안녕하세요. 이번 리뷰는 Open-world(Open-set)에 대한 Localization을 위주로 삼은 논문을 들고 왔습니다. 이미 예전에 리뷰한, 그리고 이번 주차 세미나에서 소개드린 GOOD: Exploring Geometric Cues for Detecting Objects in an Open World 이 해당 논문을 베이스로 삼은 논문이므로 해당 논문을 이해하셨다면 (이번에 소개드릴 논문의 단점을 극복한 논문이므로) 본 논문의 리뷰를 읽지 않으셔도 무방하지만 (한국인이 작성한, 권인소 교수님 연구실의, 논문임에도 영어적으로 꽤나 잘 쓰여졌다고 생각됩니다), 제 스스로는 본 논문의 Object Proposal Network 부분을 실제 제 실험에 가져다 오기 전에 실험 세팅을 위주로 다시 읽어보고서 기록으로 남기고자 작성하게 되었습니다. 본 리뷰는 GOOD의 방법론을 다수 포함하고 있으므로 서론과 본론은 핵심을 위주로 살펴보고, 실험부를 자세히 살펴보겠습니다. 그럼 시작하겠습니다.
Introduction
Object proposal이란 객체일 확률이 높은 Bounding Box 집합을 예측하는 태스크입니다. Object Detection은 Object proposal에 Classification을 더한 형태, 또는 Object recognition에 Localization을 더한 태스크로 볼 수 있으며 Detection의 Anchor보다 확장된 개념으로, Segmentation을 포함한 Computer vision system의 다양한 태스크에 사용됩니다.
이전 GOOD 리뷰에서도 언급한 바처럼 SotA Obejct proposal은 Closed world 가정아래 사전 정의된 카테고리 집합에서 다루어지므로 실 세상에서는 Annotation 이외 카테고리의 객체들은 발견하기 어렵습니다. 한 마디로, Unseen 객체에 대한 Localization이 불가합니다. 저자는 이에 대해 사람의 본질적인 능력인 “Open-world의 Novel한 Object proposal을 학습하는 방법”을 흉내내는 방법에 대해 알고자합니다. 사전 정의된 카테고리 집합 이외의 전혀 다른 외형의 객체에 대한 Proposal을 예측하고자 목표하지만, 해당 시점까지의 방법론들은 전혀 다른 외형에 대한 Proposal들을 Closed set의 Annotation과 비교하므로, 주로 배경으로 예측되도록 억압됩니다. 저자는 이 이유에 대해 Closed set과의 비교 시 학습 Loss가 단순히 Foreground vs Background의 Binary classification에서 기인하고 있음을 지적하며 “이다/아니다”의 Classification이 아닌 Proposal이 Object를 포함하고 있을 확률로 “Regression”해야함을 주장합니다 (GOOD은 본 논문의 Architecture를 토대로 설계하였으므로 동일한 주장입니다). 또한 이러한 Classification 기반의 학습은 Closed set 내의 객체에 과적합되기도 합니다. “이다/아니다”의 학습 방식으로 배경으로 억압되다보면, “우리가 아는 Pool내에 있다/없다”로 과적합되는 점을 언급합니다.
따라서 저자는 본 논문에서 Classification-free의 Localization-based Objectness Prediction 방식의 학습을 진행하며 이는 뒤의 방법론에서 다루겠지만 “Faster R-CNN:RPN의 BCE Loss가 아닌 L1Loss (Regression)을 활용”합니다. 물론 해당 방식이 저자가 처음은 아니였지만 (방법론적인 Novelty는 크지 않지만), 이를 Unseen 객체를 찾고자하는 목적으로 시도하였단 점에서 Novelty를 언급합니다. 그래도 RA-L 논문답게, Robot Grasing 측면에서 활용가능함을 언급하고자 RoboNet 데이터셋에 대한 Bounding Box Annotation을 진행하였단 점에서 본 논문이 RA-L에 붙었다는 것이 납득됩니다. 저자의 Contribution은 다음으로 축약됩니다.
- Classification-free(agnostic) 방식의 Object Localization Network (OLN)을 설계하여 Novel object에 대한 Object proposal을 예측함.
- 제안하는 OLN의 모델링 방식이 Localization cue를 활용하며 동시에 Classification 기반의 접근법이 가진 한계인 Closed set의 과적합 문제를 방지함.
- Cross-category (VOC->NON-VOC), Cross-dataset(COCO->RoboNet, LVIS, EpicKitches) generalization 실험에서 베이스라인 및 타 Object proposal에 대한 성능을 뛰어넘음.
- RoboNet 데이터셋에 대한 Annotation을 진행하였으며 이는 다수의 다른 외형의 Novel object를 포함하고 있으므로 Grasping 측면에서 활용 가능성이 있음을 시사함.
Proposed Method
저자가 제안하는 방법은 GOOD 리뷰의 Object Localization Network (OLN)와 동일합니다. 다음 그림의 Fig. 2.는 제안하는 네트워크 구조로, 네트워크는 ResNet50을 백본 네트워크로하는 FPN 구조의 Faster R-CNN의 FPN Feature 집합들에 대해, RPN (Region Proposal Network)를 통과시킵니다. 잘 아시는 바처럼 Faster R-CNN은 각 레벨의 Feature에 대해 3x3x256(512)의 Convolution을 통과시키며, 통과된 Feature map에 대해 각 Pixel별로 1×1 Convolution을 진행합니다. 이 때 Classification에 해당하는 Convolution은 1x1x(2(Object인지/아닌지) * 9(Anchor의 수)), Regression에 해당하는 Convolution은 1x1x(4(Bounding Box Offset) * 9(Anchor의 수))로 취하여 Region Proposal에 관한 연산을 진행합니다. 하지만 본 논문에서는 저자가 언급한 바와 같이 Classification에 해당하는 Convolution이 1x1x(2*9)에서 2의 Object인지/아닌지에 대해 분류하는 과정을 문제로 삼은 만큼, 이 부분을 2가 아닌 1(Objectness Score로써 취함)로 변경시킴으로써 Classification을 Localization quailty로 취급하며 이에 대한 Regression Loss를 활용합니다. 저자는 설계한 방식에 대해 다음과 같이 설명합니다. 논문 원문이 이해에 더 도움이 되리라 생각하여 말 그대로를 인용하겠습니다. The classification view of “objectness” is to ask “how much does this region look like a foreground object?” From a localization standpoint, we want to ask instead “how well does this region overlap with any ground-truth object?”. RPN과 이후 RoI head에서도 마찬가지로, 실제 코드를 보았을 때 Classification Layer를 Localization quality로 새로 명명할때 특이점은 (실험상의 Anchor 수를 하나로 정함 / Centerness와 L1Loss를 활용함 / XYWH가 아닌 LRTB의 Localization Loss를 고려함을 제외한 채) 단순히 1×1 Convolution의 채널 수를 변경했을 뿐인데, 위의 논문 문장을 읽고 난 이후엔 스스로 납득이 되는듯하는, 글의 힘을 느꼈습니다.
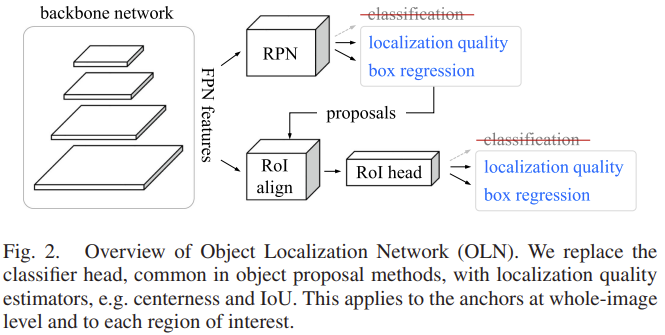
OLN에 대해 다른 부분을 몇몇 더 살펴보자면, 앞서 말한 Localization quality를 학습하고자 L1 Loss를 사용 시 위해 저자는 Centerness를 사용하였습니다. Centerness란 ground-truth 중심에 대한 위치와의 편차를 표현한 개념으로, 기존 CenterNet 등의 Centric object detection의 논문에 이미 사용된 내용이며, 자세히는 RPN head에서 Anchor의 픽셀 위치 \left( x,y \right) 가 ground-truth box B = \left( x_0, y_0, x_1, y_1 \right) , 즉 x_0 < x < x_1, y_0 < y < y_1 일 때, Centerness c^{*}_{x,y} 는 아래의 수식과 같이 ground-truth box의 네 좌표로부터의 거리로 정의됩니다. (위 수식은 Anchor의 픽셀과 ground-truth box 내 Overlap이 존재할 시 0~1 사이의 값으로 나오지만, 그렇지 않을 시에는 (음수가 되므로 0으로 처리됩니다).
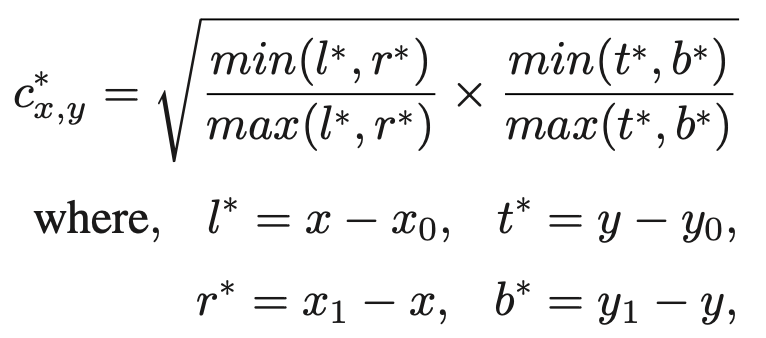
이는 Foreground에 대한 Classification으로부터의 Overfitting을 방지하고자이며, 이외 저자는 Localization quality의 예측 브랜치에서 256개의 Anchor에 대해 IoU 0.3 이상의 랜덤하게 256 개수를 선택하였으며 (Negative mining 없이), Bounding box regression 시 Centerness를 활용하므로 XYHW 형태가 아닌 (Centerness를 다룬 FCOS에서 사용된 바를 따라) LRTB (Left, Right, Top, Bottom)의 Center로부터의 Distance를 활용하였다고 합니다. 이외 저자는 Classification 외 Segmentation에서도 동일하게 해당 방법을 적용하고자 Mask R-CNN에서 RPN head를 동일한 방법으로 변경하여 실험하였습니다. 사실 저는 본 논문과 GOOD의 논문을 모두 읽었으며 두 방법론만으로 각각 엄청난 Novelty가 있다고 느끼진 않았지만, 그들의 설득이 문장을 통해 제 스스로가 설득되는 재미가 있었습니다. 그럼 실험을 살펴보겠습니다.
Experiments
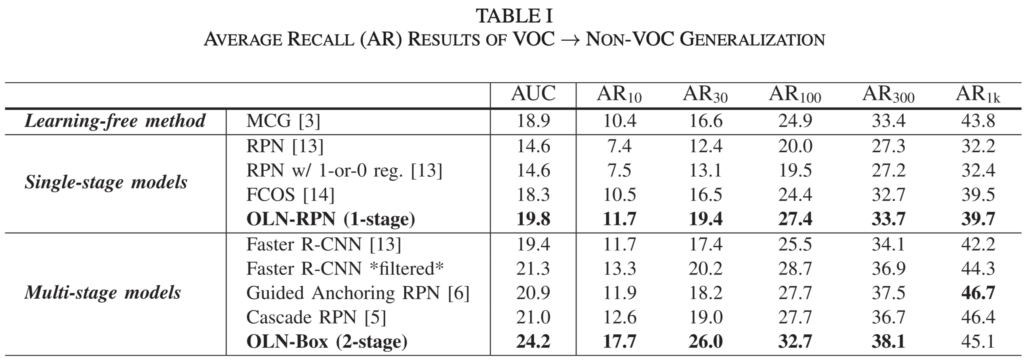
위는 Class-agnostic Object detection을 위한 벤치마크입니다. 저자는 1) Cross-category generalization: COCO 데이터셋에서 Average Recall (AR)로 Unseen에 대해 평가합니다. 이 때 저자는 VOC 클래스들과 겹치는 클래스들을 ground-truth (Seen)에 포함시키며 그렇지 않은 COCO의 60개의 클래스들을 Unseen으로 평가합니다. 아마, 본 논문이 2022년에 나온것으로 보아 해당 설정은 OWOD (CVPR2021)의 설정을 따르지 않았나 싶습니다. 이에 대한 실험 표는 Table 1로, AUC 외 AR_10, AR_30, AR_100, AR_300, AR_1k 에 대해 처음보셨을텐데, 해당 아래첨자는 Unseen에 대한 예측 시의 Budget 수로, 많은 Budget일 수록 더 많은 Objectness를 예측했단 의미이므로 (Inference 시에는 더 느린 속도를 보일테지만) 더 높은 성능을 보임은 당연합니다. Single-stage와 Multi-stage는 FPN의 사용 여부에 따른 바로, 제안하는 OLN-Box의 성능이 웬만하면 높지만 Budget이 1k까지 늘어났을 시에는 Guided Anchoring RPN (Iterative RPN + Deformable Conv) 모델에서의 성능이 더 높다고 리포팅되어 있습니다.
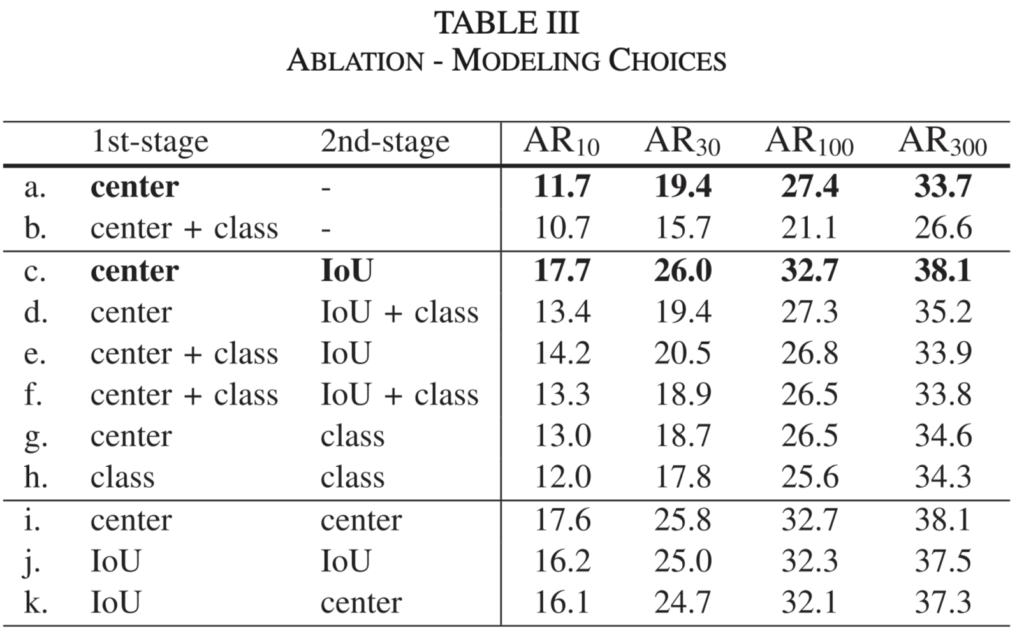
Table 3은 (Table 2는 아래 Table 5에 대한 설명 시 같이 설명드리겠습니다) Method에서 언급한 Centerness외 box-IoU (우리가 잘 아는 IoU 기반의 L1 Loss로, RoI head에서 사용됩니다)에 대한 Ablation study입니다. 저자가 최종적으로 선택한 모델링은 C로, RPN에서 Centerness와 RoI head에서 box-IoU 방식이 Localization quality prediction의 학습 방식에 도움이 됨을 언급합니다. 물론, 본 실험 표도 그렇고 성능에 대한 언급도 그렇지만, 표의 표현 방식이 가독성이 떨어지며 그렇기에 성능에 대해서도 최고 성능에 대한 단순한 리포팅만 되어 있습니다.
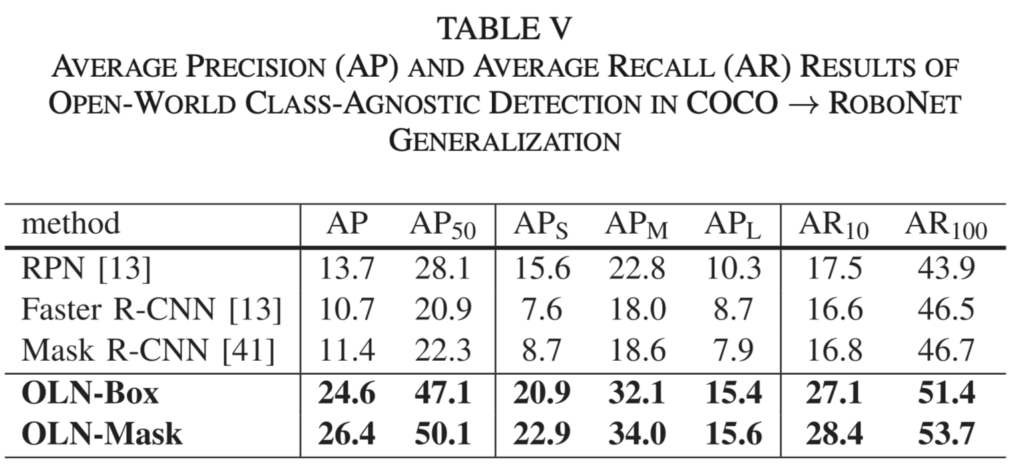
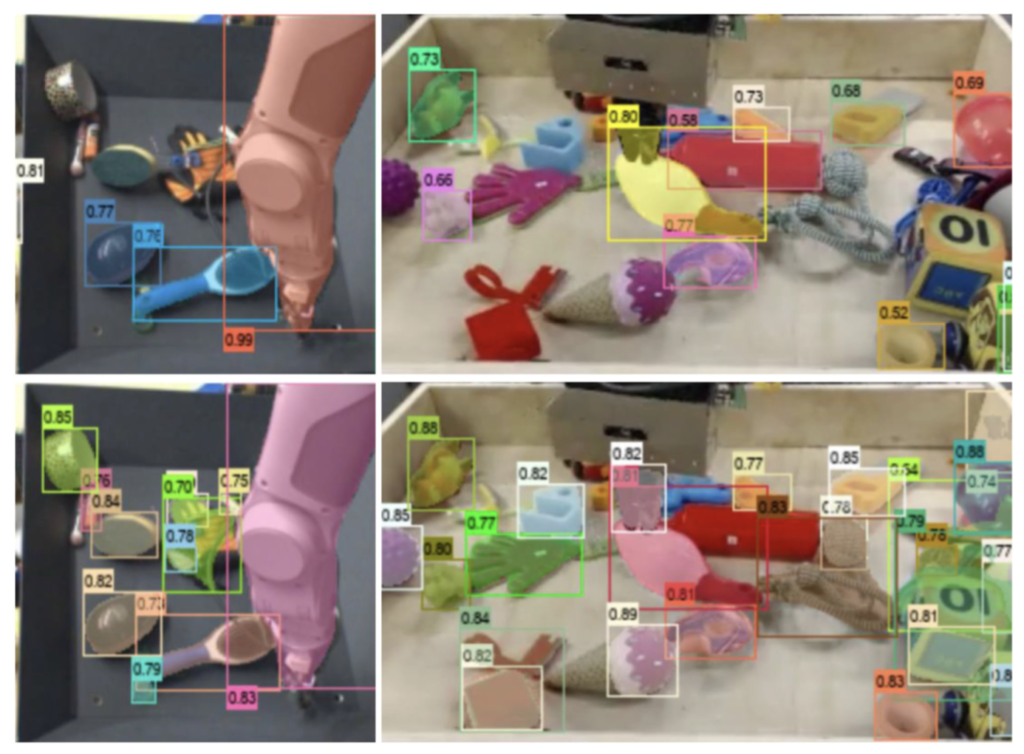
다음 살펴볼점은 Table 5로, Introduction에서 설명한 “왜 본 논문이 RA-L 논문에 관심을 이끌었을까”에 대한 답변으로, Detection에서는 적어도 저는 한번도 보지 않은 RoboNet 데이터셋에서의 2) Cross-dataset generalization 실험입니다. 저자는 RoboNet 데이터셋에 대해 직접 Annotation을 진행하였으며 (하나의 Contribution) 아래 사진에서 확인할 수 있는데, Mask R-CNN (위)과 OLN-Mask (아래)에 대한 성능 비교 시, OLN-Mask에서는 굉장히 많은 수의 Unseen을 찾아냄을 알 수 있습니다. 그보다도 제가 OLN-Mask라고 소개드렸는데, 저자는 단순 Bounding box를 사용하는 Detection 외에도 Mask branch를 사용하는 (Mask R-CNN과 같이) 방식을 OLN의 모듈에 그대로 적용하였습니다. 그 때 성능이 기존 Faster R-CNN과 Mask R-CNN의 성능 향상처럼 동일하게 높아짐을 알 수 있는데, 이는 Table 2에 나와있지만 Table 5 (Mask와 관련된 Ablation인 Table 5도 여기서 첨부합니다)의 OLN-Box, OLN-Mask에 대한 성능 차이로 설명드릴 수 있는 수준이였기에 배제하였습니다.

단 두줄의 Table 6는 LVIS 데이터셋에서의 성능 비교로, 제가 흥미롭게 본 점은 AP rare, AP comm., AP freq. 즉 해당 데이터셋이 표의 제목에서 알 수 있듯 Long-tail dataset (소수의 클래스가 다수의 데이터 분포를 차지하며, 이외의 클래스들에 대해선 몇몇의 데이터만이 존재함)인만큼 AP보다도 특히 AR rare가 관심을 이끌었는데, 그 이유는 GOOD 논문에서 언급한 바와 같이 해당 모델이 결국 학습시에는 ground-truth의 외형에 Overfitting될 수 밖에 없기에 그 성능 차이가 유의미하지 않을 것이라 보았는데 (동시에 AR freq.에서성능이 향상할 것으로 기대함), 오히려 제 예상의 정반대결과를 보였습니다. 물론, GOOD 논문에선 LVIS 데이터셋을 통한 실험을 리포팅하지 않아 해당 주장에 대한 Pair comparison은 어렵지만, 300개의 Budget을 사용했기 때문인지, 저자는 해당 데이터셋에 대한 실험 리포팅은 세팅 제외.. 성능 제외.. 없습니다. 고찰이 없음이 아쉽네요.. 그렇담 마지막으로 주방을 배경으로 한 EpicKitchens 데이터셋에 대한 시각화 자료를 살펴본 채 본 리뷰를 갈음하도록 하겠습니다.
사실, 우리가 논문에서 어쩌면 글로는 제일 안 읽는 파트가 실험파트일 수 있는데, 몇몇 논문들의 실험파트를 읽다보면 오히려 다른 서론, 관련연구, 방법론에 비해 실험파트는 각각의 논문 마다 다른 방식으로 쓰여져 있음이 최근 느껴집니다. 사실은 실험 파트가 우리의 실험을 보일 수 있으며 (위 방법론을 설득시킬 수 있는 하나의 방안이기도 하며), 실제 논문이 붙고떨어짐을 결국 방법론이 실험파트에서 증명이 되었을 때 알 수 있는데, 그렇기에 최근 논문의 실험파트를 읽으면 괜찮은 구성등은 기록해두고자 합니다 (이전 몇몇의 논문과 달리 실험파트에 꽤나 글이 많이 적힌 논문이 그와 같습니다). 그럼 리뷰 읽어주셔서 감사합니다.

안녕하세요. 좋은 리뷰 감사합니다.
long tail detection에 대한 실험을 보여주는 table6에서 AR rare, AR comm, AR freq는 각각 데이터셋에서 차지하는 분포를 기반으로 클래스를 나눠 이에 대한 AR를 각각 측정한 것으로 보이는데요, 이전 GOOD에서 이 실험을 리포팅하지 않았다고 한 것으로 보아 본 논문의 저자가 임의로 데이터셋을 나눈 것 같은데 이에 대한 기준이 무엇이었는지 궁금합니다.
감사합니다 !
안녕하세요, 이상인 연구원님. 좋은 리뷰 감사합니다.
Model choicd를 나타내는 [table 3]에서 + class를 추가하면 전체적으로 성능이 낮아지는 경향이 있는데 여기서 ‘class’란 어떤 것을 의미하는지 궁금합니다. [그림 2]에서 삭제된 classification loss를 의미하는 것일까요?
안녕하세요 상인님 좋은 리뷰 감사합니다.
분류에서의 손실함수가 이진분류를 통한 학습에 기인하기에 Open-world에서의 novel 카테고리에서의 한계를 지적하는 것이 인상적이네요.
제안하는 OLN은 기존 모델에서 classification head를 없애고 손실함수만 바꾼건가요?
RoboNet 데이터셋를 직접 annotation했다고했는데 annotation을 진행할 카테고리의 선정은 기존 RoboNet의 annotation을 따라간건가요? 기존 RoboNet의 annotation과의 차이점이 궁금합니다.
감사합니다.