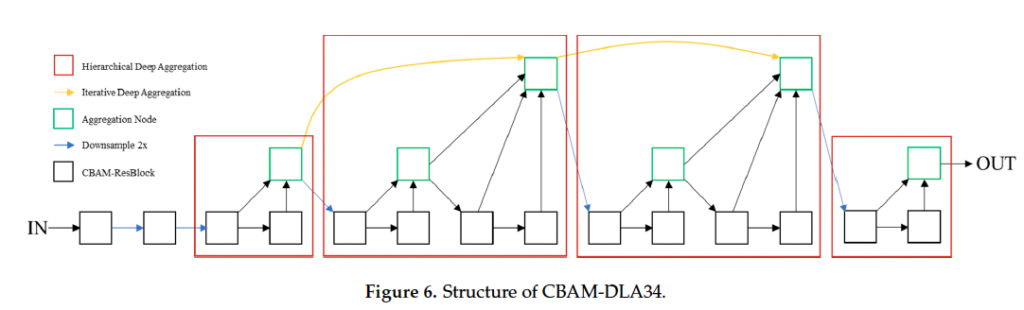
추가로 계층적인 skip connection으로 구성된 네트워크인 DLA를 CBAM과 결합하여 위 fig6과 같이 CBAM-DLA34를 제안하였고 이를 백본 네트워크로 사용하였습니다.
3.2. FEM
이 SAR 영상의 특성이 배경이 엄청 복잡하다는 것이었는데요, 특히 연산 선박 검출에서는 섬이나 암초, 노이즈 등의 영향을 받기 쉬워서 선박을 다른 object와 혼동하게 됩니다. 그렇기에 본 논문에서는 semantic segmentation이 object detection을 좀 assist할 수 있다는 이전 연구들을 참고하여, semantic segmentation을 기반으로 한 FEM(Foreground Enhancement Module)을 제안하여 복잡한 배경의 간섭을 줄이기 위하여 사전에 미리 foreground 영역에 대한 feature를 향상하도록 하였습니다.
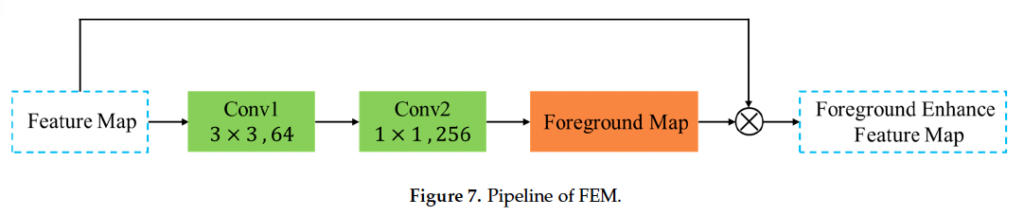
FEM 파이프라인은 figure7에 나와있는데요, 단순히 original feature map을 연속으로 convolution으로 태워서 foureground image F를 얻어내는냅니다. 그 다음 이 foureground image F와 original feature map FM에 대해 elment-wise로 곱을 해서 전경에 대해 향상된 feature map인 FEFM을 생성해내었다고 합니다 …….
전경을 정확하게 표시하기 위해서 semantic segmentation을 기반으로 한 foreground label을 사용해 FEM을 학습했는데요, 이 foureground label 생성 방식은 아래 그림 8과 같습니다.
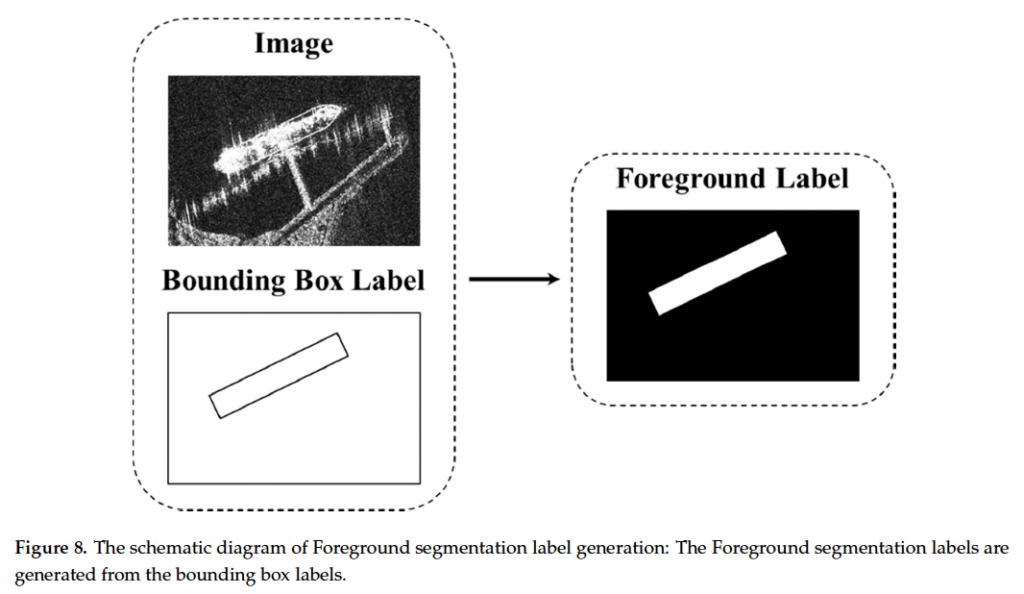
먼저, Width와 Height를 갖는 gt bbox를 output stride R에 따른 위치로 투영합니다. (H/R x W/R 크기 feature map에 따른 좌표로 매핑한다는 뜻 .. )그 다음 W/R x H/R x 1인 label을 생성하는데요, pixel이 투영된 bbox 내에 있으면 1로 밖에 있으면 0으로 하여 이진 map을 생성해 학습에 사용하였습니다.
3.3 Improved Detection Head
Ship 영상은 큰 aspect ratio와 object가 밀집되어 있다는 것이 특징인데요, 밑 figure9를 보면, 전통적인 horizontal box 검출은 ship의 height, width 및 축 정보를 정확하게 표현하기 어렵습니다. 다시 말해, 사진 상의 좀 기울어져 있는 ship을 정확하게 표현하지 못한다는 의미인데요, 이런 horizontal box와 비교해봤을 때 rotation 된 box는 ship의 정보를 더 정확하게 반영할 수 있고, 이 ship의 feature를 추출할 때 다른 배경 영역의 간섭…. 을 피할 수 있습니다. 그래서 저자는 이 rotation을 추가로 예측하기 위해 기존 CenterNet의 detection head에 rotation을 예측하는 head를 추가하여 각도까지 예측하도록 하였습니다. CenterNet에 대한 자세한 설명은 제 이전 X-Review를 참고해주세욥 ..

이렇게 각도까지 예측하도록 한 CenterNet은 총 4개의 regression map을 생성하게 되는데요, 먼저 1. position regression. object인 ship의 center point heat map을 생성하는 부분입니다. center point heat map은 W/R x H/R x C 크기를 갖는 map이며 center point 좌표는 1의 값을 갖고 그 외의 부분은 0의 값을 갖습니다. 이때 C는 검출하고자 하는 class 개수인데, 본 논문의 경우에는 ship detection이니 C=1의 값을 갖습니다. 두번째로, size regression을 하는 부분입니다. size를 예측한 map은 W/R x H/R x 2인데요, 여기서 2채널은 각각 width, height에 대한 size를 예측한 채널이라고 보면 될 것 같습니다. 3. 다음으로는 center point offset regression을 하는 부분이 있는데요, size regression과 동일한 shape의 map을 예측하게 됩니다. 여기서 offset이란 heatmap에서 예측한 center point를 보정하는 역할을 합니다. 4. 마지막으로 저자가 추가한 angle regression branch가 있습니다. 이 angle prediction map은 W/R x H/R x 1의 shape을 갖습니다. 정리하자면, 기존 centernet에서 채널 1개만 추가하여 angle을 regression하도록 변경한 것이라고 보면 되겠습니다.
본 논문에서는 ship rotation 각도를 regression하기 위해 회전한 box를 (x, y, w, h, θ)로 정의하였습니다. 여기서 x, y는 bbox의 center 좌표이고, w, h는 각각 긴 변, 짧은 변이며 θ는 회전 각도입니다. 아래 그림을 참고하면 될 것 같습니다.

3.4 Loss function
loss 함수는 5가지 파트로 나눠져 있습니다. 1. foreground 예측에 대한 loss L_f, 2. center point 예측에 대한 loss L_p 3. ship 크기 예측에 대한 loss L_s 4. center point offset 예측에 대한 loss L_o 5. 각도 예측에 대한 loss La_
loss L_f와 L_p는 focal loss를 사용하고, 나머지 loss는 전부 smooth L1 loss를 사용합니다. 식은 아래 4, 6번과 같습니다.
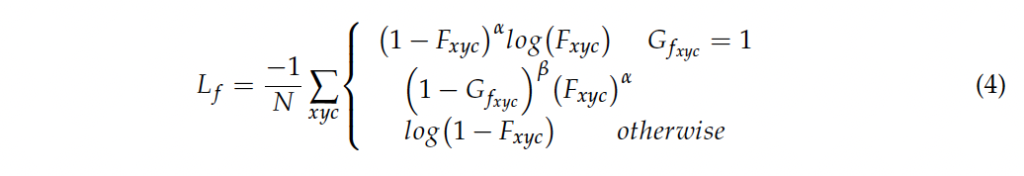
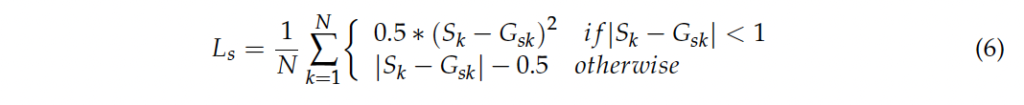
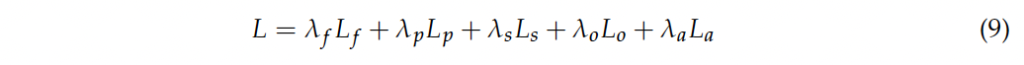
최종 loss는 위 식9와 같이 각 loss를 가중합한 loss입니다.
4. Experiment and Analysis
마지막으로 실험 부분을 살펴보도록 하겠습니다. 실험은 앞서 section 2에서 설명드린 SSDD와 AIR-SARShip에서 수행이 되었습니다. 평가지표로는 Precision, Recall, Average Precision을 사용하였습니다.
4.1. Experiments on SSDD
SSDD데이터셋 학습 과정에서 SAR 영상은 512×512로 resize하여 학습하였습니다. 먼저, 정성적 결과는 fig12에 나와있는데요, 그림에서 첫 번째 행은 small ship에 대한 detection 결과를 보입니다. 언급해왔듯이 이 small ship detection은 challenging한 문제라고 했었죠. 정성적 결과를 보시면 본 논문이 제안한 R-CenterNet+이 small ship을 잘 검출하고 있음을 볼 수 있습니다. 저자의 말에 따르면 이는 CBAM이 target에 대한 feature 표현 능력을 향상시키고 작은 선박에 대해 집중을 한 결과라고 하며, 두 번째 행은 배경이 복잡한 경우에서의 결과입니다.

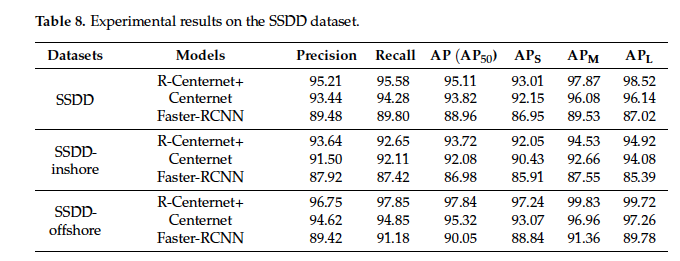
이제 정량적 성능을 살펴보도록 하겠습니다. 저자는 CenterNet과 Faster RCNN과 본 모델의 성능을 비교했는데요, SSDD 데이터셋에서 제안된 모델 AP는 95.11입니다. 반면, CenterNet과 Faster-RCNN은 그보다 좀 떨어지는 것을 볼 수 있습니다. inshore과 offshore로 나눠서 성능을 측정해본 결과 확실히 연안에서 복잡한 배경같은 것들이 있다보니 성능이 좀 떨어지는 편인 것을 볼 수 있네욤.
4.2. Comparisons with the State-of-the-Arts
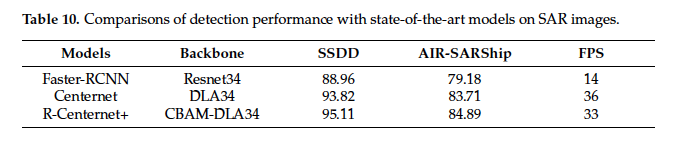
이 표는 SSDD 데이터셋에과 AIR-SARShip 데이터셋에서의 각 모델의 성능과 FPS를 확인할 수 있는 표입니다. 앞 표와 중복된 결과를 담고 있는 표이긴 한데, 정리하자면 R-CenterNet+ AP는 95.11로 Faster-RCNN보다 각 데이터셋에서 6.5, 5.7 정도 높습니다. 하지만,, faster rcnn이 2015년에 나온 모델임을 감안해봤을 때,,, 데이터셋 자체가 그렇게 어려운 데이터셋은 아닌 것으로 보입니다. FPS같은 경우도 anchor based 모델인 faster RCNN보다 anchor free 모델인 CenterNet이 더 높으며, R-CenterNet+은 그보다 좀 떨어집니다.
4.3. Ablation Study
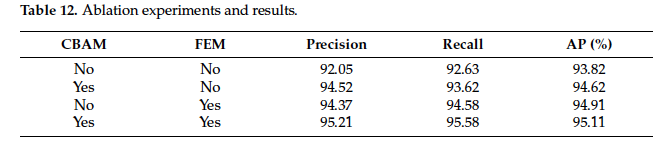
마지막으로 Ablation study인데요, CBAM을 사용했을 경우와, FEM 모듈을 태웠을 경우에 대한 실험입니다. 아무것도 하지 않은 경우는 baseline인 CenterNet 성능이라고 보면 되구요, CBAM으로 백본을 변경했을 때 AP가 1이 좀 안되게 오르며, ,,, FEM도 1정도 오르고 최종적으로 CBAM을 백본으로 사용하고 FEM 모듈을 사용했을 경우가 95.11의 성능으로 가장 높은 것을 확인할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
SAR에 관련한 Detection논문은 처음 보는데, 그렇다면 레이더를 쏘기 때문에 색상정보는 없을까요? 아니면 그냥 3D 데이터로 활용함은 별로인지..
안녕하세요. 댓글 감사합니다.
네 SAR 영상은 색상 정보가 없습니다. 그래서 SAR 영상으로 colorization하는 연구도 몇 있는 것 같더라구요.
리뷰 잘 읽었습니다
잘 읽고 테이블을 보니, 비교군이 CenterNet과 Faster-RCNN 만 있어 약간 당황워서 보니 학회 논문이 아니었군요..
저자가 문제삼은 부분 중 하나인 time cost 는 Center-Net과 큰 차이는 없는거 같은데.. 약간 아쉽긴 하네요
혹시 이 논문을 읽게된 이유가 있을까요?
그리고 이미지 도메인이 다르긴 해도, Aerial Images 에 대한 object detection과 해결하고자 하는 문제가 크게 다른거 같진 않다 생각이 듭니다. 그런데 두 분야가 서로 다르게 연구되고 있다면 둘 사이에는 어떤 차이가 있는걸까요?
안녕하세요. 댓글 감사합니다.
본 논문을 읽은 이유는,, 지금 centernet에 추가로 angle을 regression하도록 하고 있어서 참고하려고 읽어봤습니다. . .
Aerial image에 대한 object detection과 SAR image에서의 object detection의 차이점이라고 하면,, 크게 없는 것 같기는 합니다. 다만, 데이터 측면에서 보면 SAR image는 노이즈가 많아서 이 노이즈를 제거하는 전처리 과정이 좀 필요하며, 색상 정보가 없다는 점이 차이점인 것 같습니다.
감사합니다.
안녕하세요 정윤서 연구원님. 좋은 리뷰 감사합니다.
SSDD데이터셋에 관해 궁금한 점이 있는데요, [표2]를 보면 medium이나 large 보다는 small object의 sample이 많은 것 같은데요, 리뷰에서는 이로 인해 모델이 large object에 더 집중하여 여러 밀집된 small을 하나의 큰 배로 잘못 인식하게 될 수 있다고 설명해 주셨습니다.
그런데 학습 시 small의 수가 large에 비해 월등히 높으면 오히려 small에 대해서는 잘 인식하고 large의 일부분을 small로 인식하게 될 것 같은데 오히려 반대의 현상이 나타나는 이유가 궁금합니다. 혹시 관련 내용이 논문에 언급되어 있을까요?
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문 리뷰를 읽으면서 ship이라는 object가 작을 것이라 생각되어서 모델도 작은 object를 잘 detect할 수 있도록 사용하였을 것이라 생각하였는데 이 부분은 2.1 SSDD Dataset 파트에서만 언급되어 조금 당황하였습니다. 작은 배들이 밀집되어 있는 영상을 3배로 넣어 학습하는 것이 사실 왜 도움이 되는지 이해가 안가는데요. 결국에는 동일한 데이터를 1개 집어넣을거 3개 집어넣었다는 것인데 이게 왜 도움이 되는 걸까요…? 혹시 영상을 3배로 넣을 때 기본적으로 적용되는 argumentation이 있을까요?
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
SSDD 데이터셋은 많은 큰 크기의 선박에 비해 상대적으로 적은 수의 작은 배들이 밀집되어 있기 때문에 모델이 큰 배에 더 많은 집중을 하게 되어 여러 밀집된 작은 배들을 하나의 큰 배로 잘못 인식할 수 있다고 하셨는데, 오히려 큰 배를 여러 밀집된 작은 배로 인식하게 되는건 아닐지 궁금합니다. 이를 해결하기 위해 oversampling을 수행했다는데 이에 대한 검증 실험이 존재하나요?
감사합니다.