Introduction
Speech Emotion Recognition (SER)은 인간-컴퓨터 상호작용을 새롭게 정의하는 중요한 연구 분야입니다. 이 기술은 고객 서비스, 의료, 교육, 운송, 포렌식, 미디어 등 다양한 분야에서 매우 유용하게 활용될 수 있습니다. SER의 복잡성은 화자, 성별, 나이, 문화, 방언 등 여러 요인에 따라 달라지며, deep learning 기법을 이용한 감정 인식이 특히 효과적입니다. 특히 CNN, RNN, LSTM 등의 모델이 SER에 성공적으로 적용되고 있습니다.
하지만 감정 인식 모델의 generalization 능력은 제한적이며, 이는 training과 testing 데이터 간의 불일치로 인해 발생합니다. SER corpora는 상대적으로 규모가 작고, 감정 데이터의 수집과 주석 작업이 시간과 비용이 많이 듭니다. 감정은 주관적이어서 여러 annotator가 반복적으로 데이터를 검토해야 하며, 이러한 제약이 모델의 generalization 성능에 영향을 미칩니다.
이를 극복하기 위해 multi-task learning (MTL)이 제안되었습니다. MTL은 주어진 데이터의 여러 측면을 활용하거나 보조 작업에서 데이터를 추가로 얻어 모델을 보다 잘 규제하고 중요한 고수준 표현을 학습하게 합니다. 하지만 기존의 MTL 기법은 정확한 meta label이 필요하여 한계가 있었습니다.
본 연구에서는 데이터 증강과 비지도 학습을 활용한 semi-supervised MTL framework (MTL-AUG)를 제안합니다. 이 방법은 데이터 증강 유형을 auxiliary task로 사용하여 일반화된 표현을 학습하고, 주요 감정 인식 성능을 향상시킵니다. 구체적으로, data augmentation type classification과 unsupervised reconstruction을 auxiliary task로 사용하여 meta label 없이도 효과적인 감정 인식이 가능합니다. 데이터 증강을 통해 입력 음성에 temporal, frequency 변형을 적용하고, unsupervised learning을 통해 데이터를 재구성하여 모델의 성능을 더욱 향상시킵니다.
연구는 IEMOCAP, MSP-IMPROV, EMODB 등의 데이터베이스를 이용해 제안된 프레임워크의 성능을 평가하였으며, noisy 및 adversarial attack 상황에서도 강력한 generalization 능력을 보임을 입증하였습니다. 제안된 MTL-AUG 프레임워크는 기존의 CNN-BLSTM 모델과 비교하여 뛰어난 성능을 보여주었으며, 특히 다양한 환경(within-corpus, cross-corpus, cross-language, noisy)에서 감정 인식 성능 향상을 통해 그 유용성을 입증하였습니다.
Methodology
앞서 논문에서 제안하는 MTL-AUG는 일반화된 감정 표현을 학습하기 위해 augmentation type classification과 unsupervised reconstruction을 사용하였다고 합니다. MTL-AUG의 전체 framework를 설명드리기 앞서 auxiliary task 중 augmentation classification에 사용된 augmentation 기법을 간단히 설명드리겠습니다.
Speech Data Augmentation
본 논문에서는 augmentation type classification을 위해 (1) speed perturbation [51], (2) mixup [52], (3) SpecAugment이라는 augmentation 기법을 사용하였다고 합니다.
speech data에 대한 augmentation은 다소 생소하실 수도 있을 것 같아 각 기법에 대해 간단히 설명드리겠습니다.
speed perturbation은 음성 신호의 속도를 조절하는 방식으로 raw wavform 형태의 음성 신호 x(t) 가 주어졌을 때 이를 x(\alpha t)로 warping하는 것을 의미합니다. 즉, 주어진 음성 신호의 길이를 \alpha 만큼 배속하는 것이라고 이해하시면 될 것 같습니다.
다음으로 SpecAugment는 음성의 hand-craft feature인 mel-spectrogram에 적용하는 augmentation 기법으로, frequency 방향과 time 방향으로 masking을 수행하는 방식에 해당합니다. 아래 그림은 음성의 mel-spectrogram의 예시인데, 가로축인 time과 세로축인 frequency 도메인에 대해 masking을 진행한 것을 확인할 수 있습니다.
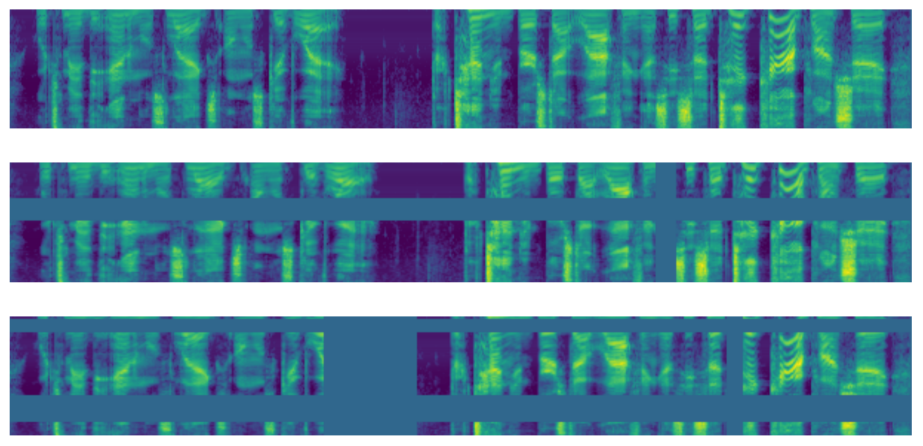
마지막으로 mixup은 vision 도메인과 서로 다른 두 sample을 가중합하는 방식입니다. 이는 raw audio와 mel-spectrogram 모두 동일한 방식으로 진행할 수 있는데 본 논문에서는 mel-spectrogram에 적용했다고 합니다.
논문의 MTL-AJG의 입력 데이터는 위의 세 가지 augmentation기법을 적용한 음성 데이터를 입력하였습니다.
MTL-AUG Framework
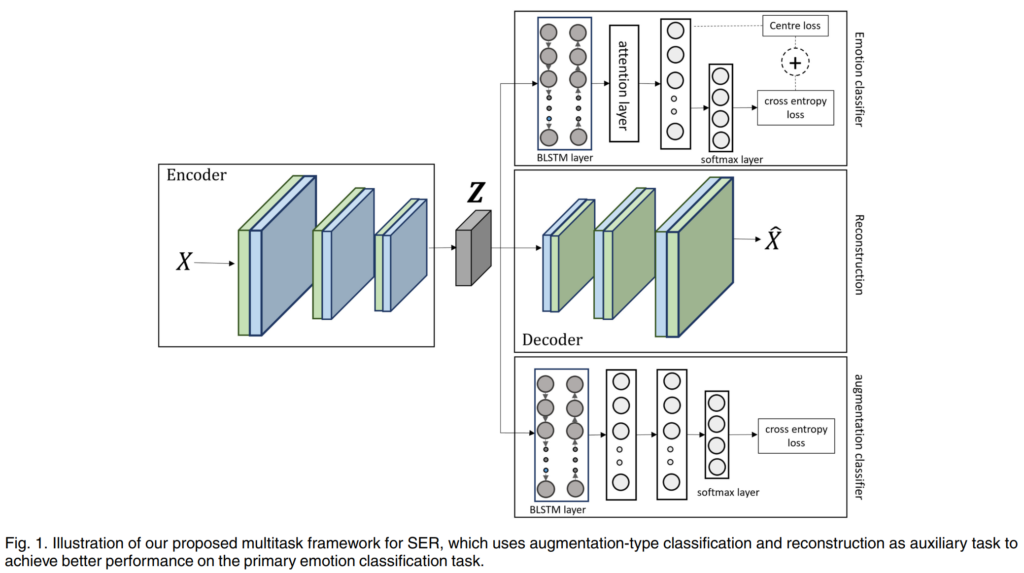
위의 [그림 1]은 논문에서 제안하는 MTL-AUG로 모든 task에서 공통으로 사용되는 encoder와 emotion classification을 수행하는 emotion classifier C_E, 그리고 reconstuction을 위한 decoder D, augmentation classifier C_A로 구성되어 있습니다.
전체 모델의 학습은 아래 MTL loss를 통해 진행되며 그 수식은 아래의 [수식 3]과 같습니다.
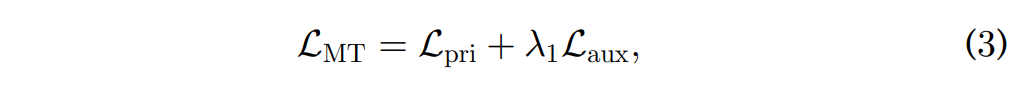
위의 [수식 3]에서 L_{pri}, L_{aux}는 각각 main task인 emotion recognition과 그 외의 auxiliary task를 의미합니다.
먼저 본 논문의 main task인 emotion recognition의 동작 방식을 설명드리겠습니다.
[그림 1]의 인코더를 통해 feature Z를 추출하고 Z는 아래 그림과 같은 emotion classifier로 들어오게 됩니다.
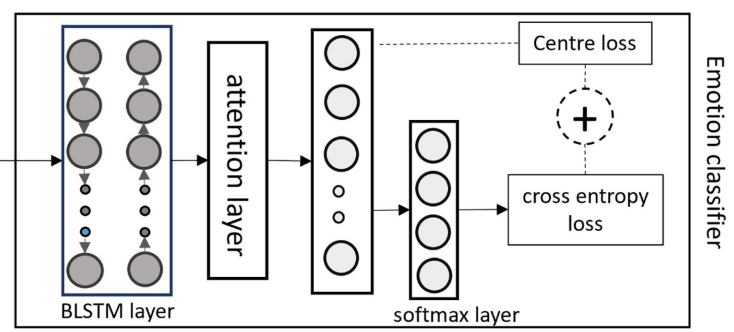
Emotion classifier는 comtextual modeling을 위한 BLSTM, 감정 분류와 가장 관련성이 높은 feature를 학습하기 위한 attention layer, 마지막으로 감정을 분류하기 위한 dense layer를 사용하였습니다.
Emotion Classifier에 sequnce h_i 가 압력되었을 때, utterence level의 feature는 attention 레이어에서 아래의 [수식 4]와 같이 계산됩니다.
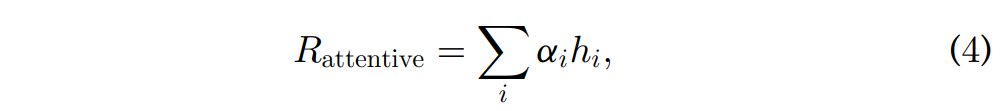
위의 [수식 4]에서 \alpha_i 는 각 sequencd의 중요도, 즉 가중치를 나타내며 아래의 [수식 5]와 같이 계산합니다.
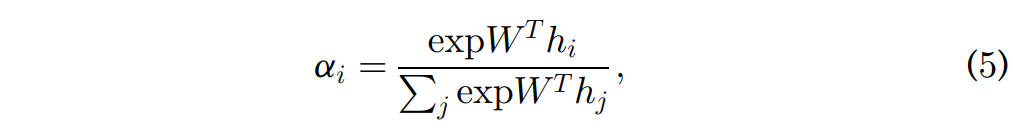
[그림 1]에서 emotion classifier는 두 가지의 loss를 통해 학습되는 것을 볼 수 있는데요, 이를 수식으로 나타내면 아래와 같습니다.
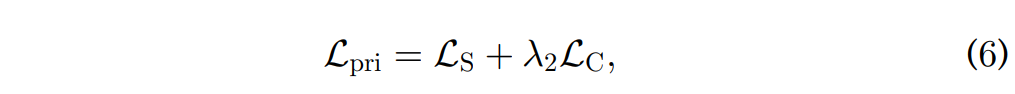
L_S는 softmax corss-entropy loss로 우리가 익히 알고 있듯이 분류를 위한 loss애 해당하고, L_C는 Center Loss입니다. Center loss는 각 데이터로부터 추출한 feature가 해당하는 class의 중심과 가까워지도록 유도하는 loss애 해당하며, class간의 분별력을 높이기 위해 사용되었다고 합니다.
다음으로는 multi task learning을 위해 추가된 auxiliary task에 대해 설명드리겠습니다.
본 논문의 두 번째 task에 해당하는 task는 input speech feature reconstruction입니다. Reconstuction task에서는 encoder와 decoder가 reconstruction loss를 최소화하는 방식으로 학습이 이루어집니다. 즉, encoder의 성능 향상을 위한 autoencoder라고 할 수 있으며 loss는 아래의 [수식 8]과 같이 나타낼 수 있습니다.
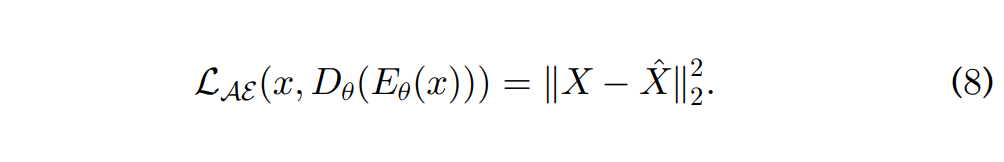
마지막 task는 augmentation classification으로 입력 데이터에 어떤 augmentation이 적용되었는지 분류하는 task에 해당합니다. raw speech에 대한 speed perturbation, Mel-spectrogram에 대한 SpecAugment, mixup의 세 가지 augmentation 중 하나를 입력 데이터에 적용하고, 네 가지 클래스(speed perturbation, SpecAugment, mixup, no augmentation)중 하나로 분류하도록 모델 학습을 진행하였습니다.
전체 네트워크는 unsupervised와 supervised 방식을 모두 사용하여 학습되었는데요, 또한 감정 label이 없는 데이터를 사용하여 학습할 때는 auxiliary task의 loss만을 encoder 업데이트에 사용하였습니다.
Experiments
Datasets
본 논문에서는 세 가지 음성 감정 데이터셋에 대해 평가를 진행하였으며, encoder의 학습을 위한 auxiliary task를 위해 감정 라벨이 없는 음성 데이터셋을 추가로 사용하였습니다. 또한 real-workd의 상황을 모델링하기 위한 noise 데이터셋도 추가로 사용하였다고 하며, 각 데이터셋에 대한 정보는 아래와 같습니다.
emotion dataset
IEMOCAP
- 10명의 전문 배우의 즉흥 대화를 수집한 영문 multiomodal emotion dabase
- 본 논문에서는 전체 감정 중 angry, happy, neutral, sad의 네 가지 감정을 사용함
MSP-IMPROV
- 12명의 배우의 즉흥 대화로 구성된 영문 multimodal emotion database
- IEMOCAP과 마찬가지로 전체 감정 중 angry, happy, neutral, sad의 네 가지 감정만을 사용함
EMODB
- IEMOCAP, MSP-IMPROV와 달리 독일어 emotion dataset
- cross-language 환경에서의 모델 성능 평가를 위해 사용함
non-emotion dataset
LibriSpeech
- 2484명의 화자로부터 수집된 1000시간 분량의 audiobook 데이터셋
- 논문에서는 100시간 분량을 sampling하여 auxiliary task의 unlabelled 데이터로 사용함
DEMAND
- 다양한 실내외 소음을 포함하는 데이터셋
- 다양한 소음 환경에서 모델의 강인성을 평가하기 위해 사용됨
Experiments and Results
지금부터 실험 결과에 대해 설명드리겠습니다. 그 전에 본 논문의 모든 실험은 speaker-independent한 방식으로 수행되었으며, 구체적으로는 학습과 평가 시 한 명의 speaker를 평가 데이터로 사용하는 one-speaker-out 교차 검증을 수행하였다고 합니다. 리포팅된 실험 결과는 10번의 실험을 수행한 평균과 표준 편차이며 metric은 unweighted Average Recall(UAR)을 사용하였습니다.
Within Corpus Experiments
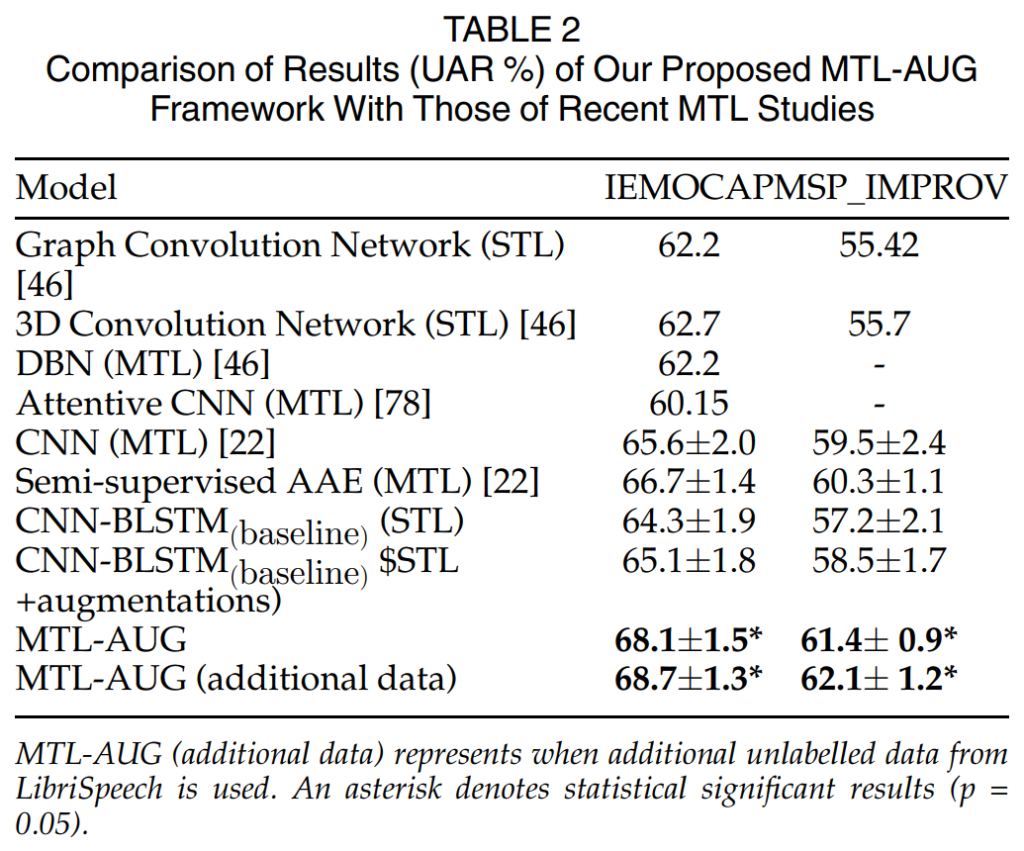
위의 [표 2]는 within-corpus 환경에서 SER 성능을 나타낸 것입니다.
위 표에서 1~4행은 감정 분류 성능을 향상시키기 위해 auxiliary task에 dimensional emotion prediction을 수행한 방법론입니다. Dimensional emotion prediction은 연속 감정 예측으로 긍/부정과 같이 연속적인 차원으로 이루어진 감정을 예측하는 것이라고 이해하시면 될 것 같습니다. 이러한 기존 감정 라벨을 사용한 방법론의 성능이 가장 낮은 것을 확인할 수 있습니다.
5~8행은 음성의 speaker and gender identification을 auxiliary task로 사용하여 multitasking semi-supervised adversarial autoencoder (SS-AAE)로 일반화된 표현을 학습한 방법론에 해당합니다. 해당 방법론들은 위의 방법론들과는 달리 추가적인 데이터를 활용하였다는 차이점이 있으며 성능 또한 항상된 것을 확인할 수 있습니다. 그러나 해당 방법론은 모델은 음성의 speaker와 gender에 대한 추가적인 label이 필요하며, 이러한 메타 정보 없이는 unsupervised 데이터를 활용할 수 없다는 문제점이 있었습니다.
마지막으로 MTL-AUG는 추가 데이터에 어떠한 label 정보가 없어도 학습 가능하다는 장점이 있으며, 그 성능 또한 기존 방법론들을 뛰어넘은 것을 확인할 수 있습니다. [표 2]의 최하단은 LibriSpeech 데이터를 추가적으로 사용한 성능을 나타내며 감정 관련 라벨이 없는 음성 데이터를 추가적으로 학습에 사용할 수 있고 이것이 성능 향상에 기여할 수 있다는 것을 보여주고 있습니다.
Cross-Corpus and Cross-Language Evaluations
Cross-Corpus
저자들은 MTL-AUG의 일반화 성능을 확인하기 위해 cross-corpus 환경에서 실험을 진행하였으며, 구체적으로는 IEMOCAP 데이터셋으로 학습한 모델을 MSL-IMPROV 데이터셋으로 평가하였습니다.
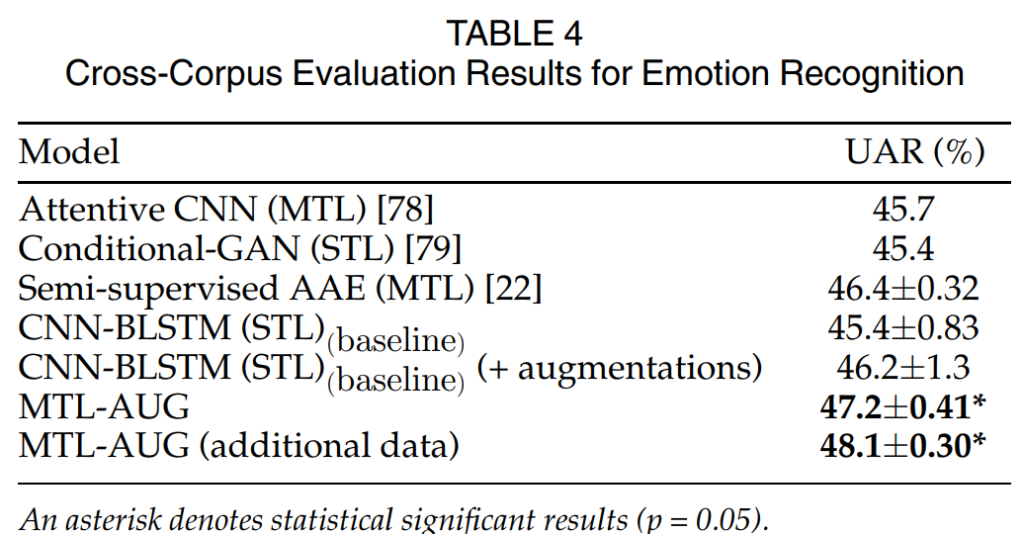
[표 4]의 결과를 통해 저자들의 방법론이 서로 다른 도메인의 환경에서도 잘 동작하며, 이를 통해 일반화 성능이 뛰어나다는 것을 확인할 수 있습니다.
Cross-Language
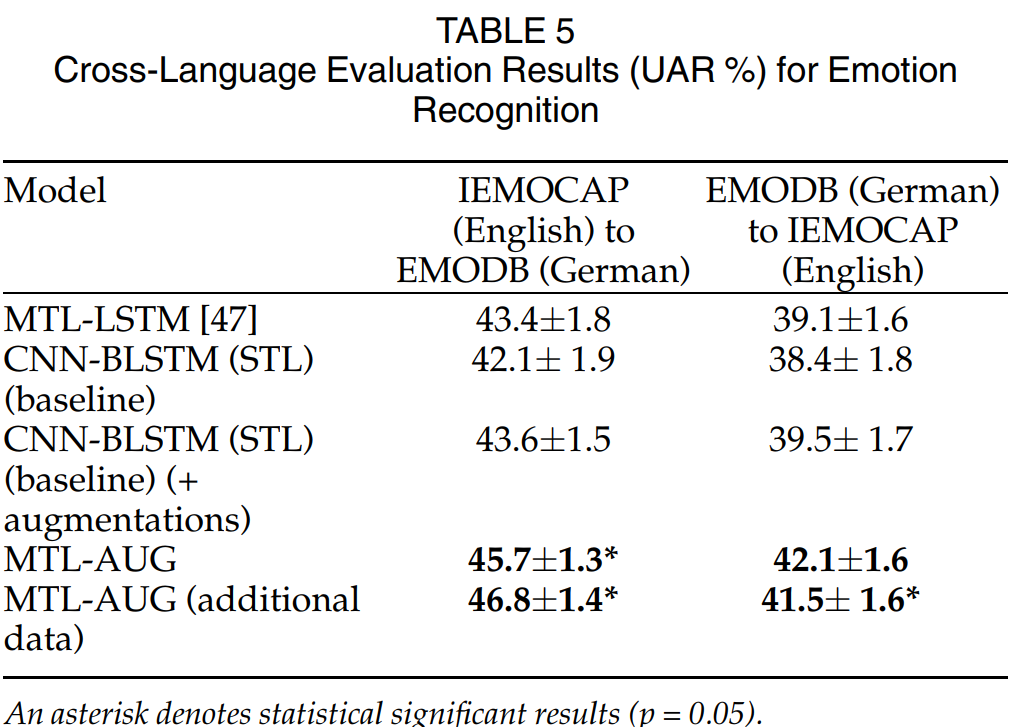
[표 5]는 cross-language 환경에서의 일반화 성능을 확인하기 위한 실험으로 영어 음성 감정 데이터셋인 IEMOCAP으로 모델을 학습하고, 독일어 음성 감정 데이터셋인 EMODB에서 평가한 성능을 나타내며, Cross-Corpus와 마찬가지로 저자들의 성능이 가장 뛰어난 일반화 성능을 보이는 것을 확인할 수 있습니다.
Evaluation of Robustness to Noise
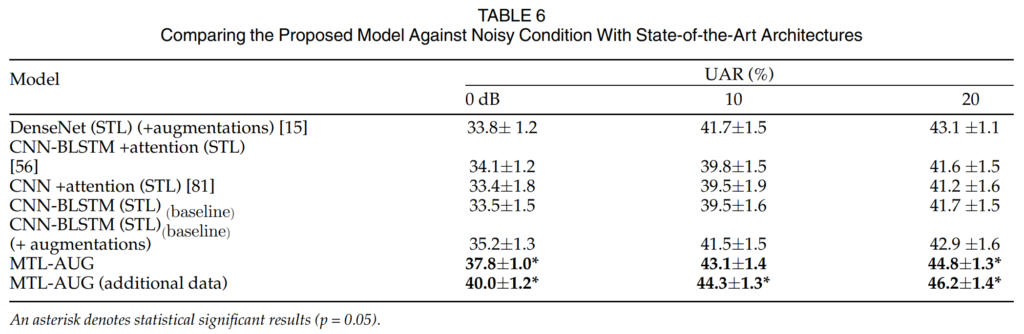
[표 6]은 noise 환경에서의 일반화 성능을 평가한 결과입니다. 구체적으로는 clean한 음성으로 학습한 모델에 noisy input이 들어왔을 때를 모델링한 것으로, 음성 데이터셋에 DEMAND 데이터셋의 noise를 무작위로 합성하여 평가 데이터로 사용하였습니다.
실험은 SNR을 [0, 10, 20]으로 설정하여 진행하였는데, 이때 SNR은 Signal-to-Noise Ratio로 clean speech와 noise간의 비율을 나타내며 숫자가 작을 수록 noise가 큰 것으로 이해하시면 됩니다.
저자들이 제안한 MTL-AUG는 encoder가 일반화된 표현을 학습하도록 하여, noise 환경에서 강인한 SER을 수행할 수 있도록 하였습니다. 는 데 강인함을 달성할 수 있도록 하였습니다. [표 6]을 통해 augmented 데이터를 사용하여 STL 모델을 학습하면 noise 환경에 대한 강인성을 향상시킬 수 있음을 확인할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
본 논문에서 다양한 augmentation을 사용하였는데 이와 관련하여 궁금한 부분이 있습니다. 이미지의 경우 augmentation했을 때 augmentation을 적용했을 때의 이미지를 확인할 수 있어서 이 augmentation이 어떤 의도로 동작하는구나를 이해할 수 있는데, SpecAugment이나 mixup같은 경우 spectrom으로 augmentation하는 경우여서 이게 정말로 실생활에서 발생할 수 있는 경우를 augmentation한 것인지 의문이 듭니다. 아니면 단순히 데이터를 불리기 위해서 사용한 걸까요? 만약에 그렇다면 정말 이 방법론이 real-world에서 동작할 수 있을지 의문이 듭니다. 혹시 논문의 저자가 이에 대해서 언급한 부분이 있을까요?
감사합니다.
댓글 감사합니다.
우선 논문에서는 모델이 common representation을 학습할 수 있도록 하기 위해 해당 기법들을 적용하였다고 언급하였습니다. 그리고 SpecAugment의 경우 실제 환경에서 발생하는 주파수 왜곡을 반영하기 위한 augmentation기법이라고는 알고 있는데, 이 부분은 해당 기법을 제안한 논문을 통해 확인해보도록 하겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
평가 지표에 대해 질문이 있는데, UAR(Unweigted Average Recall)이 구체적으로 무엇인가요 ? 기존 AR 과 차이점이 무엇인지 궁금합니다. 또, BLSTM같은 경우는 Bi-LSTM과 같은 것인가요 ? ? ?!
Dimensional emotion prediction이 연속 감정 예측이라고 하셨는데,,, 예시로 들어주신 긍/부정을 봐도 ,, 잘 이해가 안가서 좀 더 구체적으로 설명해주실 수 있을까요 !?!?
감사합니다 !
댓글 감사합니다.
1. UAR (Unweighted Average Recall)는 각 클래스의 recall 값을 평균내어 전체 성능을 평가하는 것을 의미합니다. AR은 전체 데이터에 대해 recall 값을 계산하게 되는데요, 이때 특정 class에 데이터 개수가 많다면 그 class의 결과가 더 크게 반영되겠죠. 본 논문에서는 class 별 데이터 비율에 상관없이 동일한 가중치를 부여하기 위해 UAR을 사용하였다고 합니다.
2. 넵. BLSTM은 Bi-LSTM과 동일한 레이어를 의미합니다.
3. Dimensional emotion prediction이란 ‘happy’, ‘sad’같이 discrete한 감정이 아니라 valence, arousal, dominance같이 연속적으로 나타나는 속성을 예측하는 것을 의미합니다. 예를 들어 어떤 speech의 긍정/부정 감정을 [0, 1]사이의 연속적인 값으로 표현된다고 가정하면 0.1의 값을 가지는 음성보0.5의 값을 가지는 음성이 보다 긍정적인 음성이고, 0.8인 음성이 그보다 더 긍정을 나타낸다고 할 수 있습니다. ‘sentiment analysis’의 개념으로 받아들이셔도 좋을 것 같습니다.